Kafka 深度详解
一、Kafka 核心架构
1.1 Kafka 基础定位
- Kafka 是一款分布式流处理平台,基于发布-订阅模式实现高性能的消息存储与流转,由 LinkedIn 开发,采用 Scala/Java 语言编写
- 核心设计理念:以日志为核心的存储模型,通过分区并行、批量读写、顺序 IO、零拷贝等机制,实现超高吞吐量与低延迟
- 核心优势:高吞吐、高可用、可扩展、持久化存储,支持海量消息的实时处理与离线分析,是大数据生态的核心组件,广泛用于日志收集、流式计算、数据同步等场景
1.2 整体核心架构(核心角色)
Kafka 的架构围绕「分布式、高并发、高可用」设计,所有角色各司其职,形成完整的消息流转闭环:
-
Producer(生产者)
- 消息的发送方,负责将业务数据封装为消息,发送到 Kafka 的指定 Topic
- 核心特性:支持批量发送、异步发送、分区策略选择,可配置幂等性和事务,保障消息发送的可靠性
-
Consumer(消费者)
- 消息的接收方,通过订阅 Topic 消费消息,支持分组消费和独立消费
- 核心特性:采用拉模式(Pull) 消费消息,自主控制消费速度;通过 Offset 记录消费位置,支持断点续传
-
Consumer Group(消费者组)
- 多个消费者组成的逻辑分组,是 Kafka 实现负载均衡的核心机制
- 核心规则:一个分区只能被同一个消费者组内的一个消费者消费,组内消费者并行消费不同分区,组间消费者可重复消费同一 Topic
-
Broker(服务节点)
- Kafka 集群的核心服务实例,一个 Kafka 集群由多个 Broker 组成
- 核心职责:存储消息、处理生产者的写入请求、处理消费者的读取请求;每个 Broker 有唯一 ID(
broker.id)
-
Controller(控制器节点)
- 集群中选举出的主 Broker 节点,负责管理集群的元数据(Topic 分区信息、副本状态)、选举分区的领导者副本、处理 Broker 节点的上下线
- 核心特性:控制器故障后,集群会自动重新选举新控制器,无单点故障风险
1.3 集群核心架构模式
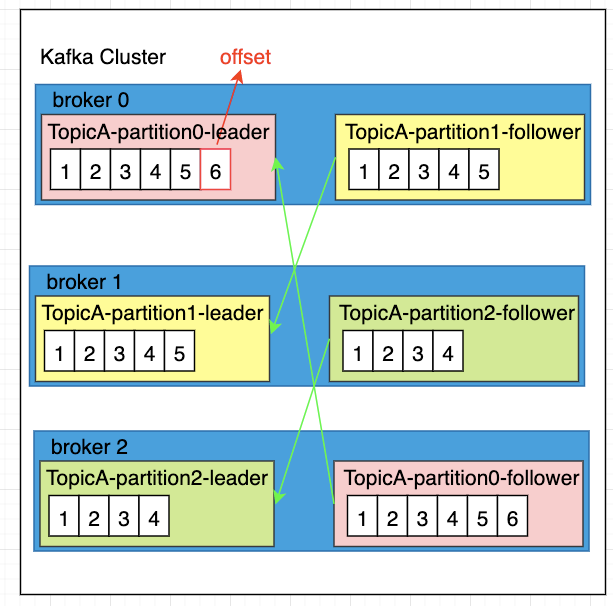
一台Kafka服务器就是一个Broker,多个broker组合在一起就构成了一个kafka Cluster,Kafka 的高可用与高性能,完全依赖于分区+副本的分布式架构设计,无额外集群模式,所有集群均基于此架构:
- 分区(Partition):Topic 的物理拆分单元,一个 Topic 可分为多个 Partition,分布在不同 Broker 上,实现并行读写
-
副本(Replica):每个 Partition 有多个副本,分为领导者副本(Leader) 和追随者副本(Follower)
- Leader 副本:处理所有读写请求,是 Partition 的主副本
- Follower 副本:同步 Leader 副本的消息,不处理读写请求;Leader 故障后,Follower 会被选举为新 Leader
- 核心优势:分区实现并行处理,副本实现高可用,二者结合保障集群的高性能与高可靠性
1.4 Kafka 生产者设计
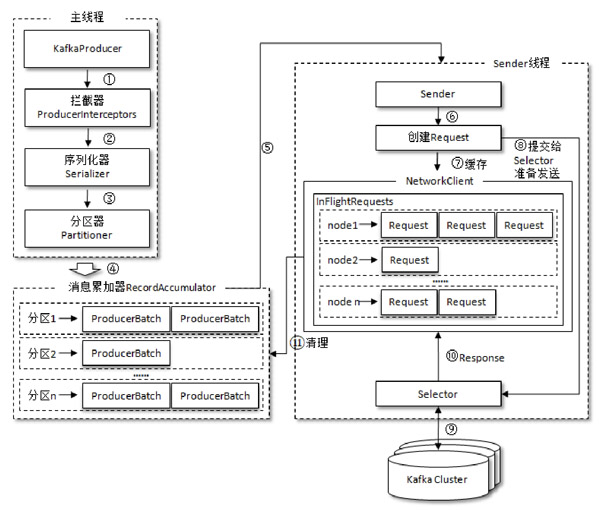
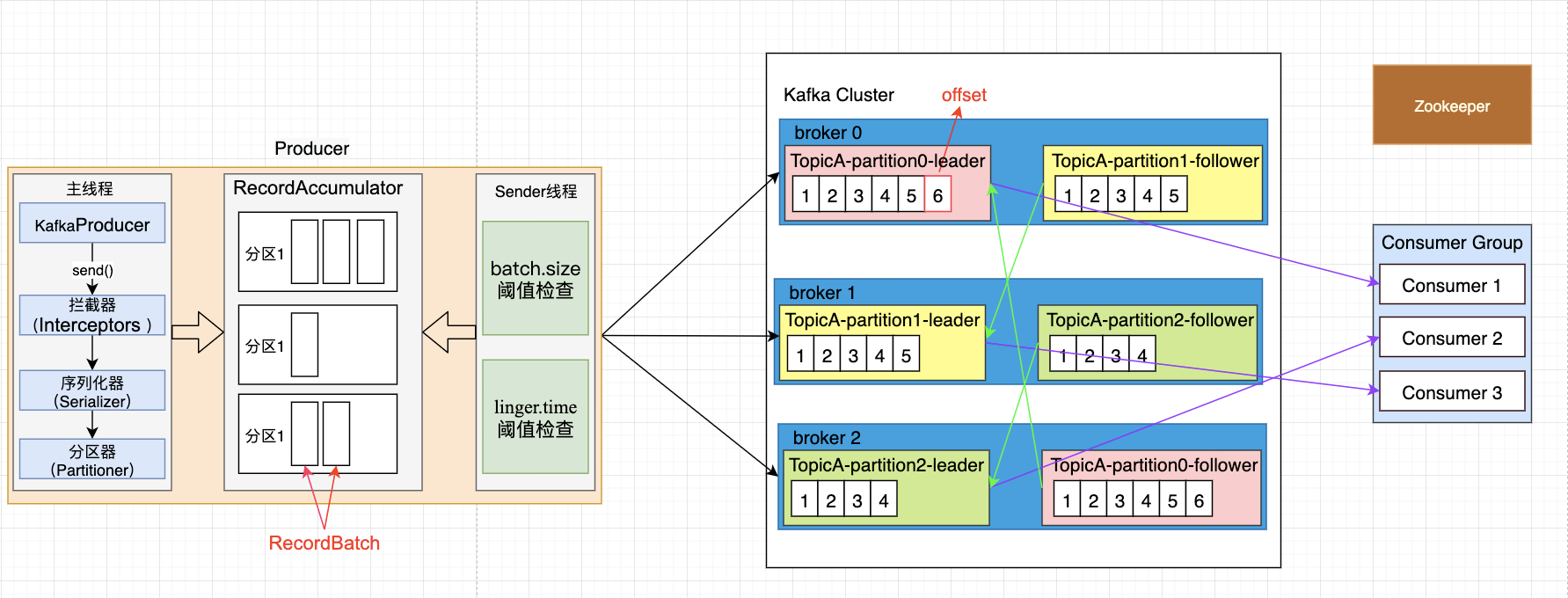
Kafka 的 Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了 两个线程即主线程和 Sender 线程,以及一个缓冲区RecordAccumulator。
-
RecordAccumulator:消息发送的内存缓冲区域,当该区域满了一后,生产者要么被阻塞,要么会抛出异常;RecordAccumulator 内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即 Deque<ProducerBatch>。消息写入缓存时,追加到双端队列的尾部;Sender读取消息时,从双端队列的头部读取。 -
