Kafka批量消费性能调优:max.poll.records参数实战指南
Kafka批量消费性能调优:max.poll.records参数实战指南
【免费下载链接】kafka Mirror of Apache Kafka
项目地址: https://gitcode.com/gh_mirrors/kafka31/kafka
你是否曾经遇到过Kafka消费者频繁触发再均衡,或者消息处理延迟突然飙升的情况?这些性能瓶颈往往与一个关键的配置参数密切相关——max.poll.records。作为控制消费者单次拉取消息数量的核心参数,它的合理设置直接决定了你的消费系统能否稳定高效运行。本文将带你从问题诊断到实战优化,系统掌握这一参数的调优技巧。
问题诊断:识别批量消费的常见瓶颈
消费者频繁再均衡的根源分析
当消费者在max.poll.interval.ms时间内未能完成当前批次消息的处理,就会触发再均衡。这种问题通常表现为:
- 日志中频繁出现"CommitFailedException"错误
- 消费组中的消费者频繁加入和退出
- 消息处理延迟周期性波动
内存压力与处理效率的平衡
过大的max.poll.records值会导致:
- JVM堆内存占用过高,可能引发GC问题
- 单次处理时间过长,影响系统响应性
- 消息积压风险增加
关键性能指标监控
要准确诊断问题,你需要关注以下指标:
-
消费延迟(Lag):通过
kafka-consumer-groups.sh工具查看 -
再均衡频率:监控
rebalance-latency-avg指标 - poll()调用间隔:观察消费者心跳机制是否正常
参数解析:深入理解max.poll.records机制
参数定义与默认值
在Kafka 3.1中,max.poll.records的默认值为500条。这个参数在源码clients/src/main/java/org/apache/kafka/clients/consumer/ConsumerConfig.java中明确定义:
public static final int DEFAULT_MAX_POLL_RECORDS = 500;
工作流程详解
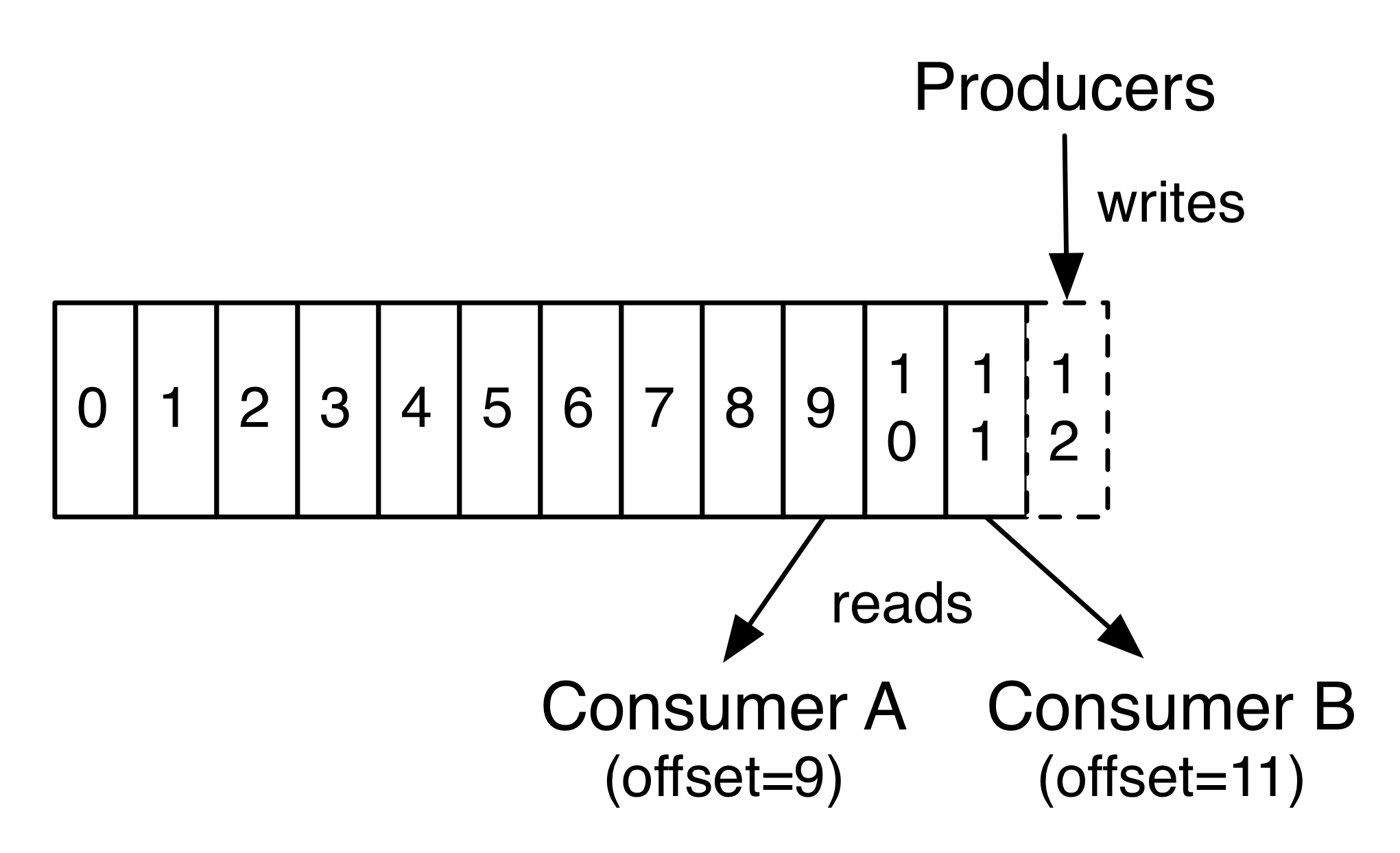
从图中可以看到,Kafka消费者通过以下步骤实现批量消费:
- 消息拉取:消费者向Kafka集群发送fetch请求
- 客户端缓存:拉取的消息在客户端缓冲区中暂存
-
poll()调用:应用程序调用
poll()方法从缓冲区获取消息 - 消息处理:业务逻辑处理获取到的消息
- 偏移量提交:处理完成后提交消费进度
与其他参数的协同作用
max.poll.records需要与以下参数配合使用:
- max.poll.interval.ms:控制两次poll()调用的最大间隔时间
- fetch.min.bytes:影响服务端返回消息的最小数据量
- fetch.max.bytes:限制单次fetch请求返回的最大数据量
场景调优:不同业务场景的参数配置策略
高频小消息场景优化
适用场景:实时日志采集、用户行为追踪、监控数据上报
特征分析:
- 消息体通常小于1KB
- 处理逻辑相对简单
- 对延迟敏感度较高
配置建议:
max.poll.records=1000
