终极指南:如何使用Spark-TTS构建企业级语音合成系统
终极指南:如何使用Spark-TTS构建企业级语音合成系统
【免费下载链接】Spark-TTS Spark-TTS Inference Code
项目地址: https://gitcode.com/gh_mirrors/sp/Spark-TTS
Spark-TTS是一款基于大型语言模型(LLM)的高效文本转语音系统,能够生成高度自然、准确的语音。它采用创新的单流解耦语音令牌技术,直接从LLM预测的代码中重建音频,无需额外的生成模型,为企业级应用提供了强大而灵活的语音合成解决方案。

核心优势:为什么选择Spark-TTS?
Spark-TTS凭借其独特的技术架构和丰富功能,在众多TTS解决方案中脱颖而出:
✅ 极致简洁与高效
完全基于Qwen2.5构建,摒弃了传统TTS系统中复杂的声学特征生成模型,直接从LLM预测的代码重建音频。这种创新架构不仅简化了系统设计,还显著提升了运行效率,使实时语音合成为可能。
✅ 高质量语音克隆
支持零样本语音克隆技术,无需针对特定声音进行专门训练即可复制说话人的声音特征。这一特性特别适用于跨语言和代码切换场景,实现无缝的语言和声音转换。
✅ 双语支持与多语言合成
原生支持中文和英文,能够在零样本语音克隆场景下实现跨语言和代码切换,确保多语言合成的自然度和准确性。
✅ 可控语音生成
提供丰富的语音控制参数,允许通过调整性别、音调、语速等参数创建虚拟说话人,满足多样化的语音合成需求。
技术原理:Spark-TTS的工作机制
Spark-TTS采用创新的技术架构,实现了高效、高质量的语音合成。以下是其核心技术流程:
语音克隆推理流程

语音克隆流程主要包括:
- 参考音频处理:通过Global Tokenizer将参考音频转换为Global Tokens
- 文本处理:使用BPE Tokenizer将文本转换为Textual Tokens
- LLM处理:将Global Tokens和Textual Tokens输入LLM,生成Semantic Tokens
- 音频生成:BiCodec解码器将Semantic Tokens转换为最终音频
可控生成推理流程

可控生成流程特点:
- 属性提示处理:Attribute Tokenizer将属性提示转换为Attribute Tokens
- 文本处理:BPE Tokenizer处理输入文本
- 细粒度控制:LLM结合Fine-grained Attribute Tokens生成可控的Semantic Tokens
