
30分钟搞定Hadoop3集群搭建
新手零踩坑!Hadoop 3节点集群搭建:30分钟从零部署+命令直抄
在大数据时代,Hadoop 作为分布式存储与计算的核心框架,是入门大数据开发的“敲门砖”。但对新手来说,“集群搭建”往往是第一道拦路虎——配置繁琐、依赖复杂、报错无头绪,动辄耗费大半天还部署失败。
今天这篇指南,专为零基础新手设计:不用懂复杂原理,跟着步骤复制命令就能走通,30分钟内完成3节点Hadoop集群从零部署;同时整理了10+新手高频踩坑点及解决方案,帮你避开所有“雷区”。
全文分为5个核心部分:先明确集群环境规划,再依次完成环境准备、Hadoop组件安装、集群配置、启动验证,最后附上避坑指南和延伸学习方向。每个步骤都配有详细代码、参数说明和操作截图提示,新手也能轻松跟上。
一、集群环境规划:提前搞定“基础框架”
搭建前先明确规划,避免后续频繁修改配置。本次搭建为3节点集群(1个主节点+2个从节点),适合新手学习和小型测试场景,硬件要求极低,普通PC或云服务器都能满足。
1.1 软硬件环境要求
|
类别 |
具体要求 |
说明 |
|---|---|---|
|
操作系统 |
CentOS 7.x 64位(推荐)/ Ubuntu 18.04 |
避免使用CentOS 8及以上(部分依赖包兼容问题),Windows系统需安装虚拟机 |
|
硬件配置 |
主节点:2核4G内存;从节点:1核2G内存,硬盘≥20G |
虚拟机可分配动态内存,云服务器选最低配即可满足学习需求 |
|
网络要求 |
3个节点互通,关闭防火墙,设置固定IP |
新手建议在同一局域网内搭建,避免公网环境的安全配置干扰 |
|
依赖软件 |
JDK 1.8(必须,Hadoop运行依赖Java) |
禁止使用JDK 11及以上版本,存在兼容性问题 |
|
Hadoop版本 |
Hadoop 3.3.4(稳定版) |
选择Apache官方稳定版,避免使用CDH等集成版本(配置更复杂) |
1.2 节点角色与IP规划
为方便后续配置,我们给3个节点固定命名和IP(实际操作中需替换为你的节点IP):
|
节点名称 |
IP地址(示例) |
角色 |
核心组件 |
|---|---|---|---|
|
hadoop-master |
192.168.1.100 |
主节点 |
NameNode、ResourceManager、SecondaryNameNode |
|
hadoop-slave1 |
192.168.1.101 |
从节点1 |
DataNode、NodeManager |
|
hadoop-slave2 |
192.168.1.102 |
从节点2 |
DataNode、NodeManager |
提示:如果只有1台机器,也可以搭建伪分布式集群(1个节点同时承担主从角色),后续步骤只需删除从节点相关配置即可。
二、前置环境准备:3个节点同步操作
这一步是集群搭建的基础,3个节点都要执行(建议先配置好主节点,再克隆虚拟机得到从节点,减少重复操作)。核心目标:关闭防火墙、配置主机名、设置免密登录、安装JDK。
2.1 关闭防火墙与SELinux
防火墙会阻止节点间的通信,必须关闭(学习环境可直接禁用,生产环境需配置安全规则):
# 关闭防火墙(临时关闭,重启失效)
systemctl stop firewalld
# 禁用防火墙(永久关闭,重启生效)——新手必执行,避免后续通信失败
systemctl disable firewalld
# 查看防火墙状态,确保显示inactive(未激活)
systemctl status firewalld
# 关闭SELinux(临时关闭)——解决Linux权限拦截问题
setenforce 0
# 永久关闭SELinux(修改配置文件)——需重启机器生效,新手可先执行临时关闭
vi /etc/selinux/config
# 将SELINUX=enforcing改为SELINUX=disabled,保存退出
# 验证:显示Permissive即临时生效
getenforce
