
基于Pyspark的大众点评数据分析和可视化之旅
____simple_html_dom__voku__html_wrapper____>
项目51: 基于pyspark的大众点评数据分析和可视化项目
简介
本项目旨在对从大众点评收集的商家数据进行深度分析和可视化,运用Pyspark高效处理大规模数据集,揭示商家运营的关键趋势。
数据涵盖商家ID、名称、地址、城市、州、邮编、经纬度、星级评分、评论数量、营业状态、属性、类别及营业时间等丰富维度。
通过Pyspark对数据进行清洗、转换和聚合,我们将探索商家类别销量前十、各城市商家分布、评论活跃度、星级评价分布以及外卖服务渗透率等核心业务指标。
最终,借助Matplotlib和Pandas的强大绘图功能,将以直观的柱状图、折线图和饼图形式呈现分析结果,为决策者提供数据驱动的洞察,助力商家优化策略,提升顾客满意度。
Pyspark:用于大数据的分布式计算,实现数据的高效处理与分析。
Matplotlib:数据可视化工具,用于创建高质量的图表。
Pandas:提供高性能、灵活的数据结构和数据分析工具。
JSON:数据格式,用于解析和处理非结构化数据源。
项目目标:分析并可视化商家类别销量TOP10;探究不同城市商家数量分布,识别TOP10城市;展示商家评论次数最多的前八名;揭示商家类别中星级评分最高的前八位。

嘿,各位数据爱好者!今天咱们要一起探索一个超有趣的项目——基于Pyspark的大众点评数据分析和可视化项目。这个项目就像是一把钥匙,能帮我们打开大众点评数据背后的秘密,为商家运营策略的优化提供有力支持。
项目简介
这个项目的目标很明确,就是对从大众点评收集来的商家数据进行深度分析和可视化。大众点评的数据那可丰富得很,涵盖了商家ID、名称、地址、城市、州、邮编、经纬度、星级评分、评论数量、营业状态、属性、类别及营业时间等多个维度。我们会用Pyspark来高效处理这些大规模的数据集,挖掘出商家运营的关键趋势。
所需工具
在这个项目里,我们会用到几个非常实用的工具:
- Pyspark:它可是大数据分布式计算的利器,能让我们高效地处理和分析数据。
- Matplotlib:强大的数据可视化工具,能创建出高质量的图表。
- Pandas:提供高性能、灵活的数据结构和数据分析工具。
- JSON:用于解析和处理非结构化数据源。
项目目标
我们的项目有几个具体的目标:
- 分析并可视化商家类别销量TOP10。
- 探究不同城市商家数量分布,找出TOP10城市。
- 展示商家评论次数最多的前八名。
- 揭示商家类别中星级评分最高的前八位。
代码实现与分析
数据读取与初步处理
首先,我们得读取数据,这里假设数据是以JSON格式存储的。
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder \
.appName("DianpingAnalysis") \
.getOrCreate()
# 读取JSON数据
df = spark.read.json("dianping_data.json")
# 查看数据基本信息
print("数据基本信息:")
df.printSchema()
# 查看数据集行数
rows, columns = df.count(), len(df.columns)
if rows < 1000000:
# 小数据量(行数少于100万)查看全量数据信息
print("数据全部内容信息:")
print(df.to_csv(sep="\t", na_rep="nan"))
else:
# 大数据量查看数据前几行信息
print("数据前几行内容信息:")
print(df.head().to_csv(sep="\t", na_rep="nan"))代码分析:
- 我们先创建了一个
SparkSession,这是使用Pyspark的入口。 - 然后用
spark.read.json方法读取JSON格式的数据。 -
printSchema方法可以让我们了解数据的结构,也就是各个列的名称和数据类型。 - 接着我们统计了数据的行数和列数,根据数据量的大小,选择查看全量数据信息或者前几行数据信息。
