【AI基础学习系列】八、机器学习常见名词汇总
机器学习常见名词汇总
- 机器学习
- 深度学习
- 神经网络
- NPU
- CUDA
- Torch
- PyTorch
- FT(Fine-Tuning)
- SFT(Supervised Fine-Tuning)
- 超参数
- 超参数调优
-
- 激活函数(Activation Function)
-
- 线性变换:
- 模型参数
-
- 权重
- 偏置
- 损失函数(Loss Function)
- 优化器(优化算法)
- 优化器选择
- 优化算法
- 前向传播(Forward Propagation)
- 反向传播(Backpropagation)
- 梯度下降(Gradient Descent)
-
- 梯度消失(Vanishing Gradient)
- 梯度爆炸(Exploding Gradients)
- 强化学习RLHF
- 二次代价函数(Quadratic Penalty Function
- 泛化能力
- 神经元
- 机器学习
-
- 监督学习(Supervised Learning)
- 无监督学习(Unsupervised Learning)
- 区别
- 过拟合
- 模型量化
-
- Bitsandbytes
- HQQ
- 大模型训练整体流程
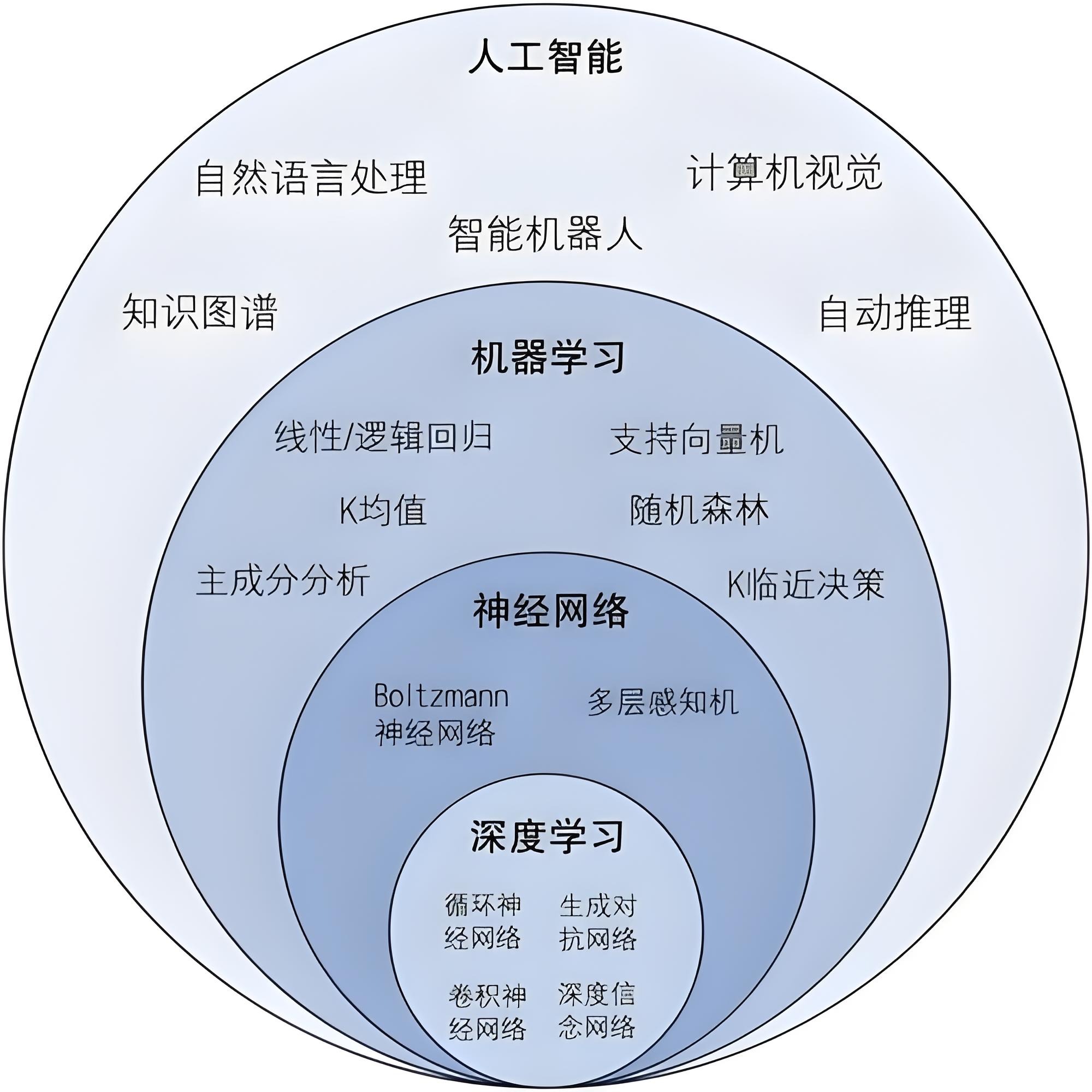
机器学习
机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习并提高性能,而无需进行明确的编程。机器学习算法使用统计技术来识别数据中的模式,然后使计算机能够做出预测或决策,无需人类直接指示。
主要特点:
- 数据驱动:机器学习模型的性能很大程度上依赖于提供给它的数据。
- 模式识别:机器学习算法能够识别数据中的模式,并用这些模式来预测新数据的结果。
- 自适应:随着时间的推移,机器学习模型可以通过积累更多的数据来改进其性能。
- 多种算法:包括监督学习、无监督学习、强化学习等多种算法。
应用领域:
- 语音识别
- 图像识别
- 推荐系统
- 自然语言处理
- 预测分析
深度学习
深度学习是**机器学习的一个子集,它基于人工神经网络**的概念,特别是深层神经网络。深度学习模型通过模仿人脑的工作方式来处理数据,通过多层(或“深度”)的神经网络来学习复杂的模式。
