ODS到DWD数据清洗实战:基于Spark的高效ETL实现
ODS到DWD数据清洗实战:基于Spark的高效ETL实现
-
- 引言
- 一、ODS与DWD层概述
-
- 1.1 分层定义
- 1.2 清洗流程概览
- 二、核心清洗操作详解
-
- 2.1 数据过滤
- 2.2 数据去重
-
- 2.2.1 去重策略选择
- 2.2.2 去重实现
- 2.3 空值处理
-
- 2.3.1 空值处理策略
- 2.3.2 空值处理实现
- 2.4 格式标准化
-
- 2.4.1 时间格式标准化
- 2.4.2 字符串标准化
- 三、完整清洗流程实现
-
- 3.1 封装清洗函数
- 3.2 执行清洗作业
- 四、性能优化技巧
-
- 4.1 分区策略优化
- 4.2 内存与缓存优化
- 4.3 并行度调优
- 五、数据质量监控
-
- 5.1 质量检查指标
- 5.2 异常数据捕获
- 六、总结
|
🌺The Begin🌺点点关注,收藏不迷路🌺
|
引言
在数据仓库分层架构中,ODS(操作数据存储)层到DWD(数据仓库明细)层的处理是数据治理的关键环节。这一阶段需要对原始数据进行清洗、去重、标准化,形成高质量、可用的明细数据。本文将深入探讨如何利用Spark实现高效、可扩展的ODS→DWD清洗流程。
一、ODS与DWD层概述
1.1 分层定义
| 层次 | 全称 | 数据特征 | 主要作用 |
|---|---|---|---|
| ODS层 | 操作数据存储 | 原始数据,未经过处理,可能存在脏数据、重复数据 | 数据备份、追溯 |
| DWD层 | 数据仓库明细 | 清洗后的明细数据,结构化、标准化 | 提供高质量数据供下游使用 |
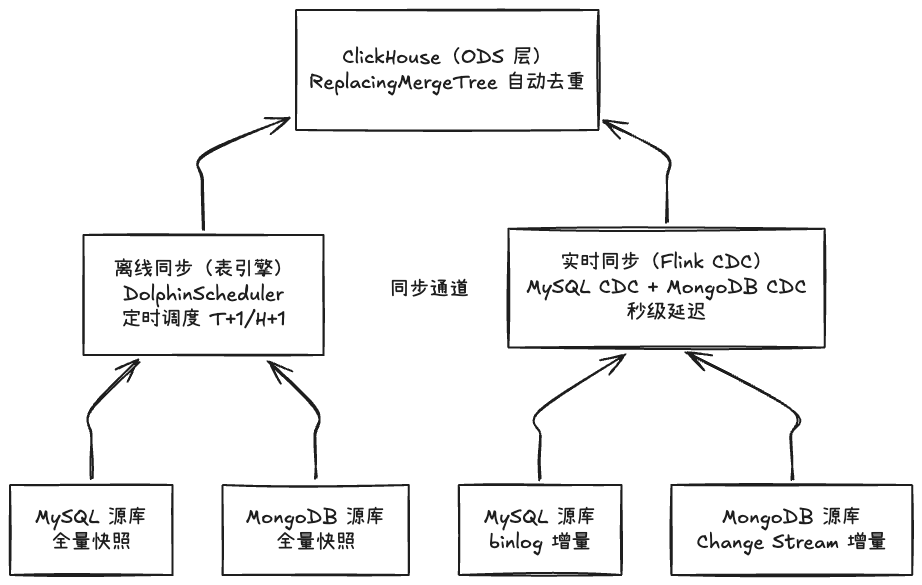
1.2 清洗流程概览
DWD层
清洗过程
ODS层
业务库Binlog
ODS表
日志文件
外部数据
数据过滤
去重处理
空值处理
格式标准化
维度退化
DWD表
数据服务
数据分析
数据挖掘
二、核心清洗操作详解
2.1 数据过滤
数据过滤是清洗的第一步,旨在剔除无效、异常数据。
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("ODS2DWD_Cleaning")
.enableHiveSupport()
.getOrCreate()
// 读取ODS层数据
val odsOrders = spark.table("ods.orders")
// 基础过滤规则
val filteredOrders = odsOrders
// 过滤关键字段为null的记录
.filter(col("order_id").isNotNull)
.filter(col("order_time").isNotNull)
.filter(col("city_id").isNotNull)
// 过滤异常数据
.filter(col("order_amount") > 0) // 金额必须为正
.filter(col("order_amount") < 1000000) // 剔除异常大额
// 过滤时间范围
.filter(col("order_time") >= lit("2024-01-01"))
.filter(col("order_time") <= lit("2024-12-31"))
println(s"过滤后数据量: ${filteredOrders.count()}")
2.2 数据去重
2.2.1 去重策略选择
| 去重级别 | 适用场景 | 代码示例 | 性能影响 |
|---|---|---|---|
| 完全去重 | 所有字段完全重复的记录 | df.dropDuplicates() |
高(需要全字段比较) |
| 指定主键去重 | 业务主键重复(如订单号) | df.dropDuplicates("order_id") |
中 |
| 组合键去重 | 联合主键重复 | df.dropDuplicates("order_id", "city_id") |
中 |
| 时间窗口去重 | 保留最新记录 | 需配合窗口函数 | 高 |
2.2.2 去重实现
// 1. 简单去重(按指定列)
val dedupedOrders = filteredOrders
.dropDuplicates("order_id", "city_id") // 组合键去重
.dropDuplicates("order_id") // 也可以单独调用
// 2. 复杂去重:保留最新记录(使用窗口函数)
import org.apache.spark.sql.expressions.Window
val windowSpec = Window
.partitionBy("order_id") // 按订单号分组
.orderBy(col("update_time").desc) // 按更新时间降序
val latestOrders = filteredOrders
.withColumn("rn", row_number().over(windowSpec))
.filter(col("rn") === 1)
.drop("rn")
// 3. 多条件去重:根据业务规则选择保留
val businessDedup = filteredOrders
.dropDuplicates("order_id") // 先简单去重
.union(
filteredOrders
.filter(col("order_status") === "completed")
.dropDuplicates("order_id", "city_id")
)
.dropDuplicates("order_id") // 最终去重
2.3 空值处理
2.3.1 空值处理策略
| 字段类型 | 处理策略 | 示例 | 说明 |
|---|---|---|---|
| 关键字段 | 直接过滤 | filter(col("id").isNotNull) |
缺少关键信息,无法使用 |
| 数值字段 | 填充默认值 | na.fill(0) |
如金额、数量等 |
| 字符串字段 | 填充"unknown" | na.fill("unknown") |
如备注、描述等 |
| 时间字段 | 填充当前时间 | when(col("ts").isNull, current_timestamp()) |
更新时间 |
2.3.2 空值处理实现
// 1. 单字段空值填充
