
【OpenAI 把 AI 玩明白了】:自主推理 + 动态知识图谱,这 4 个技术突破要颠覆行业

🎁个人主页:User_芊芊君子
🎉欢迎大家点赞👍评论📝收藏⭐文章
🔍系列专栏:AI


文章目录:
- 一、OpenAI 发展历程与核心定位
- 二、核心技术架构:从模型迭代到自主推理
-
- 2.1 双核技术 leadership 与研发架构
- 2.2 关键技术创新点(通俗解读)
-
- (1)长时推理与工具自主使用:让AI像人一样“找帮手”
- (2)多模态联合训练与理解(2)多模态联合训练与理解:打破文本、图像、语音的“沟通壁垒”
- (3)动态知识图谱重构(3)动态知识图谱重构:让AI拥有“跨学科联想能力”
- (4)渐进式安全对齐框架(4)渐进式安全对齐框架:给AI装上“安全防火墙”
- 三、OpenAI 主流模型能力对比(2025最新)
- 四、OpenAI API 实战:从环境搭建到核心调用
-
- 4.1 环境准备:API Key 配置
-
- (1)macOS/Linux 配置
- (2)Windows 配置(PowerShell)
- 4.2 Python 环境 API 调用实战
-
- 步骤 1:安装官方 SDK
- 步骤 2:基础文本生成示例(o3 模型)
- 步骤 3:多模态推理示例(解析图像中的数学公式)
- 4.3 JavaScript 环境 API 调用实战
-
- 步骤 1:安装 SDK
- 步骤 2:文本生成示例
- 五、OpenAI 创新应用案例(2025最新)
-
-
- 5.1 科学研究:GPT-5 助力分子克隆实验效率提升 79 倍5.1 科学研究:GPT-5让生物实验效率提升79倍,AI成“科研助手”
- 5.2 编程与数学:o3 模型实现 IMO 金牌水平推理5.2 编程与数学:o3模型达到IMO金牌水平,复杂问题能“分步解”
- 5.3 多模态交互:o4-mini 支持低质量图像精准解析5.3 多模态交互:o4-mini能“看懂”模糊图像,适配真实工作场景
-
- 六、总结与未来展望
【前言】
2025年,OpenAI 相继推出 o3/o4-mini 推理模型与 GPT-5,在多模态理解、自主工具使用及科学研究辅助等领域实现突破性进展,再次定义了生成式AI的技术边界。本文将从 OpenAI 的发展脉络出发,深度剖析其核心技术架构、主流模型能力对比,结合实战代码演示API调用方法,并解读其在科研、工程等领域的创新应用,为开发者提供全面的技术参考。
一、OpenAI 发展历程与核心定位

OpenAI 成立于2015年,由 Sam Altman、Elon Musk 等联合创办,最初以非营利性研究实验室形式存在,核心使命是「开发惠及全人类的通用人工智能(AGI)」。历经十年发展,其组织形态与技术方向不断演进,关键里程碑如下:
-
2015-2018年(非营利探索期):聚焦基础AI研究,开展强化学习、生成模型等方向的实验,为后续技术突破奠定基础;
-
2019-2021年(商业化转型期):转型为「非营利+营利」混合架构,推出 GPT-2、Codex 等模型,开始探索API商业化路径;
-
2022-2023年(行业引爆期):ChatGPT 正式发布,凭借自然的对话能力引爆全球AI热潮,随后推出 DALL·E 3(图像生成)、Whisper(语音转写)等多模态产品;
-
2024-2025年(技术攻坚期):完成 leadership 迭代,Mark Chen 与 Jakub Pachocki 主导技术架构重构,推出 o1/o3/o4-mini 推理模型,实现自主工具使用能力;GPT-5 在科学实验优化等领域展现出强大潜力,推动AI从「工具」向「研究伙伴」转型。
