Ubuntu20.04搭建Hadoop大数据生态——从零开始:Ubuntu 20.04 搭建Hadoop+Hive+HBase+Spark大数据平台全攻略
这是一份详细的、手把手式的博客教程,旨在帮助你在 Ubuntu 20.04 系统上从零开始搭建一个完整的 Apache Hadoop 大数据生态平台。本教程将涵盖 HDFS、YARN、Hive、HBase 和 Spark 的安装与基础配置。
前言
大数据技术生态繁复,对于初学者而言,搭建一个完整的开发测试环境往往是入门的第一道坎。本文将详细记录在 Ubuntu 20.04 LTS 系统上,如何一步步搭建包含 Hadoop (HDFS + YARN)、Hive、HBase 和 Spark 的大数据基础平台。
架构说明:本教程以搭建伪分布式/完全分布式集群为目标。为降低学习门槛,核心配置以单节点(伪分布式)为基础进行讲解,并会在关键处提示分布式集群的配置要点。
第一章:环境准备与核心思想
在正式开始安装前,统一环境是避免“踩坑”的关键。
1.1 版本选型(非常重要!)
大数据组件之间的版本兼容性至关重要。以下为本教程选用的版本组合,以“最大稳定性”和“社区广泛验证”为首要目标,经过大量生产环境考验。
|
组件 |
版本 |
说明 |
|
操作系统 |
Ubuntu 20.04.6 LTS |
长期支持版,稳定可靠 |
|
Java |
OpenJDK 8 |
Hadoop、HBase等官方推荐版本 |
|
Hadoop |
3.3.6 |
HDFS和YARN的基础,成熟稳定分支 |
|
ZooKeeper |
3.6.3 |
独立部署的协调服务,HBase依赖 |
|
HBase |
2.4.13 |
列式数据库,2.4.x官方维护分支 |
|
Hive |
3.1.2 |
数据仓库,经典稳定版(注意:3.x已于2024年EOL,但此处坚守经典) |
|
Spark |
3.1.2 |
内存计算引擎,官方强烈推荐的稳定版 |
|
MySQL |
8.0 |
Hive Metastore存储后端 |
大数据组件之间的版本兼容性至关重要。以下为本教程选用的版本组合,经过测试可稳定兼容:
- 操作系统:Ubuntu 20.04.6 LTS (Jammy)
- Java:OpenJDK 8 (Hadoop 3.x 及 HBase 要求 Java 8 或 11,这里选择最稳妥的 JDK 8)
- Hadoop:3.3.6 (HDFS 和 YARN 的基础)
- Hive:3.1.3 (数据仓库)
- HBase:2.4.17 (列式数据库)
- Spark:3.5.5 ( 计算引擎,预先编译好对应 Hadoop 3 的版本)
- MySQL:8.0 (用于 Hive 的元数据存储)
- ZooKeeper:3.8.4 (HBase 与 Hadoop HA 需要)
1.2 系统基础设置
- 更新系统
sudo apt update && sudo apt upgrade -y-
创建专门用于大数据操作的用户
为了权限管理清晰,建议创建一个新用户(例如hadoop)。
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo usermod -aG sudo hadoop后续操作如无特别说明,均切换至 hadoop 用户执行。
- 安装必备软件
sudo apt install -y vim curl wget tar git openssh-server net-tools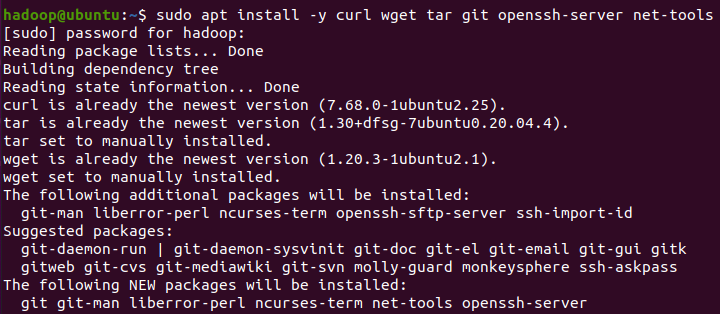
1. curl
- 用途:一个功能强大的命令行工具,用于与服务器传输数据,支持 HTTP、HTTPS、FTP 等协议。
-
在大数据搭建中的作用:主要用于下载文件或测试 API。例如,可以通过
curl -O直接下载 Hadoop、Hive 等组件的压缩包。有时也用于检查服务是否正常启动(如curl http://localhost:9870查看 HDFS Web UI 是否可访问)。
2. wget
- 用途:另一个下载工具,专注于文件获取,支持递归下载、断点续传、后台下载等特性。
-
在大数据搭建中的作用:与 curl 类似,但更侧重于稳健的文件下载。当下载大型的 Hadoop 发行包(如
hadoop-3.3.6.tar.gz)时,wget可以自动重试、断点续传,非常可靠。
3. tar
-
用途:Linux 下常用的归档工具,用于打包和解压
.tar、.tar.gz、.tgz等格式的文件。 -
在大数据搭建中的作用:所有 Apache 大数据组件(Hadoop、Hive、HBase、Spark 等)均以
.tar.gz压缩包形式发布。安装时需使用tar -zxvf解压到指定目录,并移动、重命名。
4. git
- 用途:分布式版本控制系统,用于克隆和管理代码仓库。
- 在大数据搭建中的作用:虽然本教程主要通过官网下载预编译包,但在实际开发中可能需要从 GitHub 获取配置文件模板、自定义源码或补丁。安装 git 为后续扩展或从源码编译做好准备。
5. openssh-server
- 用途:OpenSSH 的服务端组件,允许其他机器通过 SSH 协议安全地连接到本机。
- 器通过 SSH 协议安全地连接到本机。
