




Hadoop 3.1.3 完全分布式部署超详细教程(附避坑指南)
在大数据技术栈中,Hadoop 完全分布式集群是企业级应用的核心基础,它通过多节点协同实现海量数据的存储(HDFS)与计算(MapReduce/YARN)。相比于伪分布式,完全分布式集群能充分利用多服务器资源,具备更高的可靠性、扩展性和处理性能。本文基于 Hadoop 3.1.3 版本,详细拆解从环境准备到集群验证的完整部署流程,包含关键配置解析、跨节点同步技巧及常见问题排查,适合大数据初学者快速搭建生产级基础集群。
一、部署前准备
1.1 环境说明
- 操作系统:CentOS 7.x(64 位,推荐最小化安装)
- 节点规划:3 台服务器(集群规模可根据需求扩展,本文以 3 节点为例

- 依赖软件:JDK 1.8(Hadoop 3.x 需 JDK 1.8 及以上,本文使用 jdk1.8.0_221)
- 工具:MobaXterm(文件上传、远程连接)
- 安装包:hadoop-3.1.3.tar.gz(官网下载地址)
1.2 前置配置(必做)
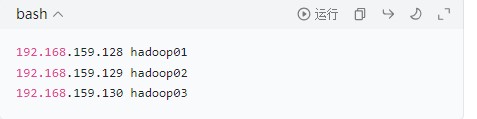
-
主机名与 IP 映射配置:在 3 台节点的
/etc/hosts文件中添加以下内容,实现主机名解析(避免依赖 DNS):

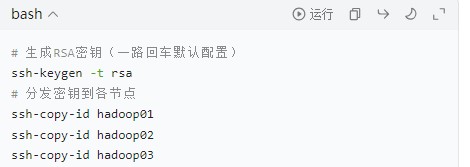
- SSH 免密登录配置:主节点 hadoop01 需免密登录到所有从节点(包括自身),执行以下命令生成密钥并分发:
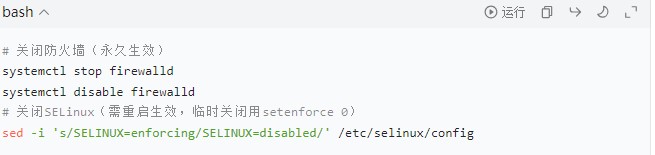
- 关闭防火墙与 SELinux:避免端口拦截(生产环境可配置白名单,测试环境直接关闭):
- 安装 JDK 并配置环境变量:Hadoop 依赖 Java 环境,需在 3 台节点统一安装 JDK(本文略去 JDK 安装步骤,重点关注 Hadoop 配置)。
二、Hadoop 核心部署步骤
2.1 上传并解压安装包
(2)YARN Web 界面(端口 8088)
在 Windows 浏览器中输入:http://192.168.159.128:8088(主节点 IP+8088 端口)
3.3 功能测试(上传 / 下载文件)
通过 HDFS 命令行测试数据读写功能,验证集群可用性:
(1)上传文件到 HDFS
创建测试文件,上传至 HDFS 根目录:
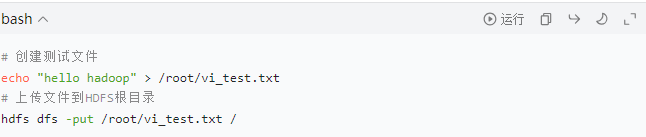
若未报错,说明文件上传成功。
- 用 MobaXterm 连接 hadoop01 节点,将
hadoop-3.1.3.tar.gz上传至/usr/local/目录。 - 解压安装包并简化目录名(可选,方便后续操作):
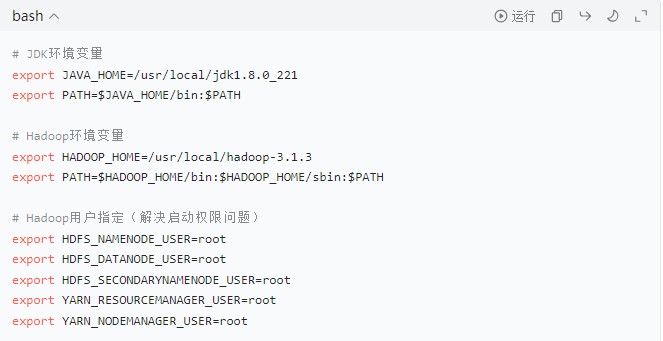
- 配置系统环境变量:
- 编辑
/etc/profile文件,添加 Hadoop 环境变量(3 台节点需保持一致,后续将通过 scp 同步):
- 添加以下内容(注意 JDK 路径需与实际安装路径一致):
