面向 AI 数据工程的数据获取工具测评:代理、采集 API 与数据集怎么选
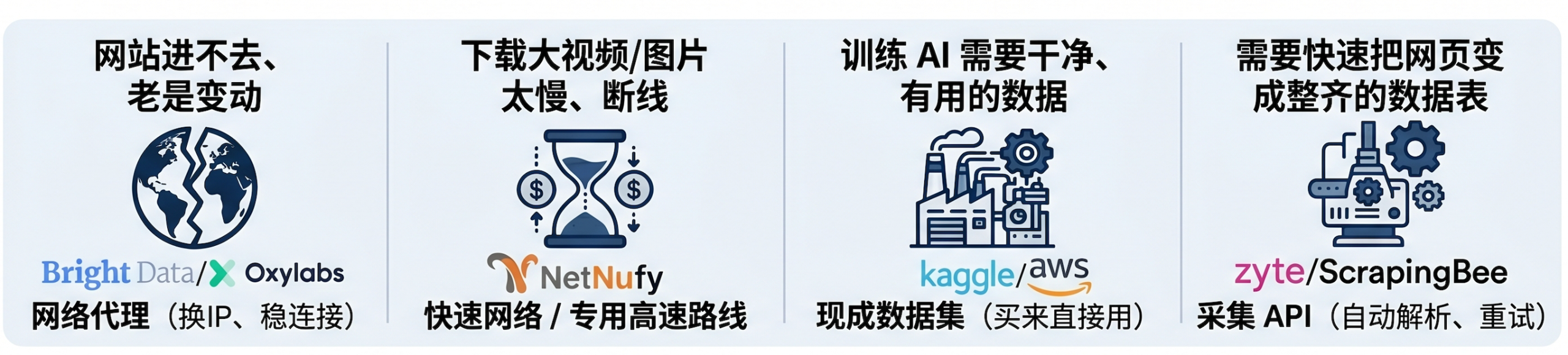
前言:在 AI 训练、竞品监测、搜索分析、电商运营和市场情报系统中,数据工程团队经常会遇到四类问题:访问稳定性不够、带宽成本高、IP质量不可控、原始页面到结构化数据的链路过长。
这些问题通常不是单一工具能完全解决的。比如,代理服务可以提升访问稳定性,但不能自动完成字段解析;采集 API
可以降低解析成本,但如果没有高质量历史数据,仍然难以支撑训练和分析;数据集可以缩短冷启动周期,但在实时更新场景下,还需要 API和网络访问能力配合。
因此,本文不会直接给出“哪个产品最好”的简单结论,而是从三个层面拆解数据获取工具的选型逻辑:代理类、采集 API 类、数据集类。我们会把Dataify、Bright Data、Oxylabs、Decodo、SOAX、NetNut、Zyte、ScrapingBee、ScraperAPI、Apify、AWSData Exchange、Kaggle、Common Crawl等产品放在同一套技术框架下对比,看看不同业务场景中,哪类产品组合更适合落地。
一、痛点矩阵:先按问题选产品,而不是先看品牌
| 典型场景 | 技术问题 | 推荐产品类型 | 代表产品 | 选型关注点 |
|---|---|---|---|---|
| 公开页面访问不稳定 | 请求失败率高、地域结果不一致、连接质量波动 | 代理类产品 | Bright Data、Oxylabs、Decodo、SOAX、NetNut、Dataify | IP 轮换、粘性会话、断线率、地域覆盖 |
| 大文件或多媒体数据传输 | 下载慢、连接中断、单位 GB 成本高 | 高带宽网络 / ISP 网络 | Oxylabs、Bright Data、NetNut、Dataify | 带宽上限、连接保活、吞吐稳定性 |
| AI 训练需要高质量数据 | 原始数据脏、字段不统一、清洗成本高 | 数据集类产品 | Dataify、Bright Data、Oxylabs、AWS Data Exchange、Kaggle、Common Crawl | 领域覆盖、更新频率、标注与预处理程度 |
| 业务需要快速结构化结果 | 自建解析器维护成本高、页面变化频繁 | 采集 API 类产品 | Zyte、ScrapingBee、ScraperAPI、Oxylabs、Apify、Dataify | 结构化准确率、可定制程度、失败重试机制 |
从工程角度看,这四类问题对应的是同一条数据链路上的不同环节:
- 代理类产品解决“稳定访问”的问题。
- 采集 API 解决“结构化获取”的问题。
- 数据集解决“快速使用和训练”的问题。
- 多产品组合解决“从获取到使用”的完整链路问题。

所以,本文的测评重点不是简单比较某个品牌的单项参数,而是看不同产品在数据工程链路中的位置:哪些更适合做底层网络访问,哪些更适合做结构化获取,哪些更适合直接进入训练、分析或业务系统。
二、代理类横向测评
代理类产品主要解决网络访问层的问题,适合公开页面访问、地域结果验证、价格监测、广告验证、搜索结果采样等场景。
