Bright Data Firehose 评测:每天 10 亿条实时 Web Data 如何接入 AI 系统
Bright Data Firehose 评测:每天 10 亿条实时 Web Data 如何接入 AI 系统
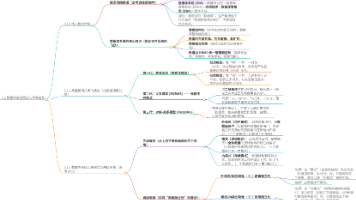
什么是 Bright Data Firehose?
Bright Data Firehose 是一种实时网页数据流服务,可将持续采集的公开网页数据直接推送到 Amazon S3、Azure Blob 或 Webhook,而无需企业自行维护爬虫基础设施。
一、两个把人坑惨的真实场景
先说两个我身边真实发生的故事。
一个做 LLM 微调的团队,花钱买了一批电商语料拿去训练价格预测模型。数据采集日期是三个月前——模型上线那天就失效了,因为市场早变了,它学到的是"过去的世界"。
另一个做跨境电商比价的团队,价格监控脚本每小时跑一次。听起来够勤快了,但竞品在两次抓取之间偷偷改了 10 次价,漏掉的每一次价格变动,都是漏掉的竞争洞察。
这两件事根子上是同一个病:你在用"按需拉取"的思路,处理一件"持续在变"的事。爬虫写得再稳,它本质还是"我想要某个页面 → 去抓回来",是离散的、有间隔的、会错过窗口的。
这篇文章讲的是另一种范式——数据采集完成的那一瞬间,自动推给你。它是 Bright Data 的新产品 Data Firehose,一条 24 小时不断流的实时公开网页数据管道。想边看边试的,可以先用这个链接领试用额度:Bright Data 注册链接。
二、先把三个产品分清楚:别再混为一谈
很多人一听"Bright Data 抓数据"就以为只有一种东西。其实它有三种完全不同的交付范式,搞混了选型就会错。
| 产品 | 模式 | 一句话比喻 | 适合场景 |
|---|---|---|---|
| Scraper API | 按需拉取(Pull) | 口渴了去倒一杯水 | 要某个具体页面的数据 |
| Datasets | 批量下载(Batch) | 一次买一桶矿泉水 | 要一次性的大量历史数据 |
| Data Firehose | 持续推送(Push/Stream) | 接上自来水管,24 小时不停流 | 要持续、实时、大规模的网页数据流 |
关键认知:Firehose 不是"更强的爬虫",它是另一种交付方式。 前两种是你主动去"拉",Firehose 是数据主动"推"给你。当你的需求从"抓一次"变成"永远要最新的",范式就该换了。
三、为什么"按需拉取"会在这四个场景翻车
| 痛点 | 自建/Pull 方案的困境 | Firehose 的解法 |
|---|---|---|
| 自建爬虫基础设施 | 代理池封锁率 60%+,JS 渲染、验证码、频率限制全要自己扛,目标站一改版解析逻辑就崩 | 告诉它你要哪些域名,数据自动流进你的 S3,零爬虫维护 |
