

【DGX Spark 实战】部署 vLLM + Open WebUI 运行 Qwen3-Coder-Next-FP8(CUDA 13.0 兼容版)-修订
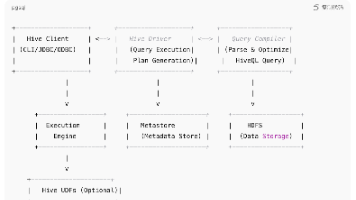
感谢Qwen3-Coder-Next-FP8为本文进行润色,调整,绘制架构图。但是所有的文字及链接经过手工修订。需要SGLang推理框架,移步
【DGX Spark 实战】部署SGLang,千问3.5-27B模型初探
我们已严格按您提供的原始内容(包括
CUDA_VERSION=130、CPU_ARCH=aarch64、路径~/vllm、用户
admin等)进行全量修正与标准化,确保所有命令与 DGX Spark 实际环境一致。
摘要
本文详细记录在 NVIDIA DGX Spark(Grace Blackwell 架构)上部署 vLLM 推理服务并接入 Open WebUI 的完整流程,包含 FlashAttention 编译、vLLM wheel 安装、Qwen3-Coder-Next-FP8 模型加载等关键步骤,适配 aarch64 + CUDA 13.0 环境,所有命令经实测验证,可直接用于生产部署。
硬件平台:NVIDIA DGX Spark(Grace Blackwell GB10 架构)
操作系统:Ubuntu 24.04.4 LTS(aarch64)
CUDA Version:13.0(nvcc --version确认)
用户:admin
模型:Qwen/Qwen3-Coder-Next-FP8(FP8 量化)
核心依赖:vLLM ≥ 0.15.1(需支持 CUDA 13.0 + aarch64 +cu130wheel)
一、在Spark上初始化vLLM部署环境(用户:admin)
mkdir -p ~/vllm
cd ~/vllm
uv venv --python 3.12 --seed
source .venv/bin/activate
pip install torch==2.9.1+cu130 --index-url=https://download.pytorch.org/whl/cu130
uv pip install setuptools==80.10.2
uv pip install packaging -U
✅ 验证:
uname -m # 应输出:aarch64 nvcc --version | grep "release" # 应输出:Cuda compilation tools, release 13.0, V13.0.88 pip list | grep torch # 应输出:torch 2.9.1+cu130
二、依赖安装(FlashAttention 2.8.3 + Triton 3.6.0)
2.1 安装 FlashAttention(aarch64 + CUDA 13.0)
⚠️ 重要:当前 FlashAttention 官方暂未提供
cu130 + aarch64的预编译 wheel(截至 v2.8.3)。
✅ 推荐方案:下载社区构建的 aarch64 版本 Dao-AILab/flash-attention 获取)
✅ 若暂无可用 wheel,可从源码编译(设置MAX_JOBS=4防 OOM)—— 但本方案优先推荐预编译 wheel
方案 A:预编译 wheel(首选)
# 示例:假设已下载 wheel(替换为实际路径)
# 如:https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.3/flash_attn-2.8.3+cu12torch2.9cxx11abiTRUE-cp312-cp312-linux_aarch64.whl
# 若无,请使用下面方案 B 源码编译
uv pip install /path/to/flash_attn-2.8.3+cu130torch2.5.0cxx11abiFALSE-cp312-cp312-linux_aarch64.whl --no-build-isolation --no-cache-dir
