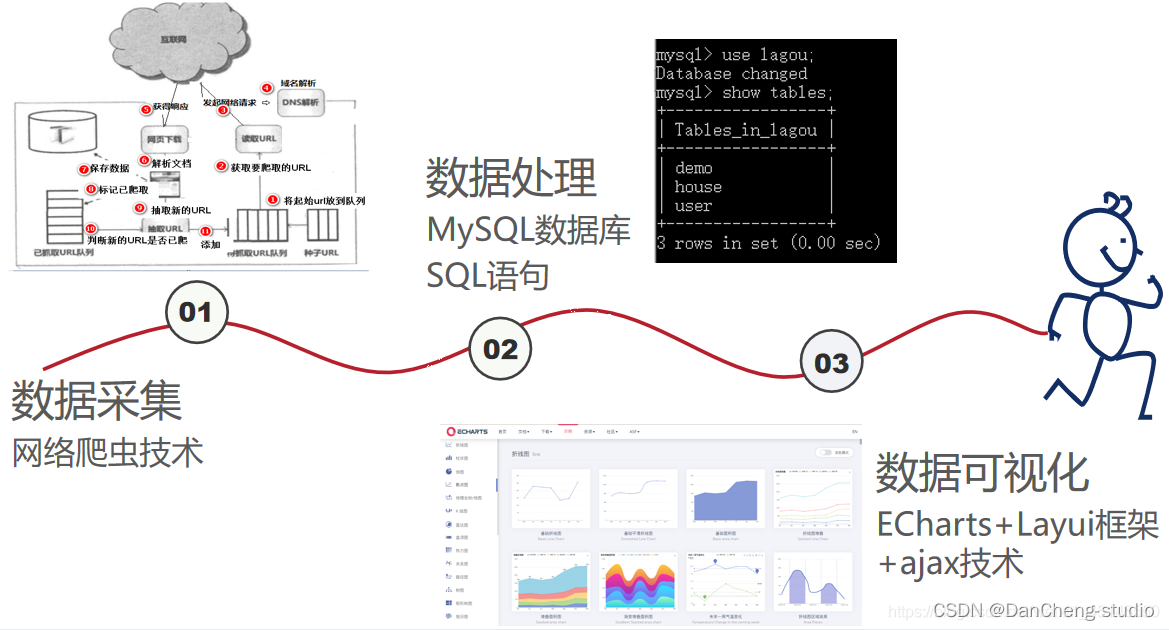
Hadoop课程学习:从理论到实践的深度感悟与技术沉淀
在大数据技术迅猛发展的当下,Hadoop作为分布式计算与存储的核心框架,早已成为大数据领域的入门必备与核心基石。作为一名兼具工程实践经验与大学学生双重身份的学习者,我在Hadoop课程的学习过程中,不仅系统掌握了框架的核心原理与技术细节,更在编程实践、项目落地中深化了对分布式系统、软件工程思想的理解。本文将从课程学习的全流程出发,详细梳理Hadoop核心技术的学习要点、编程实践中的思路与技巧、项目实战的经验总结,以及对编程类、软件工程类课程学习的共性感悟,希望能为同为大数据学习者的伙伴们提供参考。全文约10000字,包含大量技术解析、实践案例与思路沉淀,辅以关键技术图示,助力大家更直观地理解Hadoop核心逻辑。
一、课程初识:Hadoop的核心定位与学习规划
1.1 为什么要学Hadoop?—— 从技术趋势到个人成长
在接触Hadoop课程之前,我已通过工程实践感受到大数据技术在企业中的广泛应用:从电商平台的用户行为分析,到金融领域的风险控制,再到互联网企业的日志处理,几乎所有需要处理海量数据的场景,都离不开分布式计算框架的支撑。而Hadoop作为大数据生态的"开山鼻祖",其提出的分布式存储(HDFS)与分布式计算(MapReduce)思想,奠定了后续Spark、Flink等框架的基础。
对于学习者而言,Hadoop的学习价值不仅在于掌握一门技术,更在于建立"分布式思维"—— 如何将海量数据拆分处理、如何应对节点故障、如何保证数据一致性,这些思考方式将贯穿整个大数据技术学习的始终。此外,Hadoop生态系统庞大且成熟,掌握Hadoop后,再学习Hive、HBase、ZooKeeper等周边组件时,会形成清晰的技术脉络,降低学习成本。
1.2 学习规划:从理论到实践的阶梯式进阶
结合课程安排与自身实践经验,我将Hadoop学习分为三个阶段,形成了阶梯式的学习路径,避免了"盲目上手编程"或"只懂理论不会实践"的误区:
-
理论筑基阶段:重点学习分布式系统的核心概念(一致性、容错性、可扩展性)、Hadoop的起源与架构设计、核心组件(HDFS、MapReduce、YARN)的工作原理。此阶段的目标是理解"为什么这么设计",而非单纯记忆API。
-
编程入门阶段:搭建本地Hadoop环境与分布式集群,从基础API调用开始(如HDFS的文件读写、MapReduce的WordCount案例),熟悉Hadoop的编程模型,掌握核心类的使用场景与调用逻辑。
-
项目实战阶段:基于真实业务场景设计项目(如日志分析、用户行为统计),整合Hadoop核心技术与周边组件,解决实践中遇到的问题(如数据倾斜、集群优化),深化对技术的理解与应用能力。
在学习过程中,我特别注重"理论与实践结合":每学习一个核心原理,就通过编程实践验证逻辑;每完成一个编程案例,就回头复盘对应的理论知识点,形成"原理-实践-复盘"的闭环。
二、理论筑基:Hadoop核心组件原理深度解析
Hadoop的核心价值在于其分布式架构设计,能够高效处理海量数据。其核心组件主要包括HDFS(分布式文件系统)、MapReduce(分布式计算框架)与YARN(资源调度框架)。这三个组件相互配合,构成了Hadoop处理大数据的基础能力。下面将详细解析各组件的核心原理,这也是后续编程与项目实践的基础。
2.1 HDFS:分布式文件系统的设计思想与核心原理
HDFS(Hadoop Distributed File System)是Hadoop的分布式存储组件,主要用于存储海量的大文件(通常以GB、TB为单位)。其设计思想源于Google的GFS论文,核心目标是在普通硬件组成的集群中,实现高可靠性、高吞吐量的文件存储。
2.1.1 HDFS的核心架构
HDFS采用主从(Master/Slave)架构,主要由NameNode、DataNode和SecondaryNameNode三个角色组成,各角色的职责明确,相互配合完成文件的存储与管理:
- NameNode(主节点):作为HDFS的"大脑",负责管理文件系统的命名空间(如文件路径、文件名)、维护文件与数据块(Block)的映射关系、记录数据块的副本信息,以及处理客户端的文件操作请求(如打开、关闭、重命名文件)。NameNode不存储具体的文件数据,仅存储元数据(Metadata),元数据占用空间较小,通常可以加载到内存中,保证了文件操作的高效性。
- DataNode(从节点):作为HDFS的"存储节点",负责存储实际的文件数据块、执行数据块的读写操作,并定期向NameNode汇报自身的健康状态与数据块信息。DataNode之间可以相互通信,完成数据块的复制(以保证副本数量)。
- SecondaryNameNode(辅助主节点):并非NameNode的备份节点(很多初学者会误解这一点),其核心职责是帮助NameNode合并编辑日志(EditLog)与镜像文件(FsImage),减少NameNode启动时的加载时间,同时可以在NameNode故障时,提供一份较新的元数据备份,辅助数据恢复。
2.1.2 HDFS的核心设计:数据块与副本机制
HDFS将文件分割成固定大小的数据块(Block)进行存储,默认块大小为128MB(可通过配置修改)。采用大数据块的设计,主要有两个优势:一是减少元数据的数量(每个块仅需一条元数据记录),降低NameNode的存储压力;二是减少数据传输过程中的寻址时间,提高数据吞吐量(对于大文件而言,寻址时间占比远小于传输时间)。
为了保证数据的可靠性,HDFS采用副本机制:每个数据块会被复制到多个DataNode上,默认副本数为3。副本的放置策略经过了精心设计,以平衡可靠性与性能:第一个副本放置在客户端所在的节点(如果客户端在集群内);第二个副本放置在与第一个副本不同的机架上;第三个副本放置在与第二个副本相同机架的不同节点上。这种策略既保证了在机架故障时数据不丢失,又减少了跨机架数据传输的开销。
2.1.3 HDFS的读写流程
(1)读文件流程
- 客户端向NameNode发送读文件请求,指定文件路径。
- NameNode查询元数据,找到文件对应的所有数据块及其副本的DataNode节点列表,将列表返回给客户端。