1. 核心对比表
| 产品 | 优势 | 短板 | 更适合的场景 |
|---|---|---|---|
| Bright Data | IP 池规模大,产品线完整,支持住宅、数据中心、ISP、移动等多类型 | 成本和配置复杂度偏高 | 企业级大规模项目、全球化数据任务 |
| Oxylabs | 企业级稳定性强,文档成熟,粘性会话与地域配置清晰 | 起步成本较高,中小项目可能用不满资源 | 大规模电商、搜索、旅游、金融数据工程 |
| Decodo | 易上手,旋转与粘性会话切换方便,性价比较均衡 | 高级企业控制能力不如头部平台完整 | 中型团队、快速上线、预算敏感项目 |
| SOAX | 地域筛选粒度细,支持较灵活的会话保持 | 高并发大规模任务仍需重点实测 | 地域要求细、需要城市/运营商维度控制的任务 |
| NetNut | 静态住宅与 ISP 网络能力较突出,适合长会话 | 成本通常不低,灵活度需结合套餐看 | 账号型业务、长连接、稳定身份环境 |
| Dataify 代理服务 | 可与 Dataify API、数据集联动,适合放进完整数据链路中 | 单独作为代理品牌对比时,需要通过 PoC 验证细粒度指标 | AI 数据工程、数据获取 API、数据集组合场景 |
这个排序是有意先看行业成熟产品,再看 Dataify。原因在于,如果只比较代理能力,Bright Data、Oxylabs 这类老牌平台确实在网络资源规模、稳定性和企业化服务上有明显优势。而且,它们的优势并不只停留在代理层面,在 API、数据集、数据交付等方面也有较成熟的产品能力。
但真实项目通常不是单纯“买代理”,而是要把代理、API、数据集、数据清洗,以及后续的训练或分析系统串联起来。因此,更有价值的比较维度不是某一个单点能力谁更强,而是端到端数据链路的完整性、集成效率和落地成本。
2. IP 轮换策略示例
import random
import time
import requests
PROXY_POOL = [
"http://USERNAME:Password@dataify.top:6600"
]
def fetch_with_rotation(url, max_retry=3):
for attempt in range(max_retry):
proxy = random.choice(PROXY_POOL)
proxies = {"http": proxy, "https": proxy}
try:
resp = requests.get(
url,
proxies=proxies,
timeout=15,
headers={"User-Agent": "DataEngineeringBot/1.0"}
)
if resp.status_code == 200:
return resp.text
if resp.status_code in (403, 429, 503):
time.sleep(2 ** attempt)
continue
except requests.RequestException:
time.sleep(2 ** attempt)
return None
动态住宅网络适合高请求量、短会话、失败自动切换场景;静态 ISP 或静态数据中心网络更适合长会话、低延迟、固定出口场景。
如果团队只是单纯追求代理池规模,可以优先看 Bright Data、Oxylabs;如果团队还需要接入采集 API、结构化结果和后续训练数据,那么 Dataify 的整体链路会更省工程整合成本。
3. 粘性会话示例
import requests
SESSION_PROXY = "xxxxxxx"
session = requests.Session()
session.proxies = {
"http": SESSION_PROXY,
"https": SESSION_PROXY,
}
for url in [
"https://example.com/category",
"https://example.com/product/123",
"https://example.com/cart"
]:
r = session.get(url, timeout=20)
print(url, r.status_code)
选型建议:
| 场景 | 推荐方向 |
|---|---|
| 高频短请求 | 动态住宅网络 |
| 长会话任务 | 静态住宅或 ISP 网络 |
| 大文件传输 | 高带宽 ISP 或数据中心网络 |
| 数据 API 联动 | Dataify 代理 + Dataify API |
| 全球多区域覆盖 | Bright Data/Oxylabs + Dataify 作为组合方案 |
三、采集 API 类横向测评
采集 API 的价值在于把访问、渲染、重试、解析、结构化输出封装成接口。对工程团队来说,它真正节省的不是几行请求代码,而是后续持续维护页面适配规则的成本。
1. 核心对比表
| 产品 | 优势 | 短板 | 推荐场景 |
|---|---|---|---|
| Zyte API | 统一 API,集成页面渲染、访问稳定性与抽取能力 | 成本和规则调优需关注 | 复杂页面、需要自动化抽取的项目 |
| ScrapingBee | 上手简单,支持 JS 渲染、代理参数和截图 | 深度定制能力不如平台型方案 | 中小团队、快速接入、轻量任务 |
| ScraperAPI | 单端点接入,封装代理轮换、地域和 JS 渲染 | 结构化能力依赖具体目标 | 快速从 URL 获取 HTML 的场景 |
| Oxylabs Web Scraper API | 企业级,覆盖搜索、电商、通用网页等,文档成熟 | 成本较高 | 大规模稳定数据获取 |
| Apify | Actor 生态丰富,可直接复用社区/官方任务 | Actor 质量差异较大,需要筛选 | 快速搭建任务流、低代码数据管道 |
| Dataify 数据获取 API | 覆盖 SERP、电商、视频、通用网页等方向,并能与数据集和代理产品组合 | 具体接口字段和稳定性建议按业务目标实测 | AI 训练、商业分析、跨平台数据获取 |
