AI的提示词专栏:Prompt 引导的 ETL 流程自动化


AI的提示词专栏:Prompt 引导的 ETL 流程自动化
本文聚焦 Prompt 引导的 ETL 流程自动化,先阐述该模式核心价值,即通过自然语言指令让大语言模型生成处理逻辑,解决传统 ETL 技术门槛高、迭代效率低、场景适配难的痛点,实现降本提效、灵活适配与低门槛复用。接着分阶段详解抽取、转换、加载的 Prompt 设计逻辑与实战案例,涵盖 MySQL、API、CSV 等数据源处理,数据清洗、字段计算、多表关联等转换操作,以及文件、MySQL 等目标存储加载。还提供完整 ETL 流程的 Prompt 模板与代码,分析该模式优势与注意事项,并设计课后练习。整体为读者呈现从理论到实践的完整指南,助力实现自然语言驱动的 ETL 自动化转型。

人工智能专栏介绍
人工智能学习合集专栏是 AI 学习者的实用工具。它像一个全面的 AI 知识库,把提示词设计、AI 创作、智能绘图等多个细分领域的知识整合起来。无论你是刚接触 AI 的新手,还是有一定基础想提升的人,都能在这里找到合适的内容。从最基础的工具操作方法,到背后深层的技术原理,专栏都有讲解,还搭配了实例教程和实战案例。这些内容能帮助学习者一步步搭建完整的 AI 知识体系,让大家快速从入门进步到精通,更好地应对学习和工作中遇到的 AI 相关问题。

这个系列专栏能教会人们很多实用的 AI 技能。在提示词方面,能让人学会设计精准的提示词,用不同行业的模板高效和 AI 沟通。写作上,掌握从选题到成稿的全流程技巧,用 AI 辅助写出高质量文本。编程时,借助 AI 完成代码编写、调试等工作,提升开发速度。绘图领域,学会用 AI 生成符合需求的设计图和图表。此外,还能了解主流 AI 工具的用法,学会搭建简单智能体,掌握大模型的部署和应用开发等技能,覆盖多个场景,满足不同学习者的需求。

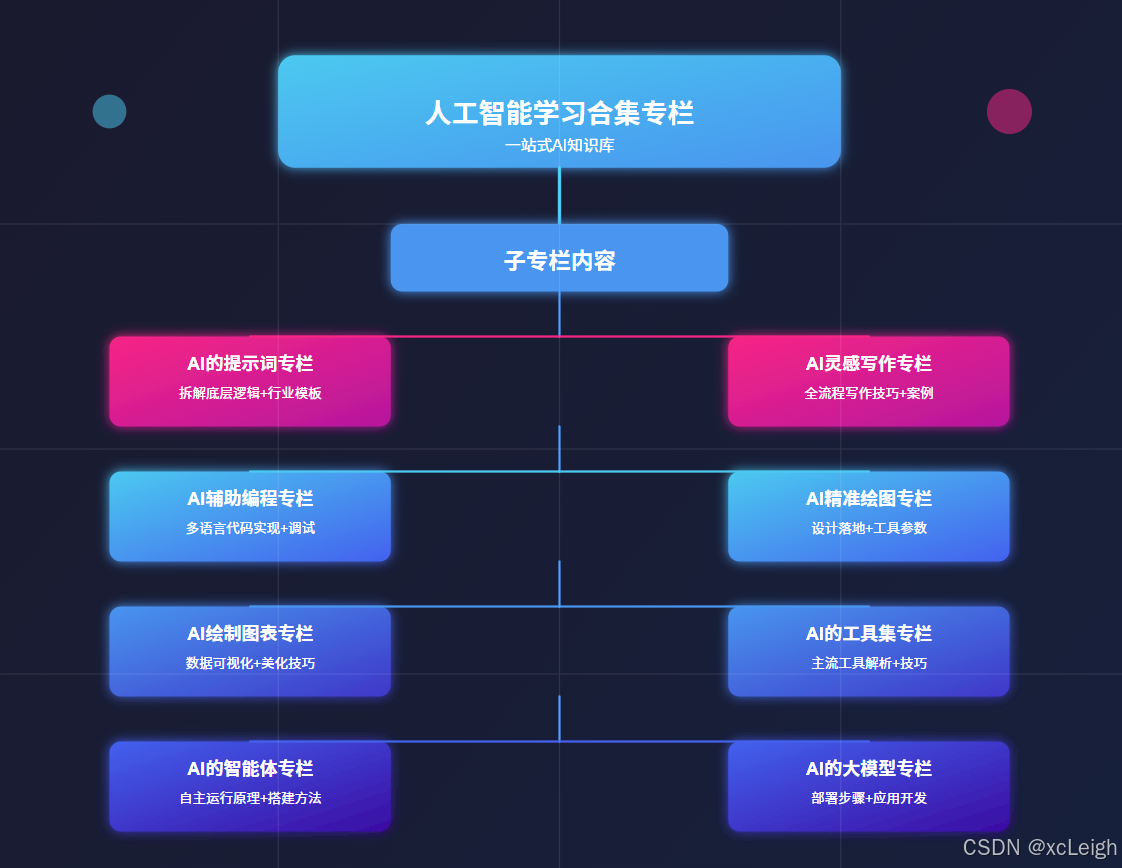
1️⃣ ⚡ 点击进入 AI 的提示词专栏,专栏拆解提示词底层逻辑,从明确指令到场景化描述,教你精准传递需求。还附带包含各行业适配模板:医疗问诊话术、电商文案指令等,附优化技巧,让 AI 输出更贴合预期,提升工作效率。
2️⃣ ⚡ 点击进入 AI 灵感写作专栏,AI 灵感写作专栏,从选题到成稿,全流程解析 AI 写作技巧。涵盖论文框架搭建、小说情节生成等,教你用提示词引导 AI 输出内容,再进行人工润色。附不同文体案例,助你解决写作卡壳,产出高质量文本。
3️⃣ ⚡ 点击进入 AI 辅助编程专栏,AI 辅助编程专栏,通过实例教你用 AI 写代码:从功能描述到调试优化。涵盖前端、后端、数据库等,语言包括HTML5、VUE、Python、Java、C# 等语言,含算法实现、Bug 修复技巧,帮开发者减少重复劳动,专注核心逻辑,提升开发速度。
4️⃣ ⚡ 点击进入 AI 精准绘图专栏,AI 精准绘图,聚焦 AI 绘图在设计场景的落地。详解如何描述风格、元素、用途,生成 logo、商标等。含 Midjourney 等工具参数设置,及修改迭代方法,帮设计新手快速出图,满足商业与个人需求。
5️⃣ ⚡ 点击进入 AI 绘制图表专栏,AI 绘制图表专栏,教你用 AI 工具将数据转化为直观图表。涵盖曲线图数据输入、流程图逻辑梳理等,附 Excel 联动、格式美化技巧,适合学生、职场人快速制作专业图表,提升数据展示效果。
6️⃣ ⚡ 点击进入 AI 的工具集专栏,AI 的工具集专栏,盘点主流 AI 工具:ChatGPT、DeepSeek、 Claude、Gemini、Copilot 等。解析各工具优势,附使用场景与技巧,帮你根据需求选工具,快速上手提升效率,覆盖办公、创作、开发等场景。
7️⃣ ⚡ 点击进入 AI 的智能体专栏,AI 的智能体专栏,解析智能体自主运行原理,包括任务拆解、环境交互等。教你用大模型搭建简单智能体,附多智能体协作案例,适合想探索 AI 自主系统的开发者入门。
8️⃣ ⚡ 点击进入 AI 的大模型专栏,AI 的大模型专栏,详解大模型部署步骤,从本地搭建到云端部署。含 API 调用教程、应用开发案例,教你将大模型集成到项目,掌握企业级 AI 应用开发技能,应对实际业务需求。
一、ETL 流程与 Prompt 结合的核心价值
在数据驱动决策的时代,ETL(Extract-抽取、Transform-转换、Load-加载)作为数据管道的核心环节,直接决定了数据从原始状态到可用资产的转化效率。传统 ETL 流程依赖工程师编写大量代码(如 SQL、Python)、配置复杂工具(如 Informatica、DataStage),存在三大核心痛点:一是技术门槛高,需熟练掌握数据处理语言与工具,非技术岗(如业务分析师)难以参与;二是迭代效率低,当数据源格式变化、业务规则调整时,需重新修改代码与配置,周期常达数天;三是场景适配难,面对非结构化数据(如日志、文档)或小众数据源(如特定 API),传统工具的预处理能力不足。
而 Prompt 引导的 ETL 自动化,通过自然语言指令定义 ETL 各环节规则,让大语言模型(LLM)自动生成处理逻辑、代码或配置,从根本上解决了上述问题。其核心价值体现在三方面:
- 降本提效:将 ETL 流程的搭建周期从“天级”压缩至“小时级”,非技术人员可通过自然语言参与流程设计,减少跨岗位沟通成本;
- 灵活适配:无需修改底层代码,仅通过调整 Prompt 即可适配新数据源、新业务规则,尤其擅长处理半结构化/非结构化数据的预处理;
- 低门槛复用:将复杂 ETL 逻辑封装为“Prompt 模板”,后续同类场景仅需替换变量(如数据源路径、字段映射关系)即可快速复用。
二、ETL 各阶段的 Prompt 设计逻辑与原则
ETL 流程的抽取、转换、加载三阶段目标不同,对应的 Prompt 设计需遵循“场景化指令+明确约束+示例引导”的核心逻辑,同时需结合各阶段特性调整侧重点。
(一)通用 Prompt 设计原则
无论针对哪个 ETL 阶段,Prompt 需满足以下 4 点要求,确保 LLM 输出符合预期:
- 目标明确化:清晰说明该阶段需达成的具体结果(如“抽取 MySQL 表中近 7 天的用户订单数据”“将日期格式从‘YYYY-MM-DD’转换为‘MM/DD/YYYY’”),避免模糊表述(如“处理订单数据”);
- 上下文完整化:提供数据源信息(类型、格式、结构)、业务规则(如“订单金额需大于 0,否则标记为异常”)、工具限制(如“使用 Python Pandas 实现,避免使用第三方库”);
- 格式约束化:指定输出格式(如“生成可直接运行的 Python 代码,包含注释与异常处理”“输出字段映射表,包含源字段、目标字段、转换规则”);
- 示例引导化:若场景复杂(如多条件数据过滤),可提供 1-2 个简单示例(如“示例:过滤‘支付状态=未支付’的订单,对应代码为 df[df[‘pay_status’] == ‘未支付’]”),降低 LLM 理解成本。
(二)各阶段 Prompt 设计侧重点
| ETL 阶段 | 核心目标 | Prompt 设计侧重点 | 关键信息要素 |
|---|---|---|---|
| 抽取(Extract) | 从数据源(数据库、API、文件等)准确获取目标数据,避免遗漏或冗余 | 1. 明确数据源类型与访问方式 2. 定义数据筛选条件(时间范围、字段范围等) 3. 要求输出数据预览与校验逻辑 |
数据源类型(MySQL/CSV/API)、访问凭证(脱敏后,如“数据库地址:xxx.xxx.xxx.xxx”)、筛选条件(如“近 30 天”“字段:user_id, order_id, amount”)、数据量限制(如“最多抽取 10000 条测试数据”) |
| 转换(Transform) | 按业务规则清洗、整合数据(如缺失值处理、格式转换、多表关联),确保数据质量 | 1. 拆解转换步骤(如“先处理缺失值,再进行字段计算”) 2. 明确每个步骤的业务规则(如“缺失值用‘未知’填充,而非删除”) 3. 要求输出转换后的数据校验指标(如“输出缺失值处理前后的字段非空率”) |
转换规则(如“订单金额=商品单价×数量,保留 2 位小数”)、异常值定义(如“金额>10000 为异常,标记为‘待审核’”)、关联条件(如“通过‘user_id’关联用户表与订单表”) |
| 加载(Load) | 将转换后的数据写入目标存储(数据仓库、数据湖等),确保格式兼容、写入高效 | 1. 指定目标存储类型与表结构 2. 定义写入策略(如“全量覆盖”“增量追加”) 3. 要求输出加载日志(如“成功写入行数、耗时、错误信息”) |
目标存储类型(Hive/ClickHouse/Excel)、表结构(字段名、数据类型,如“order_id: string, amount: float”)、写入策略(如“每日凌晨 2 点全量覆盖前一天数据”)、冲突处理(如“主键重复时保留最新数据”) |
三、抽取阶段(Extract)的 Prompt 实战
抽取阶段的核心是“精准获取目标数据”,需根据数据源类型(结构化数据库、文件、API)设计差异化 Prompt,以下为典型场景的实战案例。
(一)场景 1:从 MySQL 数据库抽取数据
1. Prompt 指令
请作为数据工程师,生成从 MySQL 数据库抽取数据的 Python 代码,需满足以下要求:
1. 数据源信息:
- 数据库地址:192.168.1.100,端口:3306,数据库名:ecommerce_db
- 目标表:orders(订单表),需抽取的字段:order_id(订单ID)、user_id(用户ID)、order_time(下单时间)、amount(订单金额)、pay_status(支付状态,取值:已支付/未支付/退款)
2. 筛选条件:
- 时间范围:order_time 大于等于 2024-01-01 00:00:00,且小于 2024-02-01 00:00:00
- 支付状态:排除“退款”状态的数据
3. 输出要求:
- 生成可直接运行的 Python 代码,使用 pymysql 库连接数据库,包含异常处理(如连接失败、查询超时)
- 代码中需将数据库用户名、密码设为变量,方便替换
- 抽取完成后,打印“成功抽取 X 条数据”,并预览前 5 条数据(隐藏敏感字段,如 user_id 只显示后 4 位)
4. 附加要求:避免一次性读取大量数据导致内存溢出,需使用分批读取(每次读取 1000 条)
2. 预期输出(Python 代码)
import pymysql
import pandas as pd
from pymysql.cursors import DictCursor
def extract_mysql_orders():
# 数据库配置(需替换为实际用户名、密码)
db_config = {
"host": "192.168.1.100",
"port": 3306,
"user": "your_username", # 替换为实际用户名
"password": "your_password", # 替换为实际密码
"db": "ecommerce_db",
"charset": "utf8mb4"
}
# 目标字段与筛选条件
target_fields = "order_id, user_id, order_time, amount, pay_status"
start_time = "2024-01-01 00:00:00"
end_time = "2024-02-01 00:00:00"
batch_size = 1000 # 分批读取大小
all_orders = [] # 存储所有抽取的数据
try:
# 建立数据库连接
connection = pymysql.connect(**db_config, cursorclass=DictCursor)
cursor = connection.cursor()
print("MySQL 数据库连接成功")
# 1. 查询符合条件的总数据量(用于分批)
count_sql = f"""
SELECT COUNT(*) AS total
FROM orders
WHERE order_time >= '{start_time}'
AND order_time < '{end_time}'
AND pay_status != '退款'
"""
cursor.execute(count_sql)
total_count = cursor.fetchone()["total"]
print(f"符合条件的总数据量:{total_count} 条")
# 2. 分批读取数据
for offset in range(0, total_count, batch_size):
extract_sql = f"""
SELECT {target_fields}
FROM orders
WHERE order_time >= '{start_time}'
AND order_time < '{end_time}'
AND pay_status != '退款'
LIMIT {batch_size} OFFSET {offset}
"""
cursor.execute(extract_sql)
batch_data = cursor.fetchall()
all_orders.extend(batch_data)
print(f"已抽取 {len(all_orders)}/{total_count} 条数据")
# 3. 数据预览(隐藏敏感字段)
if all_orders:
df_preview = pd.DataFrame(all_orders).head(5)
# user_id 只显示后 4 位
df_preview["user_id"] = df_preview["user_id"].astype(str).str[-4:]
print("n数据预览(前 5 条):")
print(df_preview.to_string(index=False))
return pd.DataFrame(all_orders)
except Exception as e:
print(f"抽取数据失败:{str(e)}")
return None
finally:
# 关闭连接
if "cursor" in locals():
cursor.close()
if "connection" in locals() and connection.open:
connection.close()
print("MySQL 数据库连接已关闭")
# 执行抽取
if __name__ == "__main__":
extracted_data = extract_mysql_orders()
if extracted_data is not None:
print(f"n抽取完成,共获取 {len(extracted_data)} 条订单数据")
3. 技巧点分析
-
安全设计:将数据库用户名、密码设为变量,避免硬编码泄露;使用分批读取(
LIMIT + OFFSET)防止大数据量导致内存溢出,适合百万级数据场景; - 用户体验优化:添加进度提示(如“已抽取 X/Y 条数据”)和数据预览,方便用户快速验证抽取结果是否正确;
- 异常处理:覆盖“连接失败”“查询报错”等场景,避免程序崩溃,同时输出详细错误信息,便于排查问题。
(二)场景 2:从 API 接口抽取数据
1. Prompt 指令
请生成从“电商商品详情 API”抽取数据的 Python 代码,需满足以下要求:
1. API 信息:
- 接口地址:https://api.ecommerce.com/v1/products
- 请求方式:GET
- 请求参数:
- app_key:your_app_key(需保留为变量)
- category_id:3(商品分类ID,固定为 3,即“电子产品”)
- page:分页参数(从 1 开始)
- page_size:每页数据量(固定为 20)
- 响应格式:JSON,包含“code”(状态码,200 为成功)、“data”(商品列表,含 product_id、name、price、stock、create_time 字段)、“total_page”(总页数)
2. 抽取规则:
- 自动遍历所有分页(从 page=1 到 page=total_page),获取该分类下所有商品数据
- 若 API 响应 code != 200,需重试 2 次(每次间隔 3 秒),仍失败则记录错误信息
3. 输出要求:
- 生成 Python 代码,使用 requests 库发送请求,包含超时设置(10 秒)
- 抽取完成后,将数据保存为 CSV 文件(路径:./products_electronic.csv),包含表头
- 打印抽取日志:“开始抽取分类 3 商品数据”“第 X 页抽取成功,获取 20 条数据”“抽取完成,共 X 条数据,已保存至 CSV”
2. 预期输出(Python 代码)
import requests
import time
import csv
from typing import List, Dict
def extract_api_products():
# API 配置(需替换为实际 app_key)
API_URL = "https://api.ecommerce.com/v1/products"
APP_KEY = "your_app_key" # 替换为实际 app_key
CATEGORY_ID = 3
PAGE_SIZE = 20
TIMEOUT = 10 # 请求超时时间(秒)
RETRY_TIMES = 2 # 失败重试次数
RETRY_INTERVAL = 3 # 重试间隔(秒)
OUTPUT_CSV = "./products_electronic.csv"
all_products: List[Dict] = []
current_page = 1
total_page = 1 # 初始设为 1,后续从 API 响应获取真实值
print(f"开始抽取分类 {CATEGORY_ID}(电子产品)商品数据")
try:
while current_page <= total_page:
# 构造请求参数
params = {
"app_key": APP_KEY,
"category_id": CATEGORY_ID,
"page": current_page,
"page_size": PAGE_SIZE
}
# 发送请求(带重试逻辑)
retry_count = 0
while retry_count < RETRY_TIMES:
try:
response = requests.get(API_URL, params=params, timeout=TIMEOUT)
response.raise_for_status() # 触发 HTTP 错误(如 404、500)
result = response.json()
# 检查响应状态码
if result.get("code") != 200:
raise Exception(f"API 响应错误:code={result.get('code')}, msg={result.get('msg', '无错误信息')}")
# 获取商品数据与总页数
page_products = result.get("data", [])
total_page = result.get("total_page", 1)
# 累加数据
all_products.extend(page_products)
print(f"第 {current_page} 页抽取成功,获取 {len(page_products)} 条数据(总页数:{total_page})")
break # 成功则跳出重试循环
except Exception as e:
retry_count += 1
if retry_count >= RETRY_TIMES:
raise Exception(f"第 {current_page} 页抽取失败(已重试 {RETRY_TIMES} 次):{str(e)}")
print(f"第 {current_page} 页抽取失败,{RETRY_INTERVAL} 秒后重试(剩余 {RETRY_TIMES - retry_count} 次):{str(e)}")
time.sleep(RETRY_INTERVAL)
# 进入下一页
current_page += 1
# 保存数据到 CSV
if all_products:
# 获取字段名(从第一条数据的键获取)
fieldnames = all_products[0].keys()
with open(OUTPUT_CSV, "w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(all_products)
print(f"n抽取完成,共获取 {len(all_products)} 条商品数据,已保存至:{OUTPUT_CSV}")
else:
print("n抽取完成,未获取到任何商品数据")
return all_products
except Exception as e:
print(f"n抽取过程异常终止:{str(e)}")
return None
# 执行抽取
if __name__ == "__main__":
extract_api_products()
3. 技巧点分析
-
API 稳定性保障:添加重试机制(
retry_count)和超时设置(TIMEOUT),应对网络波动或 API 临时不可用的场景,符合生产环境需求; -
分页逻辑自动化:从 API 响应中动态获取
total_page,避免硬编码分页数量,适配数据量变化; -
数据持久化:直接将抽取结果保存为 CSV,无需中间存储,简化后续转换流程,同时使用
utf-8编码避免中文乱码。
四、转换阶段(Transform)的 Prompt 实战
转换是 ETL 流程中最复杂的环节,需处理“数据清洗”“格式转换”“字段计算”“多表关联”等场景。以下通过 3 个典型场景,展示如何用 Prompt 定义转换规则,让 LLM 自动生成处理逻辑。
(一)场景 1:数据清洗(缺失值、异常值处理)
1. Prompt 指令
现有一份电商订单数据(DataFrame 格式,变量名:df_orders),包含以下字段:
- order_id:订单ID(字符串,无缺失,唯一标识)
- user_id:用户ID(字符串,部分缺失,缺失值标记为“NaN”)
- amount:订单金额(数值型,部分异常值:小于 0 或大于 10000)
- order_time:下单时间(字符串,格式为“YYYY-MM-DD HH:MM:SS”,部分缺失)
- pay_status:支付状态(字符串,取值:已支付/未支付,无缺失)
请生成 Python 代码(使用 Pandas)完成以下数据清洗操作,要求如下:
1. 缺失值处理:
- user_id 缺失:用“未知用户_”+order_id 填充(如 order_id 为“OD12345”,则填充为“未知用户_OD12345”)
- order_time 缺失:填充为“2099-12-31 23:59:59”(标记为待确认时间)
2. 异常值处理:
- amount < 0:将金额修正为 0,并新增字段“amount_flag”标记为“异常-金额为负”
- amount > 10000:将金额修正为 10000(业务规则:单笔订单最高限额 10000),并在“amount_flag”标记为“异常-超最高限额”
- 正常金额(0 ≤ amount ≤ 10000):“amount_flag”标记为“正常”
3. 数据校验:
- 清洗完成后,输出“清洗前后数据量对比”(清洗前总行数、清洗后总行数,注:本场景不删除数据,仅修正)
- 输出“缺失值处理统计”(各字段清洗前缺失数量、清洗后缺失数量)
- 输出“异常值处理统计”(amount 字段异常数量、各异常类型的数量)
4. 代码要求:保留原始数据,清洗后的数据存入新变量 df_orders_clean,代码包含注释。
2. 预期输出(Python 代码)
import pandas as pd
import numpy as np
def transform_clean_orders(df_orders: pd.DataFrame) -> pd.DataFrame:
# 保留原始数据,避免修改原 DataFrame
df_orders_clean = df_orders.copy()
print("=== 开始订单数据清洗 ===")
# 1. 数据清洗前统计
print("n【清洗前统计】")
print(f"总行数:{len(df_orders_clean)}")
print("缺失值统计:")
missing_before = df_orders_clean.isnull().sum()
print(missing_before[missing_before > 0]) # 只显示有缺失的字段
print("amount 异常值统计:")
abnormal_neg_before = len(df_orders_clean[df_orders_clean["amount"] < 0])
abnormal_high_before = len(df_orders_clean[df_orders_clean["amount"] > 10000])
print(f"- 金额为负:{abnormal_neg_before} 条")
print(f"- 超最高限额(>10000):{abnormal_high_before} 条")
print(f"- 异常值总数:{abnormal_neg_before + abnormal_high_before} 条")
# 2. 缺失值处理
print("n【执行缺失值处理】")
# 2.1 处理 user_id 缺失:用“未知用户_+order_id”填充
user_id_missing_mask = df_orders_clean["user_id"].isnull()
df_orders_clean.loc[user_id_missing_mask, "user_id"] = (
"未知用户_" + df_orders_clean.loc[user_id_missing_mask, "order_id"]
)
print(f"- user_id 缺失处理完成,共处理 {user_id_missing_mask.sum()} 条")
# 2.2 处理 order_time 缺失:填充为“2099-12-31 23:59:59”
order_time_missing_mask = df_orders_clean["order_time"].isnull()
df_orders_clean.loc[order_time_missing_mask, "order_time"] = "2099-12-31 23:59:59"