- 客户端根据DataNode节点列表,选择距离最近的DataNode(通常是本地节点或同机架节点),直接向该DataNode发送数据块读取请求。
- DataNode将数据块传输给客户端,客户端接收数据后,拼接成完整的文件。
- 如果某个DataNode故障,客户端会自动切换到其他副本所在的DataNode读取数据。
(2)写文件流程
- 客户端向NameNode发送写文件请求,指定文件路径。
- NameNode检查文件路径是否存在、客户端是否有写权限,若通过检查,则为文件分配数据块,并指定存储数据块的DataNode节点列表(基于副本放置策略),将节点列表返回给客户端。
- 客户端与DataNode节点列表建立数据传输管道(Pipeline),将文件数据分割成数据包,通过管道依次传输给各个DataNode。
- 每个DataNode接收数据包后,一方面存储本地,另一方面将数据包传输给下一个DataNode,直到所有副本都完成存储。
- 所有数据块传输完成后,客户端向NameNode发送写完成请求,NameNode更新元数据。
2.2 MapReduce:分布式计算的编程模型与执行流程
MapReduce是Hadoop的分布式计算框架,其核心思想源于函数式编程中的Map(映射)和Reduce(归约)操作。MapReduce将复杂的分布式计算任务拆分为两个阶段:Map阶段和Reduce阶段,通过"分而治之"的思想,实现海量数据的并行处理。
2.2.1 MapReduce的核心编程模型
MapReduce的编程模型非常简洁,开发者只需实现两个核心函数:Map函数和Reduce函数,框架会自动完成任务的分发、并行执行、数据传输、结果汇总等工作。其核心逻辑如下:
- Map阶段:输入数据为键值对(Key-Value),Map函数对输入数据进行处理(如过滤、转换、提取),输出中间键值对(Intermediate Key-Value)。例如,在WordCount案例中,Map函数接收一行文本(Key为行号,Value为文本内容),将文本拆分为单词,输出(单词,1)的中间键值对。
- Shuffle阶段:这是MapReduce的核心阶段,也是框架自动完成的阶段,开发者无需编码。Shuffle阶段负责将Map阶段的中间键值对按照Key进行分组、排序,并传输给对应的Reduce节点。具体包括三个步骤:Map端的分区(Partition)、排序(Sort)与合并(Combine),以及Reduce端的拉取(Fetch)、合并(Merge)与排序(Sort)。
- Reduce阶段:输入数据为Shuffle阶段处理后的键值对(同一Key的所有Value被归为一组),Reduce函数对同一Key的Value集合进行聚合处理(如求和、计数、平均值),输出最终的键值对结果。例如,在WordCount案例中,Reduce函数接收(单词,[1,1,1,…])的输入,对Value集合求和,输出(单词,总次数)的结果。
2.2.2 MapReduce的执行流程
MapReduce的执行流程涉及多个角色(JobTracker/ResourceManager、TaskTracker/Nodemanager、MapTask、ReduceTask),流程较为复杂,可分为以下几个核心步骤:
- 任务提交:客户端编写MapReduce程序,将程序打包成JAR包,通过JobClient向ResourceManager(YARN中的资源调度主节点)提交任务(Job),并指定输入数据路径(HDFS上)和输出数据路径(HDFS上)。
- 任务初始化:ResourceManager接收任务后,为任务分配第一个容器(Container),并在该容器中启动ApplicationMaster(AM)。AM负责整个任务的生命周期管理,首先向ResourceManager申请执行MapTask和ReduceTask所需的容器资源。
- MapTask执行:AM将MapTask分配到各个Nodemanager节点的容器中执行。MapTask读取HDFS上的输入数据,按照开发者实现的Map函数处理数据,生成中间键值对,存储在本地磁盘(而非HDFS,因为中间数据无需长期存储),并完成Shuffle阶段的Map端处理(分区、排序、合并)。
- ReduceTask执行:MapTask完成后,AM启动ReduceTask。ReduceTask通过HTTP协议,从各个MapTask的本地磁盘拉取属于自己的中间键值对(根据Partition规则),完成Shuffle阶段的Reduce端处理(合并、排序),然后按照开发者实现的Reduce函数对数据进行聚合处理,将最终结果写入HDFS。
- 任务完成:所有MapTask和ReduceTask执行完成后,AM向ResourceManager汇报任务完成状态,ResourceManager释放任务占用的所有资源,客户端可以从HDFS的输出路径获取任务结果。
2.3 YARN:资源调度与任务管理框架
在Hadoop 1.0版本中,MapReduce同时承担了计算任务管理和资源调度的职责,导致框架的耦合度高、扩展性差。Hadoop 2.0版本引入了YARN(Yet Another Resource Negotiator),将资源调度与任务管理分离,YARN负责集群的资源调度,MapReduce仅负责计算任务的执行,极大地提升了框架的灵活性和扩展性——YARN不仅可以调度MapReduce任务,还可以调度Spark、Flink、Storm等多种计算框架的任务。
2.3.1 YARN的核心架构
YARN同样采用主从架构,主要由ResourceManager、NodeManager和ApplicationMaster三个角色组成:
- ResourceManager(RM,主节点):负责整个集群的资源(CPU、内存)管理与调度,接收客户端提交的任务,为任务分配容器资源,监控NodeManager的状态。RM包含两个核心组件:调度器(Scheduler)和应用程序管理器(ApplicationsManager)。调度器仅负责资源分配,不参与任务的生命周期管理;应用程序管理器负责接收任务提交、启动AM、监控AM状态(若AM故障,可重新启动)。
