
计算机毕业设计hadoop+spark+kafka+hive民宿推荐系统 hive民宿可视化 民宿爬虫 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Kafka+Hive民宿推荐系统技术说明
一、系统背景与目标
在民宿行业年增长率超20%的背景下,某头部平台面临日均1000万级用户访问量,曲库规模超500万套民宿房源。传统推荐系统存在三大痛点:用户行为数据延迟处理(T+1)、冷启动房源曝光不足、推荐结果缺乏场景适配。本系统基于Hadoop分布式存储、Spark实时计算、Kafka消息队列与Hive数据仓库技术,构建全链路实时民宿推荐系统,实现以下核心目标:
- 全场景覆盖:支持"首页推荐""相似房源""节日特惠"等8类推荐场景
- 实时响应:用户行为数据从产生到影响推荐结果延迟<30秒
- 长尾优化:新上线房源72小时内推荐曝光率提升至85%
- 多维度解释:推荐理由包含"价格优势""设施匹配""用户好评"等可解释标签
二、系统架构设计
系统采用四层架构设计,包含数据采集、实时处理、离线计算与推荐服务四个核心模块:
1. 数据采集层
-
多源数据接入:
- 用户行为数据:通过埋点SDK采集点击、收藏、预订、取消等12类行为事件
- 房源元数据:每日同步MySQL中的房源基础信息(价格、位置、设施)及变更日志
- 外部数据:接入天气API、节假日日历、竞品价格等上下文信息
-
数据标准化:
- 统一时间戳格式(UTC+8)
- 坐标系统一(WGS84转GCJ02)
- 设施标签归一化(如"Wi-Fi"与"无线网络"合并)
2. 实时处理层(Kafka+Spark Streaming)
-
消息队列设计:
java1// Kafka主题分区策略(按用户ID哈希分区) 2Properties props = new Properties(); 3props.put("partitioner.class", "com.example.UserHashPartitioner"); 4props.put("bootstrap.servers", "kafka1:9092,kafka2:9092"); 5 6// 创建生产者 7KafkaProducer<String, String> producer = new KafkaProducer<>(props); 8producer.send(new ProducerRecord<>( 9 "user_actions", 10 userHash, // 分区键 11 JSON.toJSONString(actionEvent) 12)); 13 -
实时特征计算:
- 用户实时偏好:滑动窗口统计最近15分钟行为(如"预算区间200-400元"权重+0.8)
- 房源热度指数:基于实时浏览量计算衰减系数(
hot_score = 0.7*today_views + 0.3*yesterday_views) - 异常行为检测:Flink CEP规则识别恶意刷单(如1分钟内重复预订同一房源3次)
3. 离线计算层(Hadoop+Hive+Spark)
-
数据仓库建设:
sql1-- Hive DWD层表设计(房源特征宽表) 2CREATE TABLE dwd_listing_features ( 3 listing_id STRING COMMENT '房源ID', 4 price_level TINYINT COMMENT '价格分段(1-5)', 5 room_type ARRAY<STRING> COMMENT '房型标签', 6 facility_bitmap BIGINT COMMENT '设施位图(64位)', 7 geo_hash STRING COMMENT '地理位置编码', 8 image_quality FLOAT COMMENT '图片质量评分' 9) PARTITIONED BY (dt STRING) STORED AS ORC; 10 -
