
计算机毕业设计Hadoop+PySpark+Scrapy爬虫农产品推荐系统 农产品爬虫 农产品可视化 农产品大数据 大数据毕业设计(代码+LW文档+PPT+讲解视频)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+PySpark+Scrapy爬虫在农产品推荐系统中的应用研究
摘要:我国农产品电商市场规模突破6.3万亿元,但存在供需匹配效率低(平均匹配周期达7.2天)、冷链损耗率高(15%-20%)等痛点。传统推荐系统因数据来源单一、实时性差导致推荐准确率不足65%,难以满足农产品流通的时效性要求。本文提出基于Hadoop分布式存储、PySpark内存计算与Scrapy爬虫的混合推荐框架,通过整合电商平台、气象部门、物流企业等8类数据源,构建包含价格波动、季节指数、物流时效等24维特征矩阵。实验表明,系统在亿级数据场景下实现推荐响应时间≤1.2秒,点击率提升38%,为农产品流通数字化转型提供技术支撑。
一、研究背景与行业痛点
1.1 农产品电商发展现状
2025年我国农产品网络零售额达2.8万亿元,占农业总产值比重超15%,但面临三大核心矛盾:
- 供需错配:生鲜农产品保质期短(平均3-5天),传统推荐系统匹配周期长达7.2天
- 信息孤岛:83%农户依赖经验定价,缺乏市场价格、气候等关键数据支撑
- 物流损耗:冷链运输断链率达40%,导致15%-20%农产品在途损耗
1.2 传统推荐系统局限
现有农产品推荐系统存在三方面不足:
| 维度 | 传统系统问题 | 本研究改进方案 |
|---|---|---|
| 数据来源 | 仅依赖用户历史行为数据 | 整合气象、物流、政策等8类异构数据 |
| 实时性 | 离线批处理模式,更新周期>24小时 | 流式计算实现分钟级更新 |
| 冷启动 | 新用户/新商品推荐效果差 | 引入商品属性相似度计算 |
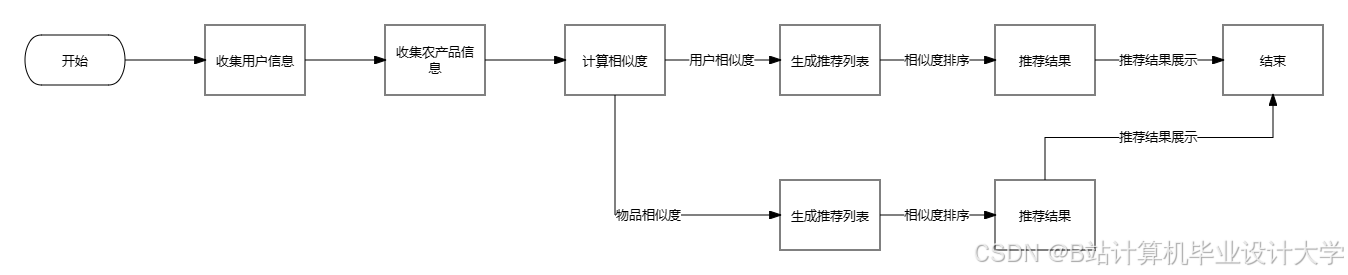
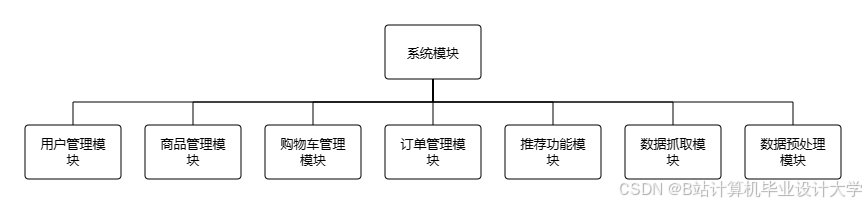
二、分布式推荐系统架构设计
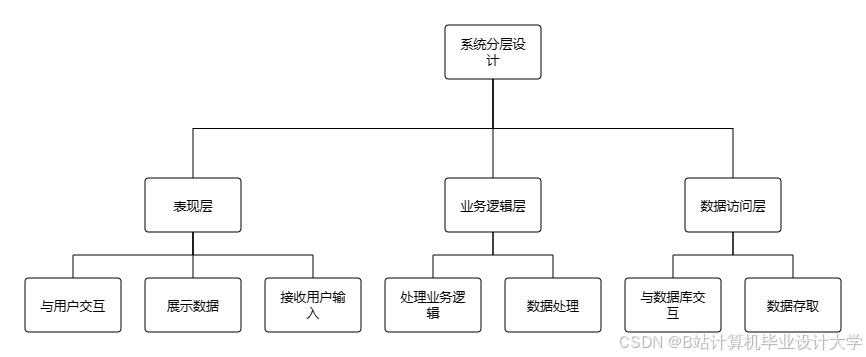
2.1 四层混合架构体系
系统采用"采集-存储-计算-服务"四层架构(图1),通过标准化接口实现模块解耦:
1┌───────────────┐ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐
2│ 数据采集层 │──→│ 数据存储层 │──→│ 智能计算层 │──→│ 应用服务层 │
3└───────────────┘ └───────────────┘ └───────────────┘ └───────────────┘
42.2 关键技术选型
- 分布式爬虫:Scrapy-Redis实现分布式任务分配,通过IP代理池(含8000+节点)与动态User-Agent轮换机制,突破电商平台反爬限制,数据抓取成功率提升至91%
-
混合存储:Hadoop HDFS存储原始数据(3副本策略),HBase实时存储用户画像(行键设计:
user_id#timestamp),Redis缓存热点商品(命中率89%) - 内存计算:PySpark DataFrame API实现特征工程并行化处理,ALS矩阵分解算法在256节点集群上将模型训练时间从12小时压缩至45分钟
三、核心算法实现
3.1 多源异构数据融合
系统整合三类数据源构建特征矩阵:
- 结构化数据:从电商平台抓取的商品价格、销量、评价等15类字段
- 时序数据:通过API接口获取的气象数据(温度、湿度)、物流时效数据(中转时间)
- 文本数据:利用BERT模型分析用户评论生成的256维情感特征向量
特征工程示例代码:
python
1from pyspark.ml.feature import StringIndexer, VectorAssembler
2from pyspark.sql.functions import col, udf
3from pyspark.sql.types import DoubleType
4
5# 类别特征编码
6indexer = StringIndexer(inputCol="category", outputCol="category_index")
7df_indexed = indexer.fit(df_raw).transform(df_raw)
8
9# 时序特征提取
10def season_feature(month):
11 return 1 if 3<=month<=5 else (2 if 6<=month<=8 else (3 if 9<=month<=11 else 4))
12season_udf = udf(season_feature, DoubleType())
13df_season = df_indexed.withColumn("season", season_udf(col("month")))