当前,OpenAI 已成为全球AGI研究的核心力量,其产品体系覆盖文本生成、多模态理解、代码开发、科学计算等多个领域,通过 API 向全球开发者开放核心能力,构建了庞大的AI应用生态。
二、核心技术架构:从模型迭代到自主推理
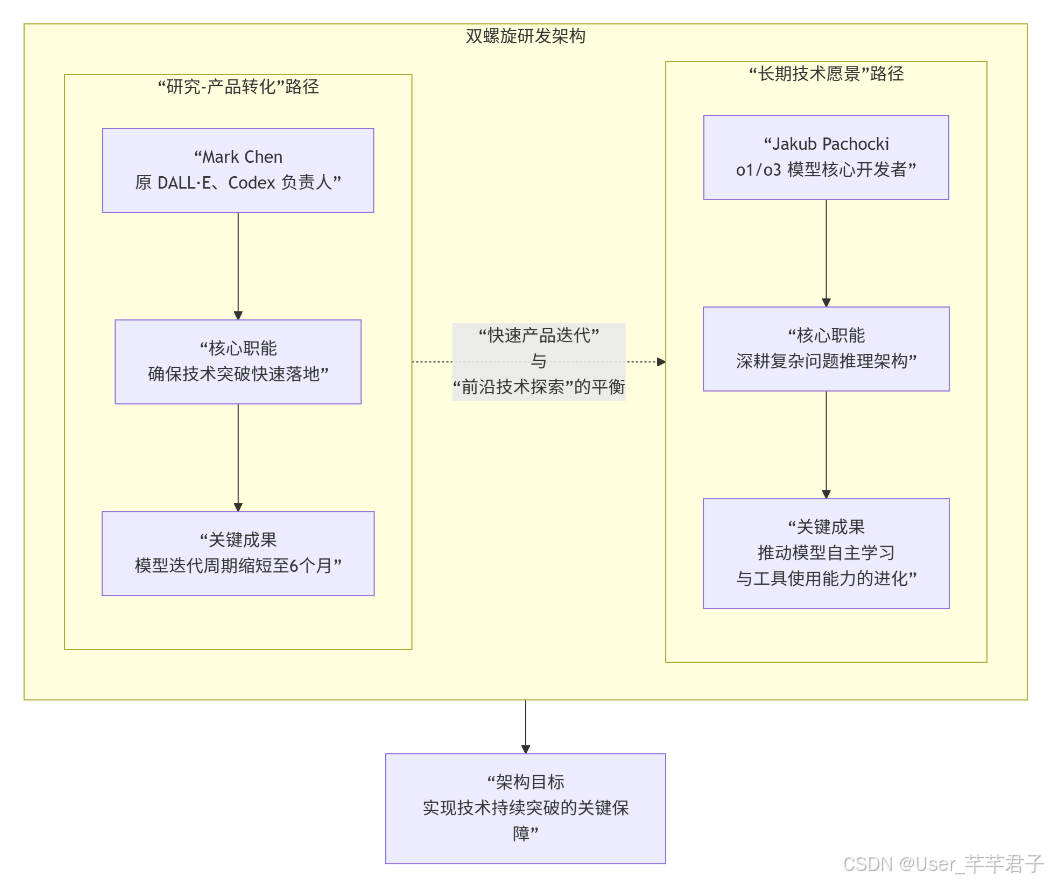
2.1 双核技术 leadership 与研发架构
2024年核心团队迭代后,OpenAI 形成了独特的「双螺旋研发架构」:
-
Mark Chen(原 DALL·E、Codex 负责人):主导「研究-产品转化」,确保技术突破快速落地,将模型迭代周期缩短至6个月;
-
Jakub Pachocki(o1/o3 模型核心开发者):聚焦「长期技术愿景」,深耕复杂问题推理架构,推动模型自主学习与工具使用能力的进化。
这种架构实现了「快速产品迭代」与「前沿技术探索」的平衡,是 OpenAI 近年来技术持续突破的关键保障。
2.2 关键技术创新点(通俗解读)
(1)长时推理与工具自主使用:让AI像人一样“找帮手”
2025年推出的 o3/o4-mini模型,首次实现「自主判断工具使用场景并整合结果」的能力。模型可根据任务需求,自动调用上网搜索、Python 代码执行、图像分析等工具,在一分钟内输出结构化、可验证的结果,大幅提升复杂问题解决效率。例如在数学建模、数据分析等任务中,模型可自主编写代码处理数据,无需人工干预。2025年推出的o3/o4-mini模型,最核心的突破是实现了“自主判断是否需要工具、该用什么工具、如何用工具并整合结果”的能力——这就像我们解决复杂问题时会查资料、用计算器一样,AI现在不用人指挥就能自己做这些事。比如遇到数学建模、大数据分析这类任务,模型会自动编写Python代码处理数据,遇到未知信息会主动上网搜索,最终在一分钟内输出条理清晰、可验证的结果,大幅降低了复杂任务的操作门槛。
(2)多模态联合训练与理解(2)多模态联合训练与理解:打破文本、图像、语音的“沟通壁垒”
继承 DALL·E 3 的多模态技术积累,o3 与 GPT-5 实现了「文本+图像+语音」的深度融合理解。用户可直接上传白板照片、手写字迹、复杂图表,模型能精准解析其中信息,即使图像模糊、倒转也不影响识别效果,甚至可通过工具对图像进行旋转、缩放等处理辅助推理。之前的AI大多只能处理单一类型的信息(比如只懂文本或只懂图像),而o3和GPT-5继承了DALL·E 3的多模态技术优势,实现了“文本+图像+语音”的深度融合理解。简单说,你现在可以直接把白板草图、手写笔记、复杂的实验图表上传给AI,哪怕图像模糊、甚至倒着放,它都能精准看懂里面的信息;如果图像不清晰,它还会自动用工具旋转、放大图像来辅助理解,真正做到“看图说话、看图解题”。
(3)动态知识图谱重构(3)动态知识图谱重构:让AI拥有“跨学科联想能力”
GPT-5 引入核心创新技术「动态知识图谱重构」,可在推理过程中实时构建跨领域知识关联网络。这一能力使其能自主发现学科间的潜在关联,例如在物理学中揭示新的对称性,或在生物信息学中建立基因调控的数学模型,为科学研究提供全新思路。GPT-5引入了“动态知识图谱重构”这一核心技术,你可以把它理解为AI在思考时,会实时构建一张“跨领域知识网络”。比如思考物理学问题时,它能自动关联数学、化学等相关学科的知识,发现人类可能忽略的潜在联系——就像科学家在研究中突然产生的“灵感”。举例来说,它能在物理学中揭示新的对称性规律,或在生物信息学中建立基因调控的数学模型,为前沿科研提供全新的思路。
(4)渐进式安全对齐框架(4)渐进式安全对齐框架:给AI装上“安全防火墙”