val cleanedOrders = dedupedOrders
// 数值字段填充0
.na.fill(0, Seq("order_amount", "discount_amount", "shipping_fee"))
// 字符串字段填充默认值
.na.fill("unknown", Seq("driver_id", "passenger_id", "remark"))
// 使用条件填充
.withColumn("payment_method",
when(col("payment_method").isNull, lit("cash"))
.otherwise(col("payment_method"))
)
// 时间字段特殊处理
.withColumn("update_time",
when(col("update_time").isNull, current_timestamp())
.otherwise(col("update_time"))
)
// 2. 批量填充不同类型字段
val fillMap = Map(
"order_amount" -> 0.0,
"discount_amount" -> 0.0,
"driver_id" -> "unknown",
"passenger_phone" -> "",
"remark" -> ""
)
val batchFilled = cleanedOrders.na.fill(fillMap)
// 3. 复杂空值逻辑:业务规则填充
val businessFilled = batchFilled
.withColumn("order_status",
when(col("order_status").isNull,
when(col("pay_time").isNotNull, "paid")
.when(col("complete_time").isNotNull, "completed")
.otherwise("unknown"))
.otherwise(col("order_status"))
)
2.4 格式标准化
2.4.1 时间格式标准化
// 1. 统一时间格式为 yyyy-MM-dd HH:mm:ss
val timeStandardized = batchFilled
// 字符串转时间戳
.withColumn("order_time_std",
when(col("order_time").cast("timestamp").isNotNull,
col("order_time").cast("timestamp"))
.otherwise(to_timestamp(col("order_time"), "yyyy/MM/dd HH:mm:ss"))
)
.withColumn("order_time_std",
when(col("order_time_std").isNotNull, col("order_time_std"))
.otherwise(to_timestamp(col("order_time"), "yyyy-MM-dd HH:mm:ss"))
)
// 提取日期维度
.withColumn("order_date", to_date(col("order_time_std")))
.withColumn("order_hour", hour(col("order_time_std")))
.withColumn("order_week", weekofyear(col("order_time_std")))
.withColumn("order_month", month(col("order_time_std")))
// 删除原始时间列,使用标准化后的
.drop("order_time")
.withColumnRenamed("order_time_std", "order_time")
// 2. 处理时区问题
import java.util.TimeZone
spark.conf.set("spark.sql.session.timeZone", "Asia/Shanghai")
val timezoneFixed = timeStandardized
.withColumn("order_time_utc", to_utc_timestamp(col("order_time"), "Asia/Shanghai"))
2.4.2 字符串标准化
// 1. 统一大小写、去除空格
val stringStandardized = timeStandardized
.withColumn("city_name", upper(trim(col("city_name"))))
.withColumn("province", initcap(trim(col("province"))))
.withColumn("remark", regexp_replace(col("remark"), "\\s+", " "))
// 2. 手机号脱敏处理
val desensitized = stringStandardized
.withColumn("passenger_phone",
when(col("passenger_phone").isNotNull,
concat(
substring(col("passenger_phone"), 1, 3),
lit("****"),
substring(col("passenger_phone"), -4, 4)
))
.otherwise(col("passenger_phone"))
)
// 3. 枚举值标准化
val enumStandardized = desensitized
.withColumn("order_type",
when(lower(col("order_type")).contains("快车"), "express")
.when(lower(col("order_type")).contains("专车"), "premium")
.when(lower(col("order_type")).contains("拼车"), "carpool")
.otherwise("other")
)
三、完整清洗流程实现
3.1 封装清洗函数
// 订单数据清洗类
class OrderDataCleaner(spark: SparkSession) {
import spark.implicits._