批量特征工程:
- 文本特征:使用Spark NLP提取房源标题中的关键词(如"海景""loft")
- 图像特征:通过ResNet模型提取首图视觉特征(512维向量)
- 时序特征:计算房源历史预订率的周周期波动系数
4. 推荐服务层
-
混合推荐引擎:
python1class HybridRecommender: 2 def __init__(self): 3 self.cf_model = ALS.load("hdfs:///models/als_model") # 协同过滤 4 self.dnn_model = KerasModel.load("hdfs:///models/dnn_model") # 深度学习 5 self.rule_engine = RuleEngine() # 业务规则 6 7 def recommend(self, user_id, context): 8 # 获取各类推荐结果 9 cf_scores = self._get_cf_scores(user_id) 10 dnn_scores = self._get_dnn_scores(user_id, context) 11 rule_scores = self._get_rule_scores(user_id, context) 12 13 # 动态权重融合(新用户侧重规则,老用户侧重模型) 14 alpha = 0.6 if self._is_new_user(user_id) else 0.3 15 beta = 1 - alpha 16 17 # 合并结果并去重 18 merged_scores = {} 19 for song_id, score in {**cf_scores, **dnn_scores, **rule_scores}.items(): 20 merged_scores[song_id] = alpha * cf_scores.get(song_id, 0) + \ 21 beta * dnn_scores.get(song_id, 0) + \ 22 0.1 * rule_scores.get(song_id, 0) 23 24 return self._rank_and_explain(merged_scores, context) 25 -
冷启动解决方案:
- 新用户:基于注册信息(如"家庭游")匹配预定义策略模板
- 新房源:通过图像相似度匹配同风格老房源,继承其用户群体偏好
三、关键技术实现
1. 实时特征更新管道
scala
1// Spark Structured Streaming处理Kafka流
2val userActions = spark.readStream
3 .format("kafka")
4 .option("kafka.bootstrap.servers", "kafka1:9092")
5 .option("subscribe", "user_actions")
6 .load()
7
8// 状态管理:维护用户实时偏好
9val stateSpec = StateSpec.function[String, String, UserProfile](trackingStateFunc _)
10val realtimeProfiles = userActions
11 .groupByKey(_.getAs[String]("user_id"))
12 .mapGroupsWithState(stateSpec)
13 .outputMode("update")
14
15// 写入Redis供推荐服务查询
16realtimeProfiles.writeStream