- 在大数据搭建中的作用:Hadoop 集群启动时,NameNode 需要通过 SSH 免密登录到所有 DataNode 节点上启动/停止进程。即使是伪分布式模式,也需要配置 SSH localhost 免密登录。安装此包后才能开启 SSH 服务并配置密钥。
6. net-tools
-
用途:经典网络工具集,包含
ifconfig、netstat、route等命令。 -
在大数据搭建中的作用:用于检查网络配置和端口监听状态。例如,使用
ifconfig查看本机 IP,使用netstat -tulpn确认 Hadoop、HBase 等服务的端口(如 9870、8088、16010)是否正常监听,快速定位启动失败的原因。
1.3 配置 SSH 免密登录
Hadoop 集群启动需要 NameNode 通过 SSH 启动或停止 DataNode 进程。
# 生成密钥对(一直回车即可)
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
# 将公钥拷贝到本机的授权列表(单节点伪分布式)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
# 测试连接本机
ssh localhost
# 如果不需要输入密码直接登录,则配置成功
exit # 退出回原来的会话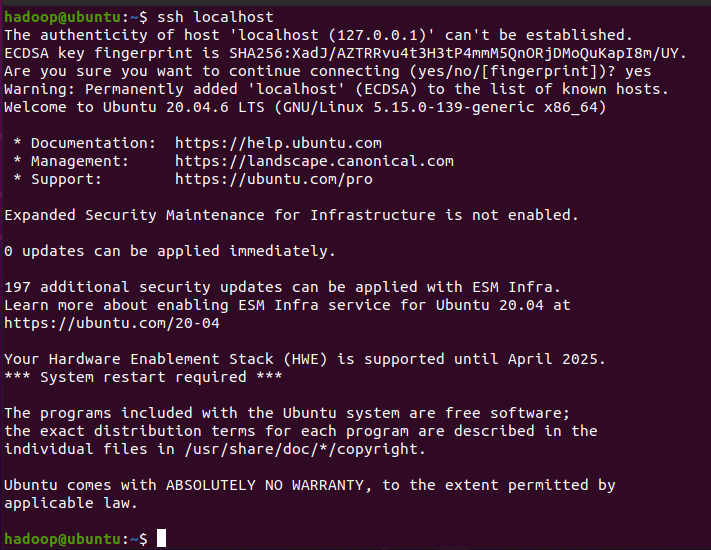
1.4 安装 Java
- 安装 OpenJDK 8
sudo apt update
sudo apt install -y openjdk-8-jdk- 验证 Java 安装
java -version如果输出类似以下信息,说明安装成功:
openjdk version "1.8.0_392"
OpenJDK Runtime Environment (build 1.8.0_392-8u392-ga-1~20.04-b08)
OpenJDK 64-Bit Server VM (build 25.392-b08, mixed mode)
-
查找 Java 安装路径(用于设置 JAVA_HOME)
执行以下命令,它会自动定位java命令的真实路径并提取 JDK 的根目录:
dirname $(dirname $(readlink -f $(which java)))输出示例:
/usr/lib/jvm/java-8-openjdk-amd64请记下这个路径,下一步配置环境变量时需要用到。
-
配置 JAVA_HOME 环境变量
编辑系统环境文件/etc/profile:
sudo vim /etc/profile在文件末尾添加以下两行(请用上一步获取的实际路径替换):
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin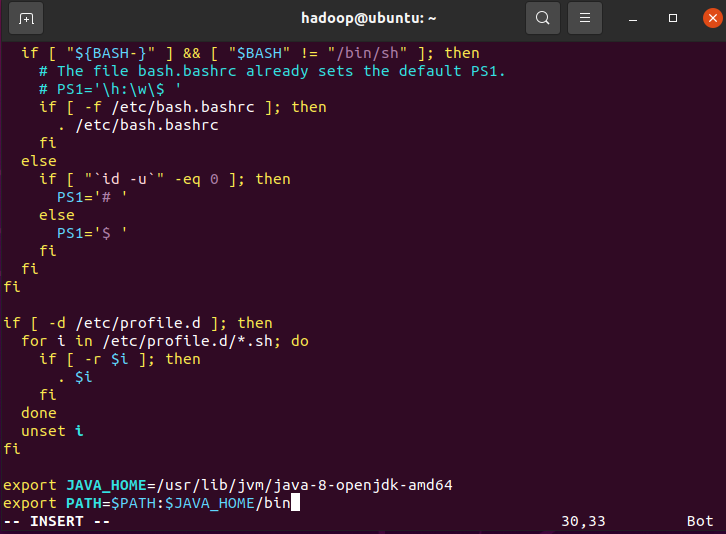
按Esc :wq 回车保存并退出
- 使配置生效并验证
source /etc/profile
echo $JAVA_HOME # 应输出刚才设置的路径
java -version # 应显示 OpenJDK 1.8 相关信息
ls -l $JAVA_HOME/bin/java
#应该显示:
#lrwxrwxrwx 1 root root 15 Apr 16 2025 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -> ../jre/bin/java第二章:搭建 Hadoop (HDFS & YARN)
Hadoop 是整个生态系统的基石,负责数据的分布式存储(HDFS)和资源调度(YARN)。
2.1 下载与安装
# 下载 Hadoop 3.3.6
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# 解压到 /usr/local 目录
sudo tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local
sudo mv /usr/local/hadoop-3.3.6 /usr/local/hadoop
sudo chown -R hadoop:hadoop /usr/local/hadoop2.2 配置环境变量
sudo vim /etc/profile
# 添加以下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#按Esc 输入:wq 回车保存并退出
# 使配置生效
source /etc/profile
2.3 修改 Hadoop 配置文件
所有配置文件均位于 $HADOOP_HOME/etc/hadoop/ 目录下。
-
hadoop-env.sh:设置 Java 环境
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# 找到 JAVA_HOME 那行,修改为:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64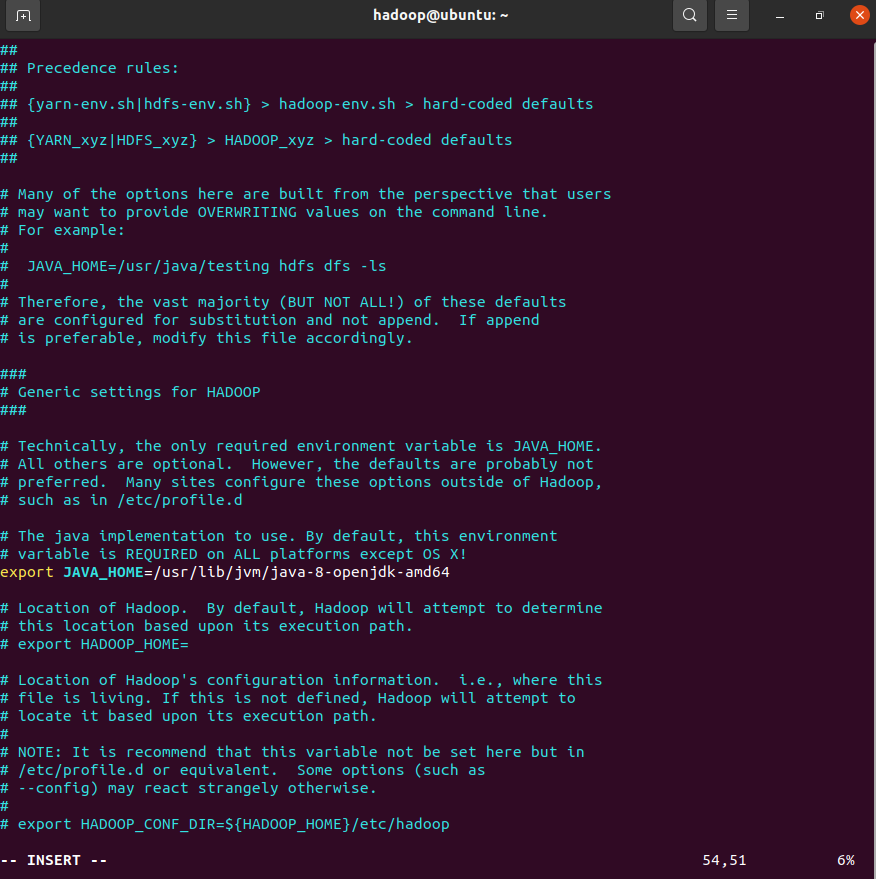
需要先删除开头的注释,如图我的是在第54行
-
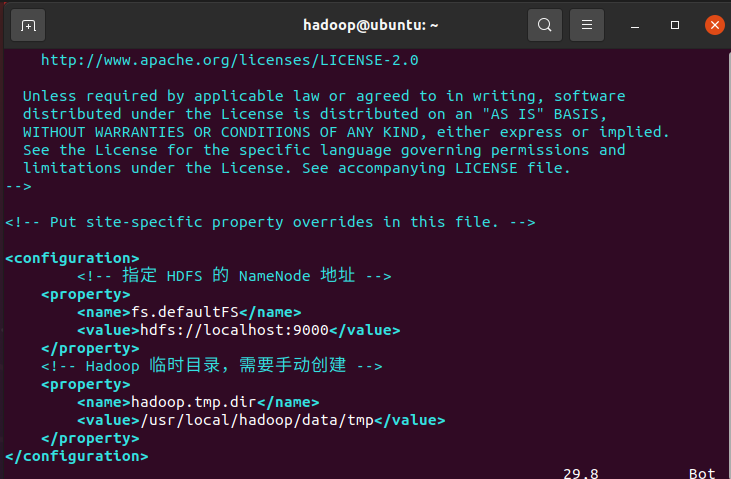
