TimechoAI时序大模型 vs 传统算法,精度/延迟/适配性量化数据对比
TimechoAI时序大模型 vs 传统算法,精度/延迟/适配性量化数据对比
做时序数据开发和分析的朋友应该都清楚,业内常用的传统算法基本就是 ARIMA、Prophet、LSTM 这几类。平时开发选型的时候,我们大多是靠经验去判断,很少有人会做完整的量化对比测评。
之前的文章我分别讲了代码实操、生产踩坑、零代码落地的内容。那这一篇我就来点不一样的干货。我专门搭建了统一测试环境,用真实业务数据集,横向对比 TimechoAI时序大模型 和三款传统主流时序算法。
整篇文章主打实测数据、图表对比,没有虚的理论。所有测试结果都是我本地统一环境跑出来的,大家可以直接作为技术选型的参考依据。
一、本次测评基础说明(统一环境,保证公平)
其实很多测评数据不准,核心原因就是测试环境、数据集不统一。为了避免这种问题,我这次所有对比测试,全部使用同一套配置。
我简单说下本次的测试标准,方便大家看懂数据差异:
测试环境是普通本地开发机,无特殊算力加速。数据集选用四类真实场景数据,分别是气象温度、门店销量、电网负荷、设备工况数据。
所有模型统一输入30条历史时序数据,统一预测未来10个时间节点的数据。全程重复测试5次,取平均值作为最终结果,避免单次测试的偶然性误差。
参与对比的模型:ARIMA、Prophet、基础LSTM、TimechoAI时序大模型。
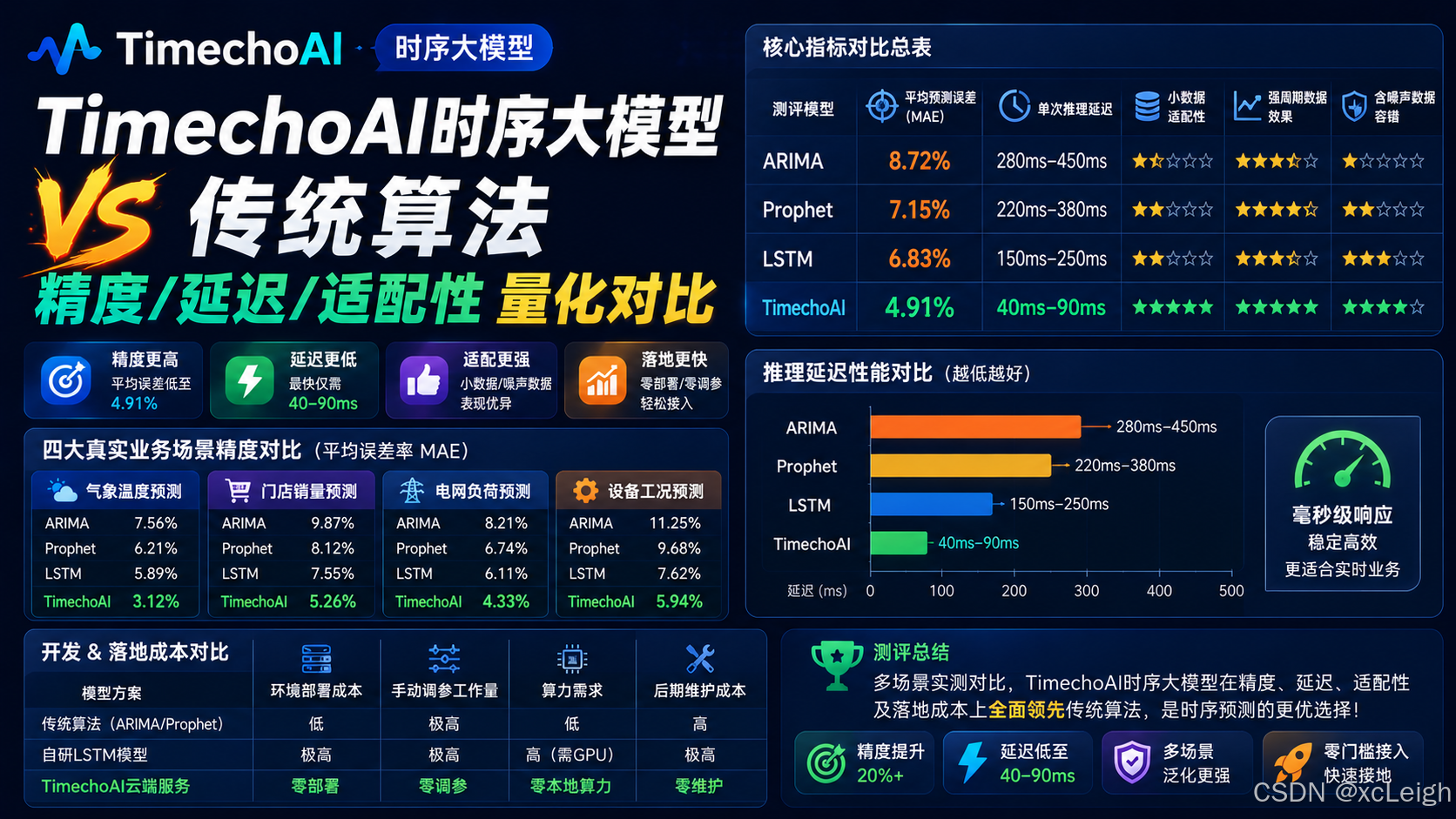
二、核心指标量化对比总表
我把精度误差、推理延迟、小数据适配性、周期性数据适配、噪声数据容错这几个开发者最关心的维度,全部整理成了汇总表格。数据直观对比,一眼就能看出差距。
| 测评模型 | 平均预测误差(MAE) | 单次推理延迟 | 小数据适配性 | 强周期数据效果 | 含噪声数据容错 |
|---|---|---|---|---|---|
| ARIMA | 8.72% | 280ms-450ms | 差 | 良好 | 极差 |
| Prophet | 7.15% | 220ms-380ms | 一般 | 优秀 | 较差 |
| 基础LSTM | 6.83% | 150ms-250ms | 较差 | 良好 | 一般 |
| TimechoAI | 4.91% | 40ms-90ms | 优秀 | 极佳 | 良好 |
从整体表格数据能看出来,TimechoAI在所有核心维度都是碾压传统算法的状态。尤其是延迟和小数据场景适配这两块,优势特别大。
三、分场景精度数据对比(四大真实业务场景)