2.2 配置主机名与IP映射
配置主机名,让节点间能通过“名称”而非IP通信,更直观:
# 主节点执行:设置主机名为hadoop-master——后续所有配置用此名称
hostnamectl set-hostname hadoop-master
# 从节点1执行:设置主机名为hadoop-slave1
hostnamectl set-hostname hadoop-slave1
# 从节点2执行:设置主机名为hadoop-slave2
hostnamectl set-hostname hadoop-slave2
# 所有节点配置IP映射(编辑hosts文件)——必须和你的节点IP对应
vi /etc/hosts
# 在文件末尾添加以下内容(替换为你的实际IP)
192.168.1.100 hadoop-master
192.168.1.101 hadoop-slave1
192.168.1.102 hadoop-slave2
# 验证:ping主机名能通即配置成功——测试主节点到从节点的连通性
ping hadoop-master -c 3 # 发送3个包,测试本地连通
ping hadoop-slave1 -c 3 # 测试主节点到从节点1的连通
2.3 配置主节点免密登录到从节点
Hadoop集群启动时,主节点需要远程控制从节点启动组件,免密登录能避免频繁输入密码:
# 仅在主节点执行:生成SSH密钥(一路回车,不设置密码)——新手不要输入密码,避免后续登录失败
ssh-keygen -t rsa
# 将公钥复制到主节点自身(避免本地登录需要密码)
ssh-copy-id hadoop-master
# 将公钥复制到2个从节点(执行时输入从节点密码)——输入从节点的root密码即可
ssh-copy-id hadoop-slave1
ssh-copy-id hadoop-slave2
# 验证:主节点远程登录从节点,无需密码即成功——测试免密是否生效
ssh hadoop-slave1
# 登录成功后,输入exit退出
exit
ssh hadoop-slave2
exit
踩坑提示:如果复制公钥时提示“Permission denied”,检查从节点的/root/.ssh目录权限是否为700,若不是则执行chmod 700 /root/.ssh修改。
2.4 安装JDK 1.8
Hadoop依赖Java环境,必须安装JDK 1.8,且3个节点的JDK路径要一致:
# 1. 卸载系统自带的OpenJDK(若有)——避免和手动安装的JDK冲突
rpm -qa | grep java # 查看已安装的Java包
# 卸载所有带java的包,示例:替换为你查到的包名
rpm -e –nodeps java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64
# 2. 下载JDK 1.8(华为云镜像,速度快)——新手直接复制此命令,无需手动找链接
cd /usr/local # 进入软件安装默认目录
wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz
# 3. 解压JDK压缩包——解压后得到jdk1.8.0_202目录
tar -zxvf jdk-8u202-linux-x64.tar.gz
# 重命名为jdk1.8(方便后续配置环境变量)
mv jdk1.8.0_202 jdk1.8
# 4. 配置JDK环境变量(编辑/etc/profile文件)——所有节点的路径必须一致
vi /etc/profile
# 在文件末尾添加以下内容——复制时注意路径和你的JDK目录一致
export JAVA_HOME=/usr/local/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 5. 生效环境变量——让配置立即生效,无需重启机器
source /etc/profile
