
RabbitMQ_10_RabbitMQ运维
我们之前的文章介绍了RabbitMQ的安装及运行,但这些都是单机版的,无法满足目前真实应用的要求。试想一下,如果RabbitMQ服务器遇到内存崩溃,断电或者主板故障等情况,应该怎么办呢?
假如单台RabbitMQ服务器可以满足每秒1000条消息的吞吐量,应用需要RabbitMQ服务满足每秒10w条消息的吞吐量,购买昂贵的服务器来增强单机RabbitMQ服务的性能显得捉襟见肘,这时候就需要通过搭建RabbitMQ集群来解决问题了。
RabbitMQ集群允许消费者和生产者在RabbitMQ单个节点崩溃的情况下继续运行,它可以通过添加更多的节点来线性地扩展消息通信地吞吐量。当失去一个RabbitMQ节点时,客户端能够重新连接到集群中地任何其他节点并继续生产或者消费。
不过RabbitMQ集群不能保证消息地万无一失,即使把消息、队列、交换机等都设置为可持久化,生产者和消费者都正确地使用了确认方式。当集群中一个RabbitMQ节点崩溃时,该节点上的所有队列中的消息也会丢失。
RabbitMQ集群中所有节点都会备份所有的元数据信息(队列,交换机的名称及属性),以及他们之间的绑定关系,还有vhost等相关信息,但是不会备份消息,当然这可以通过一些配置解决这个问题。
