
【西瓜带你学Kafka | 第五期】Kafka 副本同步机制与集群健康管理:ISR、故障选举与关键配置(文含图解)
文章目录
-
- 前言
- 一、Kafka 中 AR、ISR、OSR 三者的概念
-
- AR(Assigned Replicas)
- ISR(In-Sync Replicas)
- OSR(Out-of-Sync Replicas)
- 三者的关系
- 二、分区副本什么情况下会从 ISR 中剔出
-
- 剔出条件
- ISR 与 ACK 的关系
- 三、分区副本中的 Leader 如果宕机但 ISR 却为空该如何处理
-
- 策略一:允许 OSR 成为 Leader(true)
- 策略二:等待旧 Leader 恢复(false)
- 怎么选?
- 四、如何判断一个 Broker 是否还有效
-
- 条件一:维持与 ZooKeeper 的连接
- 条件二:Follower 能及时同步 Leader
- 两个条件的关系
- 五、Kafka 可接收的消息最大默认多少字节,如何修改
-
- 默认值
- 如何修改
- 修改时的注意事项
- 需要联动调整的参数
- 总结
前言
一个 Follower 同步太慢怎么办?Leader 挂了但所有 Follower 都不够格怎么选?怎么判断一个 Broker 是不是已经"死了"?这些问题的答案,藏在 ISR 机制、故障选举策略和集群健康检测这三个环节里,本期西瓜将带你学习相关的知识。
一、Kafka 中 AR、ISR、OSR 三者的概念
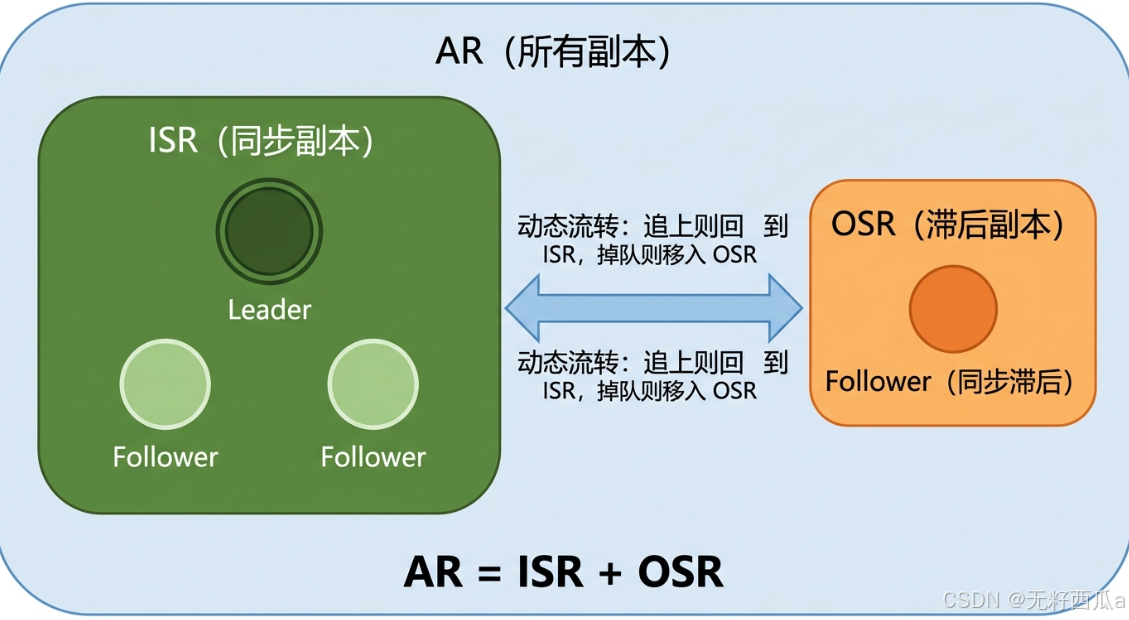
要理解 Kafka 的副本同步机制,首先要搞清楚三个副本集合的定义。它们描述的是同一个 Partition 下所有副本的"健康分级"。
AR(Assigned Replicas)
分区中的所有副本称为 AR。它是一个全集,包含了这个 Partition 被分配到的所有 Broker 上的副本,无论它们当前的同步状态如何。
ISR(In-Sync Replicas)
所有与主副本保持一定程度同步的副本(包括主副本自身)称为 ISR。这是一个动态列表,由 Leader 实时维护。只有在 ISR 中的副本,才有资格在 Leader 宕机时被选举为新的 Leader。
OSR(Out-of-Sync Replicas)
与主副本滞后过多的副本组成 OSR。这些副本因为同步太慢或长时间未发起复制请求,被 Leader 从 ISR 中移除。
三者的关系
一个简单的等式:
AR = ISR + OSR
