数据模型与关系理论 – 软考备战(三十)
数据库系统(二)
参考资料:
ER图(实体关系图)怎么画?
如何将ER图转化为关系模型(含案例)
关系模型.pdf
第五章:关系代数(Relational Algebra)笔记 | 数据库设计与开发
关于DBS中的函数依赖与关系模式范式 | WhythZ
第一范式、第二范式、第三范式、BCNF范式详解-腾讯云开发者社区-腾讯云
一文搞懂数据库设计范式:1NF、2NF、3NF 和 BCNF – 知乎
目录
数据库系统(二)
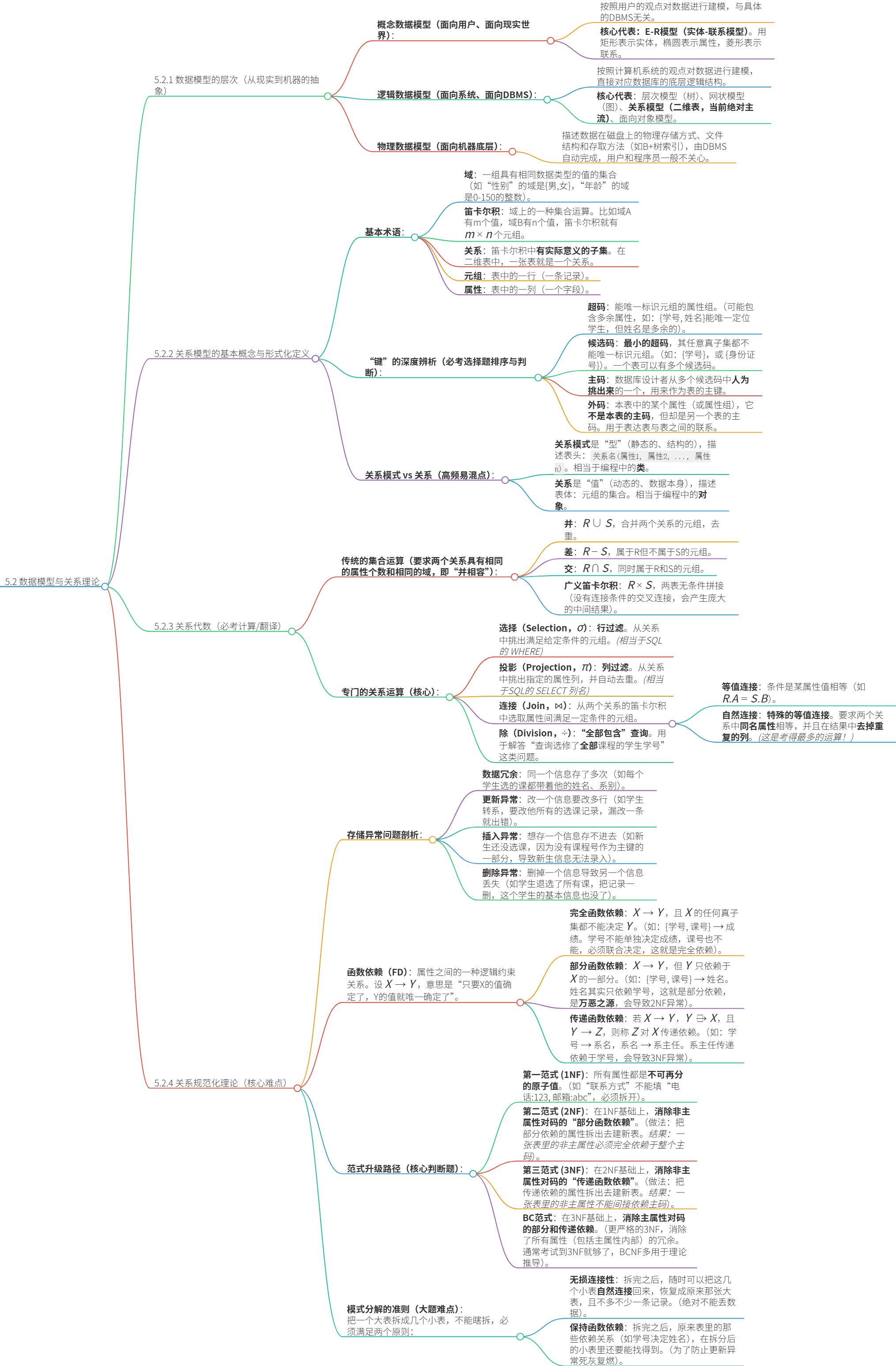
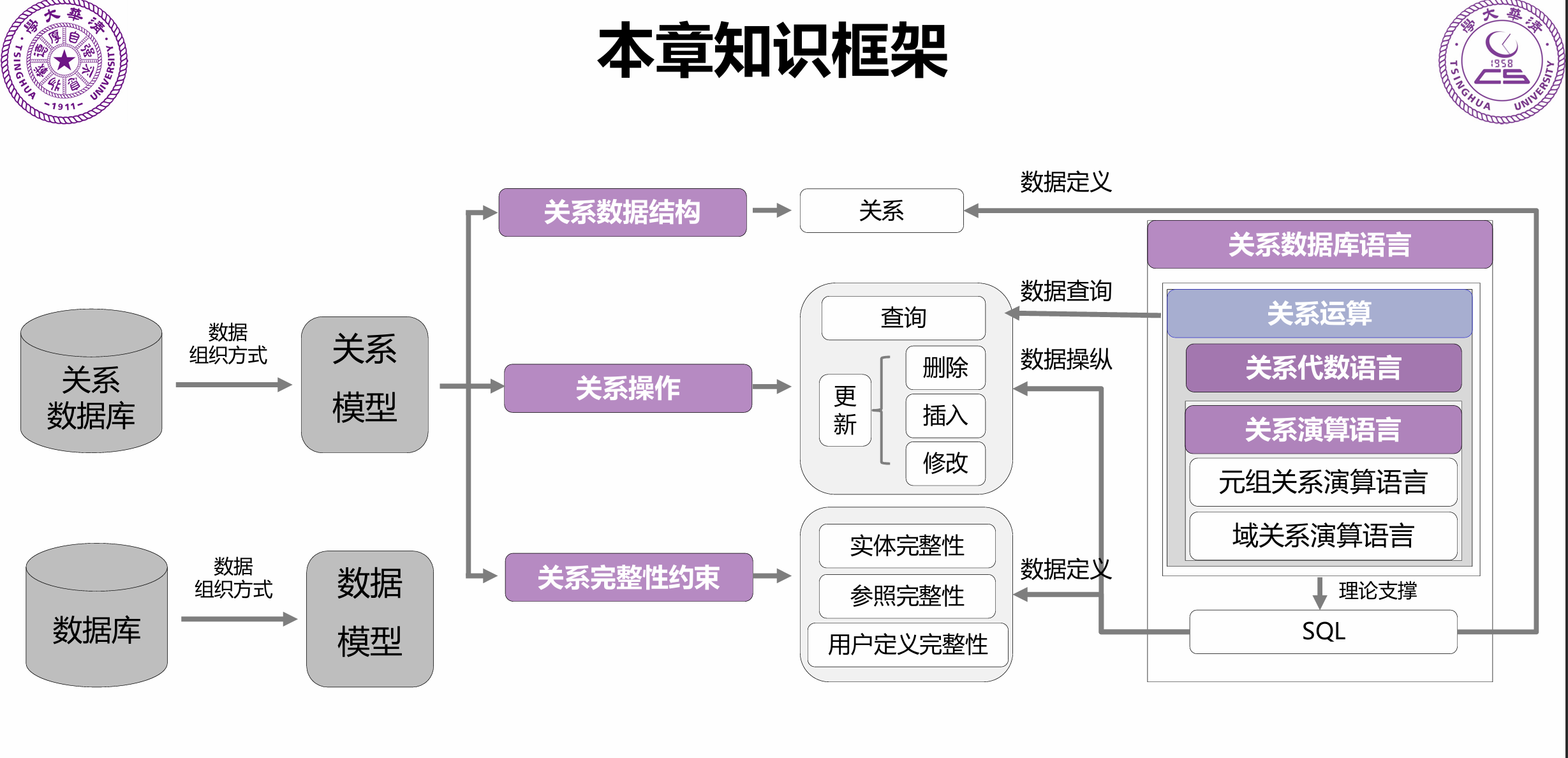
5.2 数据模型与关系理论
5.2.1 数据模型的层次(从现实到机器的抽象)
概念数据模型(面向用户、面向现实世界)
逻辑数据模型(面向系统、面向DBMS)
物理数据模型(面向机器底层)
5.2.2 关系模型的基本概念与形式化定义
5.2.3 关系代数
传统的集合运算
并
差
交
笛卡尔积
专门的关系运算(核心骨干)
选择(Selection)
投影(Projection)
等值连接
自然连接
外连接、内连接
除(Division)
5.2.4 关系规范化理论(核心难点:解决数据冗余与异常)
存储异常问题剖析(为什么要拆表?)