接下来我们来讲下,如何正确有效地搭建一个RabbitMQ集群。
多机多节点
参考:rabbitMQ的集群安装(多机器)_不同主机之间rabbitmq组建集群-CSDN博客
单机多节点
参考:详解RabbitMQ单机多节点搭建集群_rabbitmq如何查看所有节点-CSDN博客
这里博主因为只有一台云服务器,采用的是单机多节点的方式进行搭建集群环境。
宕机演示
安装之后,是会发生数据不同步德问题的。
1、添加队列
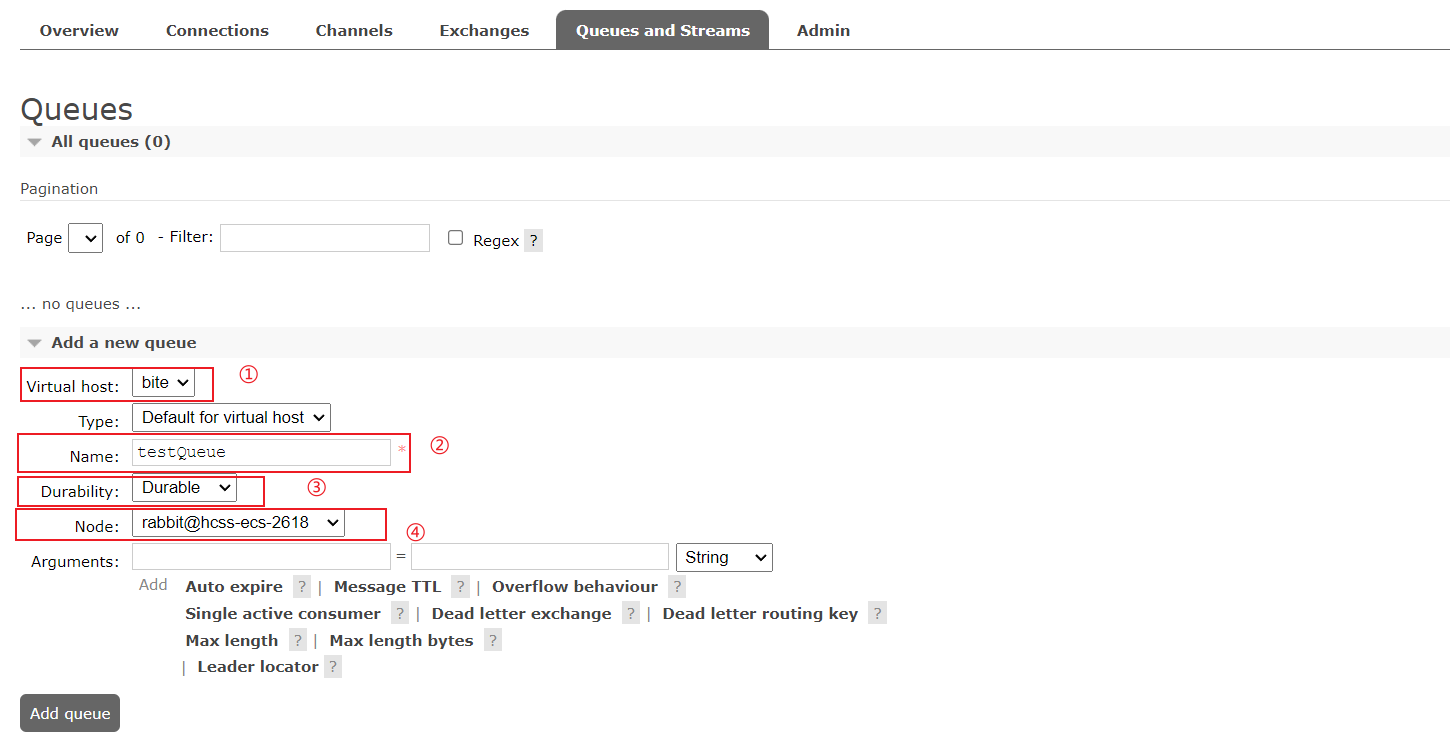
①:选择虚拟机(需要保证操作用户对当前虚拟机有操作权限)
②:设置队列名称
