【AI Coding 系列】——什么是AI Coding,怎么合理使用AI Coding,大模型上下文限制解决方案,任务拆解策略
AI Coding 并非简单的"让 AI 写代码",而是一种使用大型语言模型(LLM)为核心驱动力的新型软件编程方式。要求开发者不仅要理解编程语言,更要掌握模型边界感知、上下文工程、认知负载管理等新兴技能。
随着 Claude、GPT-4、Kimi 等模型的能力跃升,我们正从"AI 辅助编码"(Copilot 模式)变成"AI 主导架构,开发人员主导决策"的代理编程(Agentic Coding)。这一转变要求建立全新的工作流、质量控制体系和知识管理方法。
第一部分:核心概念、认知框架——小白扫盲(可直接看第二部分)
1.1 模型边界感知
AI Coding 的首要原则是清醒认知模型的能力边界。就是我们蒸米饭加多少水类似,全凭感觉,而大模型则是:
能力边界维度:
上下文窗口限制:当前主流模型支持 128K-200K tokens,但有效利用长度通常只有 8K-32K(随长度增加,召回率下降),通俗点就是前面很聪明,后面越来越笨,回答问题天南地北
知识截止时间:模型对最新框架、API 变更存在盲区
推理深度:复杂算法推导、多步骤逻辑链容易在中间环节出错
幻觉概率:在陌生领域(如特定企业内部框架)容易生成看似合理但实际错误的代码
任务拆解策略: 将复杂需求拆解为模型可稳定处理的单元:
❌ 错误:"给我写一个电商系统"
✅ 正确:拆解为 [用户认证模块] → [商品数据模型] → [购物车逻辑] → [支付接口对接]
每个子任务应满足:
-
单一职责:一个对话只解决一个具体技术问题
-
输入完备:提供必要的接口定义、数据示例、约束条件
-
输出可验证:结果可通过测试用例或类型检查验证
1.2 上下文工程
比提示词(Prompt)更重要的是上下文(Context)的构建。这是 AI Coding 中最容易被忽视的专业技能。
上下文金字塔:
项目级上下文:架构图、技术栈、编码规范、目录结构
任务级上下文:相关代码文件、依赖接口、业务逻辑背景
会话级上下文:当前对话历史、已做出的决策、待解决问题
最佳方法:
RAG(检索增强生成):使用向量数据库存储项目文档,动态检索相关片段注入提示
文件引用规范:使用 XML 标签或特定格式(如 <file path="src/utils.js">)明确标识引用内容
差异最小化:只提供变更相关的上下文,避免无关代码干扰模型注意力
1.3 提示词工程
从"技巧"到"协议"的转变:
结构化提示模板(SPF):
角色
你是一位资深后端工程师,专精分布式系统。
任务
重构以下 Python 函数,使其支持异步并发处理。
上下文
当前使用同步阻塞 I/O
目标 QPS:10,000
依赖库:asyncio, aiohttp
输入代码
[代码块]
约束条件
保持现有 API 接口不变
添加类型注解
错误处理必须兼容现有日志格式
输出要求
1、重构后的完整代码
2、关键变更点说明
3、性能测试建议
关键原则:
角色设定明确期望的知识领域和回答风格
约束条件提前声明技术限制,减少无效尝试
输出格式结构化要求便于后续自动化处理
第二部分:AI Coding 工作流与方法论
2.1 需求澄清与信息核对
AI Coding 的第一定律:输入的模糊性会直接导致输出的错误率指数级上升。
信息核对清单:
-
[是/否] 业务术语是否有特定含义?(如"用户"是否包含匿名访客)
-
[是/否] 技术约束是否明确?(浏览器兼容性、Python 版本、依赖限制)
-
[是/否] 边界条件是否定义?(空值处理、并发限制、数据范围)
-
[是/否] 验收标准是否量化?(性能指标、测试覆盖率)
有效方法: "反向复述":要求 AI 用自己的语言重述需求,确认理解一致后再开始编码。
2.2 调试与错误处理协议
当 AI 生成代码出现错误时,遵循结构化报错流程:
错误报告模板:
问题描述
[一句话概括现象,如:运行时抛出 NullPointerException]
环境信息
语言/框架版本:
操作系统:
相关依赖版本:
错误日志
[完整堆栈跟踪,使用 <error> 标签包裹]
已尝试方案
1. [方案 A] → 结果:
2. [方案 B] → 结果:
期望行为
[描述正确的行为应该是怎样的]
相关代码
[最小可复现代码片段]
!!!一定要!!!及时止损 !!!: 如果同一问题经过 3 轮迭代仍未解决:
开新对话窗口:重置上下文,避免错误累积
降低复杂度:将问题拆分为更小的验证单元
切换策略:从"AI 自动修复"转为"AI 提供方案,人工实施"
2.3 版本控制、代码审查
AI 生成代码的版本管理特殊性:
生成元数据标记:在提交信息中标注使用的模型、提示词版本、温度参数
隔离实验分支:AI 重构代码必须在独立分支进行,通过 PR 审查合并
快照对比:使用工具(如 aider、cline)对比 AI 修改前后的差异
审查清单:
-
[是/否] 是否引入未声明的依赖?