针对 AGI 安全风险,OpenAI 提出「渐进式安全框架」,将对齐问题分解为可量化的子任务。GPT-5 内置「安全沙盒」模块,可动态评估输出内容的安全性,较 GPT-4 检测准确率提升 47%,误报率下降 63%,在保障技术创新的同时降低伦理风险。随着AI能力越来越强,“安全可控”变得越来越重要。OpenAI针对AGI(通用人工智能)的安全风险,提出了“渐进式安全框架”——简单说就是把“让AI符合人类伦理、不产生有害输出”这个复杂问题,拆成一个个可量化、可验证的小任务来解决。GPT-5内置了“安全沙盒”模块,能实时检查自己的输出是否安全,相比GPT-4,安全检测的准确率提升了47%,误判率下降了63%,既保证了技术创新,又降低了伦理风险。

三、OpenAI 主流模型能力对比(2025最新)
2025年 OpenAI 模型家族进一步扩容,核心模型包括 o3/o3-pro、o4-mini 及 GPT-5,不同模型在推理能力、适用场景、成本等维度各有侧重。以下是基于官方数据与第三方测试的能力对比表:2025年OpenAI模型家族进一步扩容,核心模型包括o3/o3-pro、o4-mini及GPT-5。不同模型的定位差异很大,就像“工具套装”里的不同工具,适配不同的使用场景和预算。下面这张表格基于官方数据和第三方实测,清晰对比了各模型的核心能力,帮你快速选对模型:
| 模型名称 | 核心定位 | 推理深度 | 编程竞赛排名 | 数学竞赛成绩 | 多模态能力 | 适用场景 |
|---|---|---|---|---|---|---|
o1 |
基础推理模型 | 12步 | 前5% | 银牌 | 基础文本理解 | 简单问答、文本生成 |
o3 |
顶级推理模型 | 28步 | 前2% | 金牌 | 文本+图像深度解析 | 复杂编程、科学分析、视觉推理 |
o4-mini |
高效轻量推理模型 | 22步 | 前3% | 金牌(工具辅助) | 多模态基础支持 | 高吞吐场景、低成本推理任务 |
GPT-5 |
AGI导向科研模型 | 动态自适应 | 前1% | 超越人类顶尖水平 | 文本+图像+语音全模态 | 科学实验优化、前沿科研辅助 |
| 补充说明:o3-pro 作为 o3 的增强版本,目前已向 ChatGPT Pro 用户开放,并支持 API 调用,其在长文本分析、复杂任务规划方面性能更优;o4-mini 则以「低成本+高性能」为核心优势,在 AIME 2025 竞赛中,借助 Python 工具实现 99.5% 的 pass@1 率,成为中小团队的优选模型。补充说明:o3-pro是o3的增强版,目前已对ChatGPT Pro用户开放,也支持API调用,适合处理超长文本(比如百万字文档分析)、复杂任务规划(比如项目全流程拆解);o4-mini主打“低成本+高性能”,特别适合中小团队或高吞吐场景(比如客服机器人、批量文本处理),在2025年AIME数学竞赛中,它借助Python工具实现了99.5%的解题通过率,性价比远超同级别模型。 |
四、OpenAI API 实战:从环境搭建到核心调用
OpenAI API 提供了简洁的接口,支持文本生成、多模态理解、代码开发等多种能力。本节将以 2025 最新 SDK 为例,演示 Python 与 JavaScript 环境下的 API 调用流程(以 o3 模型为例)。OpenAI API把复杂的模型能力封装成了简单的接口,开发者不用关心模型内部的技术细节,就能快速实现文本生成、多模态理解、代码开发等功能。下面以2025最新SDK为例,用Python和JavaScript两种主流语言,演示o3模型的API调用全流程——步骤清晰,新手也能跟着做:
4.1 环境准备:API Key 配置
首先需在 OpenAI 控制台创建 API Key(官方指引),并配置为系统环境变量,避免硬编码泄露密钥:首先要准备API Key:登录OpenAI控制台(官方指引),创建并复制你的API Key。为了安全,建议把API Key配置成系统环境变量,避免直接写在代码里导致泄露。具体配置方法如下:
(1)macOS/Linux 配置
export OPENAI_API_KEY="your_api_key_here"
(2)Windows 配置(PowerShell)
setx OPENAI_API_KEY "your_api_key_here"
4.2 Python 环境 API 调用实战
Python 是 OpenAI API 最常用的开发语言,官方提供了专门的 SDK,支持 Python 3.8+ 版本。Python是调用OpenAI API最常用的语言,官方提供了专门的SDK,支持Python 3.8及以上版本。下面分步骤演示从安装SDK到实现文本生成的全流程:
步骤 1:安装官方 SDK
pip install openai # 安装最新版 SDK
步骤 2:基础文本生成示例(o3 模型)
from openai import OpenAI
# 初始化客户端(自动读取环境变量中的 API Key)
client = OpenAI()
# 调用 o3 模型生成文本
response = client.responses.create(
model="o3",
input="解释动态规划的核心思想,并给出一个 Python 实现的斐波那契数列求解示例"
)
# 输出结果
print("模型输出:")
print(response.output_text)
from openai import OpenAI
# 初始化客户端(会自动读取系统环境变量中的OPENAI_API_KEY,不用手动填写)
client = OpenAI()
# 调用o3模型生成文本:让AI解释动态规划+写斐波那契实现
response = client.responses.create(
model="o3", # 指定使用o3模型
input="解释动态规划的核心思想,并给出一个Python实现的斐波那契数列求解示例" # 你的问题/需求
)
# 打印模型输出结果
print("模型输出:")
print(response.output_text)
步骤 3:多模态推理示例(解析图像中的数学公式)
from openai import OpenAI
import base64
client = OpenAI()
# 读取图像并编码为 base64
def image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 图像路径(本地数学公式图片)
image_path = "math_formula.jpg"
image_base64 = image_to_base64(image_path)
# 调用 o3 模型解析图像
response = client.responses.create(
model="o3",
input={
"text": "解析该图像中的数学公式,并推导其证明过程",
"image": image_base64
}
)
print("图像解析结果:")
print(response.output_text)
from openai import OpenAI
import base64 # 用于将图像转成API能识别的base64格式
client = OpenAI()
# 定义函数:把本地图像文件转成base64编码(API要求图像用这种格式传输)
def image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 1. 准备本地图像(这里替换成你的数学公式图片路径,比如"xxx/数学公式.jpg")
image_path = "math_formula.jpg"
