
AI的提示词专栏:用 Prompt 进行数据清洗,缺失值、异常值自动标注


AI的提示词专栏:用 Prompt 进行数据清洗,缺失值、异常值自动标注
本文围绕 Prompt 在数据清洗中缺失值与异常值自动标注的应用展开,先阐述 Prompt 驱动数据清洗的优势,即降低编程门槛、支持个性化规则与多格式数据适配。接着分两部分详细讲解实践:缺失值标注部分,拆解核心需求要素,提供基础标注(返回数据)与带业务逻辑标注(生成 Python 代码)示例,并给出优化技巧;异常值标注部分,明确判断维度,展示数值范围与逻辑关联类标注示例,附带避坑指南。还介绍了不同工具的 Prompt 适配方式与落地注意事项,最后设计练习题与思考题辅助巩固。整体内容兼具理论指导与实操性,助力读者掌握 Prompt 清洗数据技能。

人工智能专栏介绍
人工智能学习合集专栏是 AI 学习者的实用工具。它像一个全面的 AI 知识库,把提示词设计、AI 创作、智能绘图等多个细分领域的知识整合起来。无论你是刚接触 AI 的新手,还是有一定基础想提升的人,都能在这里找到合适的内容。从最基础的工具操作方法,到背后深层的技术原理,专栏都有讲解,还搭配了实例教程和实战案例。这些内容能帮助学习者一步步搭建完整的 AI 知识体系,让大家快速从入门进步到精通,更好地应对学习和工作中遇到的 AI 相关问题。

这个系列专栏能教会人们很多实用的 AI 技能。在提示词方面,能让人学会设计精准的提示词,用不同行业的模板高效和 AI 沟通。写作上,掌握从选题到成稿的全流程技巧,用 AI 辅助写出高质量文本。编程时,借助 AI 完成代码编写、调试等工作,提升开发速度。绘图领域,学会用 AI 生成符合需求的设计图和图表。此外,还能了解主流 AI 工具的用法,学会搭建简单智能体,掌握大模型的部署和应用开发等技能,覆盖多个场景,满足不同学习者的需求。

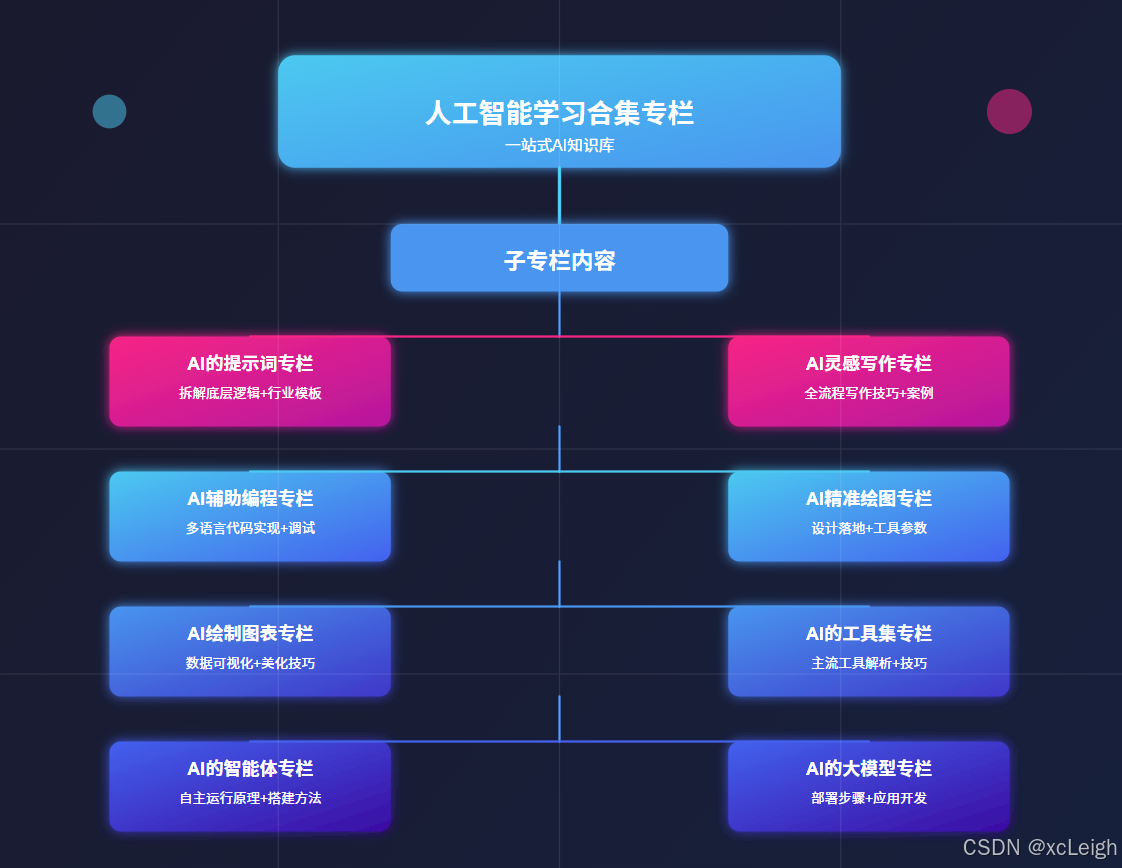
1️⃣ ⚡ 点击进入 AI 的提示词专栏,专栏拆解提示词底层逻辑,从明确指令到场景化描述,教你精准传递需求。还附带包含各行业适配模板:医疗问诊话术、电商文案指令等,附优化技巧,让 AI 输出更贴合预期,提升工作效率。
2️⃣ ⚡ 点击进入 AI 灵感写作专栏,AI 灵感写作专栏,从选题到成稿,全流程解析 AI 写作技巧。涵盖论文框架搭建、小说情节生成等,教你用提示词引导 AI 输出内容,再进行人工润色。附不同文体案例,助你解决写作卡壳,产出高质量文本。
3️⃣ ⚡ 点击进入 AI 辅助编程专栏,AI 辅助编程专栏,通过实例教你用 AI 写代码:从功能描述到调试优化。涵盖前端、后端、数据库等,语言包括HTML5、VUE、Python、Java、C# 等语言,含算法实现、Bug 修复技巧,帮开发者减少重复劳动,专注核心逻辑,提升开发速度。
4️⃣ ⚡ 点击进入 AI 精准绘图专栏,AI 精准绘图,聚焦 AI 绘图在设计场景的落地。详解如何描述风格、元素、用途,生成 logo、商标等。含 Midjourney 等工具参数设置,及修改迭代方法,帮设计新手快速出图,满足商业与个人需求。
5️⃣ ⚡ 点击进入 AI 绘制图表专栏,AI 绘制图表专栏,教你用 AI 工具将数据转化为直观图表。涵盖曲线图数据输入、流程图逻辑梳理等,附 Excel 联动、格式美化技巧,适合学生、职场人快速制作专业图表,提升数据展示效果。
6️⃣ ⚡ 点击进入 AI 的工具集专栏,AI 的工具集专栏,盘点主流 AI 工具:ChatGPT、DeepSeek、 Claude、Gemini、Copilot 等。解析各工具优势,附使用场景与技巧,帮你根据需求选工具,快速上手提升效率,覆盖办公、创作、开发等场景。
7️⃣ ⚡ 点击进入 AI 的智能体专栏,AI 的智能体专栏,解析智能体自主运行原理,包括任务拆解、环境交互等。教你用大模型搭建简单智能体,附多智能体协作案例,适合想探索 AI 自主系统的开发者入门。