core-site.xml:配置 HDFS 的访问入口
<configuration>
<!-- 指定 HDFS 的 NameNode 地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- Hadoop 临时目录,需要手动创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
</configuration>
-
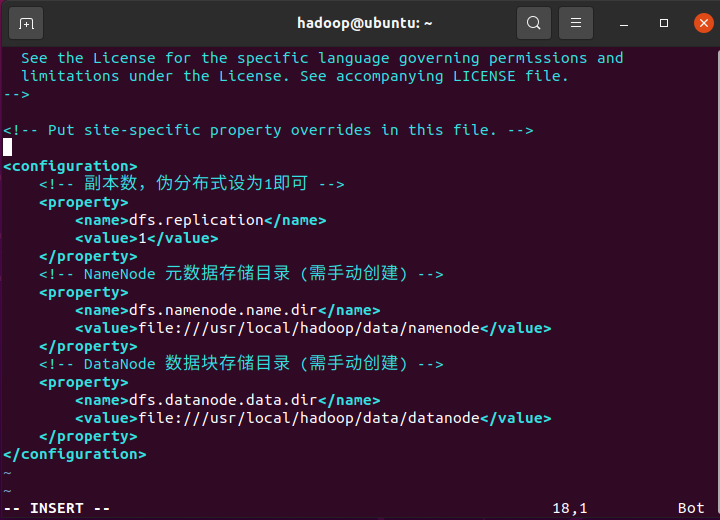
hdfs-site.xml:配置 HDFS 的副本数和数据目录
<configuration>
<!-- 副本数,伪分布式设为1即可 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- NameNode 元数据存储目录 (需手动创建) -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/namenode</value>
</property>
<!-- DataNode 数据块存储目录 (需手动创建) -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/data/datanode</value>
</property>
</configuration>
-
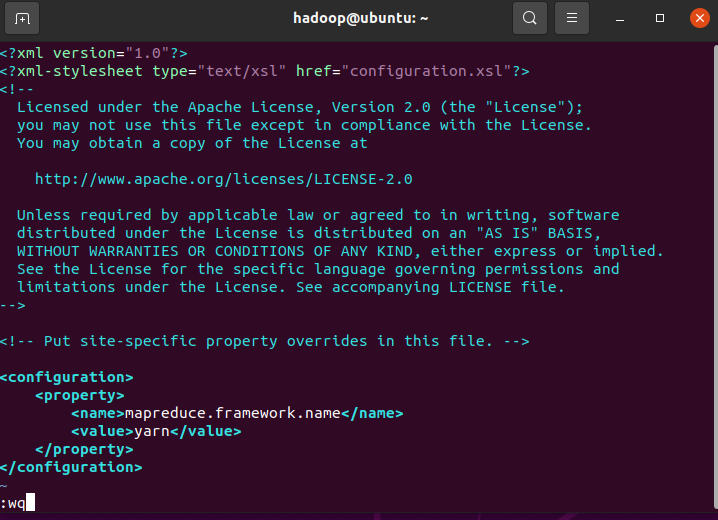
mapred-site.xml:配置 MapReduce 运行框架为 YARN
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
-
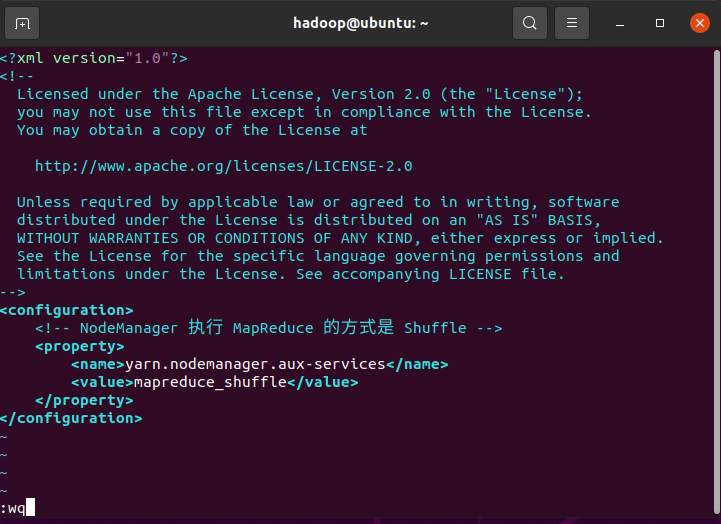
yarn-site.xml:配置 YARN 的相关服务
<configuration>
<!-- NodeManager 执行 MapReduce 的方式是 Shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 创建工作目录
mkdir -p /usr/local/hadoop/data/tmp
mkdir -p /usr/local/hadoop/data/namenode
mkdir -p /usr/local/hadoop/data/datanode
2.4 启动 Hadoop
- 格式化 NameNode(仅在第一次启动前执行)
hdfs namenode -format
- 启动 HDFS 和 YARN
# 启动 HDFS
start-dfs.sh
# 启动 YARN
start-yarn.sh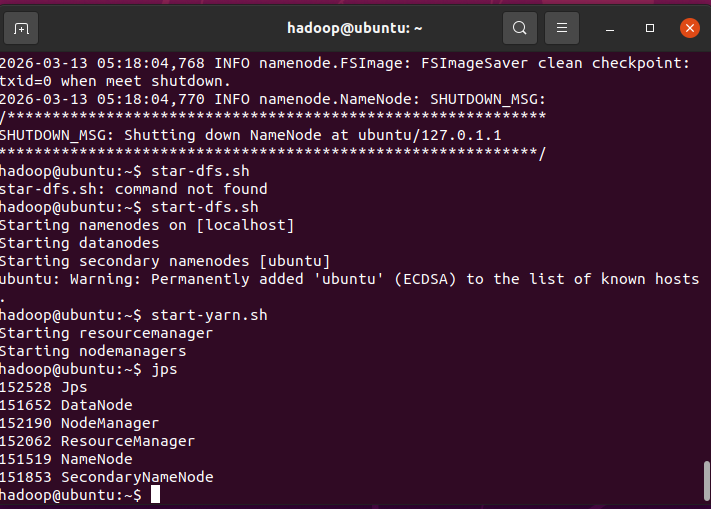
-
验证进程
输入jps,你应该能看到以下 5 个进程:
-
NameNodeDataNodeSecondaryNameNodeResourceManagerNodeManager
- 访问 Web UI
-
- HDFS 管理界面:
http://localhost:9870 - YARN 管理界面:
http://localhost:8088
- HDFS 管理界面:
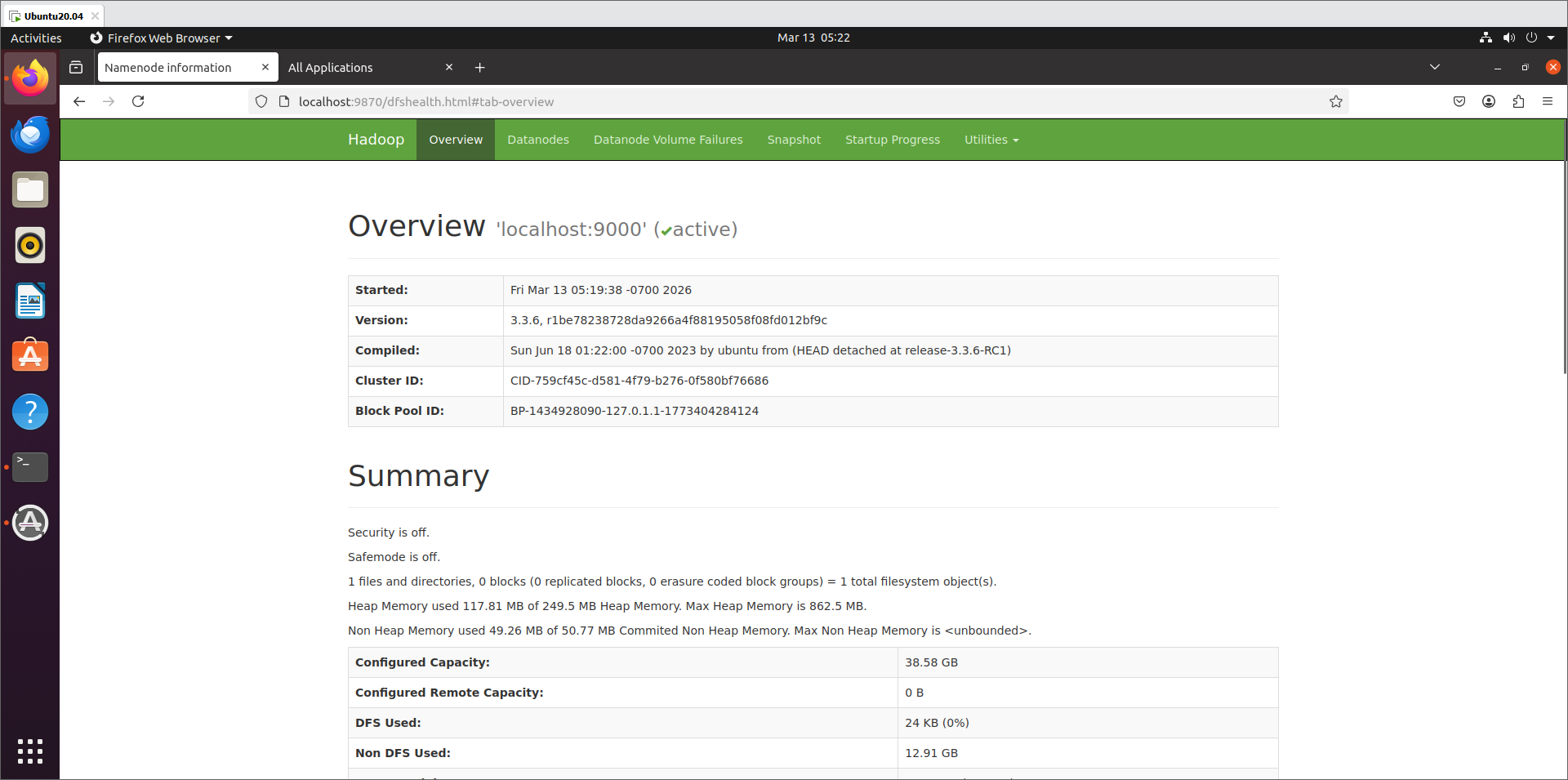
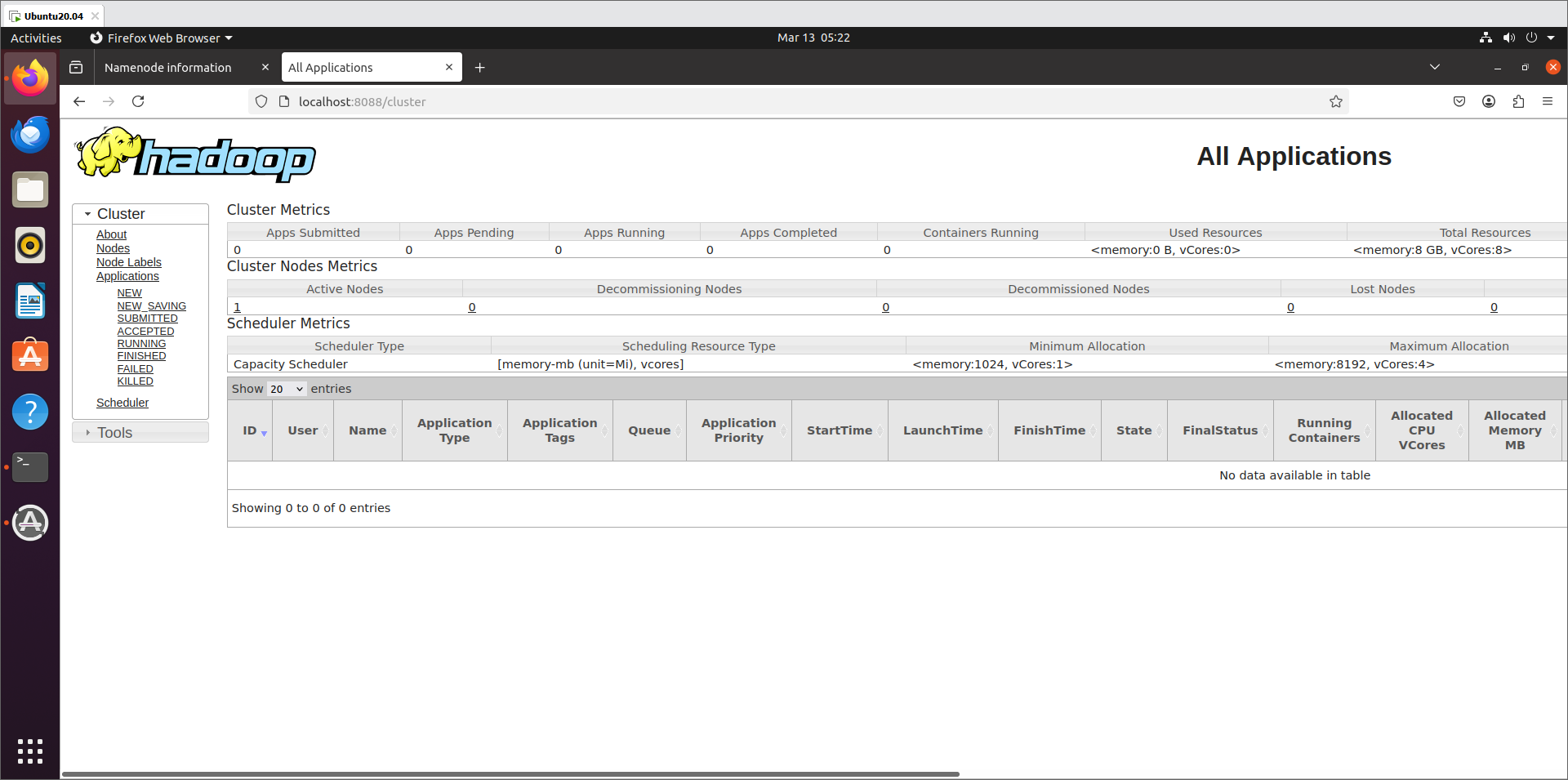
第三章:搭建 Hive (数据仓库)
Hive 将 SQL 语句转换为 MapReduce/Spark 任务运行,其元数据存储在 MySQL 中。
3.1 安装并配置 MySQL (作为 Hive Metastore)
# 安装 MySQL
sudo apt install -y mysql-server
# 初始化配置 (建议设置 root 密码)
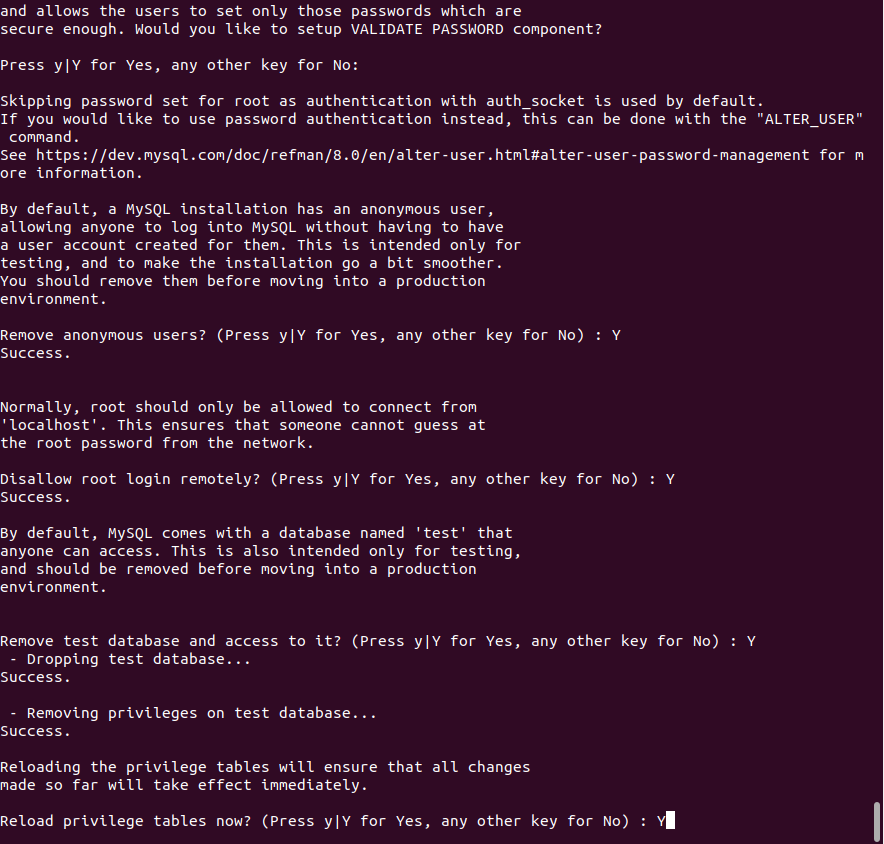
sudo mysql_secure_installation
# 登录 MySQL
sudo mysql -u root -p
# 在 MySQL shell 中执行以下命令创建 Hive 用的数据库和用户,创建一个名为 metastore 的数据库
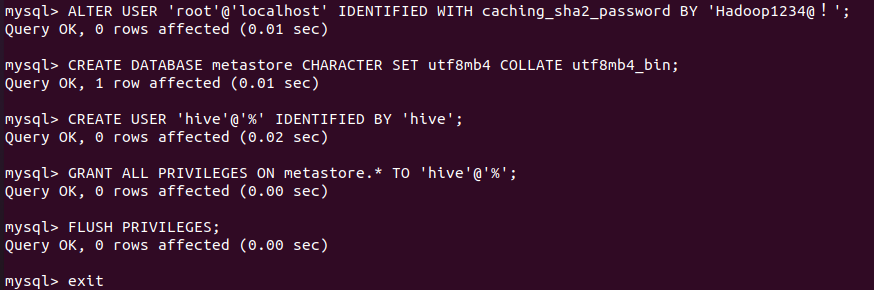
CREATE DATABASE metastore CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';
GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';
FLUSH PRIVILEGES;
exit;⚠️ 注意
- 用户名和密码可以自定义,但后续配置文件要对应。
- 如果 MySQL 和 Hive 在同一台机器,
'hive'@'localhost'更安全,但需要确保连接 URL 也使用localhost。 - 建议字符集使用
utf8mb4,避免中文或特殊字符问题。
3.2 下载并安装 Hive
# 下载 Hive 3.1.2(经典稳定版)#我晚上的时候很慢!!#换个时间段就很快了
wget https://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