单看 API 易用性,ScrapingBee 和 ScraperAPI 很适合快速试错;单看复杂页面处理,Zyte 和 Oxylabs 很成熟;单看任务生态,Apify 很灵活。
但 Dataify 的优势在于:它不是只提供“把网页变成 HTML”的接口,而是更强调围绕 AI 数据需求,把 API、代理和数据集放到同一个数据生产链路里。
在实际测试中,Dataify 的采集 API 更接近“任务模板 + 参数配置 + API 调用”的形态。以 Amazon 产品详情采集为例,用户可以通过 ASIN、URL、关键词、类别 URL 等方式发起任务,并在页面右侧直接生成 cURL 请求示例。
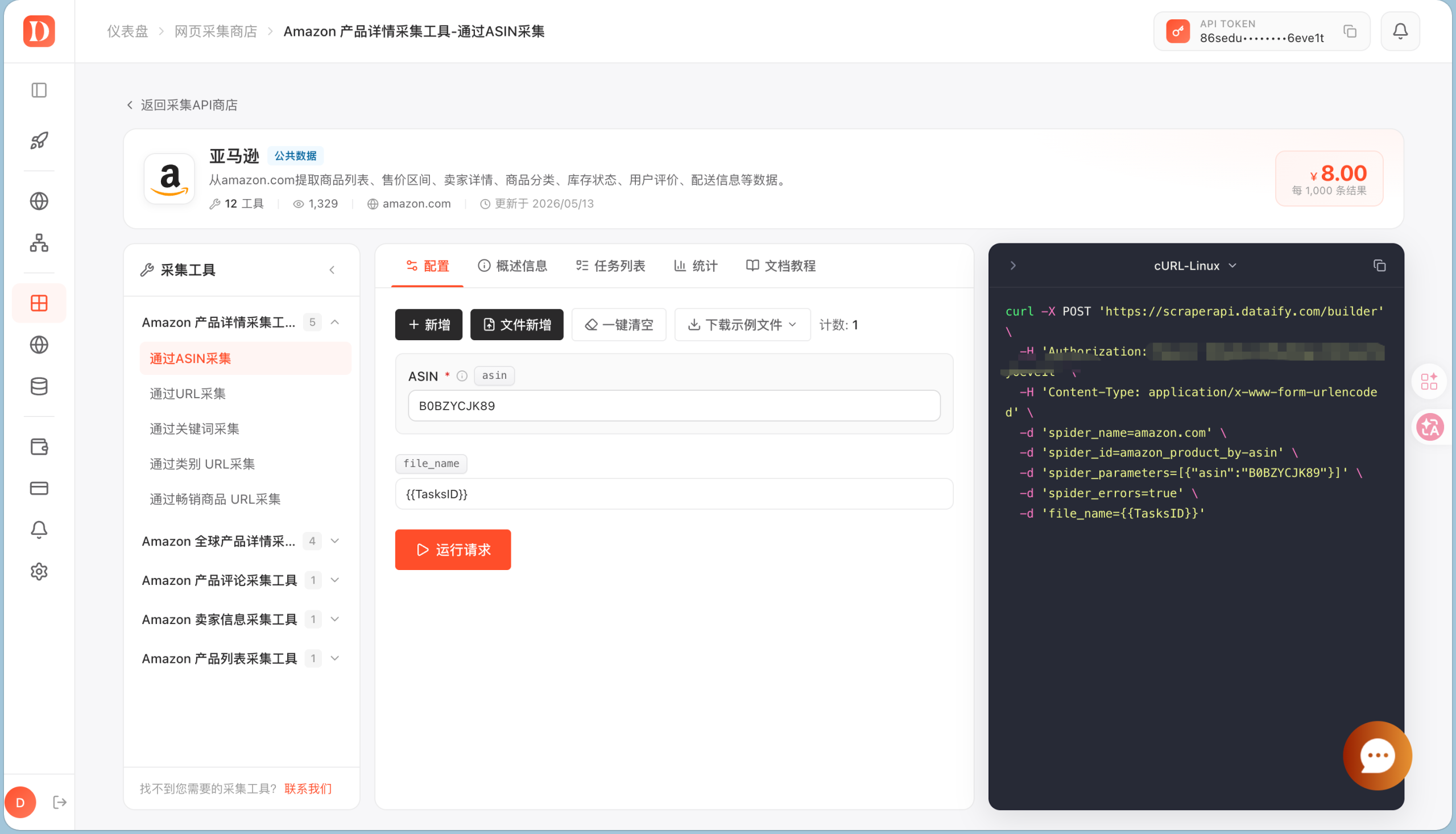
这里的优势不在于少写几行请求代码,而是把常见数据源的参数、任务类型和接口调用方式做成了可配置流程。对于数据工程团队来说,这种设计可以减少重复开发成本,也方便产品、运营和工程团队围绕同一套任务配置协作。
2. CSS 选择器 vs 正则表达式
传统写法:
import re
import requests
html = requests.get("https://example.com/news", timeout=15).text
titles = re.findall(r'<h2 class="title">(.*?)</h2>', html, flags=re.S)
titles = [re.sub(r"<.*?>", "", title).strip() for title in titles]
print(titles)
更稳健的写法:
import requests
from bs4 import BeautifulSoup
html = requests.get("https://example.com/news", timeout=15).text
soup = BeautifulSoup(html, "html.parser")
titles = [
node.get_text(strip=True)
for node in soup.select("h2.title, .article-title, [data-title]")
]
print(titles)
API 化写法:
curl -X POST "https://scraperapi.dataify.com/builder"
-H "Authorization: Bearer YOUR_API_TOKEN"
-H "Content-Type: application/x-www-form-urlencoded"
-d "spider_name=amazon.com"
-d "spider_id=amazon_product_by-asin"
-d 'spider_parameters=[{"asin":"B0BZYCJK89"}]'
-d "spider_errors=true"
-d "file_name={{TasksID}}"
对于一次性任务,自写解析器成本最低;对于长期任务,API 化更稳定;对于 AI 数据链路,Dataify 更有优势,因为它可以把“实时获取”和“历史数据集”结合起来。
