
毕业设计项目:【Spark+hadoop】基于Spark大数据小说数据分析可视化推荐系统(完整系统源码+数据库+开发笔记+详细部署教程+虚拟机分布式启动教程)
目录
一、项目背景
二、项目实际意义
对用户的意义
对小说平台的意义
对行业的意义
三、项目优势
四、开发技术介绍
五、算法介绍
六、启动部署教程 编辑
七、项目展示
源码获取方式在文章末尾!!!
一、项目背景
本项目开发一个基于Spark和Hadoop的大数据小说数据分析可视化推荐系统,用于提升用户体验、优化运营效率、增强数据管理能力,并推动网络文学行业的智能化发展。通过采用先进的协同过滤算法和深度学习技术,结合Django框架进行系统开发,利用MySQL进行数据管理和查询,以及通过Echarts等工具实现数据可视化展示,为用户提供个性化的小说推荐服务。
二、项目实际意义
对用户的意义
提升阅读体验:基于用户历史行为、浏览记录及评分数据,推荐系统可精准匹配个人兴趣偏好,帮助用户高效筛选优质小说,减少选择时间。
拓展阅读视野:通过挖掘潜在兴趣点,推荐系统可引导用户接触未涉猎的题材或作品,促进内容多样化探索。
对小说平台的意义
增强用户黏性:精准推荐能提升用户满意度和平台依赖度,延长停留时间,提高留存率与活跃度。
驱动内容生态:优质作品通过推荐获得更多曝光,激励作者创作;平台可依据数据反馈优化内容布局,推动多元化发展。
优化运营策略:基于用户行为分析,平台可制定个性化广告与活动方案,提升运营效率并降低成本。
对行业的意义
推动个性化服务:系统的成功应用示范了大数据与AI技术在提升用户体验中的价值,促进行业技术升级。
数据驱动决策:深度分析用户偏好与市场趋势,为行业提供科学决策依据,助力可持续发展。