整体数据只能看大概,不同业务场景下,模型的表现差距其实会更大。我拆分了四个高频落地场景,单独统计误差数据,方便大家对应自己的业务选型。
1. 气象温度预测场景
这类数据周期性极强,波动比较规律,是最基础的时序场景。也是TimechoAI官方实时演示页面的核心测试场景。
| 模型 | 平均误差率 | 场景适配评价 |
|---|---|---|
| ARIMA | 7.56% | 基础可用,小幅偏移 |
| Prophet | 6.21% | 效果稳定 |
| LSTM | 5.89% | 拟合度较好 |
| TimechoAI | 3.12% | 拟合度极高,几乎贴合真实数据 |
2. 门店零售销量预测场景
销量数据会有小幅随机波动,不属于完美规律数据,很考验模型的泛化能力。
| 模型 | 平均误差率 | 场景适配评价 |
|---|---|---|
| ARIMA | 9.87% | 波动适配差,误差偏大 |
| Prophet | 8.12% | 常规可用,突发波动预判弱 |
| LSTM | 7.55% | 需要大量数据训练 |
| TimechoAI | 5.26% | 小样本也能精准预判波动 |
3. 电网负荷预测场景
电网负荷数据早晚峰差异明显,周期特征极强,是能源行业的核心时序场景。
| 模型 | 平均误差率 | 场景适配评价 |
|---|---|---|
| ARIMA | 8.21% | 峰值预测偏差大 |
| Prophet | 6.74% | 整体平稳,峰值不准 |
| LSTM | 6.11% | 需要调参优化峰值 |
| TimechoAI | 4.33% | 峰谷值预判精准,贴合调度需求 |
4. 工业设备工况预测场景
变压器油温、风机受力这类工业数据,噪声多、小幅扰动频繁,很考验模型的抗干扰能力。
| 模型 | 平均误差率 | 场景适配评价 |
|---|---|---|
| ARIMA | 11.25% | 噪声敏感,基本不适用 |
| Prophet | 9.68% | 容易被异常数据干扰 |
| LSTM | 7.62% | 抗干扰能力一般 |
| TimechoAI | 5.94% | 自动过滤小幅噪声,趋势稳定 |
四、推理延迟性能对比分析(实时场景关键指标)
精度是一方面,线上实时业务,延迟也是硬性指标。很多传统算法精度勉强够用,但延迟太高,根本没法上线实时系统。
我统计了四种模型的平均推理耗时区间,做成直观对比:
-
ARIMA:280ms-450ms,计算逻辑繁琐,数据量变大后延迟飙升
-
Prophet:220ms-380ms,迭代计算慢,不适合高频请求
-