在理想情况下,所有副本都在 ISR 中,OSR 为空。但在实际运行中,网络波动、Broker 负载过高、磁盘 I/O 瓶颈等都可能导致某些 Follower 掉队,从 ISR 滑入 OSR。
二、分区副本什么情况下会从 ISR 中剔出
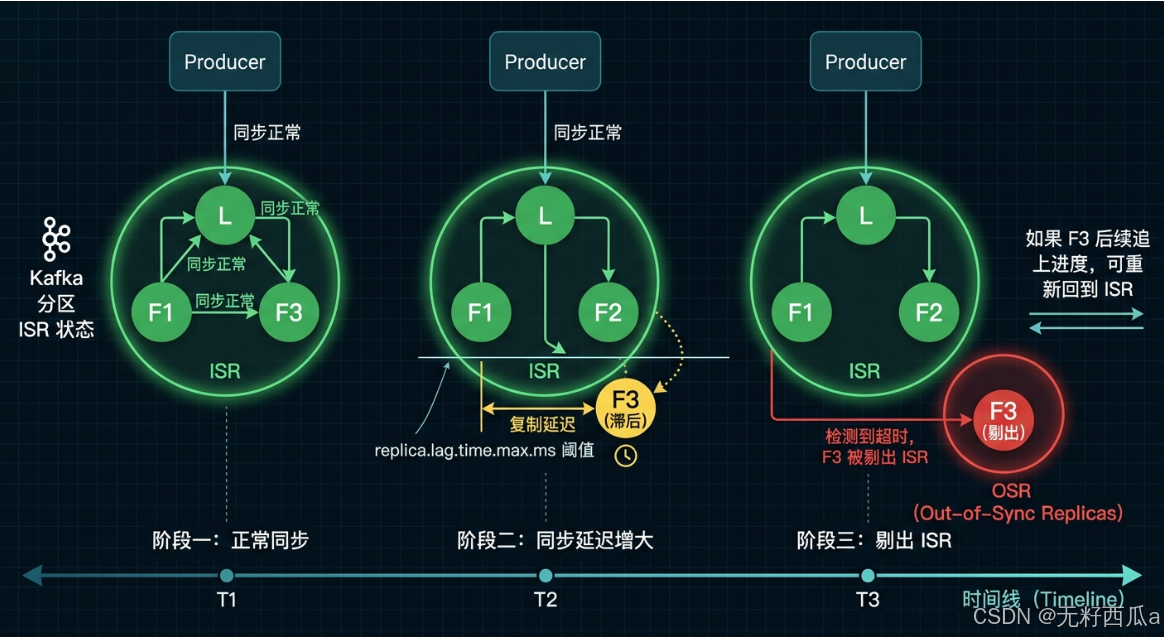
ISR 不是一成不变的,它由 Leader 动态维护。所谓动态维护,就是 Leader 会持续监控每个 Follower 的同步状态,一旦不达标就踢出去。
剔出条件
一个 Follower 会在以下两种情况下被从 ISR 中移除:
1. 落后太多
如果一个 Follower 比 Leader 落后的消息条数超过阈值(由 replica.lag.max.messages 控制,旧版本参数),Leader 会将其移出 ISR。
2. 超时未发起复制请求
如果一个 Follower 超过一定时间未向 Leader 发起数据复制请求(由 replica.lag.time.max.ms 控制,默认 30 秒),Leader 同样会将其移出 ISR。
注意:在较新版本的 Kafka 中(0.10.x 之后),
replica.lag.max.messages参数已被移除,只保留了replica.lag.time.max.ms作为唯一的判断标准。原因是基于消息条数的判断在突发流量下容易误判——一次大批量写入就可能让所有 Follower 瞬间"落后太多",导致 ISR 频繁抖动。
ISR 与 ACK 的关系
当 ISR 中 所有 Replica 都向 Leader 发送 ACK(Acknowledgement 确认) 时,Leader 才 commit 这条消息。这意味着:
- ISR 越大,数据越安全(更多副本确认了这条消息)
- ISR 越大,写入延迟越高(要等更多副本确认)
这就是 Kafka 在数据安全性和写入性能之间的核心权衡点。
| 场景 | ISR 状态 | 影响 |
|---|---|---|
| 所有 Follower 同步正常 | ISR = AR,OSR 为空 | 数据最安全,延迟略高 |
| 部分 Follower 掉队 | ISR 缩小,OSR 非空 | 安全性降低,写入变快 |
| 只剩 Leader 自己 | ISR 只有 Leader | 相当于无副本,风险最高 |
三、分区副本中的 Leader 如果宕机但 ISR 却为空该如何处理
这是一个极端但必须面对的场景:Leader 挂了,而 ISR 中没有任何可用的 Follower(可能都掉队了,或者都宕机了)。这时候怎么办?