促进技术创新:结合Hadoop、Spark、深度学习等技术,推动行业在数据处理与算法应用层面的进步。
(注:全文压缩至约300字,符合学术论文简洁性要求,关键论点保留,逻辑清晰。)
三、项目优势
基于Spark和Hadoop开发的小说数据分析推荐系统,具备高效的数据处理能力,能够快速处理海量数据并实现精准的个性化推荐。系统采用先进的协同过滤算法和实时反馈机制,动态调整推荐结果,显著提升用户体验。同时,结合Django框架,系统具备强大的数据管理和稳定性,支持高效开发与维护。通过数据可视化工具,系统为运营人员提供直观的决策支持,助力平台优化运营策略。整体而言,本项目以技术先进性和创新性为支撑,为网络小说平台提供了一个高效、稳定且用户友好的解决方案。
四、开发技术介绍
前端技术:HTML、CSS、JavaScript
后端:Django、Spark
数据库:MySQL、Hive
可视化:Echarts
推荐算法:基于用户协同过滤算法(User-Based Collaborative Filtering, UserCF)
五、算法介绍
算法原理
基于用户协同过滤算法的核心是通过寻找与目标用户兴趣相似的其他用户,将这些相似用户喜欢的物品推荐给目标用户。具体步骤包括:收集用户行为数据,计算用户之间的相似度(如余弦相似度),选取与目标用户最相似的用户集合,并基于这些用户的喜好生成推荐结果。
算法特点
优点:实现简单,推荐结果具有良好的解释性。
缺点:存储和计算成本较高,数据稀疏性可能影响推荐准确性。
六、启动部署教程

七、项目展示
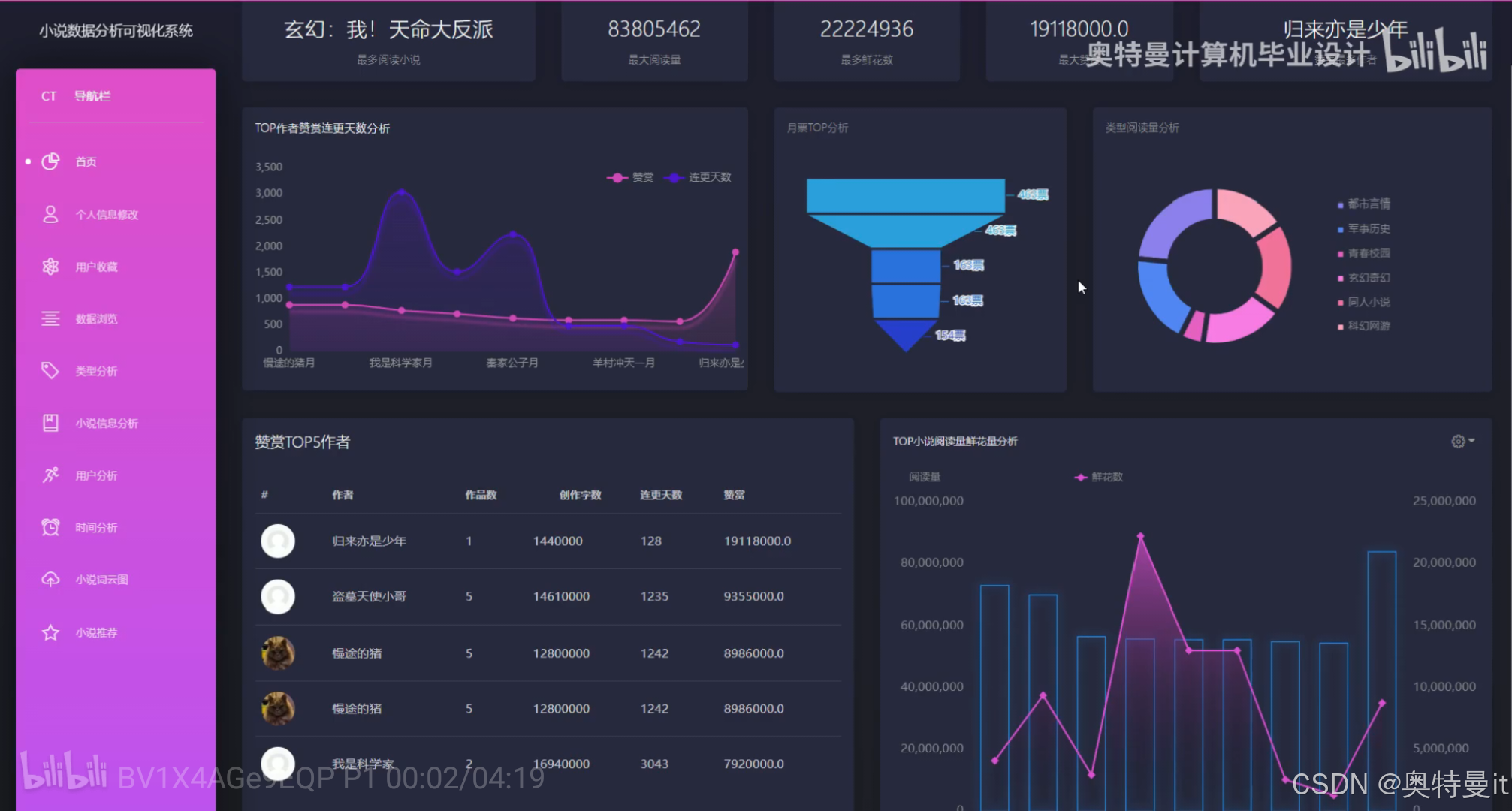