#或者使用国内大学的镜像
#wget https://mirrors.bfsu.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
#wget http://mirrors.hust.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
#wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
# 解压
sudo tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local
sudo mv /usr/local/apache-hive-3.1.2-bin /usr/local/hive
sudo chown -R $USER:$USER /usr/local/hive # 将 $USER 替换为你的用户名,如 hadoop3.3 配置环境变量
sudo vim /etc/profile
# 在文件末尾添加:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
# 使配置生效
source /etc/profile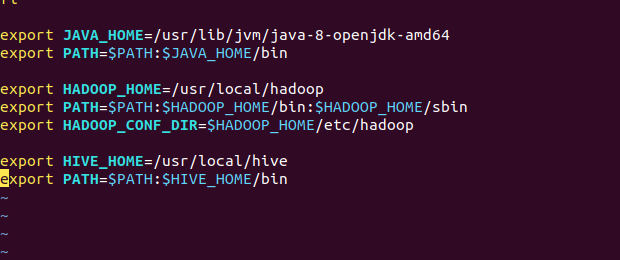
3.4 配置 Hive
- 下载 MySQL JDBC 驱动
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
# 注意:下载下来直接就是一个 .jar 文件,无需解压。
# 直接将其复制到 Hive 的 lib 目录即可
cp mysql-connector-j-8.0.33.jar $HIVE_HOME/lib/-
创建配置文件
hive-site.xml
cd $HIVE_HOME/conf
cp hive-default.xml.template hive-site.xml
vim hive-site.xml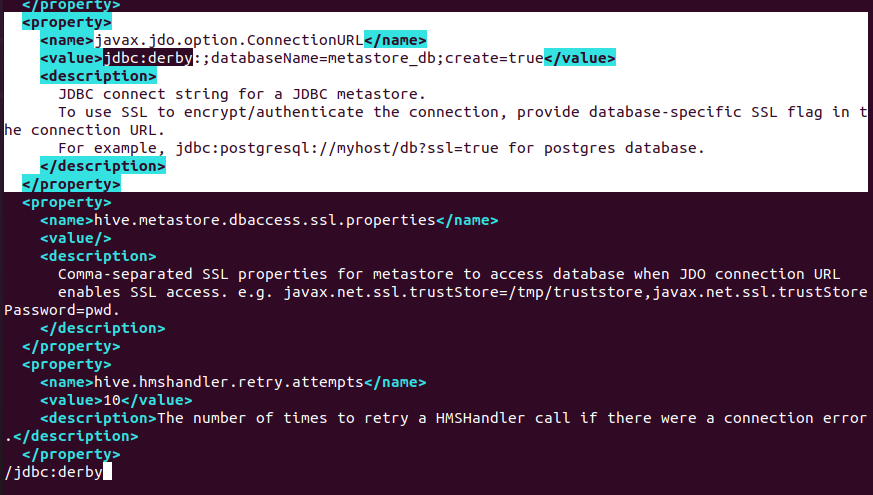
在 hive-site.xml 中,搜索 jdbc:derby(按 / 然后输入 jdbc:derby 回车),找到所有包含 Derby 的 <property> 块,整块删除。
通常需要删除以下几类:
-
javax.jdo.option.ConnectionURL的 Derby 版本 -
javax.jdo.option.ConnectionDriverName的 Derby 驱动 -
javax.jdo.option.ConnectionUserName的默认APP -
javax.jdo.option.ConnectionPassword的默认mine
删除后,确保文件中只有一个 javax.jdo.option.ConnectionURL、ConnectionDriverName、ConnectionUserName、ConnectionPassword,并且值都是 MySQL 的。
然后在 <configuration> 标签内添加(或确保只有)以下内容:
<configuration>
<!-- 配置 MySQL 连接 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<!-- 配置 Hive 在 HDFS 上的存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 解决 Metastore 连接版本警告等问题(可选) -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<!-- ⚠️ 重要:修改临时目录配置,避免变量解析失败 -->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/hive/${user.name}</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive/${hive.session.id}_resources</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/tmp/hive/${user.name}</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/tmp/hive/${user.name}/operation_logs</value>
</property>
</configuration>
🔔 特别注意
- URL 中
&是 XML 转义后的&,必须这样写。 - 添加了
allowPublicKeyRetrieval=true避免 MySQL 8.0 的 public key 错误。 - 使用
${user.name}而不是${system:user.name},因为 Hadoop 变量替换更可靠。 - 确保每个
<property>的标签正确闭合(尤其是<value>和</value>配对,不要误写<Value>)。
3.5 创建本地临时目录并设置权限
sudo mkdir -p /tmp/hive
sudo chmod 1777 /tmp/hive # 设置粘滞位,类似 /tmp 的权限💡 为什么?