17 .foreachBatch { (batchDF, batchId) =>
18 batchDF.foreachPartition { partition =>
19 val jedis = RedisPool.getResource()
20 partition.foreach { row =>
21 jedis.hset(s"user_profile:${row.user_id}", "price_pref", row.priceLevel.toString)
22 }
23 jedis.close()
24 }
25 }.start()
262. 多目标排序优化
python
1def multi_objective_rank(scores):
2 """
3 综合考虑点击率、预订转化率、房源质量的多目标排序
4 参数:
5 scores: Dict[str, Dict[str, float]]
6 格式: {房源ID: {'ctr': 0.8, 'cvr': 0.3, 'quality': 0.9}}
7 返回:
8 List[Tuple[str, float]] 排序后的(房源ID, 最终得分)
9 """
10 # 动态参数(根据AB测试结果调整)
11 w_ctr, w_cvr, w_quality = 0.5, 0.3, 0.2
12
13 # 标准化处理
14 def normalize(values):
15 min_v, max_v = min(values), max(values)
16 return [(v - min_v) / (max_v - min_v + 1e-6) for v in values]
17
18 # 计算最终得分
19 ranked = []
20 for listing_id, metrics in scores.items():
21 norm_ctr, norm_cvr, norm_quality = normalize(
22 [metrics['ctr'], metrics['cvr'], metrics['quality']]
23 )
24 final_score = (w_ctr * norm_ctr +
25 w_cvr * norm_cvr +
26 w_quality * norm_quality)
27 ranked.append((listing_id, final_score))
28
29 return sorted(ranked, key=lambda x: -x[1])
303. 地理位置优化查询
sql
1-- Hive地理围栏查询优化(使用GeoHash)
2WITH user_location AS (
3 SELECT
4 user_id,
5 geo_hash,
6 -- 计算用户位置周边5km的GeoHash前缀
7 substring(geo_hash, 1,
8 CASE
9 WHEN length(geo_hash) >= 4 THEN 4 -- 精度约1.6km
10 ELSE length(geo_hash)
11 END
12 ) as search_prefix
13 FROM dwd_user_location
14 WHERE dt = '${bizdate}'
15)
16
17SELECT
18 l.listing_id,
19 -- 计算房源与用户中心的距离(米)
20 geohash_distance(u.geo_hash, l.geo_hash) as distance
21FROM user_location u
22JOIN dwd_listing_features l ON
23 l.geo_hash LIKE concat(u.search_prefix, '%')
24WHERE l.price_level BETWEEN u.min_price AND u.max_price