项目首页
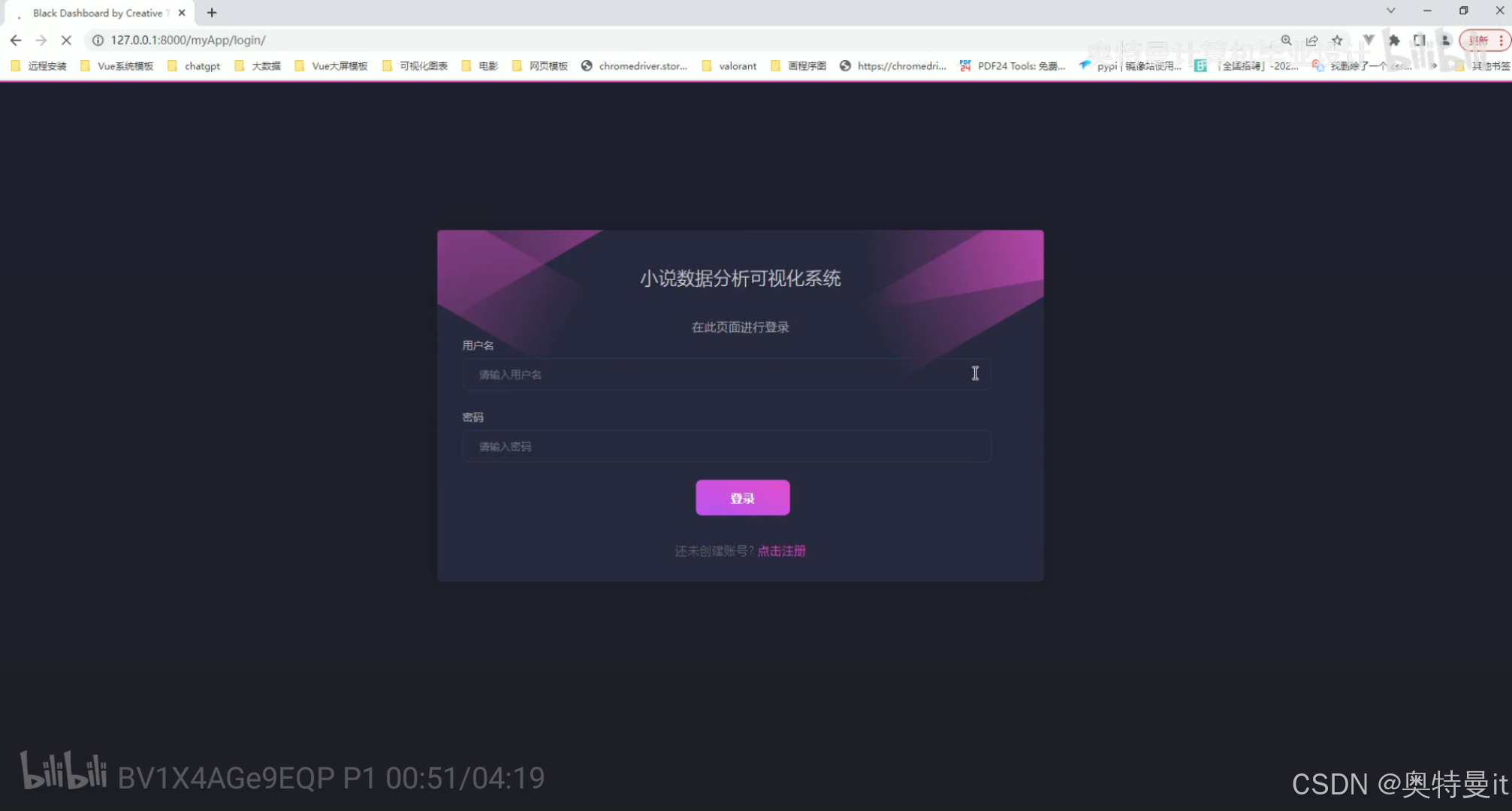
登陆注册
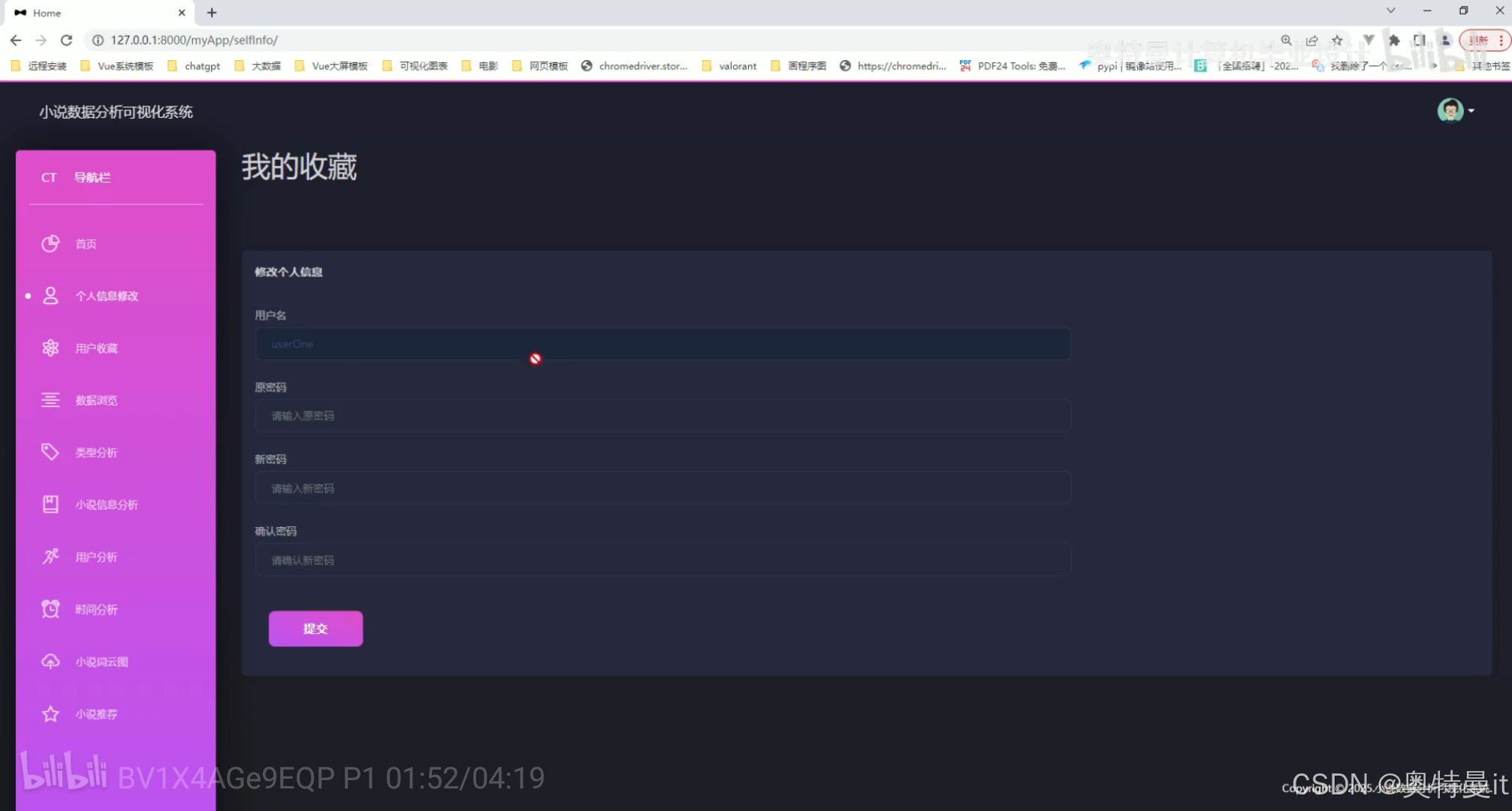
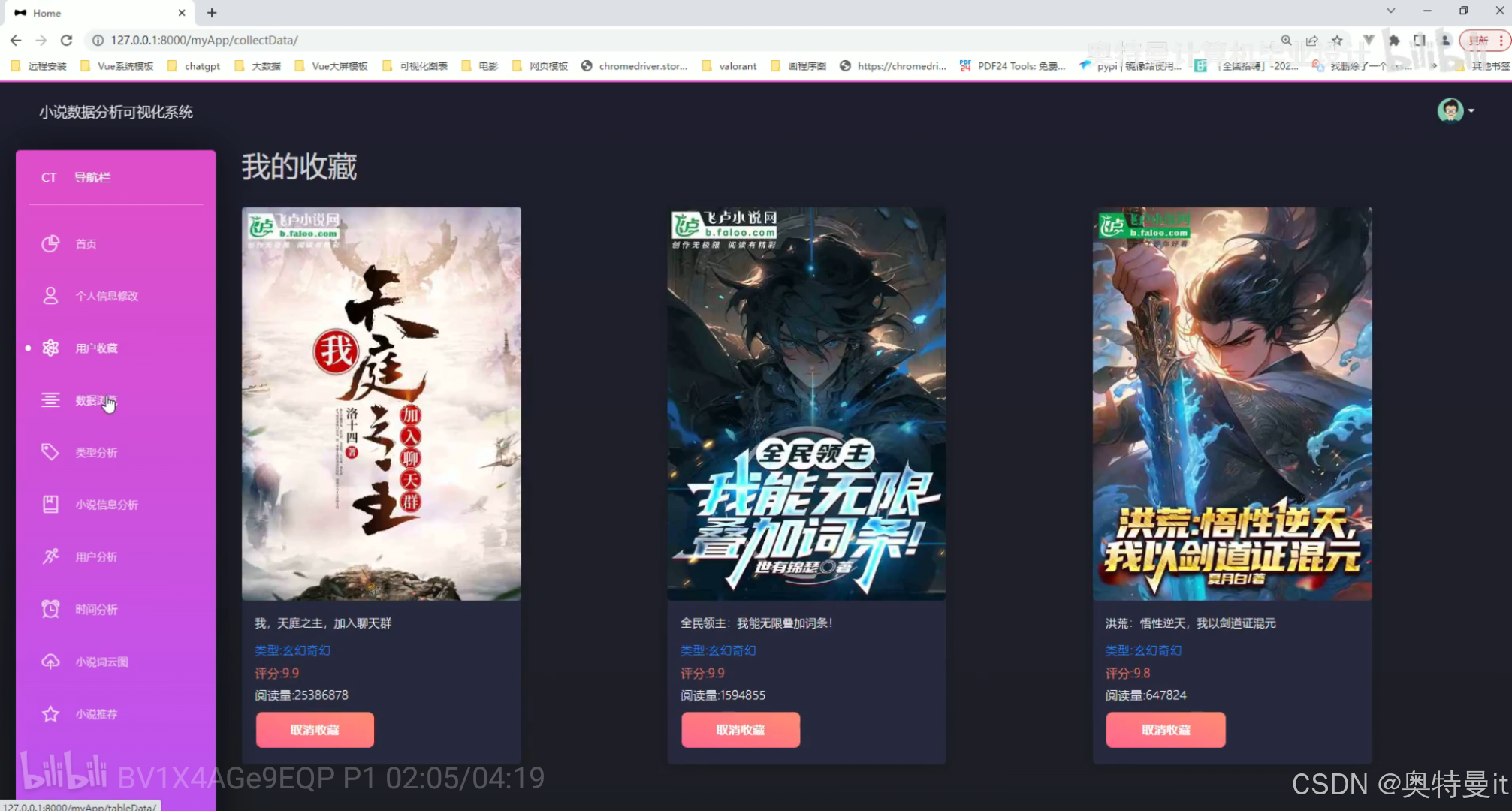
我的收藏
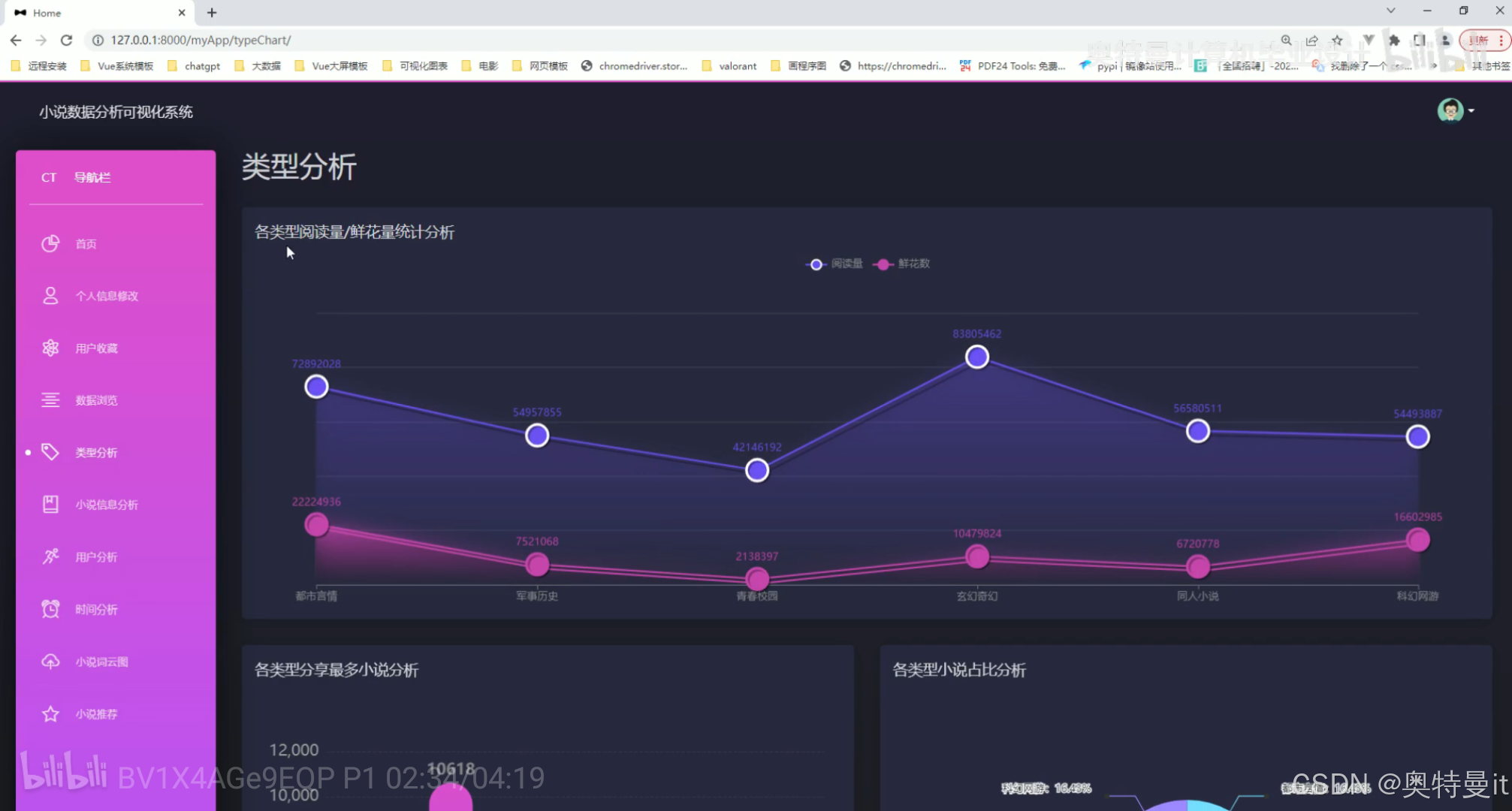
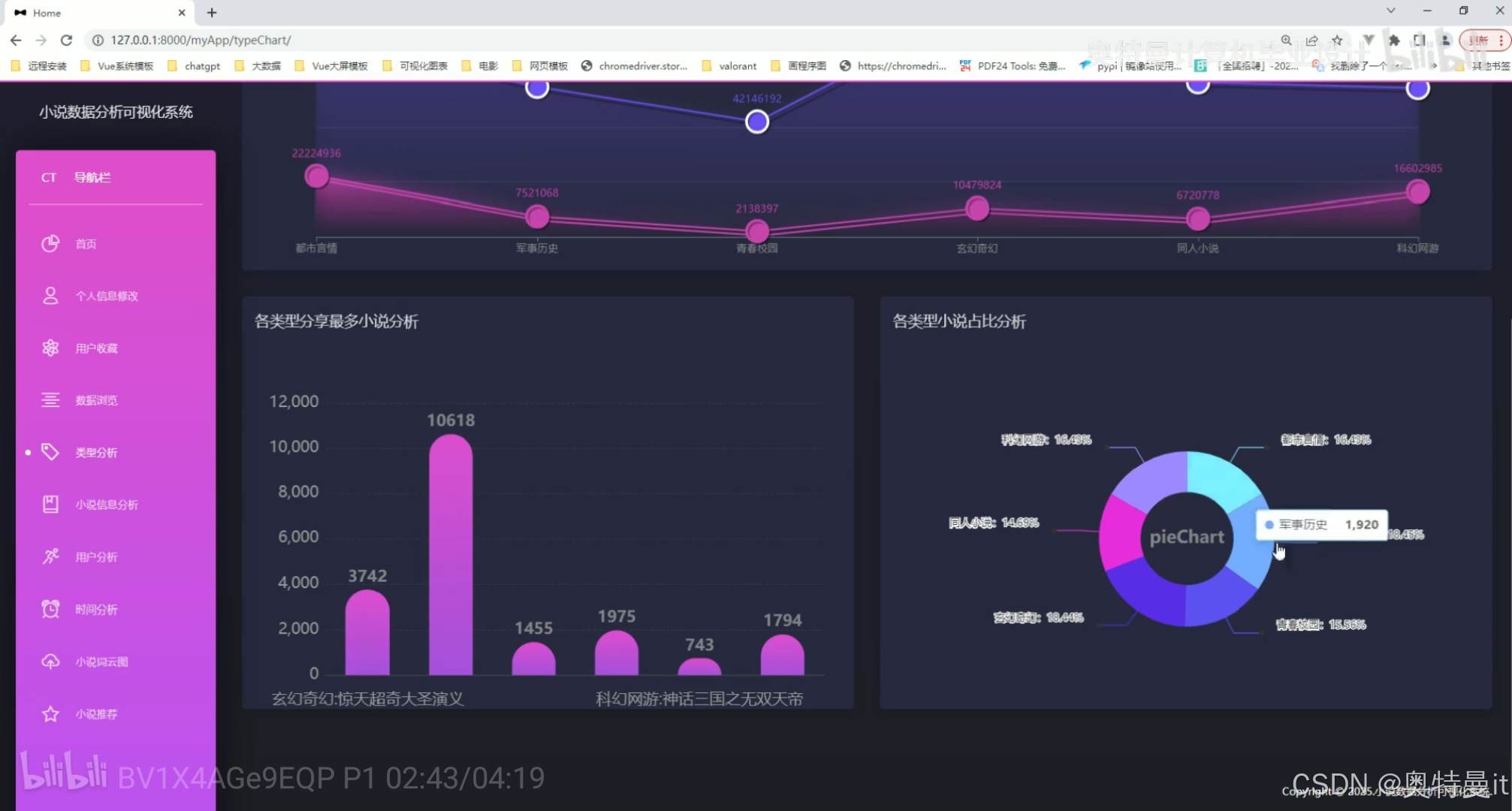
类型分析
