新手必看:从零搭建 Hadoop 完全分布式集群,手把手教你配置(含视频教程)
新手必看:从零搭建 Hadoop 完全分布式集群,手把手教你配置(含视频教程)
文章目录
- 新手必看:从零搭建 Hadoop 完全分布式集群,手把手教你配置(含视频教程)
-
- 一、完全分布式运行模式(搭建重点)
-
- 1.1.1 集群配置
-
- 1. 集群部署规划
- 2. master准备工作
- 2.1 配置修改
-
- 2.1.1 core-site.xml
- 2.1.2 hdfs-site.xml
- 2.1.3 yarn-site.xml
- 2.1.4 mapred-site.xml
- 2.1.5 hadoop-env.sh
- 2.1.6 workers
- 2.1.7 历史服务器配置
-
-
- mapred-site.xml
-
- 3.1 克隆
-
- 3.1.1 SSH无密登录配置
- 4.1 集群同时启动
-
- 1. 分组件启动集群
- (2)启动集群
- 2. 集群基本测试
- 5.1 集群启动/停止方式总结
-
- 1. 各个服务组件逐一启动/停止
- 2. 整个集群的各个模块分开启动/停止(配置ssh是前提)
- 3. 当namenode和resourcemanager配置在同一节点(常用)
- 4. 历史服务器启动
- 5. web页面端查看:
- 同步视频教程链接
一、完全分布式运行模式(搭建重点)
分析:
1)集群中有3台机器(关闭防火墙、设置静态ip、主机名称、 JDK、Hadoop)master,slave1,slave2
2)配置一个节点,再把配置好的节点克隆2台
3)单点启动
4)配置ssh(免密登录)
5)集群同时启动并测试集群
1.1.1 集群配置
1. 集群部署规划
| Master(192.168.11.10) | slave1(192.168.11.11) | slave2(192.168.11.12) | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | SecondaryNameNodeDataNode |
| YARN | ResourceManagerNodeManager | NodeManager | NodeManager |
2. master准备工作
(1)新建虚拟机(安装最小化版本) 虚拟机命名为master
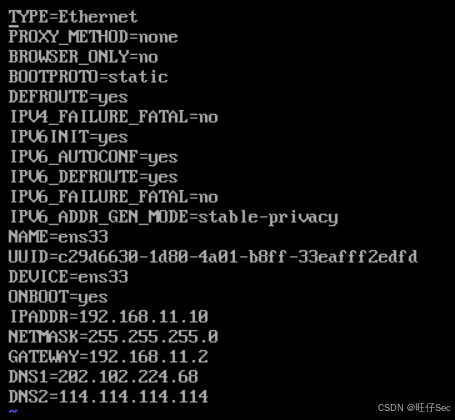
(2)修改虚拟机的静态IP,配置IP地址,连接xshell
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
[root@localhost ~]# systemctl restart network
[root@localhost ~]# ip a
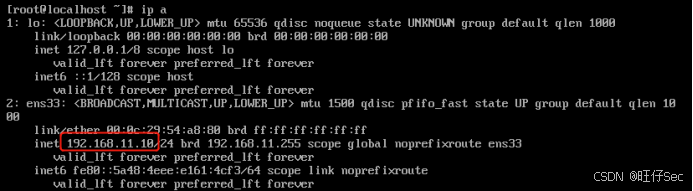
网络配置成功后,连接xshell
(3)修改主机名
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# bash
(4)关闭防火墙
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
(5)修改/etc/hosts文件,添加IP和主机名的一个映射关系
[root@master ~]# vi /etc/hosts
192.168.11.10 master
192.168.11.11 slave1
192.168.11.12 slave2
(6)在/opt目录下创建文件夹
[root@master ~]# cd /opt
[root@master opt]# mkdir module
[root@master opt]# mkdir software
(7)安装jdk和hadoop
用xftp工具将JDK和hadoop安装包导入到opt目录下面的software文件夹下面
回到xshell上解压安装包
[root@master opt]# cd software
[root@master software]# tar -zvxf jdk-8u231-linux-x64.tar.gz -C /opt/module/
[root@master software]# tar -zvxf hadoop-3.1.3.tar.gz -C /opt/module/
[root@master software]# cd ../module
[root@master module]# mv jdk1.8.0_231 java
[root@master module]# mv hadoop-3.1.3 hadoop
配置环境变量
[root@master module]# vi /etc/profile
在profile文件末尾添加java和hadoop路径
#JAVA_HOME
export JAVA_HOME=/opt/module/java
