
大模型驱动大数据SRE智能运维
____simple_html_dom__voku__html_wrapper____>
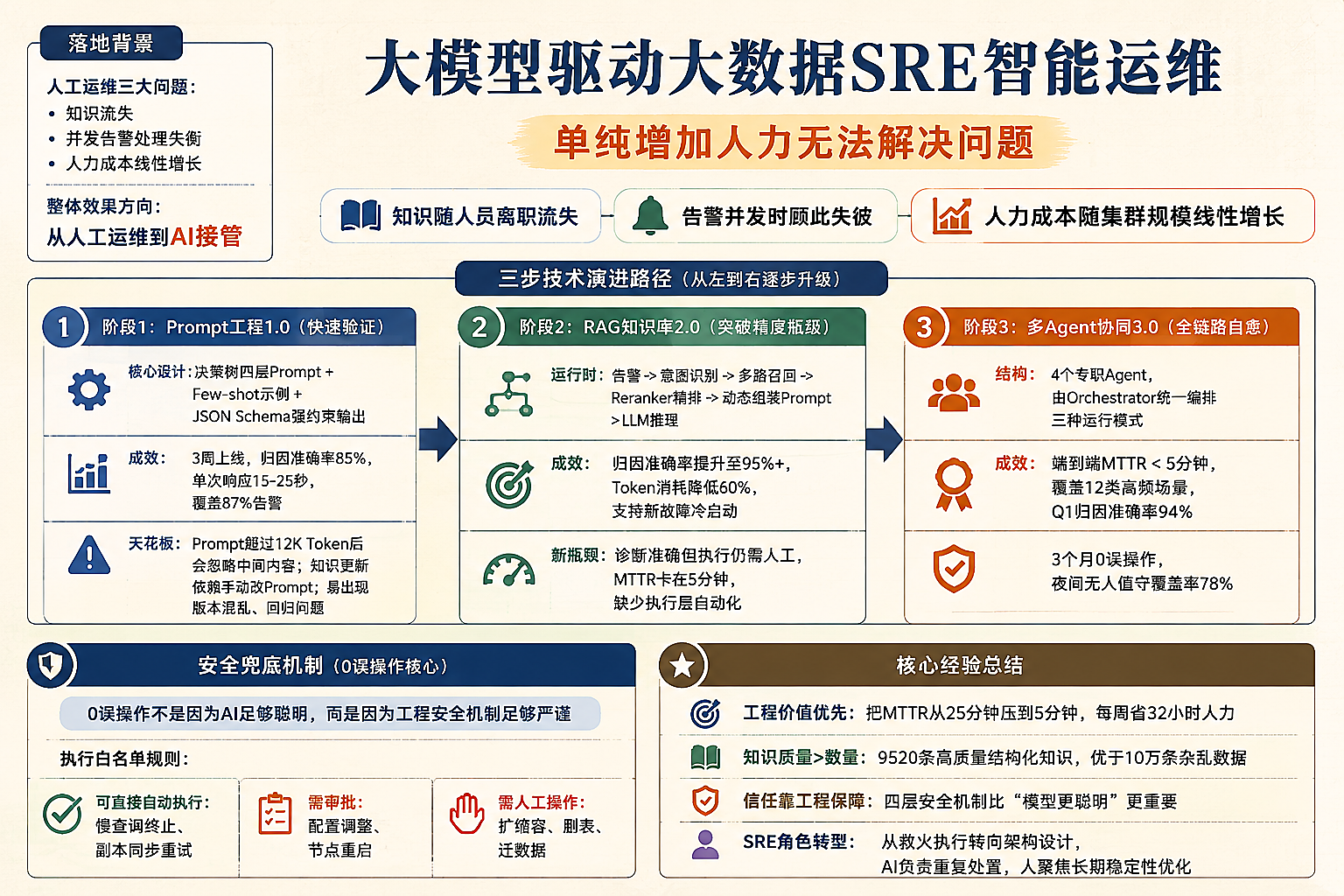
落地背景
| 困境类型 | 具体表现 |
| 规模复杂度高 | 上下游依赖复杂,集群部署模式差异大,运维规则碎片化 |
| 故障定位慢 | 无系统化工具,人工查日志、关联监控,单次定位耗时15-20分钟 |
| 故障处置慢 | SOP多且需人工判断,串行操作无法并发,60%+为重复告警 |
👉 核心结论:单纯增加人力无法解决问题——知识随人员离职流失、告警并发时顾此失彼、人力成本随集群规模线性增长。
整体效果:从人工运维到AI接管
| 环节 | 人工运维(Before) | SRE Pilot接管(After) | 提升幅度 |
| 故障定位 | 登集群→查面板→翻Wiki→凭经验判断,15-20min | DiagAgent取数+RAG召回案例+LLM推理,<30s | 效率提升30倍+ |
| 处置分析 | 回忆历史案例→定操作步骤→资深工程师把关,5-8min | PlanAgent生成方案+风险评估→SRE一键确认,<1min | – |
| 止损执行 | SSH逐条执行命令→人工盯屏验证,3-5min | ExecAgent自动执行→VerifyAgent校验,0误操作 | 全链路自动化 |
| MTTR | ~25分钟 | <5分钟 | 降低80% |
| 其他价值 | 知识无沉淀、凌晨需人工值守 | 7×24无人值守、每次处置自动入库反哺知识库 | 覆盖85%+日常告警,Q1累 |
技术演进路径:从Prompt到多Agent的三步走
阶段1:Prompt工程1.0(快速验证)
-
核心设计:决策树四层Prompt,搭配Few-shot示例、JSON Schema强约束输出
-
成效:3周上线,归因准确率85%,单次响应15-25s,覆盖87%告警
-
天花板:Prompt超过12K Token后LLM会忽略中间内容,知识更新依赖手动改Prompt,易出现版本混乱、回归问题。
阶段2:RAG知识库2.0(突破精度瓶颈)
知识库工程实践
| 模块 | 具体设计 |
| 四层结构 | L1-L4分层管理,共入库9520+条知识 |
| 版本管理 | 所有手册/RCA报告存Git,PR评审后合并,自动触发向量重建,支持回滚 |