main 线程:将消息发送给 RecordAccumulator,发送过程中消息会经历拦截器,序列化,分区器; -
Sender 线程:不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。 -
batch.size:只有数据积累到batch.size之后,sender 才会发送数据,默认16kb。 -
linger.ms:如果数据迟迟未达到batch.sizesender 等待linger.time之后就会发送数据。 -
buffer.memory:RecordAccumulator 缓冲区大小 默认32M。
这样设计带来的好处就是可以提升生产者的吞吐量:
- 主线程直接将消息发送到缓冲区,这样主线程的发送会执行得非常的快。
- Sender线程可以从缓冲区里面批量获并发送取数据到kafka broker,这样可以减少网络开销。
二、Kafka 核心概念
2.1 核心数据模型组件
Kafka 的所有消息流转与存储,均基于以下核心概念,是理解 Kafka 的关键:
-
Topic(主题)- 消息的逻辑分类容器,用于区分不同类型的消息,生产者发送消息到指定 Topic,消费者订阅 Topic 消费消息
- 核心特性:Topic 是逻辑概念,物理存储由 Partition 完成;支持动态创建和删除,可配置分区数、副本数等属性
-
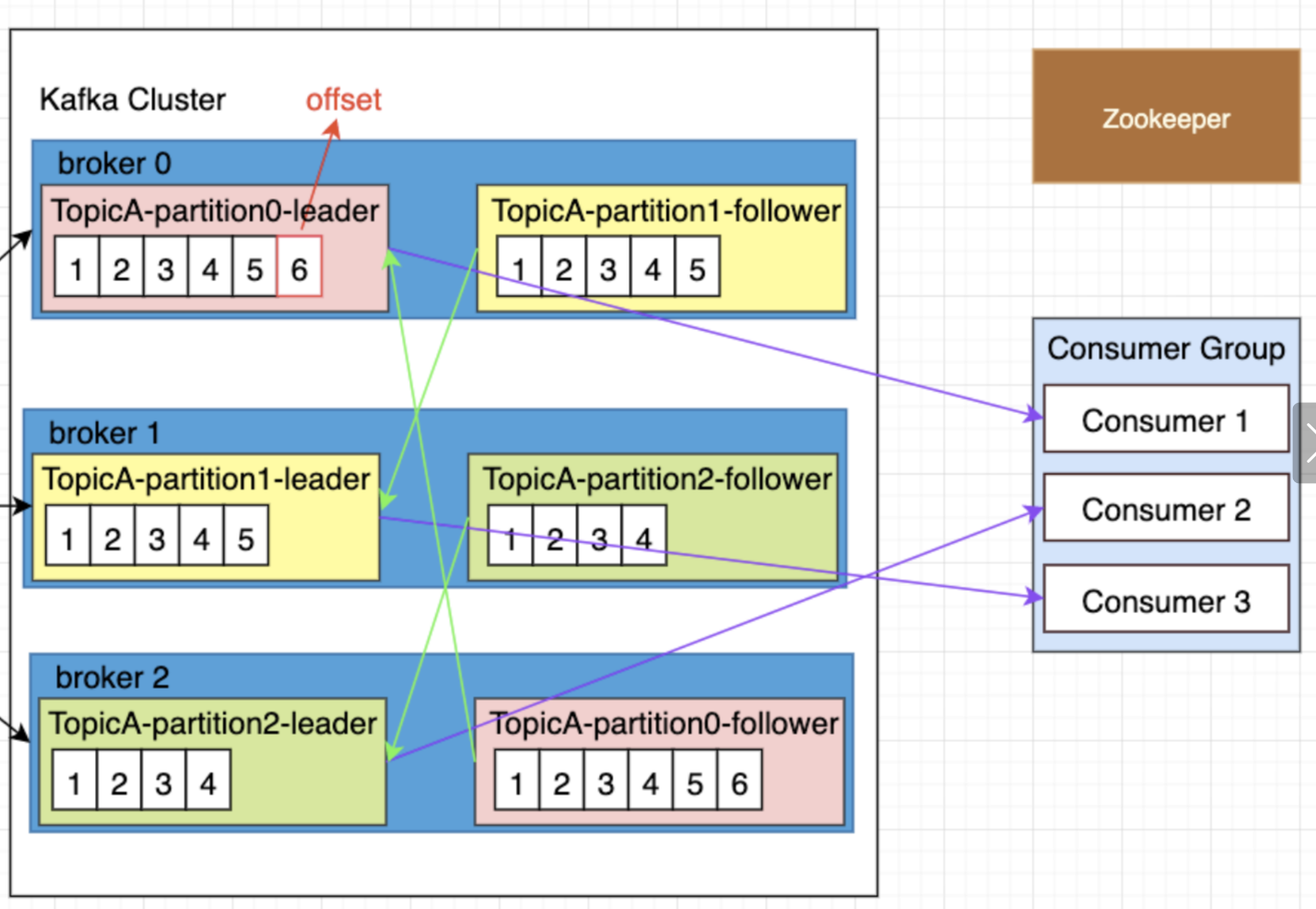
Partition(分区)- Topic 的物理存储单元,是 Kafka 实现并行处理的核心
- 核心特性:
- 每个 Partition 是一个有序的、不可变的消息日志,消息按写入顺序追加到日志末尾
- 消息在 Partition 内有唯一的偏移量(Offset),Offset 是一个自增的整数,用于标识消息的位置
- 分区数越多,并行度越高,吞吐量越大;但分区数不可随意减少(只能增加)
-
Offset(偏移量)- 消息在 Partition 内的唯一标识,相当于消息的「地址」
- 核心分类:
- 生产者 Offset:生产者发送消息时,消息被分配的 Offset(由 Leader 副本分配)
- 消费者 Offset:消费者消费到的最后一条消息的 Offset,记录了消费者的消费位置;消费者通过提交 Offset 实现断点续传
-
Replica(副本)- Partition 的冗余备份,用于保障数据不丢失和服务高可用
- 核心分类:
- 领导者副本(Leader):处理该 Partition 的所有读写请求,是 Partition 的主副本
- 追随者副本(Follower):被动同步 Leader 的消息日志,与 Leader 保持数据一致;Leader 故障时,Follower 参与选举成为新 Leader
- ISR 集合(In-Sync Replicas):与 Leader 保持同步的副本集合(包含 Leader 本身);只有 ISR 内的副本才有资格被选举为新 Leader
-
Segment(日志分段)- Partition 的物理存储分段,每个 Partition 的日志会被拆分为多个 Segment 文件(默认 1GB),分为索引文件(
.index) 和数据文件(.log) - 核心特性:分段存储便于日志的清理和维护(如删除过期日志),索引文件用于快速定位消息的物理位置,提升读取性能
- Partition 的物理存储分段,每个 Partition 的日志会被拆分为多个 Segment 文件(默认 1GB),分为索引文件(
2.2 核心消费模型概念
-
Consumer Group(消费者组)- 多个消费者的逻辑分组,组内消费者共同消费一个 Topic 的所有 Partition,实现负载均衡
- 核心规则:
- 一个 Partition 只能被同一个消费者组内的一个消费者消费,避免重复消费
- 消费者组内的消费者数量建议不超过 Topic 的 Partition 数量,否则多余的消费者会处于空闲状态
- 消费者组有唯一标识(
group.id),不同消费者组的消费 Offset 相互独立
-
Offset Commit(偏移量提交)- 消费者将自己的消费位置(Offset)提交到 Kafka 的消费者组协调器(Group Coordinator),用于记录消费进度
- 提交方式:
-
自动提交:消费者定期自动提交 Offset(默认 5 秒),配置
enable.auto.commit=true;优点是简单,缺点是可能出现重复消费 -
手动提交:消费者处理完消息后,手动调用 API 提交 Offset,配置
enable.auto.commit=false;生产核心业务必须使用手动提交,保障消费准确性
-
自动提交:消费者定期自动提交 Offset(默认 5 秒),配置
-
Rebalance(重平衡)- 消费者组内的消费者数量变化(新增/下线)或 Topic 的 Partition 数量变化时,触发的分区重新分配过程
- 核心过程:暂停所有消费者的消费 → 重新分配 Partition 给消费者 → 恢复消费
- 注意事项:重平衡会导致消费短暂停顿,生产中需尽量减少重平衡次数(如避免消费者频繁上下线)
三、Kafka 核心工作机制(核心原理)
3.1 消息生产→存储 完整流程(生产者侧)
这是 Kafka 高吞吐的核心流程,所有优化均围绕此流程展开:
- 生产者配置 Broker 地址列表,与其中一个 Broker 建立 TCP 连接,获取 Topic 的元数据(Partition 分布、Leader 副本位置)
- 生产者根据分区策略,将消息分配到指定的 Partition
- 分区策略(优先级从高到低):
- 自定义分区策略:开发者实现
Partitioner接口,自定义分区规则 - 按消息 Key 哈希:指定
key时,Kafka 对 Key 做哈希运算,分配到固定 Partition,保证相同 Key 的消息进入同一 Partition - 轮询策略:无 Key 时,消息按顺序轮询分配到所有 Partition,实现负载均衡
- 自定义分区策略:开发者实现
- 分区策略(优先级从高到低):
- 生产者将消息批量打包(默认 16KB),异步发送到目标 Partition 的 Leader 副本
- Leader 副本收到消息后,将消息追加到本地日志(Segment 文件),并返回确认回执给生产者Sender异步线程,如果是同步发送模式其实采用的是
Future.get()阻塞主线程,等待 ACK 结果。 - Follower 副本从 Leader 副本拉取消息,同步到本地日志;同步完成后,向 Leader 发送确认
- Leader 副本收到ISR 集合中所有副本的确认后,标记消息为「已提交」,此时消息才对消费者可见
3.2 消息存储机制(日志模型)
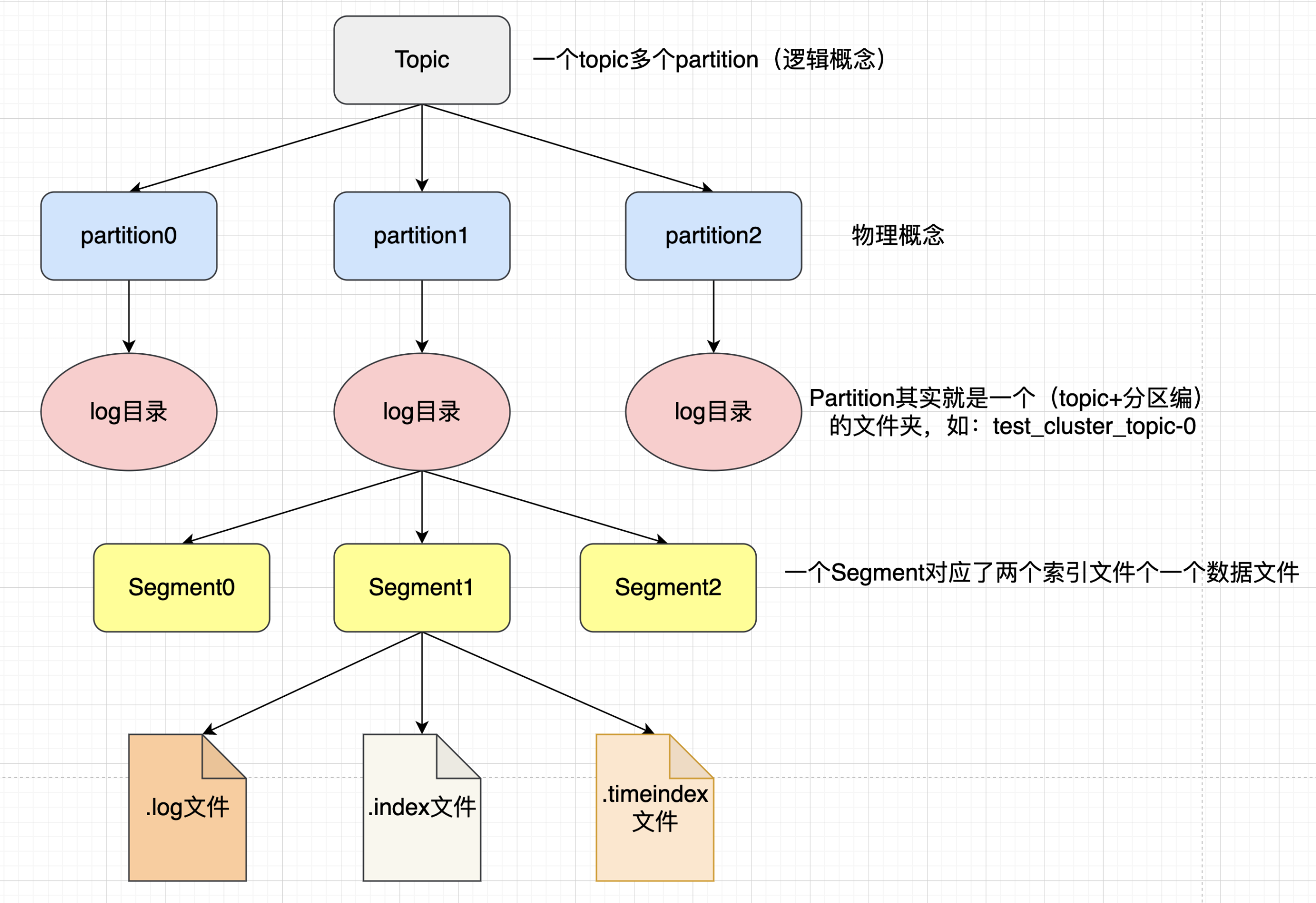
Kafka 的消息存储基于日志分段模型,是实现高吞吐、持久化的核心:
-
日志结构:每个 Partition 的日志分为多个 Segment,每个 Segment 包含
.log(数据文件)和.index(索引文件)-
.log文件:存储消息的实际内容,消息按写入顺序追加,采用顺序 IO(顺序 IO 比随机 IO 快 10 倍以上) -
.index文件:存储 Offset 到消息物理位置的映射,用于快速查找消息,避免全文件扫描
-
-
日志清理策略:Kafka 支持两种日志清理策略,用于删除过期消息,释放磁盘空间
-
删除策略(Delete):默认策略,按时间(
log.retention.hours,默认 168 小时)或大小(log.retention.bytes)删除过期 Segment - 压缩策略(Compact):保留相同 Key 的最新消息,删除旧消息;适用于存储键值对类型的消息(如配置信息、用户状态)