函数依赖(FD,决定异常的数学本质)
完全函数依赖
部分函数依赖
传递函数依赖
范式升级路径(拆表的实操指南)
第一范式 (1NF)——属性不可再分
第二范式 (2NF)
第三范式 (3NF)
BC范式
模式分解的准则
无损连接性
保持函数依赖
5.2 数据模型与关系理论
5.2.1 数据模型的层次(从现实到机器的抽象)
数据模型是对现实世界数据特征的抽象,它必须满足三个要求:
能真实模拟现实、容易被人理解、方便在计算机上实现。
为此,分成了三个层次逐步转化:
概念数据模型(面向用户、面向现实世界)
作用
按照用户的视角来建模,描述企业中的实体及实体间的联系。
它与具体的数据库管理系统(DBMS)毫无关系,是独立于计算机的。
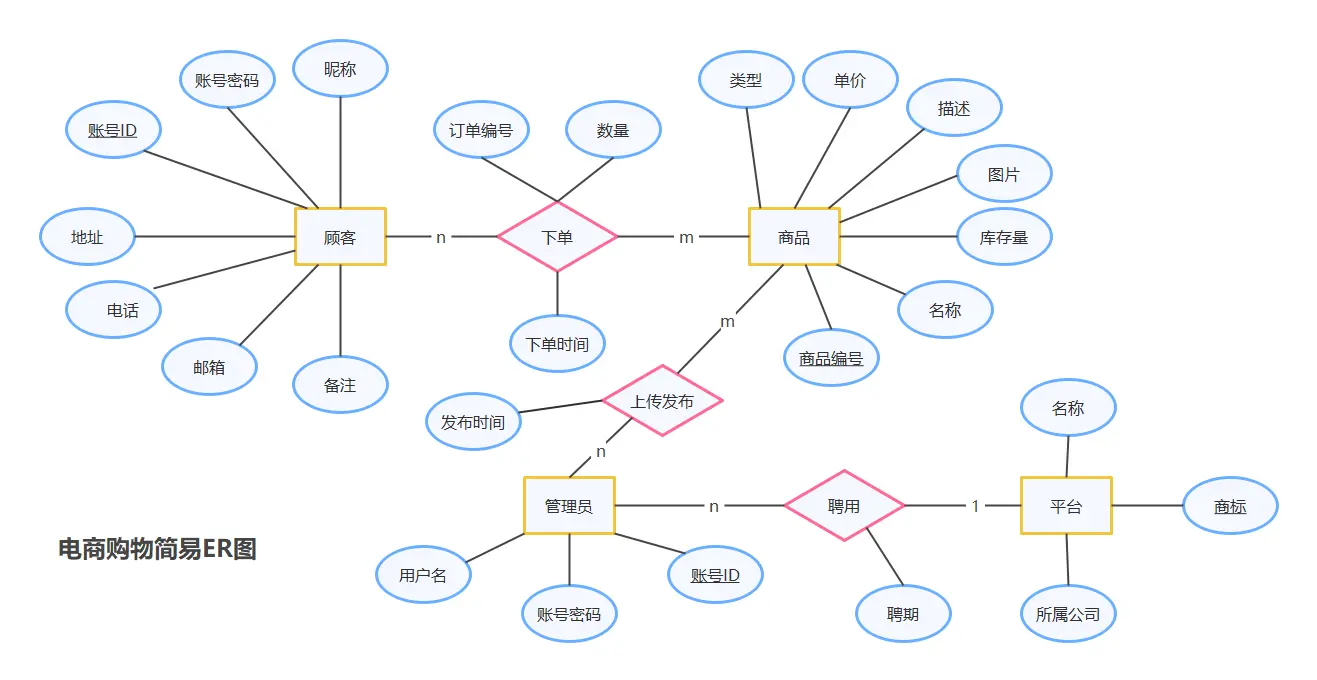
核心代表——E-R模型(实体-联系模型)
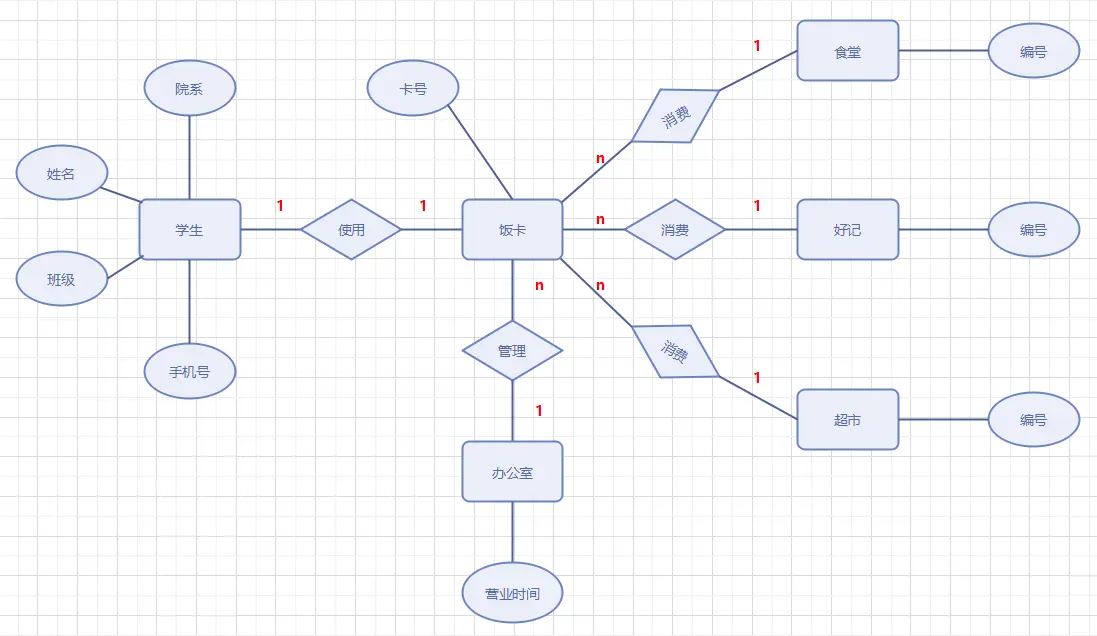
实体:客观存在且可相互区别的事物(如:学生、课程)。用矩形表示。
属性:实体具有的特性(如:学号、姓名)。用椭圆表示。
联系:实体之间的关联。用菱形表示。联系有三种基数:1:1(一对一,如夫妻)、1:N(一对多,如班级与学生)、M:N(多对多,如学生与选课)。
逻辑数据模型(面向系统、面向DBMS)
作用
将概念模型转化为计算机能够处理的数据结构,直接对应数据库的底层逻辑。
核心代表
层次模型(树结构)
网状模型(图结构)
关系模型(二维表结构,绝对主流)
面向对象模型
转化过程
E-R图中的“实体”和“联系”都要转换成关系模型中的“表”。



物理数据模型(面向机器底层)
作用
描述数据在磁盘上的物理存储方式、文件结构(如堆文件、顺序文件)、存取路径和索引结构(如 B+树索引、Hash索引)。
特点:
对用户透明,通常由 DBMS 自动完成,数据库设计人员只需偶尔参与物理参数调优。