8️⃣ ⚡ 点击进入 AI 的大模型专栏,AI 的大模型专栏,详解大模型部署步骤,从本地搭建到云端部署。含 API 调用教程、应用开发案例,教你将大模型集成到项目,掌握企业级 AI 应用开发技能,应对实际业务需求。
一、数据清洗与 Prompt 的关联逻辑
在数据处理全流程中,数据清洗是保障后续分析准确性的核心环节,其核心目标是解决数据中的“脏数据”问题,包括缺失值、异常值、重复值、格式不一致等。传统数据清洗依赖 Python(Pandas、NumPy)或 SQL 编写代码,需使用者具备编程基础,且针对不同数据场景需重复调整逻辑;而 Prompt 驱动的数据清洗,通过自然语言描述清洗需求,让大语言模型生成对应代码或直接输出清洗结果,大幅降低技术门槛,同时支持快速迭代调整规则。
对于缺失值和异常值标注,Prompt 的价值体现在三个方面:
- 无需手动编码,通过描述“标注缺失值并标注缺失原因(如空字符串、NA)”,模型可直接生成带标注的数据集或清洗代码;
- 支持个性化规则,例如“对‘年龄’字段中大于 150 或小于 0 的值标注为‘逻辑异常’”,模型能精准识别并执行;
- 适配多格式数据,无论是 CSV、Excel 还是数据库表,只需在 Prompt 中明确数据来源和格式,即可生成适配的清洗方案。
二、缺失值自动标注的 Prompt 设计与实践
(一)缺失值标注的核心需求拆解
在设计 Prompt 前,需明确缺失值标注的关键要素,避免模型输出模糊或不符合预期的结果。核心要素包括:
- 目标字段:需标注缺失值的具体字段(如“客户姓名”“订单金额”);
- 缺失类型定义:明确哪些情况属于缺失(如 NA、空字符串、“未知”文本、0 值是否算缺失);
- 标注形式:是在原数据中新增“缺失标注”列,还是直接用特定符号标记缺失值;
- 输出格式:需模型返回清洗后的数据(如表格、CSV 文本),还是生成可执行的清洗代码(如 Python、SQL)。
(二)不同场景的 Prompt 示例与效果
示例 1:基础缺失值标注(返回清洗后数据)
Prompt:
请处理以下 CSV 格式的客户数据,完成缺失值标注:
1. 数据内容:
客户ID,姓名,年龄,手机号,注册时间
1001,张三,28,13800138000,2024-01-05
1002,,35,,2024-02-10
1003,李四,,13900139000,
1004,王五,42,13700137000,2024-03-18
2. 标注规则:
- 识别“姓名”“年龄”“手机号”“注册时间”字段中的缺失值(空字符串视为缺失);
- 新增“缺失标注”列,用“字段名:缺失类型”格式标注(如“姓名:空字符串;手机号:空字符串”),无缺失则填“无”;
3. 输出格式:保留原数据结构,新增“缺失标注”列,以 Markdown 表格形式呈现。
预期输出:
| 客户ID | 姓名 | 年龄 | 手机号 | 注册时间 | 缺失标注 |
|---|---|---|---|---|---|
| 1001 | 张三 | 28 | 13800138000 | 2024-01-05 | 无 |
| 1002 | 35 | 2024-02-10 | 姓名:空字符串;手机号:空字符串 | ||
| 1003 | 李四 | 13900139000 | 年龄:空字符串;注册时间:空字符串 | ||
| 1004 | 王五 | 42 | 13700137000 | 2024-03-18 | 无 |
技巧点分析:
- 明确提供“数据内容”,避免模型因信息不足假设数据格式,减少误差;
- 用“字段名:缺失类型”的固定格式约束标注结果,确保输出结构化,便于后续处理;
- 指定输出格式为 Markdown 表格,提升结果可读性,若需导入工具,可替换为“CSV 文本”格式。
示例 2:带业务逻辑的缺失值标注(生成 Python 代码)
Prompt:
请生成 Python 代码,对电商订单数据进行缺失值标注,需求如下:
1. 数据来源:Excel 文件“order_data.xlsx”,数据包含“订单ID”“用户ID”“支付金额”“支付时间”“物流单号”字段;
2. 业务规则:
- “支付金额”字段中,0 值或空值视为“支付未完成”,需标注;
- “支付时间”字段为空且“支付金额”>0 时,标注为“支付时间缺失(金额已存在)”;
- “物流单号”字段为空且“支付时间”不为空时,标注为“待发货(物流单号未生成)”;
3. 代码功能:
- 读取 Excel 文件;
- 新增“缺失标注”列,按上述规则填写标注内容,多缺失情况用“;”分隔;
- 将清洗后的数据保存为新 Excel 文件“order_data_with_missing_label.xlsx”;
4. 代码要求:使用 Pandas 库,添加关键步骤注释,处理可能的文件读取异常(如文件不存在)。
预期输出:
import pandas as pd
from pandas import ExcelWriter
import os
def label_missing_values(input_path, output_path):
# 处理文件读取异常
if not os.path.exists(input_path):
raise FileNotFoundError(f"输入文件不存在:{input_path}")
# 读取Excel数据
df = pd.read_excel(input_path)
# 初始化缺失标注列
df["缺失标注"] = "无"
# 1. 标注支付金额缺失/异常(0值或空值)
payment_missing = (df["支付金额"].isna()) | (df["支付金额"] == 0)
df.loc[payment_missing, "缺失标注"] = df.loc[payment_missing, "缺失标注"].apply(
lambda x: f"{x};支付金额:支付未完成" if x != "无" else "支付金额:支付未完成"
)
# 2. 标注支付时间缺失(金额已存在)
time_missing_with_payment = (df["支付时间"].isna()) & (df["支付金额"] > 0)
df.loc[time_missing_with_payment, "缺失标注"] = df.loc[time_missing_with_payment, "缺失标注"].apply(
lambda x: f"{x};支付时间:支付时间缺失(金额已存在)" if x != "无" else "支付时间:支付时间缺失(金额已存在)"
)
# 3. 标注物流单号缺失(已支付)
logistics_missing_with_payment = (df["物流单号"].isna()) & (df["支付时间"].notna())
df.loc[logistics_missing_with_payment, "缺失标注"] = df.loc[logistics_missing_with_payment, "缺失标注"].apply(
lambda x: f"{x};物流单号:待发货(物流单号未生成)" if x != "无" else "物流单号:待发货(物流单号未生成)"
)
# 保存清洗后的数据
with ExcelWriter(output_path, engine="openpyxl") as writer:
df.to_excel(writer, index=False, sheet_name="订单数据(含缺失标注)")
print(f"数据清洗完成,已保存至:{output_path}")
return df
# 调用函数(可根据实际路径修改)
if __name__ == "__main__":
input_file = "order_data.xlsx"
output_file = "order_data_with_missing_label.xlsx"
label_missing_values(input_file, output_file)
技巧点分析:
- 融入业务逻辑(如“支付金额>0但支付时间为空”),让标注结果更贴合实际业务场景,而非单纯的技术缺失;