| 批量数据集时效性 | 买来的数据集是三个月前的,模型"活在过去" | 持续流式更新,训练管道永远喂到今天的数据 |
| Common Crawl 处理成本 | 免费,但单个 WARC 压缩后就 >1GB,要自己写解析、过滤大量失效页,更新还是月级 | 按需过滤、清洁交付、随时可用,不碰原始 WARC |
| 价格监控实时性 | 每小时一次的批次,错过两次抓取之间的所有价格变动 | 采集完即推送,不等批次周期,价格变动第一时间可见 |
四个场景共享同一个结论:当"新鲜度"成为硬指标时,批次模式的间隔本身就是缺陷。
四、Firehose 的能力拆解 & 与 Common Crawl
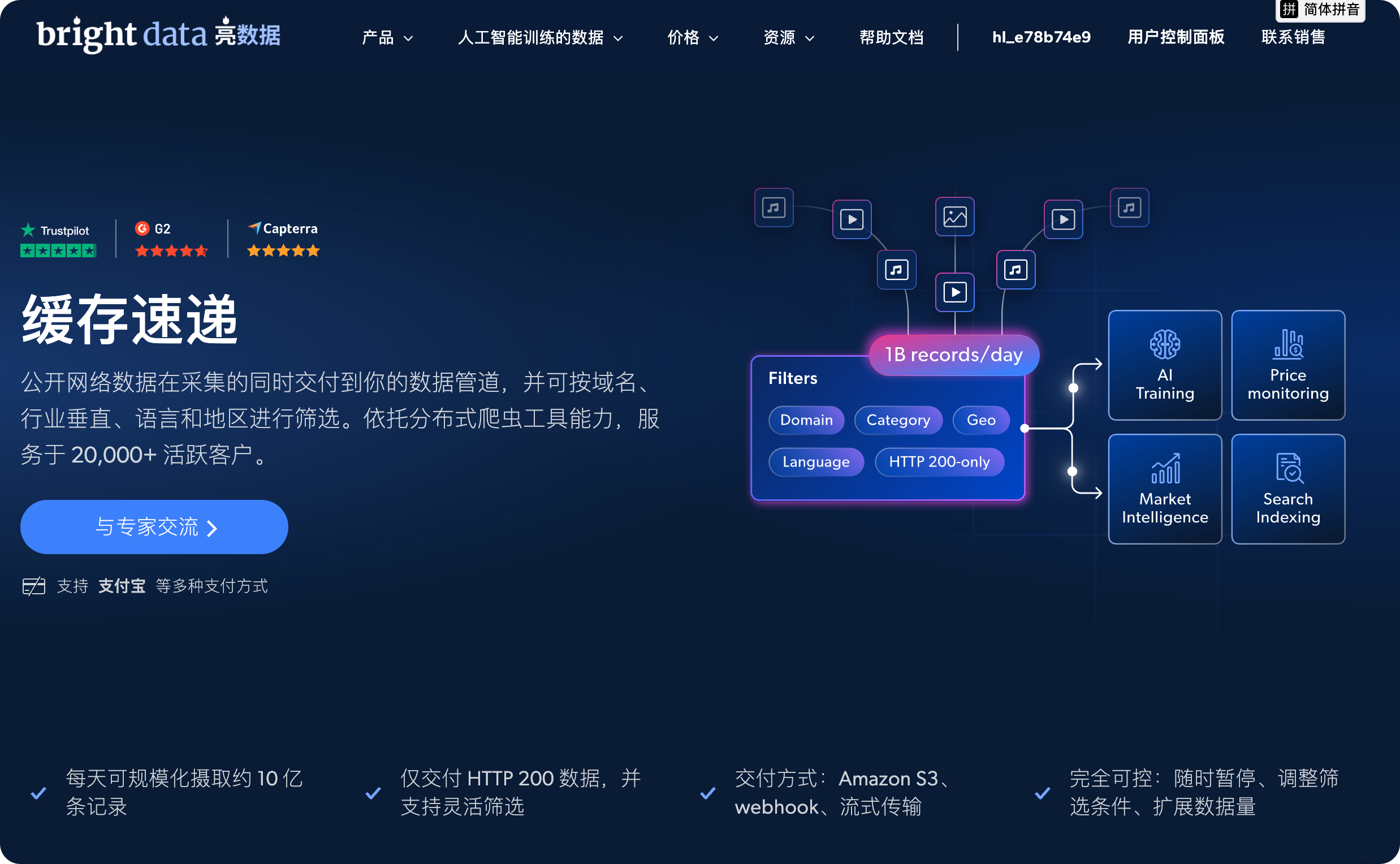
先看它的体量(官方口径):
| 指标 | 数值 |
|---|---|
| 每日数据量 | 约 10 亿条记录 |
| 每日数据体积 | 约 350TB |
| 每日新增文本 Token | 5T+ 个 |
| 每日新发现域名 | 约 20 万个 |
| 数据质量 | HTTP 200 only——只交付成功加载的页面,失败请求全部过滤 |
| 历史存量 | Web Archive 90PB+,6240 亿+ 历史页面 |
"HTTP 200 only"这条很容易被忽略,但对工程师是真省心:你拿到的每一条都是成功加载的页面,不用再写一堆 try/except 去剔除 404、403、超时的脏数据。
它也不是"全量轰炸",有四个可调旋钮:
- 过滤:域名 / 行业垂类 / 语言 / 地区 / URL 路径 / 时间范围,六个维度精准收口
- 交付:Amazon S3、Azure Blob、Webhook、Stream 流式
- 数据类型:原始 HTML(JS 渲染后)、结构化解析字段、图片/视频 URL、元数据
- 定价:$0.2 / 1,000 条 HTML(24 小时内新鲜数据,约 1 小时内交付);$1 / 1,000 条(历史归档,2 天内交付)
大量 AI/ML 工程师现在用的是免费的 Common Crawl,这也是 Firehose 最该被拿来对比的对象:
| 对比维度 | Bright Data Firehose | Common Crawl |
|---|---|---|
| 数据新鲜度 | 实时,采集即交付 | 每月/每两月批次,数据可能已过期 |
| 数据体量 | 8 个月采集 17.5PB、1180 亿页面 | 18 年累计 250 亿页面 |
| 数据质量 | HTTP 200 only,支持 JS 渲染 | 98.6% 静态 HTML,不支持 JS 渲染 |
| 过滤能力 | 域名/分类/语言/地区/路径多维过滤 | 无内置过滤,需自己处理原始 WARC |