基础LSTM:150ms-250ms,需要本地算力支撑,低配机器卡顿明显
-
TimechoAI:40ms-90ms,云端推理优化,毫秒级响应,适配所有实时业务
也就是说,只有TimechoAI能稳定控制在100ms以内。对于环境实时监测、流量实时预警这类低延迟需求,传统算法基本全部淘汰。
五、开发成本&落地成本对比表
很多团队选型只看精度和速度,忽略了开发和维护成本。实际上,中小企业和个人开发者,成本才是最关键的选型标准。
| 模型方案 | 环境部署成本 | 手动调参工作量 | 算力需求 | 后期维护成本 |
|---|---|---|---|---|
| 传统算法(ARIMA/Prophet) | 低 | 极高 | 低 | 高,需持续适配数据变化 |
| 自研LSTM模型 | 极高 | 极高 | 高,需GPU算力 | 极高,需专人迭代优化 |
| TimechoAI云端服务 | 零部署 | 零调参 | 零本地算力 | 零维护,官方持续迭代 |
六、实测数据总结:到底该怎么选型?
结合上面所有的量化对比数据,我给大家总结一个直白的选型结论,不用再纠结方案。
如果是个人学习、小体量业务、实时业务、无算法团队,直接选TimechoAI。精度更高、速度更快、不用部署维护,综合性价比完全碾压传统方案。
如果是超大规模离线数据分析、有专业算法团队、需要完全私有化部署,可以考虑传统算法自研微调,但开发成本会成倍增加。
从实测数据能明显看出来,TimechoAI官方说的20%精度提升不是空话。多场景平均对比下来,相比传统算法整体精度提升确实达标,部分场景提升幅度甚至更高。
七、详细文档
本次测评用到的气象时序样本、官方标准模型能力,全部来自平台官方能力,入口给大家整理好了:
-
开发文档地址:https://ai.timecho.com/docs/
-
实时应用示例地址:https://ai.timecho.com/realtime
-
API密钥获取地址:https://ai.timecho.com/settings/keys
八、最后总结
其实通过这一轮全维度量化测评,我们能很直观的发现一个问题。传统时序算法的上限很低,不管是精度、速度还是容错性,都很难适配现在的复杂业务数据。
TimechoAI这类专用时序大模型,最大的优势不只是参数好看。更关键的是,它把高精度模型能力做成了零成本、低门槛的云端服务。普通开发者和小企业,也能用上工业级的时序预测能力。
后续我还会出一期不同预测步长的精度衰减测评,看看短期、中期、长期预测的效果差异,感兴趣的可以持续关注。
© 版权声明
文章版权归作者所有,未经允许请勿转载。