5.2.2 关系模型的基本概念与形式化定义
关系模型是建立在严格的集合论基础上的,每一个概念都能找到数学映射。
基本术语(必须能与二维表严格对应)

域
一组具有相同数据类型的值的集合。
是属性的取值范围。
(如:“性别”的域是集合 {男, 女};“年龄”的域是 {15, 16, …, 30} 的整数集合)。
笛卡尔积
域上的一种集合乘法运算。假设有 n 个域,分别有
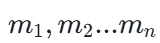
元素,它们的笛卡尔积就是把这些域里的元素无脑排列组合,产生

个元组。
关系
笛卡尔积中有实际意义的子集。

在二维表中,一张表(包含表头和表体)就是一个关系。
元组
表中的一行,即笛卡尔积中的一个元素。
属性
表中的一列,给每一列起个名字就是属性名。
分量
元组中的一个具体属性值(如某一行对应的“年龄=20”)。
超码
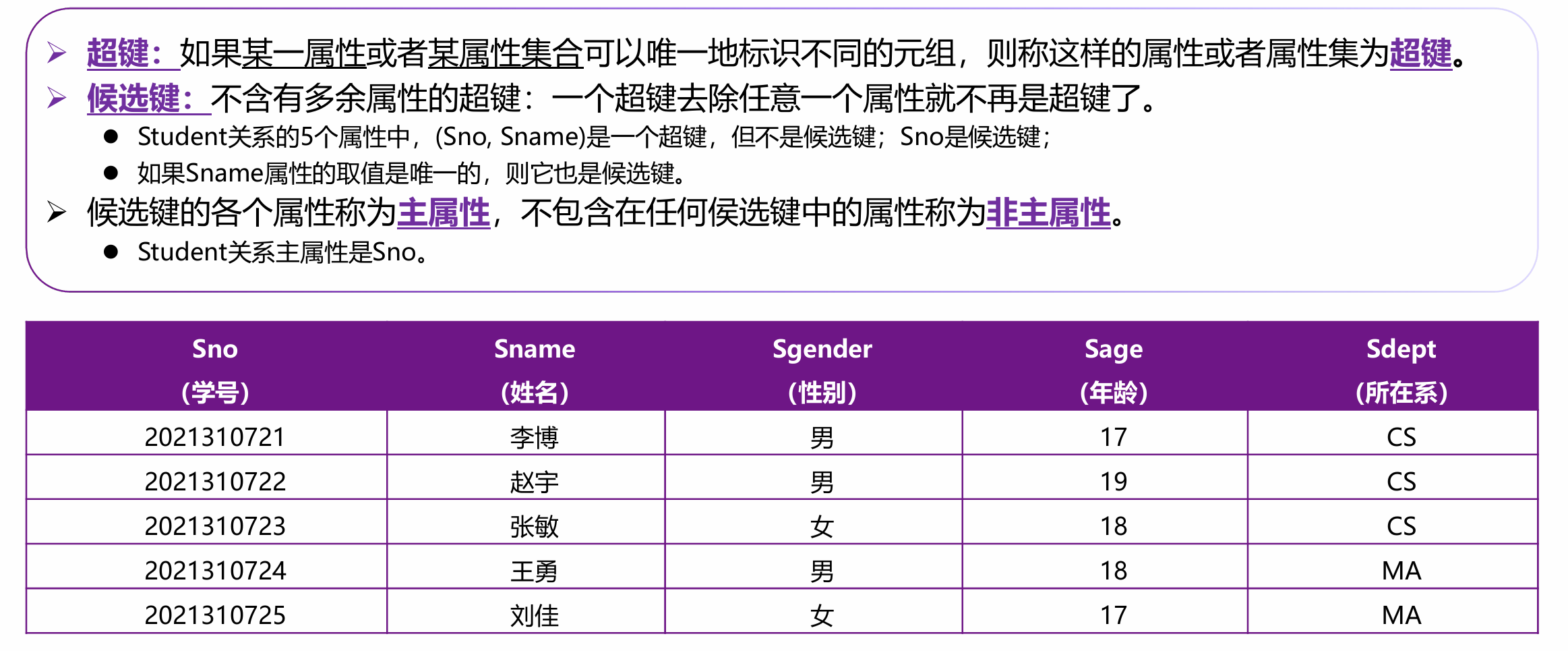
能唯一标识一个元组的属性组。
(缺陷:可能包含多余属性。如 {学号, 姓名} 能定位学生,但“姓名”纯属陪衬。)
候选码
最小的超码。
它的任何真子集都不能再唯一标识元组(即属性之间没有冗余)。
(如:{学号} 或 {身份证号}。一张表可以有多个候选码。)
主码 / 主键
数据库设计者从多个候选码中人为挑选出来的一个,用下划线标注。(一张表只能有一个主码。)
外码 / 外键
本表中的某个属性(或属性组)X,它不是本表的主码,但却对应着另一个表的主码Y。外码是表与表建立联系的桥梁。
主属性 vs 非主属性
包含在任何一个候选码中的属性叫主属性(哪怕它只是个陪衬的超码属性,只要在某个候选码里就算);
完全不包含在任何候选码中的属性叫非主属性。
关系模式 vs 关系(高频易混点)
关系模式是“型”(静态的表头结构)。描述为:关系名(属性1, 属性2, …, 属性n)。相当于面向对象编程中的类。