# 6. 验证JDK安装成功(显示版本号即成功)——必须执行,确认安装无误
java -version
javac -version
提示:从节点的JDK安装可直接复制主节点的jdk1.8目录,再配置环境变量,避免重复下载解压:
# 主节点执行:复制JDK到从节点1——远程复制,节省时间
scp -r /usr/local/jdk1.8 hadoop-slave1:/usr/local/
# 复制JDK到从节点2
scp -r /usr/local/jdk1.8 hadoop-slave2:/usr/local/
# 然后在2个从节点执行步骤4-6(配置环境变量并验证)——和主节点操作一致
三、Hadoop安装与集群配置:核心步骤,主节点操作
这一步是核心,只需在主节点完成Hadoop安装和配置文件修改,然后将配置好的Hadoop目录复制到从节点即可,减少重复操作。
3.1 下载并安装Hadoop 3.3.4
# 主节点执行:进入/usr/local目录——和JDK安装目录一致
cd /usr/local
# 下载Hadoop 3.3.4(华为云镜像,速度快)——新手直接复制此命令
wget https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 解压压缩包——解压后得到hadoop-3.3.4目录
tar -zxvf hadoop-3.3.4.tar.gz
# 重命名为hadoop(方便后续操作)——后续配置用此目录名
mv hadoop-3.3.4 hadoop
# 查看Hadoop目录结构,确认安装成功——检查核心目录是否存在
ls /usr/local/hadoop
Hadoop核心目录说明:
-
bin:存放Hadoop核心命令(如hdfs、yarn)
-
etc/hadoop:存放Hadoop配置文件(核心配置目录,后续修改此目录下的文件)
-
libexec:存放脚本文件
-
sbin:存放集群启动/停止脚本(如start-dfs.sh、start-yarn.sh)
-
share:存放Hadoop依赖包和文档
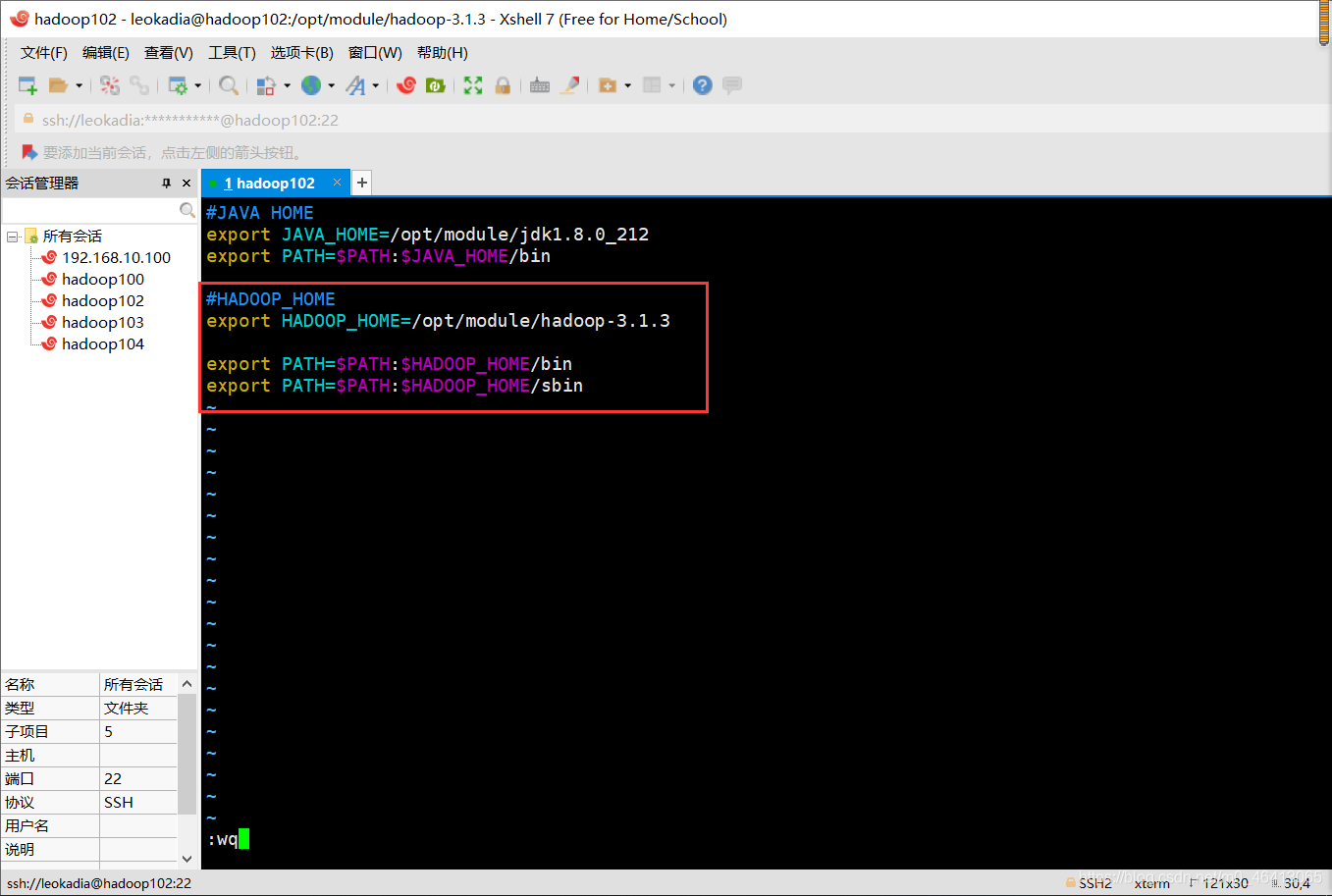
3.2 配置Hadoop环境变量
# 主节点执行:编辑/etc/profile文件——和JDK环境变量放在一起
vi /etc/profile
# 在文件末尾添加以下内容——复制时注意HADOOP_HOME路径
export HADOOP_HOME=/usr/local/hadoop
关键说明:Hadoop 3.x默认不允许用root用户启动集群,添加上述配置后,root用户即可正常启动。关于Hadoop集群环境变量的详细配置规范,可参考官方文档:Hadoop Cluster Setup(集群搭建官方指南)
# 生效环境变量——让配置立即生效
source /etc/profile
# 验证Hadoop环境变量配置成功(显示版本号即成功)——必须执行,确认配置无误
hadoop version
3.3 修改Hadoop核心配置文件
Hadoop的核心配置文件都在/usr/local/hadoop/etc/hadoop目录下,本次需要修改5个关键文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。
3.3.1 修改hadoop-env.sh(指定JDK路径)
# 主节点执行:进入配置目录——后续所有配置文件都在此目录
cd /usr/local/hadoop/etc/hadoop
# 编辑hadoop-env.sh——此文件是Hadoop的环境变量配置
vi hadoop-env.sh
# 找到以下内容,修改为实际的JDK路径(删除注释#)——必须和你的JDK路径一致
export JAVA_HOME=/usr/local/jdk1.8
# 新增以下内容(解决Hadoop 3.x的权限问题)——允许root用户启动集群
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