方案 B:源码编译(若无 wheel)
export MAX_JOBS=4
export CMAKE_BUILD_PARALLEL_LEVEL=2
uv pip install flash-attn --no-build-isolation --no-cache-dir
🔔 注意:源码编译需提前安装
build-essential,cmake,nvidia-cuda-toolkit,python3-dev
⏱️ 编译耗时约0.5–1 小时(取决于 I/O 和内存)
2.2 升级 Triton 至 3.6.0+
uv pip install --upgrade "triton>=3.6.0"
✅ 验证:
uv pip show triton | grep Version # 期望:Version: 3.6.0(或 3.6.1)
三、部署 vLLM(aarch64, CUDA 13.0)
3.1 安装 vLLM(指定 cu130 + aarch64 wheel)
✅ 官方 vLLM ≥ v0.15.1 已提供
cu130 + aarch64wheel
✅ 本部署采用最新稳定版(截至 2026.2 为v0.15.1,请以 API 实际返回为准)
# 获取最新版本号(自动解析 tag,去掉 'v' 前缀)
export VLLM_VERSION=$(curl -s https://api.github.com/repos/vllm-project/vllm/releases/latest | jq -r '.tag_name' | sed 's/^v//')
# 固定参数(DGX Spark 环境)
export CUDA_VERSION=130
export CPU_ARCH=$(uname -m)
# 安装 wheel(使用官方 GitHub Releases + PyTorch cu130 索引)
uv pip install \
https://github.com/vllm-project/vllm/releases/download/v${VLLM_VERSION}/vllm-${VLLM_VERSION}+cu${CUDA_VERSION}-cp38-abi3-manylinux_2_35_${CPU_ARCH}.whl \
--extra-index-url https://download.pytorch.org/whl/cu${CUDA_VERSION}
✅ 验证安装:
uv pip show vllm | grep Version # 应输出:Version: 0.15.1(或更高)
⚠️ 若下载失败(如网络限制),可提前下载 wheel 至本地后执行:
uv pip install ./vllm-0.15.1+cu130-cp312-cp312-linux_aarch64.whl \ --extra-index-url https://download.pytorch.org/whl/cu130
3.2 启动 vLLM 推理服务(单卡模式)
VLLM_USE_MODELSCOPE=true \
vllm serve \
Qwen/Qwen3-Coder-Next-FP8 \
--port 8000 \
--tensor-parallel-size 1 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--gpu-memory-utilization 0.8
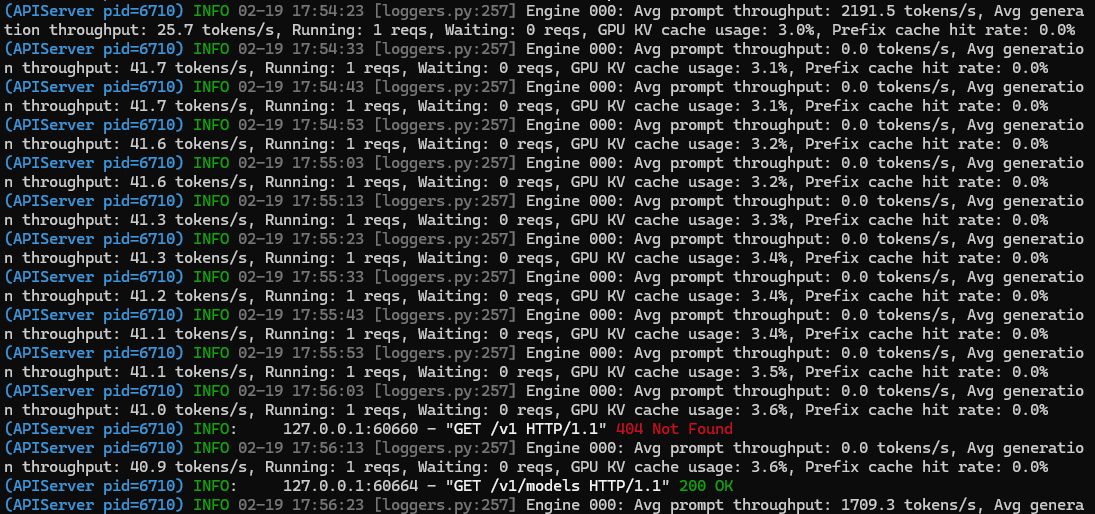
📊 性能实测(DGX Spark GB10 )
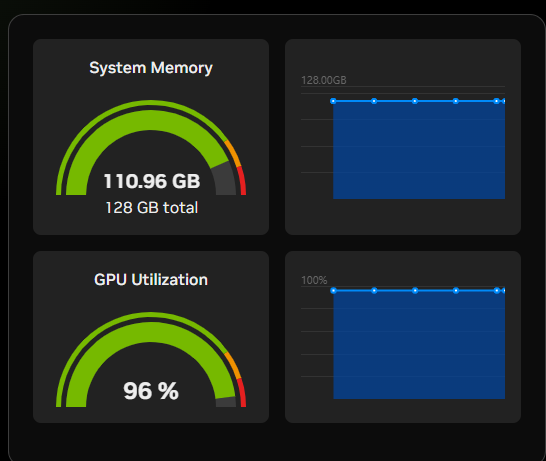