- # JDK环境变量 export JAVA_HOME=/usr/local/jdk1.8.0_221 export PATH=$JAVA_HOME/bin:$PATH # Hadoop环境变量 export HADOOP_HOME=/usr/local/hadoop-3.1.3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH # Hadoop用户指定(解决启动权限问题) export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
- 生效环境变量:
- source /etc/profile
2.3 修改 Hadoop 核心配置文件
Hadoop 配置文件位于
$HADOOP_HOME/etc/hadoop/目录,需修改以下 6 个关键文件(所有配置项涉及主机名的,需替换为实际节点名称)。 -
(1)hadoop-env.sh(环境变量配置)
指定 JDK 路径,避免 Hadoop 无法找到 Java 环境,添加 / 修改以下内容:
-
vi hadoop-env.sh
-
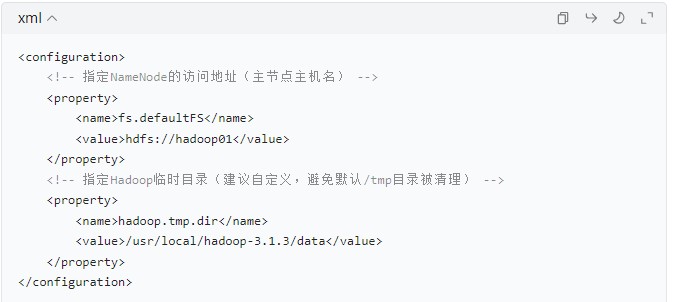
(2)core-site.xml(核心配置)
定义 HDFS 的 NameNode 地址和临时目录,是 Hadoop 集群的核心配置:
-
-
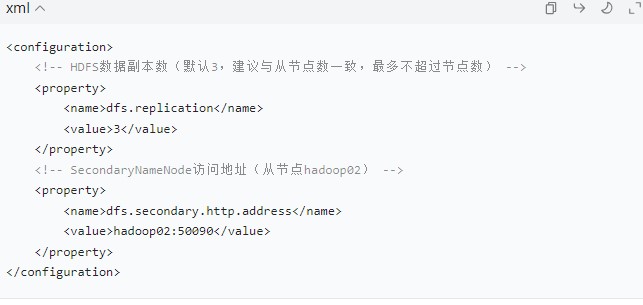
(3)hdfs-site.xml(HDFS 配置)
配置 HDFS 副本数、SecondaryNameNode 地址等:
-
-
关键说明:SecondaryNameNode 用于辅助 NameNode 管理元数据,并非备份节点,建议部署在非主节点。
-
(4)yarn-site.xml(YARN 配置)
-
配置 YARN 的 ResourceManager 地址、NodeManager 辅助服务等:
-
-
(5)mapred-site.xml(MapReduce 配置)
-
指定 MapReduce 运行在 YARN 上,配置相关环境变量:
-
-
(6)workers(从节点列表)
指定 Hadoop 集群的从节点(DataNode 和 NodeManager 将在这些节点启动):
-
vi workers
-
删除默认内容,添加以下节点名称(每行一个):
-
hadoop01 hadoop02 hadoop03
-
注意:Hadoop 3.x 中该文件名为
workers,Hadoop 2.x 中为slaves,避免混淆。 -
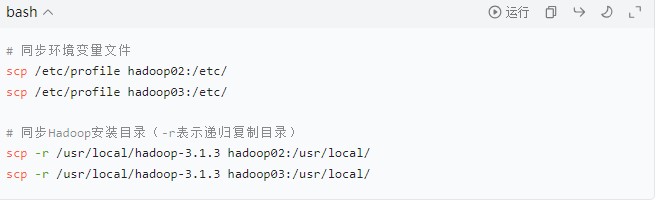
2.4 同步配置到所有从节点
hadoop01 节点的配置文件修改完成后,通过
scp命令同步到 hadoop02 和 hadoop03,避免重复配置: -
同步完成后,需在 hadoop02 和 hadoop03 节点执行
source /etc/profile生效环境变量。 -
2.5 格式化 NameNode(关键步骤)
首次启动 Hadoop 集群前,需在主节点 hadoop01 执行 NameNode 格式化(仅执行一次!重复格式化会导致集群数据丢失):
-
hdfs namenode -format
-
格式化成功标志
日志中出现以下信息,说明格式化成功:
-
INFO common.Storage: Storage directory /usr/local/hadoop-3.1.3/data/dfs/name has been successfully formatted.