- 明确代码功能和要求(如异常处理、注释),确保生成的代码可直接运行,减少后续调试成本;
- 指定库(Pandas)和输出文件格式,避免模型使用不常用工具,提升兼容性。
(三)缺失值标注 Prompt 的优化技巧
- 避免模糊表述:不用“处理缺失值”,而用“识别‘年龄’字段中的 NA 值并标注为‘数据未采集’”,明确“字段+缺失类型+标注内容”;
- 提供示例参考:若数据结构复杂,可在 Prompt 中加入 1-2 行示例数据和对应的标注结果,让模型更易理解规则;
- 分场景指定输出:若需快速查看结果,用“返回 Markdown 表格”;若需批量处理,用“生成 Python/SQL 代码”,按需选择输出形式。
三、异常值自动标注的 Prompt 设计与实践
(一)异常值标注的核心维度
异常值通常偏离数据的正常分布或业务逻辑,标注前需明确判断维度,常见维度包括:
- 数值范围:如“年龄”>150 或<0、“订单金额”<0;
- 逻辑关联:如“下单时间”晚于“支付时间”、“库存数量”为负数;
- 格式规范:如“手机号”非 11 位数字、“邮箱”不含“@”;
- 统计分布:如“用户消费金额”超出均值 3 倍标准差(需在 Prompt 中明确统计规则)。
(二)不同类型异常值的 Prompt 示例
示例 1:数值范围类异常值标注(返回标注结果)
Prompt:
请分析以下用户消费数据,完成异常值标注:
1. 数据内容(CSV格式):
用户ID,月消费金额(元),消费次数,会员等级
U001,580,12,VIP3
U002,-200,8,VIP2
U003,15000,5,VIP1
U004,320,0,VIP3
U005,650,15,
2. 异常值规则:
- “月消费金额(元)”:<0 标注为“金额异常(负数)”,>10000 标注为“金额异常(超出常规范围)”;
- “消费次数”:=0 且“会员等级”为 VIP3/VIP2 标注为“次数异常(会员无消费)”;
- “会员等级”:空值标注为“等级异常(未填写)”;
3. 输出要求:
- 新增“异常标注”列,按规则标注异常类型,无异常填“无”;
- 用 Markdown 表格展示结果,并在表格下方简要说明每个异常值的判断依据。
预期输出:
| 用户ID | 月消费金额(元) | 消费次数 | 会员等级 | 异常标注 |
|---|---|---|---|---|
| U001 | 580 | 12 | VIP3 | 无 |
| U002 | -200 | 8 | VIP2 | 金额异常(负数) |
| U003 | 15000 | 5 | VIP1 | 金额异常(超出常规范围) |
| U004 | 320 | 0 | VIP3 | 次数异常(会员无消费) |
| U005 | 650 | 15 | 等级异常(未填写) |
异常值判断依据说明:
- U002 月消费金额为-200 元,符合“<0”规则,标注“金额异常(负数)”;
- U003 月消费金额为 15000 元,符合“>10000”规则,标注“金额异常(超出常规范围)”;
- U004 消费次数为 0,且会员等级为 VIP3,符合“会员无消费”规则,标注“次数异常(会员无消费)”;
- U005 会员等级为空,符合“未填写”规则,标注“等级异常(未填写)”。
技巧点分析:
- 对“消费次数=0”添加“会员等级”的关联条件,避免误判非会员用户的正常 0 消费;
- 要求输出“判断依据”,便于人工复核异常标注的准确性,尤其适用于对数据质量要求高的场景;
- 明确数值阈值(如>10000),避免模型因“常规范围”的理解差异导致标注偏差。
示例 2:逻辑关联类异常值标注(生成 SQL 代码)
Prompt:
现有电商订单表“orders”,存储在 MySQL 数据库中,表结构如下:
order_id (订单ID, 主键), user_id (用户ID), create_time (下单时间, datetime), pay_time (支付时间, datetime), product_num (商品数量), total_price (总金额, decimal(10,2))
