
当 IoT 遇上大数据:为什么顶尖架构师都在押注 Apache IoTDB?
文章目录
-
- 一、引言:时序数据时代的数据库选型困境
- 二、时序数据库的核心特性与选型维度
-
- 2.1 什么是时序数据库
- 2.2 时序数据库选型的关键维度
-
- 2.2.1 写入性能
- 2.2.2 存储效率
- 2.2.3 查询能力
- 2.2.4 分布式架构
- 2.2.5 生态兼容性
- 三、主流时序数据库技术对比
-
- 3.1 国际主流产品分析
- 3.2 国产时序数据库的崛起
- 四、Apache IoTDB 深度解析
-
- 4.1 项目背景与发展历程
- 4.2 核心架构设计
-
- 4.2.1 TsFile 存储引擎
- 4.2.2 分布式架构
- 4.3 数据模型设计
- 4.4 SQL 语法示例
- 4.5 Java 客户端开发示例
- 4.6 Python 客户端示例
- 五、IoTDB 在工业场景中的应用实践
-
- 5.1 能源电力行业
- 5.2 轨道交通行业
- 5.3 汽车制造行业
- 六、IoTDB 与国外产品的对比分析
-
- 6.1 与 InfluxDB 对比
- 6.2 与 TimescaleDB 对比
- 七、选型建议与最佳实践
-
- 7.1 适用场景推荐
- 7.2 部署架构建议
- 7.3 性能优化建议
- 八、总结
- 相关链接
一、引言:时序数据时代的数据库选型困境
在物联网、工业互联网、金融交易、智能运维等领域蓬勃发展的今天,时序数据已经成为企业数据资产中增长最快、规模最大的数据类型之一。据统计,一个中等规模的工业制造企业每天产生的时序数据量可达数十亿条,而大型互联网公司的监控数据更是以每秒百万级的速度持续增长。
面对如此海量的时序数据,传统的数据库方案已经难以满足业务需求。关系型数据库在处理时序数据时面临着写入性能瓶颈、存储成本高昂、查询效率低下等问题。因此,选择一款合适的时序数据库成为企业大数据架构设计中的关键决策。
本文将从大数据架构视角出发,深入分析时序数据库的选型要点,并重点介绍 Apache IoTDB 这款国产开源时序数据库的核心优势与应用实践。
二、时序数据库的核心特性与选型维度
2.1 什么是时序数据库
时序数据库是专门用于存储和管理时间序列数据的数据库系统。时间序列数据是指按照时间顺序排列的数据点序列,通常具有以下特征:
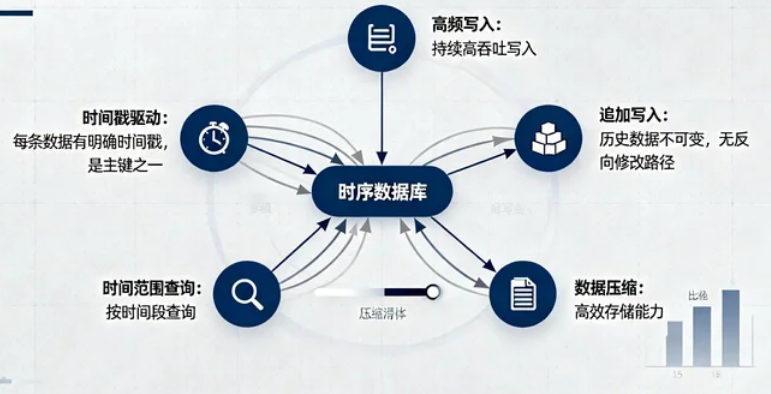
- 时间戳驱动:每条数据都有明确的时间戳,时间戳是数据的主键之一
- 高频写入:数据以持续、高频的方式写入,写入量通常远大于读取量
- 追加写入:历史数据很少修改,新数据持续追加
- 时间范围查询:查询通常基于时间范围,如查询某设备最近一小时的数据
- 数据压缩:时序数据通常具有较高的压缩比,适合采用专用压缩算法
2.2 时序数据库选型的关键维度
在企业级应用场景中,时序数据库的选型需要综合考虑以下维度:
2.2.1 写入性能
写入性能是时序数据库最核心的指标之一。在工业物联网场景中,成千上万的设备每秒产生海量数据点,数据库必须能够支撑高并发的写入请求。优秀的时序数据库应该具备:
- 百万级/秒写入能力:支持每秒百万级数据点的写入
- 批量写入优化:支持批量写入接口,减少网络开销
- 乱序写入支持:工业场景中数据可能乱序到达,数据库需要支持乱序写入
2.2.2 存储效率
时序数据通常具有很高的数据冗余度,优秀的压缩算法可以大幅降低存储成本。存储效率的考量包括:
- 压缩比:压缩比越高,存储成本越低
- 压缩速度:压缩算法不能成为写入瓶颈
- 冷热数据分层:支持将历史数据迁移到低成本存储
2.2.3 查询能力
时序数据库需要支持多种查询模式:
- 时间范围查询:查询指定时间范围内的数据
- 聚合查询:支持降采样、聚合统计等操作
- 最新值查询:快速获取设备的最新状态
- 多设备关联查询:支持跨设备的数据关联分析
2.2.4 分布式架构
随着数据规模的增长,单机架构难以满足需求,分布式能力成为必要条件:
- 水平扩展:支持通过增加节点扩展存储和计算能力
- 数据分片:支持数据自动分片和负载均衡
- 高可用性:支持数据副本和故障自动切换
2.2.5 生态兼容性
时序数据库需要与现有技术栈良好集成:
- 标准SQL支持:降低学习成本,便于与BI工具集成
- 多种协议支持:支持MQTT、HTTP等常见协议
- 可视化工具:支持Grafana等可视化平台
三、主流时序数据库技术对比
3.1 国际主流产品分析
在国际市场上,InfluxDB、TimescaleDB 等产品占据重要地位:

InfluxDB 是最早流行的时序数据库之一,采用自研的存储引擎,具有写入性能高的特点。但其集群版本闭源收费,且SQL兼容性有限,在企业级应用中存在一定局限。
TimescaleDB 基于PostgreSQL构建,继承了PostgreSQL的SQL兼容性和生态优势,但在处理超大规模时序数据时,性能和存储效率相对有限。
Prometheus 在监控领域广泛应用,但其设计定位更偏向监控系统,不适合作为通用时序数据库使用。
3.2 国产时序数据库的崛起
近年来,国产时序数据库快速发展,Apache IoTDB 作为其中的代表,已经在众多大型企业中得到验证。与国外产品相比,国产时序数据库在以下方面具有独特优势:
- 本地化支持:更好的中文文档和技术支持
- 工业场景适配:针对国内工业物联网场景深度优化
- 自主可控:满足信创要求,核心技术自主可控
