架构抉择:数据仓库与数据湖的全面对比与选型指南
架构抉择:数据仓库与数据湖的全面对比与选型指南
-
- 1. 数据仓库与数据湖概述
-
- 1.1 什么是数据仓库?
- 1.2 什么是数据湖?
- 1.3 架构对比全景图
- 2. 核心区别详解
-
- 2.1 核心对比表
- 2.2 Schema-on-Write vs Schema-on-Read
- 2.3 技术栈对比
- 3. 数据仓库与数据湖的优缺点
-
- 3.1 数据仓库优缺点
- 3.2 数据湖优缺点
- 4. 数据湖 vs 数据仓库 详细对比
-
- 4.1 数据处理流程对比
- 4.2 性能对比
- 4.3 成本对比
- 5. 数据湖与数据仓库的融合
-
- 5.1 Lakehouse 架构
- 5.2 三种架构对比
- 6. 选型决策框架
-
- 6.1 决策流程图
- 6.2 决策矩阵
- 6.3 选型评分表
- 7. 混合架构实践
-
- 7.1 数据仓库 + 数据湖混合架构
- 7.2 混合架构实施示例
- 8. 主流产品对比
-
- 8.1 云服务对比
- 8.2 开源产品对比
- 9. 选型最佳实践
-
- 9.1 选型检查清单
- 9.2 典型场景选型建议
- 10. 实战案例:某电商平台的架构演进
-
- 10.1 初期阶段:纯数据仓库
- 10.2 演进阶段:数据湖+数据仓库
- 10.3 效果对比
- 11. 结语
|
🌺The Begin🌺点点关注,收藏不迷路🌺
|
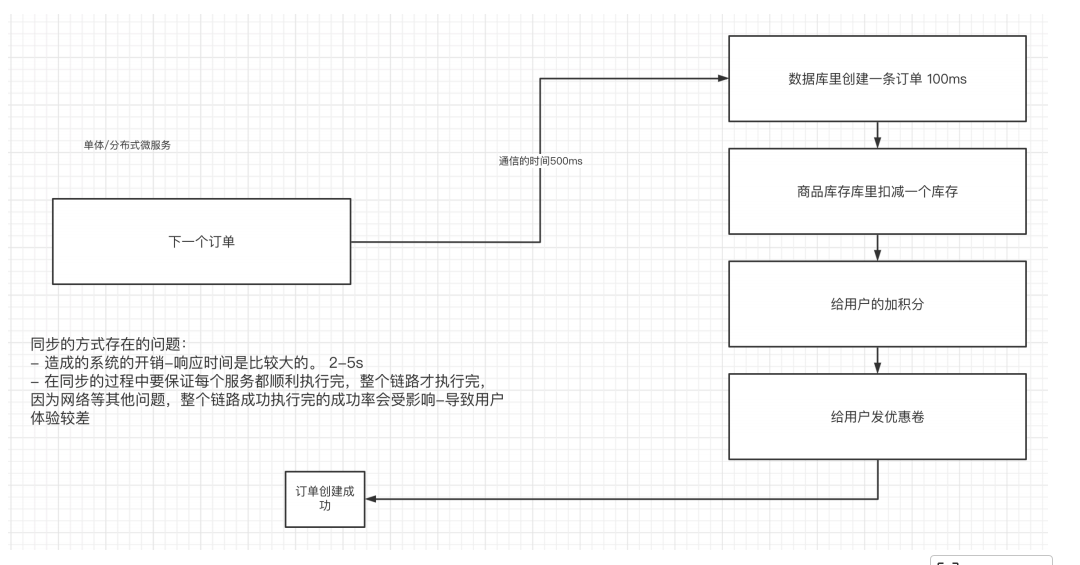
在数据技术快速演进的今天,数据仓库和数据湖是两种最重要的数据管理架构。它们各有优劣,适用于不同的场景。如何正确理解两者的区别,并在实际项目中做出正确的架构选择?本文将系统性地对比数据仓库和数据湖,并提供清晰的选型决策框架。
1. 数据仓库与数据湖概述
1.1 什么是数据仓库?
数据仓库(Data Warehouse) 是面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。它通常采用“写时模式”(Schema-on-Write)的方式,在数据加载前定义好数据模型。
核心特征:
- 结构化数据为主
- 预先定义Schema
- 高查询性能
- 数据经过清洗和转换
1.2 什么是数据湖?