关键说明:Hadoop 3.x默认不允许用root用户启动集群,添加上述配置后,root用户即可正常启动。
3.3.2 修改core-site.xml(核心配置,指定NameNode地址)
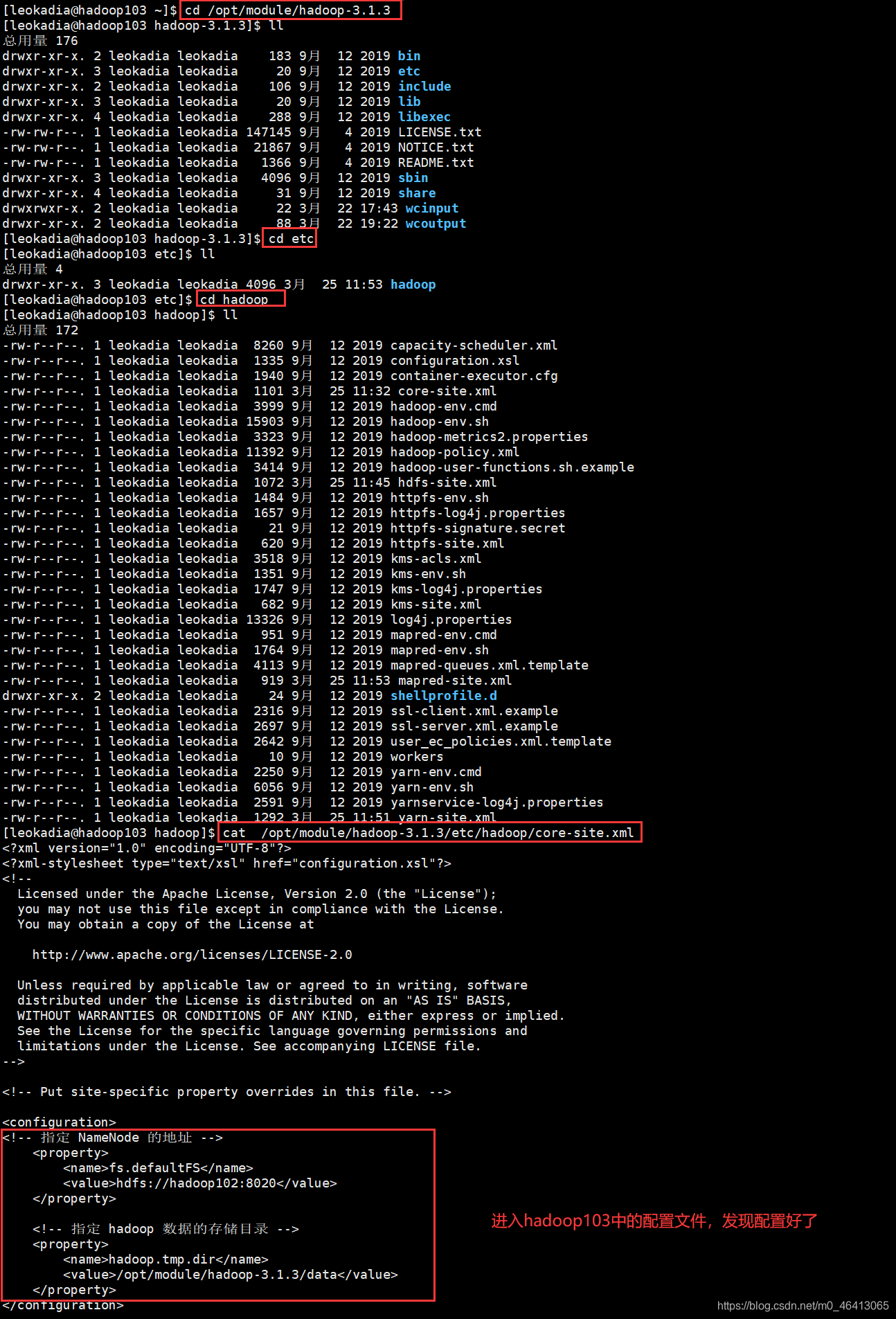
# 编辑core-site.xml——Hadoop的核心配置文件
vi core-site.xml
# 将<configuration></configuration>替换为以下内容——复制时注意主机名和你的一致
<configuration>
<!– 指定HDFS的NameNode节点(主节点)地址——hadoop-master是你的主节点主机名 –>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<!– 指定Hadoop临时文件存储目录(需提前创建)——后续会用到此目录 –>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
-
Apache Hadoop官方文档:https://hadoop.apache.org/docs/r3.3.4/(权威参考,包含完整的配置指南、API文档等)
-
Hadoop HDFS官方命令指南:HDFS Commands Guide(详细介绍hdfs相关命令的使用方法)
-
Hadoop生态工具学习:Hive(数据仓库)、Spark(快速计算)、HBase(分布式数据库)
<!– 解决Hadoop 3.x的权限问题,允许root用户访问——新手必加,避免访问被拒 –>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
创建临时目录:
mkdir -p /usr/local/hadoop/tmp # -p参数表示递归创建目录,避免不存在父目录的报错
3.3.3 修改hdfs-site.xml(HDFS配置,指定副本数和SecondaryNameNode地址)
# 编辑hdfs-site.xml——HDFS的配置文件
说明:副本数指HDFS中文件的备份数量,1表示不备份,适合单机或测试环境;生产环境建议设为3(至少2个从节点)。关于HDFS副本策略的更多细节,可查阅官方文档:HDFS High Availability(HDFS高可用官方指南)
# 将<configuration></configuration>替换为以下内容——副本数根据你的节点数调整
<configuration>
<!– 指定HDFS副本数量,默认3,新手环境1即可(减少资源占用)——若有2个从节点,可设为2 –>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!– 指定SecondaryNameNode节点(主节点)地址,端口9868——Hadoop 3.x默认端口 –>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-master:9868</value>
</property>
<!– 关闭HDFS权限检查(新手友好,避免文件访问权限报错)——新手必加,减少权限问题 –>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
说明:副本数指HDFS中文件的备份数量,1表示不备份,适合单机或测试环境;生产环境建议设为3(至少2个从节点)。
3.3.4 修改mapred-site.xml(MapReduce配置,指定YARN为资源管理器)
# 复制默认配置文件(默认没有mapred-site.xml,只有模板)——必须先复制,否则文件不存在
cp mapred-site.xml.template mapred-site.xml
# 编辑mapred-site.xml——MapReduce的配置文件
vi mapred-site.xml