Hive 会在 /tmp/hive 下创建用户子目录存放临时文件,如果目录不存在或权限不足,启动会失败。
3.6 初始化元数据库
3.7 确保 MySQL 服务已启动
sudo systemctl status mysql # 检查状态
sudo systemctl start mysql # 如果未启动3.8 执行初始化命令
schematool -dbType mysql -initSchema如果成功,最后会显示 schemaTool completed。
常见错误
- Access denied:检查用户名、密码、MySQL 用户权限。
-
Public Key Retrieval is not allowed:URL 中已添加
allowPublicKeyRetrieval=true。 -
Table already exists:说明之前初始化过,可以用
-initSchemaTo 3.1.0或先删除数据库重建。
3.9 启动 Hive
3.10 确保 Hadoop 已启动
start-dfs.sh
start-yarn.sh
jps # 检查 NameNode、DataNode、ResourceManager 等进程3.12 创建 Hive 仓库目录(如果 HDFS 上没有)
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -chmod 755 /user/hive/warehouse # 可选,设置权限3.13 启动 Hive CLI
hive如果一切正常,你会进入 Hive 命令行,可以执行 show databases; 测试。exit;退出
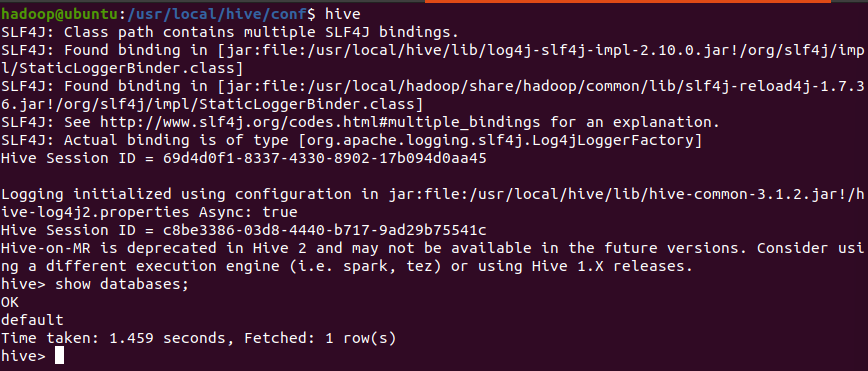
hive-site.xml
第四章:搭建 ZooKeeper (独立协调服务)
HBase 依赖 ZooKeeper 进行分布式协调。本教程使用独立部署的 ZooKeeper 3.6.3,以保证稳定性和可控性。
4.1 下载与安装
# 下载 ZooKeeper 3.6.3
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
# 解压到 /usr/local 目录
sudo tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C /usr/local
sudo mv /usr/local/apache-zookeeper-3.6.3-bin /usr/local/zookeeper
sudo chown -R hadoop:hadoop /usr/local/zookeeper4.2 配置环境变量
sudo vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile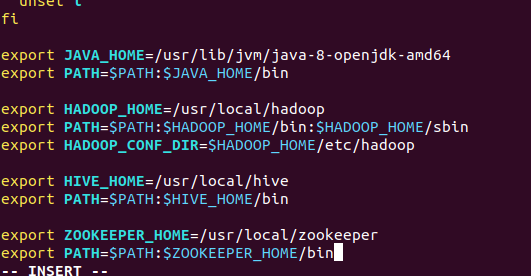
4.3 配置 ZooKeeper
- 创建数据目录
mkdir -p /usr/local/zookeeper/data- 创建并编辑配置文件
cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg
vim $ZOOKEEPER_HOME/conf/zoo.cfg主要修改数据目录:
dataDir=/usr/local/zookeeper/data
clientPort=2181
# 单节点无需额外配置,集群模式需添加 server 列表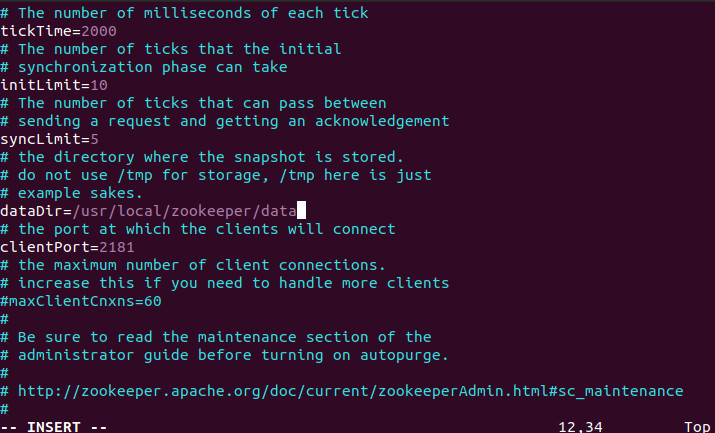
4.4 启动 ZooKeeper
# 启动 ZK 服务
zkServer.sh start
# 检查状态
zkServer.sh status
# 单节点应显示 Mode: standalone
# 可选:进入 ZK 客户端测试
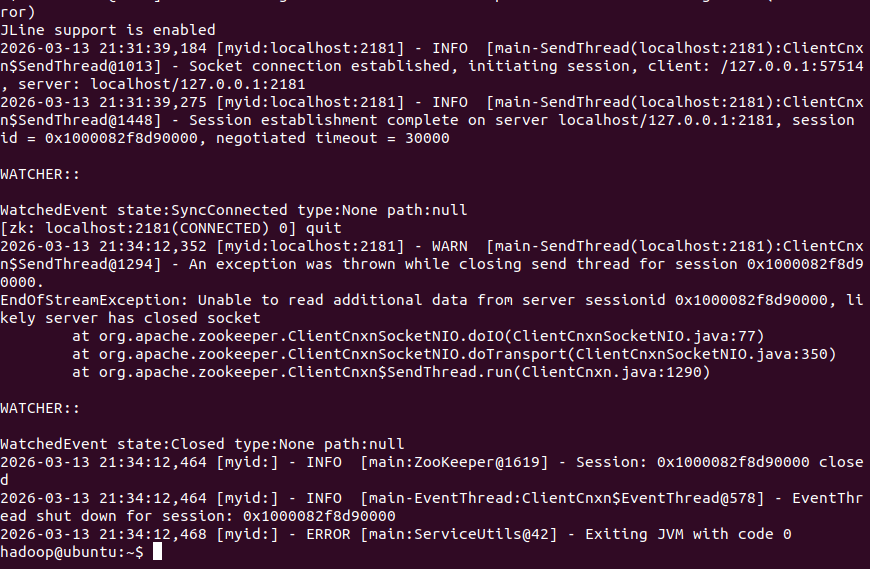
zkCli.sh -server localhost:2181
quit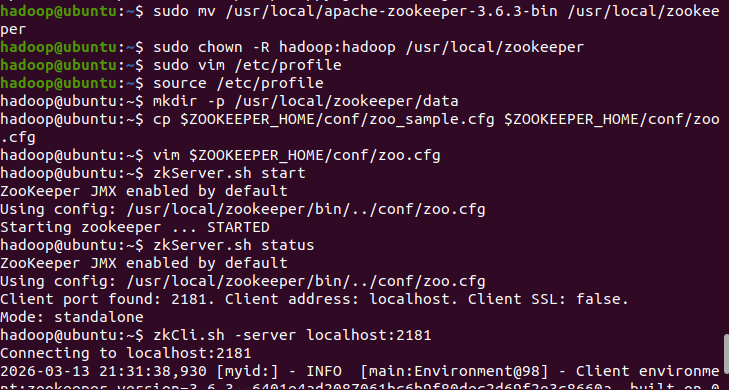
、
第五章:搭建 HBase (NoSQL 数据库)
HBase 是一个面向列的分布式数据库,依赖 HDFS 存储和 ZooKeeper 协同服务。
5.1 下载与安装
# 下载 HBase 2.4.13
wget https://archive.apache.org/dist/hbase/2.4.13/hbase-2.4.13-bin.tar.gz
sudo tar -zxvf hbase-2.4.13-bin.tar.gz -C /usr/local
sudo mv /usr/local/hbase-2.4.13 /usr/local/hbase
sudo chown -R hadoop:hadoop /usr/local/hbase5.2 配置环境变量
sudo vim /etc/profile
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile5.3 修改 HBase 配置
hbase-env.sh
vim $HBASE_HOME/conf/hbase-env.sh