主要特点:
- 多层结构:深度学习模型包含多个隐藏层,这使得它们能够学习数据中的复杂和抽象的表示。
- 自动特征提取:深度学习模型能够自动从原始数据中提取特征,减少了手动特征工程的需求。
- 大数据需求:深度学习模型通常需要大量的数据来训练,以便它们能够学习到有效的模式。
- 计算密集型:深度学习模型需要大量的计算资源,尤其是GPU,来训练复杂的模型。
应用领域:
- 语音识别(如语音助手)
- 图像识别和分类(如面部识别)
- 自动驾驶汽车
- 自然语言理解(如机器翻译)
- 游戏和模拟(如AlphaGo)
神经网络
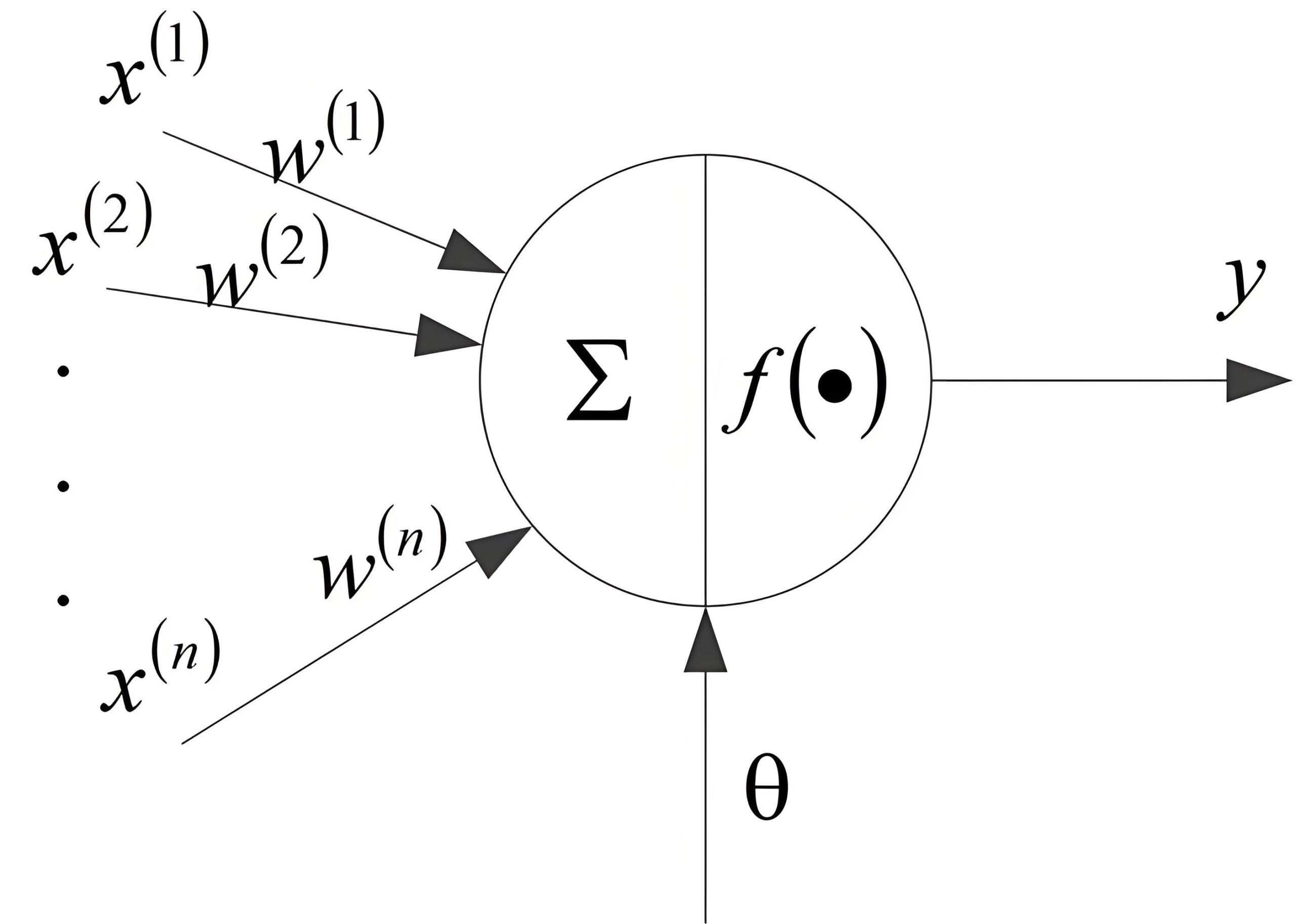
- y:通常是预测的输出或者目标变量。
- f():是一个函数,通常在神经网络中指的是激活函数(如ReLU、sigmoid、tanh等),它引入非线性,使得模型能够学习复杂的模式。
- W:是权重矩阵,包含了网络中的参数,这些参数在训练过程中会被优化。
-x:是输入数据矩阵,每一行代表一个样本,每一列代表一个特征。 - θ theta θ:是偏置项,也是一个参数,它允许模型在没有输入或者所有输入都是零的情况下也能产生非零的输出。
区别
- 复杂性:深度学习模型通常比传统机器学习模型更复杂,需要更多的数据和计算资源 。
- 特征工程:在传统机器学习中,特征工程是一个重要的步骤,而在深度学习中,模型可以自动学习特征。
- 应用范围:深度学习在处理大规模数据集和复杂问题时表现更好,而传统机器学习可能更适合数据量较小或问题较为简单的场景。
NPU
即神经处理单元(Neural Processing Unit),是专门为优化人工智能和神经网络任务性能而设计的**硬件** 。与传统的CPU和GPU相比,NPU在处理AI任务时表现出更高的效率和性能,尤其是在执行深度学习算法时。NPU的设计初衷是快速完成大量的小规模并行计算,这使得它们在处理图片、视频等多媒体数据以及神经网络数据时特别出色
CUDA
**CUDA(Compute Unified Device Architecture,统一计算架构)**是由NVIDIA公司开发的一种并行计算平台和编程模型。它允许软件开发者和软件工程师使用NVIDIA GPU(图形处理单元)进行通用计算任务,而不仅仅是传统的图形渲染。CUDA提供了一套丰富的API(应用程序编程接口),使得开发者能够利用GPU的强大计算能力来加速计算密集型的应用。
Torch