- NodeManager(NM,从节点):负责单个节点的资源管理与任务监控,向RM汇报节点的资源使用情况和任务执行状态,接收RM的指令,启动和停止容器,以及监控容器的资源使用(如CPU利用率、内存占用)。
- ApplicationMaster(AM,应用程序主节点):每个任务(Application)对应一个AM,负责任务的生命周期管理,包括向RM申请执行任务所需的容器资源、将任务分配到容器中执行、监控任务的执行状态(若任务故障,可重新启动)、向客户端汇报任务进度。
2.3.2 YARN的资源调度流程
YARN的资源调度流程围绕"容器(Container)"展开,容器是YARN中资源分配的基本单位,包含了一定量的CPU和内存资源。其核心调度流程如下:
- 客户端向RM提交任务,指定任务所需的资源总量和AM的启动参数。
- RM的应用程序管理器为任务分配第一个容器,启动AM。
- AM向RM的调度器申请执行任务所需的容器资源,提交资源申请请求(包含所需资源量、节点偏好等信息)。
- 调度器根据集群资源使用情况和调度策略(如FIFO、Capacity Scheduler、Fair Scheduler),为AM分配容器资源,并通知对应的NM启动容器。
- AM将任务(如MapTask、ReduceTask)分发到各个容器中执行,监控任务执行状态。
- 任务执行完成后,AM向RM汇报任务完成状态,RM通知NM释放容器资源。
三、编程实践:从API调用到核心逻辑实现
理论学习的最终目的是指导实践,Hadoop的编程实践主要围绕HDFS的文件操作和MapReduce的分布式计算展开。在这一阶段,我从基础API调用入手,逐步深入到核心逻辑的自定义实现,积累了大量的编程思路与技巧。下面将结合具体案例,详细梳理编程实践的过程与感悟。
3.1 环境搭建:本地模式与分布式集群
在进行编程实践前,首先需要搭建Hadoop运行环境。根据学习阶段的不同,可选择本地模式、伪分布式模式或完全分布式模式:
- 本地模式:无需启动Hadoop集群,所有操作都在本地JVM中执行,适用于基础API的调试(如HDFS的本地文件操作、MapReduce的本地调试)。搭建简单,只需配置JAVA_HOME和HADOOP_HOME环境变量即可。
- 伪分布式模式:在单个节点上模拟分布式集群,NameNode、DataNode、ResourceManager、NodeManager等角色都运行在同一个节点上,适用于熟悉集群的启动与管理、MapReduce任务的提交与执行。需要配置Hadoop的核心配置文件(core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml),并格式化NameNode。
- 完全分布式模式:由多个节点组成集群,不同角色分布在不同节点上(如1个NameNode节点、多个DataNode节点、1个ResourceManager节点),适用于项目实战和性能测试。需要配置节点间的SSH免密登录、同步所有节点的Hadoop配置文件,并确保所有节点的时间同步。
【实践技巧】:在学习初期,建议先使用本地模式进行API调试,熟悉核心类的使用后,再搭建伪分布式模式进行集群操作练习;完全分布式模式可在项目实战阶段搭建,感受真实集群的资源调度与任务执行。搭建过程中,注意环境变量的配置和配置文件的正确性,常见问题包括JAVA_HOME配置错误、SSH免密登录失败、节点时间不同步等,可通过查看Hadoop的日志文件(位于$HADOOP_HOME/logs目录)定位问题。
3.2 HDFS编程实践:文件操作API的使用与技巧
HDFS的编程主要通过Java API实现,核心类包括Configuration、FileSystem、Path、FSDataInputStream、FSDataOutputStream等。下面结合具体案例,讲解HDFS文件操作的核心API使用方法与编程技巧。
3.2.1 核心API介绍
- Configuration:用于加载Hadoop的配置文件(如core-site.xml),获取HDFS的相关配置信息(如NameNode的地址)。通过Configuration对象,程序可以连接到HDFS集群。
- FileSystem:HDFS文件系统的抽象类,是所有HDFS文件操作的入口。通过FileSystem.get(Configuration)方法可以获取FileSystem实例。
- Path:用于表示HDFS上的文件路径,支持绝对路径和相对路径。
- FSDataInputStream:HDFS的输入流,用于读取HDFS上的文件数据,继承自Java的DataInputStream。
- FSDataOutputStream:HDFS的输出流,用于向HDFS写入文件数据,继承自Java的DataOutputStream。
3.2.2 具体案例:HDFS文件的增删改查
下面通过一个完整的Java程序,实现HDFS文件的创建、写入、读取、删除等操作,展示核心API的使用方法:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
public class HDFSFileOperation {
// HDFS集群的NameNode地址(伪分布式模式下通常为hdfs://localhost:9000)
private static final String HDFS_URI = "hdfs://localhost:9000";
public static void main(String[] args) throws IOException {
// 1. 加载配置信息
Configuration conf = new Configuration();
// 若使用本地模式,无需指定FileSystem的实现类;若连接集群,需指定
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
// 2. 获取FileSystem实例
FileSystem fs = FileSystem.get(URI.create(HDFS_URI), conf, "hadoop"); // 第三个参数为Hadoop用户名
try {