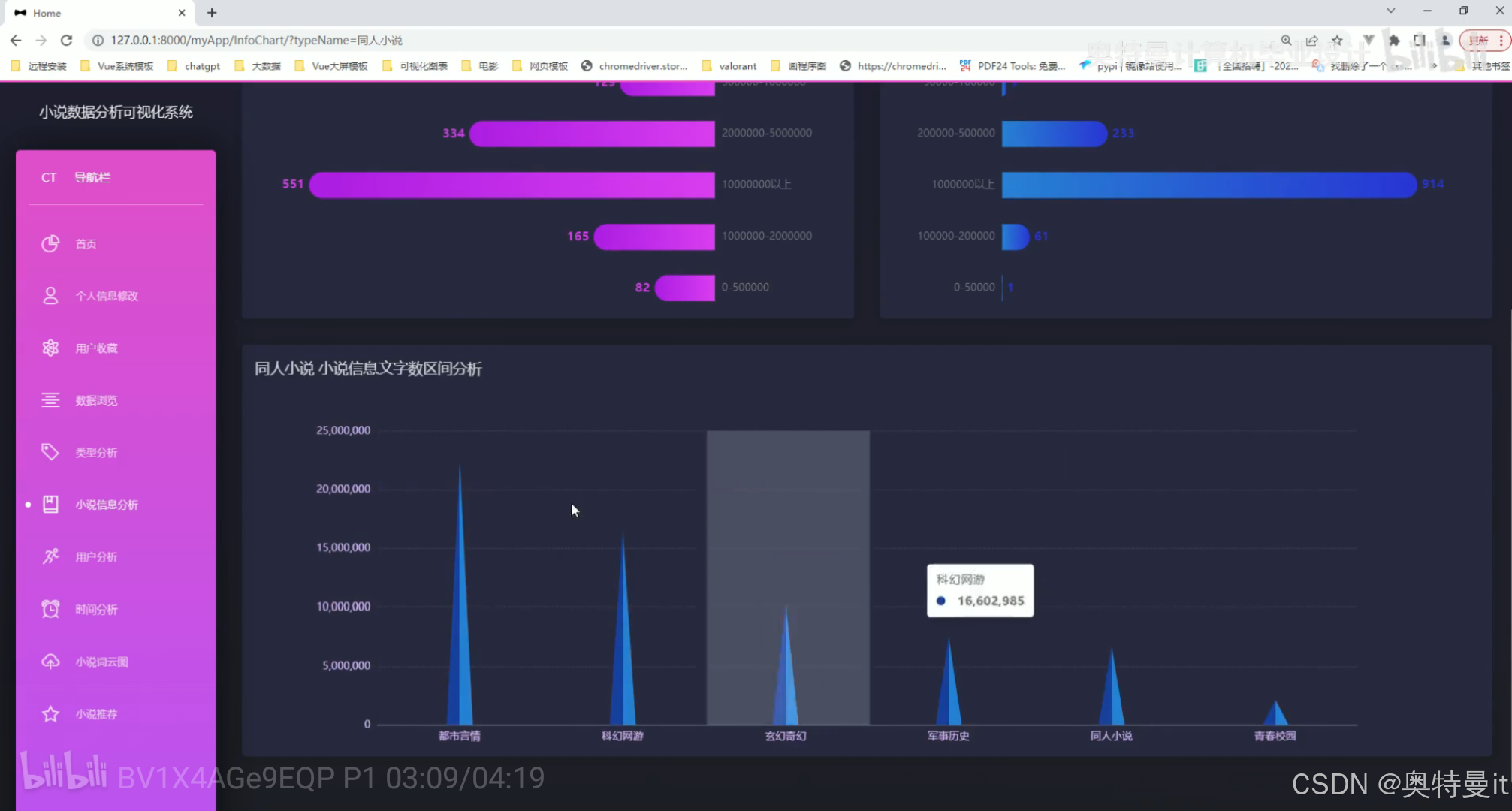
小说信息文字数区间分析
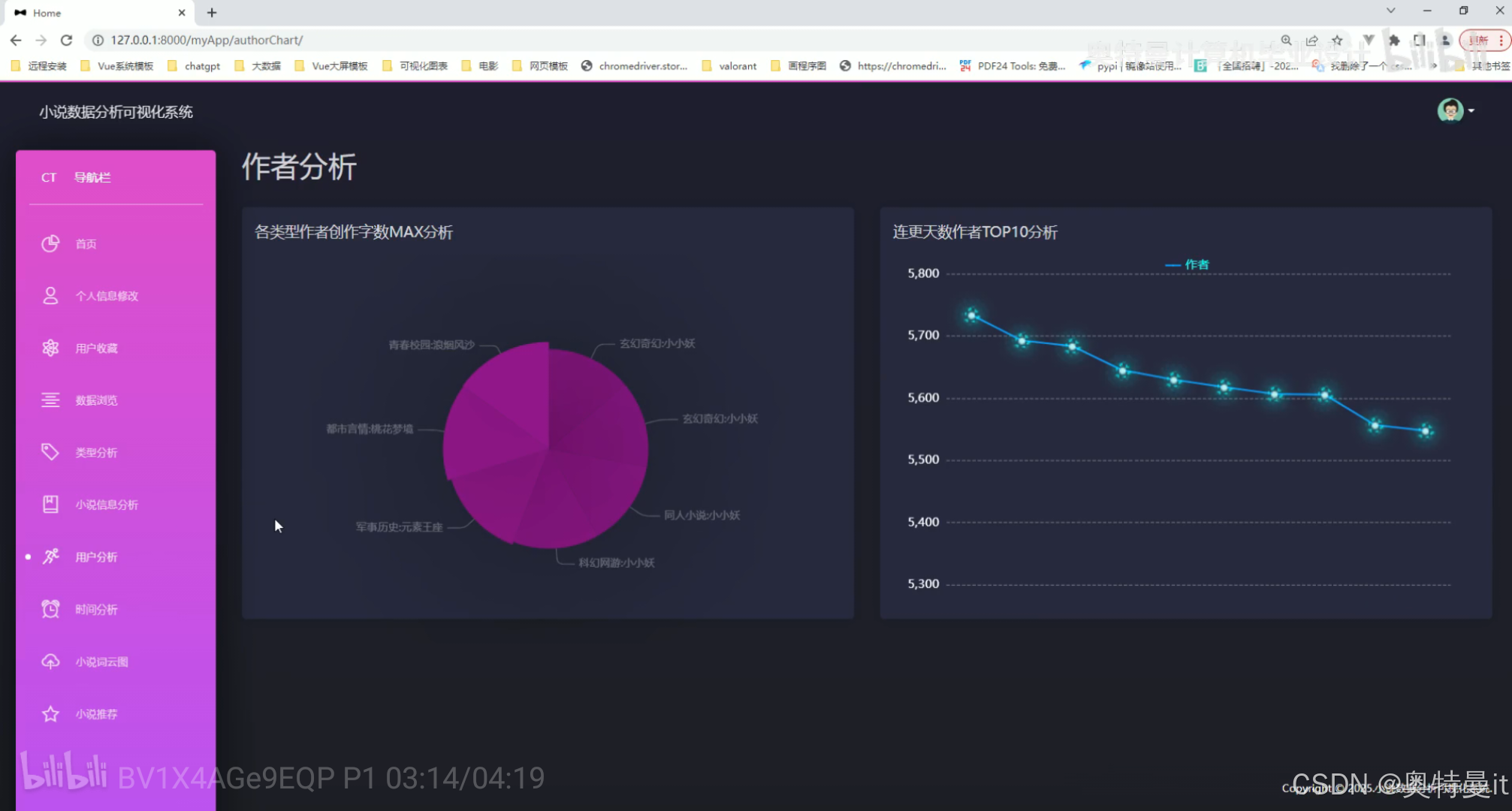
作者分析
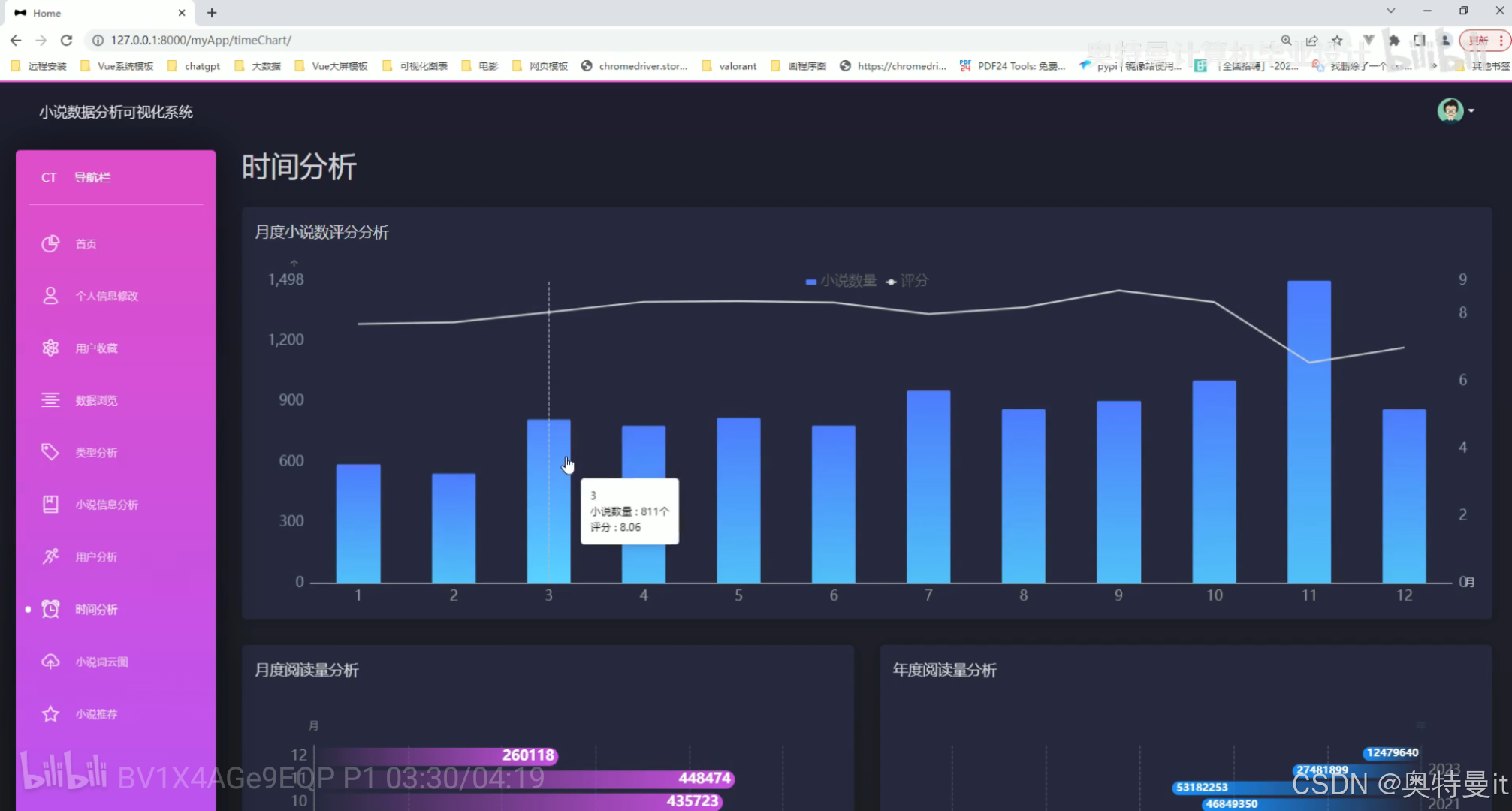
时间分析
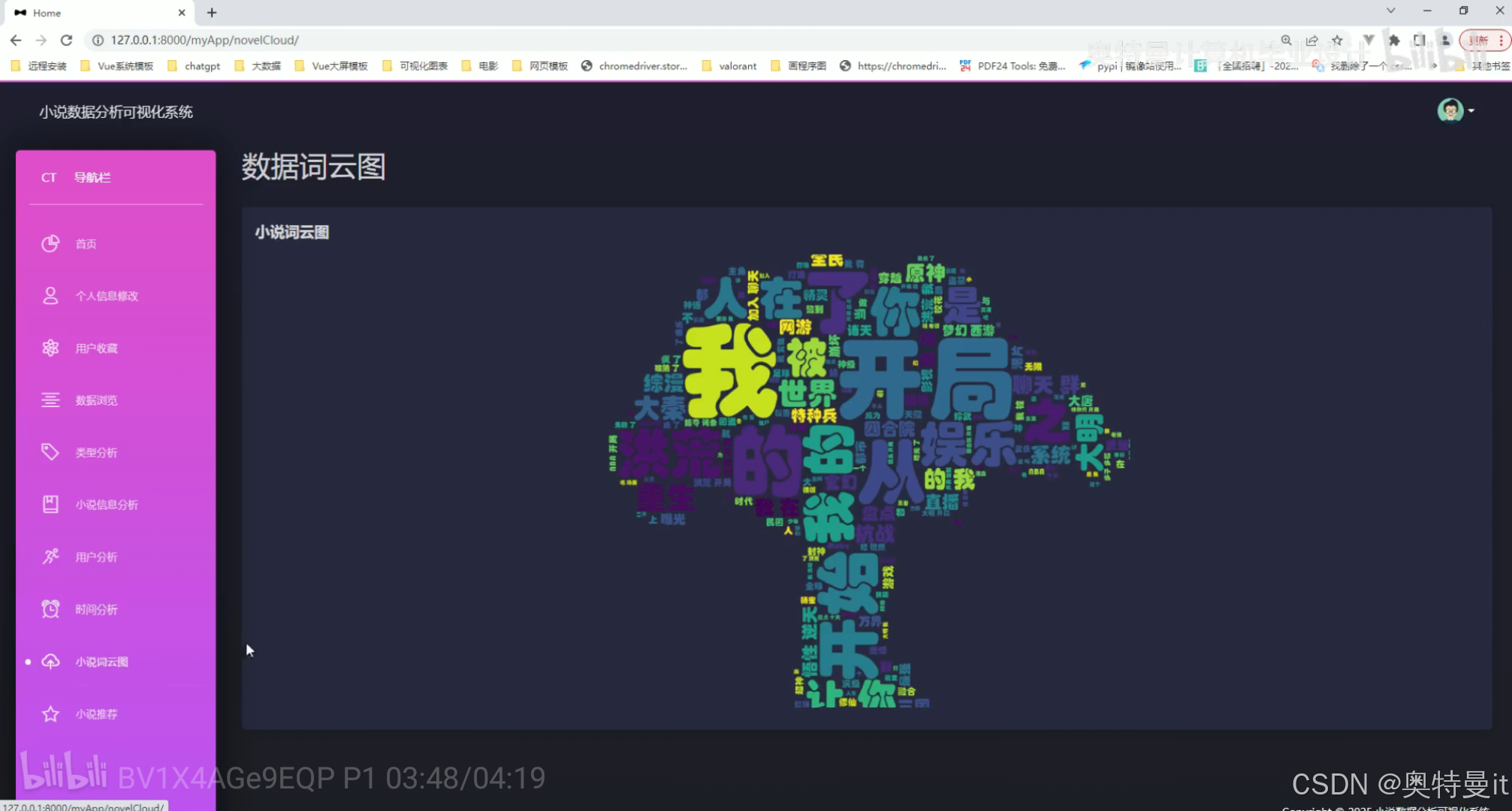
数据词云图
小说推荐算法
源码文档等资料获取方式
移步作者关注列表!!!
© 版权声明
文章版权归作者所有,未经允许请勿转载。