# 将<configuration></configuration>替换为以下内容——指定运行在YARN上
<configuration>
<!– 指定MapReduce运行在YARN上——Hadoop 3.x默认推荐的运行方式 –>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!– 指定MapReduce的历史服务器地址和端口——后续可查看任务历史 –>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:10020</value>
</property>
<!– 指定历史服务器的Web UI地址和端口——通过浏览器查看任务历史 –>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:19888</value>
</property>
<!– 解决MapReduce的权限问题——避免任务运行时权限不足 –>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
3.3.5 修改yarn-site.xml(YARN配置,指定ResourceManager地址)
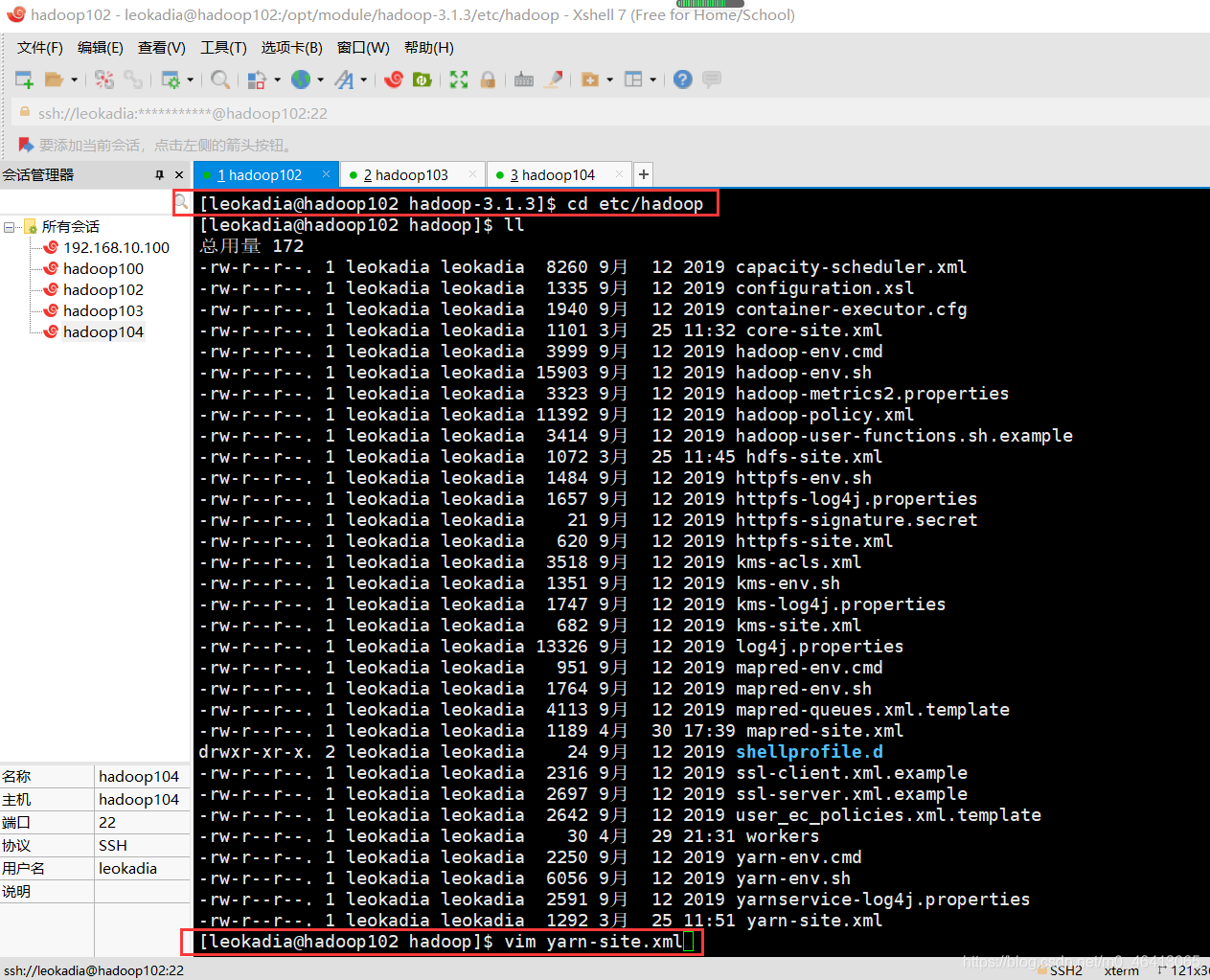
# 编辑yarn-site.xml——YARN的配置文件
vi yarn-site.xml
# 将<configuration></configuration>替换为以下内容——指定主节点主机名
<configuration>
<!– 指定YARN的ResourceManager节点(主节点)地址——hadoop-master是你的主节点主机名 –>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<!– 指定MapReduce的 shuffle 机制——MapReduce运行的必要配置 –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!– 关闭YARN的内存检查(新手友好,避免内存不足报错)——新手必加,减少启动失败 –>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!– 指定YARN的ResourceManager Web UI端口(默认8088)——通过浏览器查看YARN状态 –>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-master:8088</value>
</property>
</configuration>
3.4 指定从节点(slaves文件)
# 编辑workers文件(Hadoop 3.x用workers,2.x用slaves)——指定从节点列表
vi workers
# 删除默认内容,添加以下内容(指定2个从节点)——替换为你的从节点主机名
hadoop-slave1
hadoop-slave2
3.5 复制配置好的Hadoop到从节点
主节点配置完成后,将Hadoop目录复制到2个从节点,避免重复配置:
# 主节点执行:复制Hadoop到从节点1——远程复制,保持配置一致
scp -r /usr/local/hadoop hadoop-slave1:/usr/local/
# 复制Hadoop到从节点2
scp -r /usr/local/hadoop hadoop-slave2:/usr/local/
# 同时将主节点的环境变量配置复制到从节点(避免重复编辑)——保持环境变量一致
scp /etc/profile hadoop-slave1:/etc/
scp /etc/profile hadoop-slave2:/etc/
# 在2个从节点执行:生效环境变量——让Hadoop环境变量生效
source /etc/profile