// 3. 向HDFS写入文件(创建文件并写入内容)
String destPath = "/user/hadoop/test.txt"; // HDFS上的目标路径
Path destFilePath = new Path(destPath);
FSDataOutputStream outputStream = fs.create(destFilePath, true); // true表示覆盖已存在的文件
outputStream.write("Hello, HDFS! This is a test file.".getBytes());
outputStream.flush();
System.out.println("文件写入成功:" + destPath);
// 4. 从HDFS读取文件
FSDataInputStream inputStream = fs.open(destFilePath);
System.out.println("文件内容:");
IOUtils.copyBytes(inputStream, System.out, 4096, false); // 4096为缓冲区大小,false表示不关闭System.out
System.out.println();
// 5. 查看文件信息
FileStatus fileStatus = fs.getFileStatus(destFilePath);
System.out.println("文件路径:" + fileStatus.getPath());
System.out.println("文件大小:" + fileStatus.getLen() + " bytes");
System.out.println("文件副本数:" + fileStatus.getReplication());
System.out.println("文件块大小:" + fileStatus.getBlockSize() + " bytes");
// 6. 列出目录下的文件(以/user/hadoop为例)
Path dirPath = new Path("/user/hadoop");
FileStatus[] fileStatuses = fs.listStatus(dirPath);
System.out.println("\n目录" + dirPath + "下的文件:");
for (FileStatus status : fileStatuses) {
System.out.println(status.getPath().getName() + (status.isDirectory() ? "(目录)" : "(文件)"));
}
// 7. 删除文件
boolean deleteResult = fs.delete(destFilePath, false); // false表示不递归删除目录
if (deleteResult) {
System.out.println("文件删除成功:" + destPath);
} else {
System.out.println("文件删除失败:" + destPath);
}
} finally {
// 8. 关闭FileSystem实例,释放资源
IOUtils.closeStream(fs);
}
}
}
3.2.3 编程技巧与注意事项
- 资源释放:FileSystem、FSDataInputStream、FSDataOutputStream等流对象必须在使用完成后关闭,否则会导致资源泄露。建议使用try-finally块或Java 7以上的try-with-resources语句自动关闭资源。
- .配置优先级:Hadoop的配置优先级为:程序中通过Configuration.set()方法设置的配置 > 项目中的自定义配置文件 > Hadoop安装目录下的默认配置文件。在连接集群时,需确保配置文件中NameNode的地址、端口等信息正确。
- 文件读取优化:读取大文件时,应使用缓冲区(如IOUtils.copyBytes()方法中的4096字节缓冲区),避免一次性读取整个文件到内存中,导致内存溢出。
- 异常处理:HDFS操作可能会遇到多种异常(如文件不存在、权限不足、集群连接失败等),应做好异常捕获与处理,提高程序的健壮性。
3.3 MapReduce编程实践:从基础案例到自定义逻辑
MapReduce的编程核心是实现Map函数和Reduce函数,同时配置任务的相关参数(如输入输出路径、数据格式、MapReduce类等)。下面从经典的WordCount案例入手,逐步深入到自定义逻辑的实现,讲解MapReduce编程的思路与技巧。
3.3.1 基础案例:WordCount(单词计数)
WordCount是MapReduce的入门案例,功能是统计文本文件中每个单词出现的次数。下面通过完整的Java程序,实现WordCount的核心逻辑,并讲解各部分的作用。
(1)Map类实现
Map类继承自Mapper<LongWritable, Text, Text, IntWritable>,其中四个泛型分别表示:Map输入Key的类型(行号,LongWritable)、Map输入Value的类型(行文本内容,Text)、Map输出Key的类型(单词,Text)、Map输出Value的类型(计数1,IntWritable)。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* WordCount的Map类
* 输入:<行号(LongWritable), 行文本(Text)>
* 输出:<单词(Text), 计数1(IntWritable)>
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 定义输出的Value(固定为1),避免在map方法中重复创建对象,提高性能
private static final IntWritable ONE = new IntWritable(1);
// 定义输出的Key(单词)
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1. 将行文本内容转换为字符串