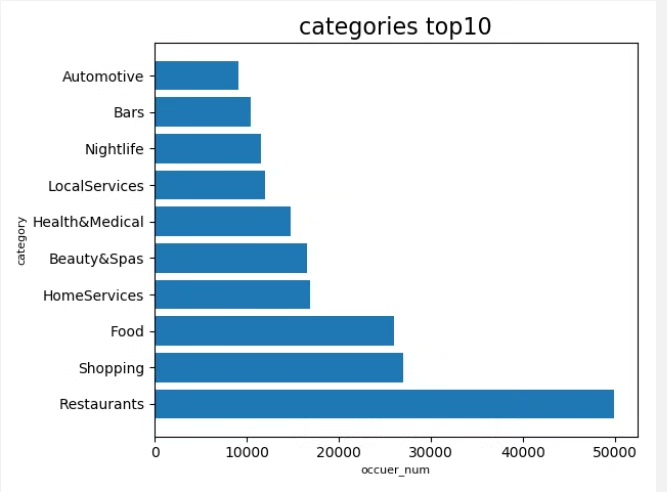
分析商家类别销量TOP10
接下来,我们要找出商家类别销量排名前十的类别。
from pyspark.sql.functions import col
# 按照商家类别进行分组,并对销量进行求和
category_sales = df.groupBy("category") \
.sum("sales") \
.withColumnRenamed("sum(sales)", "total_sales")
# 对总销量进行降序排序,并取前10条记录
top_10_categories = category_sales.orderBy(col("total_sales").desc()) \
.limit(10)
# 将结果转换为Pandas DataFrame,方便后续可视化
top_10_categories_pd = top_10_categories.toPandas()
import matplotlib.pyplot as plt
# 绘制柱状图
plt.bar(top_10_categories_pd["category"], top_10_categories_pd["total_sales"])
plt.xlabel("商家类别")
plt.ylabel("总销量")
plt.title("商家类别销量TOP10")
plt.xticks(rotation=45)
plt.show()代码分析:
- 我们使用
groupBy方法按照商家类别对数据进行分组,然后用sum方法对每个类别的销量进行求和,并将结果列重命名为total_sales。 - 接着使用
orderBy方法对总销量进行降序排序,再用limit方法取前10条记录。 - 把结果转换为Pandas DataFrame,这是因为Matplotlib更适合处理Pandas DataFrame的数据。
- 最后,我们用Matplotlib绘制了柱状图,直观地展示了商家类别销量TOP10。
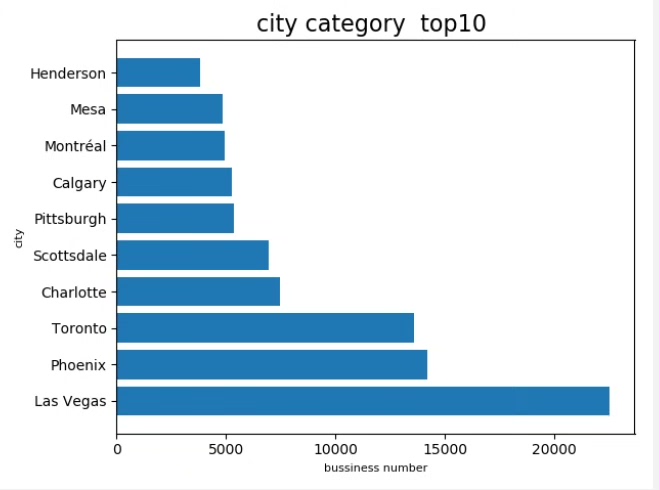
探究不同城市商家数量分布,识别TOP10城市
下面我们来看看不同城市的商家数量分布,找出商家数量最多的前10个城市。
# 按照城市进行分组,并统计每个城市的商家数量
city_counts = df.groupBy("city") \
.count() \
.withColumnRenamed("count", "num_businesses")
# 对商家数量进行降序排序,并取前10条记录
top_10_cities = city_counts.orderBy(col("num_businesses").desc()) \
.limit(10)
# 将结果转换为Pandas DataFrame
top_10_cities_pd = top_10_cities.toPandas()
# 绘制柱状图
plt.bar(top_10_cities_pd["city"], top_10_cities_pd["num_businesses"])
plt.xlabel("城市")
plt.ylabel("商家数量")
plt.title("不同城市商家数量TOP10")
plt.xticks(rotation=45)
plt.show()代码分析:
- 这里同样使用
groupBy方法按照城市对数据进行分组,用count方法统计每个城市的商家数量,并将结果列重命名为num_businesses。 - 对商家数量进行降序排序,取前10条记录。
- 转换为Pandas DataFrame后,用Matplotlib绘制柱状图,清晰地展示了不同城市商家数量的TOP10。
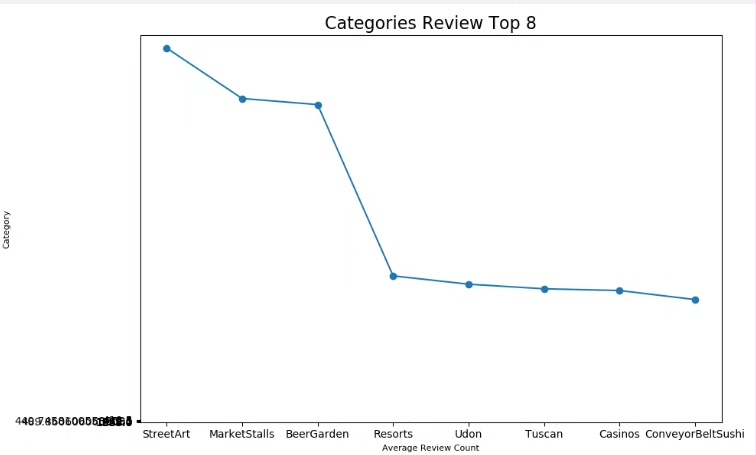
展示商家评论次数最多的前八名
我们继续找出评论次数最多的前8个商家。
# 对评论数量进行降序排序,并取前8条记录
top_8_commented = df.orderBy(col("comment_count").desc()) \
.limit(8)