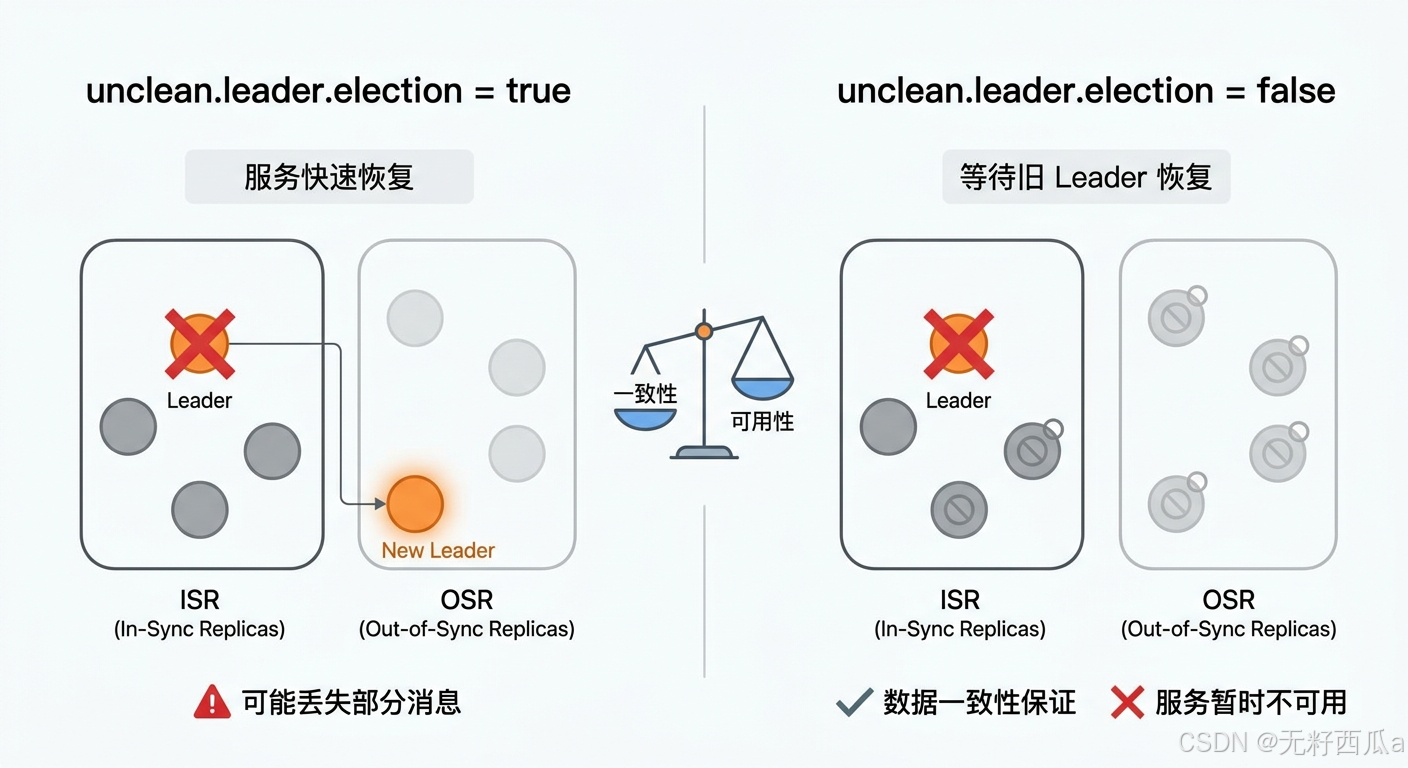
Kafka 通过配置 unclean.leader.election.enable 提供了两种策略,本质上是在数据一致性和服务可用性之间做选择。
策略一:允许 OSR 成为 Leader(true)
unclean.leader.election.enable=true
- 允许 OSR 中的副本被选举为新的 Leader
- 好处:服务可以快速恢复,不会长时间不可用
- 代价:OSR 的消息较为滞后,可能会出现消息不一致的问题——那些已经被旧 Leader commit 但 OSR 还没同步到的消息,会永久丢失
策略二:等待旧 Leader 恢复(false)
unclean.leader.election.enable=false
- 不允许 OSR 成为 Leader,会一直等待旧 Leader 恢复正常
- 好处:数据一致性得到保证,不会丢消息
- 代价:降低了可用性——如果旧 Leader 长时间无法恢复,这个 Partition 就一直不可用
怎么选?