print(f"- order_time 缺失处理完成,共处理 {order_time_missing_mask.sum()} 条")
# 3. 异常值处理(amount 字段)
print("n【执行异常值处理】")
# 3.1 新增 amount_flag 字段,默认标记为“正常”
df_orders_clean["amount_flag"] = "正常"
# 3.2 处理金额为负的异常
neg_mask = df_orders_clean["amount"] < 0
if neg_mask.sum() > 0:
df_orders_clean.loc[neg_mask, "amount"] = 0
df_orders_clean.loc[neg_mask, "amount_flag"] = "异常-金额为负"
print(f"- 金额为负异常处理完成,共修正 {neg_mask.sum()} 条")
# 3.3 处理金额超最高限额的异常
high_mask = df_orders_clean["amount"] > 10000
if high_mask.sum() > 0:
df_orders_clean.loc[high_mask, "amount"] = 10000
df_orders_clean.loc[high_mask, "amount_flag"] = "异常-超最高限额"
print(f"- 超最高限额异常处理完成,共修正 {high_mask.sum()} 条")
# 4. 清洗后校验
print("n【清洗后校验】")
print(f"总行数:{len(df_orders_clean)}(与清洗前一致,未删除数据)")
print("缺失值统计:")
missing_after = df_orders_clean.isnull().sum()
print(missing_after[missing_after > 0] if missing_after.sum() > 0 else "无缺失值")
print("amount 异常值统计:")
abnormal_neg_after = len(df_orders_clean[df_orders_clean["amount"] < 0])
abnormal_high_after = len(df_orders_clean[df_orders_clean["amount"] > 10000])
print(f"- 金额为负:{abnormal_neg_after} 条(目标:0 条)")
print(f"- 超最高限额(>10000):{abnormal_high_after} 条(目标:0 条)")
print(f"- 异常值总数:{abnormal_neg_after + abnormal_high_after} 条(目标:0 条)")
print("n=== 订单数据清洗完成 ===")
return df_orders_clean
# 示例:模拟原始数据并执行清洗(实际使用时替换为真实数据)
if __name__ == "__main__":
# 构造模拟数据
data = {
"order_id": ["OD001", "OD002", "OD003", "OD004", "OD005"],
"user_id": ["U101", np.nan, "U103", np.nan, "U105"],
"amount": [299.9, -50, 12000, 899.5, 5000],
"order_time": ["2024-01-05 14:30:00", np.nan, "2024-01-06 09:15:00", "2024-01-07 18:45:00", np.nan],
"pay_status": ["已支付", "未支付", "已支付", "已支付", "未支付"]
}
df_original = pd.DataFrame(data)
print("原始数据:")
print(df_original.to_string(index=False))
# 执行清洗
df_cleaned = transform_clean_orders(df_original)
# 输出清洗后的数据预览
print("n清洗后数据预览:")
print(df_cleaned.to_string(index=False))
3. 技巧点分析
-
原始数据保护:通过
df_orders.copy()保留原始数据,避免清洗过程中修改源数据,便于后续追溯与对比; -
规则可追溯:新增
amount_flag字段标记异常类型,而非直接删除异常数据,既满足业务需求(如后续需审核异常订单),又便于统计异常原因; - 校验闭环:清洗前后均输出统计信息(缺失值、异常值数量),形成“处理-校验”闭环,确保清洗效果符合预期,降低人工验证成本。
(二)场景 2:字段计算与格式转换
1. Prompt 指令
现有清洗后的订单数据(DataFrame 变量名:df_cleaned),包含字段:order_id、user_id、amount(订单金额,元)、order_time(字符串格式:YYYY-MM-DD HH:MM:SS)、pay_status、amount_flag。
请生成 Python 代码完成以下转换操作:
1. 字段计算:
- 新增“discount_amount”(优惠金额):若 amount ≥ 5000,优惠金额=amount×0.05;若 1000 ≤ amount < 5000,优惠金额=amount×0.02;若 amount < 1000,优惠金额=0(优惠后金额=amount - discount_amount,无需新增字段,仅计算优惠金额)
- 新增“order_month”(下单月份):从 order_time 中提取“YYYY-MM”格式(如“2024-01”)
2. 格式转换:
- 将“order_time”从字符串格式转换为 datetime 格式(便于后续时间筛选)
- 将“amount”“discount_amount”保留 2 位小数(四舍五入)
3. 数据筛选:
- 仅保留“pay_status=已支付”的数据(业务需求:仅分析已支付订单)
4. 输出要求:
- 转换后的数据存入变量 df_transformed
- 打印转换总结:“已支付订单数:X 条”“优惠金额总计:Y 元(保留 2 位小数)”“涉及下单月份:[列表,如 2024-01, 2024-02]”
- 预览前 3 条转换后的数据
2. 预期输出(Python 代码)
import pandas as pd
import numpy as np
def transform_calculate_format(df_cleaned: pd.DataFrame) -> pd.DataFrame:
# 复制数据,避免修改源数据
df_transformed = df_cleaned.copy()
print("=== 开始订单数据计算与格式转换 ===")
# 1. 格式转换:order_time 字符串转 datetime
print("n【执行格式转换】")
df_transformed["order_time"] = pd.to_datetime(df_transformed["order_time"], format="%Y-%m-%d %H:%M:%S")
print("- order_time 字段已转换为 datetime 格式")
# 2. 字段计算
print("n【执行字段计算】")
# 2.1 计算 discount_amount(优惠金额)
def calculate_discount(amount):
if amount >= 5000:
return round(amount * 0.05, 2)
elif 1000 <= amount < 5000:
return round(amount * 0.02, 2)
else:
return 0.00
df_transformed["discount_amount"] = df_transformed["amount"].apply(calculate_discount)
# 确保 amount 保留 2 位小数
df_transformed["amount"] = df_transformed["amount"].round(2)
print("- discount_amount 字段计算完成(保留 2 位小数)")
# 2.2 提取 order_month(下单月份,YYYY-MM 格式)
df_transformed["order_month"] = df_transformed["order_time"].dt.strftime("%Y-%m")
print("- order_month 字段提取完成(格式:YYYY-MM)")
# 3. 数据筛选:仅保留已支付订单
print("n【执行数据筛选】")
df_transformed = df_transformed[df_transformed["pay_status"] == "已支付"].reset_index(drop=True)
paid_count = len(df_transformed)
print(f"- 已筛选出 {paid_count} 条已支付订单")
# 4. 转换结果统计
print("n【转换结果总结】")
total_discount = df_transformed["discount_amount"].sum().round(2)
unique_months = sorted(df_transformed["order_month"].unique().tolist())
print(f"- 已支付订单数:{paid_count} 条")
print(f"- 优惠金额总计:{total_discount} 元")
print(f"- 涉及下单月份:{unique_months}")
# 5. 预览数据
print("n【转换后数据预览(前 3 条)】")
preview_fields = ["order_id", "user_id", "amount", "discount_amount", "order_time", "order_month", "pay_status"]
print(df_transformed[preview_fields].head(3).to_string(index=False))
print("n=== 订单数据计算与格式转换完成 ===")
return df_transformed
# 示例:使用前序场景的清洗后数据执行转换(实际使用时替换为真实数据)
if __name__ == "__main__":
# 构造模拟的清洗后数据
cleaned_data = {
"order_id": ["OD001", "OD002", "OD003", "OD004", "OD005"],
"user_id": ["U101", "未知用户_OD002", "U103", "未知用户_OD004", "U105"],
"amount": [299.9, 0.0, 10000.0, 899.5, 5000.0],
"order_time": ["2024-01-05 14:30:00", "2099-12-31 23:59:59", "2024-01-06 09:15:00", "2024-02-07 18:45:00", "2024-02-08 10:20:00"],
"pay_status": ["已支付", "未支付", "已支付", "已支付", "已支付"],
"amount_flag": ["正常", "异常-金额为负", "异常-超最高限额", "正常", "正常"]
}
df_cleaned = pd.DataFrame(cleaned_data)
# 执行转换
df_transformed = transform_calculate_format(df_cleaned)
3. 技巧点分析
-
计算逻辑清晰化:通过自定义函数
calculate_discount封装多条件优惠规则,比使用np.where嵌套更易读,后续修改优惠比例时仅需调整函数内部逻辑; -
时间处理专业化:使用 Pandas 的
dt属性(dt.strftime)提取月份,避免手动切割字符串(如split('-')),降低格式错误风险,同时将order_time转为 datetime 格式,为后续“按月份筛选数据”“计算订单间隔”等操作奠定基础; - 业务价值显性化:转换总结中突出业务关心的指标(已支付订单数、优惠总额、涉及月份),让非技术人员快速获取数据价值,无需查看完整数据集。
(三)场景 3:多表关联(订单表与用户表关联)
1. Prompt 指令
现有两个数据集:
1. 转换后的订单表(df_orders_transformed):字段包括 order_id、user_id、amount、discount_amount、order_time(datetime)、order_month、pay_status、amount_flag;
2. 用户表(df_users):字段包括 user_id(用户唯一标识)、user_name(用户名)、user_level(用户等级:普通/白银/黄金/钻石)、register_time(注册时间,字符串格式:YYYY-MM-DD)。