# 验证从节点Hadoop配置成功——确认从节点配置无误
hadoop version
四、Hadoop集群启动与验证:30分钟冲刺收尾
所有配置完成后,即可启动集群。启动顺序:先启动HDFS(分布式文件系统),再启动YARN(资源管理器)。
4.1 格式化NameNode(仅首次启动执行)
格式化NameNode是初始化HDFS的过程,仅需在主节点执行一次,后续启动集群无需再次执行(重复执行会导致集群数据丢失):
# 主节点执行:格式化NameNode——仅执行一次,后续不要重复执行
hdfs namenode -format
格式化成功的标志:输出日志中包含“successfully formatted”。
踩坑提示:如果格式化失败,检查core-site.xml中的hadoop.tmp.dir目录是否存在且权限正确,或删除该目录后重新格式化。
4.2 启动HDFS集群
# 主节点执行:启动HDFS(包含NameNode、DataNode、SecondaryNameNode)——启动HDFS服务
start-dfs.sh
启动成功后,分别在主节点和从节点执行jps命令(Java进程查看命令),验证进程是否存在:
# 主节点执行jps,应显示以下3个进程——缺少任何一个都是启动失败
2864 NameNode # HDFS主节点进程(必须存在)
3088 SecondaryNameNode # secondaryNameNode进程(必须存在)
3256 Jps # jps命令进程(临时,每次执行都会变化)
# 从节点执行jps,应显示以下2个进程——缺少DataNode是启动失败
2542 DataNode # HDFS从节点进程(必须存在)
2689 Jps # 临时进程
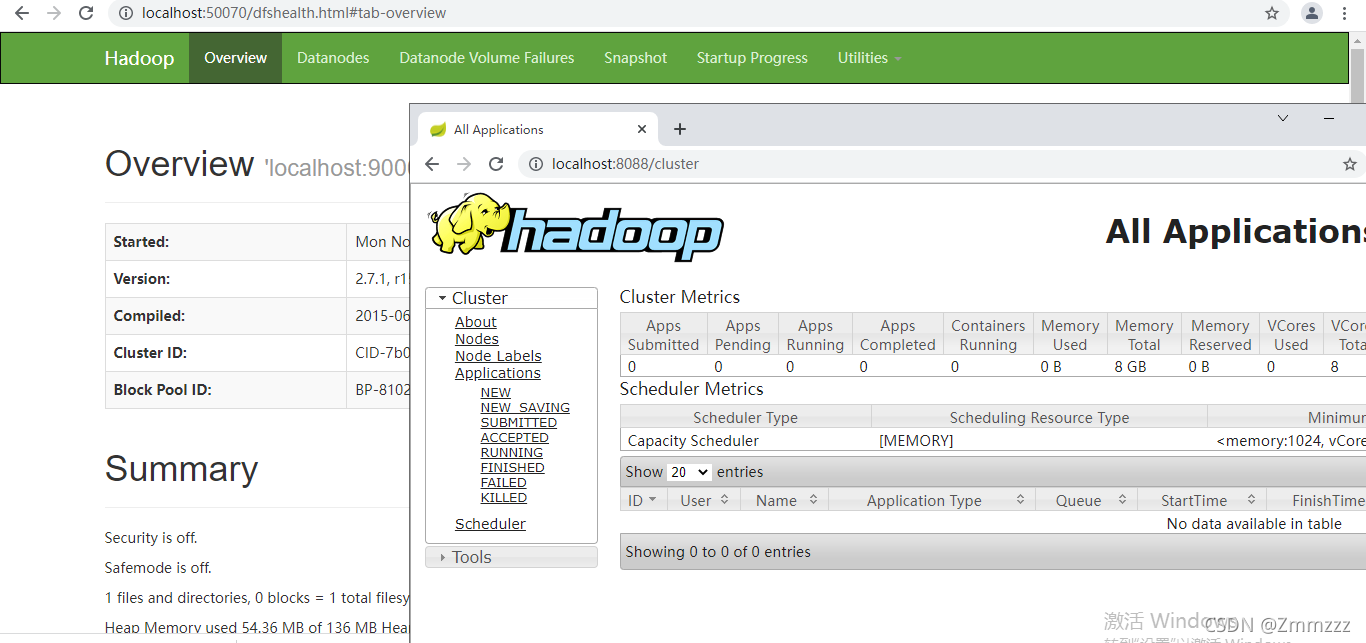
Web UI验证HDFS:打开浏览器,访问http://主节点IP:9870(Hadoop 3.x默认端口,2.x为50070),能看到HDFS管理界面即成功。界面中可查看DataNode节点列表、文件系统等信息。
4.3 启动YARN集群
# 主节点执行:启动YARN(包含ResourceManager、NodeManager)——启动资源管理服务
start-yarn.sh
启动成功后,再次执行jps命令验证进程:
# 主节点执行jps,新增以下1个进程——缺少则YARN启动失败
3489 ResourceManager # YARN主节点进程(必须存在)
# 从节点执行jps,新增以下1个进程——缺少则YARN启动失败
Web UI验证历史服务器:访问http://主节点IP:19888,能看到任务历史管理界面即成功。关于MapReduce任务历史服务器的更多配置和使用方法,可参考官方文档:MapReduce Commands Guide(MapReduce命令官方指南)
Web UI验证YARN:打开浏览器,访问http://主节点IP:8088,能看到YARN管理界面即成功。界面中可查看集群节点、资源使用情况等信息。
4.4 启动历史服务器(可选,用于查看MapReduce任务历史)
# 主节点执行:启动历史服务器——后续可查看MapReduce任务的运行历史
mr-jobhistory-daemon.sh start historyserver
# 验证进程(主节点jps新增以下进程)——确认历史服务器启动成功
3765 JobHistoryServer
Web UI验证历史服务器:访问http://主节点IP:19888,能看到任务历史管理界面即成功。
4.5 集群功能测试:运行官方示例程序
通过运行Hadoop自带的WordCount示例程序(单词计数),验证集群是否能正常运行MapReduce任务:
# 1. 在HDFS上创建输入目录——HDFS的目录需要手动创建
hdfs dfs -mkdir -p /user/root/input