# 将结果转换为Pandas DataFrame
top_8_commented_pd = top_8_commented.toPandas()
# 绘制柱状图
plt.bar(top_8_commented_pd["business_name"], top_8_commented_pd["comment_count"])
plt.xlabel("商家名称")
plt.ylabel("评论数量")
plt.title("商家评论次数最多的前八名")
plt.xticks(rotation=45)
plt.show()代码分析:
- 直接使用
orderBy方法对评论数量进行降序排序,取前8条记录。 - 转换为Pandas DataFrame后绘制柱状图,这样就能直观地看到哪些商家的评论次数最多啦。
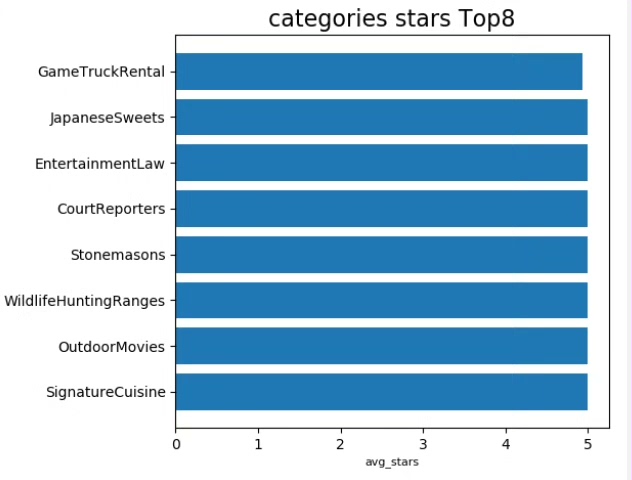
揭示商家类别中星级评分最高的前八位
最后,我们来找出星级评分最高的前8个商家类别。
# 按照商家类别进行分组,并对星级评分进行求平均值
category_ratings = df.groupBy("category") \
.avg("rating") \
.withColumnRenamed("avg(rating)", "average_rating")
# 对平均星级评分进行降序排序,并取前8条记录
top_8_ratings = category_ratings.orderBy(col("average_rating").desc()) \
.limit(8)
# 将结果转换为Pandas DataFrame
top_8_ratings_pd = top_8_ratings.toPandas()
# 绘制柱状图
plt.bar(top_8_ratings_pd["category"], top_8_ratings_pd["average_rating"])
plt.xlabel("商家类别")
plt.ylabel("平均星级评分")
plt.title("商家类别中星级评分最高的前八位")
plt.xticks(rotation=45)
plt.show()代码分析:
- 用
groupBy方法按照商家类别分组,avg方法求每个类别的平均星级评分,并将结果列重命名为average_rating。 - 对平均星级评分进行降序排序,取前8条记录。
- 转换为Pandas DataFrame后绘制柱状图,展示出星级评分最高的前8个商家类别。
总结
通过这个基于Pyspark的大众点评数据分析和可视化项目,我们利用Pyspark高效地处理了大规模的商家数据,借助Matplotlib和Pandas将分析结果以直观的图表形式展示出来。这些分析结果能为商家决策者提供数据驱动的洞察,帮助他们优化运营策略,提升顾客满意度。希望大家也能从这个项目中获得启发,在自己的数据探索之旅中发现更多有趣的东西!
项目51: 基于pyspark的大众点评数据分析和可视化项目
简介
本项目旨在对从大众点评收集的商家数据进行深度分析和可视化,运用Pyspark高效处理大规模数据集,揭示商家运营的关键趋势。
数据涵盖商家ID、名称、地址、城市、州、邮编、经纬度、星级评分、评论数量、营业状态、属性、类别及营业时间等丰富维度。
通过Pyspark对数据进行清洗、转换和聚合,我们将探索商家类别销量前十、各城市商家分布、评论活跃度、星级评价分布以及外卖服务渗透率等核心业务指标。
最终,借助Matplotlib和Pandas的强大绘图功能,将以直观的柱状图、折线图和饼图形式呈现分析结果,为决策者提供数据驱动的洞察,助力商家优化策略,提升顾客满意度。
Pyspark:用于大数据的分布式计算,实现数据的高效处理与分析。
Matplotlib:数据可视化工具,用于创建高质量的图表。
Pandas:提供高性能、灵活的数据结构和数据分析工具。
JSON:数据格式,用于解析和处理非结构化数据源。
项目目标:分析并可视化商家类别销量TOP10;探究不同城市商家数量分布,识别TOP10城市;展示商家评论次数最多的前八名;揭示商家类别中星级评分最高的前八位。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