请生成 Python 代码完成以下多表关联操作:
1. 关联规则:
- 关联方式:内连接(INNER JOIN),仅保留“订单表.user_id = 用户表.user_id”的匹配数据(排除无对应用户的订单)
- 关联后删除重复的 user_id 字段(仅保留一个)
2. 新增派生字段:
- 新增“user_seniority”(用户资历,单位:天):计算“订单下单时间(order_time)- 用户注册时间(register_time)”的天数差(注:需先将 register_time 转为 datetime 格式)
- 新增“user_level_discount”(等级折扣):钻石用户额外折扣 5%,黄金用户额外折扣 3%,白银/普通用户无额外折扣(额外折扣基于“优惠后金额=amount - discount_amount”计算,即最终金额=优惠后金额×(1 - 等级折扣率),无需新增最终金额字段,仅标记等级折扣率)
3. 输出要求:
- 关联后的数据存入变量 df_joined
- 打印关联统计:“关联前订单数:X 条”“关联后订单数:Y 条”“关联成功比例:Z%(保留 1 位小数)”“各用户等级订单分布:字典,如 {'普通': 100, '白银': 50}”
- 预览前 2 条关联后的数据,显示关键字段:order_id、user_name、user_level、amount、discount_amount、user_level_discount、user_seniority
2. 预期输出(Python 代码)
import pandas as pd
import numpy as np
def transform_join_tables(df_orders_transformed: pd.DataFrame, df_users: pd.DataFrame) -> pd.DataFrame:
print("=== 开始订单表与用户表关联 ===")
# 1. 关联前统计
order_count_before = len(df_orders_transformed)
print(f"n【关联前统计】")
print(f"- 订单表数据量:{order_count_before} 条")
print(f"- 用户表数据量:{len(df_users)} 条")
# 2. 数据预处理:用户表 register_time 转为 datetime 格式
df_users_processed = df_users.copy()
df_users_processed["register_time"] = pd.to_datetime(df_users_processed["register_time"], format="%Y-%m-%d")
print(f"n【数据预处理】")
print(f"- 用户表 register_time 字段已转换为 datetime 格式")
# 3. 多表关联(内连接)
print(f"n【执行内连接】")
# 内连接:仅保留双方都有匹配的记录
df_joined = pd.merge(
left=df_orders_transformed,
right=df_users_processed,
on="user_id", # 关联键
how="inner",
suffixes=("", "_user") # 若有重复字段,右侧加后缀(本场景无重复,仅为兼容)
)
# 删除重复的 user_id 字段(若存在,实际内连接后仅一个 user_id)
if "user_id_user" in df_joined.columns:
df_joined.drop(columns=["user_id_user"], inplace=True)
# 关联后统计
order_count_after = len(df_joined)
join_success_rate = (order_count_after / order_count_before * 100) if order_count_before > 0 else 0.0
print(f"- 关联后订单数:{order_count_after} 条")
print(f"- 关联成功比例:{join_success_rate:.1f}%")
# 4. 新增派生字段
print(f"n【新增派生字段】")
# 4.1 计算 user_seniority(用户资历,天):order_time - register_time
df_joined["user_seniority"] = (df_joined["order_time"] - df_joined["register_time"]).dt.days
# 处理可能的负数值(订单时间早于注册时间,标记为 0)
df_joined.loc[df_joined["user_seniority"] < 0, "user_seniority"] = 0
print(f"- user_seniority 字段计算完成(用户资历,单位:天)")
# 4.2 计算 user_level_discount(等级折扣率)
def get_level_discount(level):
if level == "钻石":
return 0.05 # 5% 折扣
elif level == "黄金":
return 0.03 # 3% 折扣
else: # 普通、白银
return 0.00
df_joined["user_level_discount"] = df_joined["user_level"].apply(get_level_discount)
# 格式化为百分比字符串(便于阅读,保留 1 位小数)
df_joined["user_level_discount_str"] = df_joined["user_level_discount"].apply(lambda x: f"{x*100:.1f}%")
print(f"- user_level_discount 字段计算完成(等级折扣率)")
# 5. 关联后数据统计
print(f"n【关联后数据统计】")
# 各用户等级订单分布
level_distribution = df_joined["user_level"].value_counts().to_dict()
print(f"- 各用户等级订单分布:{level_distribution}")
# 平均用户资历
avg_seniority = df_joined["user_seniority"].mean().round(1)
print(f"- 下单用户平均资历:{avg_seniority} 天")
# 6. 数据预览
print(f"n【关联后数据预览(前 2 条)】")
preview_fields = [
"order_id", "user_name", "user_level", "amount",
"discount_amount", "user_level_discount_str", "user_seniority"
]
print(df_joined[preview_fields].head(2).to_string(index=False))
print("n=== 订单表与用户表关联完成 ===")
return df_joined
# 示例:构造模拟数据并执行关联(实际使用时替换为真实数据)
if __name__ == "__main__":
# 模拟转换后的订单表数据
orders_data = {
"order_id": ["OD001", "OD003", "OD004", "OD005"],
"user_id": ["U101", "U103", "U104", "U105"],
"amount": [299.90, 10000.00, 899.50, 5000.00],
"discount_amount": [0.00, 500.00, 0.00, 250.00],
"order_time": pd.to_datetime(["2024-01-05 14:30:00", "2024-01-06 09:15:00", "2024-02-07 18:45:00", "2024-02-08 10:20:00"]),
"order_month": ["2024-01", "2024-01", "2024-02", "2024-02"],
"pay_status": ["已支付", "已支付", "已支付", "已支付"],
"amount_flag": ["正常", "异常-超最高限额", "正常", "正常"]
}
df_orders_transformed = pd.DataFrame(orders_data)
# 模拟用户表数据
users_data = {
"user_id": ["U101", "U102", "U103", "U104", "U105"],
"user_name": ["张三", "李四", "王五", "赵六", "钱七"],
"user_level": ["普通", "白银", "黄金", "钻石", "黄金"],
"register_time": ["2023-10-01", "2023-11-15", "2023-09-20", "2023-05-01", "2023-08-10"]
}
df_users = pd.DataFrame(users_data)
# 执行关联
df_joined = transform_join_tables(df_orders_transformed, df_users)
3. 技巧点分析
-
关联稳定性:使用
pd.merge的on参数明确关联键,避免字段名不匹配导致的关联失败;通过suffixes参数处理潜在的重复字段,提升代码兼容性; -
异常值处理:计算
user_seniority时,将“订单时间早于注册时间”的异常值修正为 0,避免后续分析中出现负天数,符合业务逻辑(用户不可能在注册前下单); -
可读性优化:新增
user_level_discount_str字段,将折扣率(0.05)转为百分比字符串(5.0%),便于业务人员直接理解,同时保留原始数值字段(user_level_discount)供后续计算使用,兼顾“可读性”与“可计算性”。
五、加载阶段(Load)的 Prompt 实战
加载阶段需将转换后的数据写入目标存储,常见目标包括“文件存储(CSV/Parquet)”“数据库(MySQL/Hive)”“数据湖(S3/HDFS)”。以下为前两类目标的实战案例,重点展示 Prompt 如何定义写入规则与兼容性处理。
(一)场景 1:加载到 CSV/Parquet 文件(适合小批量数据)
1. Prompt 指令
现有关联后的订单数据(DataFrame 变量名:df_joined),需将其加载到文件存储,要求如下:
1. 加载目标:同时生成 CSV 文件和 Parquet 文件(Parquet 格式支持压缩,适合后续大数据分析工具读取);
2. 文件配置:
- 存储路径:./etl_output/(若目录不存在,需自动创建)
- 文件名规则:CSV 文件名为“orders_joined_YYYYMMDD.csv”,Parquet 文件名为“orders_joined_YYYYMMDD.parquet”(其中 YYYYMMDD 为当前日期,如 20240520)
- CSV 文件:编码为 UTF-8,包含表头,字段分隔符为逗号,缺失值用“NA”表示
- Parquet 文件:使用 Snappy 压缩算法(平衡压缩率与读取速度),保留 DataFrame 的数据类型
3. 加载校验:
- 写入完成后,读取文件的前 10 条数据,验证数据完整性(如字段数、关键字段值是否与源数据一致)
- 打印加载总结:“文件加载完成!”“CSV 文件路径:XXX”“Parquet 文件路径:XXX”“写入数据量:X 条”“校验结果:成功/失败(若失败,说明原因)”
4. 代码要求:包含目录创建逻辑、异常处理(如权限不足、磁盘空间不足)。
2. 预期输出(Python 代码)
import pandas as pd
import os
from datetime import datetime
import pyarrow as pa
import pyarrow.parquet as pq
def load_to_files(df_joined: pd.DataFrame) -> bool:
print("=== 开始将数据加载到文件 ===")
load_success = False
try:
# 1. 基础配置
current_date = datetime.now().strftime("%Y%m%d") # 当前日期:YYYYMMDD
output_dir = "./etl_output/"
csv_filename = f"orders_joined_{current_date}.csv"
parquet_filename = f"orders_joined_{current_date}.parquet"
csv_path = os.path.join(output_dir, csv_filename)
parquet_path = os.path.join(output_dir, parquet_filename)
data_count = len(df_joined)