# 设置 Java 环境
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 关闭 HBase 内置 ZooKeeper,使用独立部署的 ZooKeeper
export HBASE_MANAGES_ZK=false
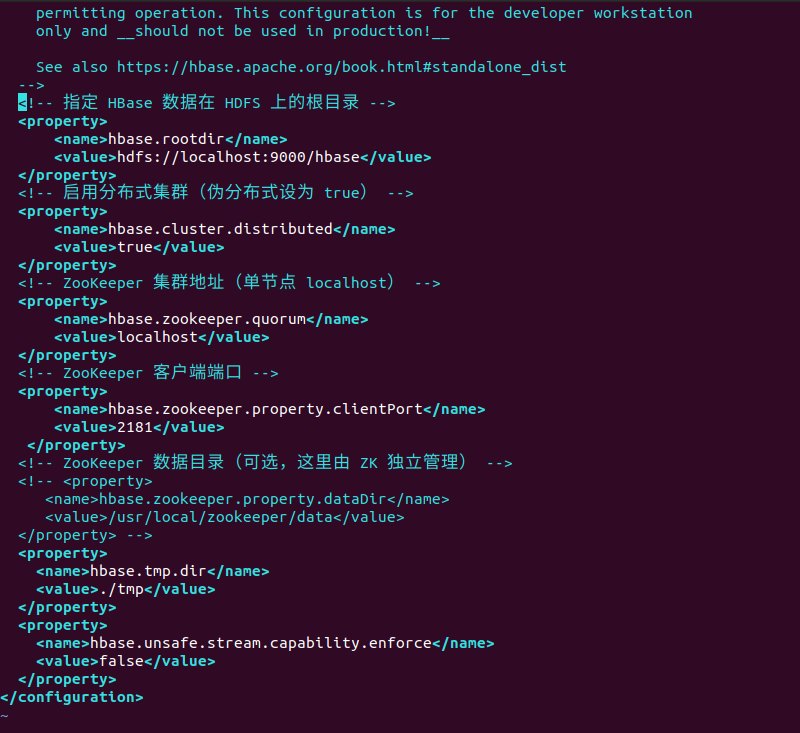
hbase-site.xml
<configuration>
<!-- 指定 HBase 数据在 HDFS 上的根目录 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<!-- 启用分布式集群(伪分布式设为 true) -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper 集群地址(单节点 localhost) -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<!-- ZooKeeper 客户端端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- ZooKeeper 数据目录(可选,这里由 ZK 独立管理) -->
<!-- <property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/data</value>
</property> -->
<property>
<name>hbase.wal.async.enabled</name>
<value>false</value>
</property>
</configuration>
5.4 启动 HBase
启动顺序:必须确保 Hadoop HDFS 和 ZooKeeper 已经启动。
# 启动 HBase
start-hbase.sh
# 验证进程 (jps 应看到 HMaster 和 HRegionServer)
jps
# 进入 HBase Shell
hbase shell
# 在 shell 中输入 status,如果显示正常,则搭建成功
status
exit
# 访问 Web UI: http://localhost:16010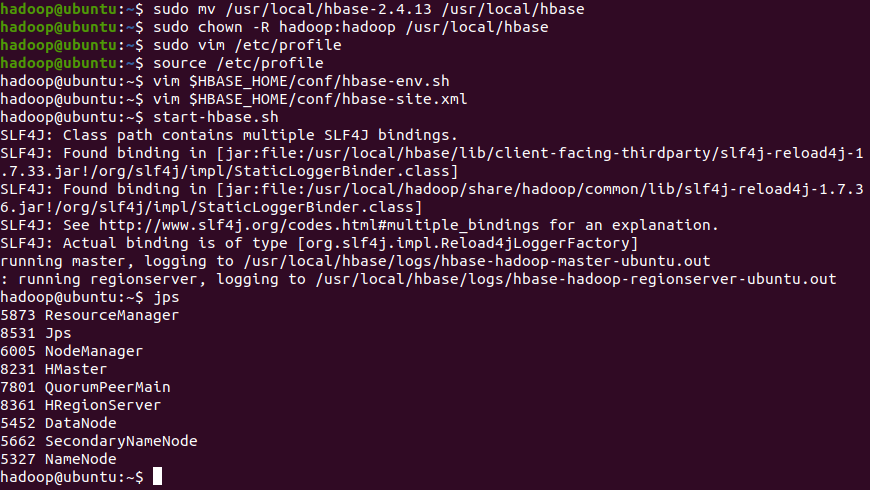
第六章:搭建 Spark (内存计算引擎)
Spark 可以运行在 YARN 之上,与 Hadoop 生态系统无缝集成。
6.1 下载与安装
选择预先编译好针对 Hadoop 3.2 的版本(与 Hadoop 3.3.6 兼容)。
# 下载 Spark 3.1.2 (官方强烈推荐的稳定版)
wget https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
sudo tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /usr/local
sudo mv /usr/local/spark-3.1.2-bin-hadoop3.2 /usr/local/spark
sudo chown -R hadoop:hadoop /usr/local/spark6.2 配置环境变量
sudo vim /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile
6.3 配置 Spark 集成 YARN
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh
vim $SPARK_HOME/conf/spark-env.sh
# 添加以下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=localhost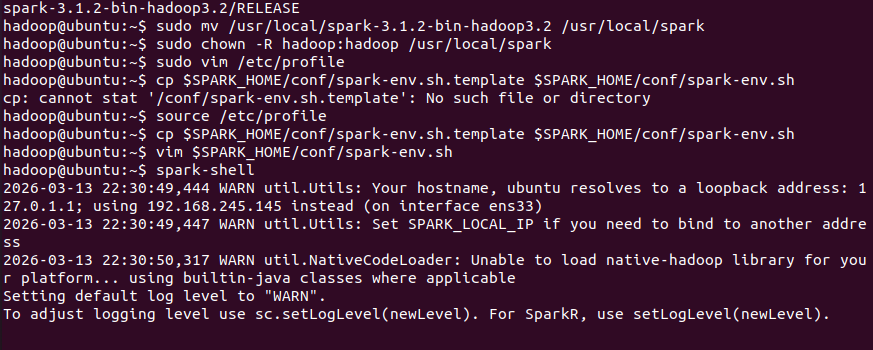
6.4 验证 Spark
- 运行 Spark Shell (Scala)
spark-shell
# 在 Scala 交互式界面输入以下内容测试
sc.parallelize(1 to 10).count() //在内存中创建了一个包含 1,2,3,...,10 的 RDD
// 按 Ctrl+D 退出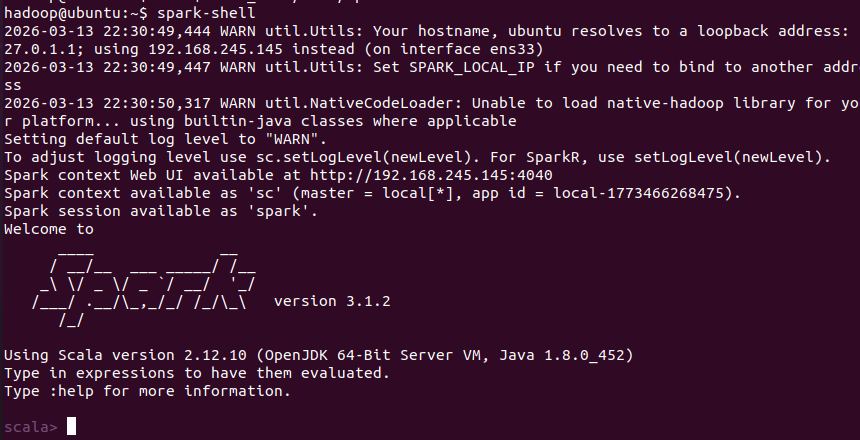
- 运行 PySpark (Python)
pyspark
>>> sc.parallelize(range(1,11)).count()
>>> df = spark.range(1, 11)
>>> df.count()
>>> exit()- 提交任务到 YARN
# 计算 Pi 值
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 10第七章:集群验证与常用命令
7.1 完整启动顺序
在日常使用中,请严格按照以下顺序启动服务,确保各组件依赖关系正确:
- 启动 ZooKeeper
zkServer.sh start- 启动 Hadoop HDFS 和 YARN
start-dfs.sh
start-yarn.sh- 等待 HDFS 退出安全模式(可选,但建议)
hdfs dfsadmin -safemode wait- 启动 HBase(如需使用)