| 配置 | 倾向 | 适用场景 |
|---|---|---|
| true | 可用性优先 | 日志采集、监控指标等允许少量丢失的场景 |
| false | 一致性优先 | 金融交易、订单系统等不允许丢消息的场景 |
这其实就是分布式系统中经典的 CAP 权衡 在 Kafka 中的具体体现。
四、如何判断一个 Broker 是否还有效
Kafka 集群需要实时感知每个 Broker 的健康状态,判断标准有两个,必须同时满足:
条件一:维持与 ZooKeeper 的连接
Broker 必须可以维护和 ZooKeeper 的连接。ZooKeeper 通过心跳机制检查每个节点的连接状态。
- 每个 Broker 启动时会在 ZooKeeper 上创建一个临时节点(Ephemeral Node)
- ZooKeeper 定期检测心跳,如果超时未收到心跳,临时节点会被自动删除
- 临时节点消失意味着该 Broker 被判定为"失联"
条件二:Follower 能及时同步 Leader
如果 Broker 是一个 Follower,它必须能及时同步 Leader 的写操作,延时不能太久。
- 这就是前面讲的
replica.lag.time.max.ms参数的作用 - 如果同步延迟超过阈值,即使 Broker 进程还活着、和 ZooKeeper 的连接也正常,它也会被认为"不健康",从 ISR 中移除
两个条件的关系
| ZooKeeper 连接 | 同步及时 | 判定结果 |
|---|---|---|
| ✓ | ✓ | 有效 Broker,在 ISR 中 |
| ✓ | × | 进程存活但同步滞后,从 ISR 移入 OSR |
| × | — | Broker 失联,触发故障转移 |
五、Kafka 可接收的消息最大默认多少字节,如何修改
默认值
Kafka 可以接收的最大消息默认为 1000000 字节(约 1MB)。
如何修改
可在 Broker 中修改配置参数 message.max.bytes 的值:
# Broker 端配置:单条消息最大字节数
message.max.bytes=2097152 # 调整为 2MB
修改时的注意事项
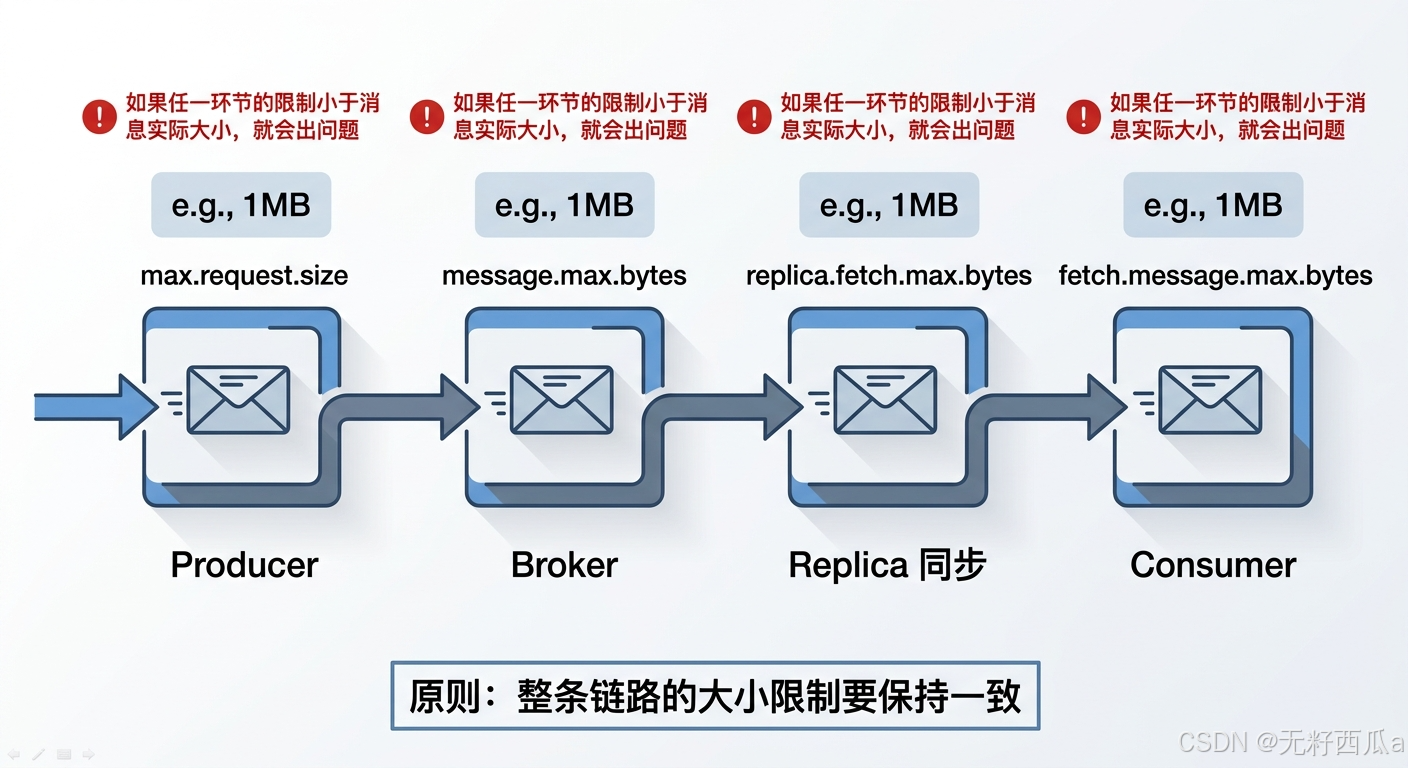