-
删除策略(Delete):默认策略,按时间(
-
持久化保障:消息写入 Leader 副本后,会先写入内存缓冲区,再异步刷盘到磁盘;可配置
acks=1或acks=all保障消息不丢失
3.3 消息拉取→消费 完整流程(消费者侧)
Kafka 采用拉模式消费消息,由消费者自主控制消费速度,是 Kafka 高吞吐的关键设计:
- 消费者配置 Broker 地址列表和消费者组 ID(
group.id),与 Broker 建立 TCP 连接 - 消费者向 Group Coordinator 发送请求,获取自己分配到的 Partition 列表
- 消费者向分配的 Partition 的 Leader 副本发送拉取请求,指定拉取的起始 Offset 和拉取大小
- Leader 副本根据拉取请求,从本地日志中读取消息,返回给消费者
- 消费者接收消息后,执行业务处理逻辑
- 消费者处理完消息后,提交 Offset(自动或手动),记录消费进度;下一次拉取时,从提交的 Offset 开始继续消费
3.4 核心可靠性保障机制
Kafka 通过副本同步+生产者确认+消费者 Offset 管理,实现消息的端到端可靠性保障:
3.4.1 生产者确认机制(acks 参数)
生产者发送消息后,需要等待 Leader 副本的确认,acks 参数控制确认的严格程度:
-
acks=0:生产者发送消息后,不等待任何确认,直接认为发送成功;消息可能丢失,性能最高 -
acks=1:生产者等待 Leader 副本将消息写入本地日志后,返回确认;Leader 故障时,消息可能丢失,性能适中(默认值) -
acks=all:生产者等待 Leader 副本写入日志,且 ISR 集合中所有 Follower 副本同步完成后,返回确认;消息永不丢失,性能最低,生产核心业务必配
3.4.2 幂等性生产者(Idempotent Producer)
解决生产者重复发送消息的问题,通过生产者 ID(PID)+ 序列号(Sequence Number) 实现:
- 生产者初始化时,Kafka 分配一个唯一 PID
- 生产者发送消息时,为每个 Partition 维护一个递增的序列号
- Leader 副本收到消息时,检查 PID 和序列号,丢弃重复的消息
- 配置方式:
enable.idempotence=true,开启后acks自动设为all
3.4.3 事务生产者(Transactional Producer)
实现跨分区、跨 Topic 的原子性消息发送,保障一批消息要么全部发送成功,要么全部失败:
- 核心特性:支持「发送消息」和「提交 Offset」的原子性操作,常用于 Kafka Streams 等流处理场景
- 配置方式:开启幂等性后,配置
transactional.id即可启用事务
四、Kafka 核心特性
4.1 核心高性能特性
-
超高吞吐量
- 核心优化:批量读写(生产者批量发送、消费者批量拉取)、顺序 IO(消息追加写入,无随机写)、分区并行(多 Partition 同时读写)、零拷贝
- 性能指标:单 Broker 可支持百万级/秒的消息吞吐量,延迟低至毫秒级
-
高并发支持
- 基于分区的并行处理,支持数千个 Partition 和数千个消费者并发消费,适合海量消息场景
-
低延迟
- 消息从生产到消费的端到端延迟可低至毫秒级,满足实时业务需求(如实时监控、实时推荐)
零拷贝优化:
- 传统数据拷贝:
磁盘文件 → 内核缓冲区(Kernel Buffer)→ 用户缓冲区(User Buffer)→ Socket 缓冲区 → 网卡【4次拷贝:磁盘→内核、内核→用户、用户→Socket、Socket→网卡】- 优化后的拷贝:
磁盘文件 → 内核缓冲区(Kernel Buffer)→ Socket 缓冲区 → 网卡【2次拷贝:磁盘→内核(DMA拷贝)、内核→网卡(DMA拷贝),全程无用户态参与】