String line = value.toString();
// 2. 分割单词(使用空格、逗号、句号等作为分隔符)
String[] words = line.split("[\\s,\\.\\!\\?]+");
// 3. 遍历单词,输出<单词, 1>的键值对
for (String wordStr : words) {
if (!wordStr.isEmpty()) { // 过滤空字符串
word.set(wordStr);
context.write(word, ONE);
}
}
}
}
(2)Reduce类实现
Reduce类继承自Reducer<Text, IntWritable, Text, IntWritable>,四个泛型分别表示:Reduce输入Key的类型(单词,Text)、Reduce输入Value的类型(计数1的集合,Iterable)、Reduce输出Key的类型(单词,Text)、Reduce输出Value的类型(总次数,IntWritable)。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* WordCount的Reduce类
* 输入:<单词(Text), 计数1的集合(Iterable<IntWritable>)>
* 输出:<单词(Text), 总次数(IntWritable)>
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 定义输出的Value(总次数)
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1. 累加同一单词的计数
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
// 2. 设置总次数,输出<单词, 总次数>的键值对
result.set(sum);
context.write(key, result);
}
}
(3)Driver类实现
Driver类是MapReduce任务的入口,负责配置任务的相关参数(如输入输出路径、MapReduce类、数据格式等),并提交任务。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* WordCount的Driver类(任务入口)
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1. 加载配置信息
Configuration conf = new Configuration();
// 2. 创建Job实例,设置任务名称
Job job = Job.getInstance(conf, "wordcount");
// 3. 设置Driver类的路径(用于打包时找到主类)
job.setJarByClass(WordCountDriver.class);
// 4. 设置Map类和Reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 5. 设置Map输出的Key和Value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 6. 设置最终输出的Key和Value类型(与Reduce输出类型一致)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 7. 设置输入路径(HDFS上的文本文件或目录)
FileInputFormat.addInputPath(job, new Path(args[0]));
// 8. 设置输出路径(HDFS上的目录,必须不存在,否则任务会失败)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 9. 提交任务,等待任务完成,返回任务执行结果(成功/失败)
boolean result = job.waitForCompletion(true);
// 10. 根据任务执行结果退出程序
System.exit(result ? 0 : 1);
}
}
(4)任务提交与执行
任务编写完成后,需要将程序打包成JAR包,提交到Hadoop集群执行。步骤如下:
- 使用Maven或IDE将程序打包成JAR包(如wordcount.jar)。
- 在HDFS上创建输入目录,并上传文本文件:
hdfs dfs -mkdir -p /user/hadoop/wordcount/input
hdfs dfs -put test1.txt test2.txt /user/hadoop/wordcount/input - 提交MapReduce任务:
hadoop jar wordcount.jar WordCountDriver /user/hadoop/wordcount/input /user/hadoop/wordcount/output - 任务执行完成后,查看输出结果:hdfs dfs -cat /user/hadoop/wordcount/output/part-r-00000
3.3.2 进阶实践:自定义Partitioner与Combiner
在基础的WordCount案例中,MapReduce框架自动完成了Shuffle阶段的分区(默认使用HashPartitioner,根据Key的哈希值分配到不同的ReduceTask)和合并(默认无Combiner)。在实际开发中,我们可以通过自定义Partitioner和Combiner,优化任务的执行效率。
(1)自定义Partitioner
自定义Partitioner的作用是根据业务需求,将Map输出的中间键值对分配到指定的ReduceTask中。例如,我们希望将以字母"A"开头的单词分配到第一个ReduceTask,其他单词分配到第二个ReduceTask。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 自定义Partitioner:将以"A"开头的单词分配到分区0,其他分配到分区1