请生成 MySQL 语句,完成以下异常值标注:
1. 异常规则:
- 逻辑异常1:pay_time < create_time(支付时间早于下单时间),标注为“时间异常:支付早于下单”;
- 逻辑异常2:product_num < 1(商品数量小于1),标注为“数量异常:商品数量无效”;
- 逻辑异常3:total_price < 0(总金额为负数),标注为“金额异常:总金额为负”;
2. SQL 要求:
- 新增“abnormal_label”字段(VARCHAR(100)),用于存储异常标注;
- 先初始化“abnormal_label”为“无异常”,再按上述规则更新异常标注(多异常用“;”分隔);
- 最后查询出所有存在异常的订单(abnormal_label != '无异常'),包含 order_id、user_id、abnormal_label 字段。
预期输出:
-- 1. 新增异常标注字段(若字段不存在)
ALTER TABLE orders
ADD COLUMN IF NOT EXISTS abnormal_label VARCHAR(100) DEFAULT '无异常';
-- 2. 初始化异常标注字段为“无异常”
UPDATE orders
SET abnormal_label = '无异常';
-- 3. 更新逻辑异常1:支付时间早于下单时间
UPDATE orders
SET abnormal_label =
CASE
WHEN abnormal_label = '无异常' THEN '时间异常:支付早于下单'
ELSE CONCAT(abnormal_label, ';时间异常:支付早于下单')
END
WHERE pay_time < create_time;
-- 4. 更新逻辑异常2:商品数量小于1
UPDATE orders
SET abnormal_label =
CASE
WHEN abnormal_label = '无异常' THEN '数量异常:商品数量无效'
ELSE CONCAT(abnormal_label, ';数量异常:商品数量无效')
END
WHERE product_num < 1;
-- 5. 更新逻辑异常3:总金额为负数
UPDATE orders
SET abnormal_label =
CASE
WHEN abnormal_label = '无异常' THEN '金额异常:总金额为负'
ELSE CONCAT(abnormal_label, ';金额异常:总金额为负')
END
WHERE total_price < 0;
-- 6. 查询所有异常订单
SELECT order_id, user_id, abnormal_label
FROM orders
WHERE abnormal_label != '无异常';
技巧点分析:
- 使用“CASE WHEN”和“CONCAT”函数,支持多异常情况的叠加标注(如同时存在“支付早于下单”和“总金额为负”);
- 先新增字段再初始化,避免字段不存在或原有数据干扰;
- 最后查询异常订单,直接定位问题数据,无需额外筛选操作,提升效率。
(三)异常值标注 Prompt 的避坑指南
- 明确统计规则:若用“标准差”“四分位距”判断异常,需在 Prompt 中写清计算方式(如“超出均值 3 倍标准差”),避免模型自行定义规则;
- 区分“异常”与“错误”:如“会员等级为空”是“异常”,但“手机号为 12 位”是“错误”,在 Prompt 中明确标注术语,保持一致性;
- 处理多异常叠加:需说明“多异常时是否合并标注”(如用“;”分隔),避免模型只标注首个异常。
四、Prompt 驱动数据清洗的工具适配与落地建议
(一)常用工具与 Prompt 适配方式
不同工具对 Prompt 的输入格式和输出支持不同,需根据工具特性调整 Prompt 内容,常见工具适配方式如下:
| 工具类型 | 适配方式 | Prompt 示例片段 |
|---|---|---|