4.2 核心高可用特性
持久化+ACK+副本机制为核心本质
-
副本机制(高可用核心基石)
- 每个
Partition配置多副本(1个Leader + N个Follower),Leader处理读写请求,Follower实时同步数据,规避单点数据丢失; - Leader故障时,通过
Raft协议(2.8+)或ZooKeeper自动选举健康Follower为新Leader,毫秒级完成且业务无感知; - 支持机架感知配置,提升跨节点/机房容灾能力;引入
ISR(同步副本集)机制,确保只有同步完成的副本参与选举。
- 每个
-
消息持久化(数据不丢失的基础)
- 消息以日志文件形式追加写入磁盘(顺序IO),默认持久化,Broker宕机重启后可从磁盘完整恢复数据;
- 数据先写入内核缓冲区再异步刷盘,兼顾性能与可靠性,支持自定义刷盘策略(同步/定时刷盘);
- 支持将日志同步至外部存储(如
HDFS),实现异地容灾。
-
ACK确认机制(数据投递可靠性保障)
- 生产者支持3种
ACK级别配置,适配不同业务场景:-
ACK=0:发送后无需Broker确认,性能最高但可能丢数; -
ACK=1:Leader写入成功即返回确认,性能与可靠性折中; -
ACK=-1/all:ISR内所有副本写入成功才确认,核心业务首选;
-
- 与副本机制深度联动,平衡数据可靠性与生产性能。
- 生产者支持3种
-
控制器自动选举(集群管控高可用)
- 集群选举1个Broker作为控制器,负责
Partition副本分配、Leader选举、Broker上下线感知; - 控制器故障后,
ZooKeeper或KRaft立即触发新控制器选举,秒级完成且管控无中断; - 实时监听集群状态,自动触发副本重分配、Leader转移,无需人工干预。
- 集群选举1个Broker作为控制器,负责
-
Broker故障自愈(节点级容灾)
- Broker宕机后,其上
PartitionLeader自动转移至其他Broker的健康Follower副本; - 故障Broker重启后,自动从新Leader同步增量数据,重新加入
ISR恢复Follower角色; - 支持优雅下线,下线前先转移Leader,避免服务中断或数据丢失。
- Broker宕机后,其上
-
数据一致性保障(故障后数据不紊乱)
-
HW(高水位)机制:仅HW之前的消息对消费者可见,避免读取未同步完成的消息; - Follower失联后,基于
HW和LEO(日志末端偏移量)增量同步;数据损坏或落后过多时触发全量同步; - 日志清理/压缩策略有序清理过期数据,避免存储故障,保障有效数据完整性。
-
4.3 核心灵活扩展特性
-
水平扩展
- 支持动态添加 Broker 节点,新节点加入后,集群自动将 Partition 迁移到新节点,实现负载均衡,无需停机
-
分区扩展
- 支持动态增加 Topic 的 Partition 数量(不支持减少),提升并行度
-
多语言客户端支持
- 支持 Java、Go、Python、PHP 等多种语言的客户端,生态完善
4.4 核心流处理特性
-
Kafka Streams
- Kafka 内置的轻量级流处理库,无需独立部署,可直接嵌入应用程序中
- 核心能力:支持实时数据处理、聚合计算、窗口计算、状态管理,实现从消息到结果的端到端处理
-
连接器(Kafka Connect)
- 用于实现 Kafka 与外部系统(如数据库、Elasticsearch、HDFS)的数据同步,支持数据的导入和导出
- 核心特性:支持分布式部署,自动容错,无需编写代码即可实现数据同步
五、Kafka 关键运维与配置要点
5.1 核心配置优化(生产必改,性能+稳定性双提升)
所有配置均在 Kafka 的核心配置文件 server.properties 中修改,以下是优先级最高的核心配置:
-
基础集群配置
-
broker.id=1:Broker 的唯一 ID,每个节点必须不同 -