start-hbase.sh- 启动 Hive Metastore 服务(可选,用于远程连接)
hive --service metastore &-
使用 Spark
Spark 无需单独启动服务,直接使用spark-shell、pyspark或通过spark-submit提交任务即可。
7.2 一键启动脚本(推荐)
为了避免每次手动启动多个服务,可以创建一个整合的启动脚本 start-all.sh。以下脚本已包含环境变量设置、服务状态检查和等待逻辑,确保启动过程稳健可靠。
创建脚本
vim ~/start-all.sh脚本内容
#!/bin/bash
# 大数据服务启动脚本(适配教程稳定版)
# 设置环境变量(根据实际路径修改)
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin
echo ">>> 启动 ZooKeeper ..."
zkServer.sh start
if [ $? -ne 0 ]; then
echo "ZooKeeper 启动失败!"
exit 1
fi
sleep 3
echo ">>> 启动 Hadoop HDFS ..."
start-dfs.sh
echo ">>> 启动 Hadoop YARN ..."
start-yarn.sh
echo ">>> 等待 HDFS 退出安全模式 ..."
hdfs dfsadmin -safemode wait
echo ">>> HDFS 已就绪"
echo ">>> 启动 HBase ..."
start-hbase.sh
sleep 5 # 等待 HBase 完成初始化
echo ">>> 所有服务启动完成。"
echo ">>> 当前 Java 进程:"
jps | grep -E 'NameNode|DataNode|ResourceManager|NodeManager|HMaster|HRegionServer|QuorumPeerMain'赋予执行权限
chmod +x ~/start-all.sh运行脚本
./start-all.sh如果需要全局使用,可以将脚本复制到 /usr/local/bin 并重命名:
sudo cp ~/start-all.sh /usr/local/bin/start-all
sudo chmod +x /usr/local/bin/start-all之后在任何目录下直接执行 start-all 即可。
7.3 一键停止脚本
对应的停止脚本 stop-all.sh 应按照与启动相反的顺序停止服务,同样建议包含环境变量以保证命令可用。
创建脚本
vim ~/stop-all.sh脚本内容
#!/bin/bash
# 大数据服务停止脚本(适配教程稳定版)
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin
echo ">>> 停止 HBase ..."
stop-hbase.sh
sleep 3
echo ">>> 停止 Hadoop YARN ..."
stop-yarn.sh
sleep 2
echo ">>> 停止 Hadoop HDFS ..."
stop-dfs.sh
sleep 2
echo ">>> 停止 ZooKeeper ..."
zkServer.sh stop
echo ">>> 所有服务停止完成。"
echo ">>> 剩余 Java 进程:"
jps | grep -E 'NameNode|DataNode|ResourceManager|NodeManager|HMaster|HRegionServer|QuorumPeerMain' || echo "无相关进程"同样赋予执行权限,并可选择放入 /usr/local/bin。
7.4 可选:启动 Hive Metastore 服务
如果需要在远程连接 Hive(例如通过 JDBC 或 Beeline),可以单独启动 Hive Metastore 服务。在 HBase 启动后执行:
nohup hive --service metastore > /dev/null 2>&1 &但大多数情况下,直接使用 Hive CLI 会通过本地模式连接元数据,无需额外启动服务。
7.5 使用建议
- 每次重启操作系统后,只需运行
start-all即可恢复所有服务。 - 停止服务时运行
stop-all。 - 若个别组件未按预期启动,可查看对应日志(位于各组件
logs目录)进行排查。 - 脚本中的环境变量路径应与您的实际安装路径一致,本教程示例路径已适用。
通过以上脚本,您可以极大简化日常集群的管理操作,更专注于大数据应用开发。
7.1 完整启动顺序
7.2 一键启动脚本示例
创建一个 start-all.sh 脚本方便操作:
#!/bin/bash
echo "Starting ZooKeeper..."
zkServer.sh start
echo "Starting Hadoop HDFS..."
start-dfs.sh
echo "Starting Hadoop YARN..."
start-yarn.sh
echo "Waiting for 10 seconds for HDFS to be safe..."
sleep 10
echo "Starting HBase..."