修改这个值时,必须同时检查其他相关参数,否则可能引发系统异常。
最关键的一条规则:message.max.bytes 的值要小于消费端的 fetch.message.max.bytes 参数值。
原因很直观:如果 Broker 允许存储一条 2MB 的消息,但消费端最大只能读取 1MB 的消息,那这条 2MB 的消息就永远无法被消费,Broker 会因为消费端无法使用这个消息而挂起。
需要联动调整的参数
| 参数 | 所在位置 | 默认值 | 说明 |
|---|---|---|---|
message.max.bytes |
Broker | 1MB | Broker 接收的单条消息最大字节数 |
fetch.message.max.bytes |
Consumer | 1MB | 消费者能读取的最大消息字节数 |
replica.fetch.max.bytes |
Broker | 1MB | 副本同步时能拉取的最大字节数 |
max.request.size |
Producer | 1MB | 生产者发送请求的最大字节数 |
调整时的原则:整条链路上的大小限制要保持一致,从 Producer 发送 → Broker 接收 → Replica 同步 → Consumer 消费,每个环节的上限都要能容纳你期望的最大消息。
总结
- AR、ISR、OSR:三个集合描述了副本的健康分级,AR = ISR + OSR,ISR 由 Leader 动态维护
-
ISR 剔出机制:Follower 同步超时(
replica.lag.time.max.ms)会被移出 ISR,ISR 中所有副本 ACK 后 Leader 才 commit -
ISR 为空时的选举:
unclean.leader.election.enable决定了在一致性和可用性之间的取舍,这是 CAP 权衡的具体体现 - Broker 有效性判断:ZooKeeper 心跳连接 + Follower 同步及时性,两个条件缺一不可
- 消息大小限制:默认约 1MB,修改时必须联动调整 Producer、Broker、Replica、Consumer 整条链路的参数
© 版权声明
文章版权归作者所有,未经允许请勿转载。