| 交付方式 | S3 / Azure / Webhook | 无,需自行下载处理 |
| 价格 | $0.2/1K HTML(按需付费) | 免费,但处理成本极高 |
一句话总结这张表:Common Crawl 适合预算敏感且具备数据工程能力的团队,而 Firehose 更适合需要实时性和可直接消费数据的企业场景。 如果你想看完整定价对比,可以查 Bright Data 定价页,或直接用 我的专属注册链接 开个账号试。
五、它到底能干什么
① AI / LLM 训练数据持续更新
做预训练/微调的团队最怕"数据过期"。用 Firehose:过滤设成 语言=中英 + 垂类=新闻/科技/电商,交付到 S3 按日批次,下游直接接 Hugging Face Dataset 处理脚本。每天 5T+ 新增 Token,训练数据永远反映今天的互联网。
② 电商价格实时监控
过滤设成 域名=目标电商 + 路径=/dp/、/product/,交付走 Webhook 实时推送,写进时序库(InfluxDB / TimescaleDB),接价格告警系统,价差超阈值自动通知。采集即到,不再漏掉两次抓取之间的价格窗口。
剩下两个场景逻辑也类似,这里就不展开了:市场情报监控把垂类设成新闻+社媒,Webhook 接 NLP 管道做实体识别和情感分析,趋势信号在变成"新闻"之前就被你捕获;搜索/RAG 索引保鲜则走目标域名白名单 → S3 → Elasticsearch 增量更新,让用户和 RAG 知识库永远搜到今天的内容。
六、三步接入:真实可跑的代码
接入的整体数据流向是这样的——你只定义「要什么」和「推到哪」,中间的反爬、渲染、重试全由 Firehose 兜底:

整条链路对应三个步骤:① 定义过滤条件 → ② 选交付方式(S3 或 Webhook)→ ③ 消费数据接下游。
Step 1:定义过滤条件(提交给 Bright Data 配置)
{
"filters": {
"domains": ["amazon.com", "ebay.com", "walmart.com"],
"categories": ["ecommerce", "retail"],
"languages": ["en", "zh"],
"geos": ["US", "CN", "GB"],
"paths": ["/dp/", "/product/", "/item/"]
},
"delivery": {
"method": "s3",
"bucket": "your-s3-bucket-name",
"prefix": "firehose/ecommerce/",
"format": "json"
},
"schedule": "continuous"
}
Step 2:从 S3 消费 Firehose 数据
import boto3, json
import pandas as pd