关系是“值”(动态的表体数据)。是元组的集合。相当于面向对象编程中的对象实例。
举例:
Student(学号, 姓名, 年龄) 是关系模式;
而表里实际存的那 1000 个学生的具体数据行,叫关系。
5.2.3 关系代数
关系代数是一种过程化查询语言,写的每一条 SQL 语句,数据库底层都会先把它翻译成关系代数,再决定如何执行。
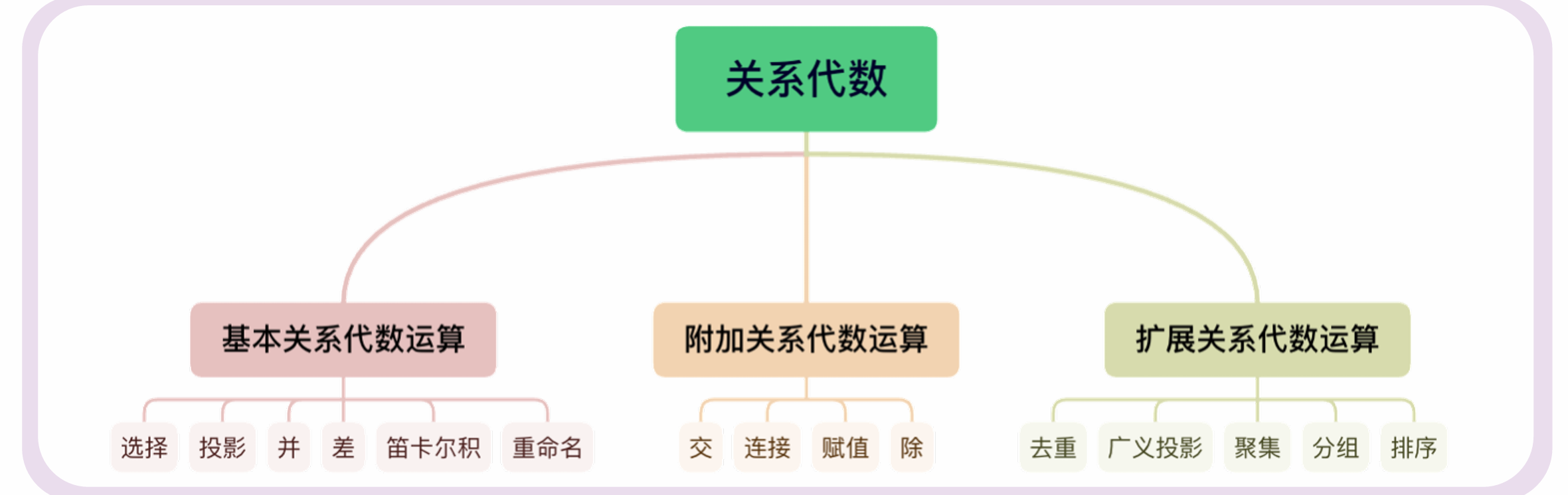
传统的集合运算
(前提:参与运算的两个关系必须是“并相容”的,即列数相同、对应列的域相同):
并

合并两个关系的所有元组,自动去重。
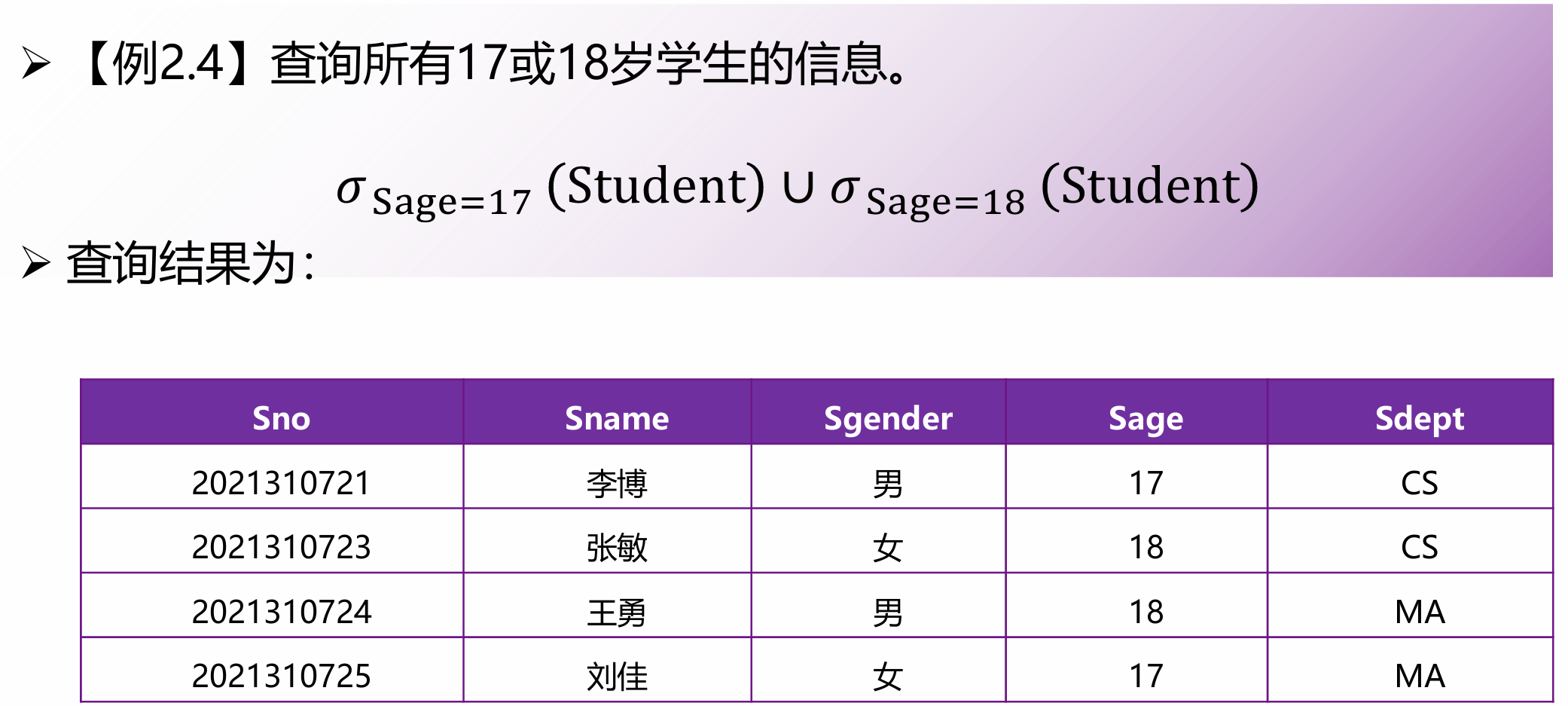
差
![]()
在 R 中但不在 S 中的元组。
(求“选了课但没及格”的学生,就是 选课表 – 及格表)

交

既在 R 中又在 S 中的元组。
(注:
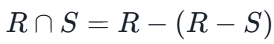
)
笛卡尔积
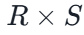
把 R 的每一行与 S 的每一行强行拼接。
结果列数 = 列数相加,行数 = 行数相乘。
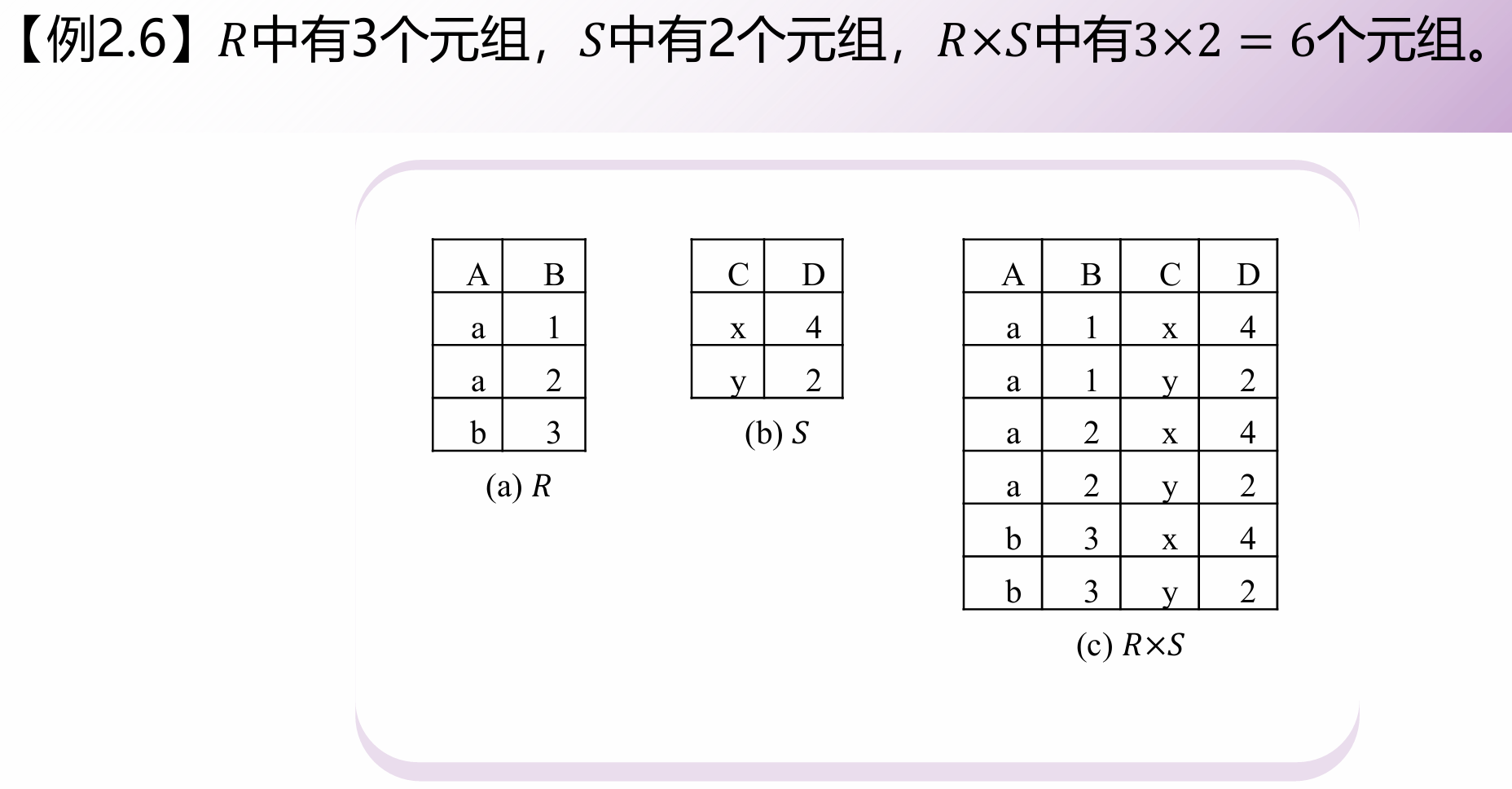
(通常会产生大量无意义的垃圾数据,需要配合“选择”来过滤)。
专门的关系运算(核心骨干)
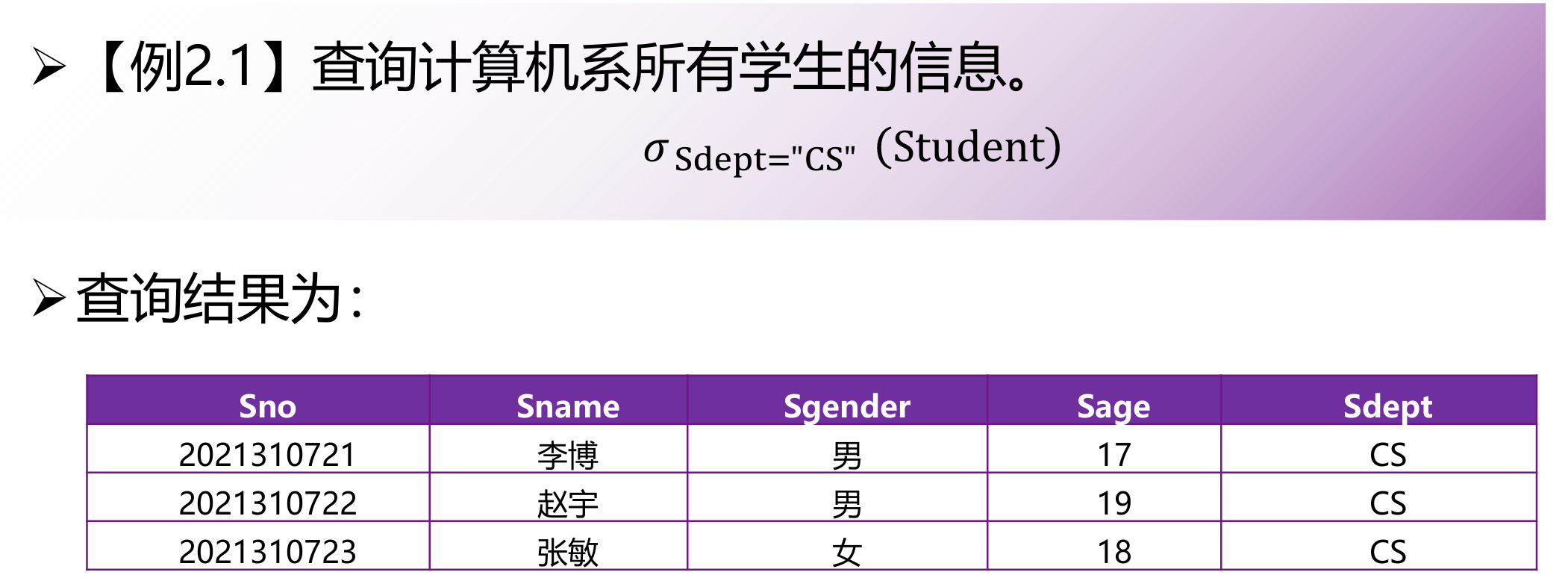
选择(Selection)
行过滤。从关系中挑出满足给定布尔条件的元组。
格式:

相当于 SQL 中的 WHERE
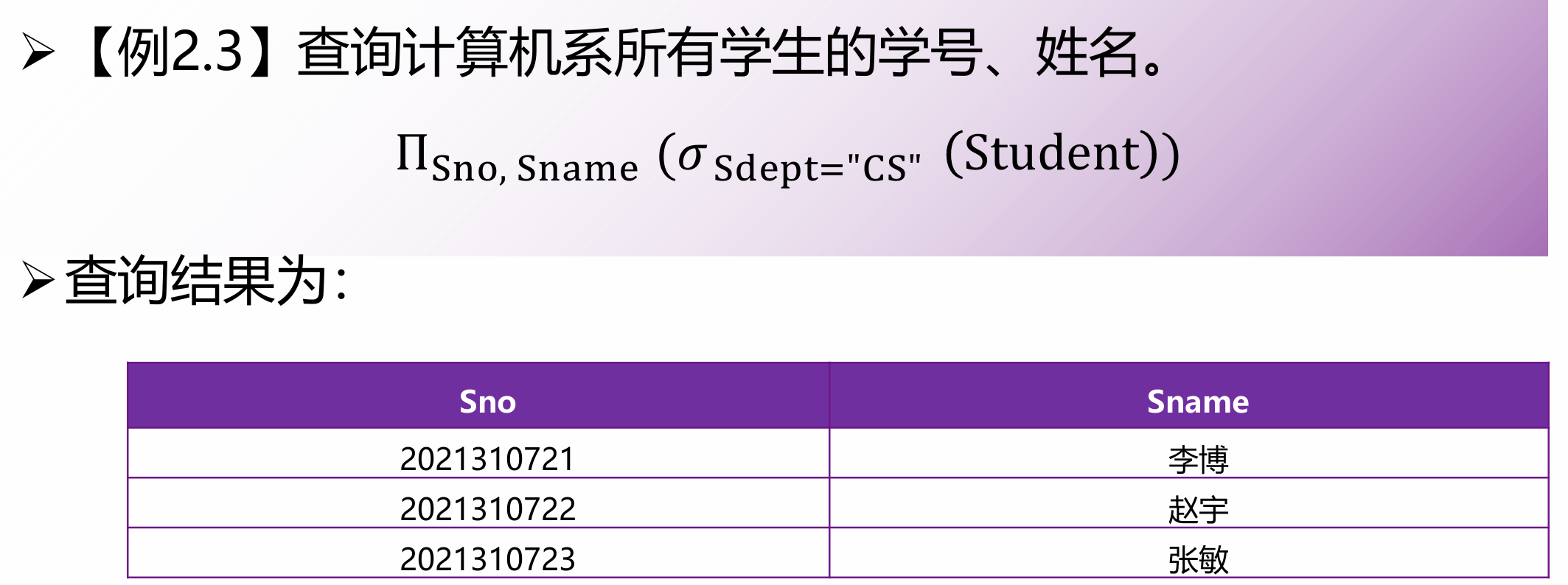
投影(Projection)
列过滤。从关系中挑选出指定的若干属性列。注意:投影会自动取消重复的行!