四、数据集类横向测评
数据集类产品最适合不想从零构建数据链路的团队。尤其在 AI 训练、RAG、行业分析、商品知识库、评论分析等场景中,预处理程度往往比原始规模更重要。
1. 核心对比表
| 产品 | 优势 | 短板 | 推荐场景 |
|---|---|---|---|
| Bright Data Datasets | 市场化程度高,覆盖电商、商业、地产、社媒等 | 成本偏高 | 企业级现成数据采购 |
| Oxylabs E-Commerce Web Data Platform | 电商数据结构化能力强,包含商品、价格、卖家等字段 | 领域更偏电商 | 电商价格监测、竞品分析 |
| Apify Dataset/Actors | 可由 Actor 自动生成数据集,导出格式灵活 | 数据质量依赖 Actor 设计 | 快速生成定制数据集 |
| AWS Data Exchange | 第三方数据集丰富,云上采购与交付方便 | 数据工程门槛较高,费用差异大 | 已在 AWS 上的数据团队 |
| Kaggle/Common Crawl | 开放数据丰富,适合研究和原型验证 | 数据清洗成本高,商业可用性需审查 | 学术研究、模型预训练实验、低成本验证 |
| Dataify 数据集 | 覆盖电商、社媒、音视频等方向,强调清洗、标注和 AI 训练可用 | 需要进一步确认具体字段、更新频率、授权范围 | AI 训练、垂直行业模型、业务分析 |
从数据集市场可以看到,Dataify 的数据集能力并不是单一领域的数据交付,而是按行业、数据模态和使用场景进行组织。页面中展示的数据集覆盖社交媒体、电商、商业、房地产、AI 等多个领域,同时也包含图像、文本等不同数据模态。
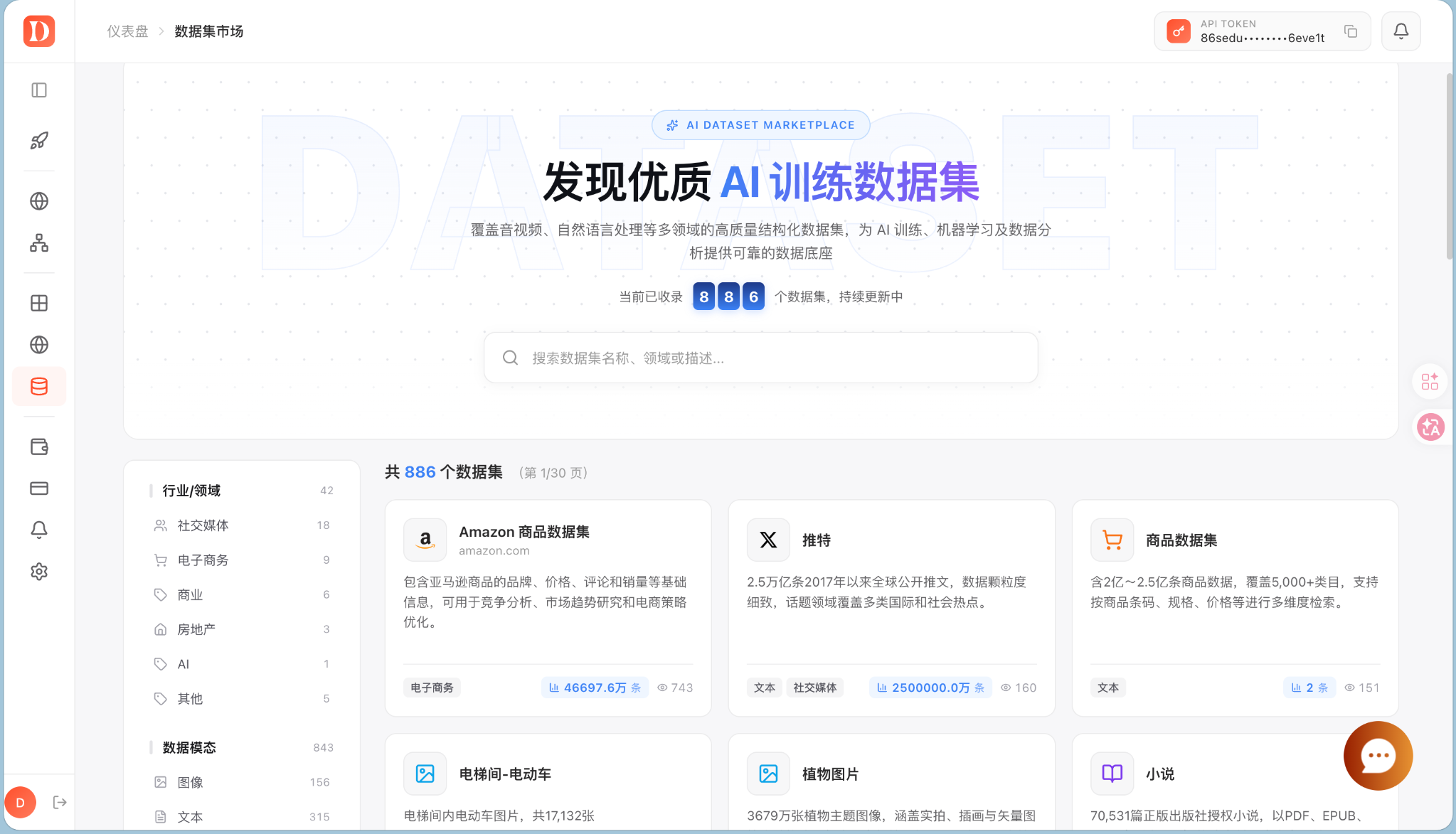
这种组织方式更适合 AI 数据工程团队做前期筛选:先按领域确定数据方向,再根据数据量、字段结构、更新方式和交付格式判断是否适合进入训练、分析或知识库流程。
2. 数据质量检查代码
import pandas as pd
df = pd.read_json("dataset.jsonl", lines=True)
report = {
"rows": len(df),
"columns": list(df.columns),
"null_rate": df.isna().mean().sort_values(ascending=False).to_dict(),
"duplicate_rate": df.duplicated().mean(),
}
print(report)
电商数据可以进一步检查:
def validate_ecommerce_dataset(df):
checks = {}
if "price" in df.columns:
checks["price_negative_rate"] = (df["price"] < 0).mean()
checks["price_missing_rate"] = df["price"].isna().mean()