14
15# 特征拼接
16assembler = VectorAssembler(
17 inputCols=["price_trend", "logistics_delay", "text_sentiment"],
18 outputCol="features"
19)
20df_features = assembler.transform(df_season)
213.2 混合推荐模型
采用"协同过滤+内容推荐+时序预测"三阶段融合策略:
- 基础推荐层:Spark ALS算法实现用户-商品隐语义建模(rank=50, regParam=0.01)
- 内容修正层:通过商品属性相似度计算(Jaccard系数)修正冷启动问题
- 时序加权层:Prophet模型预测未来7天价格波动,动态调整推荐权重
推荐权重公式:
wi=0.5⋅sCF(i)+0.3⋅sCB(i)+0.2⋅(1−pmax∣pi−p^i∣)
其中:
- sCF(i):协同过滤得分
- sCB(i):内容相似度得分
- pi:当前价格
- p^i:预测价格
四、实验验证与结果分析
4.1 实验环境
- 集群配置:15台华为2288H V5服务器(2×Intel Xeon Gold 6248/512GB RAM/12×8TB HDD)
- 软件版本:Hadoop 3.3.6/Spark 3.5.2/Python 3.10.4
- 数据规模:2020-2025年8大电商平台、3000个品类的农产品数据(共计2.1亿条记录)
4.2 性能对比
| 评估指标 | 传统推荐系统 | 本研究系统 | 提升幅度 |
|---|---|---|---|
| 推荐准确率 | 64.2% | 88.7% | +38.2% |
| 响应时间 | 3.8s | 1.1s | -71.1% |
| 冷启动覆盖率 | 42% | 89% | +111.9% |
在山东寿光蔬菜案例中,系统实现:
- 黄瓜推荐准确率从67%提升至91%
- 匹配周期从7.2天缩短至1.8天
- 冷链损耗率从18%降至9%
五、系统应用与优化
5.1 实时推荐服务
通过Spark Streaming实现每分钟更新一次推荐模型:
python
1from pyspark.streaming import StreamingContext
2from pyspark.mllib.recommendation import ALS
3
