
Ranger-HDFS与Hive配合改造字段级鉴权能力
Apache云原生版本下Hive自身截止3.x是没有任何完整鉴权能力的,业内常说的Hive表级别鉴权,本质上是表Base路径开放了HDFS的权限,且只有Hive自己的使用场景下,受限于HDFS鉴权会对路径自身、父路径、祖先路径均需要有权限才能正常访问,从而造成诸多不便。因此市场上,Ranger提供了Ranger-HDFS插件解决了从 0 到 1 的HDFS路径权限解决方案,通过相对完善的内部逻辑在解决鉴权的同时,也省略了很多鉴权成本。官网上的确存在Hive的授权语句文档,但没有实际使用价值,因为从实际使用上来讲它是残缺的,也就导致任然选择采用未经过改造的Apche原生版本hdfs+hive的公司,他们的对标用户,通常都具备着以下几个特点
1、对多租户之间的权限管控能力需求不大,甚至没有
2、用户不具备大数据行业技术的深入使用能力,说白了就是有漏洞用户也发现不了,大炮打蚊子,解决一些行业基础的事情,纯骗钱
3、提供服务的时候,主观上不给用户开放较为下沉的技术使用环境,比如直接操作hdfs,甚至是不给客户端
至于开头提到的Hive自带鉴权功能,抛开它的残缺不谈,即使强行使用,由于hdfs其本身的鉴权并不是专属给表,或者结构化数据存在的,而是为了文件存储系统存在。一个视频、一段音乐、一张图片都可以是一个文件,所以hive自带鉴权本质上只到了元数据层级,能力非常有限,且为了hive的自带权限管控能够勉强发挥一些实际作用,还要放开hdfs上表路径权限,后果就是必须对直接操作hdfs侧的需求一刀切,不然使用者绕过hive,鉴权能力就瞎了,可见它不完全满足商用化
hdfs自身对文件的权限把控来讲,删除与生成一个新文件看的是操作用户是否有目标路径父路径的写和执行权限,读取文件看的是操作用户是否有目标文件自身的读权限以及父路径的执行权限,续写一个文件看的也是操作用户是否有目标文件自身写权限以及父路径的执行权限。官方文档-》https://hadoop.apache.ac.cn/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html#Overview
特别说明,hdfs上对同一个文件是可以续写的,只是基本不这样做,而且非本地命令行执行续写需要集群配置支持,由于很容易发生与元数据不一致的问题,所以基本不续写,多数情况直接选择覆盖写。而hdfs的执行权限是访问其下子路径的基本权限,hdfs本身没有执行某个文件的概念,因此当你做任何操作的时候保险起见最好拥有父路径的执行权限
这样的权限能力设计,对于文件系统来讲已经足够,但是对于其他服务就不见得了,尤其是hive这种很多用户已操作表为核心的服务,像上面说的那样给hive数据路径设置一个宽松权限,当使用者越过hive,那一场事故在所难免。spark、kyuubi等等这样的引擎也都是绕不开的,这样来看hdfs本身的鉴权能力就显得不符合生产需要。对此有的人会说,可以用市面上的ranger-hive插件,但其实它也只做到了元数据层面,而且还是只管控了Hiveserver2服务,无法影响到hdfs路径的多用户灵活控制,用hive-cli客户端就能越过它的权限管控,所以它的使用意义不大,没办法完整的支撑需要鉴权多用户场景
至于本篇后面要用到的ranger-hdfs插件,当它存在于你的集群上时,hdfs自己的acl是不优先生效的,只有ranger-hdfs无任何权限策略命中时,默认会回退到hdfs鉴权,而ranger-hdfs鉴权只是具备了满足hive这种多用户场景的潜力,如何调用和适配,还是需要企业自己改造,怎么都绕不开的,毕竟ranger-hdfs也只是鉴权了路径整体的读写,而没到字段,这也是本篇要给大家分享的改造。注意!!本篇只围绕最小改造成本,完成字段鉴权的核心能力,至于更多的扩展,就需要大家自己去完成了
hive自带的权限管控(了解就行没有实际使用意义)
