【深度解析】Apache Kafka:驾驭海量数据流的引擎(附图解与代码)
个人名片
🎓作者简介:java领域优质创作者
🌐个人主页:码农阿豪
📞工作室:新空间代码工作室(提供各种软件服务)
💌个人邮箱:[2435024119@qq.com]
📱个人微信:15279484656
🌐个人导航网站:www.forff.top
💡座右铭:总有人要赢。为什么不能是我呢?
- 专栏导航:
码农阿豪系列专栏导航
面试专栏:收集了java相关高频面试题,面试实战总结🍻🎉🖥️
Spring5系列专栏:整理了Spring5重要知识点与实战演练,有案例可直接使用🚀🔧💻
Redis专栏:Redis从零到一学习分享,经验总结,案例实战💐📝💡
全栈系列专栏:海纳百川有容乃大,可能你想要的东西里面都有🤸🌱🚀
目录
-
- 【深度解析】Apache Kafka:驾驭海量数据流的引擎(附图解与代码)
-
- 一、Kafka 是什么?为什么需要它?
- 二、Kafka 核心架构深度图解
-
- 1. Topic 与 Partition(分区):实现水平扩展的基石
- 2. Partition 的复制(Replication)与 Leader/Follower 机制:保障高可用
- 3. Producer:智能的消息路由
- 4. Consumer Group:负载均衡与并行消费
- 5. ZooKeeper 的角色(过去与现在)
- 三、Java代码实战:生产与消费
-
- 1. 生产者代码(Producer)
- 2. 消费者代码(Consumer)
- 四、面试官:“请介绍一下Kafka的架构和原理”如何回答(300字范例)
【深度解析】Apache Kafka:驾驭海量数据流的引擎(附图解与代码)
在大数据与实时处理领域,Apache Kafka 已然成为分布式事件流平台的事实标准。它就像数据循环系统的“中枢神经”,负责高效、可靠地处理和传递海量数据流。无论是构建实时数据管道、流式分析还是事件驱动架构,Kafka都扮演着至关重要的角色。今天,我们就来深入剖析Kafka的架构、核心原理,并通过代码实践加深理解。
一、Kafka 是什么?为什么需要它?
在深入架构之前,我们先要理解Kafka解决的核心问题。
在传统系统中,应用程序通常通过点对点的直接调用(如REST API)进行通信。但当系统规模扩大,特别是需要处理海量实时数据时,这种方式会变得笨重、脆弱且难以扩展。例如:
- 系统耦合严重:生产者和服务消费者紧密耦合,一方的变更可能影响另一方。
- 性能瓶颈:瞬时流量高峰可能冲垮消费者服务。
- 数据丢失风险:如果消费者宕机,期间产生的数据可能丢失。
Kafka的出现完美解决了这些问题。它作为一个高吞吐、低延迟、可持久化、分布式的发布-订阅消息系统,在生产者和消费者之间扮演了一个“缓冲层”和“管道”的角色。
核心概念先行:
- Producer(生产者):向Kafka发送消息的客户端。
- Consumer(消费者):从Kafka接收和处理消息的客户端。
- Topic(主题):消息的类别或流名称,生产者向其发布消息,消费者从其订阅消息。
- Broker(代理):一个Kafka服务器实例,多个Broker组成一个Kafka集群。
二、Kafka 核心架构深度图解
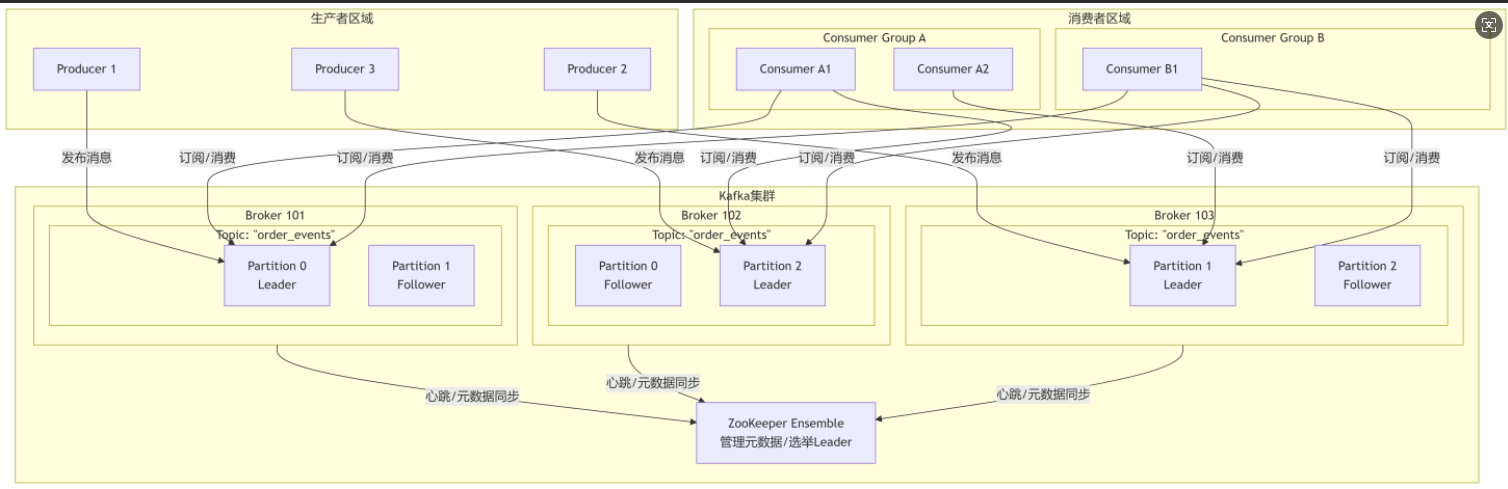
一个典型的Kafka集群架构如下图所示,让我们通过这张图来理解其核心组件是如何协同工作的:
1. Topic 与 Partition(分区):实现水平扩展的基石
Topic是逻辑上的概念,但物理上,一个Topic的消息并非存储在一个地方。为了实现高吞吐和水平扩展,Topic被分割成一个或多个Partition(分区)。
- 每个Partition都是一个有序的、不可变的消息序列。消息一旦被追加到Partition,就不能被修改或删除(基于特定策略的清理除外)。
- 每个消息在Partition中都有一个唯一的偏移量(Offset),用于标识其顺序和位置。Offset是分区级别的,而不是Topic级别的。
- 分区允许Topic的消息被并行处理。生产者可以同时向多个分区写入消息,消费者可以同时从多个分区读取消息,极大地提高了吞吐量。
图解说明:在上图中,Topic order_events 被分成了3个分区(P0, P1, P2),分布在不同Broker上。
2. Partition 的复制(Replication)与 Leader/Follower 机制:保障高可用