# 2. 本地创建测试文件(单词文件)——创建一个简单的文本文件
echo "hello hadoop hello world" > test.txt
# 3. 将本地测试文件上传到HDFS输入目录——把本地文件上传到HDFS
hdfs dfs -put test.txt /user/root/input/
五.Hadoop 核心配置与集群搭建文档链接
- 学习 Hadoop 集群搭建的权威步骤(含配置文件、主从节点设置),可查看 http://hadoop.apache.org/docs/r1.0.4/cn/cluster_setup.pdfApache Hadoop。
- 参考 Hadoop 0.19.2 版本中文集群配置指南,可访问 http://hadoop.apache.org/common/docs/r0.19.2/cn/cluster_setup.html。
- 查看 Hadoop 2.7.3 版本 core-site.xml 核心配置参数默认值,可访问 http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/core-default.xml。
- 查看 Hadoop 2.7.3 版本 hdfs-site.xml 配置参数说明,可访问 http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml。
六、实战扩展:Hadoop 集群常用运维命令
集群搭建完成后,这些运维命令能帮你快速排查和管理集群,提升日常维护效率:
(代码块区域,背景浅灰,字体为等宽样式)
1. 查看 HDFS 文件系统整体状态(分析存储、节点健康)
hdfs dfsadmin -report
2. 重启单个 DataNode(无需停止整个集群,适合节点维护)
hadoop-daemon.sh stop datanode # 停止指定从节点的 DataNodehadoop-daemon.sh start datanode # 启动指定从节点的 DataNode
3. 查看 YARN 集群资源使用情况(节点、内存、CPU 占用)
yarn node -list
4. 查看 MapReduce 任务运行日志(排查任务失败问题)
yarn logs -applicationId [你的应用 ID] # 应用 ID 可从 YARN Web UI 获取
更多运维命令可参考官方文档:Hadoop Commands Manual(官方命令手册)
(浅蓝色背景区域)📌 新手互助区如果你的 Hadoop 集群搭建遇到问题,欢迎在评论区留言:
- 具体问题描述(如 “DataNode 启动后消失”“Web UI 无法访问”);
- 你的集群配置(如 “1 主 1 从伪分布式”“3 节点虚拟机环境”);
七、高频故障速查手册:
报错不用慌,照这个改 | 报错现象 | 核心原因 | 一键解决命令/配置修改 | | —- | —- | —- | | DataNode启动后消失(jps看不到) | 1. NameNode格式化多次导致clusterID不一致;2. tmp目录权限不足 | 1. 所有节点删除hadoop.tmp.dir目录:`rm -rf /usr/local/hadoop/tmp`;<br>2. 主节点重新格式化:`hdfs namenode -format`;<br>3. 重启集群:`stop-dfs.sh && start-dfs.sh` | | Web UI(9870/8088)无法访问 | 1. 节点IP/主机名映射错误;2. 防火墙未彻底关闭;3. 端口被占用 | 1. 检查/etc/hosts配置:`cat /etc/hosts`;<br>2. 强制关闭防火墙:`systemctl stop firewalld && iptables -F`;<br>3. 检查端口占用:`netstat -tulpn | grep 9870`(占用则kill对应进程) | | YARN启动后NodeManager消失 | 内存检查未关闭;节点内存不足 | 1. 