from datetime import datetime, timezone
def consume_firehose_from_s3(bucket: str, prefix: str, since_hours: int = 1) -> pd.DataFrame:
"""从 S3 消费 Bright Data Firehose 数据,默认读最近 1 小时的新鲜数据。"""
s3 = boto3.client("s3")
records = []
resp = s3.list_objects_v2(Bucket=bucket, Prefix=prefix)
for obj in resp.get("Contents", []):
age_h = (datetime.now(timezone.utc) - obj["LastModified"]).total_seconds() / 3600
if age_h > since_hours:
continue
body = s3.get_object(Bucket=bucket, Key=obj["Key"])["Body"].read().decode("utf-8")
for line in body.strip().split("n"):
if not line:
continue
r = json.loads(line)
records.append({
"url": r.get("url"),
"domain": r.get("domain"),
"html": r.get("html"),
"collected_at": r.get("timestamp"),
"language": r.get("language"),
"status_code": r.get("status_code"), # 全部是 200
})
df = pd.DataFrame(records)
print(f"✅ 已消费 {len(df)} 条 Firehose 记录(最近 {since_hours} 小时)")
return df
Step 3:Webhook 接收端(价格监控场景)
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route("/firehose/webhook", methods=["POST"])
def receive_firehose():
data = request.json or {}
records = data.get("records", [])
for r in records:
price = extract_price_from_html(r.get("html", ""))
if price is not None:
save_to_timeseries_db({"url": r.get("url"), "price": price, "ts": r.get("timestamp")})
check_price_alert(r.get("url"), price) # 价差超阈值自动告警
return jsonify({"status": "ok", "processed": len(records)}), 200

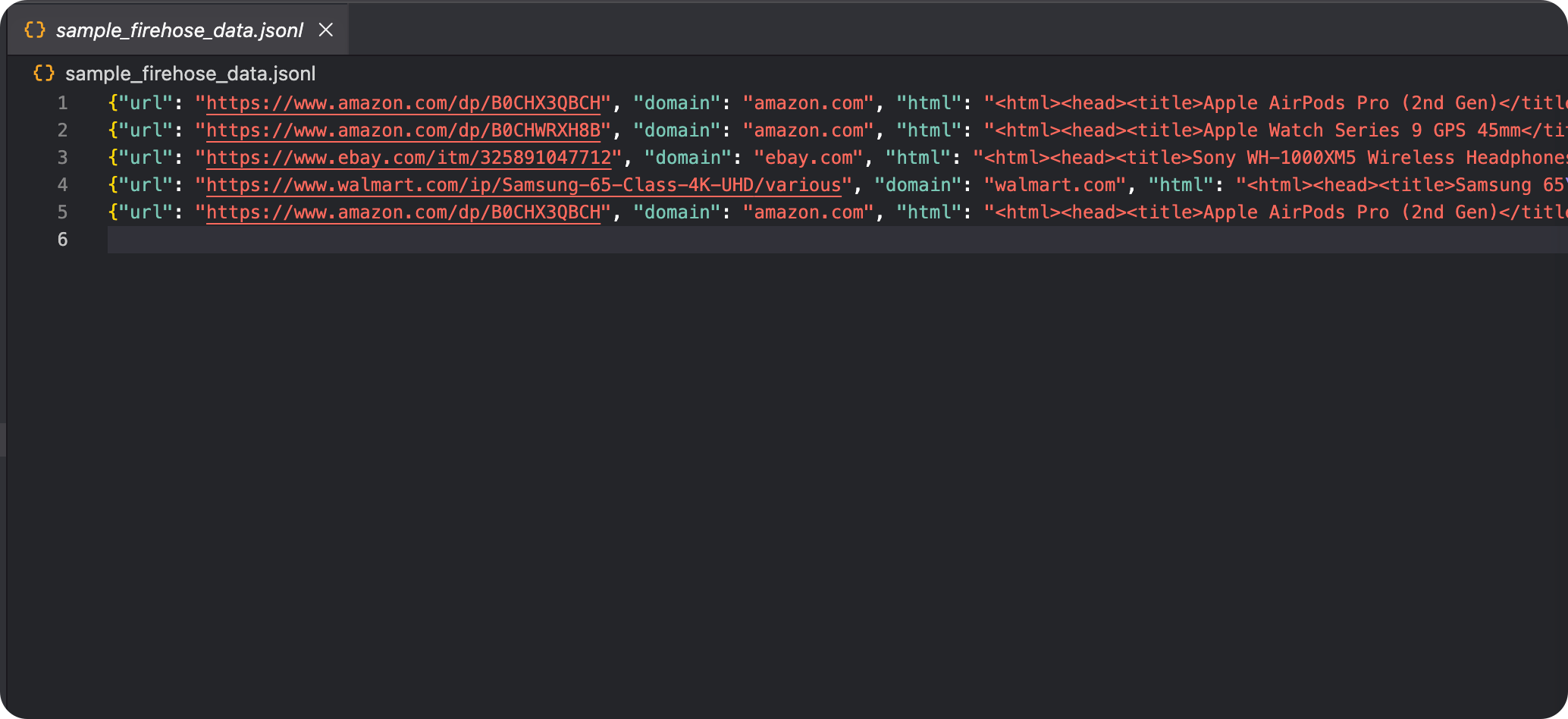
数据样本:
七、算一笔总账:贵的从来不是调用费
| 方案 | 成本结构 | 工程维护 | 数据新鲜度 |
|---|---|---|---|
| 自建爬虫集群 | 服务器 $500–$3000+/月 + 工程师时间 | 极高(封锁/维护/改版) | 取决于爬取频率 |
| Common Crawl | 免费 | 高(WARC 处理 + 质量过滤) | 月级,数据已过期 |
| Bright Data Firehose | $0.2/1K HTML,按需付费 | 极低(零爬虫维护) | 实时,采集即推送 |
真正昂贵的,是高级工程师每月 20+ 小时的维护时间、账号被封导致的数据中断、以及目标站每次改版你都要重新逆向。Firehose 把这部分最难维护的东西,外包给了成熟基础设施。
八、FAQ:关于 Firehose 的五个高频问题
Q1:Firehose 与 Web Scraper API 有什么区别?
Firehose 提供持续实时的数据流,而 Web Scraper API 用于按需获取特定网站数据。
Q2:Firehose 能替代 Common Crawl 吗?
对于需要实时数据更新的场景可以,但 Common Crawl 仍适合低成本历史数据研究。
Q3:Firehose 适合 AI 训练吗?
适合持续更新 AI 和 LLM 训练数据集,减少模型知识过时问题。
Q4:Firehose 如何交付数据?
支持 Amazon S3、Azure Blob Storage、Webhook 和流式交付。
Q5:Firehose 是否需要维护代理池?
不需要,底层抓取、反爬处理和数据交付全部由 Bright Data 负责。
九、总结 & 怎么开始
如果说"按需抓取"解决的是"我要这一页",那 Firehose 解决的是另一件事:让数据像自来水一样持续、实时地流进你的管道。 选型其实很简单——要某个页面用 Scraper API,要一批历史用 Datasets,要持续实时的数据流,就用 Firehose。
如果你的数据需求已经从"定时抓取"升级为"持续获取最新信息",不妨 申请一个测试账号,亲自体验 Firehose 的实时数据流模式是否适合你的业务场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。