格式:

相当于 SQL 中的 SELECT 列1, 列2
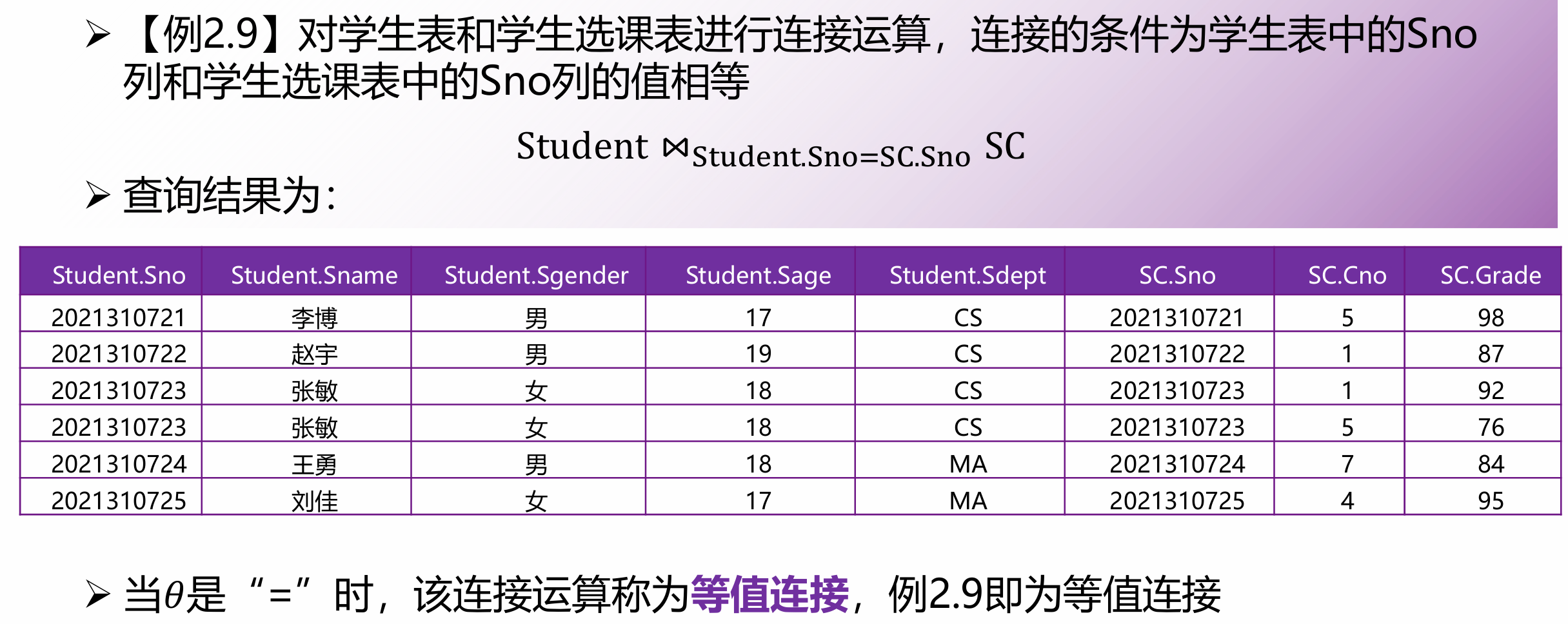
等值连接
条件为
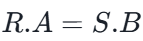
拼接后,A列和B列都会保留在结果中。
自然连接
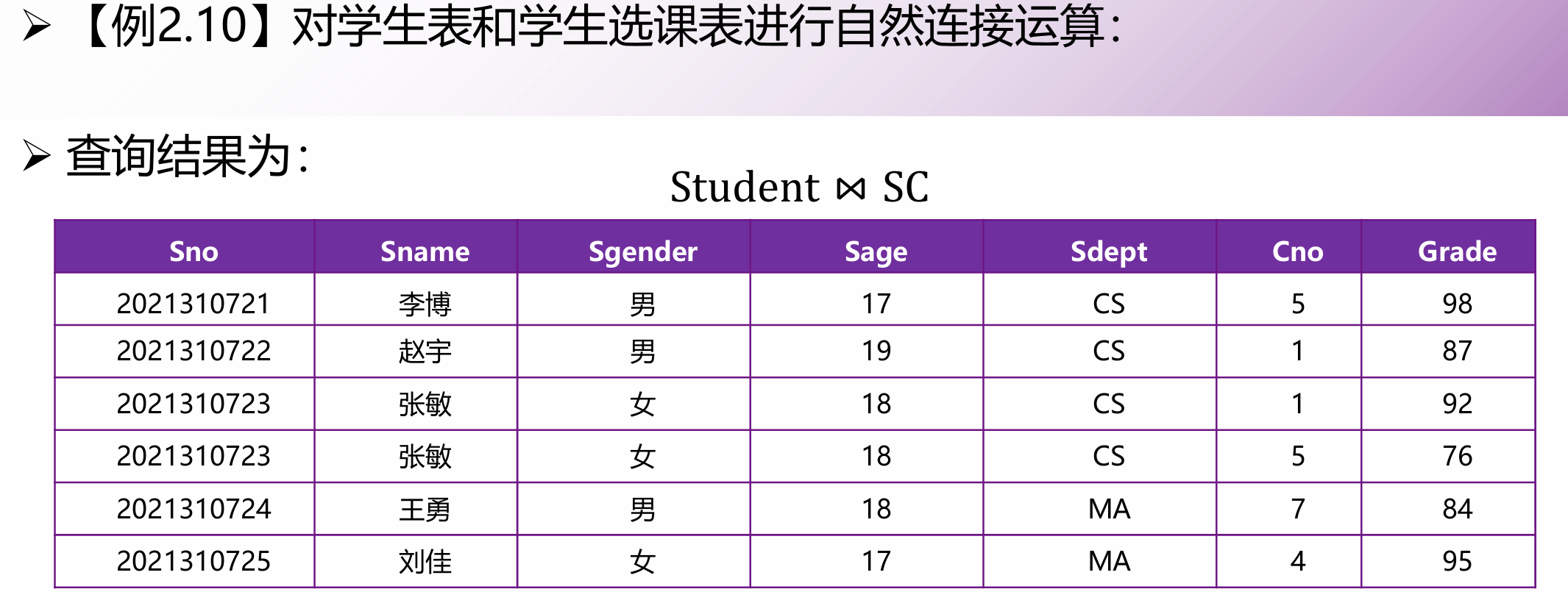
特殊的等值连接。
它要求两个关系必须在同名属性上进行等值比较,并且在结果中自动去掉重复的同名列。
遇到自然连接,先找两表的公共列,按公共列值相等进行匹配拼接,最后只保留一列公共列。