使用hive自带的权限管控,前提需要hive在hdfs上的存储路径权限全部为755,包括其下的所有表路径,否则鉴权功能通过之后,hive会在读取阶段报错
其次是在hive-site.xml文件中添加如下配置
<!-- 开启鉴权功能,注意!自带的权限能力,在后面使用中当你关闭后再开启,已存在的权限会随着消失 -->
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<!-- 自带鉴权功能的核心类,SQL标准赋权,hive自带的还有其他的!但是矮子里面找高个,也就这个能用一下了 -->
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<!-- 表owner的默认权限 但其实这个配置没有任何作用 -->
<property>
<name>hive.security.authorization.createtable.owner.grants</name>
<value>ALL</value>
</property>
<!-- 权限管理员是谁 其实这个参数也是无效的,后面会说到,可以先不设置,反正这几个参数改造的时候都不需要了-->
<property>
<name>hive.users.in.admin.role</name>
<value>hive</value>
</property>
随后就可以使用hive默认的鉴权功能了,给其他用户权限的语句,在hive中,有如下语法
--将某个库或表的权限赋予一个用户
GRANT ALL ON DATABASE/table 库名/表明 TO USER 用户名;
--多个用户可以使用一个统一的角色来完成统一授权
--创建一个角色
CREATE ROLE 角色名称;
--将库或者表的权限赋予角色
GRANT SELECT ON DATABASE/table 库名/表明 TO ROLE 角色名称;
--绑定角色和用户
GRANT ROLE 角色名 TO USER 用户名;
-- 移除角色的某个权限
REVOKE ALL ON DATABASE/table 库名/表明 FROM ROLE 角色名称;
-- 移除用户的某个权限
REVOKE ALL ON DATABASE/table 库名/表明 FROM USER 用户名;
--解除角色和用户的绑定
REVOKE ROLE 角色名 FROM USER 用户名;
按照比较官方的说法,注意用词!!“比较官方”,权限标识有如下几类,首先是对数据库的
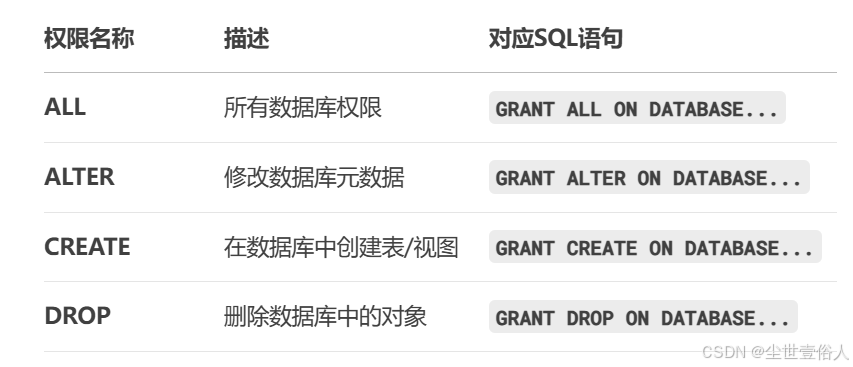
随后是对表的
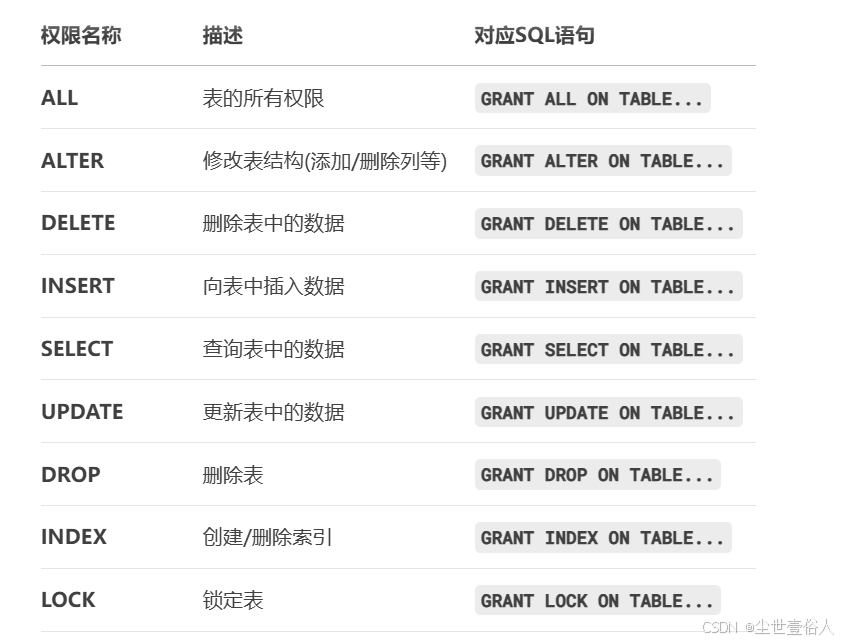
下面开始就是不官方的内容了。
在网上其他文献会看到,标准sql授权可以到字段,比如SELECT权限可以执行语句GRANT SELECT(字段1,字段2) ON DATABASE/table 库名/表明 TO ROLE 角色名称;,但是截至到我遇到最高商用的hive3.1.3版本实际都不支持,运行会提示你Privilege with columns are not currently supported with sql standard authorization:Privilege,因此网上其他文献说的到列的字段名,应该是和我现在要和大家分享的一样自己改造的,但写文献的人半桶水分不清以为是默认就支持的。
至于hive中很少用的视图,它和表查询权限是同步的,同时上面这些权限列表在使用中需要格外留意使用的hive版本是否支持,像索引和锁定,在16年的2.x左右版本还是在开发中的状态,甚至有很多权限场景都不会用到,比如说UPDATE,除了表owner还没有见过给第二个的场景,同时执行相关的权限语句时,hive也会阻止UPDATE被改变,也就是说有这个权限标识,但是不能改。至于INSERT,这个权限改动之后hive的鉴权能过,但需要看文件系统给不给过。