| 向量更新 | 用bge-m3(中英双语)嵌入,增量更新延迟<5分钟,按namespace隔离 |
| 质量校验 | CI流水线自动检查文档结构、命令可执行性、内链有效性 |
| 召回监控 | 跟踪Top-K命中率,低质文档自动标记人工复核,召回精度从72%提升至89% |
-
运行时:告警→意图识别→多路召回→Reranker精排→动态组装Prompt→LLM推理
-
成效:归因准确率提升至95%+,Token消耗降低60%,支持新故障冷启动
-
新瓶颈:诊断准确但执行仍需人工,MTTR卡在5分钟,缺少执行层自动化。
阶段3:多Agent协同3.0(全链路自愈)
拆分4个专职Agent,由Orchestrator统一编排三种运行模式:
| 运行模式 | 适用场景 | 占比 |
| 串行 | 标准诊断+自愈主流程:采集→根因→决策→执行→验证 | 70% |
| 并行 | 多告警同时触发,多组Agent实例并发处理 | 20% |
| 循环 | 验证失败时触发补偿动作,最多重试3次 | 10% |
安全兜底机制(0误操作核心)
| 防护层级 | 规则 |
| 置信度门槛 | 置信度<0.7自动降级为「建议模式」,推送人工处理,已拦截23次误触发 |
| 高危审批 | 扩容/配置变更等操作100%推送KIM审批卡片,平均响应47秒 |
| 步骤级验证+回滚 | 每步执行后立即校验指标,异常自动回滚,已成功触发7次自动回滚 |
| 全程审计 | 全链路操作日志留存90天,支持完整回放,满足合规要求 |
-
执行白名单规则:慢查询终止、副本同步重试可直接自动执行;配置调整、节点重启需审批;扩缩容、删表/迁数据需人工操作。
-
成效:端到端MTTR<5分钟,覆盖12类高频场景,Q1归因准确率94%,3个月0误操作,夜间无人值守覆盖率78%。
核心经验总结
-
工程价值优先:AI要解决真实痛点,不是炫技——把MTTR从25分钟压到5分钟、每周省32小时人力,才是硬价值。
-
知识质量>数量:RAG的本质是「用好知识」,不是堆砌内容,9520条高质量结构化知识的价值远高于10万条杂乱数据。
-
信任靠工程保障:0误操作不是因为AI足够聪明,是因为四层安全机制够严谨,AI落地的最后一公里是「人对机器的信任」。
-
SRE角色转型:从「救火执行」转向「架构设计」,AI负责重复处置,人聚焦长期稳定性优化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