export PATH=$JAVA_HOME/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
让修改后的文件生效
[root@master module]# source /etc/profile
验证测试
[root@master module]# java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
[root@master module]$ hadoop version
Hadoop 3.1.3
2.1 配置修改
2.1.1 core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
</configuration>
2.1.2 hdfs-site.xml
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
2.1.3 yarn-site.xml
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 环境变量的继承 --> ·
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,
CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
2.1.4 mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.1.5 hadoop-env.sh
export JAVA_HOME=/opt/module/java
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.1.6 workers
master
slave1
slave2
2.1.7 历史服务器配置
mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
3.1 克隆
master再克隆两台虚拟机slave1,slave2
将master关机后克隆。 重新生成mac地址,修改静态IP,主机名,查看防火墙是否已经关闭,/etc/hosts配置是否齐全
slave1节点:
[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
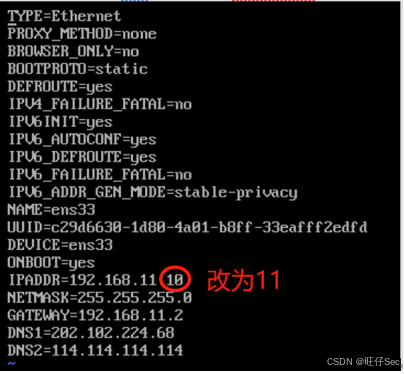
[root@master ~]# systemctl restart network
[root@master ~]# hostnamectl set-hostname slave1
[root@master ~]# bash
[root@slave1 ~]# systemctl status firewalld
slave2节点:
[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
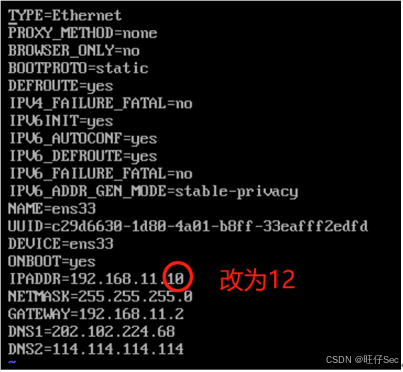
[root@master ~]# systemctl restart network
[root@master ~]# hostnamectl set-hostname slave2
[root@master ~]# bash
[root@slave2 ~]# systemctl status firewalld
3.1.1 SSH无密登录配置
三台虚拟机都已经可以正常工作,但是仍然存在问题:(1)实际工作中,服务器被放置在机房,同时受到地域和管理的限制,通常不会直接在机器上操作,而是通过远程连接服务器进行操作;(2)一个节点一个节点启动非常繁琐,当节点数有1000个时,根本无法一个一个操作,因此需要主节点代劳,主节点去连接各个从节点来一次启动,因而主节点就需要知道从节点的用户名和密码,以免每次远程访问还需要不断输入用户名和密码。
为了解决这些问题,可以用过配置SSH服务来实现远程登录和免密登录。
SSH是Secure Shell的缩写,它是建立在应用层基础上的安全协议。SSH是目前较为可靠,专为远程登录会话和其他网络服务提供安全性的协议。
SSH由客户端软件和服务端软件组成。
- 配置ssh
(1)基本语法
ssh另一台电脑的ip地址 - 无密钥配置
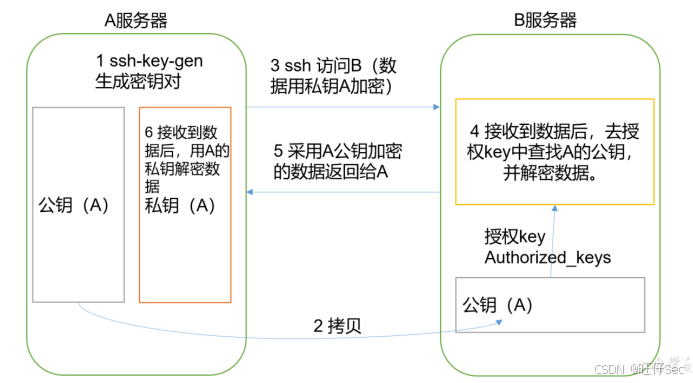
(1)免密登录原理,如图所示

免密登陆原理
(2)生成公钥和私钥:
[root@master ~]# ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[root@master ~]# cd .ssh
[root@master .ssh]# ssh-copy-id master
[root@master .ssh]# ssh-copy-id slave1
[root@master .ssh]# ssh-copy-id slave2
slave1节点:
[root@slave1 ~]# ssh-keygen -t rsa
[root@slave1 ~]# cd .ssh
[root@slave1 .ssh]# ssh-copy-id master
[root@slave1 .ssh]# ssh-copy-id slave1
[root@slave1 .ssh]# ssh-copy-id slave2
slave2节点:
[root@slave2 ~]# ssh-keygen -t rsa
[root@slave2 ~]# cd .ssh
[root@slave2 .ssh]# ssh-copy-id master
[root@slave2 .ssh]# ssh-copy-id slave1
[root@slave2 .ssh]# ssh-copy-id slave2
- .ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过得无密登录服务器公钥 |
4.1 集群同时启动
1. 分组件启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和logs数据)
[root@master hadoop]# hdfs namenode -format
(2)启动集群
[root@master hadoop]# start-all.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在配置了ResouceManager所在的机器上启动YARN。
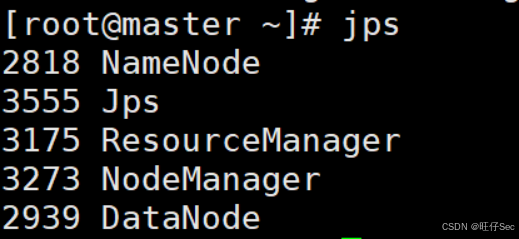
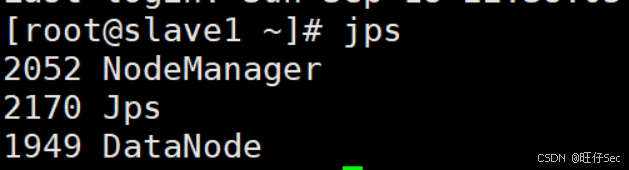
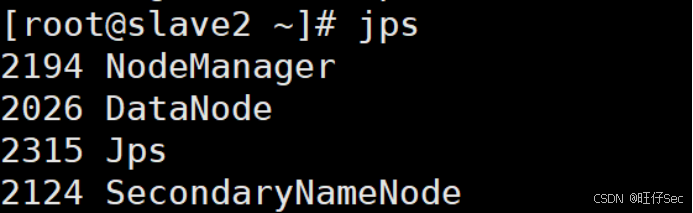
(3)Web端查看集群(namenode)
浏览器中输入:192.168.11.10:9870
2. 集群基本测试
(1)上传文件到集群
上传小文件
[root@master hadoop]# cd ../../
[root@master hadoop]# pwd
/opt/module/hadoop
[root@master hadoop]# mkdir wcinput
[root@master hadoop]# cd wcinput
[root@master wcinput]# vi wc.input
hadoop hello
fandi hello
hdfs hello
yarn hello
mapreduce hello
[root@master wcinput]# cd ../
[root@master hadoop]# hdfs dfs -mkdir -p /user/input
[root@master hadoop]# hdfs dfs -put wcinput/wc.input /user/input
上传大文件
[root@master hadoop]# hdfs dfs -put /opt/software/hadoop-2.7.3.tar.gz /user/input
(2)用MapReduce计算wordcount案例
[root@master hadoop]# hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/input/wc.input /user/output
[root@master hadoop]# hdfs dfs -cat /user/output/*
(3)最后关机之前记得关闭集群
master节点:
[root@master hadoop]# stop-all.sh
5.1 集群启动/停止方式总结
1. 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2. 整个集群的各个模块分开启动/停止(配置ssh是前提)
(1)整体启动/停止HDFS(在namenode上)
启动:start-dfs.sh / 停止:stop-dfs.sh
(2)整体启动/停止YARN(在resourcemanager上)
启动:start-yarn.sh / 停止:stop-yarn.sh
3. 当namenode和resourcemanager配置在同一节点(常用)
这种情况可以整体启动/停止集群
启动:start-all.sh
停止:stop-all.sh
4. 历史服务器启动
mapred –daemon start historyserver
5. web页面端查看:
hadoop(namenode): 192.168.11.50:9870
yarn: 192.168.11.50:8088
历史服务器: 192.168.11.50:19888
secondarynamenode: 192.168.11.52:9868
同步视频教程链接
十五分钟带你搭建Hadoop分布式集群(保姆级教程)
© 版权声明
文章版权归作者所有,未经允许请勿转载。