四、Apache IoTDB 深度解析
4.1 项目背景与发展历程

Apache IoTDB 是一款开源的时序数据库管理系统,最初由清华大学开发,后捐赠给 Apache 软件基金会。IoTDB 专为物联网场景设计,可以满足工业物联网领域对海量数据存储、高速数据写入和复杂数据查询的需求。
IoTDB 的核心设计理念是"端-边-云"一体化架构,支持从边缘设备到云端数据中心的全链路时序数据管理。这一设计使其在工业物联网、车联网、能源电力等领域得到广泛应用。
4.2 核心架构设计
4.2.1 TsFile 存储引擎
IoTDB 采用自研的 TsFile 作为底层存储格式,具有以下特点:
TsFile 结构示意:
├── Chunk Group (设备级别数据组织)
│ ├── Chunk (测点级别数据组织)
│ │ ├── Page (数据页,压缩存储)
│ │ └── Statistics (统计信息)
│ └── Timeseries Chunk
└── File Metadata (文件元数据)
TsFile 的设计优势:
- 高压缩比:采用专有压缩算法,压缩比可达10:1以上
- 快速查询:通过元数据和统计信息实现快速过滤
- 顺序写入:优化磁盘IO,提升写入性能
4.2.2 分布式架构
IoTDB 支持分布式部署,架构如下:
┌─────────────────────────────────────────┐
│ Config Node │
│ (配置管理、元数据管理) │
└─────────────────────────────────────────┘
│
┌───────────┼───────────┐
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ Data Node │ │ Data Node │ │ Data Node │
│ (数据1) │ │ (数据2) │ │ (数据3) │
└───────────┘ └───────────┘ └───────────┘
分布式架构特点:
- 秒级扩容:无需数据迁移,新节点自动参与负载
- 高可用:支持多副本,自动故障切换
- 弹性伸缩:支持动态增删节点
4.3 数据模型设计
IoTDB 采用树形数据模型,天然契合物联网设备的层级结构:
root
├── factory1 (工厂)
│ ├── workshop1 (车间)
│ │ ├── device1 (设备)
│ │ │ ├── temperature (温度测点)
│ │ │ ├── humidity (湿度测点)
│ │ │ └── pressure (压力测点)
│ │ └── device2
│ └── workshop2
└── factory2
这种模型的优势:
- 语义清晰:路径结构直观反映设备层级关系
- 灵活扩展:新增设备或测点无需修改Schema
- 高效查询:支持前缀匹配,快速定位设备数据
4.4 SQL 语法示例
IoTDB 提供类SQL查询语言,学习成本低:
-- 创建时间序列
CREATE TIMESERIES root.factory1.device1.temperature
WITH DATATYPE=FLOAT, ENCODING=RLE;
-- 插入数据
INSERT INTO root.factory1.device1(timestamp, temperature, humidity)
VALUES (1704067200000, 25.5, 60.0);
-- 查询最近一小时数据
SELECT temperature, humidity
FROM root.factory1.device1
WHERE time > now() - 1h;
-- 聚合查询
SELECT avg(temperature), max(temperature), min(temperature)
FROM root.factory1.device1
GROUP BY ([0, now()), 1h);
-- 降采样查询
SELECT temperature
FROM root.factory1.device1
SAMPLE BY 5m;
4.5 Java 客户端开发示例
以下是使用 IoTDB Java SDK 进行开发的完整示例:
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
public class IoTDBExample {
private static Session session;
public static void main(String[] args) {
initSession();
try {
createTimeseries();
insertData();
queryData();
batchInsert();
} catch (Exception e) {
e.printStackTrace();
} finally {
closeSession();
}
}
private static void initSession() {
session = new Session.Builder()
.host("127.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
try {