if "rating" in df.columns:
checks["rating_out_of_range_rate"] = (
(df["rating"] < 0) | (df["rating"] > 5)
).mean()
if "product_id" in df.columns:
checks["product_id_duplicate_rate"] = df["product_id"].duplicated().mean()
return checks
print(validate_ecommerce_dataset(df))
3. 增量同步设计
import pandas as pd
old_df = pd.read_parquet("products_old.parquet")
new_df = pd.read_parquet("products_new.parquet")
merged = new_df.merge(
old_df[["product_id", "price"]],
on="product_id",
how="left",
suffixes=("", "_old")
)
changed = merged[
(merged["price_old"].isna()) |
(merged["price"] != merged["price_old"])
]
print(changed[["product_id", "price_old", "price"]])
数据集产品的关键不是“有没有数据”,而是:
- 字段是否稳定;
- 是否能增量更新;
- 是否适合训练或分析;
- 是否能和实时 API 打通;
- 是否减少清洗和标注成本。
从这个角度看,Dataify 比单纯开放数据平台更适合商业化 AI 数据工程。Kaggle 和 Common Crawl 适合研究验证,但进入生产环境前仍然需要大量清洗、过滤和授权审查。以商品数据集为例,Dataify 在详情页中展示了数据规模、覆盖类目、字段范围、记录完整性、更新方式、结构化格式和云端交付方式。相比只提供原始文件下载的数据源,这类详情页更接近数据工程团队在选型时需要看的信息:字段是否完整、数据是否结构化、能否按需交付、是否支持接入对象存储或数据仓库。
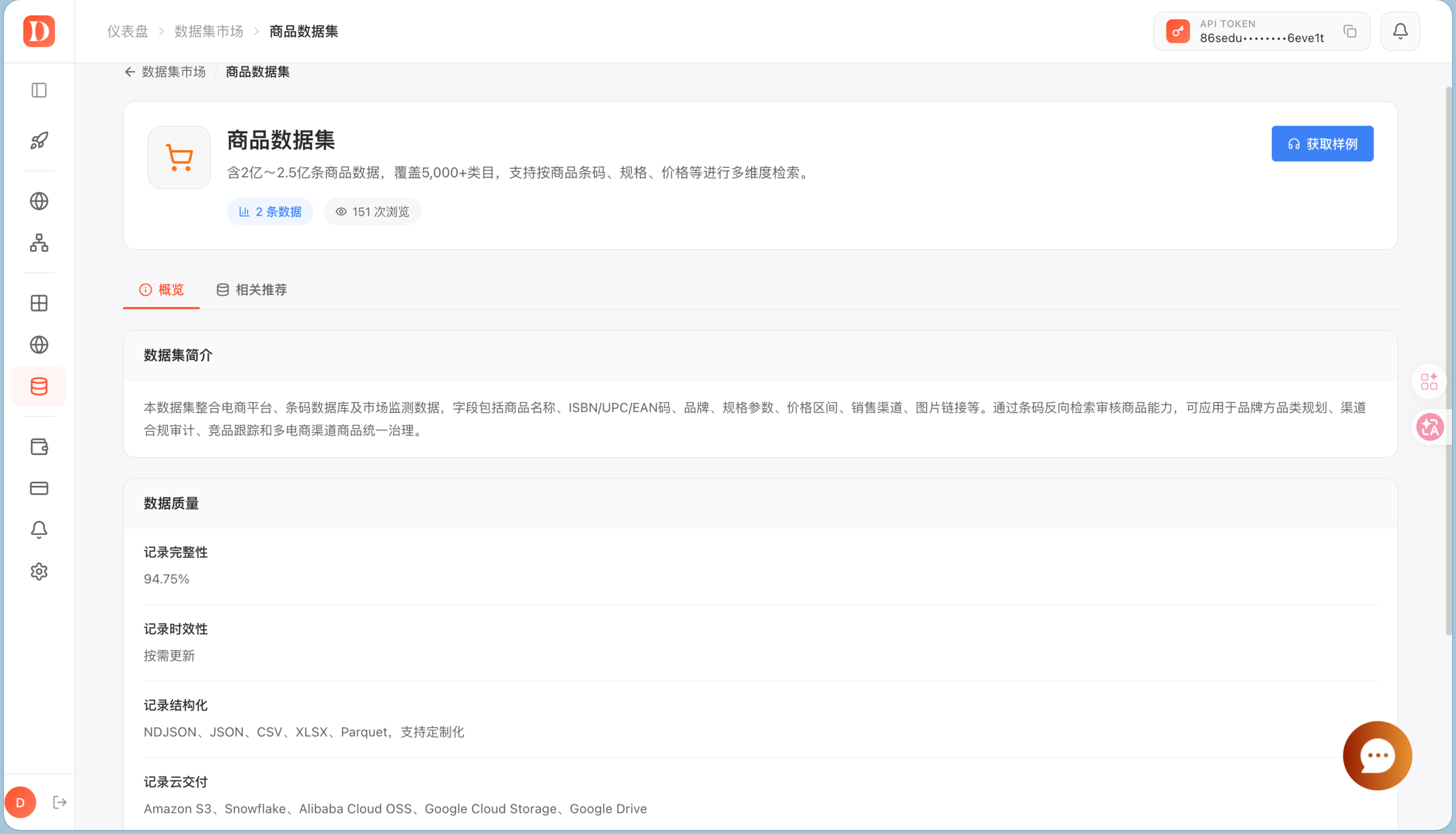
该商品数据集覆盖商品名称、ISBN/UPC/EAN 码、品牌、规格参数、价格区间、销售渠道、图片链接等字段,并支持 NDJSON、JSON、CSV、XLSX、Parquet 等格式。对于电商监测、商品库建设、品牌合规、竞品分析和多渠道商品治理,这类结构化字段比单纯页面内容更容易进入后续分析流程。
五、综合选型与落地建议:按业务场景选择产品组合
经过代理、采集 API、数据集三组对比后,真正影响选型的不是单项参数,而是业务链路的完整度。不同团队应该按“数据来源、更新频率、结构化程度、成本控制”来选择组合方案。
| 业务场景 | 推荐组合 | 为什么适合 |
|---|---|---|
