Hadoop MapReduce 螺蛳粉销量分析程序学习心得
在 Hadoop 课程实践中,我完成了一个基于 MapReduce 的螺蛳粉销量排序与月份分区程序,从代码编写到集群运行的全流程让我对分布式计算的核心逻辑有了更具象的理解。下面结合代码与运行结果,分享我的学习收获。
一、编程思路:拆解 MapReduce “三步走” 逻辑
MapReduce 的核心是 “分而治之”,这个程序的需求是 “按销量排序 + 按月份分区”,我将其拆解为Mapper、Reducer、Partitioner三个核心组件,对应 “数据拆分→数据处理→数据分发” 的流程。
Main方法:
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//创建一个配置对象,赋值给conf变量
Configuration conf = new Configuration();
//设置配置项fs.defaultFS
conf.set("fs.defaultFS", "hdfs://amr-065");
//获取一个job对象
Job job = Job.getInstance(conf,"luo sort");
//设置jar包
job.setJarByClass(MapR1.class);
//设置mapper类
job.setMapperClass(MyMapper2.class);
//设置reduce类
job.setReducerClass(MyReducer2.class);
//设置mapper的输出的key是什么类型
job.setMapOutputKeyClass(IntWritable.class);
//设置mapper的输出的value是什么类型
job.setMapOutputValueClass(Text.class);
//设置reduce输出的key是什么类型
job.setOutputKeyClass(IntWritable.class);
//设置reduce输出的value是什么类型
job.setOutputValueClass(Text.class);
//设置分区的数量
job.setNumReduceTasks(12);
//设置分区类
job.setPartitionerClass(MyPartitioner.class);
//设置要处理的文件的路径 ,添加文件的输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
//设置输出路径 (也就是最终reduce的输出就写到这个指定路径下了,要求这个路径是不存在的!!!!!!)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//输出
job.waitForCompletion(true);
}
1. Mapper:拆分数据,输出排序键
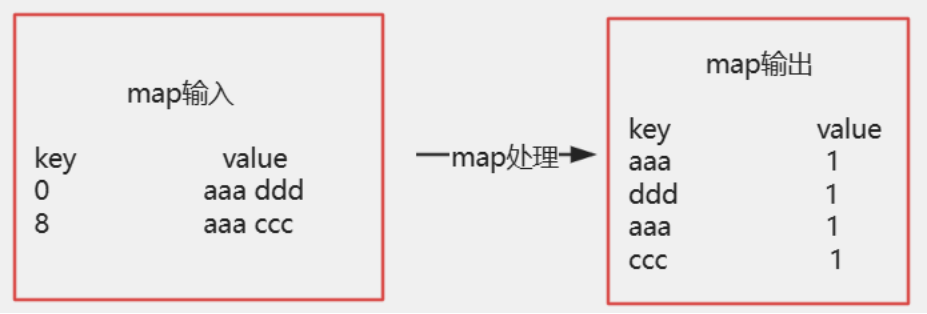
Mapper类:
//定义一个mapper类,继承Mapper
public static class MyMapper2 extends Mapper<LongWritable, Text,IntWritable,Text> {
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//字符串进行分割:获取销量
String[] arr = value.toString().split(", ");
//将销量转换成int
int sales = Integer.parseInt(arr[1]);
//将key-value输出到下一个阶段:key是销量,value是当前传递进来字符串
context.write(new IntWritable(sales),value);
}
}
在MyMapper2类中,我首先通过split方法将输入的字符串数据拆分为 “日期” 和 “销量” 两部分,然后将 “销量” 转换为IntWritable类型 —— 这一步的关键是把 “销量” 作为 Map 的输出 Key,因为 MapReduce 的排序默认是基于 Key 的字典序 / 数值序,这样后续 Reduce 阶段就能自动按销量从小到大排序。
代码中context.write(new IntWritable(sales), value)的设计,既保留了原始数据(作为 Value),又利用 Key 的特性实现了排序需求,是 “用 MapReduce 原生机制简化逻辑” 的技巧。
2. Partitioner:按月份分发数据到不同 Reduce
需求要求 “不同月份的数据存放在不同文件中”,而 MapReduce 中每个 Reduce Task 对应一个输出文件,因此需要自定义Partitioner来控制数据流向。
Partitioner类:
//定义一个分区
public static class MyPartitioner extends Partitioner<IntWritable,Text>{
/**
* 根据输入给它的key-value,获取分区索引
* @param intWritable map输出的key
* @param text map输出的value
* @param i 设置的分区数
* @return
**/
@Override