session.open(false);
System.out.println("IoTDB 连接成功");
} catch (IoTDBConnectionException e) {
System.err.println("连接失败: " + e.getMessage());
}
}
private static void createTimeseries()
throws IoTDBConnectionException, StatementExecutionException {
String storageGroup = "root.factory";
session.setStorageGroup(storageGroup);
session.createTimeseries(
"root.factory.device1.temperature",
TSDataType.FLOAT,
TSEncoding.RLE,
CompressionType.SNAPPY
);
session.createTimeseries(
"root.factory.device1.humidity",
TSDataType.FLOAT,
TSEncoding.RLE,
CompressionType.SNAPPY
);
System.out.println("时间序列创建成功");
}
private static void insertData()
throws IoTDBConnectionException, StatementExecutionException {
String deviceId = "root.factory.device1";
List<String> measurements = new ArrayList<>();
List<TSDataType> types = new ArrayList<>();
List<Object> values = new ArrayList<>();
measurements.add("temperature");
measurements.add("humidity");
types.add(TSDataType.FLOAT);
types.add(TSDataType.FLOAT);
values.add(25.5f);
values.add(60.0f);
long timestamp = System.currentTimeMillis();
session.insertRecord(deviceId, timestamp, measurements, types, values);
System.out.println("数据插入成功");
}
private static void queryData()
throws IoTDBConnectionException, StatementExecutionException {
String sql = "SELECT temperature, humidity " +
"FROM root.factory.device1 " +
"WHERE time > now() - 1h";
SessionDataSet dataSet = session.executeQueryStatement(sql);
System.out.println("查询结果:");
while (dataSet.hasNext()) {
RowRecord record = dataSet.next();
System.out.printf("时间: %d, 温度: %.2f, 湿度: %.2f%n",
record.getTimestamp(),
record.getFields().get(0).getFloatV(),
record.getFields().get(1).getFloatV());
}
dataSet.closeOperationHandle();
}
private static void batchInsert()
throws IoTDBConnectionException, StatementExecutionException {
String deviceId = "root.factory.device1";
List<MeasurementSchema> schemas = new ArrayList<>();
schemas.add(new MeasurementSchema("temperature", TSDataType.FLOAT));
schemas.add(new MeasurementSchema("humidity", TSDataType.FLOAT));
Tablet tablet = new Tablet(deviceId, schemas, 10000);
long baseTimestamp = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
int rowIndex = tablet.rowSize++;
tablet.addTimestamp(rowIndex, baseTimestamp + i);
tablet.addValue("temperature", rowIndex, 25.0f + (float)(Math.random() * 5));