数据湖(Data Lake) 是一个以原始格式存储大量数据的系统,包括结构化、半结构化和非结构化数据。它采用“读时模式”(Schema-on-Read)的方式,数据在读取时才进行解析和结构化。
核心特征:
- 支持所有数据类型
- Schema灵活,无需预定义
- 存储成本低廉
- 支持大数据处理
1.3 架构对比全景图
应用
数据仓库
数据湖
数据源
业务数据库
MySQL/Oracle
日志文件
Nginx/App
物联网数据
传感器/IoT
社交媒体
JSON/XML
图片/视频
非结构化
原始数据存储
S3/HDFS/OSS
元数据层
Hive Metastore
处理引擎
Spark/Flink
ODS层
DWD层
DWS层
DM层
BI报表
机器学习
实时分析
数据科学
2. 核心区别详解
2.1 核心对比表
| 对比维度 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据类型 | 结构化数据为主 | 结构化、半结构化、非结构化 |
| Schema模式 | Schema-on-Write(写时模式) | Schema-on-Read(读时模式) |
| 数据质量 | 高(经过ETL清洗) | 低/原始(未加工) |
| 存储成本 | 高(使用昂贵存储) | 低(使用廉价对象存储) |
| 查询性能 | 高(预优化) | 中/低(取决于引擎) |
| 用户群体 | 业务分析师、BI开发者 | 数据科学家、数据工程师 |
| 典型场景 | 固定报表、BI分析 | 数据探索、机器学习 |
| ACID事务 | 完整支持 | 部分支持(如Delta Lake) |
| 数据更新 | 支持(UPDATE/DELETE) | 有限支持 |
| Schema演化 | 困难(需要迁移) | 简单(灵活适应) |
2.2 Schema-on-Write vs Schema-on-Read
渲染错误: Mermaid 渲染失败: Lexical error on line 2. Unrecognized text. …raph Schema-on-Write(数据仓库) A1[原始 ———————–^
2.3 技术栈对比
| 层次 | 数据仓库 | 数据湖 |
|---|---|---|
| 存储 | Teradata, Greenplum, ClickHouse | HDFS, S3, ADLS, GCS |
| 格式 | 专有格式 | Parquet, ORC, Avro, JSON |
| 计算 | SQL引擎 | Spark, Flink, Presto, Hive |
| 元数据 | 内置数据字典 | Hive Metastore, Glue |
| 查询 | SQL | SQL, Python, R, Scala |
| 云服务 | Snowflake, Redshift, BigQuery | AWS Lake Formation, Azure Data Lake |
3. 数据仓库与数据湖的优缺点
3.1 数据仓库优缺点
root(数据仓库)
优点
查询性能高
预计算优化
索引支持
列式存储
数据质量高
ETL清洗
一致性保证
完整性约束
易用性好
SQL标准
BI工具集成
用户友好
事务支持
ACID保证
并发控制
缺点
成本高昂
专用硬件
许可费用
运维成本
灵活性差
Schema固定
变更困难
数据类型有限
主要是结构化
非结构化支持弱
扩展性受限
垂直扩展为主
水平扩展复杂
3.2 数据湖优缺点
root(数据湖)
优点
成本低廉
廉价对象存储
开源技术
按需付费
灵活性强
Schema-on-Read
支持所有数据类型
快速适应变化
扩展性好
水平扩展
无限容量
数据完整
保留原始数据
支持数据探索
缺点
数据质量差
缺乏清洗
可能存在脏数据
一致性难保证
查询性能低
无预优化
需要计算引擎
延迟较高
治理困难
数据沼泽风险
元数据管理复杂
权限控制难
学习曲线陡
需要多种技术
专业技能要求高
4. 数据湖 vs 数据仓库 详细对比
4.1 数据处理流程对比
数据湖处理流程
BI分析
机器学习
数据探索
源数据
原始存储
使用场景
ETL/ELT
数据仓库
SQL查询
特征工程
模型训练
交互式查询
可视化
数据仓库处理流程
源数据
ETL清洗转换
结构化存储
SQL查询
BI报表
4.2 性能对比
| 查询类型 | 数据仓库 | 数据湖 | 说明 |
|---|---|---|---|
| 聚合查询 | 极快(秒级) | 中等(分钟级) | 数仓有预聚合 |
| 明细查询 | 快(毫秒-秒级) | 快(秒级) | 湖可使用列式存储 |
| 复杂Join | 快 | 中等 | 数仓优化更好 |
| 全文搜索 | 不支持 | 快 | 湖支持多种引擎 |
| 机器学习 | 有限支持 | 原生支持 | 湖支持Python生态 |
| 实时查询 | 支持 | 支持(需配置) | 两者均可实现 |
4.3 成本对比
| 成本项 | 数据仓库 | 数据湖 |
|---|---|---|
| 存储成本 | $0.1-0.5/GB/月 | $0.01-0.05/GB/月 |
| 计算成本 | 较高(按节点) | 弹性(按使用量) |
| 运维成本 | 高(专业团队) | 中(云托管) |
| 开发成本 | 中(SQL为主) | 高(多技术栈) |
| TCO(3年) | 高 | 低 |
5. 数据湖与数据仓库的融合
5.1 Lakehouse 架构
Lakehouse(湖仓一体)是数据湖和数据仓库的融合架构,旨在结合两者的优点。
Lakehouse架构
数据湖存储
S3/ADLS/GCS
表格式
Delta Lake/Iceberg/Hudi
元数据层
统一Catalog
SQL引擎
Presto/Spark SQL
机器学习
Python/R
流处理
Flink/Spark Streaming
BI工具
Tableau/PowerBI
数据科学
Jupyter/SageMaker
实时应用
Kafka/API
5.2 三种架构对比
| 架构 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 传统数据仓库 | 成熟稳定,性能好 | 成本高,灵活性差 | 企业BI、固定报表 |
| 数据湖 | 灵活,成本低 | 数据质量差,治理难 | 数据探索、机器学习 |
| Lakehouse | 兼具两者优点 | 技术较新,成熟度待验证 | 现代数据平台 |
6. 选型决策框架
6.1 决策流程图
仅有结构化数据
包含非结构化数据
< 10TB
> 10TB
固定报表/BI
灵活探索
高(秒级)
低(小时级)
高
中/低
是
否
开始选型
数据类型分析
数据量级?