listeners=PLAINTEXT://:9092:Broker 的监听地址和端口,生产建议配置内网 IP -
log.dirs=/data/kafka/logs:消息日志的存储目录,建议配置多个磁盘目录,提升 IO 性能 -
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181:ZooKeeper 集群地址(Kafka 依赖 ZooKeeper 存储元数据)
-
-
高可用配置
-
default.replication.factor=3:默认副本数,建议配置 3(生产核心 Topic 必配 3 副本) -
min.insync.replicas=2:ISR 集合的最小副本数,配合acks=all使用,保障消息可靠性
-
-
性能优化配置
-
num.partitions=8:Topic 的默认分区数,建议根据 Broker 数量配置(如 3 个 Broker 配置 8~12 个分区) -
batch.size=16384:生产者批量发送的默认大小(16KB),可根据业务调整 -
linger.ms=5:生产者等待批量发送的时间,5ms 内积累的消息一起发送,提升吞吐量 -
log.segment.bytes=1073741824:Segment 文件的大小(默认 1GB),建议不修改
-
-
日志清理配置
-
log.retention.hours=168:日志保留时间(默认 7 天),可根据业务调整 -
log.cleanup.policy=delete:日志清理策略(默认删除),键值对场景可配置为compact
-
5.2 核心运维命令
Kafka 提供丰富的命令行工具(位于 bin 目录),以下是生产高频使用的命令:
- Topic 管理命令
# 创建 Topic(3 分区,3 副本)
kafka-topics.sh --create --topic test_topic --bootstrap-server broker1:9092 --partitions 3 --replication-factor 3# 查看 Topic 详情
kafka-topics.sh --describe --topic test_topic --bootstrap-server broker1:9092# 删除 Topic
kafka-topics.sh --delete --topic test_topic --bootstrap-server broker1:9092# 列出所有 Topic
kafka-topics.sh --list --bootstrap-server broker1:9092
- 生产者消费者命令
# 启动控制台生产者
kafka-console-producer.sh --topic test_topic --bootstrap-server broker1:9092# 启动控制台消费者(从头开始消费)
kafka-console-consumer.sh --topic test_topic --bootstrap-server broker1:9092 --from-beginning# 查看消费者组的 Offset 信息
kafka-consumer-groups.sh --describe --group test_group --bootstrap-server broker1:9092
- 集群状态命令
# 查看 Broker 节点状态
kafka-broker-api-versions.sh --bootstrap-server broker1:9092# 查看消费者组列表
kafka-consumer-groups.sh --list --bootstrap-server broker1:9092
5.3 生产高频运维问题与解决方案
5.3.1 消息堆积问题(最常见)
- 问题现象:Topic 的 Partition 中未消费的消息数持续增长,消费速度远低于生产速度