其次是DELETE,在很早之前hive就有delete语法,但使用上一直有很大的问题,比如你可以在网上看到如下的相关信息,但是上手做一遍会发现都跑不通
delete的前提,表必须是事务性表(Transactional Table)、且表必须存储为ORC文件格式
CREATE TABLE acid_table (
id int,
name string
)
STORED AS ORC
TBLPROPERTIES ('transactional'='true');
需要启用Hive的ACID支持
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
Hive自带鉴权有角色这个概念,需要配置hive.users.in.admin.role相关,当你去配置,就会发现一个致命的能力残缺问题,默认情况下hive内部有一个内建管理员角色ADMIN,所有对更改角色相关的操作,都需要操作用户属于该内建管理员角色,也就是说当你需要用一个名为root的用户做更改角色相关的操作时,道理上要做如下前置操作
--root属于管理员角色,且先切换到管理员角色
SET ROLE ADMIN;
--确定当前角色,预期会正常会输出admin
SHOW CURRENT ROLES;
--给某个用户admin权限,或者其他角色相关的操作
GRANT ROLE ADMIN TO USER root;
但是当你去操作的时候,会发现一个问题,不临时切换到admin角色就不能操作角色的更改,但是默认的执行管理员配置并没有生效,导致所有用户都能执行切换admin,这就是一个一条筋变两头堵的不健全能力,开源社区看来有些摆烂的意思。所以到此!基于自带hive授权的介绍就结束了,一个不完整的能力本身就没有使用价值,更谈何细谈其他的呢
下面开始本篇的正经上手改代码的内容,这里只介绍改造什么,至于编译和如何把改造的内容打进结果包这些,如果你不会那么本篇就当了解就行。首先是对Hive下刀
Hive权限的二次改造
当你想要实现hive的完整鉴权能力,有三个地方必须要自定义实现
<name>hive.security.authorization.manager</name>
<value>所有语句执行时的监测控制器提供类,是一个org.apache.hadoop.hive.ql.security.authorization.plugin.HiveAuthorizerFactory的实现类</value>
<final>true</final>
<name>hive.metastore.pre.event.listeners</name>
<value>元数据被更改之前的事件监听器,是一个org.apache.hadoop.hive.metastore.MetaStorePreEventListener的子类</value>
<final>true</final>
<name>hive.metastore.event.listeners</name>
<value>元数据发生改变之后的监听器,一般是一个 org.apache.hadoop.hive.metastore.MetaStoreEventListener的子类</value>
<final>true</final>
这部分的源码我写了一套日常权限能力就满足的插件,放在了git上有需要的拉取,特殊需求自己改造一下就行https://gitee.com/wangyang159/hive-auth
随后是一个可选的HiveServer2用户密码认证,代码也在上面分享的git仓库里
<!-- 启动自定义的hiveserver2用户密码验证插件 -->
<property>
<name>hive.server2.authentication</name>
<value>CUSTOM</value>
</property>
<!-- 自定义的hiveserver2用户密码验证插件类路径 -->
<property>