数据湖
查询模式?
实时性要求?
数据仓库
数据质量要求?
Lakehouse
是否需要ACID?
实施
使用表格式
Delta/Iceberg
6.2 决策矩阵
| 场景特征 | 推荐架构 | 理由 |
|---|---|---|
| 企业BI报表 | 数据仓库 | 性能稳定,工具生态成熟 |
| 数据科学探索 | 数据湖 | 灵活处理各种数据类型 |
| 日志分析 | 数据湖 | 数据量大,Schema多变 |
| 实时数仓 | 数据仓库/Lakehouse | 需要低延迟查询 |
| 机器学习特征存储 | 数据湖 | 支持大规模特征工程 |
| 合规审计 | 数据仓库 | 数据质量可控 |
| 数据归档 | 数据湖 | 存储成本低 |
| IoT数据分析 | 数据湖 | 数据量大,格式多样 |
| 现代化数据平台 | Lakehouse | 兼收并蓄 |
6.3 选型评分表
| 考量因素 | 权重 | 数据仓库 | 数据湖 | Lakehouse |
|---|---|---|---|---|
| 查询性能 | 25% | 10 | 5 | 8 |
| 数据灵活性 | 20% | 4 | 10 | 9 |
| 存储成本 | 15% | 5 | 10 | 9 |
| 运维复杂度 | 10% | 7 | 6 | 6 |
| 数据质量 | 15% | 9 | 4 | 7 |
| 技术成熟度 | 10% | 10 | 8 | 5 |
| 扩展性 | 5% | 6 | 10 | 10 |
| 加权得分 | 100% | 7.5 | 7.6 | 7.8 |
7. 混合架构实践
7.1 数据仓库 + 数据湖混合架构
应用层
数据仓库层
数据湖层
数据源层
清洗后数据
特征数据
业务数据库
应用日志
传感器数据
社交媒体
原始数据存储
S3/HDFS
数据处理
Spark/Flink
ODS层
DWD层
DWS层
DM层
BI报表
数据科学
实时分析
数据API
7.2 混合架构实施示例
-- 示例:使用数据湖存储原始数据,数据仓库存储加工数据
-- 1. 数据湖中的原始数据(以Parquet格式存储在S3)
-- s3://data-lake/raw/orders/dt=2024-01-01/data.parquet
-- 2. 使用Spark处理湖数据
-- from pyspark.sql import SparkSession
-- spark = SparkSession.builder.getOrCreate()
-- df = spark.read.parquet("s3://data-lake/raw/orders/dt=2024-01-01/")
-- cleaned_df = df.filter(df.amount > 0).dropDuplicates(["order_id"])
-- 3. 写入数据仓库
-- cleaned_df.write.jdbc(url="jdbc:mysql://dw-host:3306/dw",
-- table="ods_orders", mode="append")
-- 4. 在数据仓库中进行建模
CREATE TABLE dwd_orders AS
SELECT
order_id,
customer_id,
order_date,
amount,
CASE
WHEN amount >= 1000 THEN 'HIGH'
WHEN amount >= 100 THEN 'MEDIUM'
ELSE 'LOW'
END as order_tier
FROM ods_orders
WHERE order_status = 'COMPLETED';
-- 5. 聚合到数据集市
CREATE TABLE dm_daily_sales AS
SELECT
order_date,
COUNT(*) as order_count,
SUM(amount) as total_sales
FROM dwd_orders
GROUP BY order_date;
8. 主流产品对比
8.1 云服务对比
| 厂商 | 数据仓库产品 | 数据湖产品 | Lakehouse产品 |
|---|---|---|---|
| AWS | Redshift | S3 + Lake Formation | Redshift Spectrum |
| Azure | Synapse SQL | Data Lake Storage | Synapse Analytics |
| GCP | BigQuery | Cloud Storage | BigLake |
| Snowflake | Snowflake | Snowflake(原生) | Snowflake |
| Databricks | Databricks SQL | Databricks Lakehouse | Databricks |
8.2 开源产品对比
| 产品 | 类型 | 特点 | 适用场景 |
|---|---|---|---|
| ClickHouse | 数据仓库 | 极致OLAP性能 | 实时分析 |
| Apache Hive | 数据湖工具 | SQL over Hadoop | 批处理分析 |
| Apache Spark | 湖计算引擎 | 统一分析引擎 | 大数据处理 |
| Presto/Trino | 湖查询引擎 | 联邦查询 | 交互式分析 |
| Delta Lake | Lakehouse表格式 | ACID事务 | 湖仓一体 |
| Apache Iceberg | Lakehouse表格式 | Schema演化 | 湖仓一体 |
| Apache Hudi | Lakehouse表格式 | 增量处理 | 流式湖仓 |
9. 选型最佳实践
9.1 选型检查清单
## 业务需求分析
□ 主要使用场景是BI报表还是数据科学?