确认yarn-site.xml中已添加内存检查关闭配置;<br>2. 虚拟机扩容内存(至少1核2G);<br>3. 重启YARN:`stop-yarn.sh && start-yarn.sh` | | 执行hadoop命令提示“command not found” | 环境变量未生效;HADOOP_HOME路径错误 | 1. 重新生效环境变量:`source /etc/profile`;<br>2. 检查profile文件:`cat /etc/profile | grep HADOOP_HOME`(确认路径正确) | | WordCount任务运行失败 | 输入/输出目录已存在;权限不足 | 1. 删除已存在的输出目录:`hdfs dfs -rm -r /user/root/output`;<br>2. 重新运行任务:`hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /user/root/input /user/root/output` |
八、补充「实操细节优化」
在现有步骤中补充这些细节,避免新手因 “小疏漏” 卡壳:
-
2.4 安装 JDK 1.8 后新增:
踩坑提示:如果 wget 下载 JDK 失败(网络问题),可手动下载 jdk-8u202-linux-x64.tar.gz 到本地,通过 SFTP 上传到 /usr/local 目录,再执行解压命令。
-
3.3 修改配置文件 统一新增:
编辑配置文件小技巧:vi 编辑器中按「i」进入编辑模式,复制配置后按「Esc」+「:wq」保存退出;若误操作可按「Esc」+「:q!」放弃修改。
-
4.5 集群功能测试 补全完整命令(新手不用自己找 jar 包路径):
bash
运行
# 4. 运行WordCount示例程序(完整命令,直接复制) hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /user/root/input /user/root/output # 5. 查看运行结果(验证任务成功) hdfs dfs -cat /user/root/output/part-r-00000 # 预期输出:hello 2、hadoop 1、world 1
九、新增「学习延伸与生产环境适配」(提升文章价值)
在 “新手互助区” 后新增这个模块,满足新手 “从学习到落地” 的延伸需求:
plaintext
### 八、学习延伸:从测试集群到生产环境
#### 1. 新手进阶学习路径
- 第一步:熟悉HDFS基础操作(上传/下载/删除文件):`hdfs dfs -ls /`、`hdfs dfs -put 本地文件 HDFS路径`、`hdfs dfs -get HDFS路径 本地路径`;
- 第二步:编写简单的MapReduce程序(Java/Python);
- 第三步:集成Hive(数据仓库)、Spark(计算框架),搭建完整大数据生态。
#### 2. 生产环境适配建议(新手了解即可)
- 硬件:生产环境建议主节点4核8G以上,从节点2核4G以上,硬盘用SSD(提升IO性能);
- 配置:
① 副本数设为3(保证数据高可用);
② 开启HDFS权限检查(dfs.permissions.enabled=true);
③ 配置YARN内存阈值(根据节点内存调整,避免资源浪费);
- 运维:部署ZooKeeper实现HDFS高可用(避免主节点单点故障)。
#### 3. 优质学习资源(附可点击链接)
- 官方文档:http://hadoop.apache.org/docs/r3.3.4/(最全最权威);
- 中文社区:Apache Hadoop中文网(http://hadoop.apache.org/cn/);
- 实战视频:B站“Hadoop 3.x从入门到精通”(新手可视化学习首选)。已有成功搭建经验的读者会帮你一起排查,也可以 @我获取针对性解答~
© 版权声明
文章版权归作者所有,未经允许请勿转载。