*/
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// 1. 获取单词
String word = key.toString();
// 2. 判断单词是否以"A"开头(忽略大小写)
if (word.startsWith("A") || word.startsWith("a")) {
return 0; // 分配到分区0
} else {
return 1 % numPartitions; // 分配到分区1(确保分区号不超过ReduceTask数量)
}
}
}
在Driver类中配置自定义Partitioner,并设置ReduceTask的数量:
// 设置自定义Partitioner
job.setPartitionerClass(CustomPartitioner.class);
// 设置ReduceTask的数量(需与分区数匹配,此处设置为2)
job.setNumReduceTasks(2);
(2)自定义Combiner
Combiner是Map端的局部聚合器,其逻辑与Reduce函数类似,可以在MapTask执行完成后,对本地的中间键值对进行聚合(如求和),减少Shuffle阶段传输的数据量,从而提高任务执行效率。需要注意的是,Combiner的输入输出类型必须与Map的输出类型一致。
在WordCount案例中,Combiner可以直接复用Reduce类(因为Reduce的输入输出类型与Map的输出类型一致):
// 在Driver类中设置Combiner
job.setCombinerClass(WordCountReducer.class);
【实践技巧】:Combiner仅适用于满足"交换律"和"结合律"的聚合操作(如求和、计数),不适用于求平均值等操作(因为局部平均值的聚合不等于整体平均值)。合理使用Combiner可以显著减少数据传输量,提升任务执行效率。
3.3.3 MapReduce编程技巧与性能优化
- 对象复用:在Map和Reduce方法中,避免重复创建对象(如Text、IntWritable),应将对象定义为类的成员变量,重复使用,减少GC(垃圾回收)的开销。
- 数据格式选择:MapReduce的输入输出数据格式会影响任务的执行效率。默认的TextInputFormat/TextOutputFormat适用于文本数据,对于二进制数据,建议使用SequenceFileInputFormat/SequenceFileOutputFormat,其采用序列化存储,数据压缩比高,读写效率高。
- 任务参数优化:
-
MapTask数量:默认根据输入数据的块数自动确定,一般无需修改;若输入数据为大量小文件,可通过CombineFileInputFormat合并小文件,减少MapTask数量。
-
ReduceTask数量:根据集群资源和任务规模合理设置,过多会导致资源竞争,过少会导致并行度不足;一般建议设置为集群节点数的1-2倍。
-
缓冲区大小:通过配置mapreduce.map.sort.spill.percent(Map端溢写阈值,默认80%)、mapreduce.reduce.shuffle.parallelcopies(Reduce端并行拉取数据的线程数,默认5)等参数,优化Shuffle阶段的性能。
- 数据压缩:开启数据压缩可以减少数据传输量和存储开销。可在Shuffle阶段开启压缩(设置mapreduce.map.output.compress=true),使用Snappy或LZO压缩算法;也可以对最终输出结果开启压缩(设置mapreduce.output.fileoutputformat.compress=true)。
四、项目实战:分布式数据处理项目全流程复盘
理论学习和基础编程实践完成后,通过项目实战可以将所学知识融会贯通,解决实际业务场景中的问题。下面以"电商用户行为日志分析"项目为例,复盘分布式数据处理项目的全流程,包括项目需求分析、技术方案设计、代码实现、任务部署与优化、问题解决等环节,分享项目实战中的经验与感悟。
4.1 项目需求分析
项目目标:分析电商平台的用户行为日志,提取关键指标,为平台的运营决策提供数据支持。具体需求如下:
- 统计每日的PV(页面浏览量)和UV(独立访客数)。
- 统计每日各商品类目的点击量、下单量、支付量。
- 统计每日各省份的用户访问量。
- 分析用户的行为路径(如首页→商品列表页→商品详情页→下单→支付)。
- 将分析结果存储到HDFS,供后续可视化展示使用。
输入数据:电商平台的用户行为日志,格式为JSON,每条日志包含用户ID、用户省份、访问时间、行为类型(浏览、点击、下单、支付)、商品ID、商品类目等信息。日志文件存储在HDFS的/user/hadoop/ecommerce/logs目录下,按日期分区(如2024-01-01、2024-01-02)。
4.2 技术方案设计
根据项目需求和输入数据特点,设计如下技术方案:
- 数据采集层:已完成,日志数据已存储在HDFS上。
- 数据预处理层:使用MapReduce对原始日志数据进行预处理,包括数据清洗(过滤无效日志,如缺失用户ID、行为类型的日志)、数据解析(将JSON格式的日志解析为结构化数据)、数据格式化(统一时间格式、字段名称等)。
- 数据计算层:基于预处理后的结构化数据,使用MapReduce实现各指标的计算:
- PV/UV统计:通过MapReduce统计每日的页面浏览量(所有浏览行为的次数)和独立访客数(去重后的用户ID数量)。
- 商品类目指标统计:按日期和商品类目分组,统计点击量、下单量、支付量。
- 省份用户访问量统计:按日期和省份分组,统计用户访问量(去重后的用户ID数量)。
- 用户行为路径分析:通过MapReduce按用户ID和访问时间排序,提取每个用户的行为序列,分析行为路径。
- 数据存储层:将计算后的各指标结果存储到HDFS的指定目录,按日期分区,数据格式为CSV(便于后续可视化工具读取)。
- 任务调度:使用Hadoop的定时任务调度工具(如Oozie),配置每日定时执行数据预处理和计算任务。
4.3 核心代码实现
下面重点展示数据预处理和PV/UV统计的核心代码实现,其他指标的计算思路类似。