Torch是一个科学计算框架,最初使用Lua语言开发,专门用于机器学习和深度学习算法,特别是神经网络的构建和训练。它以其动态图、自动求导功能、张量操作和丰富的模型库而闻名。Torch的设计注重简洁和灵活性,允许开发者快速构建和测试新的模型和算法
PyTorch
PyTorch是Facebook的人工智能研究团队开发,并在2016年开源的深度学习框架,它是Torch的Python版本。PyTorch继承了Torch的设计理念和一些基本功能,但在实现上有所不同。PyTorch使用Python作为主要开发语言,并提供了更友好和灵活的API接口。PyTorch的一个显著特点是其动态计算图,允许在运行时根据需要定义、更改和调整计算图,这使得PyTorch在处理复杂的模型和任务时非常灵活和方便。与Torch相比,PyTorch提供了更丰富的文档和社区支持,以及与其他流行框架的接口,如TensorFlow和Keras。PyTorch还支持多种计算设备,包括CPU、GPU和TPU,用户可以轻松地将模型迁移到不同的硬件上运行,以获得更高的计算效率。
FT(Fine-Tuning)
- 通常指的是在预训练模型的基础上进行微调。这个过程涉及使用特定任务的数据来调整模型的权重,以便模型能够更好地执行该任务。
- FT可以用于各种任务,包括分类、回归、命名实体识别等。
- FT通常在模型的最后几层进行,而保留预训练的底层权重不变,因为底层权重已经在大量数据上学习到了通用特征。
SFT(Supervised Fine-Tuning)
监督微调是指在源数据集上预训练一个神经网络模型,即源模型。然后创建一个新的神经网络模型,即目标模型。目标模型复制了源模型上除了输出层外的所有模型设计及其参数。这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。源模型的输出层与源数据集的标签紧密相关,因此在目标模型中不予采用。微调时,为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。在目标数据集上训练目标模型时,将从头训练到输出层,其余层的参数都基于源模型的参数微调得到。