start-hbase.sh
echo "All services started."第八章:避坑指南——那些年我们踩过的坑
在搭建这套大数据平台的过程中,我几乎把每个组件的“脾气”都摸了一遍。为了让你少走弯路,这里整理了一份实战级避坑手册,每一个坑都是我用头发换来的经验。
1. JAVA_HOME not set——最基础也最容易忽略的坑
现象:启动 Hadoop 或 HBase 时,终端无情地抛出 JAVA_HOME is not set。
原因:虽然你在 /etc/profile 里配置了环境变量,但 Hadoop 的启动脚本(如 hadoop-env.sh)在执行时并不会继承登录 shell 的环境变量。
解决方案:
-
一定要在
hadoop-env.sh和hbase-env.sh中 显式 声明JAVA_HOME,不要偷懒只依赖系统变量。
# 在 $HADOOP_HOME/etc/hadoop/hadoop-env.sh 中
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 在 $HBASE_HOME/conf/hbase-env.sh 中同样加上-
验证:启动后执行
jps看到各进程,或者查看对应日志确认。
经验:即使你在命令行里 echo $JAVA_HOME 能打印出路径,也不代表所有子进程都能拿到。这是 Linux 环境变量继承的经典问题,所有依赖 Java 的守护进程脚本里,最好都显式设置一次。
2. HDFS 处于安全模式(Safe mode)——刚启动时的“假死”状态
现象:执行 hdfs dfs -mkdir /test 时报错 Cannot create directory... Name node is in safe mode。
原因:NameNode 启动后默认进入安全模式,在此期间它只接收读请求,不接受写操作,直到它从 DataNode 收到足够多的数据块报告,确认数据块副本数达到阈值。
解决方案:
- 佛系等待:一般 30 秒左右自动退出。
- 主动干预:
hdfs dfsadmin -safemode leave # 强制离开安全模式- 检查状态:
hdfs dfsadmin -safemode get # 查看当前是否在安全模式注意:如果你刚格式化 NameNode 并第一次启动,安全模式是正常的。如果长时间不退,可能是 dfs.replication 设置为大于集群实际 DataNode 数量的值,调整配置即可。
3. HBase 启动失败——最常见的“Server is not running yet”
现象:jps 能看到 HMaster 和 HRegionServer 进程,但进入 HBase Shell 执行 status 时报错 Server is not running yet。
原因:HBase 2.4.x 与 Hadoop 3.3.x 组合下,默认的异步 WAL(Write-Ahead Log)存在兼容性问题,导致 HMaster 初始化卡住。
解决方案:
-
禁用异步 WAL:在
hbase-site.xml中添加:
<property>
<name>hbase.wal.async.enabled</name>
<value>false</value>
</property>
-
确认 HDFS 根目录:确保 HDFS 上
/hbase目录已创建且可写:
hdfs dfs -mkdir /hbase
hdfs dfs -chmod 755 /hbase-
检查 ZooKeeper 连接:
zkServer.sh status必须显示Mode: standalone(单机)。 -
查看日志:
tail -f /usr/local/hbase/logs/hbase-hadoop-master-ubuntu.log,等待看到Master has completed initialization后再进入 Shell。
经验:如果你用 HBase 自带的 ZooKeeper(HBASE_MANAGES_ZK=true),也可能遇到端口冲突或数据目录问题。本教程采用独立 ZooKeeper 是最稳的。
4. Hive 元数据连接失败——MySQL 驱动的“最后一公里”
现象:执行 schematool -dbType mysql -initSchema 时报错 Access denied 或 Public Key Retrieval is not allowed。
原因:MySQL 8.0 对连接参数要求更严格,且驱动类名发生了变化。
解决方案:
- 使用正确的驱动 JAR:从 Maven 中央仓库下载(避免官网 404):
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
cp mysql-connector-j-8.0.33.jar $HIVE_HOME/lib/-
确保
hive-site.xml中的连接参数正确:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value> <!-- 注意驱动类名变了 -->
</property>
- 检查 MySQL 用户权限:
GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%' IDENTIFIED BY 'hive';
FLUSH PRIVILEGES;避坑提示:如果之前初始化过但失败了,需要先删库重建:
DROP DATABASE metastore;
CREATE DATABASE metastore CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;5. ZooKeeper 无法启动——数据目录和端口的“双杀”
现象:zkServer.sh start 后进程立即消失,或 zkServer.sh status 报错 Error contacting service。
原因:
-
dataDir目录不存在或权限不足。 - 端口 2181 已被其他进程占用。
解决方案: - 创建数据目录:
mkdir -p /usr/local/zookeeper/data
chown -R hadoop:hadoop /usr/local/zookeeper- 检查端口占用:
netstat -tulpn | grep 2181如果被占用,要么杀掉占用进程,要么修改 zoo.cfg 中的 clientPort 为其他端口(但后续 HBase 也要相应修改)。
-
验证配置:
zoo.cfg中的路径必须绝对路径,不能有~符号。
经验:ZooKeeper 的日志默认输出到控制台,但也可以通过 zkServer.sh start-foreground 启动来实时查看错误信息,调试利器!
6. 端口占用——那些你意想不到的“冲突”
现象:启动 Hadoop 或 HBase 时,日志中出现 Address already in use。
原因:Hadoop 3.x 默认端口与老版本不同,但仍可能被系统其他服务占用。
常用端口列表(务必记牢):
|
组件 |
服务 |
端口 |
说明 |
|
Hadoop HDFS |
NameNode Web UI |
9870 |
原 50070 |
|
NameNode RPC |
9000 |
fs.defaultFS 默认值 |
|
|
DataNode Web UI |
9864 |
||
|
Hadoop YARN |
ResourceManager Web |
8088 |
|
|
NodeManager Web |
8042 |
||
|
HBase |
HMaster Web UI |
16010 |
|
|
HRegionServer Web |
16030 |
||
|
ZooKeeper |
客户端端口 |
2181 |
|
|
Hive Metastore |
Thrift 服务 |
9083 |
可选 |
排查命令:
sudo netstat -tulpn | grep -E '9870|9000|8088|16010|2181'如果端口被占用,可以修改相应配置文件中的端口号,但要注意组件间的引用一致性(如 HBase 的 ZooKeeper 端口必须与 ZooKeeper 实际端口一致)。
7. 附加题:Hive 临时目录变量解析失败(血泪教训)
现象:启动 Hive 时抛出异常 java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir}。
原因:Hive 默认配置文件中使用了 ${system:java.io.tmpdir} 这类变量,但在某些环境下无法被正确解析。
解决方案:
-
在
hive-site.xml中显式覆盖这些临时目录配置,使用${user.name}和绝对路径:
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/hive/${user.name}</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive/${hive.session.id}_resources</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/tmp/hive/${user.name}</value>
</property>
- 提前创建目录并设置权限:
sudo mkdir -p /tmp/hive
sudo chmod 1777 /tmp/hive # 类似 /tmp 的粘滞位权限8. Spark 启动时主机名解析警告——可以忽略但影响美观
现象:启动 spark-shell 时出现 WARN util.Utils: Your hostname, ubuntu resolves to a loopback address: 127.0.1.1。
原因:Ubuntu 默认将主机名映射到 127.0.1.1,Spark 在尝试绑定 Web UI 时可能找不到合适的网卡。
解决方案:
- 忽略:不影响任何功能,可无视。
-
消除警告:在
/etc/hosts中添加一条本机真实 IP 的映射:
192.168.x.x ubuntu或者设置环境变量 SPARK_LOCAL_IP 指定 IP。
9. 配置文件语法错误——看不见的“杀手”
现象:启动时抛出类似 com.ctc.wstx.exc.WstxParsingException: Illegal character entity 的 XML 解析异常。
原因:从网页复制配置文件时,带入了不可见控制字符(如 0x8)。
解决方案:
-
使用
xmllint验证:
sudo apt install libxml2-utils -y
xmllint /path/to/hive-site.xml # 若输出无错误,说明格式正确- 重建文件:从模板重新复制,并手动输入关键配置,避免复制粘贴。
-
检查非法字符:可用
cat -A 文件名查看,正常换行应为$,如果出现^@等符号说明有控制字符。
10. 环境变量加载失败——新终端里命令找不到的烦恼
现象:明明已经按照教程把 HADOOP_HOME、HBASE_HOME 等路径添加到了 /etc/profile,也执行了 source /etc/profile 让当前终端生效。但当你欢快地关掉终端,再打开一个新的终端窗口,输入 start-hbase.sh 却得到冷酷的 command not found,而执行 source /etc/profile 后又恢复正常。
原因:这是一个典型的 Linux 环境变量加载机制 问题。/etc/profile 是系统级的全局配置文件,但它只在登录 shell(login shell)启动时自动加载一次。而你新开的终端窗口(比如在图形界面里按 Ctrl+Alt+T 打开的)通常是非登录 shell,它不会再次读取 /etc/profile,因此你在那里设置的 PATH 扩展也就不生效了。
换句话说:/etc/profile 的修改不会自动广播到所有已经存在或新建的终端。
解决方案:
将环境变量的配置写入 ~/.bashrc 文件中,因为 ~/.bashrc 会被每一个交互式非登录 shell 自动加载,这才是用户自定义环境的“永久居所”。
具体操作:
- 打开
~/.bashrc文件:
vim ~/.bashrc- 在文件末尾添加所有大数据组件的环境变量(根据你的实际路径):
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export ZOOKEEPER_HOME=/usr/local/zookeeper
export HIVE_HOME=/usr/local/hive
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin- 保存退出,然后执行
source ~/.bashrc使当前终端立即生效。 - 以后打开的任何新终端,这些变量都会自动就位,再也不用
source /etc/profile了。
经验:
- 可以通过
echo $0查看当前 shell 类型:输出-bash是登录 shell,输出bash是非登录 shell。登录 shell 会读取/etc/profile和~/.profile,而非登录 shell 只读~/.bashrc。 - 如果你坚持要把变量放在
/etc/profile里,那么每次修改后,所有已打开的终端都不会自动更新,必须手动source;而新开的终端如果是登录 shell(比如通过 SSH 登录),则会自动加载,但图形界面下的新终端通常不是登录 shell,所以依然无效。 - 为了彻底统一,建议把所有用户级别的环境变量都写在
~/.bashrc里,系统级的配置(如需要所有用户生效)才放/etc/profile。 - 你已经创建的
start-all.sh和stop-all.sh脚本里显式导出了环境变量,所以它们在任何终端下都能运行,不受此问题影响。这再次证明了脚本中主动设置环境变量的重要性。
延伸思考:为什么脚本里要重新 export 一次环境变量?因为脚本执行时是在一个子 shell 中,它可能无法继承父 shell 的所有变量。所以在脚本开头重复设置关键变量,是保证脚本在任何环境下都能独立运行的最佳实践。
写在最后
大数据平台搭建就像组装一台精密的仪器,每个螺丝都要拧到位。以上问题覆盖了 90% 的初学者障碍,如果你遇到了其他“灵异事件”,不妨先去各组件 logs 目录下看一眼错误日志,那里往往藏着真相。记住:日志是最好的老师,Google 是最好的助教。祝你在 Big Data 的世界里越走越远!
© 版权声明
文章版权归作者所有,未经允许请勿转载。