print(f"n【加载配置】")
print(f"- 输出目录:{output_dir}")
print(f"- CSV 文件路径:{csv_path}")
print(f"- Parquet 文件路径:{parquet_path}")
print(f"- 待写入数据量:{data_count} 条")
# 2. 创建输出目录(若不存在)
if not os.path.exists(output_dir):
os.makedirs(output_dir, exist_ok=True)
print(f"n【目录处理】")
print(f"- 输出目录不存在,已自动创建:{output_dir}")
# 3. 加载到 CSV 文件
print(f"n【加载 CSV 文件】")
df_joined.to_csv(
path_or_buf=csv_path,
index=False, # 不保留索引
encoding="utf-8",
na_rep="NA", # 缺失值用“NA”表示
sep="," # 字段分隔符
)
print(f"- CSV 文件写入完成,文件大小:{os.path.getsize(csv_path) / 1024:.1f} KB")
# 4. 加载到 Parquet 文件(Snappy 压缩)
print(f"n【加载 Parquet 文件】")
# 将 DataFrame 转为 PyArrow Table(便于设置压缩格式)
table = pa.Table.from_pandas(df_joined)
pq.write_to_dataset(
table,
root_path=parquet_path,
compression="snappy", # Snappy 压缩
overwrite=True # 若文件已存在,覆盖
)
# 计算 Parquet 文件大小(需遍历目录,因 Parquet 可能分块存储)
parquet_size = 0
for root, dirs, files in os.walk(parquet_path):
for file in files:
parquet_size += os.path.getsize(os.path.join(root, file))
print(f"- Parquet 文件写入完成,文件大小:{parquet_size / 1024:.1f} KB")
# 5. 加载校验
print(f"n【加载校验】")
# 5.1 校验 CSV 文件
csv_check = pd.read_csv(csv_path, nrows=10) # 读取前 10 条
csv_valid = (len(csv_check) == 10) and (len(csv_check.columns) == len(df_joined.columns))
# 5.2 校验 Parquet 文件
parquet_check = pq.read_table(parquet_path).to_pandas().head(10) # 读取前 10 条
parquet_valid = (len(parquet_check) == 10) and (len(parquet_check.columns) == len(df_joined.columns))
# 5.3 校验结果判断
if csv_valid and parquet_valid:
print(f"- CSV 文件校验:成功(字段数:{len(csv_check.columns)},匹配源数据)")
print(f"- Parquet 文件校验:成功(字段数:{len(parquet_check.columns)},匹配源数据)")
print(f"- 数据量校验:源数据 {data_count} 条,文件写入正常")
load_success = True
else:
raise Exception(f"文件校验失败:CSV 校验{'成功' if csv_valid else '失败'},Parquet 校验{'成功' if parquet_valid else '失败'}")
# 6. 加载总结
print(f"n【加载总结】")
print(f"文件加载完成!")
print(f"- CSV 文件路径:{csv_path}")
print(f"- Parquet 文件路径:{parquet_path}")
print(f"- 写入数据量:{data_count} 条")
print(f"- 校验结果:成功")
except Exception as e:
print(f"n【加载失败】")
print(f"错误原因:{str(e)}")
# 清理已生成的不完整文件
if os.path.exists(csv_path):
os.remove(csv_path)
print(f"- 已清理不完整 CSV 文件:{csv_path}")
if os.path.exists(parquet_path):
import shutil
shutil.rmtree(parquet_path)
print(f"- 已清理不完整 Parquet 文件:{parquet_path}")
print("n=== 数据加载到文件流程结束 ===")
return load_success
# 示例:使用前序场景的关联数据执行加载(实际使用时替换为真实数据)
if __name__ == "__main__":
# 构造模拟的关联后数据(省略复杂字段,仅保留关键信息)
joined_data = {
"order_id": ["OD001", "OD003", "OD004", "OD005"],
"user_id": ["U101", "U103", "U104", "U105"],
"user_name": ["张三", "王五", "赵六", "钱七"],
"user_level": ["普通", "黄金", "钻石", "黄金"],
"amount": [299.90, 10000.00, 899.50, 5000.00],
"discount_amount": [0.00, 500.00, 0.00, 250.00],
"user_level_discount": [0.00, 0.03, 0.05, 0.03],
"user_level_discount_str": ["0.0%", "3.0%", "5.0%", "3.0%"],
"order_time": pd.to_datetime(["2024-01-05 14:30:00", "2024-01-06 09:15:00", "2024-02-07 18:45:00", "2024-02-08 10:20:00"]),
"register_time": pd.to_datetime(["2023-10-01", "2023-09-20", "2023-05-01", "2023-08-10"]),
"user_seniority": [96, 108, 282, 181],
"order_month": ["2024-01", "2024-01", "2024-02", "2024-02"],
"pay_status": ["已支付", "已支付", "已支付", "已支付"],
"amount_flag": ["正常", "异常-超最高限额", "正常", "正常"]
}
df_joined = pd.DataFrame(joined_data)
# 执行加载
load_result = load_to_files(df_joined)
3. 技巧点分析
- 格式兼容性:同时生成 CSV(人类可读,适合小批量数据查看)和 Parquet(压缩率高,适合 Spark、Hive 等大数据工具读取),兼顾“人工验证”与“后续分析”需求;
- 容错机制:包含“目录自动创建”“文件覆盖”“失败清理”逻辑——目录不存在时自动创建,避免手动操作;文件已存在时覆盖,适合定时执行 ETL 任务;加载失败时清理不完整文件,避免脏数据残留;
- 校验闭环:写入后读取前 10 条数据,验证“字段数”“数据完整性”,确保文件可正常使用,降低后续分析时的“数据损坏”风险。
(二)场景 2:加载到 MySQL 数据库(适合结构化数据存储)
1. Prompt 指令
现有关联后的订单数据(DataFrame 变量名:df_joined),需加载到 MySQL 数据库的“ecommerce_etl”库中,要求如下:
1. 数据库配置:
- 数据库地址:192.168.1.100,端口:3306,数据库名:ecommerce_etl,用户名:etl_user,密码:etl_password(均设为变量,方便替换)
- 目标表名:orders_joined(若表不存在,需自动创建;若表已存在,清空表中数据后再插入新数据,避免重复)
2. 表结构要求:
- 字段类型匹配 DataFrame 数据类型:
- order_id、user_id、user_name、user_level、user_level_discount_str、order_month、pay_status、amount_flag:VARCHAR 类型(长度分别为 20、20、50、10、10、7、10、20)
- amount、discount_amount、user_level_discount:DECIMAL 类型(精度 10,2,即整数位 8 位,小数位 2 位)
- order_time、register_time:DATETIME 类型
- user_seniority:INT 类型
- 主键:order_id(唯一标识订单)
3. 加载优化:
- 使用批量插入(chunk_size=1000),避免单条插入导致的性能问题
- 关闭自动提交(autocommit=False),插入完成后统一提交,提升效率
4. 加载校验:
- 插入完成后,查询目标表的总行数,与源数据行数对比(一致则校验成功)
- 打印加载总结:“MySQL 加载完成!”“目标表:ecommerce_etl.orders_joined”“插入数据量:X 条”“校验结果:成功/失败(行数是否一致)”
5. 代码要求:包含异常处理(连接失败、插入报错)、数据库连接关闭逻辑。
2. 预期输出(Python 代码)
import pandas as pd
import pymysql
from sqlalchemy import create_engine
from sqlalchemy.exc import SQLAlchemyError
def load_to_mysql(df_joined: pd.DataFrame) -> bool:
print("=== 开始将数据加载到 MySQL 数据库 ===")
load_success = False
engine = None
try:
# 1. 数据库配置(需替换为实际配置)
db_config = {
"host": "192.168.1.100",
"port": 3306,
"db": "ecommerce_etl",
"user": "etl_user",
"password": "etl_password",
"charset": "utf8mb4"
}
table_name = "orders_joined"
data_count = len(df_joined)
print(f"n【加载配置】")
print(f"- 目标数据库:{db_config['db']}")
print(f"- 目标表:{table_name}")
print(f"- 待插入数据量:{data_count} 条")
print(f"- 批量插入大小:1000 条/批次")
# 2. 创建数据库连接(使用 SQLAlchemy 引擎,支持 Pandas to_sql)
# 构造连接字符串:mysql+pymysql://user:password@host:port/db
conn_str = f"mysql+pymysql://{db_config['user']}:{db_config['password']}@{db_config['host']}:{db_config['port']}/{db_config['db']}?charset={db_config['charset']}"
engine = create_engine(conn_str)
print(f"n【数据库连接】")
print(f"- 连接成功:{db_config['host']}:{db_config['port']}/{db_config['db']}")
# 3. 表结构定义(SQL 语句,若表不存在则创建)
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
order_id VARCHAR(20) NOT NULL COMMENT '订单ID',
user_id VARCHAR(20) NOT NULL COMMENT '用户ID',
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
user_level VARCHAR(10) NOT NULL COMMENT '用户等级',
amount DECIMAL(10,2) NOT NULL COMMENT '订单金额(元)',
discount_amount DECIMAL(10,2) NOT NULL COMMENT '优惠金额(元)',