- 核心原因:消费者数量不足、消费逻辑阻塞、拉取批次太小、Partition 数量不足
-
解决方案:
- 批处理:(调大消费者的拉取批次(
fetch.max.bytes、max.poll.records)) - 提升消费效率(优化消费逻辑,减少业务处理时间(如异步处理、批量处理))
- 提升消费能力(增加消费者数量和Partition 数量,提升并行度)
- 如果消息积压过多,可新增topic快速恢复业务,存量的消息如果不太总要可丢弃,如果不能丢弃需要单独新增消费者慢慢消费
- 批处理:(调大消费者的拉取批次(
5.3.2 副本同步失败问题
- 问题现象:Follower 副本无法同步 Leader 副本的消息,被踢出 ISR 集合
- 核心原因:网络延迟过高、Follower 副本性能不足、Leader 副本压力过大
-
解决方案:
- 检查网络状态,确保 Broker 之间网络通畅
- 调大 Follower 副本的拉取超时时间(
replica.fetch.timeout.ms) - 平衡 Leader 副本的分布(避免单个 Broker 上的 Leader 过多)
5.3.3 Offset 丢失问题
- 问题现象:消费者重启后,消费位置回退到之前的 Offset,导致重复消费
- 核心原因:使用自动提交 Offset,消费者处理消息时宕机,Offset 已提交但消息未处理完成
- 解决方案:使用手动提交 Offset,确保消息处理完成后再提交 Offset
5.3.4 控制器节点故障问题
- 问题现象:控制器节点宕机,集群出现短暂的 Partition 领导者选举
- 解决方案:无需人工干预,集群会自动重新选举新控制器;选举完成后,集群恢复正常
六、Kafka 核心使用场景
Kafka 的核心价值是高吞吐、持久化、分布式,所有使用场景均围绕这三个核心特性展开,覆盖大数据和业务系统的全领域:
6.1 日志收集与聚合
- 业务场景:收集分布式系统的日志(如应用日志、服务器日志),聚合到 Kafka 中,再由消费者将日志写入 Elasticsearch、HDFS 等存储系统
- 核心价值:高吞吐支持海量日志的实时收集,持久化保障日志不丢失,分布式架构支持水平扩展
- 典型案例:ELK 日志分析系统(Elasticsearch + Logstash + Kibana),使用 Kafka 作为日志缓冲层
6.2 大数据流式处理
- 业务场景:实时处理海量数据流(如用户行为数据、订单数据),进行实时分析、聚合计算、实时推荐
- 核心价值:Kafka Streams 提供轻量级流处理能力,无需独立部署;高吞吐支持实时处理,低延迟满足实时业务需求
- 典型案例:实时用户行为分析、实时风控系统、实时推荐系统
6.3 分布式消息队列(解耦+削峰)
- 业务场景:实现分布式系统之间的异步通信,解耦上下游服务;应对突发流量(如秒杀、促销),实现流量削峰填谷
- 核心价值:高吞吐支持突发流量的缓冲,持久化保障消息不丢失,分区并行支持高并发消费
- 典型案例:电商订单系统,订单创建后发送到 Kafka,库存服务、支付服务、物流服务异步消费订单消息
6.4 数据同步与复制
- 业务场景:实现不同系统之间的数据同步(如数据库与缓存同步、跨地域数据同步)
- 核心价值:Kafka Connect 支持与外部系统的无缝集成,无需编写代码;分布式架构支持跨地域数据同步
- 典型案例:MySQL 数据变更同步到 Elasticsearch、跨地域 Kafka 集群数据同步
6.5 事件溯源(Event Sourcing)
- 业务场景:记录系统的所有事件(如用户操作、订单状态变更),通过重放事件恢复系统状态
- 核心价值:持久化保障事件不丢失,有序的日志模型支持事件的顺序重放
- 典型案例:金融交易系统、订单状态追溯系统
七、Kafka 常见问题
7.1 基础概念类
-
问题:Kafka 的核心组件有哪些?各自的作用是什么?