max.poll.interval.ms=300000
优化效果:减少网络往返开销,提升吞吐量30%-50%
低频大消息场景调优
适用场景:图片处理、视频转码、ETL数据转换
配置策略:
max.poll.records=200
max.poll.interval.ms=600000
流处理平台集成配置
在Kafka Streams或Connect框架中,通常需要更大的批量值:
max.poll.records=5000
内存占用评估公式
预估内存 = max.poll.records × 平均消息大小 × 安全系数(1.5-2.0)
性能验证:调优效果的量化评估
基准测试方法
要验证调优效果,建议采用以下测试流程:
- 建立基准:使用默认配置运行性能测试
- 逐步调整:每次调整参数值后重新测试
- 对比分析:记录关键指标的变化趋势
关键性能指标对比
| 配置方案 | 吞吐量(records/sec) | 处理延迟(ms) | 再均衡次数 |
|---|---|---|---|
| 默认配置 | 基准值 | 基准值 | 基准值 |
| 高频优化 | +30%-50% | 基本稳定 | 显著减少 |
| 低频优化 | +15%-25% | 降低20%-40% | 完全消除 |
日志验证要点
优化成功后,你应该观察到:
- "Commit failed for group"错误消失
- 心跳机制稳定运行
- 消费组状态保持稳定
最佳实践:生产环境配置建议
配置模板参考
通用配置模板:
# config/consumer.properties
bootstrap.servers=localhost:9092
group.id=your-consumer-group
max.poll.records=500
max.poll.interval.ms=300000
高吞吐场景:
max.poll.records=1500
max.poll.interval.ms=300000
enable.auto.commit=false
风险控制策略
- 灰度发布:先在测试环境验证配置效果
- 监控告警:设置关键指标的阈值告警
- 回滚预案:准备快速回滚到原配置的方案
分阶段优化建议
| 优化阶段 | 目标 | 参数调整范围 | 监控重点 |
|---|---|---|---|
| 第一阶段 | 稳定性验证 | ±20% | 再均衡频率、错误日志 |
| 第二阶段 | 性能提升 | ±50% | 吞吐量、延迟指标 |
| 第三阶段 | 极致优化 | 根据业务特点定制 | 系统资源使用率 |
常见陷阱与规避方法
陷阱1:盲目追求大批量导致内存溢出 规避:根据消息大小和JVM配置合理设置
陷阱2:忽略max.poll.interval.ms的联动影响 规避:确保处理时间始终小于间隔时间
通过系统化的参数调优,你可以显著提升Kafka消费者的性能和稳定性。记住,没有一劳永逸的最优配置,只有最适合你业务场景的配置方案。建议从默认值开始,结合具体业务特点逐步优化,同时建立完善的监控体系,确保系统的长期稳定运行。
【免费下载链接】kafka Mirror of Apache Kafka
项目地址: https://gitcode.com/gh_mirrors/kafka31/kafka
© 版权声明
文章版权归作者所有,未经允许请勿转载。