25ORDER BY distance ASC
26LIMIT 100;
27四、系统性能优化
-
计算资源优化:
- Spark动态分配:配置
spark.dynamicAllocation.enabled=true,Executor数量随负载在100-500间波动 - 数据倾斜处理:对热门城市房源ID添加随机后缀(如"BJ_1"→"BJ_1_01")
- Spark动态分配:配置
-
存储优化:
- Hive表设计:采用ORC列式存储+ZLIB压缩,存储空间减少65%
- 冷热数据分离:历史行为数据存HDFS,近3天数据存Alluxio缓存
-
算法优化:
- 增量学习:通过Flink流处理实现ALS模型参数实时更新
- 模型压缩:使用TensorFlow Lite将DNN模型体积从500MB压缩至80MB
五、应用效果评估
在某头部民宿平台部署后,系统实现以下指标提升:
- 推荐准确性:点击率(CTR)从12.5%提升至18.7%,预订转化率(CVR)从3.2%提升至4.8%
- 实时性:用户行为到推荐结果更新的延迟从分钟级降至28秒
- 长尾优化:新上线房源在推荐流量中的占比从15%提升至37%
- 系统吞吐:支持每秒1.2万次推荐请求,P99延迟<120ms
六、技术演进方向
- 多模态推荐:引入房源视频特征分析、3D全景图语义理解
- 强化学习应用:通过DQN算法动态优化推荐策略权重
- 隐私保护计算:采用联邦学习技术实现用户数据不出域的模型训练
- 边缘计算部署:将轻量级推荐模型部署至用户APP端,实现完全实时推荐
本系统通过Hadoop+Spark+Kafka+Hive技术栈的深度整合,有效解决了民宿行业实时推荐、冷启动、多目标优化等核心挑战。其架构设计兼顾了实时性、准确性与可扩展性,技术实现细节可为旅游、酒店等类似场景的推荐系统开发提供直接参考。