答案:核心组件包括 Producer(生产者,发送消息)、Consumer(消费者,消费消息)、Broker(服务节点,存储和处理消息)、Topic(主题,消息逻辑分类)、Partition(分区,物理存储单元)、Replica(副本,保障高可用)、Controller(控制器,管理集群元数据)。 -
问题:Kafka 的 Topic 和 Partition 的关系是什么?Partition 的作用是什么?
答案:Topic 是消息的逻辑分类,Partition 是 Topic 的物理存储单元,一个 Topic 可分为多个 Partition;Partition 的作用是实现并行处理,多个 Partition 分布在不同 Broker 上,支持生产者并行写入、消费者并行消费,提升吞吐量。 -
问题:Kafka 的消费者组是什么?核心规则是什么?
答案:消费者组是多个消费者的逻辑分组;核心规则是「一个 Partition 只能被同一个消费者组内的一个消费者消费」,组内消费者负载均衡消费不同 Partition,组间消费者可重复消费同一 Topic。 -
问题:Kafka 的 Offset 是什么?有什么作用?
答案:Offset 是消息在 Partition 内的唯一标识,是一个自增整数;作用是记录消息的位置,消费者通过 Offset 记录消费进度,实现断点续传。
7.2 原理机制类
-
问题:Kafka 的消息生产流程是什么?
答案:分 6 步:① 生产者获取 Topic 元数据;② 根据分区策略分配 Partition;③ 批量发送消息到 Leader 副本;④ Leader 写入本地日志;⑤ Follower 同步消息;⑥ Leader 收到 ISR 确认后,返回成功给生产者。 -
问题:Kafka 如何保障消息不丢失?
答案:需三层保障:① 生产者端配置acks=all,等待所有副本同步完成;② Broker 端配置副本数≥3,确保 ISR 集合有足够副本;③ 消费者端使用手动提交 Offset,处理完消息再提交。 -
问题:Kafka 的副本机制是什么?ISR 集合的作用是什么?
答案:每个 Partition 有 Leader 和 Follower 副本,Leader 处理读写,Follower 同步数据;ISR 集合是与 Leader 保持同步的副本集合,只有 ISR 内的副本有资格被选举为新 Leader,保障高可用。 -
问题:Kafka 的幂等性和事务是如何实现的?
答案:① 幂等性通过 PID(生产者 ID)+ 序列号实现,Leader 丢弃重复消息;② 事务基于幂等性,通过transactional.id实现跨分区、跨 Topic 的原子性消息发送。 -
问题:Kafka 的重平衡是什么?如何避免频繁重平衡?
答案:重平衡是消费者组内 Partition 重新分配的过程;避免方法:① 避免消费者频繁上下线;② 配置合理的session.timeout.ms和heartbeat.interval.ms;③ 消费者数量不超过 Partition 数量。
7.3 高可用与运维类
-
问题:Kafka 的控制器节点的作用是什么?故障后如何处理?
答案:控制器负责管理集群元数据、选举 Partition Leader、处理 Broker 上下线;控制器故障后,集群自动重新选举新控制器,无需人工干预。 -
问题:Kafka 消息堆积的原因和解决方案是什么?
答案:原因:消费者数量不足、消费逻辑阻塞、Partition 不足;解决方案:增加消费者数量、优化消费逻辑、调大拉取批次、增加 Partition 数量。 -
问题:Kafka 的日志清理策略有哪些?各自的适用场景是什么?
答案:① 删除策略:按时间/大小删除过期日志,适用于普通消息场景;② 压缩策略:保留相同 Key 的最新消息,适用于键值对场景(如配置同步)。
7.4 选型对比类
-
问题:Kafka 和 RabbitMQ 的核心区别是什么?各自适用场景是什么?
答案:特性维度 Kafka RabbitMQ 设计定位 分布式流处理平台,高吞吐优先 企业级消息队列,可靠性与灵活性优先 核心协议 自定义 TCP 协议 AMQP 0-9-1 协议 吞吐量 超高吞吐量,百万级/秒 中低吞吐量,万级/秒 消费模式 拉模式,自主控制消费速度 推模式为主,支持拉模式 存储模型 日志分段存储,持久化能力强 内存+磁盘存储,持久化依赖配置 适用场景 日志收集、流式计算、海量消息存储 业务解耦、异步通信、延迟任务 - 选型建议:大数据场景、海量日志场景选 Kafka;业务系统解耦、复杂路由场景选 RabbitMQ。
-
问题:Kafka 的优缺点是什么?
答案:- 优点:超高吞吐量、高可用、可扩展、持久化能力强、支持流处理、生态完善;
- 缺点:路由灵活性低(仅支持 Topic 分区路由)、消息延迟略高于 RabbitMQ、运维复杂度高于 RabbitMQ。
© 版权声明
文章版权归作者所有,未经允许请勿转载。