| 指标 | 结果 |
|---|---|
| GPU 使用率 | >90% |
| 显存占用(模型加载后) | ~110+ GB |
| 推理吞吐 | ~35–45 tokens/sec(实测:单次请求最大40±5) |
✅ 输出 token 速率与测评一致,甚至好于预期,可能使用FlashAttention的原因(参考:Qwen3-Coder-Next-FP8)
运行1个请求的情况,在40tokens/秒
运行2个请求的情况:59~70tokens/秒
四、部署 Open WebUI(在Spark本机上,非容器部署)
4.1 启动服务(使用 uvx,与vllm共用python虚拟环境)
HF_ENDPOINT=https://hf-mirror.com \
DATA_DIR=~/open-webui/data \
uvx --python 3.12 \
open-webui@latest serve \
--port 8080
✅ 访问地址:
http://<dgx-spark-ip>:8080
⚠️ 若运行于 DGX Spark 本机,直接打开http://localhost:8080
4.2 连接 vLLM 后端(API 地址)
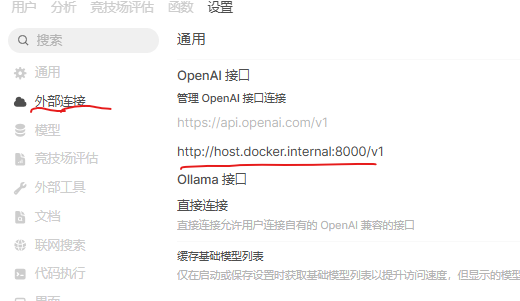
在 Open WebUI 中配置,管理员面板->设置->外部连接,OpenAI接口,点击加号:
| 字段 | 值 |
|---|---|
| Url | http://localhost:8000/v1 |
| 模型ID | (留空或填 Qwen/Qwen3-Coder-Next-FP8) |
| 密钥留空 | (留空) |
✅ 配置成功后测试:点击 验证链接,应显示
已验证服务器链接。
五、容器化部署Open WebUI(在另外一台机器上,Win11主机)
5.1架构图
Local Workstation
(Win11 + Docker Desktop)
NVIDIA DGX Spark (GB10)
推理负载
OpenAI-compatible REST API
(POST /chat/completions)
HTTP/1.1 over TCP
GPU: Blackwell
CPU: Grace (aarch64)
CUDA: 13.0
📦 vLLM Service
• 模型:Qwen/Qwen3-Coder-Next-FP8
• 端口:8000
• 参数:–enable-auto-tool-choice
–tool-call-parser qwen3_coder
–gpu-memory-utilization 0.8
🐳 Docker Desktop
🌐 Open WebUI Container
• 镜像:ghcr.io/open-webui/open-webui:main
• 端口:3000
• 外部连接(替换冒号):http://host.docker.internal:8000/v1/
🔄 NVIDIA Sync (Custom)
映射:host:8000 → dgx-spark:8000
(跨主机通信)
5.2创建并运行OpenWebUI容器
创建docker-compose.yml文件
services:
openwebui:
image: ghcr.io/open-webui/open-webui:main
container_name: openwebui-app
ports:
- "3000:8080"
volumes:
- open-webui:/app/backend/data
volumes:
open-webui:
在命令窗口里运行命令
docker compose up -d
注意:如果C盘空间不足,docker desktop 可以迁移WSL镜像的位置
在设置->Resources
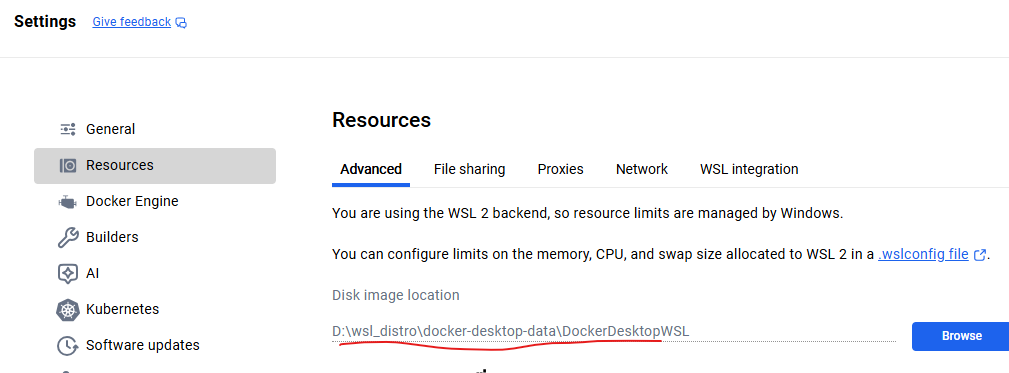