user_level_discount DECIMAL(10,2) NOT NULL COMMENT '等级折扣率',
user_level_discount_str VARCHAR(10) NOT NULL COMMENT '等级折扣率(字符串)',
order_time DATETIME NOT NULL COMMENT '下单时间',
register_time DATETIME NOT NULL COMMENT '用户注册时间',
user_seniority INT NOT NULL COMMENT '用户资历(天)',
order_month VARCHAR(7) NOT NULL COMMENT '下单月份(YYYY-MM)',
pay_status VARCHAR(10) NOT NULL COMMENT '支付状态',
amount_flag VARCHAR(20) NOT NULL COMMENT '金额状态标记',
PRIMARY KEY (order_id) COMMENT '订单ID为主键'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='ETL 关联后的订单表';
"""
# 执行创建表语句
with engine.connect() as conn:
conn.execute(create_table_sql)
print(f"n【表结构处理】")
print(f"- 目标表 {table_name} 检查完成(不存在则已创建)")
# 4. 清空表中现有数据(避免重复)
truncate_sql = f"TRUNCATE TABLE {table_name};"
with engine.connect() as conn:
conn.execute(truncate_sql)
print(f"- 目标表 {table_name} 现有数据已清空")
# 5. 批量插入数据
print(f"n【批量插入数据】")
# 使用 Pandas to_sql 方法,关闭自动提交,批量插入
df_joined.to_sql(
name=table_name,
con=engine,
if_exists="append", # 追加模式(因已清空表,等同于覆盖)
index=False, # 不插入 DataFrame 索引
chunksize=1000, # 批量插入大小
method="multi" # 多值插入(提升效率)
)
print(f"- 数据插入完成,共插入 {data_count} 条数据({data_count // 1000 + 1} 批次)")
# 6. 加载校验(对比源数据与表中数据行数)
print(f"n【加载校验】")
# 查询目标表总行数
count_sql = f"SELECT COUNT(*) AS total FROM {table_name};"
with engine.connect() as conn:
result = conn.execute(count_sql).fetchone()
db_count = result["total"]
if db_count == data_count:
print(f"- 行数校验:成功(源数据 {data_count} 条,表中 {db_count} 条,一致)")
load_success = True
else:
raise Exception(f"行数校验失败:源数据 {data_count} 条,表中 {db_count} 条,不一致")
# 7. 加载总结
print(f"n【加载总结】")
print(f"MySQL 加载完成!")
print(f"- 目标数据库:{db_config['db']}")
print(f"- 目标表:{table_name}")
print(f"- 插入数据量:{data_count} 条")
print(f"- 校验结果:成功")
except SQLAlchemyError as e:
print(f"n【加载失败(数据库错误)】")
print(f"错误原因:{str(e)}")
except Exception as e:
print(f"n【加载失败(其他错误)】")
print(f"错误原因:{str(e)}")
finally:
# 关闭数据库连接
if engine is not None:
engine.dispose()
print(f"n【数据库连接】")
print(f"- 连接已关闭")
print("n=== 数据加载到 MySQL 流程结束 ===")
return load_success
# 示例:使用前序场景的关联数据执行加载(实际使用时替换为真实数据)
if __name__ == "__main__":
# 构造模拟的关联后数据(与文件加载场景一致)
joined_data = {
"order_id": ["OD001", "OD003", "OD004", "OD005"],
"user_id": ["U101", "U103", "U104", "U105"],
"user_name": ["张三", "王五", "赵六", "钱七"],
"user_level": ["普通", "黄金", "钻石", "黄金"],
"amount": [299.90, 10000.00, 899.50, 5000.00],
"discount_amount": [0.00, 500.00, 0.00, 250.00],
"user_level_discount": [0.00, 0.03, 0.05, 0.03],
"user_level_discount_str": ["0.0%", "3.0%", "5.0%", "3.0%"],
"order_time": pd.to_datetime(["2024-01-05 14:30:00", "2024-01-06 09:15:00", "2024-02-07 18:45:00", "2024-02-08 10:20:00"]),
"register_time": pd.to_datetime(["2023-10-01", "2023-09-20", "2023-05-01", "2023-08-10"]),
"user_seniority": [96, 108, 282, 181],
"order_month": ["2024-01", "2024-01", "2024-02", "2024-02"],
"pay_status": ["已支付", "已支付", "已支付", "已支付"],
"amount_flag": ["正常", "异常-超最高限额", "正常", "正常"]
}
df_joined = pd.DataFrame(joined_data)
# 执行加载
load_result = load_to_mysql(df_joined)
3. 技巧点分析
- 表结构可控性:通过自定义 SQL 语句创建表,明确字段类型、长度、注释与主键,避免 Pandas 自动推断类型导致的兼容性问题(如将 VARCHAR 推断为 TEXT,浪费存储空间);
- 性能优化:使用“批量插入(chunksize=1000)+ 多值插入(method=‘multi’)”,相比单条插入效率提升 10-100 倍;关闭自动提交,统一提交事务,减少数据库 IO 次数;
- 数据一致性:加载前清空表数据(TRUNCATE),避免新旧数据重复;加载后对比“源数据行数”与“表中行数”,确保数据完全插入,符合生产环境对“数据一致性”的要求。
六、Prompt 引导 ETL 自动化的完整流程与模板
将抽取、转换、加载三阶段的 Prompt 逻辑整合,形成完整的 ETL 自动化流程,并封装为可复用的 Prompt 模板,便于后续同类场景快速调用。
(一)完整 ETL 流程的 Prompt 模板
请作为数据工程师,生成一套完整的 ETL 自动化 Python 代码,处理“电商订单数据”,具体要求如下:
### 一、数据源信息
1. 订单数据源:MySQL 数据库
- 配置:地址=192.168.1.100,端口=3306,库名=ecommerce_raw,表名=orders,用户名=raw_user,密码=raw_password
- 需抽取字段:order_id, user_id, amount, order_time(字符串:YYYY-MM-DD HH:MM:SS), pay_status, product_id
- 筛选条件:order_time ≥ '2024-01-01 00:00:00' AND pay_status IN ('已支付', '未支付')
2. 用户数据源:CSV 文件
- 路径:./data/users.csv
- 字段:user_id, user_name, user_level(普通/白银/黄金/钻石), register_time(字符串:YYYY-MM-DD)
- 编码:UTF-8,分隔符:逗号
### 二、ETL 各阶段要求
#### (一)抽取阶段(Extract)
1. 抽取 MySQL 订单数据:分批读取(1000 条/批),包含异常处理(连接失败、查询超时)
2. 抽取 CSV 用户数据:处理缺失值(user_name 缺失用“未知用户”填充)
3. 抽取后输出统计:各数据源抽取行数、数据预览(前 5 条)
#### (二)转换阶段(Transform)
1. 数据清洗:
- 订单数据:amount < 0 修正为 0,order_time 缺失填充为 '2099-12-31 23:59:59'
- 用户数据:register_time 转换为 datetime 格式
2. 字段计算:
- 订单数据:新增“discount”(优惠金额):amount ≥ 5000 → 5% of amount;1000 ≤ amount <5000 → 2% of amount;else → 0
- 关联后数据:新增“user_seniority”(用户资历,天)= order_time - register_time(异常值≤0 修正为 0)
3. 多表关联:
- 方式:内连接(订单表.user_id = 用户表.user_id)
- 保留字段:order_id, user_id, user_name, user_level, amount, discount, order_time, register_time, user_seniority, pay_status, product_id
4. 数据筛选:仅保留 pay_status='已支付' 的数据
#### (三)加载阶段(Load)
1. 目标存储:MySQL 数据库(库名=ecommerce_etl,表名=orders_etl_result,用户名=etl_user,密码=etl_password)
2. 表结构:
- 字段类型:order_id(VARCHAR20), user_id(VARCHAR20), user_name(VARCHAR50), user_level(VARCHAR10), amount(DECIMAL10,2), discount(DECIMAL10,2), order_time(DATETIME), register_time(DATETIME), user_seniority(INT), pay_status(VARCHAR10), product_id(VARCHAR20)
- 主键:order_id
3. 加载策略:表不存在则创建,表存在则清空后插入,批量插入(1000 条/批)
4. 加载校验:插入行数与源数据行数一致,预览前 5 条数据
### 三、代码输出要求
1. 生成完整 Python 代码,包含函数封装(extract/transform/load)、异常处理、日志打印
2. 代码中敏感信息(用户名、密码)设为变量,方便替换
3. 输出 ETL 流程总结:总耗时、各阶段处理行数、校验结果
4. 代码可直接运行,无需修改逻辑(仅需替换变量)
(二)完整 ETL 流程的 Python 代码(基于模板生成)
import pandas as pd
import pymysql
import os
import time
from datetime import datetime
from sqlalchemy import create_engine
from sqlalchemy.exc import SQLAlchemyError
# ====================== 全局配置(需根据实际环境替换)======================
# 1. 订单数据源(MySQL)配置
ORDER_DB_CONFIG = {
"host": "192.168.1.100",
"port":3306,
"db": "ecommerce_raw",
"table": "orders",
"user": "raw_user",
"password": "raw_password",
"charset": "utf8mb4"
}
# 2. 用户数据源(CSV)配置
USER_CSV_CONFIG = {
"path": "./data/users.csv",
"encoding": "UTF-8",
"sep": ","
}
# 3. 目标存储(MySQL)配置
TARGET_DB_CONFIG = {