/**
* 完整的ODS→DWD清洗流程
*/
def cleanOrders(odsTable: String, dwdTable: String, date: String): Unit = {
val odsDF = spark.table(odsTable)
.filter(col("dt") === date) // 只处理指定日期
// 步骤1:数据过滤
val filtered = filterOrders(odsDF)
// 步骤2:数据去重
val deduped = deduplicateOrders(filtered)
// 步骤3:空值处理
val nullFilled = handleNulls(deduped)
// 步骤4:格式标准化
val standardized = standardizeFormats(nullFilled)
// 步骤5:字段增强
val enhanced = enhanceFields(standardized)
// 写入DWD层
enhanced.write
.mode("overwrite")
.partitionBy("dt")
.format("parquet")
.saveAsTable(dwdTable)
println(s"成功清洗 $date 数据,共 ${enhanced.count()} 条")
}
/**
* 数据过滤
*/
private def filterOrders(df: DataFrame): DataFrame = {
df.filter(col("order_id").isNotNull)
.filter(col("order_time").isNotNull)
.filter(col("city_id").isNotNull)
.filter(col("order_amount") > 0)
.filter(col("order_amount") < 1000000)
}
/**
* 数据去重
*/
private def deduplicateOrders(df: DataFrame): DataFrame = {
// 按订单号去重,保留最新的
val windowSpec = Window
.partitionBy("order_id")
.orderBy(col("update_time").desc)
df.withColumn("rn", row_number().over(windowSpec))
.filter(col("rn") === 1)
.drop("rn")
}
/**
* 空值处理
*/
private def handleNulls(df: DataFrame): DataFrame = {
df.na.fill(Map(
"driver_id" -> "unknown",
"passenger_name" -> "",
"order_amount" -> 0.0,
"discount_amount" -> 0.0,
"remark" -> ""
)).na.fill(0, Seq("order_amount", "discount_amount", "shipping_fee"))
}
/**
* 格式标准化
*/
private def standardizeFormats(df: DataFrame): DataFrame = {
// 时间标准化
val withTime = df
.withColumn("order_time_std",
to_timestamp(col("order_time"), "yyyy-MM-dd HH:mm:ss"))
.withColumn("order_date", to_date(col("order_time_std")))
.withColumn("order_hour", hour(col("order_time_std")))
// 字符串标准化
val withString = withTime
.withColumn("city_name", upper(trim(col("city_name"))))
.withColumn("order_type",
when(lower(col("order_type")).contains("快车"), "express")
.when(lower(col("order_type")).contains("专车"), "premium")
.otherwise("other"))
withString.drop("order_time").withColumnRenamed("order_time_std", "order_time")
}
/**
* 字段增强
*/
private def enhanceFields(df: DataFrame): DataFrame = {
df.withColumn("amount_with_tax", col("order_amount") * 1.06)
.withColumn("is_weekend", dayofweek(col("order_date")).isin(1, 7))
.withColumn("processing_time", current_timestamp())
}
}
3.2 执行清洗作业
object ODSToDWDJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("ODS_To_DWD_Cleaning")
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.config("spark.sql.parquet.compression.codec", "snappy")
.enableHiveSupport()
.getOrCreate()
try {
val cleaner = new OrderDataCleaner(spark)
// 处理历史数据
val dates = Seq("2024-01-01", "2024-01-02", "2024-01-03")
dates.foreach { date =>
cleaner.cleanOrders("ods.orders", "dwd.orders", date)
}
// 处理当天数据(增量)
val today = java.time.LocalDate.now.toString