□ 需要处理哪些数据类型?
□ 查询延迟要求是多少?
□ 数据量级和增长速度如何?
□ 预算和成本约束是什么?
## 技术能力评估
□ 团队熟悉SQL还是Spark/Python?
□ 是否有数据治理能力?
□ 是否能够管理复杂的ETL流程?
□ 是否有专职的数据工程师?
## 数据特征分析
□ 数据是否有明确的Schema?
□ 数据质量要求有多高?
□ 是否需要支持非结构化数据?
□ 数据更新频率如何?
## 长期规划
□ 未来3-5年的数据增长预期?
□ 是否需要支持机器学习和AI?
□ 是否有数据共享和联邦查询需求?
9.2 典型场景选型建议
| 场景 | 推荐架构 | 说明 |
|---|---|---|
| 初创公司数据分析 | 数据湖 | 成本低,灵活性好 |
| 传统企业BI | 数据仓库 | 成熟稳定,工具生态好 |
| 互联网公司大数据 | Lakehouse | 兼顾性能和灵活性 |
| 金融机构合规报表 | 数据仓库 | 数据质量要求高 |
| AI/ML驱动公司 | 数据湖 | 支持多种数据类型 |
| 多云数据平台 | Lakehouse | 避免厂商锁定 |
| 实时分析场景 | 数据仓库 | 查询延迟要求高 |
| 日志分析 | 数据湖 | 数据量大,格式灵活 |
10. 实战案例:某电商平台的架构演进
10.1 初期阶段:纯数据仓库
业务数据库
ETL
数据仓库
Teradata
BI报表
运营看板
问题:
- 日志数据无法接入(非结构化)
- 存储成本快速增长
- 数据探索能力受限
10.2 演进阶段:数据湖+数据仓库
应用
数据仓库
数据湖
数据源
CDC
清洗日志
特征工程
行为分析
业务DB
应用日志
用户行为
S3存储
Spark处理
Redshift
BI报表
推荐系统
用户画像
10.3 效果对比
| 指标 | 纯数据仓库 | 混合架构 | 改善 |
|---|---|---|---|
| 月存储成本 | $15,000 | $5,000 | 67% ↓ |
| 数据接入类型 | 2种 | 5种 | 150% ↑ |
| 查询性能 | 2秒 | 3秒 | – |
| 数据探索能力 | 有限 | 完整 | – |
| ML模型迭代 | 周级 | 天级 | 7倍 ↑ |
11. 结语
数据仓库和数据湖不是非此即彼的选择,而是可以根据实际需求灵活组合的架构选项。
核心区别速记:
| 特征 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 结构化、精炼 | 原始、多样化 |
| 模式 | 先定义后写入 | 先写入后定义 |
| 用户 | 业务分析师 | 数据科学家 |
| 场景 | BI报表 | 数据探索 |
选型建议:
- 纯BI场景 → 数据仓库
- 数据科学为主 → 数据湖
- 混合需求 → Lakehouse/混合架构
- 不确定 → 从数据湖开始,按需引入数仓
未来趋势:数据仓库和数据湖正在融合,Lakehouse架构将成为现代数据平台的主流选择。无论选择哪种架构,核心都是要服务于业务需求,而不是追逐技术潮流。

|
🌺The End🌺点点关注,收藏不迷路🌺
|
© 版权声明
文章版权归作者所有,未经允许请勿转载。