光有分区还不够,如果存储某个分区的Broker宕机,数据就不可用了。因此Kafka引入了多副本机制(Replication)。
- 每个Partition有多个副本(Replica),数量由复制因子(Replication Factor)决定(例如RF=3)。
- 这些副本中,只有一个被选举为 Leader,其他副本称为 Follower。
- 所有读写请求都由Leader副本处理。Follower副本的唯一任务就是从Leader副本异步地拉取数据,保持与Leader的数据同步。
- 如果Leader副本所在的Broker宕机,Kafka会从剩余的Follower副本中自动选举出一个新的Leader,继续对外提供服务,从而实现故障转移和高可用。
图解说明:图中Partition 0的Leader在Broker 101上,它的一个Follower在Broker 102上。如果Broker 101宕机,ZooKeeper会协助在Follower中选举出新Leader(例如Broker 102上的副本),服务不受影响。
3. Producer:智能的消息路由
生产者并非盲目地发送消息。它需要决定将消息发送到Topic的哪个分区。
-
默认策略:
- 指定Key:如果消息指定了Key(如用户ID),Kafka会对Key进行哈希,根据哈希值将消息路由到特定的分区。这确保了相同Key的消息总是被写入同一个分区,从而保证了消息的顺序性。
- 轮询(Round-Robin):如果未指定Key,则默认以轮询的方式均匀地分发到所有分区。
4. Consumer Group:负载均衡与并行消费
消费者是以消费者组(Consumer Group) 的形式工作的。
- 组内所有消费者共同消费一个Topic的数据。
- 一条消息只能被消费者组内的一个消费者消费。
- Kafka会将Topic的分区平均分配给组内的所有消费者。每个消费者负责消费分配给它的分区。
图解说明:
- Consumer Group A 有两个消费者(A1, A2),而Topic有3个分区。分配结果可能是:A1消费P0和P2,A2消费P1。
- Consumer Group B 只有一个消费者(B1),那么B1将消费所有3个分区的数据。这体现了Kafka的“广播”和“单播”能力:同一个消息可以被多个组消费(广播),但在一个组内只能被一个消费者消费(单播)。
5. ZooKeeper 的角色(过去与现在)
在Kafka 2.8.0版本之前,ZooKeeper是必不可少的组件,负责:
- 管理Broker和Consumer的元数据(如Topic、分区信息)。
- 领导者选举(Partition Leader Election)。
- 检测Broker和Consumer的上下线。
然而,最新版本的Kafka(自2.8.0起)通过KRAFT模式(Kafka Raft Metadata)逐步弃用了ZooKeeper,将元数据管理内置到Kafka自身,简化了部署架构,提高了稳定性和可扩展性。图中的ZK代表了传统架构。
三、Java代码实战:生产与消费
下面我们通过一个简单的Java示例,使用Kafka的Java客户端API来演示如何生产和使用消息。
首先,在Maven项目的pom.xml中添加依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.4.0</version> <!-- 请使用最新版本 -->
</dependency>
1. 生产者代码(Producer)
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class SimpleProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1. 配置生产者属性
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // Kafka集群地址
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // Key序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // Value序列化器
// 可选:设置acks,0(无确认),1(Leader确认),all/-1(所有副本确认,最强持久性)
props.put(ProducerConfig.ACKS_CONFIG, "all");
// 2. 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 3. 创建一条消息