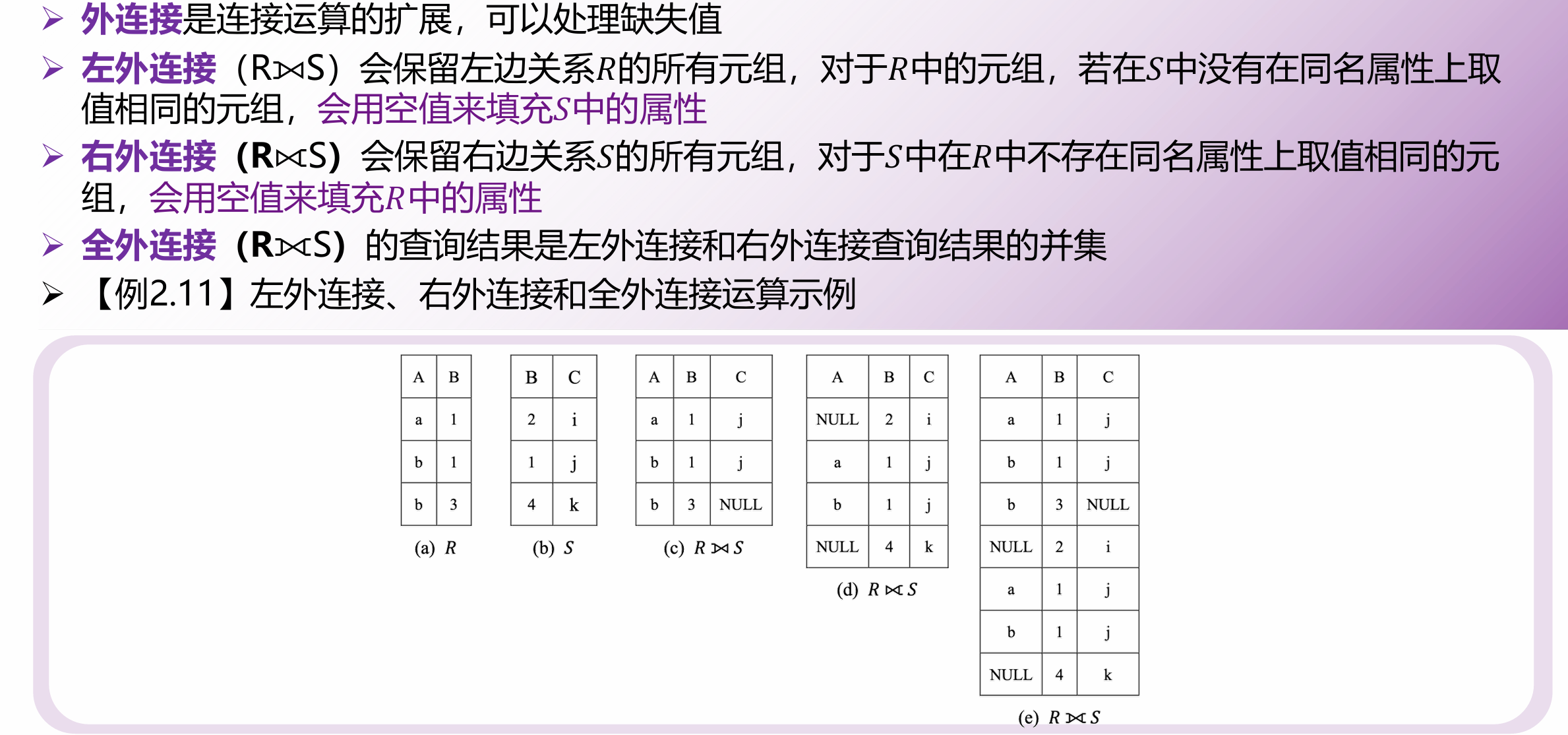
外连接、内连接
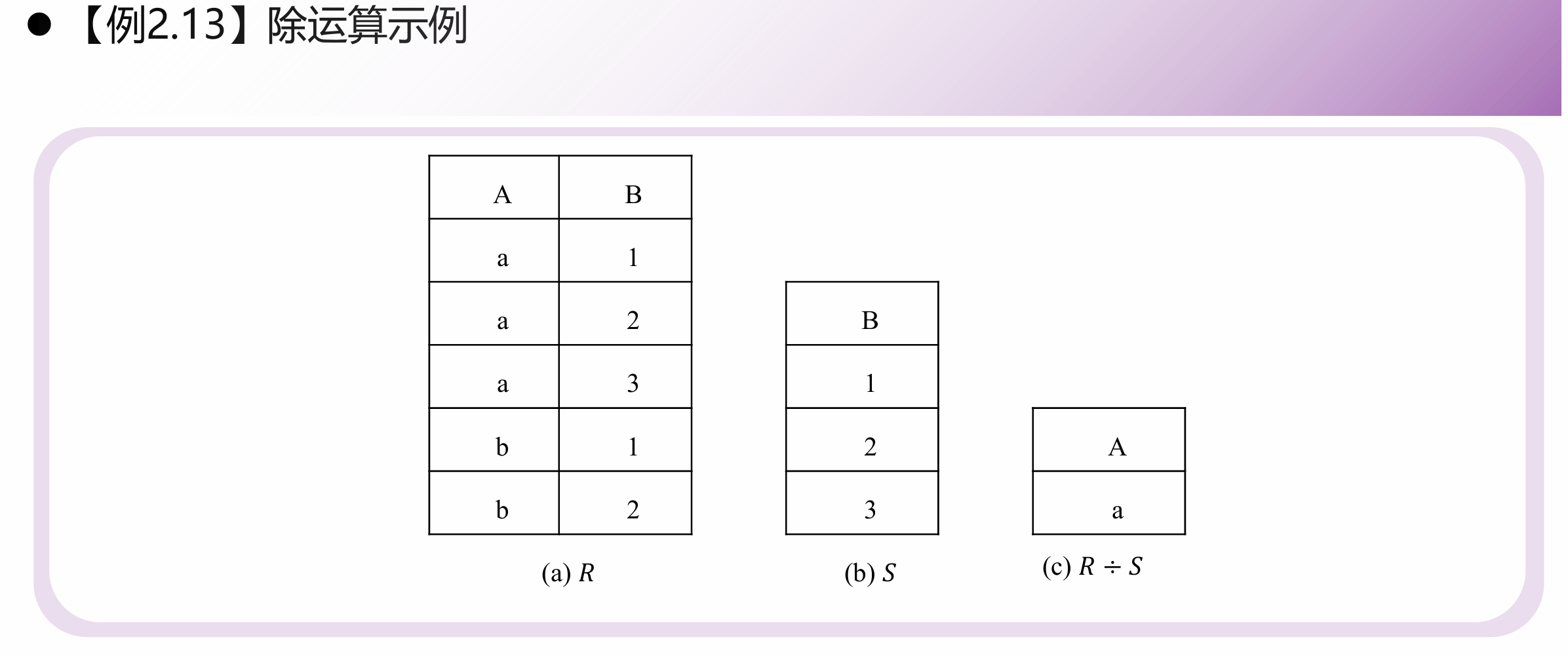
除(Division)
“全部包含”查询。同时满足投影和选择的复合操作。

场景:“查询选修了全部课程的学生学号”。把学生选课表按学号除以课程表,能除尽的学号就是答案。
5.2.4 关系规范化理论(核心难点:解决数据冗余与异常)
如果设计数据库时,为了图省事把所有东西塞进一张大表(俗称“大宽表”),就会引发灾难。
存储异常问题剖析(为什么要拆表?)