- 音频解码:BiCodec解码器生成符合属性控制的音频
快速上手:Spark-TTS安装与基础使用
环境准备
Spark-TTS需要以下依赖环境:
- Python 3.12+
- PyTorch 2.5+
- 其他依赖:einops、numpy、omegaconf、safetensors、soundfile、transformers、gradio等
一键安装步骤
- 克隆仓库
git clone https://gitcode.com/gh_mirrors/sp/Spark-TTS
cd Spark-TTS
- 创建并激活虚拟环境
conda create -n sparktts -y python=3.12
conda activate sparktts
pip install -r requirements.txt
- 模型下载
mkdir -p pretrained_models
git lfs install
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
基础使用示例
命令行推理
python -m cli.inference \
--text "欢迎使用Spark-TTS语音合成系统" \
--device 0 \
--save_dir "output_audio" \
--model_dir pretrained_models/Spark-TTS-0.5B \
--prompt_text "这是参考音频的文本内容" \
--prompt_speech_path "example/prompt_audio.wav"
批处理示例
cd example
bash infer.sh
图形界面:轻松实现语音合成
Spark-TTS提供了直观的Web UI界面,无需编写代码即可实现语音克隆和语音创建。
启动Web UI
python webui.py --device 0
语音克隆功能
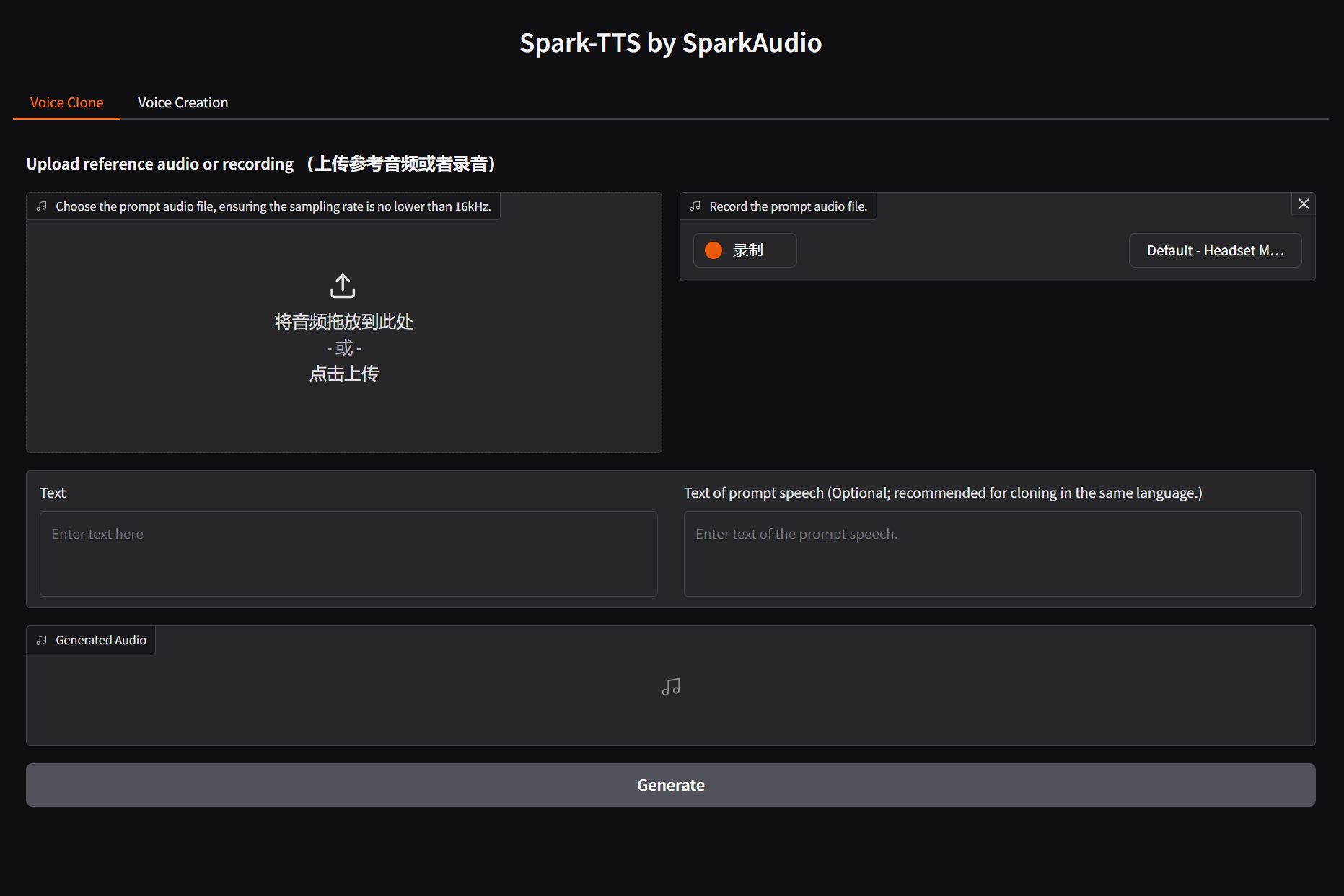
语音克隆功能允许您:
- 上传参考音频或直接录制音频
- 输入要合成的文本
- 生成与参考音频相似的语音
语音创建功能
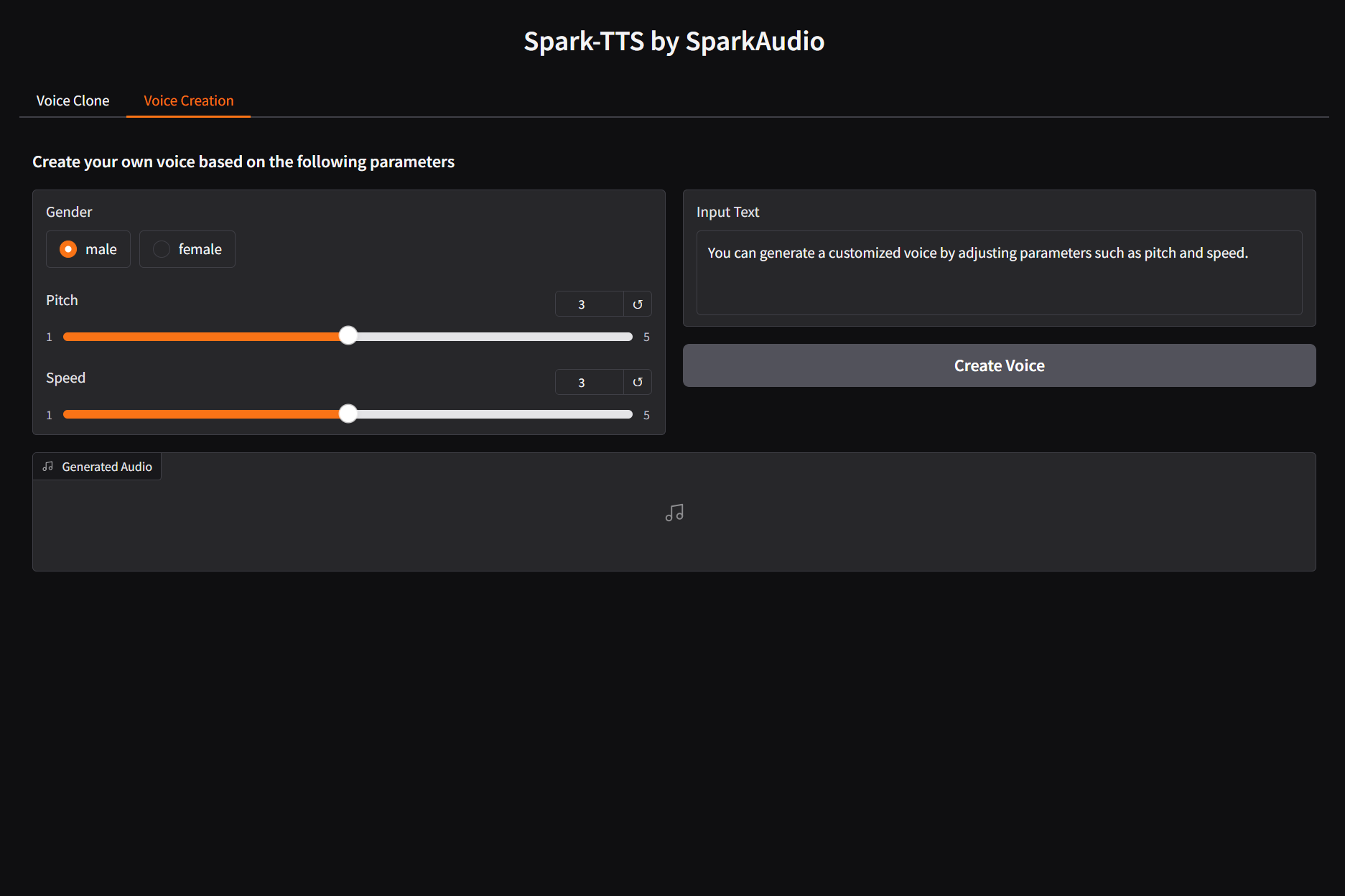
语音创建功能提供:
- 性别选择(男/女)
- 音调调节(1-5)
- 语速调节(1-5)
- 文本输入与语音生成
企业级部署:Nvidia Triton推理服务