| 大语言模型(ChatGPT、Claude) | 直接输入自然语言需求,提供数据样本或表结构,指定输出格式(表格、代码) | “请处理 CSV 数据,标注缺失值,输出 Markdown 表格” |
| 数据工具(Excel、Power BI) | 要求模型生成工具内置函数(如 Excel 公式),明确单元格范围或数据列 | “生成 Excel 公式,对 A2:A100 列的缺失值标注‘缺失’,公式结果填入 B 列” |
| 编程工具(VS Code、Jupyter) | 要求生成可执行代码(Python、SQL),指定库、函数名,处理异常情况 | “用 Pandas 生成代码,读取 CSV 并标注异常值,处理 FileNotFoundError 异常” |
(二)落地时的关键注意事项
- 小样本验证:首次使用 Prompt 清洗数据时,先用少量样本(如 10-20 行数据)测试 Prompt 效果,确认标注规则正确后再批量处理;
- 人工复核:对关键业务数据(如金融、医疗数据),Prompt 标注后需人工抽样复核,避免模型因理解偏差导致标注错误;
- 规则迭代:若发现标注遗漏或误判,需在原 Prompt 中补充规则(如“新增‘邮箱格式错误’的标注规则”),逐步优化 Prompt 精度。
五、课后练习与思考题
(一)练习题
-
现有一份“学生成绩表”,包含“学号”“姓名”“语文成绩”“数学成绩”“考试日期”字段,请设计 Prompt,标注以下异常值:
- 语文/数学成绩 <0 或 >100;
- 考试日期为“2024-02-30”(无效日期);
- 姓名为空但成绩不为空。
要求:输出 Markdown 表格(含“异常标注”列)和对应的 Python 清洗代码。
-
针对 MySQL 中的“物流表”(字段:logistics_id、order_id、send_time、receive_time、transport_distance),设计 Prompt 生成 SQL 语句,标注“receive_time < send_time(收货早于发货)”和“transport_distance <0(运输距离为负)”的异常数据,并查询出所有异常记录。
(二)思考题
- 当数据量超过 10 万行时,直接用 Prompt 让模型返回清洗后的数据会超出上下文窗口,此时应如何调整 Prompt 方案?
- 对于“用户评论”这类非结构化文本数据,如何设计 Prompt 标注“无意义评论”(如“啊啊啊”“123456”)这类异常值?
(三)参考答案与思路点拨
- 练习题 1 思路:在 Prompt 中明确“成绩范围”“无效日期”“姓名-成绩关联”三个规则,输出时同时要求表格和代码,表格用于快速验证,代码用于批量处理;Python 代码可使用 Pandas 的 to_datetime 函数判断日期有效性(errors=‘coerce’)。
- 练习题 2 思路:SQL 语句需先更新“abnormal_label”字段,再查询异常记录,注意用 CONCAT 处理多异常叠加,如“物流表”中同时存在“收货早于发货”和“运输距离为负”时,标注内容需合并。
- 思考题 1 思路:此时应让 Prompt 生成“分批次处理”的 Python 代码(如用 chunksize 分块读取数据),或生成 SQL 语句直接在数据库中处理(数据库支持海量数据操作,无需担心上下文限制)。
- 思考题 2 思路:在 Prompt 中定义“无意义评论”的特征(如“长度<3 且不含中文/英文单词”“仅含数字/符号”),让模型按特征标注,若需更高精度,可在 Prompt 中提供 2-3 个无意义评论示例(Few-Shot 提示)。
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注:本文撰写于CSDN平台,作者:xcLeigh(所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌
© 版权声明
文章版权归作者所有,未经允许请勿转载。