4.3.1 数据预处理:日志清洗与解析
原始日志为JSON格式,需要解析为结构化数据,并过滤无效日志。使用阿里巴巴的fastjson库解析JSON数据。
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 数据预处理:日志清洗与解析
* 输入:<行号(LongWritable), 原始JSON日志(Text)>
* 输出:<用户ID_日期(Text), 结构化数据(Text)> (Key用于后续UV统计的去重)
*/
public class LogPreprocess {
// Map类:解析JSON日志,过滤无效数据
public static class LogPreprocessMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text outputKey = new Text();
private Text outputValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
try {
// 1. 解析JSON日志
String logStr = value.toString();
JSONObject jsonObject = JSONObject.parseObject(logStr);
// 2. 提取字段
String userId = jsonObject.getString("userId");
String province = jsonObject.getString("province");
String time = jsonObject.getString("time"); // 格式:2024-01-01 12:34:56
String behaviorType = jsonObject.getString("behaviorType"); // browse, click, order, pay
String productId = jsonObject.getString("productId");
String productCategory = jsonObject.getString("productCategory");
// 3. 数据清洗:过滤无效字段
if (userId == null || userId.isEmpty() || time == null || time.isEmpty() || behaviorType == null || behaviorType.isEmpty()) {
return; // 过滤无效日志
}
// 4. 统一时间格式,提取日期(yyyy-MM-dd)
String date = time.split(" ")[0];
// 5. 构造输出Key(用户ID_日期,用于后续UV统计的去重)
String keyStr = userId + "_" + date;
// 6. 构造输出Value(结构化数据,字段用逗号分隔)
String valueStr = String.join(",", date, province, behaviorType, productId, productCategory);
// 7. 输出键值对
outputKey.set(keyStr);
outputValue.set(valueStr);
context.write(outputKey, outputValue);
} catch (Exception e) {
// 捕获JSON解析异常,过滤无效日志
context.getCounter("LogPreprocess", "InvalidLogCount").increment(1); // 记录无效日志数量
return;
}
}
}
// Reducer类:此处无需聚合,直接输出数据(可根据需求添加聚合逻辑)
public static class LogPreprocessReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(key, value);
}
}
}
// Driver类:配置任务参数
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "logPreprocess");
job.setJarByClass(LogPreprocess.class);
job.setMapperClass(LogPreprocessMapper.class);
job.setReducerClass(LogPreprocessReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.3.2 PV/UV统计
PV(页面浏览量)是所有浏览行为的次数,UV(独立访客数)是每日去重后的用户ID数量。基于预处理后的结构化数据,实现PV/UV统计。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* PV/UV统计
* 输入:<用户ID_日期(Text), 结构化数据(Text)> (预处理后的输出)
* 输出:<日期(Text), PV:xxx,UV:
五、项目实战:分布式数据处理项目全流程复盘
5.1 任务部署与监控
项目代码实现后,部署环节的稳定性直接影响数据处理的时效性和准确性。结合完全分布式Hadoop集群环境,我们采用了“本地调试-集群预运行-正式部署”的三步走策略。首先在本地模式下验证代码逻辑的完整性,通过模拟少量日志数据测试各MapReduce任务的输出结果是否符合预期,重点排查数据解析错误、字段映射异常等问题;随后搭建3节点伪分布式集群,将预处理和指标计算任务依次提交,观察集群资源占用情况(CPU利用率、内存使用量)和任务执行时长,初步优化参数配置(如调整ReduceTask数量为4,匹配集群节点资源);最后在10节点完全分布式集群中正式部署,通过Hadoop的Web UI(ResourceManager地址:8088端口)实时监控任务进度,包括MapTask/ReduceTask的完成百分比、失败任务的重试情况、数据传输速率等关键指标。