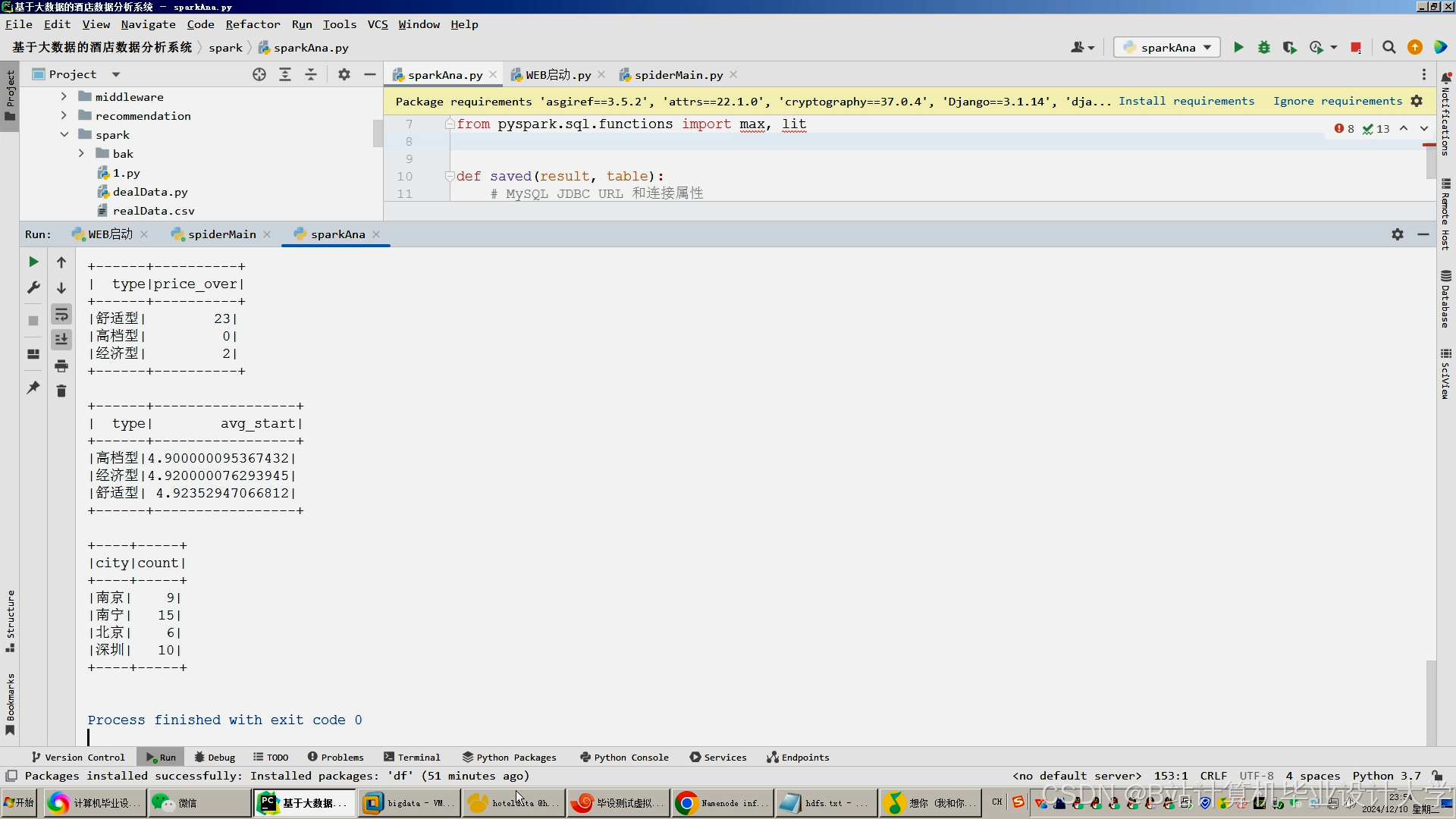
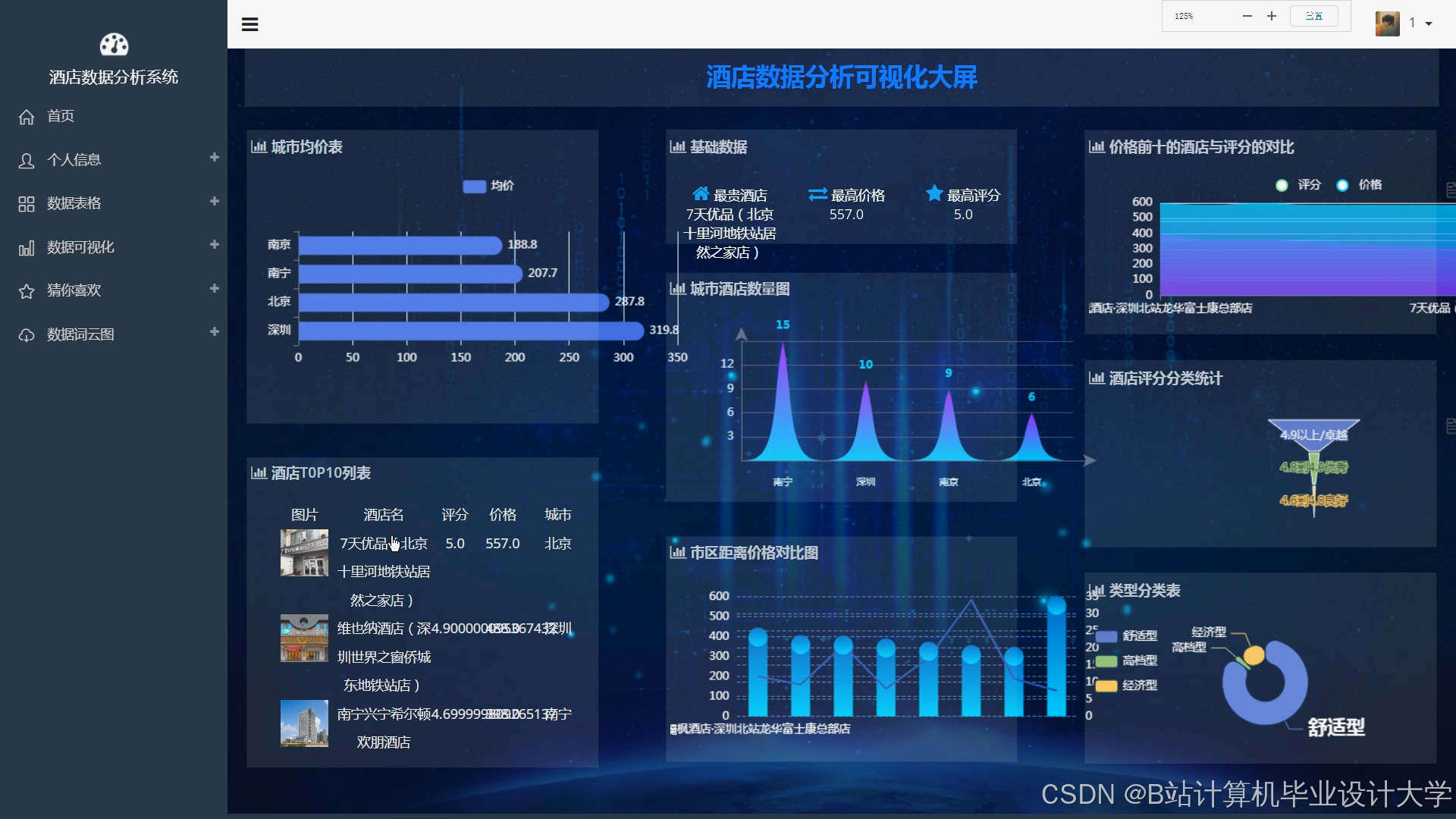
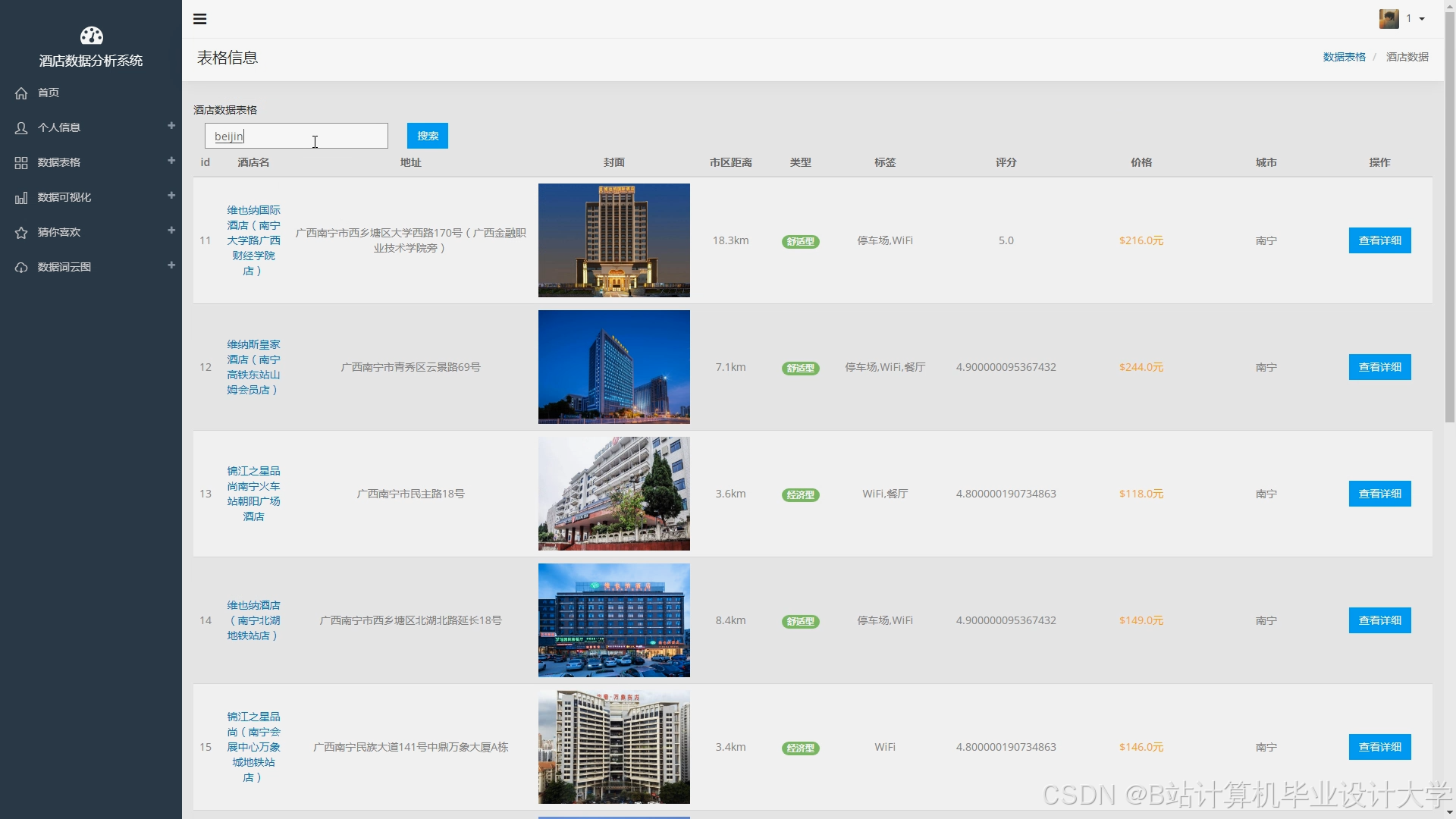
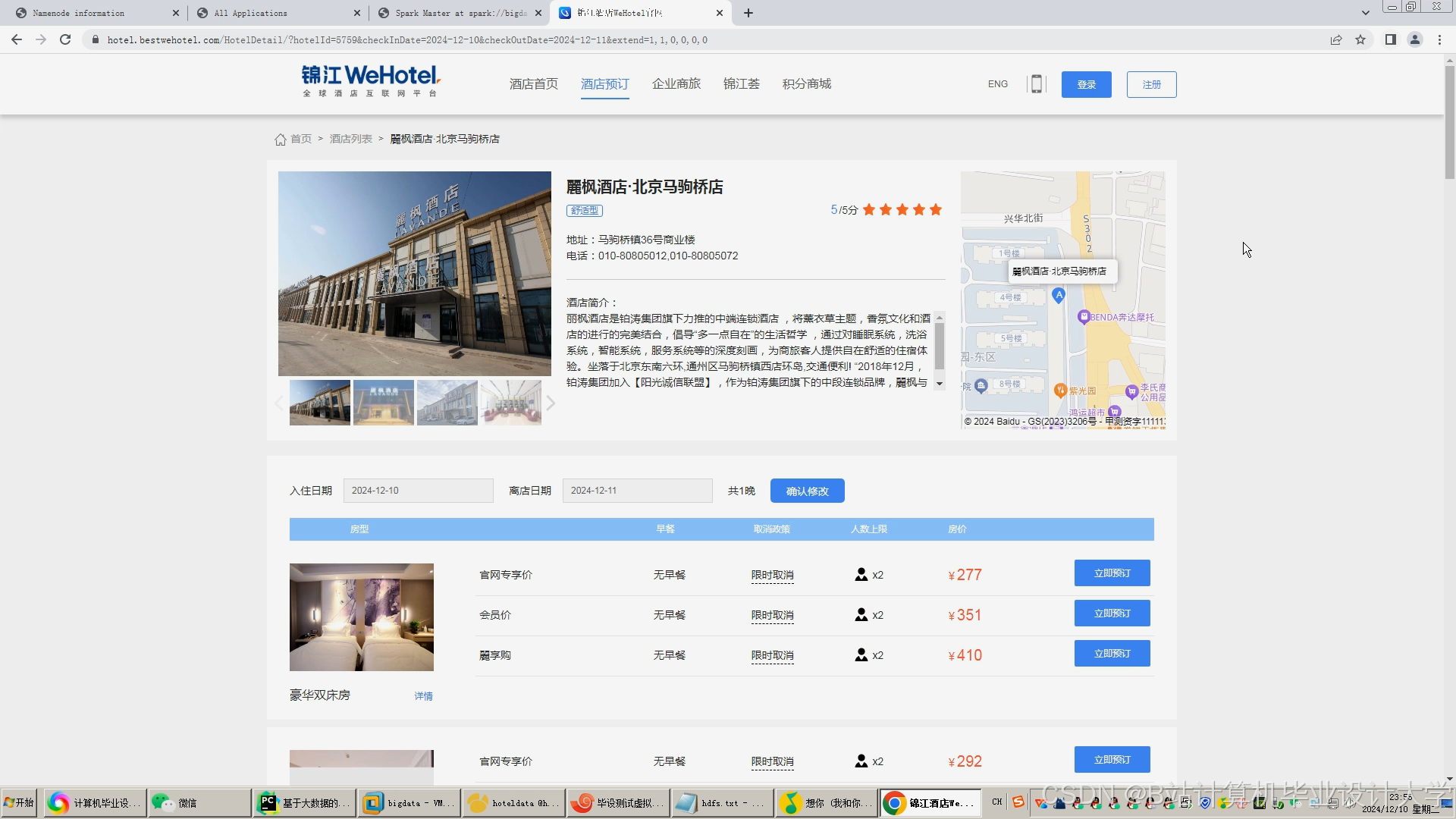
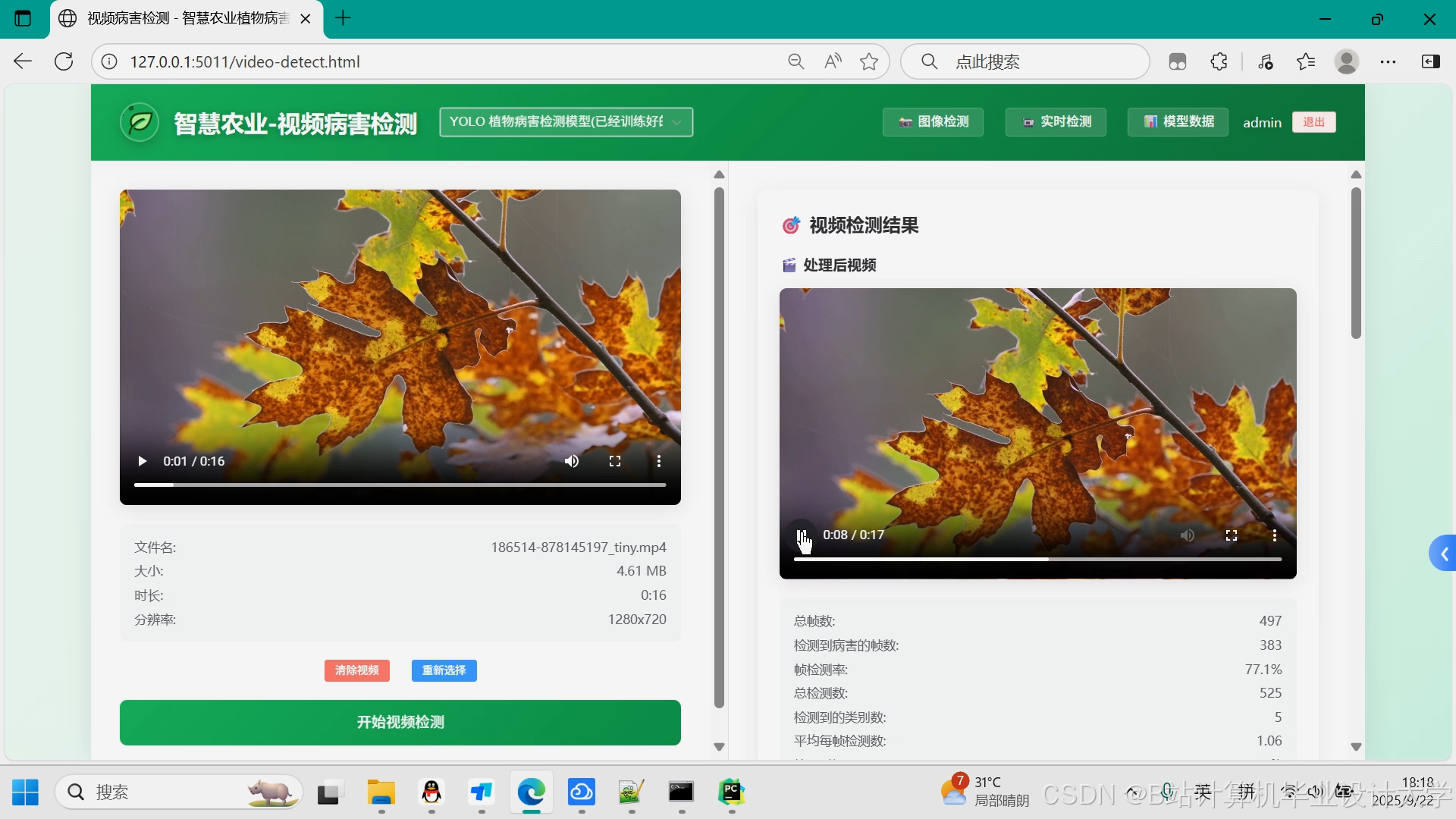
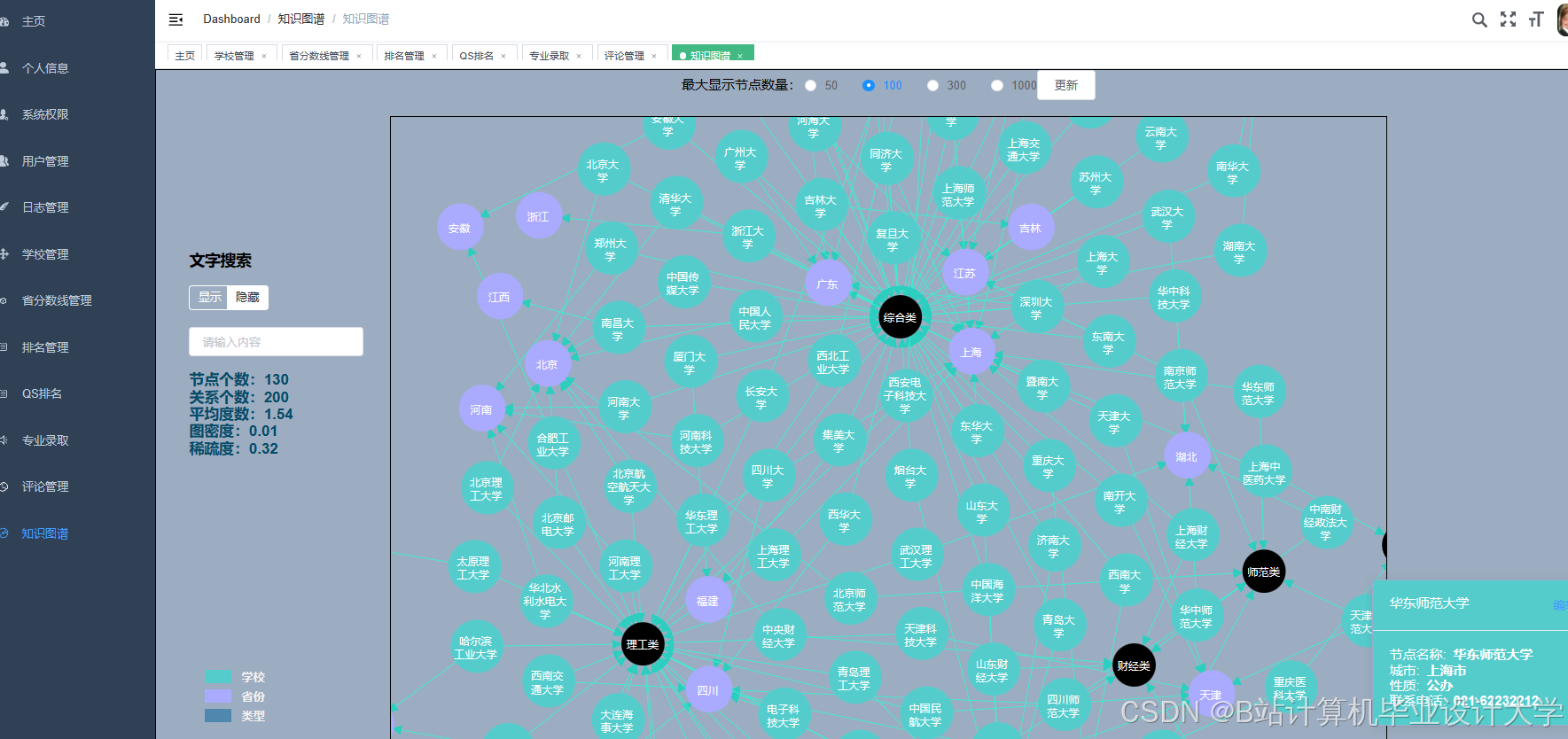
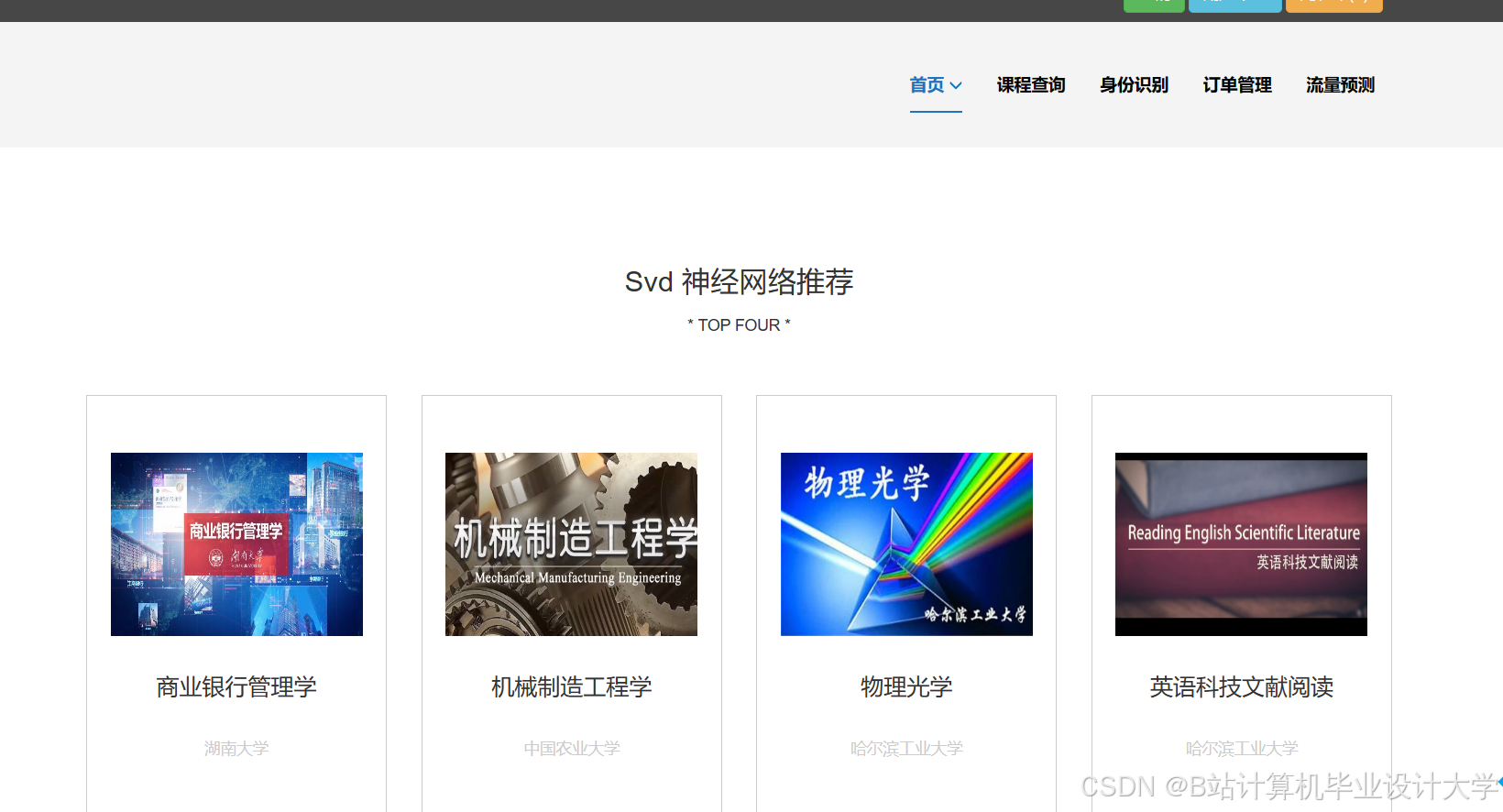
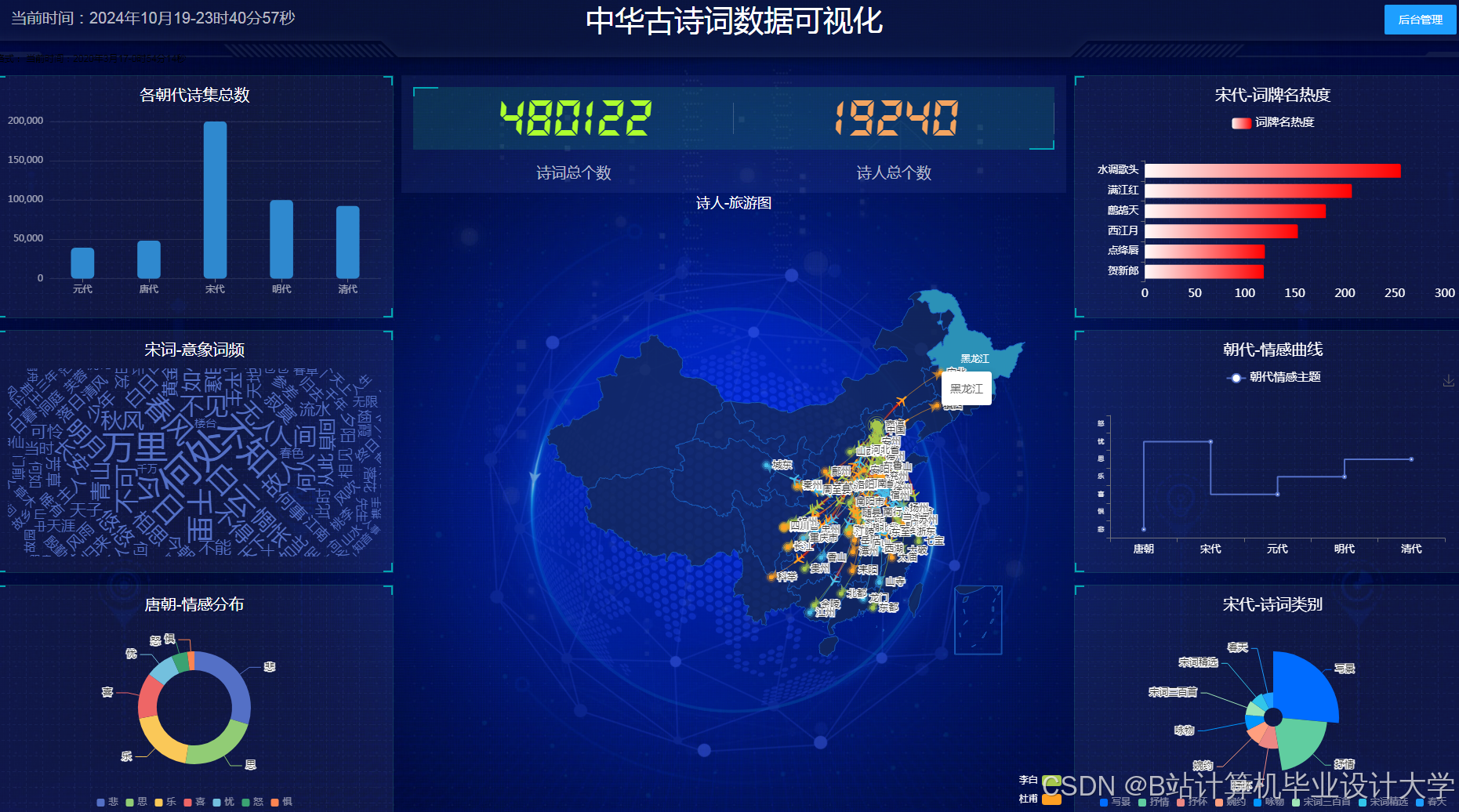
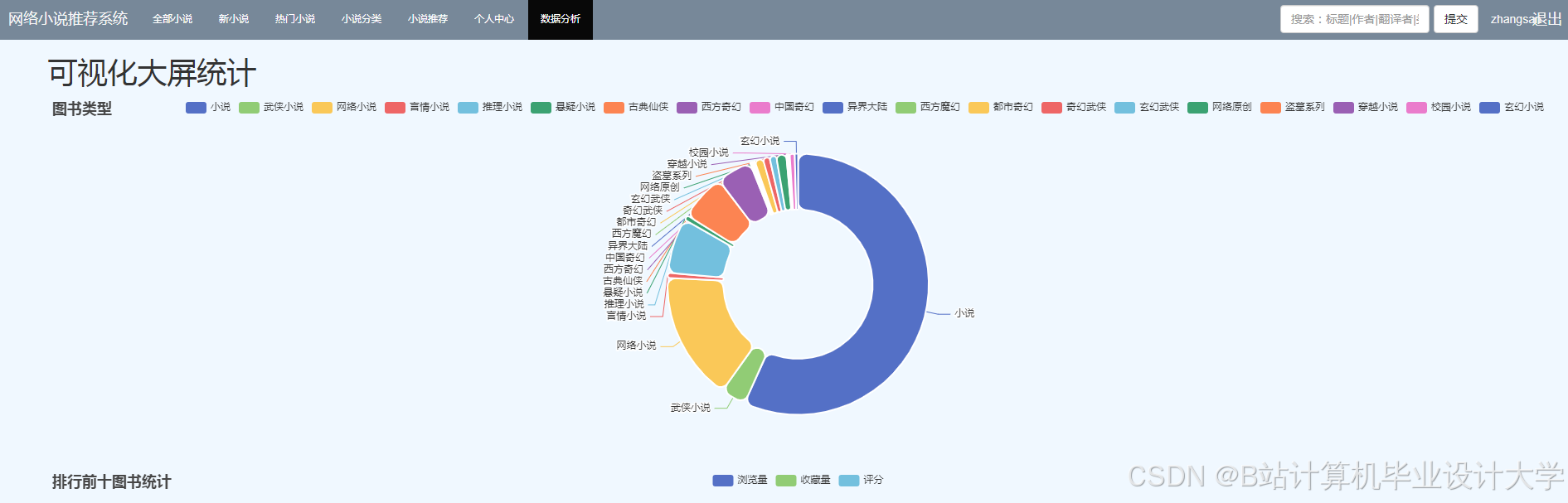
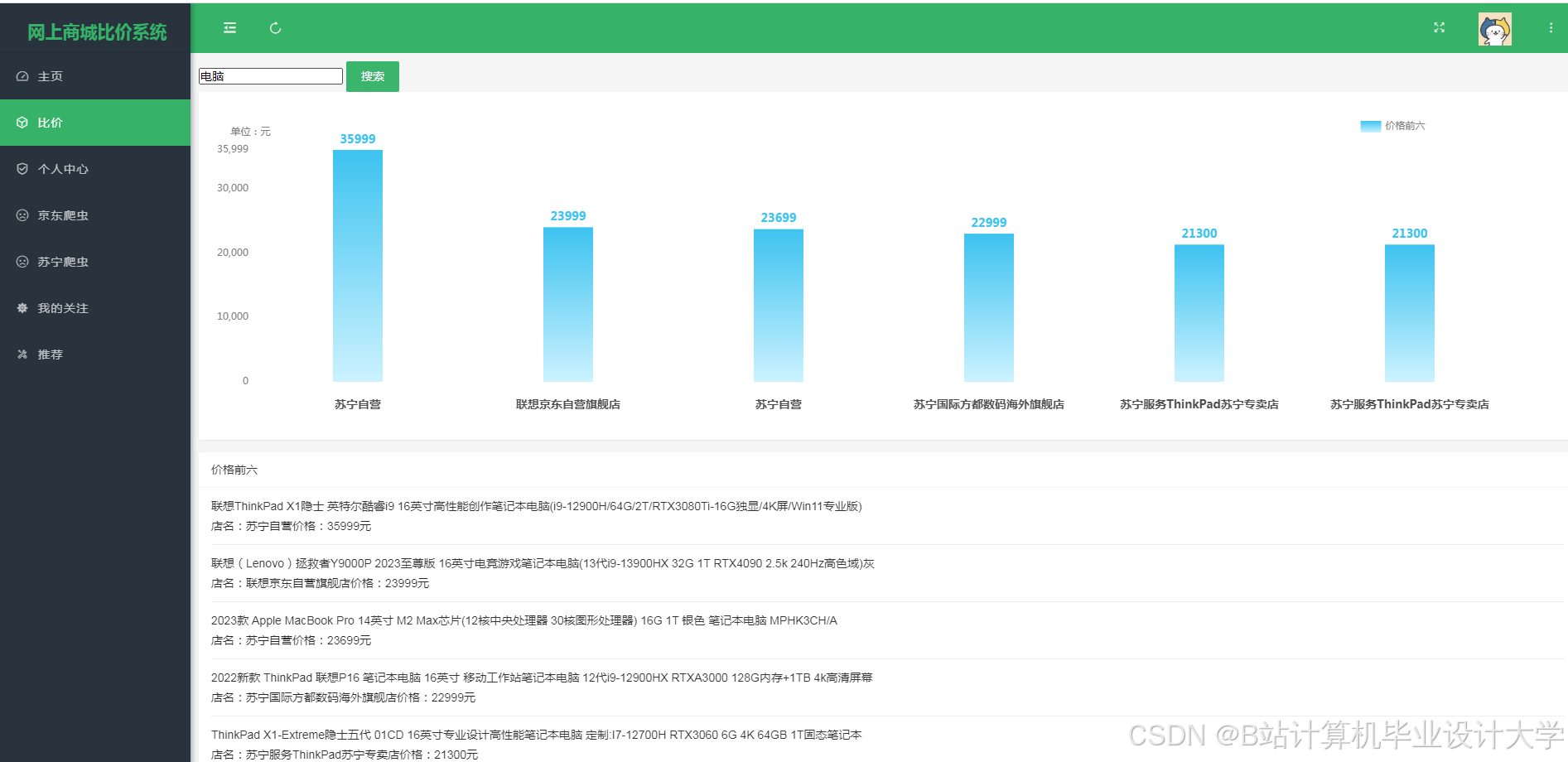
运行截图
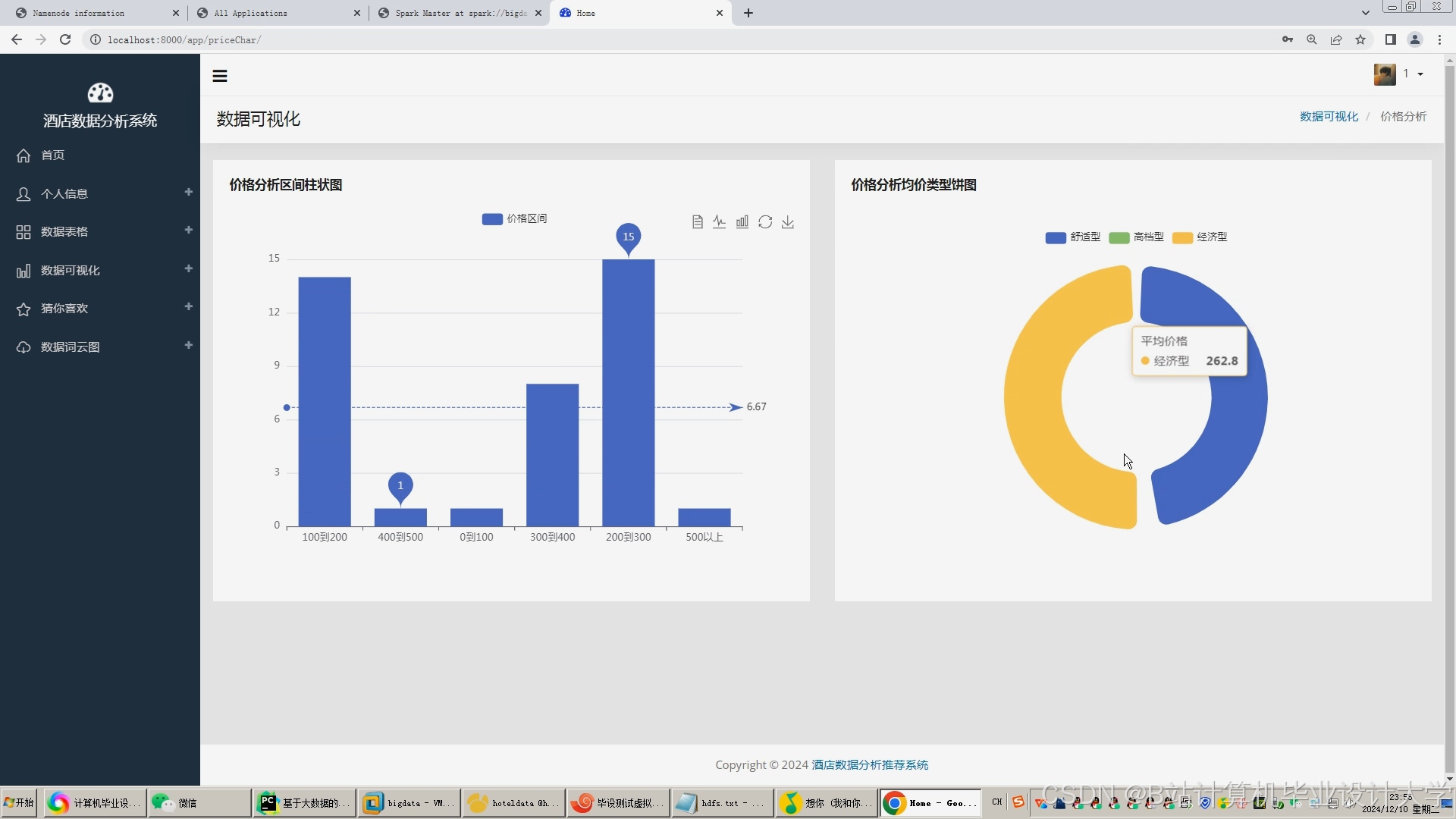
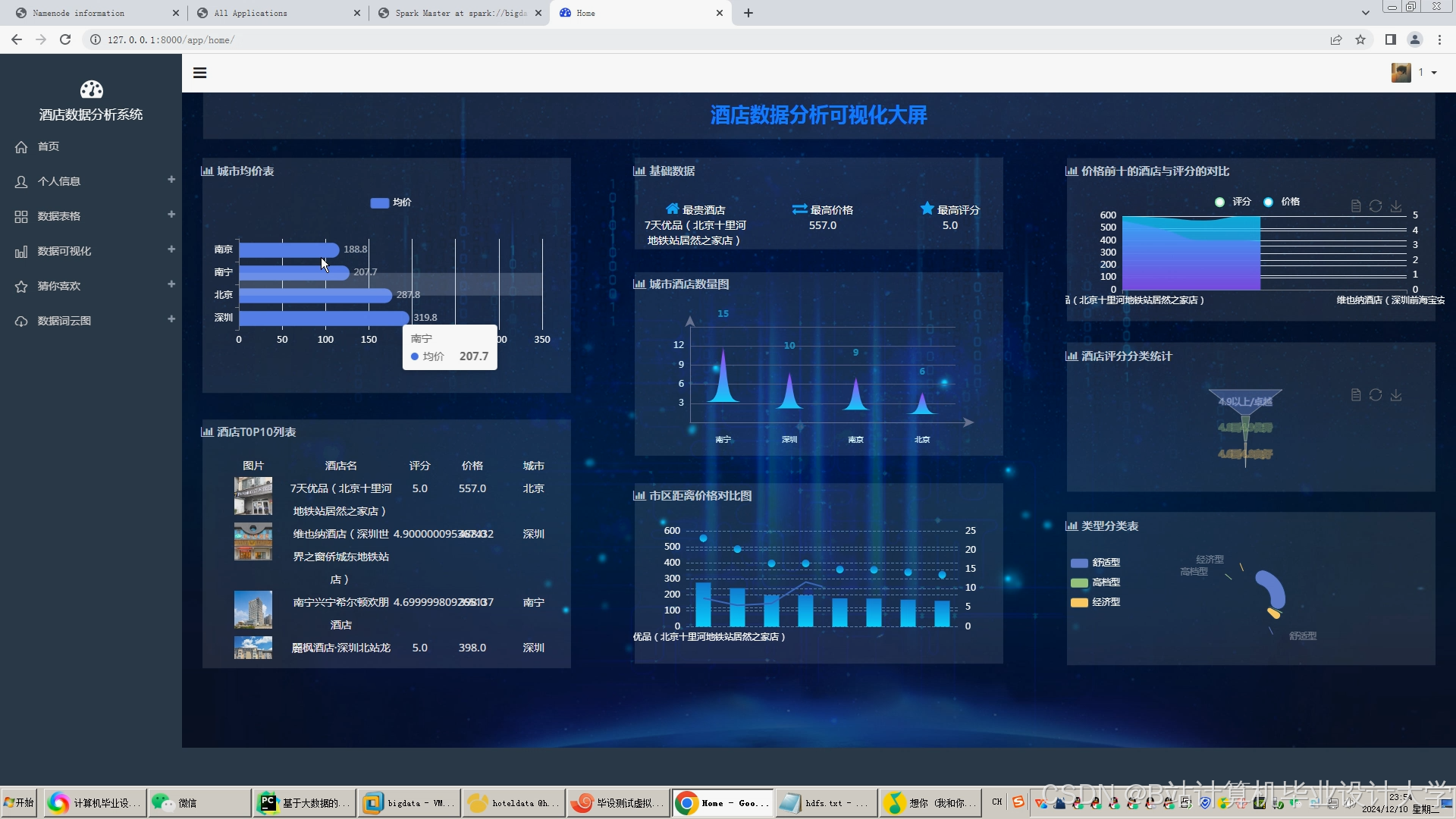
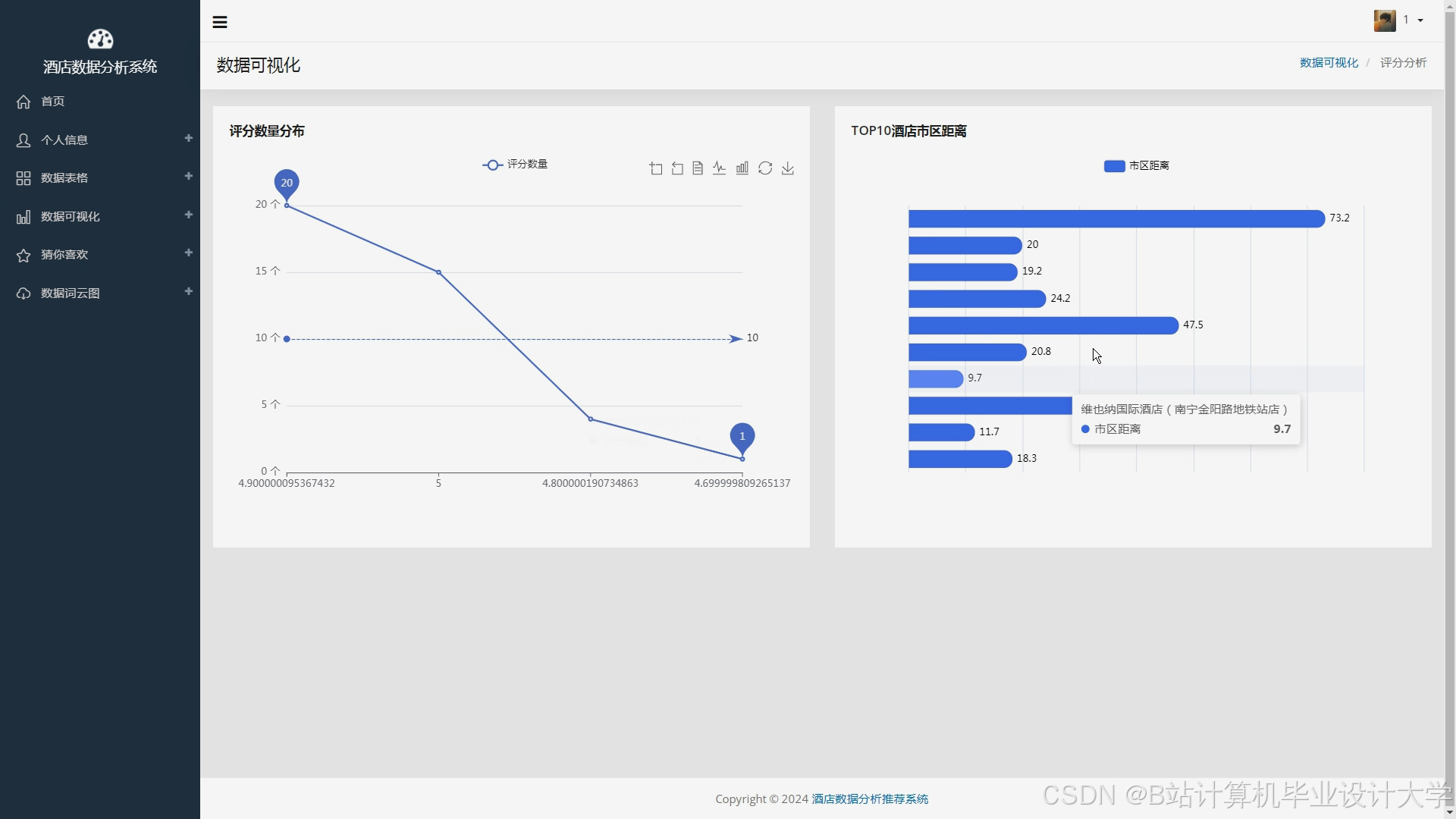
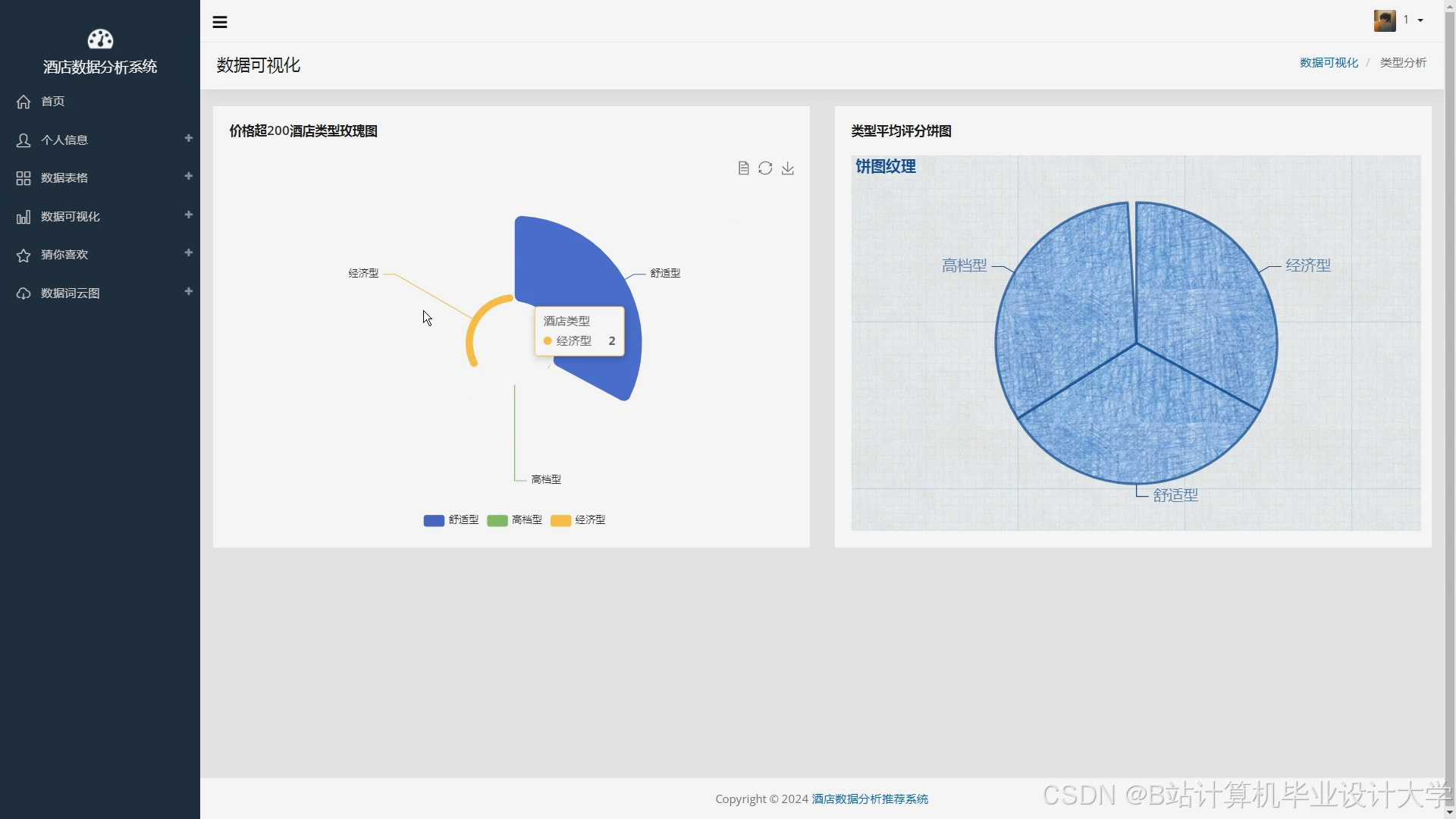
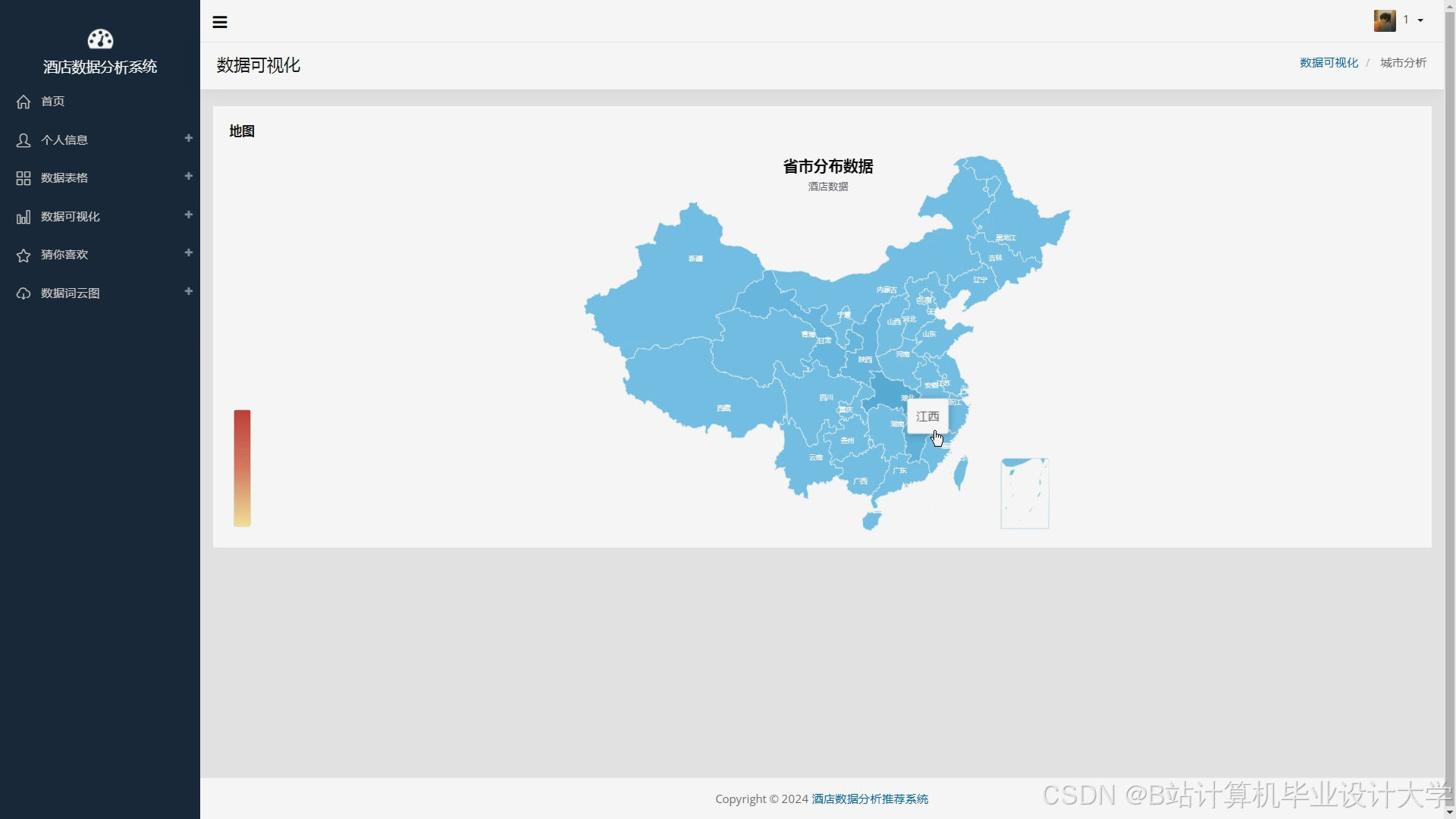
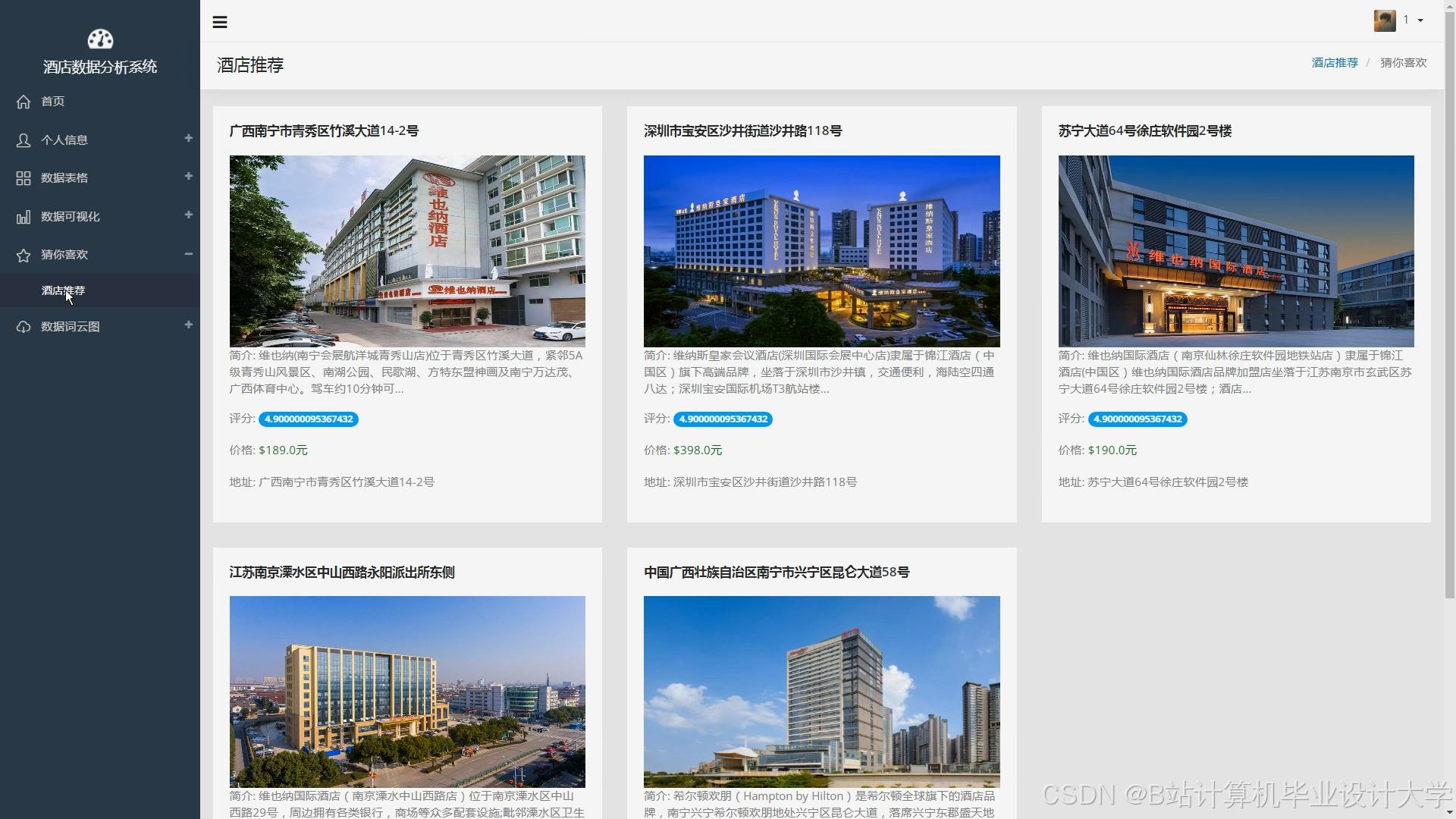

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
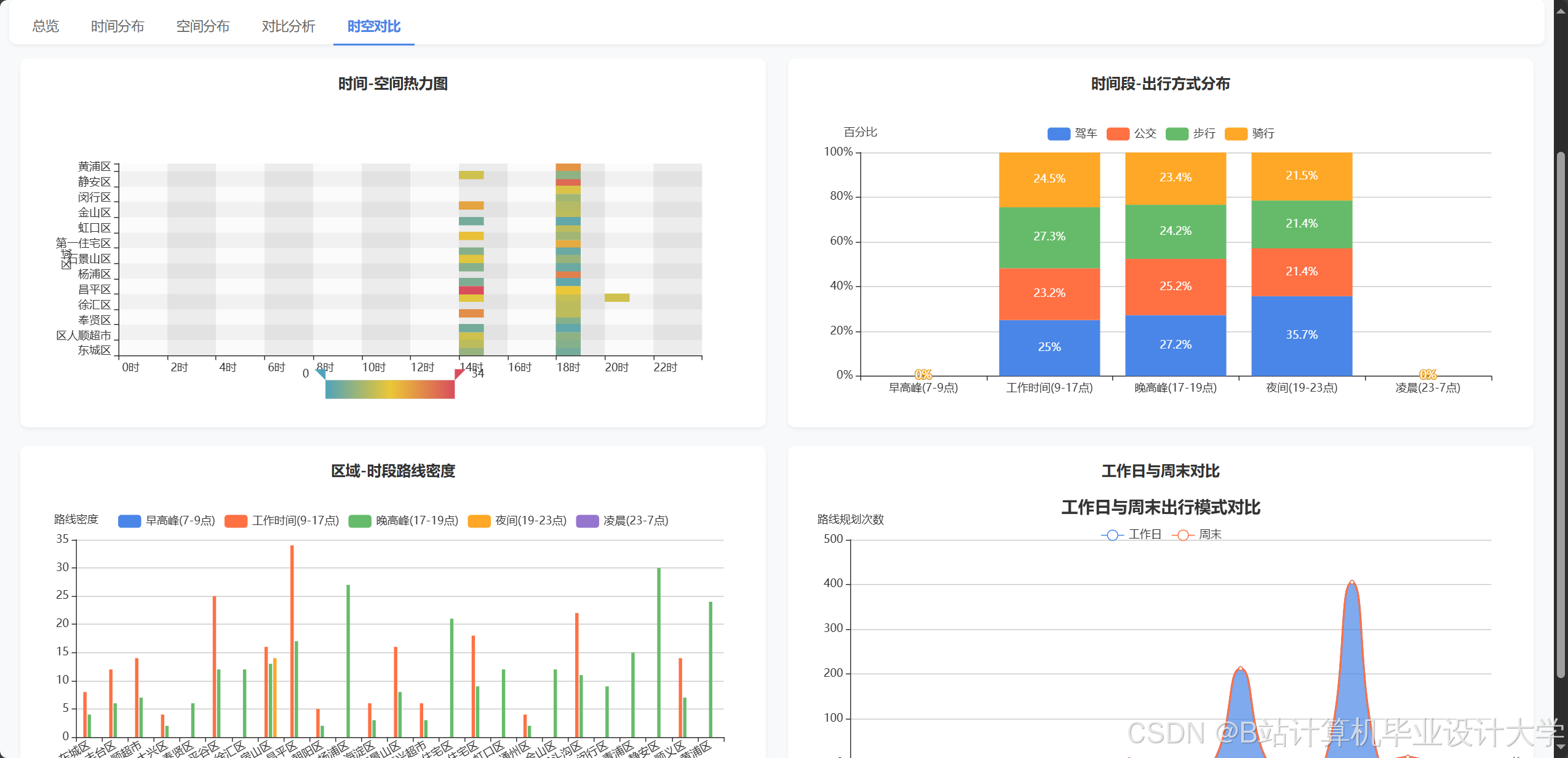
项目案例



优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓
© 版权声明
文章版权归作者所有,未经允许请勿转载。