tablet.addValue("humidity", rowIndex, 55.0f + (float)(Math.random() * 10));
}
session.insertTablet(tablet);
System.out.println("批量插入 10000 条数据成功");
}
private static void closeSession() {
try {
session.close();
System.out.println("连接已关闭");
} catch (IoTDBConnectionException e) {
e.printStackTrace();
}
}
}
4.6 Python 客户端示例
IoTDB 同样提供 Python SDK 支持:
from iotdb.Session import Session
from iotdb.tablet import Tablet
from iotdb.schema import MeasurementSchema
from iotdb.tsfile.file.metadata.enums import TSDataType, TSEncoding
class IoTDBClient:
def __init__(self, host='127.0.0.1', port=6667):
self.session = Session(host, port, 'root', 'root')
def connect(self):
self.session.open(False)
print("IoTDB 连接成功")
def create_timeseries(self):
self.session.set_storage_group("root.factory")
self.session.create_timeseries(
"root.factory.device1.temperature",
TSDataType.FLOAT,
TSEncoding.RLE
)
self.session.create_timeseries(
"root.factory.device1.humidity",
TSDataType.FLOAT,
TSEncoding.RLE
)
print("时间序列创建成功")
def insert_data(self):
import time
device_id = "root.factory.device1"
measurements = ["temperature", "humidity"]
data_types = [TSDataType.FLOAT, TSDataType.FLOAT]
values = [25.5, 60.0]
timestamp = int(time.time() * 1000)
self.session.insert_record(
device_id, timestamp, measurements, data_types, values
)
print("数据插入成功")
def query_data(self):
sql = """
SELECT temperature, humidity
FROM root.factory.device1
WHERE time > now() - 1h
"""
result = self.session.execute_query_statement(sql)
print("查询结果:")
for record in result:
print(f"时间: {record.get_timestamp()}, "
f"温度: {record.get_fields()[0].get_float_v()}, "
f"湿度: {record.get_fields()[1].get_float_v()}")
result.close()
def batch_insert(self):
import time
import random
device_id = "root.factory.device1"
schemas = [
MeasurementSchema("temperature", TSDataType.FLOAT),
MeasurementSchema("humidity", TSDataType.FLOAT)
]
tablet = Tablet(device_id, schemas, 10000)
base_timestamp = int(time.time() * 1000)
for i in range(10000):
tablet.add_timestamp(base_timestamp + i)
tablet.add_value("temperature", 25.0 + random.random() * 5)
tablet.add_value("humidity", 55.0 + random.random() * 10)
self.session.insert_tablet(tablet)
print("批量插入 10000 条数据成功")
def close(self):
self.session.close()
print("连接已关闭")
if __name__ == "__main__":
client = IoTDBClient()