# 2. 转换图像格式
image_base64 = image_to_base64(image_path)
# 3. 调用o3模型解析图像中的数学公式
response = client.responses.create(
model="o3",
input={
"text": "解析该图像中的数学公式,并推导其证明过程", # 对图像的需求
"image": image_base64 # 转换后的图像数据
}
)
# 打印解析结果
print("图像解析结果:")
print(response.output_text)
4.3 JavaScript 环境 API 调用实战
适用于 Node.js、Deno 等服务端 JavaScript 环境,需安装官方 TypeScript/JavaScript SDK。如果你的项目是基于Node.js、Deno等服务端JavaScript开发的,也可以直接使用官方的TypeScript/JavaScript SDK,步骤和Python类似,具体如下:
步骤 1:安装 SDK
npm install openai
步骤 2:文本生成示例
import OpenAI from "openai";
// 初始化客户端
const client = new OpenAI();
// 异步调用 API
async function generateText() {
const response = await client.responses.create({
model: "o3",
input: "写一篇关于 AI 辅助软件开发的技术博客大纲"
});
console.log("模型输出:");
console.log(response.output_text);
}
// 执行函数
generateText().catch(err => console.error(err));
import OpenAI from "openai";
// 初始化客户端(自动读取环境变量中的API Key)
const client = new OpenAI();
// 定义异步函数:调用API生成文本(JavaScript中网络请求需用异步)
async function generateText() {
const response = await client.responses.create({
model: "o3", // 指定o3模型
input: "写一篇关于AI辅助软件开发的技术博客大纲" // 你的需求
});
// 打印输出结果
console.log("模型输出:");
console.log(response.output_text);
}
// 执行函数,并捕获可能出现的错误(比如API Key错误、网络问题)
generateText().catch(err => console.error("调用失败:", err));
【注意事项】1. 调用多模态接口时,图像大小需控制在 25MB 以内,支持 JPG、PNG 等格式;2. 不同模型的 API 计费标准不同,o3 模型按推理 tokens 与图像分辨率双重计费,建议先在控制台设置用量限额。【新手必看注意事项】1. 多模态接口限制:上传的图像大小不能超过25MB,支持JPG、PNG格式,建议先压缩图像再上传;2. 计费提醒:不同模型的收费标准不一样,o3模型会同时按“推理字数(tokens)”和“图像分辨率”收费,新手建议先在OpenAI控制台设置每月用量限额,避免超支;3. 环境变量生效:配置完环境变量后,需要重启终端/IDE才能生效,否则会提示“API Key未找到”。
五、OpenAI 创新应用案例(2025最新)