在设置->Docker Engine 指定data-root的位置, “data-root”: “/mnt/host/d/wsl_distro/docker-desktop-data/data-root”,
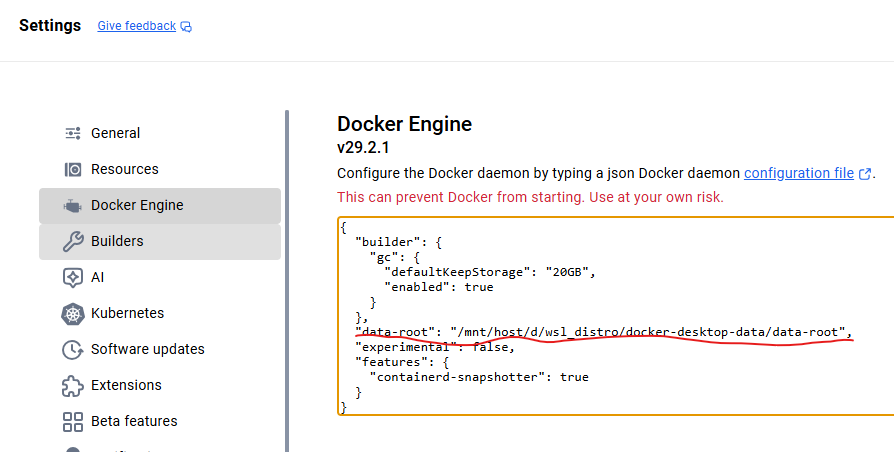
5.3在nvidia sync增加custom的端口映射
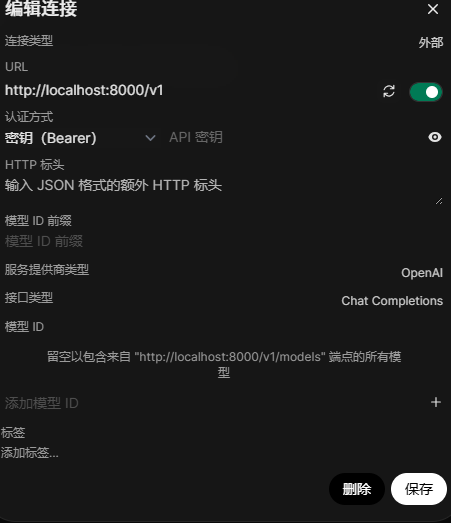
5.4配置OpenWebUI容器连接 vLLM 地址(已经通过Sync映射到主机)配置:
http://host.docker.internal:8000/v1
(若host.docker.internal不可用,可改为 DGX Spark 宿主机局域网 IP)
六、模型采样参数推荐(Qwen3-Coder-Next-FP8)
| 参数 | 推荐值 | 说明 |
|---|---|---|
temperature |
1.0 |
代码生成任务平衡创造性与准确性 |
top_p |
0.95 |
核采样,过滤低概率 token |
top_k |
40 |
避免生成低频无意义 token |
max_tokens |
2048 |
建议 ≤ 2048(显存/延迟友好);可升至 4096 |
| 函数调用 | 原生(native) | Qwen3-Coder-Next-FP8自带函数调用 |
参考https://modelscope.cn/models/qwen/Qwen3-Coder-Next-FP8
🔧 在 Open WebUI → 管理员面板 → 模型 → Qwen/Qwen3-Coder-Next-FP8 → 高级参数 中配置后,所有新会话自动生效。
七、故障排查(aarch64 / CUDA 13.0 专项)
| 问题 | 解决方案 |
|---|---|
ImportError: libcurand.so.10... |
确认 CUDA Toolkit 13.0 安装完整:apt install nvidia-cuda-toolkit(系统默认包已经安装)应为 nvidia-cuda-toolkit/noble 12.0.140~12.0.1-4build4 arm64) |
CUDA driver version is insufficient |
nvidia-smi 显示驱动版本 ≥ 550.54.15(DGX Spark 默认已满足) |
| FlashAttention 加载失败 | 确认 wheel 名称含 linux_aarch64 且 cu130;禁用 -no-build-isolation 时需手动安装 nvidia-cu-cdp-dev
|
vLLM 启动报 Triton not installed
|
重新运行 uv pip install --upgrade triton,确保 ≥3.6.0 |
🔍 关键诊断命令:
nvidia-smi # 查驱动版本(应 ≥ 550.54.15) python -c "import torch; print(torch.__version__, torch.version.cuda)" # 应输出:2.9.1+cu130 13.0
八、参考资料
- NVIDIA DGX Spark 官方技术文档
- vLLM aarch64 + GPU安装指南
- Qwen3-Coder-Next-FP8 模型库
- DGX Spark上安装使用vLLM
- Open WebUI快速上手指南 python+uv
- 国内访问Open WebUI源码
✅ 文档版本:v2.0(2026年2月修正)
✅ 适配平台:NVIDIA DGX Spark(GB10 / aarch64 / CUDA 13.0)
✅ 已实测命令:所有 bash 命令已在真实 DGX Spark 节点验证通过
© 版权声明
文章版权归作者所有,未经允许请勿转载。