-
[是/否] 错误处理是否完备?
-
[是/否] 是否存在潜在的安全漏洞(SQL 注入、XSS)?
-
[是/否] 性能特征是否可接受?
第三部分:工程化与系统化
3.1 上下文窗口管理策略
长上下文的陷阱: 虽然模型支持 128K+ tokens,但"支持"不等于"有效"。当上下文超过 32K 时,模型对早期信息的召回率显著下降。
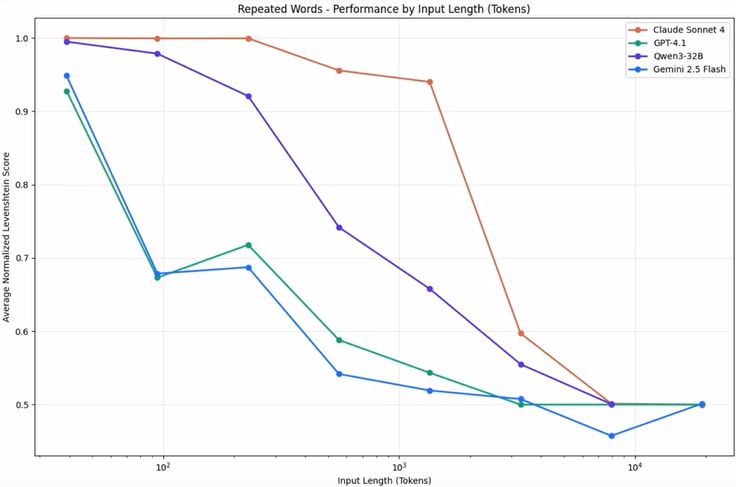
管理策略:
-
对话分片:
每个对话窗口专注一个功能点,完成后将结论沉淀到 Wiki 或文档,新任务基于沉淀文档开启新对话
-
记忆管理:
使用外部记忆系统(如 Mem0、Zep)持久化项目知识,关键决策点(技术选型、架构设计)必须人工确认后存入记忆,定期整理记忆空间,删除过时信息
-
增量更新:
只传递变更差异(diff),而非完整文件,使用
git diff格式让模型理解修改范围
3.2 MCP、工作流封装
MCP 架构是 AI Coding 的工程化核心,它将常用能力封装为标准接口:
典型 MCP 工具分类:
| 类别 | 功能 | 示例 |
|---|---|---|
| 文件系统 | 读写代码、搜索文件、目录遍历 |
read_file, search_code
|
| 终端执行 | 运行命令、执行脚本、构建项目 |
execute_command, run_tests
|
| 网络请求 | API 调试、文档检索、依赖查询 |
http_request, fetch_docs
|
| 数据库 | Schema 查询、数据验证、迁移生成 |
query_db, migrate
|
| 版本控制 | Git 操作、差异查看、提交管理 |
git_diff, commit
|
工作流封装示例:
workflow: "安全重构"
steps:
1. 分析: 使用 AST 解析理解代码结构
2. 规划: AI 生成重构方案(不修改代码)
3. 验证: 运行现有测试套件,确保基线通过
4. 实施: 按方案执行修改,每步后运行测试
5. 回滚: 如测试失败,自动回滚到上一步
6. 审查: 生成 diff 报告供人工确认
3.3 项目 Wiki 与知识管理
AI 友好型 Wiki 结构:
wiki/
├── 1.开始/
│ ├── 快速开始.md # 5 分钟运行 Hello World
│ ├── 环境搭建.md # 依赖安装、IDE 配置
│ └── 架构概览.md # 一张图看懂系统
├── 2.指南/
│ ├── 添加新功能.md # 端到端开发流程
│ ├── 调试技巧.md # 常见问题排查
│ └── 性能优化.md # 基准测试与调优
├── 3.参考/
│ ├── API 文档/ # 自动生成
│ ├── 配置手册.md # 环境变量、参数说明
│ └── 错误码表.md # 对照表与解决方案
└── 4.开发/
├── 贡献指南.md # 代码规范、提交格式
├── 架构决策记录(ADR)/ # 关键设计决策
└── 路线图.md # 未来规划
AI 可读性优化:
使用机器可读格式(Markdown、YAML、JSON)
显式优于隐式:明确写出默认值、边界条件、异常行为
示例驱动:每个概念配有一个可运行的最小示例
总结:
4.1 误区
准备不完善,目标功能模糊,过早追求完美,对AI期望过高
4.2 感想
目前已经有很多公司决定不在按照技术栈分技术岗位,统一为Agent工程师,工作安排上是根据产品、项目任务安排
对于不懂的技术栈,最重要是要有一个基本的概念,配合AI Coding完成需求开发。对于门外汉来说,什么也不会的话,建议还是重0开始学习,之前是0到1,现在可以0到0.8的学习,就可以做一些开发,然后在实际业务中学习。
© 版权声明
文章版权归作者所有,未经允许请勿转载。