client.connect()
try:
client.create_timeseries()
client.insert_data()
client.query_data()
client.batch_insert()
finally:
client.close()
五、IoTDB 在工业场景中的应用实践
5.1 能源电力行业
在能源电力行业,IoTDB 已成功应用于国家电网的精准用电调控系统:
场景特点:
- 千万级设备并发接入
- 千万点数据/秒的实时写入
- 日新增数据量达亿级
应用效果:
- 实现多种能源数据采集缓存
- 支持多类终端千万级接入管控
- 在线汇聚全量实时数据
5.2 轨道交通行业
中车四方采用 IoTDB 构建城轨车辆智能运维系统:
场景特点:
- 300辆列车监控
- 3200测点/列车
- 日增4140亿数据点
应用效果:
- 可管理列车数增加1倍
- 采样时间提升60%
- 需要服务器数降为1/13
- 月数据增量压缩后大小下降95%
5.3 汽车制造行业
长安汽车将 IoTDB 应用于智能网联车辆数据管理:
场景特点:
- 接入车辆设备约57万
- 测点数约8000万
- 托管时间序列约1.5亿
- 写入量级达150万条数据/秒
应用效果:
- 同等硬件资源条件下查询效率从分钟级提升到毫秒级
- 支撑海量车况时序数据处理
六、IoTDB 与国外产品的对比分析
6.1 与 InfluxDB 对比
| 对比维度 | Apache IoTDB | InfluxDB |
|---|---|---|
| 开源协议 | Apache 2.0 | MIT (单机) / 商业 (集群) |
| 集群功能 | 完全开源 | 企业版收费 |
| SQL兼容 | 类SQL语法 | Flux语言 (学习成本高) |
| 压缩算法 | 自研TsFile | TSM |
| 边缘支持 | 原生支持 | 需要额外组件 |
6.2 与 TimescaleDB 对比
| 对比维度 | Apache IoTDB | TimescaleDB |
|---|---|---|
| 底层架构 | 自研存储引擎 | 基于PostgreSQL |
| 写入性能 | 更优 | 依赖PG性能 |
| 存储效率 | 高压缩比 | 中等 |
| 分布式 | 原生分布式 | 需要扩展 |
| 运维复杂度 | 较低 | 需要PG运维经验 |
七、选型建议与最佳实践
7.1 适用场景推荐
IoTDB 特别适合以下场景:
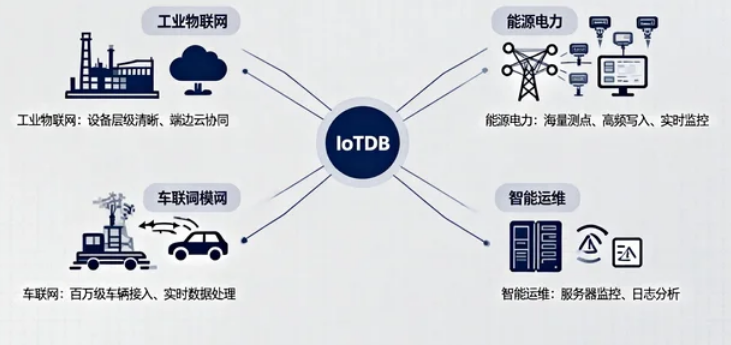
- 工业物联网:设备层级结构清晰,需要端边云协同
- 能源电力:海量测点、高频写入、实时监控
- 车联网:百万级车辆接入、实时数据处理
- 智能运维:服务器监控、日志分析
7.2 部署架构建议
根据数据规模选择合适的部署架构:
小规模场景(千万级数据点):
单机部署
├── Config Node
├── Data Node
└── Grafana (可视化)
中大规模场景(亿级数据点):
分布式部署
├── Config Node (3节点,高可用)
├── Data Node (多节点,按需扩展)
└── Grafana + 数据同步工具
7.3 性能优化建议
-- 1. 合理设置存储组
CREATE DATABASE root.factory1;
-- 2. 选择合适的编码方式
CREATE TIMESERIES root.factory.device.temperature
WITH DATATYPE=FLOAT, ENCODING=RLE;
-- 3. 使用批量写入接口
-- Java: session.insertTablet(tablet)
-- Python: session.insert_tablet(tablet)
-- 4. 优化查询语句
-- 使用时间范围限制
SELECT * FROM root.factory.device
WHERE time >= 1704067200000 AND time <= 1704153600000;
-- 使用聚合减少返回数据量
SELECT avg(temperature) FROM root.factory.device
GROUP BY ([1704067200000, 1704153600000), 1h);
八、总结
时序数据库选型是企业大数据架构设计的重要决策。在当前国产化替代和技术自主可控的大背景下,Apache IoTDB 作为一款成熟的国产开源时序数据库,凭借其高性能、高压缩比、分布式架构和工业场景深度适配等优势,已经成为众多大型企业的首选方案。
从技术架构角度看,IoTDB 的 TsFile 存储引擎、树形数据模型、端边云一体化设计,都体现了其对物联网场景的深度理解。从应用实践看,IoTDB 在国家电网、中车四方、长安汽车等头部企业的成功落地,充分验证了其技术成熟度和工程可靠性。
对于正在进行时序数据库选型的企业,建议从自身业务场景出发,综合考虑写入性能、存储效率、查询能力、分布式架构、生态兼容性等维度,选择最适合的技术方案。而 Apache IoTDB 无疑是一个值得重点评估和试用的选择。
相关链接
- IoTDB 下载地址:https://iotdb.apache.org/zh/Download/
- 企业版官网:https://timecho.com
© 版权声明
文章版权归作者所有,未经允许请勿转载。