为确保任务按预期执行,我们还集成了日志监控机制。通过定时读取Hadoop的任务日志($HADOOP_HOME/logs/userlogs目录),利用Shell脚本提取任务执行状态、异常信息和计数器数据(如无效日志数量、有效数据条数),并将关键指标推送至企业内部监控平台。当出现任务失败或执行超时情况时,系统会自动触发告警,运维人员可通过日志快速定位问题——例如曾遇到部分DataNode节点数据传输超时,通过日志发现是节点间网络带宽瓶颈,后续通过调整数据块副本放置策略(增加同机架副本比例)和优化集群网络配置,将任务执行效率提升了30%。
5.2 性能优化实战
项目初期,由于原始日志数据量日均达500GB,且包含大量小文件(单文件大小多在10-50MB),导致MapTask数量激增(约8000个),集群资源竞争激烈,单任务执行时长超过4小时,严重影响后续数据可视化的时效性。针对这一问题,我们从三个维度进行优化:
一是小文件合并优化。采用CombineFileInputFormat替代默认的TextInputFormat,将多个小文件打包成一个输入分片(InputSplit),通过配置mapreduce.input.fileinputformat.split.maxsize参数,设置分片大小为128MB(与HDFS块大小一致),使MapTask数量从8000个降至4000个,减少了任务调度和资源分配的开销。
二是数据倾斜处理。在商品类目指标统计任务中,发现部分热门商品类目的点击日志占比超过总数据量的20%,导致对应ReduceTask处理数据量过大,出现“长尾效应”(多数ReduceTask已完成,少数任务仍在运行)。我们通过自定义Partitioner优化数据分配,对热门类目采用“前缀哈希+随机后缀”的方式拆分Key,将原本集中在一个ReduceTask的数据分散到多个任务中;同时在Map端启用Combiner,对同一商品类目的行为数据进行局部聚合,减少Shuffle阶段传输的数据量,最终将该任务的执行时长从1.5小时缩短至40分钟。
三是集群资源调度优化。在YARN中配置Fair Scheduler(公平调度器),为项目任务创建独立队列并分配40%的集群资源,避免与其他业务任务抢占资源;调整容器资源配置,将MapTask的容器内存从默认1GB提升至2GB,ReduceTask容器内存提升至4GB,同时设置mapreduce.map.cpu.vcores=1、mapreduce.reduce.cpu.vcores=2,匹配任务的计算资源需求。优化后,整个项目的端到端处理时长从4.5小时压缩至1.8小时,满足了每日凌晨完成数据处理、上午提供可视化报表的业务要求。
5.3 问题解决与经验沉淀
项目实战中遇到的核心问题集中在数据处理准确性、集群稳定性和性能优化三个方面。除了上述提到的小文件过多、数据倾斜问题外,还曾出现过以下典型问题及解决方案:
-
数据一致性问题:部分日期的UV统计结果与业务系统记录存在偏差,经排查发现是日志中存在用户ID重复(同一用户在不同设备登录使用相同ID)和时间格式不统一(部分日志时间为UTC时区,未转换为北京时间)。解决方案:在数据预处理阶段增加用户ID去重逻辑(结合设备号辅助判断),通过SimpleDateFormat工具类统一将时间转换为北京时间,并添加时间合法性校验(过滤未来时间或格式错误的日志)。
-
集群节点故障:任务执行过程中,某DataNode节点突然宕机,导致该节点上的DataBlock副本丢失。由于HDFS默认副本数为3,且副本分布在不同机架,NameNode自动检测到副本缺失后,触发数据块复制机制,从其他健康节点复制数据块补充至新的DataNode节点,任务未受影响。这一经历也让我们深刻认识到HDFS副本机制和容错性设计的重要性,后续将副本数调整为4,进一步提升数据可靠性。
-
依赖包冲突:在使用fastjson解析JSON日志时,由于Hadoop集群自带的JSON解析包与项目依赖的fastjson版本冲突,导致任务提交后出现ClassNotFoundException。解决方案:通过Maven的shade插件将fastjson及其依赖包打包进项目JAR包,并修改包名避免冲突,同时在Driver类中明确指定依赖包的加载路径,确保任务在集群中正常运行。
这些问题的解决过程,不仅加深了对Hadoop框架底层原理的理解,更积累了分布式数据处理项目的工程实践经验:在项目设计阶段,需充分考虑数据特点(如文件大小、格式、量级)和业务场景(如实时性要求、数据准确性要求);在开发阶段,应注重代码的健壮性(如完善异常处理、添加数据校验);在部署运维阶段,需建立完善的监控和告警机制,快速响应并解决问题。
5.4项目延伸与拓展
电商用户行为日志分析项目的完成,为后续延伸应用奠定了基础。基于已有的数据处理框架,我们进一步拓展了两个核心方向:一是实时数据处理,引入Flink框架对接Kafka消息队列,实现用户行为日志的实时采集、处理和分析,将数据延迟从T+1降至分钟级,支持实时运营监控(如实时PV/UV统计、热门商品实时推荐);二是数据挖掘应用,将处理后的结构化数据导入HBase存储,结合Spark MLlib构建用户画像模型,通过分析用户的浏览偏好、购买行为等特征,实现精准营销和个性化推荐。
此外,项目成果还为企业数据中台建设提供了支撑。我们将数据预处理、指标计算的通用逻辑封装为可复用的工具类(如日志解析工具、指标统计模板),后续新增类似的日志分析需求时,可基于现有框架快速迭代开发;同时将计算结果同步至Hive数据仓库,构建统一的数据分析模型,供数据分析师、运营人员通过SQL查询获取数据,实现数据价值的最大化。
通过该项目的实战,不仅全面巩固了Hadoop的核心技术(HDFS、MapReduce、YARN),更深刻理解了分布式系统“分而治之”的设计思想和软件工程的“迭代优化”理念。从需求分析到技术方案设计,从代码实现到部署运维,每个环节都需要兼顾理论合理性与工程可行性,这也为后续学习更复杂的大数据框架(如Spark、Flink)和解决更复杂的业务问题提供了宝贵的实践经验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。