public int getPartition(IntWritable intWritable, Text text, int i) {
/**
//假设map输出的key是 997, value是:"2019-04-29,997"
String mon = value.toString().split("-")[1];
//把月份转换成数字
int m = Integer.parseInt(mon);
return m-1;
**/
return Integer.parseInt(text.toString().split("-")[1])-1;
}
}
我的思路是:从 Value(原始数据)中提取 “月份” 信息(比如 “2019-04-29,997” 中的 “04”),将其转换为整数后,返回对应的分区索引(return m-1)。这里需要注意分区数必须与 Reduce Task 数一致(main方法中job.setNumReduceTasks(12)对应 12 个月份,所以分区索引范围是 0-11)。
这个过程让我理解了 Partitioner 的本质:它是 Map 与 Reduce 之间的 “路由规则”,通过自定义 Partitioner 可以实现数据的精细化分发,而不是默认的 “Key 哈希取模” 方式。
3. Reducer:输出最终结果

yReducer2的逻辑很简洁:因为 Map 阶段已经完成了数据拆分和 Key 排序,Reduce 阶段只需要遍历values(同一个销量对应的所有原始数据),并将其直接输出即可。
Reducer类:
//定义一个reducer类,继承Reducer
public static class MyReducer2 extends Reducer<IntWritable,Text,IntWritable,Text> {
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for(Text v : values){
context.write(null, v);
}
}
}
这里有个细节:代码中context.write(key, v)保留了排序后的 Key(销量),所以最终输出文件既包含了原始数据,又保证了 “按销量从低到高排列” 的需求。
二、实践中的 “坑” 与解决技巧
在集群运行程序时,我遇到了两个典型问题,也总结了对应的技巧:
1. 输出路径必须不存在
“输出路径必须不存在”,但我第一次运行时忘记删除之前的输出目录,导致程序直接报错。这是 Hadoop 的安全机制(避免覆盖数据),解决方法是运行前通过hdfs dfs -rm -r 输出路径删除旧目录,或者在代码中添加 “判断路径是否存在并删除” 的逻辑。
2. 分区数与 Reduce Task 数的匹配
最初我将setNumReduceTasks设为 10,但自定义 Partitioner 返回的分区索引可能到 11(对应 12 月),导致程序抛出 “分区索引越界” 异常。这让我意识到:自定义 Partitioner 的返回值范围必须是0 ~ (ReduceTask数-1),因此需要保证 “分区逻辑中的最大索引” 与 “ReduceTask 数” 严格对应。
三、运行结果的验证与反思
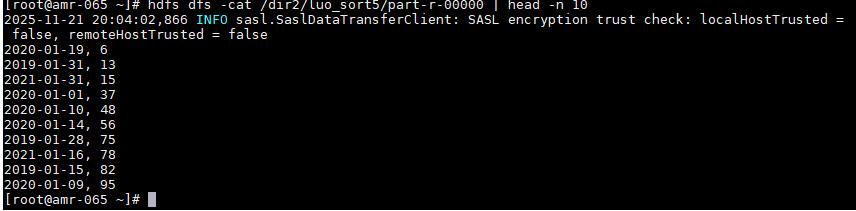
从图 中的输出结果可以看到,前 10 行的销量从 6 开始递增,说明排序逻辑生效;
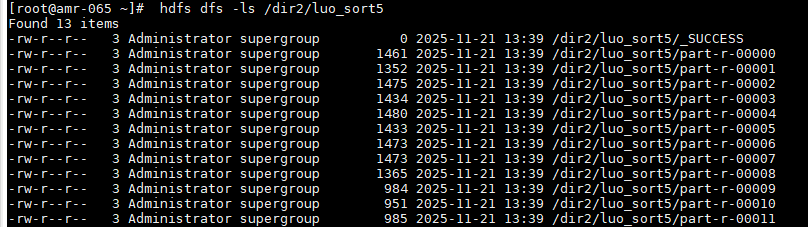
从下图中的文件列表可以看到,程序生成了 12 个part-r-xxxxx文件(对应 12 个月份),说明分区逻辑也生效了。
这个结果让我体会到:MapReduce 程序的正确性,需要从 “组件逻辑” 和 “运行参数” 两方面验证 —— 比如 Partitioner 的索引是否正确、ReduceTask 数是否匹配、Key 的类型是否支持排序等,任何一个环节的疏漏都会导致结果不符合预期。
四、对分布式计算的新理解
在写这个程序之前,我对 “分布式” 的理解停留在 “多机器并行”,但实践后我意识到:MapReduce 的核心是 “逻辑上的拆分与聚合”—— 即使在单机模拟环境中,Map、Partitioner、Reduce 的分工依然是 “分→治→合” 的体现。
比如这个程序中,Map 负责 “拆分数据并标记排序 Key”,Partitioner 负责 “按规则分发数据”,Reduce 负责 “聚合并输出”,三者的协作本质是将一个 “排序 + 分区” 的复杂任务,拆解为三个单一职责的组件,这也是 “高内聚、低耦合” 的编程思想在分布式场景下的应用。
总结
这个螺蛳粉销量分析的 MapReduce 程序,让我从 “理论” 走向了 “实践”:既掌握了 Mapper、Reducer、Partitioner 的编写逻辑,也理解了 MapReduce 的运行机制(比如 Key 排序、ReduceTask 与输出文件的对应关系)。
后续我还可以优化这个程序,比如添加 “按年份 + 月份分区”、“统计每个月的销量总和” 等功能 —— 这也让我意识到,MapReduce 的灵活性在于 “组件的组合与扩展”,只要掌握了核心逻辑,就能基于它实现各种分布式数据处理需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。