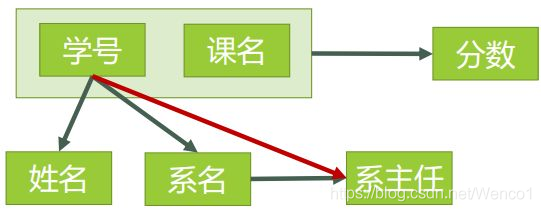
假设有一张表:选课表(学号, 姓名, 系名, 系主任, 课号, 成绩)
数据冗余:一个学生选了 10 门课,他的“姓名、系名、系主任”就要被重复存 10 次,浪费硬盘。
更新异常:如果该系换了个系主任,需要更新该系所有学生的记录,漏改一条数据就不一致了。
插入异常:如果新建了一个“武术系”,暂时还没招学生,因为没有“学号”和“课号”(它们是主码的一部分),导致系的信息无法录入数据库。
删除异常:如果某个学生把选的课全退了,把记录一删,这个学生的基本信息和所在系的信息也跟着从数据库里消失了。
函数依赖(FD,决定异常的数学本质)
设 X -> Y(读作 X 决定 Y),意思是“在当前表中,只要 X 的值确定了,Y 的值就唯一确定”。这就像函数 y = f(x) 一样。
完全函数依赖
X -> Y,且 X 的任何真子集都不能决定 Y。
例子:在 {学号, 课号} -> 成绩 中,单独学号不能定成绩,单独课号也不能定成绩,必须联合起来,这就是完全依赖。(这是好的依赖,必须保留)。
部分函数依赖
X -> Y,但 Y 实际上只依赖于 X 的一部分属性。
例子:在 {学号, 课号} -> 姓名 中,姓名其实只依赖“学号”,“课号”在这里是个打酱油的。(这就是万恶之源,是导致 2NF 异常的元凶)。
传递函数依赖
若 X -> Y(但 Y 不能反向决定 X),且 Y -> Z,则称 Z 对 X 传递依赖。
例子:学号 -> 系名,系名 -> 系主任,推导出 学号 -> 系主任。系主任是通过系名“传递”过来的。(这是导致 3NF 异常的元凶)。
范式升级路径(拆表的实操指南)
范式是符合某一种级别的关系模式的集合。
级别越高,冗余越小,但表拆得越碎,查询时需要连表(JOIN)的性能开销就越大。
实际工程中,通常达到 3NF 或 BCNF 即可。
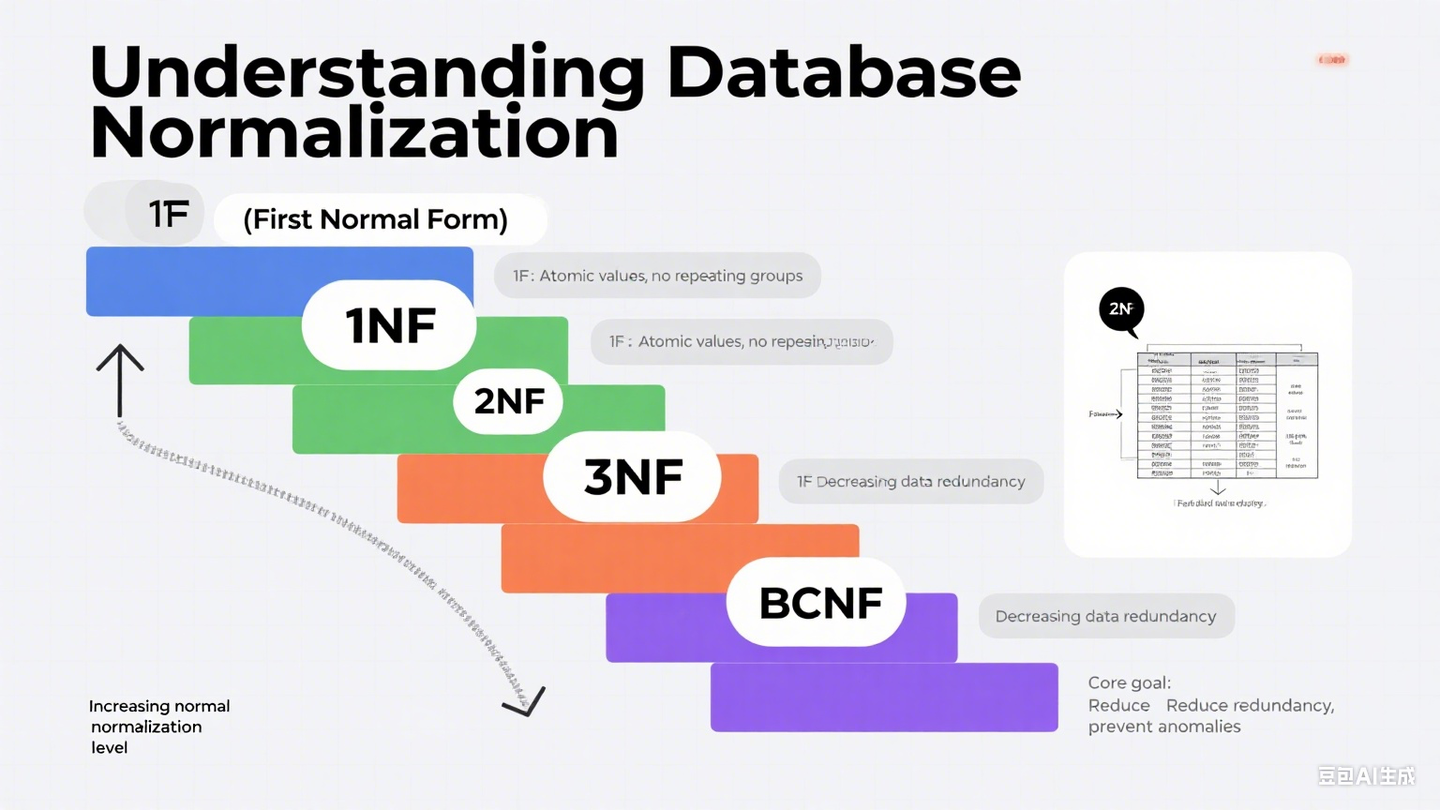
| 范式 | 核心口诀 | 关键动作 | 解决的问题 |
|---|---|---|---|
| 1NF | 列要原子不可分 | 拆分多值列 | 数据结构混乱,无法检索单值 |
| 2NF | 非主属性靠主键 | 拆分复合主键表 | 部分依赖导致的数据冗余 |
| 3NF | 非主属性别互赖 | 拆分传递依赖表 | 传递依赖导致的更新/插入异常 |
第一范式 (1NF)——属性不可再分
检验标准:表里的每个单元格必须是纯粹的原子值。