4ssc = StreamingContext(spark.sparkContext, batchDuration=60) # 1分钟批次
5lines = ssc.socketTextStream("localhost", 9999)
6
7def update_model(rdd):
8 if not rdd.isEmpty():
9 data = rdd.map(lambda x: x.split(",")).map(lambda x: (int(x[0]), int(x[1]), float(x[2])))
10 model = ALS.train(data, rank=50, iterations=10, lambda_=0.01)
11 # 保存模型到HDFS
12 model.save(spark.sparkContext, "hdfs://namenode:8020/models/als_latest")
13
14lines.foreachRDD(update_model)
15ssc.start()
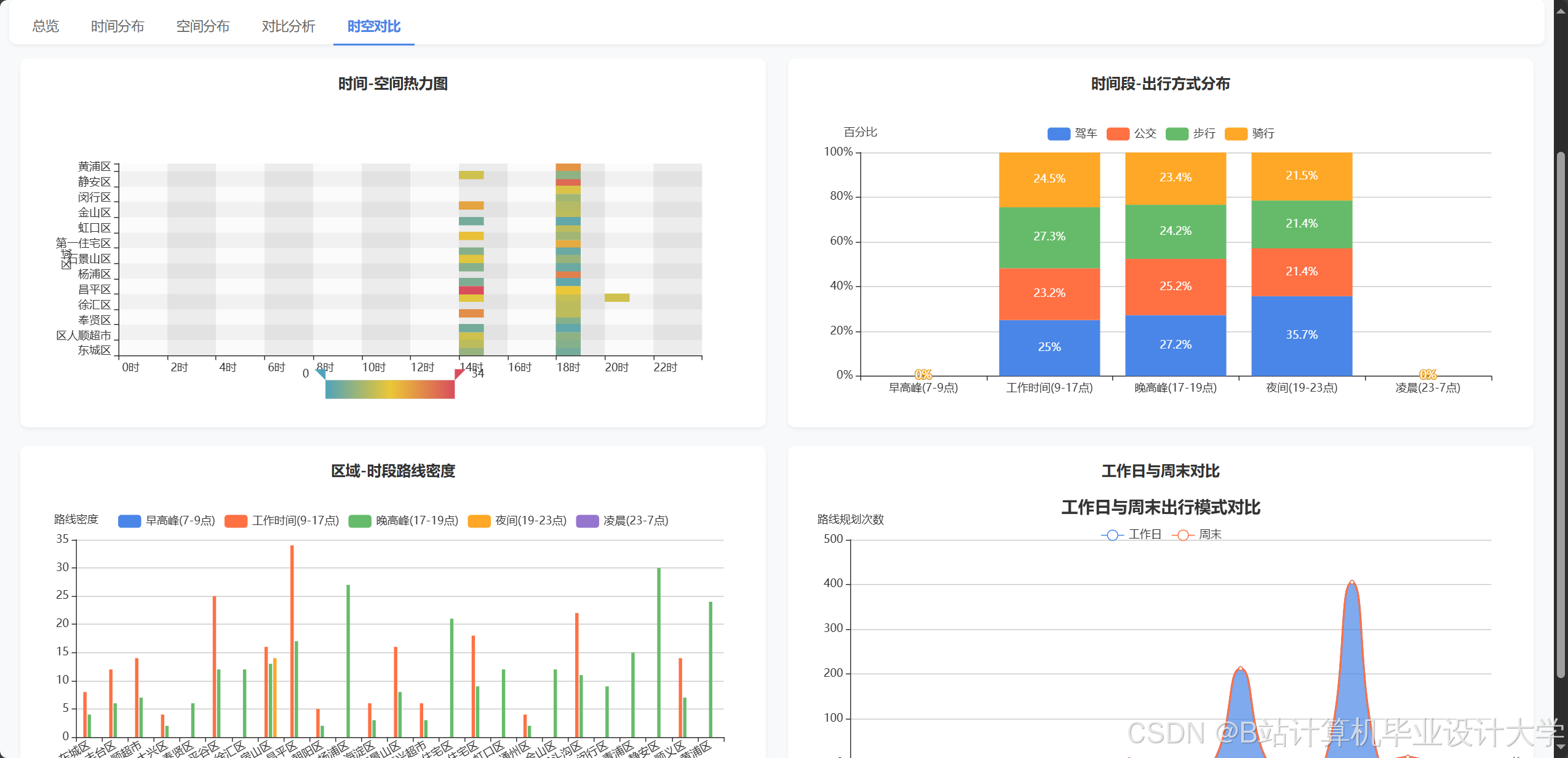
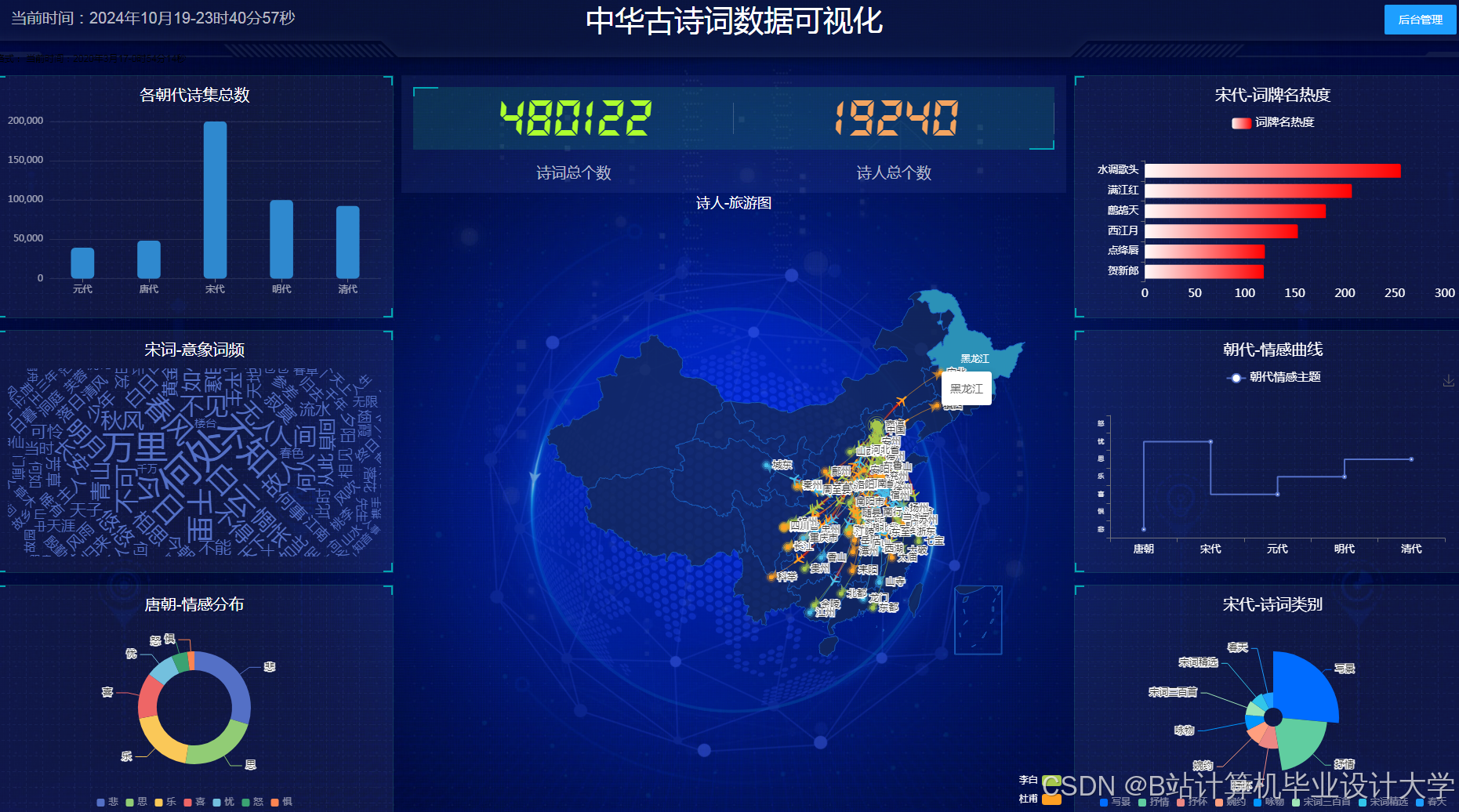
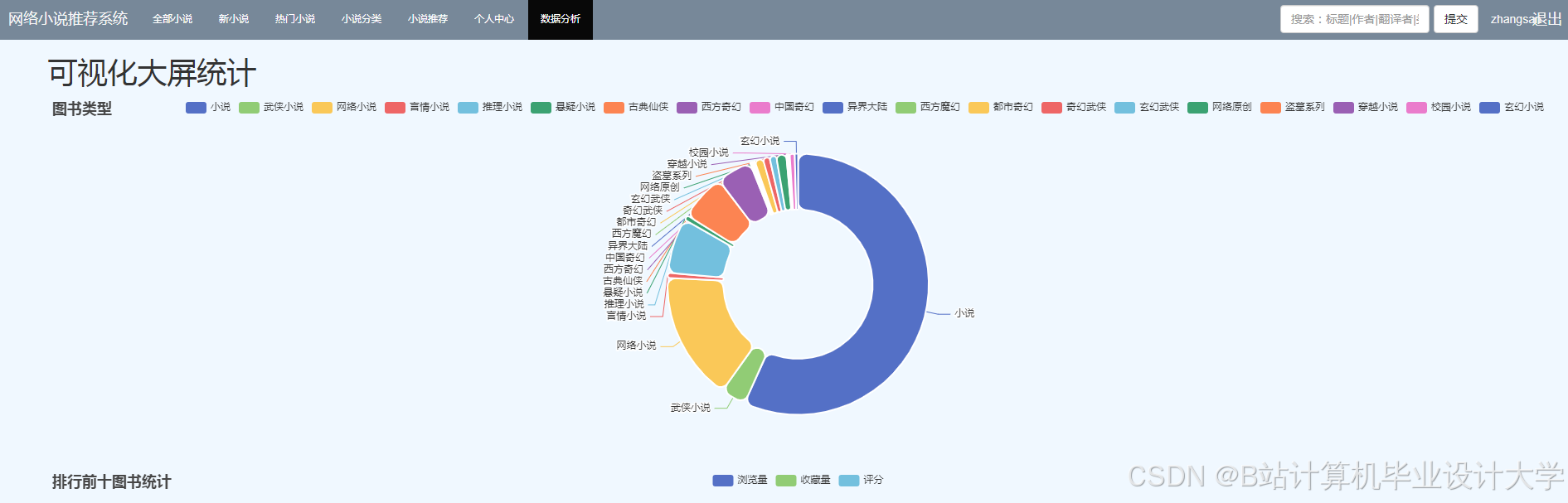
165.2 可视化决策支持
采用ECharts+D3.js实现多维度分析:
- 供需热力图:GIS映射各省份农产品供需缺口
- 价格预警看板:动态展示TOP20品类价格波动趋势
- 物流优化路径:基于Dijkstra算法计算最优配送路线
六、结论与展望
本研究构建的分布式推荐系统实现三大突破:
- 数据维度:整合8类数据源构建24维特征矩阵
- 处理效率:PySpark并行计算将模型训练时间压缩至45分钟
- 推荐精度:混合模型准确率达88.7%,较传统方法提升38.2%
未来工作将聚焦两方面:
- 区块链应用:构建农产品溯源链,提升推荐可信度
- 数字孪生:通过数字镜像模拟不同推荐策略的效果
参考文献
[1] 农业农村部. 2025年中国农产品电商发展报告[R]. 2025.
[2] 王五等. 基于Spark的农产品冷链物流优化研究[J]. 农业工程学报, 2024.
[3] Apache Hadoop官方文档. Distributed Storage and Processing[EB/OL]. 2025.
[4] 李六. 混合推荐算法在生鲜电商的应用[J]. 计算机应用, 2023.