-
失败处理
若格式化失败,需先删除
hadoop.tmp.dir指定的目录(本文为/usr/local/hadoop-3.1.3/data),再重新执行格式化命令: -
rm -rf /usr/local/hadoop-3.1.3/data hdfs namenode -format
-
2.6 启动 Hadoop 集群
在主节点 hadoop01 执行启动命令(Hadoop 3.x 推荐使用
start-all.sh一键启动,底层会调用start-dfs.sh和start-yarn.sh): -
start-all.sh
-
启动过程中会显示各节点的进程启动信息,若提示
Are you sure you want to continue connecting (yes/no)?,输入yes即可(SSH 免密配置成功后不会重复提示)。 -
三、集群验证(全方位确认集群可用性)
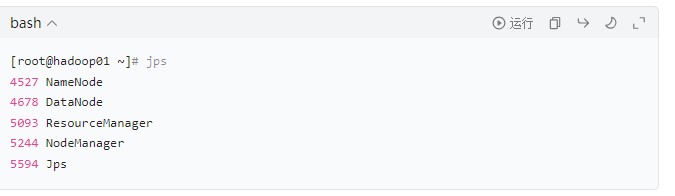
3.1 查看各节点进程(jps 命令)
分别在 3 台节点执行
jps命令,查看进程是否符合预期: -
hadoop01(主节点):应包含
NameNode、ResourceManager、DataNode、NodeManager -
hadoop02(从节点):应包含
SecondaryNameNode、DataNode、NodeManager -
hadoop03(从节点):应包含
DataNode、NodeManager -
示例输出(hadoop01)
-
注意:若某节点缺少进程(如 DataNode 未启动),需查看
$HADOOP_HOME/logs/目录下的日志文件排查原因。3.2 Web 界面验证
Hadoop 提供了可视化 Web 界面,可直观查看集群状态(需关闭防火墙或开放对应端口)。
(1)HDFS Web 界面(端口 9870)
在 Windows 浏览器中输入:
http://192.168.159.128:9870(主节点 IP+9870 端口) - 进入
Datanodes标签页,应显示 3 个 DataNode 节点,状态为In service,说明 HDFS 存储集群正常。 - 可查看集群存储容量、数据块分布等信息。
- 进入
Nodes标签页,应显示 3 个 NodeManager 节点,状态为RUNNING,说明 YARN 计算集群正常。 - 可查看集群资源使用情况、运行中的任务等。
(2)从 HDFS 读取文件
读取 HDFS 上的测试文件,验证数据可访问:
hdfs dfs -cat /vi_test.txt
预期输出:hello hadoop,说明 HDFS 读写功能正常。
四、常见问题与避坑指南
4.1 启动时提示 “hdfs: 未找到命令”
- 原因:环境变量未生效或配置错误。
- 解决:执行
source /etc/profile生效环境变量;检查/etc/profile中 HADOOP_HOME 路径是否正确。
4.2 DataNode 未启动(jps 看不到 DataNode 进程)
- 原因 1:重复格式化 NameNode,导致 DataNode 的 clusterID 与 NameNode 不一致。解决:删除所有节点的
hadoop.tmp.dir目录(本文为/usr/local/hadoop-3.1.3/data),重新在主节点执行hdfs namenode -format,再启动集群。 - 原因 2:workers 文件配置错误(如节点名称拼写错误)。解决:检查
workers文件,确保节点名称与/etc/hosts一致。
4.3 Web 界面无法访问
- 原因 1:防火墙未关闭,端口被拦截。解决:执行
systemctl stop firewalld关闭防火墙。 - 原因 2:IP 地址或端口错误(Hadoop 3.x 的 HDFS 端口为 9870,Hadoop 2.x 为 50070)。解决:确认 Hadoop 版本,使用对应端口访问。
4.4 YARN 任务运行失败(提示内存不足)
- 原因:YARN 默认虚拟内存限制过低。解决:在
yarn-site.xml中调整yarn.nodemanager.vmem-pmem-ratio参数(本文设置为 4.5),重启 YARN 集群(stop-yarn.sh+start-yarn.sh)。
五、总结
Hadoop 完全分布式部署的核心在于 “配置一致性” 和 “权限正确性”:首先需确保各节点的环境变量、配置文件完全同步;其次通过指定 Hadoop 运行用户避免权限问题;最后通过进程查看、Web 界面验证、功能测试三层校验集群可用性。
本文基于 Hadoop 3.1.3 版本,覆盖了从环境准备到集群验证的全流程,适用于初学者快速搭建测试集群或小型生产集群。实际生产环境中,还需考虑集群高可用(HA)、数据备份、资源调度优化等进阶配置,后续将逐步分享相关内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。