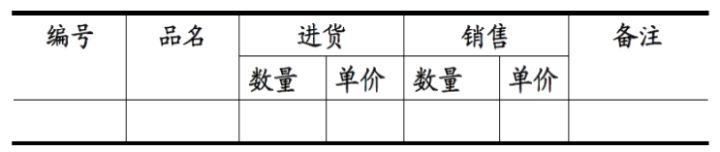
比如“联系方式”这一列不能填“电话:123, 邮箱:abc”,必须拆成两列。

(满足1NF是关系型数据库的最基本要求)。
第二范式 (2NF)
在 1NF 基础上,消除非主属性对码的“部分函数依赖”。
拆表动作:
把部分依赖的属性剥离出去。在上例中,把 {学号, 课号, 成绩} 留在原表,把 {学号, 姓名, 系名, 系主任} 拆成一张新表。
结果:
此时所有非主属性都完全依赖于整个主码了。
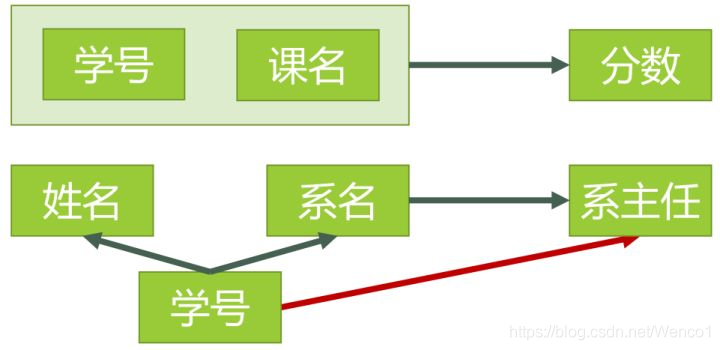
(注:如果一张表的主码只有一个属性,它天然满足 2NF,因为不存在部分依赖)。
第三范式 (3NF)
在 2NF 基础上,消除非主属性对码的“传递函数依赖”。
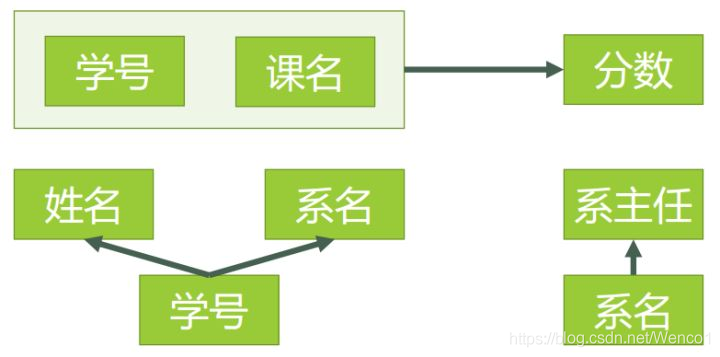
拆表动作:
把传递依赖的链条斩断。继续拆上面那张新表,把 {学号, 姓名, 系名} 留在学生表,把 {系名, 系主任} 拆成一张系别表。
结果:
在 3NF 下,非主属性既不部分依赖于码,也不传递依赖于码。
2NF 和 3NF 只针对“非主属性”提要求,不管“主属性”。绝大多数业务系统做到这就够了。
BC范式
在 3NF 基础上的加强版。
所有的属性(包括主属性本身)都不能对候选码产生部分依赖和传递依赖。
换句话说,在 BCNF 中,只有候选码才能决定其他属性,没有任何非码属性能决定别的属性。
(BCNF 消除了主属性内部的冗余,理论上的完美形态,但有时为了查询效率会刻意不满足它)。
模式分解的准则
把一个大表拆成几个满足 3NF 的小表,不能瞎拆,必须同时满足以下两个黄金准则:
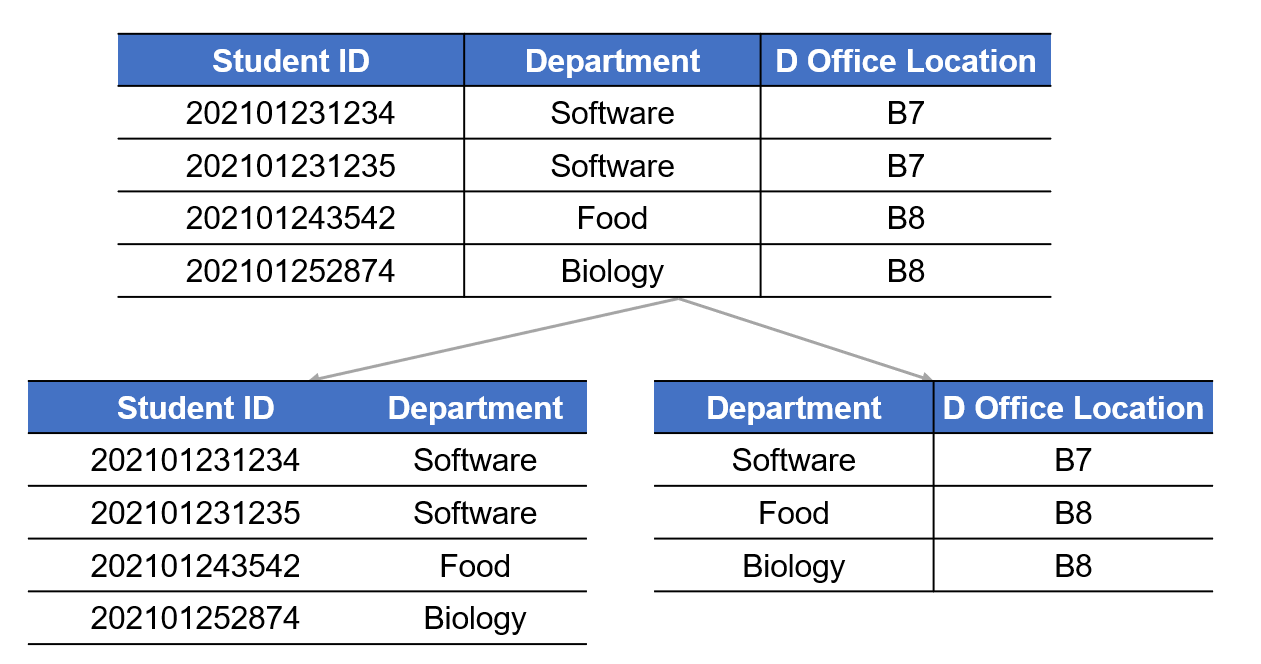
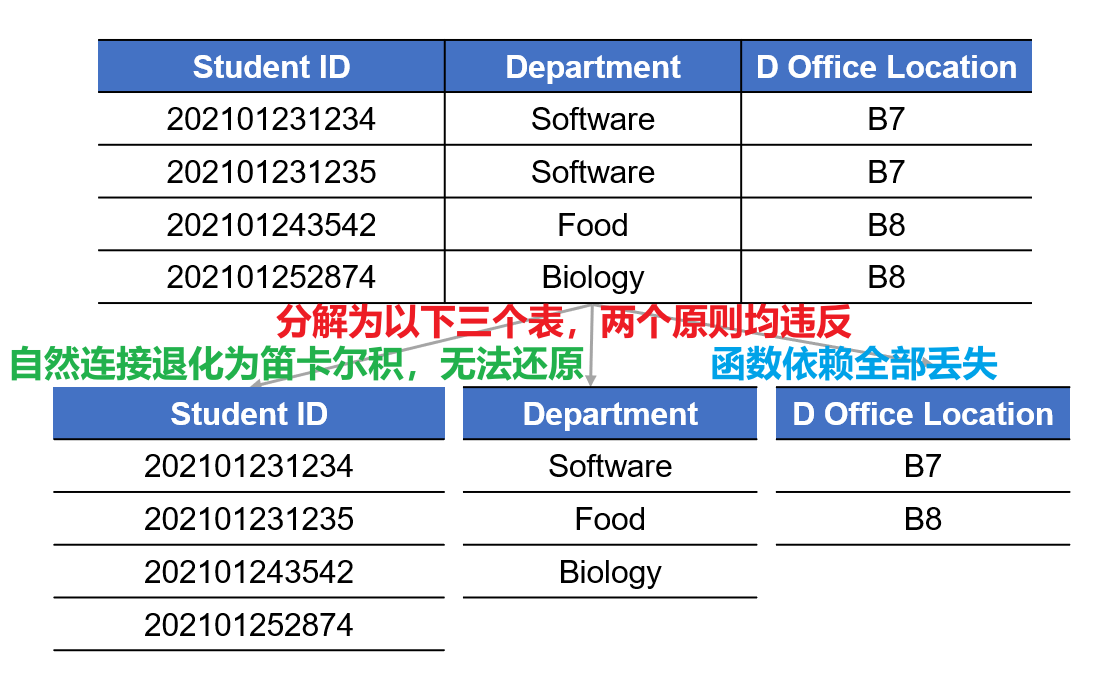
无损连接性
拆完之后,把这几个小表按照原来的外键/主键关系自然连接起来,必须能百分之百还原成原来那张大表,不能多出一条记录,也不能少一条记录。(绝对底线:不能丢数据!)
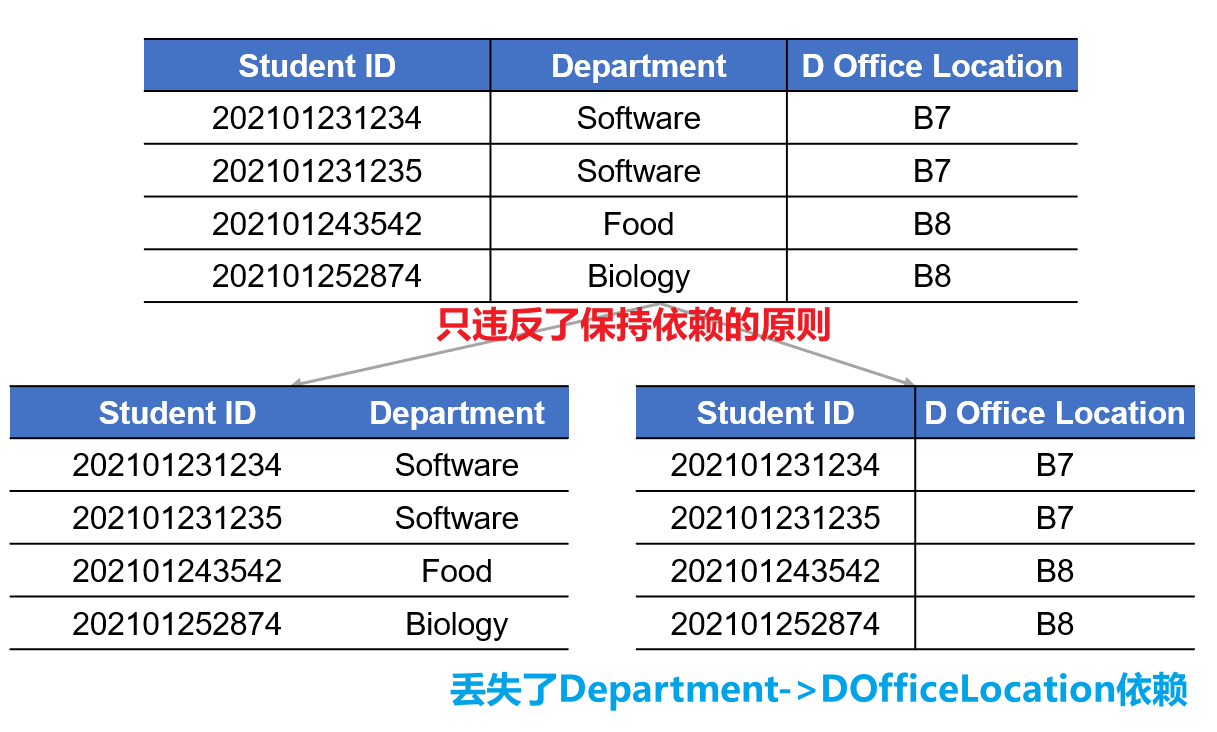
保持函数依赖
拆完之后,原来在大表里存在的那些函数依赖规则(比如 学号决定姓名),在拆分后的小表里还必须能找得到,不能因为拆表导致约束条件丢失。(高线要求:防止更新异常死灰复燃!)
© 版权声明
文章版权归作者所有,未经允许请勿转载。