- 预训练阶段:首先在一个大型的源数据集上训练一个神经网络模型,这个模型我们称之为”源模型”。
- 模型复制:接着创建一个新的模型,即”目标模型”。这个目标模型复制了源模型除了输出层之外的所有层和参数。
- 输出层替换:因为源模型的输出层是针对源数据集的特定任务设计的,所以目标模型不使用源模型的输出层,而是添加一个新的输出层,这个新层的参数是随机初始化的。
- 微调训练:最后,目标模型在目标数据集上进行训练。在这个过程中,除了新添加的输出层是从头开始训练的,其他层的参数都是在源模型参数的基础上进行微调。
监督微调的步骤
具体来说,监督式微调包括以下几个步骤:
预训练
首先在一个大规模的数据集上训练一个深度学习模型,例如使用自监督学习或者无监督学习算法进行预训练;
微调
使用目标任务的训练集对预训练模型进行微调。通常,只有预训练模型中的一部分层被微调,例如只微调模型的最后几层或者某些中间层。在微调过程中,通过反向传播算法对模型进行优化,使得模型在目标任务上表现更好;
评估
使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标。
超参数
超参数是机器学习模型训练前需要设置的参数,它们通常控制着学习过程的某些方面,而不是模型本身的结构或行为。与模型参数不同,模型参数是通过训练数据学习得到的,而超参数则需要人为设定或通过交叉验证等技术进行调整。
学习率(Learning Rate):控制模型权重更新的幅度。如果学习率太高,可能导致训练过程中的震荡或发散(跳过最低损失函数值);如果太低,则可能导致训练过程缓慢或陷入局部最优。
批量大小(Batch Size):指定每次迭代中用于计算梯度的样本数量。小批量大小有助于提高模型的泛化能力,但可能增加训练时间。
迭代次数(Epochs):表示整个训练数据集通过模型的次数。过多的迭代可能导致过拟合,而太少则可能导致模型欠拟合。
优化器(Optimizer): 选择用于模型训练的优化算法,如梯度下降、随机梯度下降、Adam、RMSprop等。
正则化系数(Regularization Coefficient):控制模型正则化的强度,以防止过拟合,如L1、L2正则化。
网络结构参数:如神经网络中的层数、每层的神经元数量等。
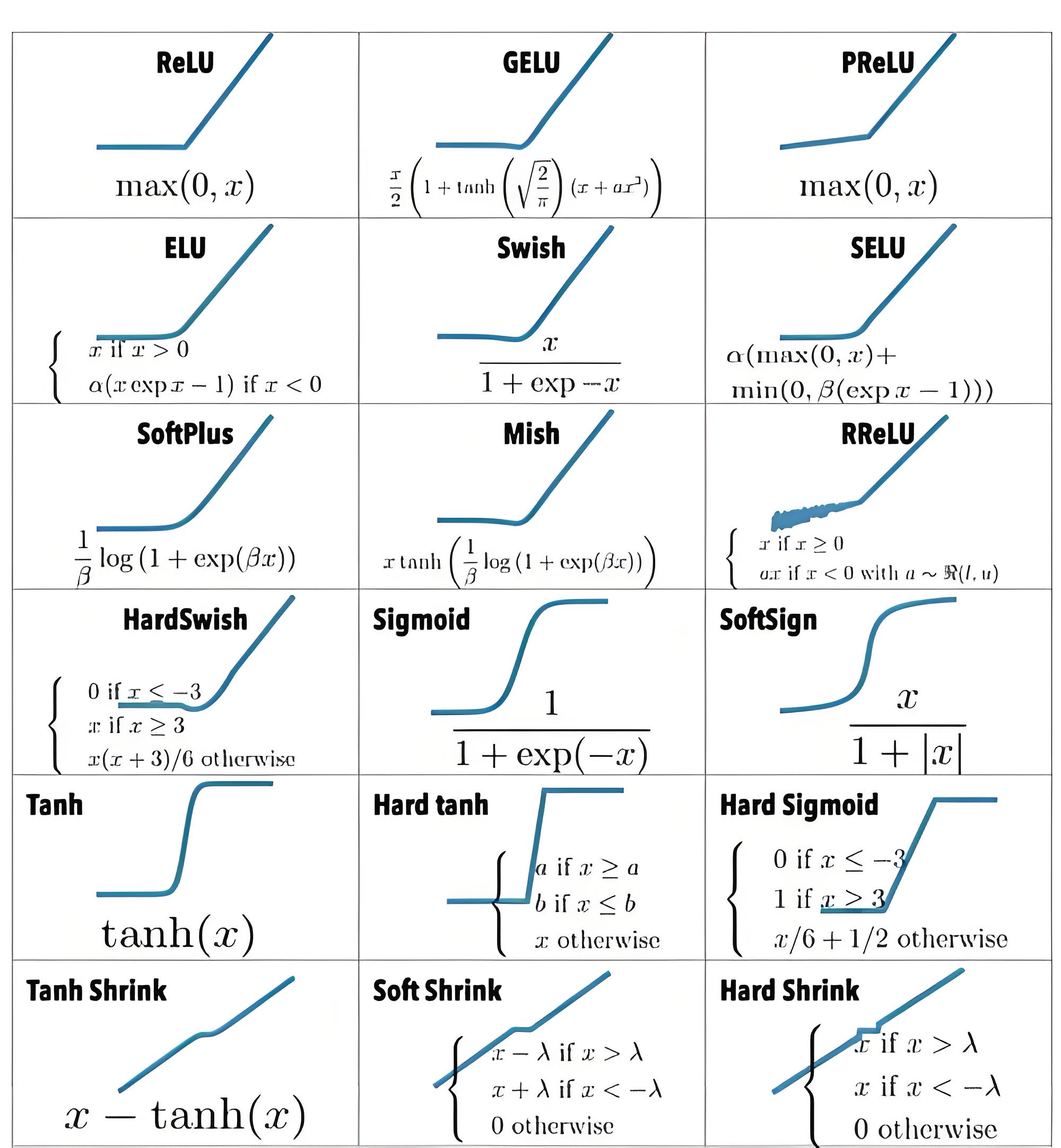