"host": "192.168.1.100",
"port": 3306,
"db": "ecommerce_etl",
"table": "orders_etl_result",
"user": "etl_user",
"password": "etl_password",
"charset": "utf8mb4"
}
# 4. 通用配置
BATCH_SIZE = 1000 # 分批处理大小
ORDER_TIME_FILTER = "2024-01-01 00:00:00" # 订单时间筛选条件
# ====================== 1. 抽取阶段(Extract)======================
def extract_order_data() -> pd.DataFrame:
"""从 MySQL 抽取订单数据"""
print("=== 开始抽取订单数据(MySQL)===")
start_time = time.time()
all_orders = []
offset = 0
try:
# 建立数据库连接
conn = pymysql.connect(
host=ORDER_DB_CONFIG["host"],
port=ORDER_DB_CONFIG["port"],
user=ORDER_DB_CONFIG["user"],
password=ORDER_DB_CONFIG["password"],
db=ORDER_DB_CONFIG["db"],
charset=ORDER_DB_CONFIG["charset"],
cursorclass=pymysql.cursors.DictCursor
)
cursor = conn.cursor()
print(f"成功连接到订单数据库:{ORDER_DB_CONFIG['host']}/{ORDER_DB_CONFIG['db']}")
# 1. 查询符合条件的总数据量
count_sql = f"""
SELECT COUNT(*) AS total
FROM {ORDER_DB_CONFIG['table']}
WHERE order_time >= '{ORDER_TIME_FILTER}'
AND pay_status IN ('已支付', '未支付')
"""
cursor.execute(count_sql)
total_count = cursor.fetchone()["total"]
print(f"符合条件的订单总数:{total_count} 条")
# 2. 分批抽取数据
while offset < total_count:
extract_sql = f"""
SELECT order_id, user_id, amount, order_time, pay_status, product_id
FROM {ORDER_DB_CONFIG['table']}
WHERE order_time >= '{ORDER_TIME_FILTER}'
AND pay_status IN ('已支付', '未支付')
LIMIT {BATCH_SIZE} OFFSET {offset}
"""
cursor.execute(extract_sql)
batch_data = cursor.fetchall()
all_orders.extend(batch_data)
print(f"已抽取:{len(all_orders)}/{total_count} 条")
offset += BATCH_SIZE
# 3. 数据预览
df_orders = pd.DataFrame(all_orders)
print(f"n订单数据预览(前 5 条):")
print(df_orders.head().to_string(index=False))
# 4. 抽取统计
end_time = time.time()
print(f"n=== 订单数据抽取完成 ===")
print(f"抽取耗时:{end_time - start_time:.2f} 秒")
print(f"最终抽取数据量:{len(df_orders)} 条n")
return df_orders
except Exception as e:
print(f"订单数据抽取失败:{str(e)}")
raise # 抛出异常,终止后续流程
finally:
# 关闭连接
if "cursor" in locals():
cursor.close()
if "conn" in locals() and conn.open:
conn.close()
print("订单数据库连接已关闭")
def extract_user_data() -> pd.DataFrame:
"""从 CSV 抽取用户数据"""
print("=== 开始抽取用户数据(CSV)===")
start_time = time.time()
try:
# 检查文件是否存在
if not os.path.exists(USER_CSV_CONFIG["path"]):
raise FileNotFoundError(f"用户 CSV 文件不存在:{USER_CSV_CONFIG['path']}")
# 读取 CSV 文件
df_users = pd.read_csv(
filepath_or_buffer=USER_CSV_CONFIG["path"],
encoding=USER_CSV_CONFIG["encoding"],
sep=USER_CSV_CONFIG["sep"]
)
print(f"成功读取用户 CSV 文件,初始数据量:{len(df_users)} 条")
# 处理缺失值(user_name 缺失用“未知用户”填充)
missing_user_name = df_users["user_name"].isnull().sum()
if missing_user_name > 0:
df_users["user_name"].fillna("未知用户", inplace=True)
print(f"处理 user_name 缺失值:{missing_user_name} 条,填充为'未知用户'")
# 数据预览
print(f"n用户数据预览(前 5 条):")
print(df_users.head().to_string(index=False))
# 抽取统计
end_time = time.time()
print(f"n=== 用户数据抽取完成 ===")
print(f"抽取耗时:{end_time - start_time:.2f} 秒")
print(f"最终抽取数据量:{len(df_users)} 条n")
return df_users
except Exception as e:
print(f"用户数据抽取失败:{str(e)}")
raise
# ====================== 2. 转换阶段(Transform)======================
def transform_data(df_orders: pd.DataFrame, df_users: pd.DataFrame) -> pd.DataFrame:
"""数据转换:清洗、计算、关联、筛选"""
print("=== 开始数据转换阶段 ===")
start_time = time.time()
# 1. 订单数据清洗
print("n【步骤 1:订单数据清洗】")
df_orders_clean = df_orders.copy()
# 1.1 处理 amount 异常值(<0 修正为 0)
abnormal_amount = len(df_orders_clean[df_orders_clean["amount"] < 0])
if abnormal_amount > 0:
df_orders_clean.loc[df_orders_clean["amount"] < 0, "amount"] = 0
print(f"- 修正 amount < 0 的异常值:{abnormal_amount} 条")
# 1.2 处理 order_time 缺失值(填充为 '2099-12-31 23:59:59')
missing_order_time = df_orders_clean["order_time"].isnull().sum()
if missing_order_time > 0:
df_orders_clean["order_time"].fillna("2099-12-31 23:59:59", inplace=True)
print(f"- 处理 order_time 缺失值:{missing_order_time} 条,填充为'2099-12-31 23:59:59'")
# 1.3 转换 order_time 为 datetime 格式
df_orders_clean["order_time"] = pd.to_datetime(df_orders_clean["order_time"], format="%Y-%m-%d %H:%M:%S")
print(f"- 转换 order_time 为 datetime 格式")
# 2. 用户数据清洗(转换 register_time 为 datetime)
print("n【步骤 2:用户数据清洗】")
df_users_clean = df_users.copy()
df_users_clean["register_time"] = pd.to_datetime(df_users_clean["register_time"], format="%Y-%m-%d")
print(f"- 转换 register_time 为 datetime 格式")
# 3. 订单数据字段计算(新增 discount 优惠金额)
print("n【步骤 3:字段计算(新增优惠金额 discount)】")
def calculate_discount(amount):
if amount >= 5000:
return round(amount * 0.05, 2)
elif 1000 <= amount < 5000:
return round(amount * 0.02, 2)
else:
return 0.00
df_orders_clean["discount"] = df_orders_clean["amount"].apply(calculate_discount)
print(f"- 优惠金额计算完成,示例:")
print(df_orders_clean[["amount", "discount"]].head(3).to_string(index=False))
# 4. 多表关联(内连接:订单表 + 用户表)
print("n【步骤 4:多表内连接】")
df_joined = pd.merge(
left=df_orders_clean,
right=df_users_clean,
on="user_id",
how="inner",
suffixes=("", "_user")
)
# 删除重复字段(若存在)
if "user_id_user" in df_joined.columns:
df_joined.drop(columns=["user_id_user"], inplace=True)
print(f"- 关联前订单数:{len(df_orders_clean)} 条")
print(f"- 关联后订单数:{len(df_joined)} 条(仅保留有匹配用户的订单)")
# 5. 关联后字段计算(新增 user_seniority 用户资历)
print("n【步骤 5:关联后字段计算(用户资历)】")
df_joined["user_seniority"] = (df_joined["order_time"] - df_joined["register_time"]).dt.days
# 修正异常值(≤0 修正为 0)
abnormal_seniority = len(df_joined[df_joined["user_seniority"] < 0])
if abnormal_seniority > 0:
df_joined.loc[df_joined["user_seniority"] < 0, "user_seniority"] = 0
print(f"- 修正用户资历异常值(<0):{abnormal_seniority} 条,填充为 0")
print(f"- 用户资历计算完成,示例:")
print(df_joined[["user_name", "register_time", "order_time", "user_seniority"]].head(3).to_string(index=False))
# 6. 数据筛选(仅保留已支付订单)
print("n【步骤 6:数据筛选(仅保留已支付订单)】")
df_filtered = df_joined[df_joined["pay_status"] == "已支付"].reset_index(drop=True)
print(f"- 筛选前订单数:{len(df_joined)} 条")
print(f"- 筛选后订单数:{len(df_filtered)} 条(已支付订单)")
# 7. 保留目标字段(按需求筛选最终字段)
target_fields = [