// 参数:Topic名,Key(可选),Value(消息体)
ProducerRecord<String, String> record = new ProducerRecord<>("order_events", "user_123", "Order Created: OrderID=456");
// 4. 发送消息(异步发送,并添加回调)
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.printf("Message sent successfully! Topic: %s, Partition: %d, Offset: %d%n",
metadata.topic(), metadata.partition(), metadata.offset());
} else {
System.err.println("Failed to send message: " + exception.getMessage());
}
}
});
// 5. 关闭生产者(会等待所有发送中的请求完成)
producer.close();
}
}
2. 消费者代码(Consumer)
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class SimpleConsumer {
public static void main(String[] args) {
// 1. 配置消费者属性
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "order-processing-group"); // 指定消费者组ID
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // 如果无偏移量,从最早的消息开始消费
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 自动提交偏移量
// 2. 创建消费者实例
Consumer<String, String> consumer = new KafkaConsumer<>(props);
// 3. 订阅Topic
consumer.subscribe(Collections.singletonList("order_events"));
// 4. 持续轮询,获取消息
try {
while (true) {
// 等待最多100ms拉取一批消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Consumed message: Key = %s, Value = %s, Partition = %d, Offset = %d%n",
record.key(), record.value(), record.partition(), record.offset());
// 在这里处理业务逻辑,如解析消息、入库等
}
}
} finally {
// 5. 关闭消费者
consumer.close();
}
}
}
四、面试官:“请介绍一下Kafka的架构和原理”如何回答(300字范例)
“好的。Kafka本质上是一个分布式的、基于发布-订阅模式的消息流平台,其核心架构设计旨在实现极高的吞吐量和可靠性。
首先,从逻辑上,消息按Topic分类。物理上,每个Topic被划分为多个Partition,这是实现水平扩展和并行处理的基础。每个Partition是一个有序的消息队列,消息以Offset唯一标识。
其次,为保证高可用,每个Partition配置多个副本,遵循Leader-Follower机制。所有读写请求都由Leader处理,Follower异步从Leader拉取数据同步。若Leader宕机,系统会自动选举新Leader,实现故障自动转移。
生产者端,它可通过消息Key智能地将消息路由到特定分区,保证了相同Key消息的顺序性。消费者端,则以消费者组形式工作,组内消费者共同消费一个Topic,分区会均衡分配给组内成员,实现负载均衡。同一个消息可被多个组消费,即‘发布-订阅’,但在组内是‘竞争消费者’模式。
最后,在早期版本依赖ZooKeeper进行元数据管理和领导者选举,而新版本通过KRAFT模式已逐步去ZooKeeper化,使架构更简洁。其高性能得益于磁盘顺序读写、页缓存、零拷贝等技术。”
© 版权声明
文章版权归作者所有,未经允许请勿转载。