Spark-TTS支持通过Nvidia Triton和TensorRT-LLM进行高效部署,满足企业级应用需求。
部署优势
- 高并发处理能力
- 低延迟响应
- 优化的GPU资源利用
性能基准
在单L20 GPU上使用26个不同的prompt_audio/target_text对(总计169秒音频)的基准测试结果:
| 模型 | 并发数 | 平均延迟 | RTF |
|---|---|---|---|
| Spark-TTS-0.5B | 1 | 876.24 ms | 0.1362 |
| Spark-TTS-0.5B | 2 | 920.97 ms | 0.0737 |
| Spark-TTS-0.5B | 4 | 1611.51 ms | 0.0704 |
详细部署指南请参见runtime/triton_trtllm/README.md
实际应用场景与案例
Spark-TTS的强大功能使其适用于多种应用场景:
内容创作
- 有声书制作
- 播客生成
- 视频配音
智能交互
- 虚拟助手
- 智能客服
- 语音导航
无障碍服务
- 视觉障碍辅助
- 文本转语音阅读
教育领域
- 语言学习
- 有声教材
- 个性化教学
总结与展望
Spark-TTS作为一款基于LLM的高效文本转语音模型,通过创新的单流解耦语音令牌技术,为企业级语音合成应用提供了强大支持。其简洁高效的架构、高质量的语音克隆能力、双语支持和丰富的可控参数,使其成为语音合成领域的理想选择。
随着项目的不断发展,未来还将发布训练代码和训练数据集VoxBox,进一步拓展Spark-TTS的应用潜力。无论是研究用途还是商业应用,Spark-TTS都能为您提供高质量、灵活可控的语音合成解决方案。
使用免责声明
本项目提供的零样本语音克隆TTS模型旨在用于学术研究、教育目的和合法应用,如个性化语音合成、辅助技术和语言研究。
请注意:
- 请勿将此模型用于未经授权的语音克隆、 impersonation、欺诈、诈骗、深度伪造或任何非法活动。
- 使用本模型时,请遵守当地法律法规并坚持道德标准。
- 开发人员对本模型的任何误用不承担责任。
我们倡导负责任地开发和使用AI,并鼓励社区在AI研究和应用中坚持安全和道德原则。如果您对伦理或滥用有任何疑虑,请与我们联系。
【免费下载链接】Spark-TTS Spark-TTS Inference Code
项目地址: https://gitcode.com/gh_mirrors/sp/Spark-TTS
© 版权声明
文章版权归作者所有,未经允许请勿转载。