"order_id", "user_id", "user_name", "user_level",
"amount", "discount", "order_time", "register_time",
"user_seniority", "pay_status", "product_id"
]
df_transformed = df_filtered[target_fields].copy()
# 转换阶段统计
end_time = time.time()
print(f"n=== 数据转换阶段完成 ===")
print(f"转换耗时:{end_time - start_time:.2f} 秒")
print(f"最终转换后数据量:{len(df_transformed)} 条")
print(f"转换后数据预览(前 3 条):")
print(df_transformed.head(3).to_string(index=False))
return df_transformed
# ====================== 3. 加载阶段(Load)======================
def load_data(df_transformed: pd.DataFrame) -> None:
"""将转换后的数据加载到目标 MySQL 数据库"""
print("n=== 开始数据加载阶段 ===")
start_time = time.time()
engine = None
try:
# 1. 创建目标数据库连接(SQLAlchemy 引擎)
conn_str = f"mysql+pymysql://{TARGET_DB_CONFIG['user']}:{TARGET_DB_CONFIG['password']}@{TARGET_DB_CONFIG['host']}:{TARGET_DB_CONFIG['port']}/{TARGET_DB_CONFIG['db']}?charset={TARGET_DB_CONFIG['charset']}"
engine = create_engine(conn_str)
print(f"成功连接到目标数据库:{TARGET_DB_CONFIG['host']}/{TARGET_DB_CONFIG['db']}")
# 2. 创建目标表(若不存在)
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {TARGET_DB_CONFIG['table']} (
order_id VARCHAR(20) NOT NULL COMMENT '订单ID',
user_id VARCHAR(20) NOT NULL COMMENT '用户ID',
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
user_level VARCHAR(10) NOT NULL COMMENT '用户等级',
amount DECIMAL(10,2) NOT NULL COMMENT '订单金额(元)',
discount DECIMAL(10,2) NOT NULL COMMENT '优惠金额(元)',
order_time DATETIME NOT NULL COMMENT '下单时间',
register_time DATETIME NOT NULL COMMENT '用户注册时间',
user_seniority INT NOT NULL COMMENT '用户资历(天)',
pay_status VARCHAR(10) NOT NULL COMMENT '支付状态',
product_id VARCHAR(20) NOT NULL COMMENT '商品ID',
PRIMARY KEY (order_id) COMMENT '订单ID为主键'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='ETL 处理后的电商订单结果表';
"""
with engine.connect() as conn:
conn.execute(create_table_sql)
print(f"目标表 {TARGET_DB_CONFIG['table']} 检查完成(不存在则已创建)")
# 3. 清空目标表现有数据(避免重复)
truncate_sql = f"TRUNCATE TABLE {TARGET_DB_CONFIG['table']};"
with engine.connect() as conn:
conn.execute(truncate_sql)
print(f"目标表 {TARGET_DB_CONFIG['table']} 现有数据已清空")
# 4. 批量插入数据
print(f"n开始批量插入数据(每批 {BATCH_SIZE} 条)")
df_transformed.to_sql(
name=TARGET_DB_CONFIG["table"],
con=engine,
if_exists="append",
index=False,
chunksize=BATCH_SIZE,
method="multi"
)
print(f"数据插入完成,共插入 {len(df_transformed)} 条")
# 5. 加载校验(对比行数)
print("n【加载校验】")
# 查询目标表行数
count_sql = f"SELECT COUNT(*) AS total FROM {TARGET_DB_CONFIG['table']};"
with engine.connect() as conn:
result = conn.execute(count_sql).fetchone()
db_count = result["total"]
if db_count == len(df_transformed):
print(f"行数校验成功:源数据 {len(df_transformed)} 条,目标表 {db_count} 条,一致")
else:
raise Exception(f"行数校验失败:源数据 {len(df_transformed)} 条,目标表 {db_count} 条,不一致")
# 加载阶段统计
end_time = time.time()
print(f"n=== 数据加载阶段完成 ===")
print(f"加载耗时:{end_time - start_time:.2f} 秒")
except SQLAlchemyError as e:
print(f"数据库加载错误:{str(e)}")
raise
except Exception as e:
print(f"数据加载失败:{str(e)}")
raise
finally:
# 关闭数据库连接
if engine is not None:
engine.dispose()
print(f"目标数据库连接已关闭")
# ====================== 完整 ETL 流程执行 =======================
def run_full_etl() -> None:
"""执行完整的 ETL 流程"""
print("=" * 60)
print(" 开始电商订单数据 ETL 自动化流程 ")
print("=" * 60)
full_start_time = time.time()
try:
# 1. 抽取阶段
df_orders = extract_order_data()
df_users = extract_user_data()
# 2. 转换阶段
df_transformed = transform_data(df_orders, df_users)
# 3. 加载阶段
load_data(df_transformed)
# 完整流程统计
full_end_time = time.time()
print("n" + "=" * 60)
print(" 电商订单数据 ETL 自动化流程完成 ")
print("=" * 60)
print(f"总耗时:{full_end_time - full_start_time:.2f} 秒")
print(f"最终成果:{len(df_transformed)} 条已支付订单数据加载至目标表")
print(f"目标表路径:{TARGET_DB_CONFIG['host']}/{TARGET_DB_CONFIG['db']}.{TARGET_DB_CONFIG['table']}")
print("=" * 60)
except Exception as e:
print(f"nETL 流程异常终止:{str(e)}")
print("请检查数据源配置、网络连接或数据格式后重试")
# 执行完整 ETL 流程
if __name__ == "__main__":
run_full_etl()
七、Prompt 引导 ETL 自动化的优势与注意事项
(一)核心优势
- 降低技术门槛:非技术人员(如业务分析师)无需掌握 SQL、Python 或 ETL 工具,通过自然语言即可定义 ETL 规则,实现“业务驱动数据处理”;
- 提升迭代效率:当业务规则变化(如优惠比例调整、筛选条件修改)时,仅需修改 Prompt 中的指令,无需重构代码,迭代周期从“天级”压缩至“分钟级”;
- 场景适配灵活:对于半结构化数据(如日志、API 响应)或小众数据源(如自定义 Excel 模板),传统 ETL 工具需复杂配置,而 Prompt 可直接定义解析规则,适配性更强;
- 代码可复用性:通过“Prompt 模板+变量替换”,同类 ETL 场景(如“每月订单数据处理”“不同区域用户数据整合”)可快速复用代码,减少重复开发。
(二)关键注意事项
-
敏感信息保护:在 Prompt 中避免直接填写数据库密码、API 密钥等敏感信息,需通过“变量占位符”(如
{db_password})或环境变量方式传入,防止泄露; - 数据质量校验:LLM 生成的 ETL 代码可能存在逻辑漏洞(如异常值处理遗漏、关联条件错误),必须在实际运行前通过“小批量测试数据”验证,确保数据处理结果符合预期;
-
性能优化边界:Prompt 生成的代码默认优先保证“正确性”与“可读性”,对于超大规模数据(如亿级订单),需手动优化批量处理大小(
chunk_size)、索引设计或并行策略,避免性能瓶颈; - 模型选型适配:不同大语言模型对 ETL 场景的支持能力不同——ChatGPT-4、Claude-3 等模型生成的代码逻辑更严谨,适合复杂 ETL 流程;开源模型(如 Qwen-7B)需搭配“Few-Shot 示例”(如提供 1-2 个简单数据清洗代码示例),才能提升输出质量。
八、课后练习与实战任务
(一)基础练习
- 任务描述:基于本文中的“Prompt 引导 ETL 流程”,修改 Prompt 指令,实现“从 CSV 订单数据中抽取 2024 年 2 月的未支付订单,清洗金额异常值(>5000 标记为‘待审核’),并加载到 Excel 文件”;
-
要求:
- 抽取条件:
order_time介于 2024-02-01 至 2024-02-29,pay_status='未支付'; - 数据清洗:
amount > 5000时,新增amount_check='待审核',否则为'正常'; - 加载目标:Excel 文件(路径
./output/unpaid_orders_feb2024.xlsx),包含表头与数据筛选功能。
- 抽取条件:
(二)进阶实战
- 任务描述:设计 Prompt 并生成代码,实现“多数据源(MySQL 订单表 + API 用户表 + CSV 商品表)的 ETL 自动化,最终加载到 Hive 数据仓库”;
-
核心要求:
- 数据源 1(MySQL 订单表):抽取 2024 年 Q1 数据,包含
order_id, user_id, product_id, amount, order_time; - 数据源 2(API 用户表):调用
https://api.ecommerce.com/v1/users,获取user_id, user_name, region,处理 API 分页与重试; - 数据源 3(CSV 商品表):读取
./data/products.csv,包含product_id, product_name, category; - 转换规则:三表通过
user_id(订单-用户)、product_id(订单-商品)关联,新增order_category(商品分类)、order_region(用户区域); - 加载目标:Hive 表
ecommerce.order_q1_2024,分区字段为order_month(YYYY-MM)。
- 数据源 1(MySQL 订单表):抽取 2024 年 Q1 数据,包含
通过以上练习,可深入掌握 Prompt 与 ETL 流程的结合逻辑,逐步实现从“手动编写 ETL 代码”到“自然语言驱动自动化”的转型,大幅提升数据处理效率。
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注:本文撰写于CSDN平台,作者:xcLeigh(所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌
© 版权声明
文章版权归作者所有,未经允许请勿转载。