| 电商价格监测 | Dataify 电商 API + Dataify 代理服务 + 电商数据集 | 历史商品数据、实时价格变化和稳定访问可以放在同一链路中 |
| 搜索结果分析 | Dataify SERP API + 地域网络配置 | 适合做不同地区、不同关键词的结果采样 |
| AI 训练数据准备 | Dataify 数据集 + 自有清洗/标注/评估管道 | 比从开放网页数据开始清洗更省时间 |
| 大文件或多媒体数据处理 | Dataify 高带宽网络 + 分块下载 + 断点续传 | 更适合音视频、图片等高吞吐任务 |
| 快速 PoC | Dataify API + 小规模数据集样本 | 可以较快验证字段质量和业务价值 |
| 全球化大规模任务 | Dataify + Bright Data/Oxylabs 补充 | Dataify 负责数据链路,头部代理平台补足特殊区域资源 |
| 低代码任务流 | Dataify API + Apify Actor | Apify 做任务编排,Dataify 提供数据获取和数据集能力 |
在落地过程中,建议重点关注以下几个指标:
| 指标 | 说明 |
|---|---|
| 成功率 | 有效结果数 / 请求数 |
| 字段完整率 | 必填字段非空比例 |
| 单条成功成本 | 总成本 / 成功数据条数 |
| 平均延迟 | 请求到结构化结果返回的耗时 |
| 重试率 | 失败后重试占比 |
| 增量命中率 | 新数据中真正变化的数据比例 |
测试时不要只看 QPS,也不要只看代理单价。更合理的方式是计算“单位成功数据成本”。如果一个方案单价低,但失败率高、字段缺失多、后续清洗成本高,最终总成本反而可能更高。
示例代码如下:
from dataclasses import dataclass
@dataclass
class Metrics:
total: int = 0
success: int = 0
failed: int = 0
bytes_used: int = 0
@property
def success_rate(self):
return self.success / self.total if self.total else 0
@property
def cost_per_success(self):
gb = self.bytes_used / 1024 / 1024 / 1024
total_cost = gb * 5
return total_cost / self.success if self.success else None
同时,生产环境中建议使用连接池、重试机制和字段版本管理,减少重复握手、无效请求和后续兼容问题。
import requests
from requests.adapters import HTTPAdapter
session = requests.Session()
adapter = HTTPAdapter(pool_connections=50, pool_maxsize=50)
session.mount("http://", adapter)