cleaner.cleanOrders("ods.orders", "dwd.orders", today)
} finally {
spark.stop()
}
}
}
四、性能优化技巧
4.1 分区策略优化
// 1. 合理设置分区键
val partitionedDF = cleanedDF
.repartition(200, col("order_date"), col("city_id"))
// 2. 使用分区裁剪
val incrementalRead = spark.table("ods.orders")
.filter(col("dt") === today) // 只读当天分区
// 3. 动态分区写入
cleanedDF.write
.mode("overwrite")
.partitionBy("dt", "city_id")
.format("parquet")
.option("maxRecordsPerFile", "1000000") // 控制文件大小
.saveAsTable("dwd.orders")
4.2 内存与缓存优化
// 1. 缓存中间结果
val cleanedCache = cleanedDF.persist(StorageLevel.MEMORY_AND_DISK)
// 2. 检查点设置
spark.sparkContext.setCheckpointDir("hdfs://checkpoint/")
cleanedDF.checkpoint()
// 3. 广播小维表
val dimCity = spark.table("dim.city").filter("is_active=1")
val broadcastDim = broadcast(dimCity)
val enriched = cleanedDF.join(broadcastDim, Seq("city_id"), "left")
4.3 并行度调优
// 根据数据量动态调整分区数
val dataSize = spark.table("ods.orders").filter(col("dt") === today).count()
val targetPartitionSize = 128 * 1024 * 1024 // 128MB
val recommendedPartitions = (dataSize / targetPartitionSize).toInt.max(200)
spark.conf.set("spark.sql.shuffle.partitions", recommendedPartitions.toString)
五、数据质量监控
5.1 质量检查指标
// 清洗前后对比
def qualityCheck(odsDF: DataFrame, dwdDF: DataFrame, date: String): Unit = {
val odsCount = odsDF.filter(col("dt") === date).count()
val dwdCount = dwdDF.filter(col("dt") === date).count()
println(s"""
|========== 数据质量报告 [$date] ==========
|ODS层数据量: $odsCount
|DWD层数据量: $dwdCount
|清洗率: ${(odsCount - dwdCount) * 100.0 / odsCount}% 被过滤
|空值率 - driver_id: ${nullRate(dwdDF, "driver_id")}%
|空值率 - passenger_id: ${nullRate(dwdDF, "passenger_id")}%
|重复率: ${duplicateRate(dwdDF, "order_id")}%
|========================================
""".stripMargin)
}
def nullRate(df: DataFrame, column: String): Double = {
val total = df.count()
val nullCount = df.filter(col(column).isNull).count()
nullCount * 100.0 / total
}
def duplicateRate(df: DataFrame, key: String): Double = {
val total = df.count()
val uniqueCount = df.select(key).distinct().count()
(total - uniqueCount) * 100.0 / total
}
5.2 异常数据捕获
// 将异常数据写入异常表
val abnormalData = odsOrders
.filter(col("order_amount") <= 0 || col("order_amount") >= 1000000)
abnormalData.write
.mode("append")
.partitionBy("dt")
.saveAsTable("dwd.abnormal_orders")
六、总结
| 清洗阶段 | 主要操作 | 优化要点 | 质量指标 |
|---|---|---|---|
| 数据过滤 | 非空检查、范围过滤 | 分区裁剪、谓词下推 | 过滤率<20% |
| 数据去重 | dropDuplicates、窗口函数 | 选择合适的去重粒度 | 重复率<0.1% |
| 空值处理 | fill、when-otherwise | 批量填充、业务规则 | 关键字段空值率=0 |
| 格式标准化 | to_timestamp、regexp_replace | 内置函数优化 | 格式统一率100% |
| 字段增强 | withColumn、join维表 | 广播小表、列剪枝 | 字段完整度提升 |
核心原则:
- 可重复性:清洗逻辑要幂等,支持重跑
- 可观测性:埋点监控,及时发现质量问题
- 高性能:合理利用Spark优化技术
- 可维护性:清洗逻辑模块化,便于扩展
通过以上方法,可以构建一个高效、可靠、可扩展的ODS→DWD数据清洗流程,为数据分析和数据服务提供高质量的数据基础。

|
🌺The End🌺点点关注,收藏不迷路🌺
|
© 版权声明
文章版权归作者所有,未经允许请勿转载。