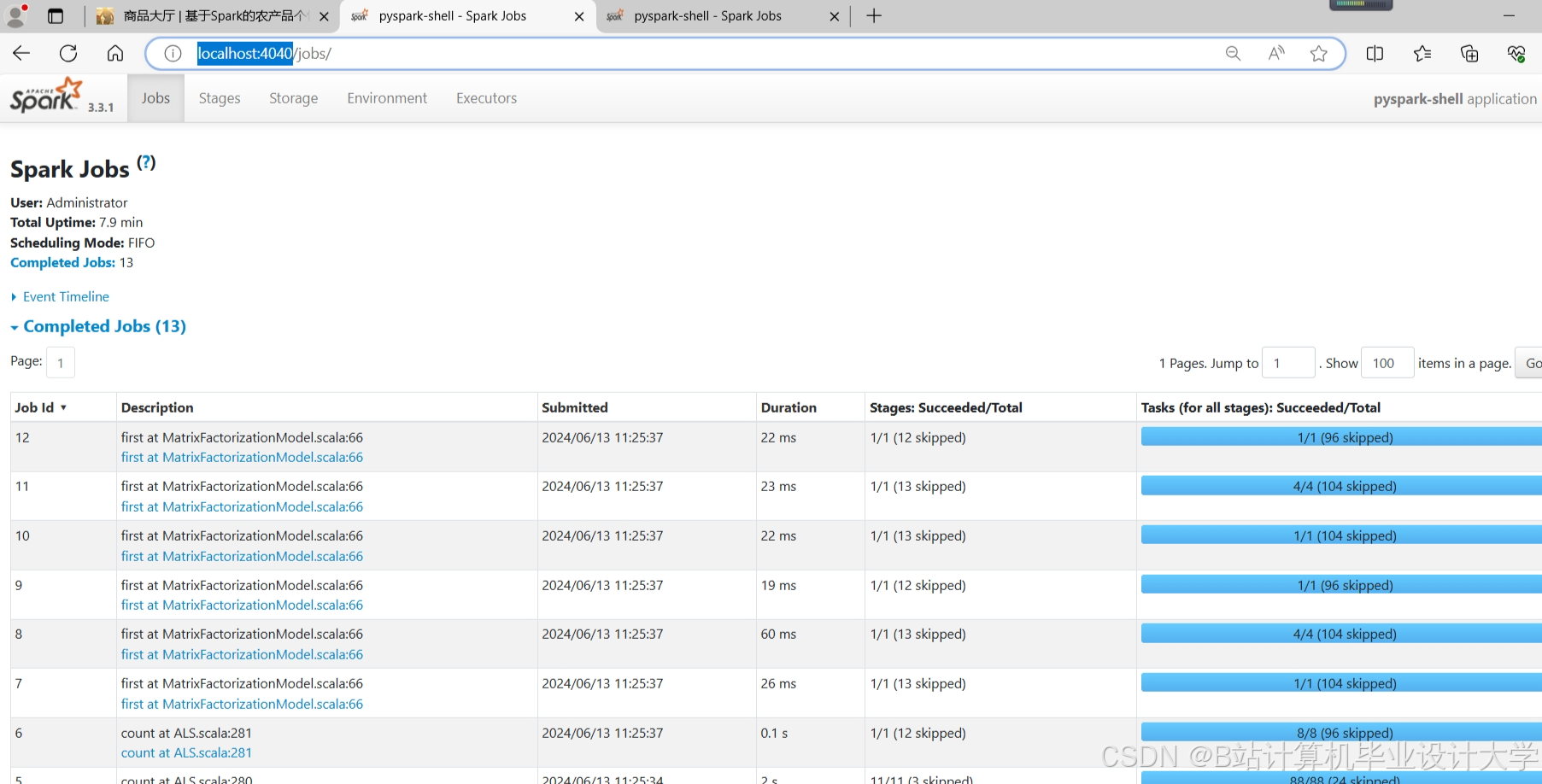
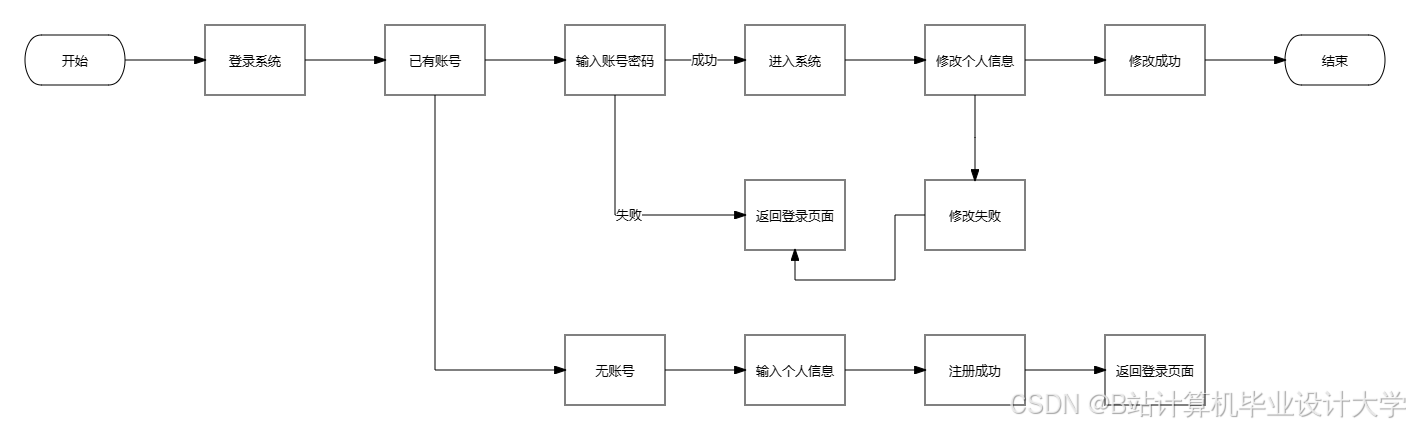
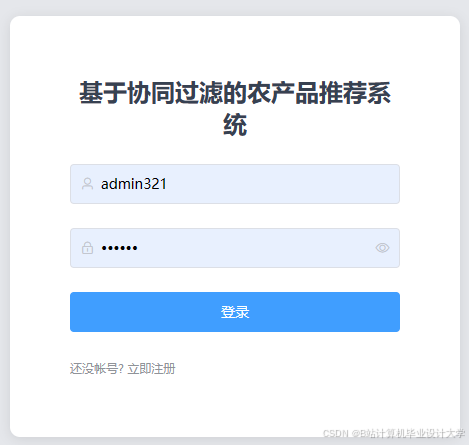