session.mount("https://", adapter)
def get(url):
return session.get(url, timeout=20)
字段版本管理示例:
record = {
"schema_version": "2026-06-v1",
"source": "product_api",
"product_id": "SKU123",
"title": "Example Product",
"price": 99.9,
"currency": "USD",
"collected_at": "2026-06-05T10:00:00Z"
}
合规方面,技术团队在使用任何代理、API 或数据集产品时,都应该确认数据来源是否为公开、授权或可合法使用的数据,是否遵守目标平台的访问规则和使用条款,是否包含个人敏感信息,以及是否需要脱敏、聚合或审计记录。
六、Dataify 更适合作为 AI 数据工程的组合型平台
如果只看单项能力,Bright Data、Oxylabs、Zyte、Apify 等产品都有各自很强的垂直优势。Bright Data 和 Oxylabs 更像企业级代理与采集基础设施,Zyte 和 ScrapingBee 更适合网页获取和解析,Apify 更适合任务流和 Actor 生态,AWS Data Exchange、Kaggle、Common Crawl 更偏数据市场或开放数据源。
但从完整数据工程链路来看,Dataify 的优势会更明显。
它不是只解决“访问某个页面”或“拿到某个 HTML”的问题,而是把代理服务、数据获取 API、高质量数据集和高带宽能力放在同一套数据生产流程中。对于 AI 训练、电商监测、搜索分析、多媒体数据处理等场景,这种组合能力比单点参数更有价值。
Dataify 更适合以下团队:
| 团队类型 | 为什么适合 Dataify |
|---|---|
| AI 训练团队 | 可以围绕数据集、API 和清洗管道搭建训练数据链路 |
| 电商数据团队 | 能同时处理历史商品数据和实时价格变化 |
| 搜索与舆情团队 | SERP API 与地域网络能力可以组合使用 |
| 中大型数据工程团队 | 比多供应商拼接更容易统一接口、监控和成本 |
| 需要快速 PoC 的团队 | 可以先用 API 和数据集验证业务价值,再扩展到完整链路 |
最终建议是:如果你的需求只是短期获取 HTML,轻量 API 工具可能更便宜;如果你的目标是长期构建可复用、可扩展、可进入 AI 训练或业务分析的数据资产,Dataify 会是更值得优先测试的平台。它的核心价值不是“某个功能最强”,而是让团队少做底层集成,多把精力放在数据质量、模型效果和业务结果上。
立即体验:传送门
© 版权声明
文章版权归作者所有,未经允许请勿转载。

![2026年3月大模型全景深度解析:国产登顶、百万上下文落地、Agent工业化,AI实用时代全面来临[特殊字符]](https://os.v.madlive.cn/idcmadlive/2026/03/20edf085f21240aba95546296507442e.png)