5.1 科学研究:GPT-5 助力分子克隆实验效率提升 79 倍5.1 科学研究:GPT-5让生物实验效率提升79倍,AI成“科研助手”
OpenAI 与生物安全初创企业 Red Queen Bio 合作,利用 GPT-5 优化分子克隆实验流程。在严格无人工干预的条件下,GPT-5 自主推理实验方案,引入大肠杆菌重组酶 RecA 与噬菌体 T4 单链 DNA 结合蛋白 gp32,设计出全新的 RAPF-HiFi 组装流程,并优化转化条件。OpenAI和生物安全初创公司Red Queen Bio合作,用GPT-5优化了“分子克隆”这一生物实验的核心流程。分子克隆是基因工程的基础操作,传统流程复杂、效率低,且需要研究员积累大量经验才能优化。而GPT-5在完全无人干预的情况下,自己推理出了全新的实验方案:引入大肠杆菌重组酶RecA和噬菌体T4单链DNA结合蛋白gp32,设计出“RAPF-HiFi组装流程”,还自动优化了实验中的转化条件。
实验结果显示,优化后的流程较传统 HiFi 组装效率提升 79 倍,在相同输入 DNA 量下,获得的序列验证克隆数量增加 79 倍。这一突破证明 AI 可直接参与湿实验室实验设计,大幅缩短生物研究周期、降低成本。实验结果非常惊人:优化后的流程比传统HiFi组装效率提升了79倍——在输入相同DNA量的情况下,能获得的“序列验证合格克隆”数量增加了79倍。这意味着AI不再只是“分析数据的工具”,而是能直接参与实验室实验设计的“科研助手”,能大幅缩短生物研究的周期、降低实验成本。
5.2 编程与数学:o3 模型实现 IMO 金牌水平推理5.2 编程与数学:o3模型达到IMO金牌水平,复杂问题能“分步解”
Jakub Pachocki 团队开发的 o3 模型,通过「分步推理框架」将复杂问题分解为可验证的子任务,在国际数学奥林匹克竞赛(IMO)中达到金牌水平,编程竞赛排名进入前 2%。其在 Codeforces、SWE-bench 等工程类基准测试中也表现优异,无需定制架构即可完成复杂软件漏洞修复任务。Jakub Pachocki团队开发的o3模型,核心优势是“分步推理框架”——遇到复杂的数学题或编程题时,它不会直接给出答案,而是像优秀学生一样,把问题拆成一个个小步骤,逐步推导验证。这个能力让它在国际数学奥林匹克竞赛(IMO)中达到了金牌水平,编程竞赛排名也进入了前2%。在Codeforces(全球顶级编程竞赛平台)、SWE-bench(软件漏洞修复测试)等工程类测试中,o3不用专门定制模型架构,就能独立完成复杂的软件漏洞修复任务,大大提升了开发效率。
5.3 多模态交互:o4-mini 支持低质量图像精准解析5.3 多模态交互:o4-mini能“看懂”模糊图像,适配真实工作场景
o4-mini 模型具备强大的视觉推理能力,可精准解析模糊、倒转或低分辨率的图像内容。用户上传白板草图、手写笔记或复杂图表后,模型能自动识别关键信息,结合文本推理生成结构化结论。例如,科研人员可直接上传实验数据图表,模型快速生成数据分析报告与结论建议。
六、总结与未来展望
2025 年的 OpenAI 已从「AI 工具提供商」向「AGI 研究引领者」全面迈进,o3/o4-mini 的自主工具使用能力与 GPT-5 的科研辅助能力,推动 AI 从「被动执行任务」转向「主动解决问题」。对于开发者而言,借助 OpenAI API 可快速赋能各类应用,但需关注模型选型(如高吞吐场景选 o4-mini,复杂科研选 GPT-5)与成本控制。
未来,随着动态知识图谱、渐进式安全框架等技术的持续优化,OpenAI 有望在更多前沿科研领域实现突破。但 AGI 发展带来的伦理风险与社会影响也需行业共同关注,实现技术创新与安全可控的平衡。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