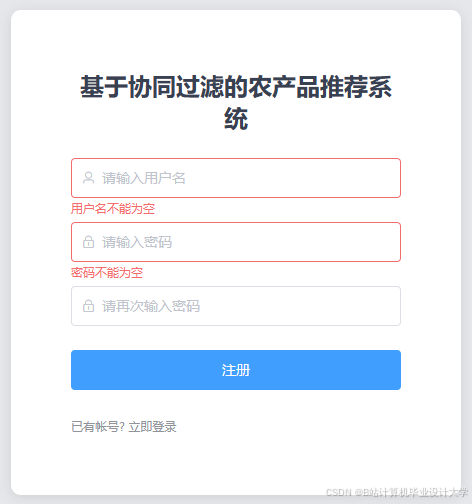
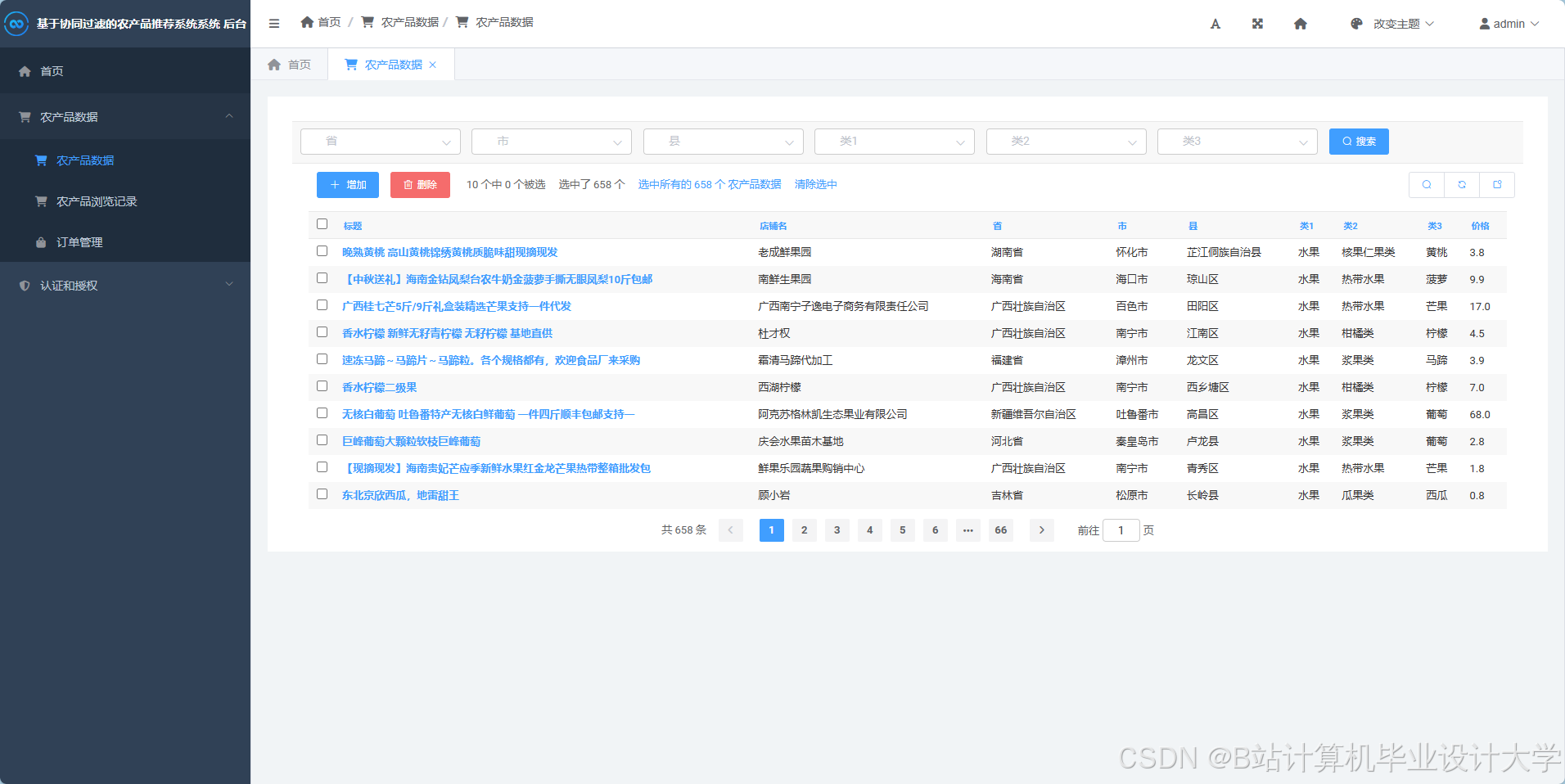
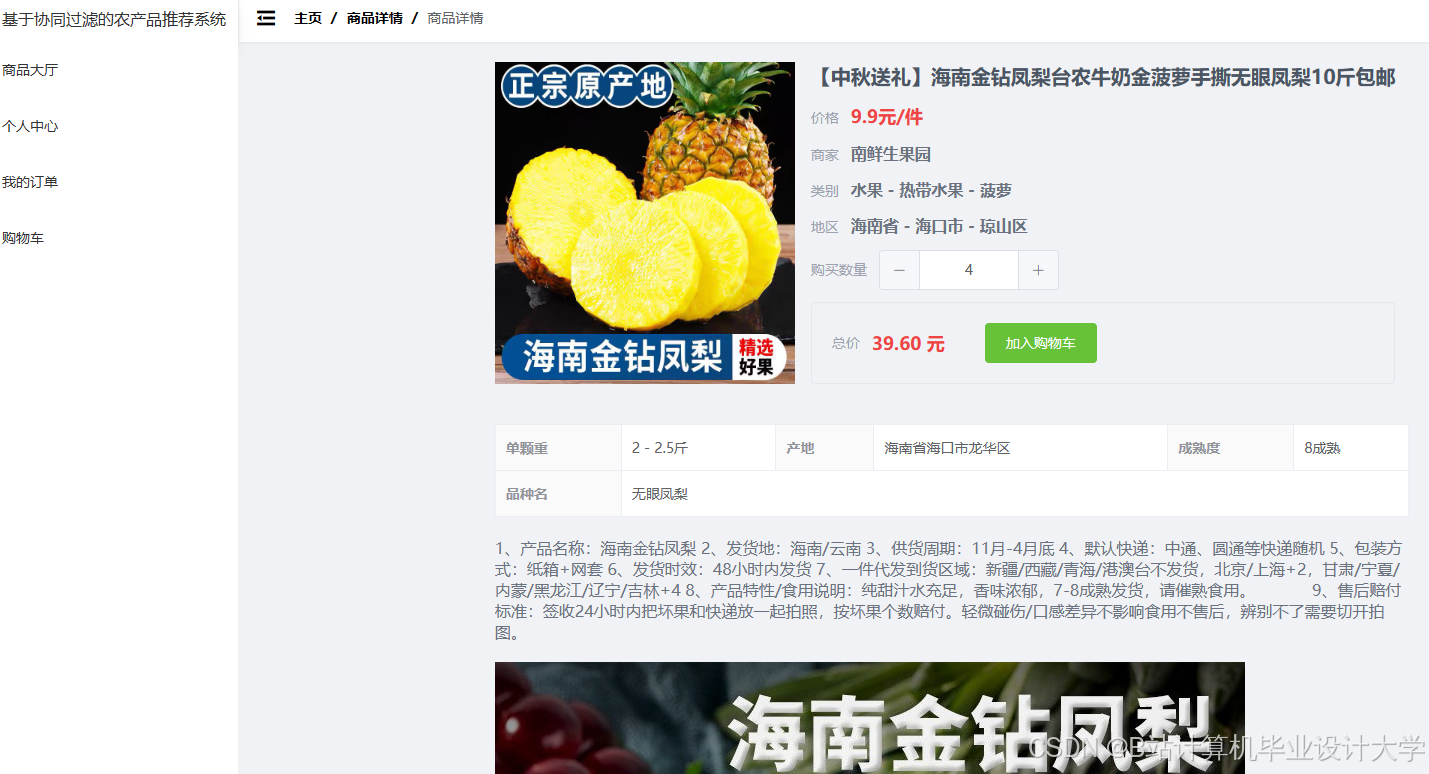