<name>hive.server2.custom.authentication.class</name>
<value>com.wy.hs2.MyHiveServer2JDBCUserPass</value>
</property>
上面这四个是鉴权能力需要自己开发的内容,但还不够,Apache-Hive版本源码中有一个阻碍改造的功能点要改掉,当一个语句到达Hive服务端,Hive会使用org.apache.hadoop.hive.ql.parse.SemanticAnalyzer类构建执行计划,涉及到抽象语法树解析、抽象语法树转逻辑执行数、元数据获取、当查询的对象不是一个视图时会物化元数据等等的内容,这里说的物化的意思就是当前sql任务需要的一切实际数据,比如解析出需要读取哪些hdfs路径为任务的最高需要路径,例如你读取表的一个分区,hive拿到的其实是表Base路径的整体读取权限,这就只需要鉴权一次就能访问所有表数据,可是Hive获取路径权限在HDFS存储下,就有点妖孽,它并没有直接调用HDFS鉴权拿到允许访问的令牌,而是调用了HDFS加密数据类,去判断这个路径是否在hdfs的加密区里,此时如果你没有该路径的权限就会报错,源码如下
/**
* Checks if a given path is encrypted (valid only for HDFS files)
* @param path The path to check for encryption
* @return True if the path is encrypted; False if it is not encrypted
* @throws HiveException If an error occurs while checking for encryption
*/
private boolean isPathEncrypted(Path path) throws HiveException {
try {
HadoopShims.HdfsEncryptionShim hdfsEncryptionShim = SessionState.get().getHdfsEncryptionShim(path.getFileSystem(conf));
if (hdfsEncryptionShim != null) {
if (hdfsEncryptionShim.isPathEncrypted(path)) {
return true;
}
}
} catch (Exception e) {
throw new HiveException("Unable to determine if " + path + " is encrypted: " + e, e);
}
return false;
}
这个地方的矛盾点在于,上面的自定义鉴权类生效在SemanticAnalyzer之后,如果你要在该方法调用之前改造,首先你拿不到完整的鉴权依据,其次过渡侵略Hive源码不符合最小改造成本的核心,最重要的是这里会影响最终的运行实际效果。比如HS2时,虽然可以让鉴权组件鉴权,文件系统直接放行,反之直接访问元数据的情况,可以让鉴权组件不鉴权,文件系统鉴权,可总体上多了一次对namenode的访问,后台涉及的鉴权库与其他相关服务要多出三分之一的服务成本,而且即便这样设计在通过元数据访问的方式下,权限不足的报错会优先于鉴权组件触发,导致实际效果不在预期内,所以这里最小成本的改造方式,就是将isPathEncrypted方法中原有的逻辑直接注释掉,如果你使用了hdfs加密区的相关内容,就通过调用外部接口的方式重构此方法逻辑,反之直接返回false就行了。
那话说回来,大厂是怎么解决这个问题的呢?这就非常有意思了,看上面的源码注释里说了,这个方法只对hdfs存储有效,那么它是怎么调用的呢,给大家看源码
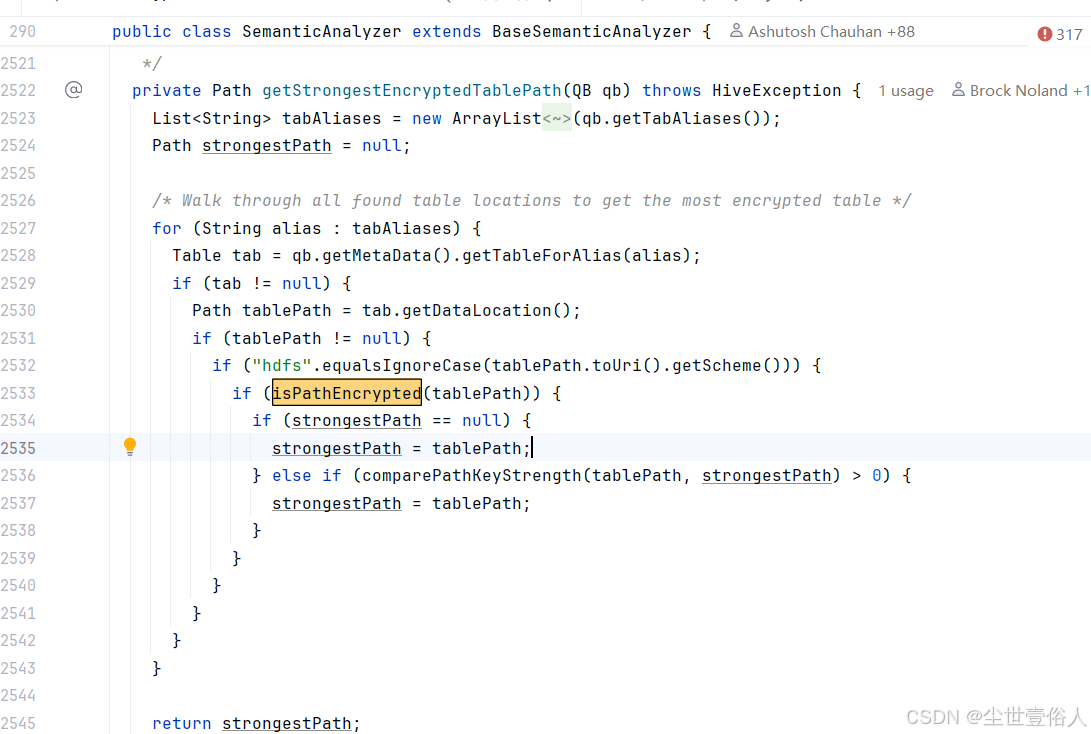