激活函数(Activation Function):选择模型中使用的非线性激活函数,如ReLU、Sigmoid、Tanh等。
dropout率:在训练过程中随机丢弃一些网络连接的比例,用于防止过拟合。
卷积核大小(Kernel Size):在卷积神经网络中,卷积核的尺寸会影响特征提取的范围。
池化窗口大小(Pooling Size):池化层中使用的窗口大小,影响特征图的下采样程度。
超参数调优
激活函数(Activation Function)
网络的每一层在输出时,都需要进行一次非线性变换,被称为激活。如果不进行激活,则网络中各层均进行线性变换。
线性变换:
- 线性变换可以看作是对空间进行拉伸、压缩、反射、旋转等操作,而不改变点的相对位置。
- 线性变换保持向量间的角度和比例不变,但不一定保持长度。
激活函数在神经网络中起着重要的作用,主要有以下几点:
1.完成数据的非线性变换:激活函数引入非线性元素,解决线性模型的表达、分类能力不足的问题。非线性是现实世界中许多现象的基础,因此这非常有用。
2.增加网络的能力:激活函数的存在,使得神经网络的”多层有了实际的意义,使网络更加强大,增加网络的能力,使它可可以学习复杂的事物,复杂的数据,以及表示输入输出之间非线性的复杂的任意函数映射。
3.执行数据的归一化:激活函数将输入数据映射到某个范围内,再往下传递,这样做的好处是可以限制数据的扩张,防止数据过大导致的溢出风险。
4.作为预测概率输出:某些激活函数,如sigmoid函数,其输出范围因为[0,1],适用于作为预测概率输出。
模型参数
权重
- 来源:权重是模型中的参数,它们在初始化时通常是随机设置的(例如,随机小数或零初始化)。权重的初始值不影响模型的学习能力,因为它们将在训练过程中被调整。
- 作用:权重决定了输入特征对模型输出的影响程度。不同的权重值可以增强或减弱某些输入特征对最终预测结果的贡献。在线性回归中,权重是斜率,表示特征与目标变量之间的线性关系强度。
偏置
- 来源:偏置(也称为偏差项或截距)同样是模型参数,在初始化时通常被设置为零或一个小的随机数。
- 作用:偏置允许模型的输出在没有输入的情况下不从零开始。它为模型提供了沿目标轴平移的能力,使得模型可以更好地拟合数据集中的模式。
在训练过程中,权重和偏置通过优化算法(如梯度下降)不断更
© 版权声明
文章版权归作者所有,未经允许请勿转载。