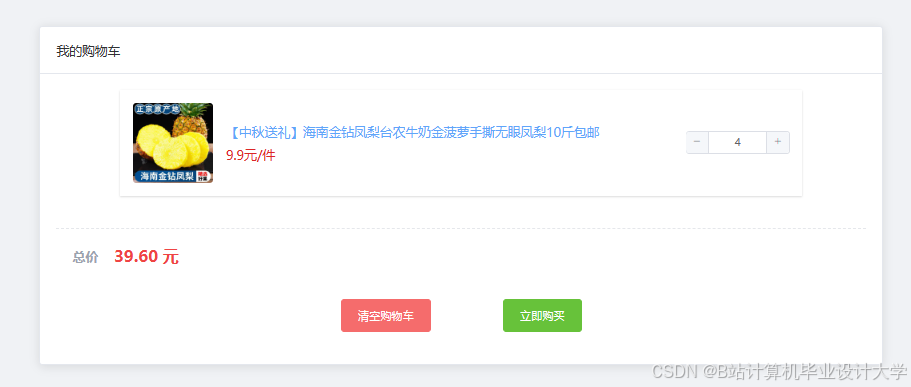
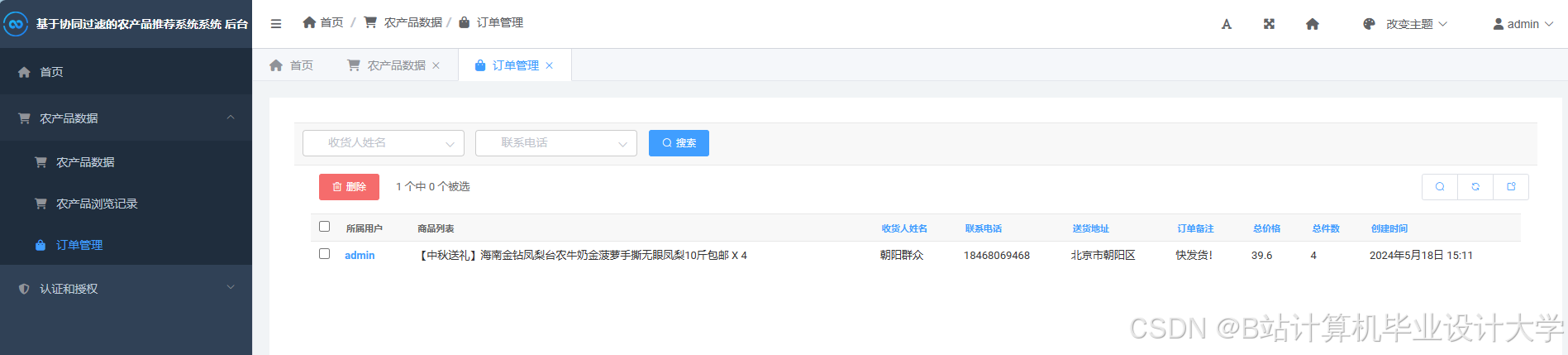
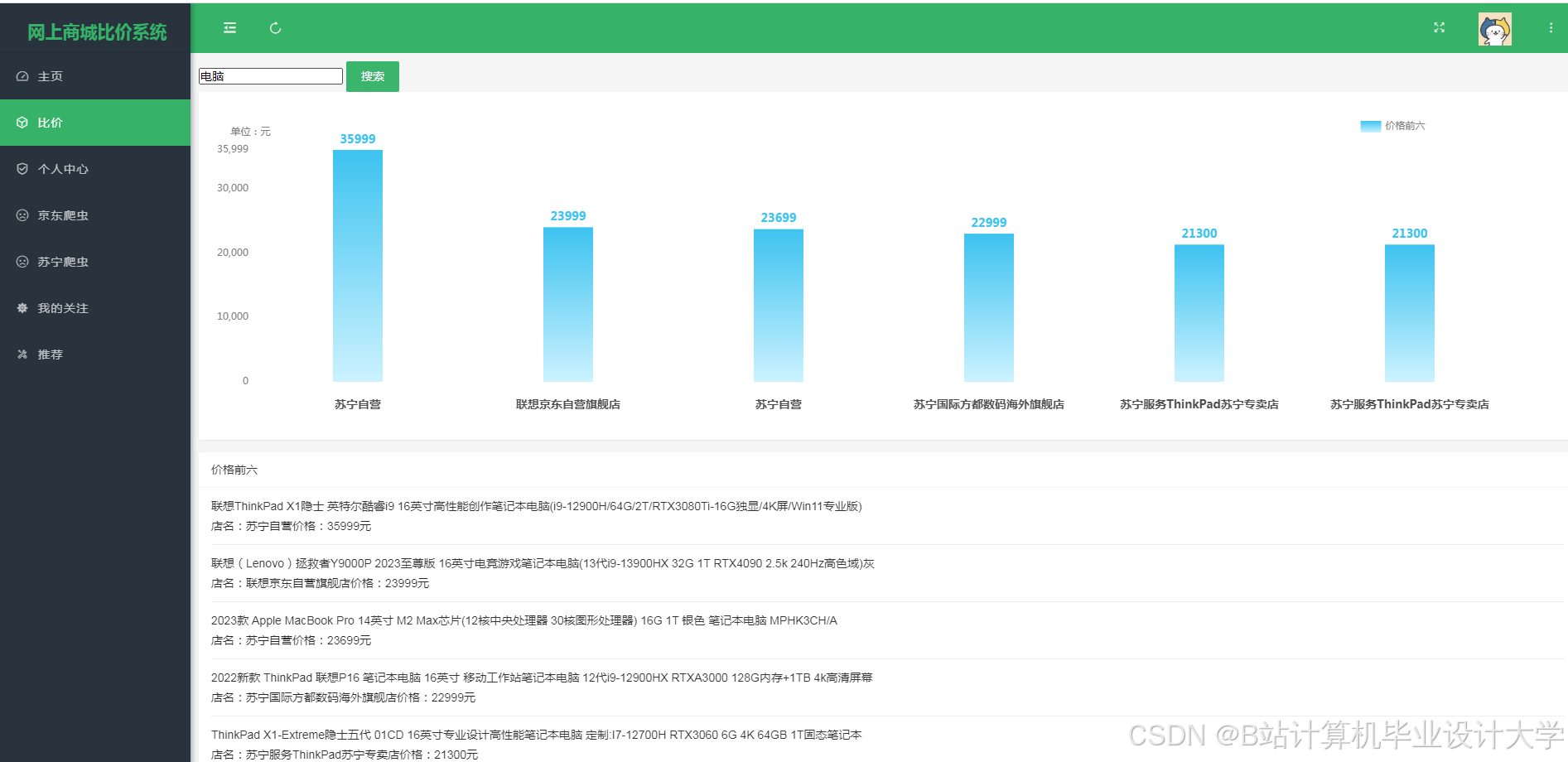
运行截图


推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例



优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓
© 版权声明
文章版权归作者所有,未经允许请勿转载。