是不是就一目了然了?它其实就是加了个判断只有从元数据服务获取到的存储路径是hdfs协议的才调用这个方法,而且源码写的非常让人难受一路的 if 嵌套,说个题外话大家多看看开源架构的源码,你就会发现在你看来很牛逼的架构,内部其实也不见得有多高的代码质量,各种设计模式项目调用,非常难受,所以去魅的同时,听到网上哪些喷if各种嵌套的笑一笑就行了,其实大家都这样,功能实现了,钱转了,能养家户口就可以了。
所以,大厂的解决思路其实就很直白了,通常的选择是付出成本,直接干掉HDFS,Hadoop本身也支持这样做,Hadoop本身除了HDFS,还能直接支持的有:阿里的OSS、腾讯的COS、Amazon的S3、Azure Blob Storage、Azure Data Lak Storage,除此还有其他第三方存储服务厂商,不过相比下就需要企业自己适配了,而且成本是个大问题,比如之前在李老板家干活,用的是百度自己的BOS,适配起来成本还是很大的,而且它会由于某个热点路径导致整个服务级别的限速,还需要自己开发一个中转用的服务协议,然后还提供了完整的技术工具,例如统一客户端、sql接口等等,后来听说改换HDFS+BOS缓解限速和适配成本,不过这种没有一个完整的团队是玩不转的,知道就行了
至于改造后完整的源码,大家也可以拉取我的git仓库-》https://gitee.com/wangyang159/hive,hive313_auth_cust 分支
文件系统权限的插件支持
有了上面的Hive自定义权限改造,只是完成了三分之一,它保障了hive自身权限访问的可用性。但就像最开始说的那样,如果没有文件系统的支持,就和hive自带权限认证一样了,只是元数据层面有了权限。
为了解决这一问题,就要用到市场上存在的Ranger-hdfs组件,它部署在Hadoop集群上时,会代替Hadoop自身的ACL权限校验,从而保障访问路径时RW或RO权限的正常,在自身没有命中的权限策略时,默认自动回退到hdfs自带acl。注意!!!正常情况下只使用Ranger-HDFS插件就行了,不要用Ranger-Hive插件,一是因为上面已经定制化了Hive的鉴权功能,无论是Hivecli这种直接访问元数据服务从而操作路径的方式,还是HiveServer2这类JDBC方式,能够命中自定义代码,二是Ranger-Hive只能实现HiveServer2的访问鉴权,Hivecli这种客户端无法实现鉴权
至于,Ranger-HDFS这个插件如何部署,可以看我之前发的博文-》https://blog.csdn.net/dudadudadd/article/details/156490216,当然,再说句题外话,如果你实在没有定制化代码的能力,也不对外提供hive-cli这类通过元数据服务对路径强访问的操作方式,那么用Ranger-Hive + Ranger-HDFS 这种相对来讲比较残缺的能力也是没办法的事,但是一般不会怎么可怜,都涉及多租户了那其他必要的Hadoop联邦成本,存储成本,砸进去一堆了不差这点
ranger-hdfs的二次改造
有了上面的东西后,也只是完成了权限改造的三分之二,因为此时hive鉴权插件,以及hdfs灵活的对多用户路径权限能力已经没问题了,可是有一种情况需要完善,当用户越过sql链接协议直接查询表路径怎么办呢?就像上面说的HiveCli或者SparkSession
因此需要去改造ranger-hdfs鉴权插件的核心类,不过本文改完一套了,大家可以参考-》https://gitee.com/wangyang159/ranger ranger26_hdfs_cust 分支
当然上面这一套是改造成本最低的,一般中小企业这么玩,背靠大厂或者是自身能力足够的,都是像上面说的那样,直接改造hadoop底层存储系统,这个工作量真的很大了,需要每一个引擎都有专业的引擎开发,相互协作,围绕着底层存储系统开发人员去改造集群环境
到此所有的权限改造能力点,就给大家分享完了,祝大家早日写入自己的鉴权功能
© 版权声明
文章版权归作者所有,未经允许请勿转载。