③:是否持久化
④:指定主节点,其他为从节点
分别以rabbit节点和rabbit2节点添加两个队列
2、添加之后,三个节点就都有队列了
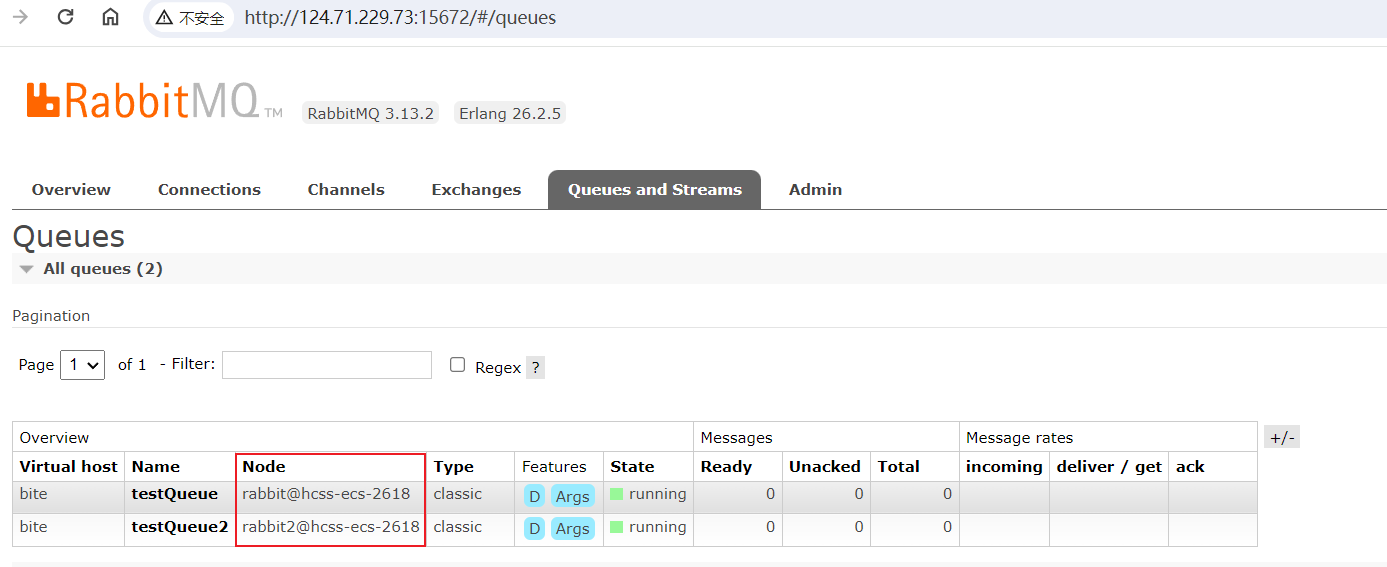
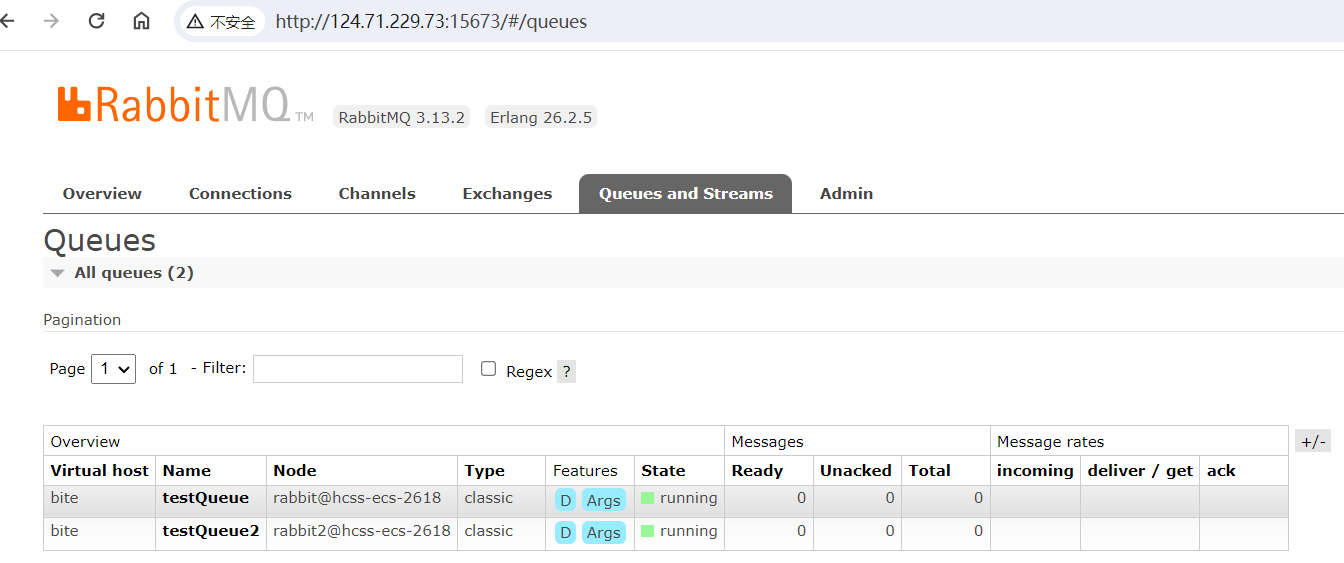
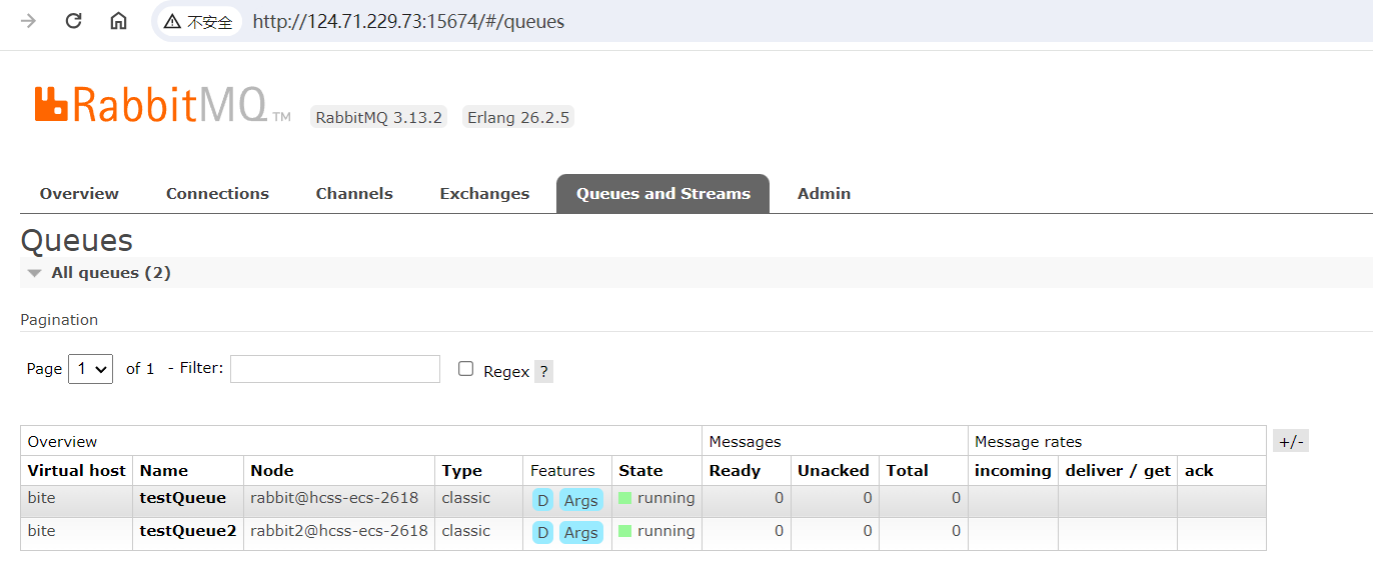
3、往testQueue队列中发送一条数据(从任意节点都可以)
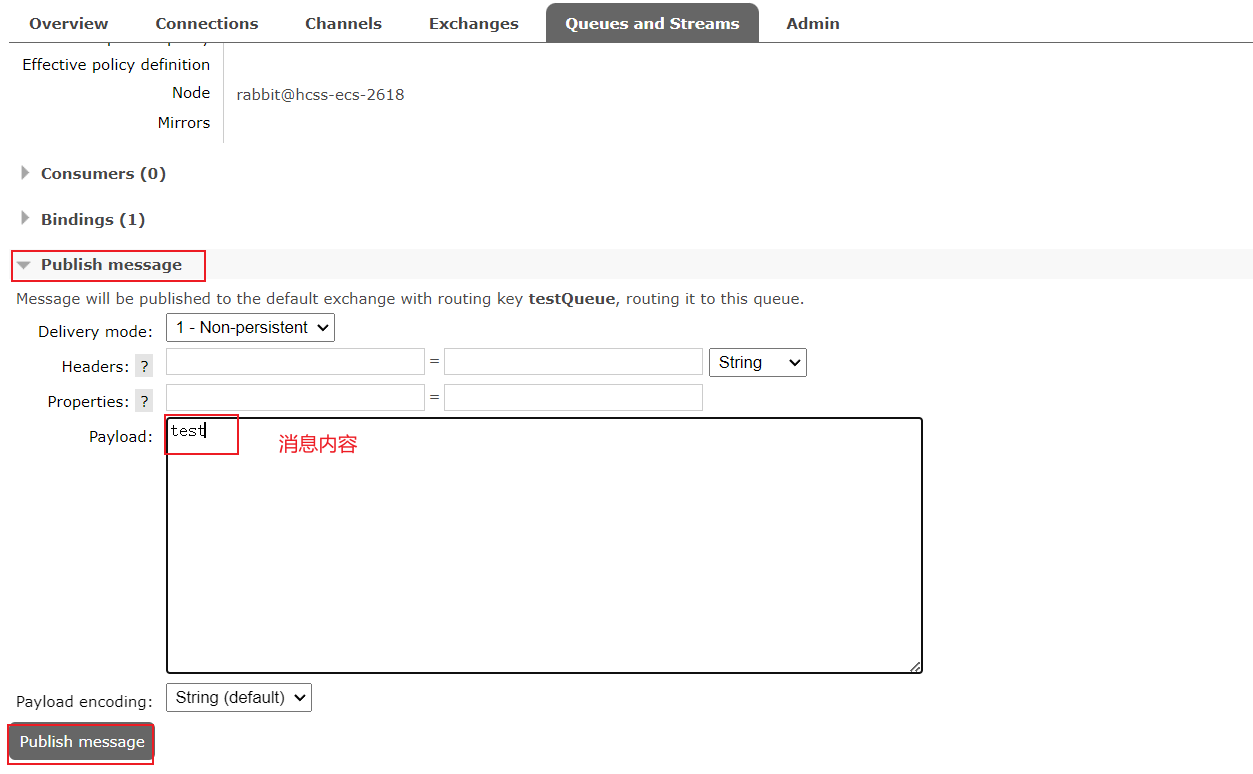
发送之后,三个节点的队列中均有消息
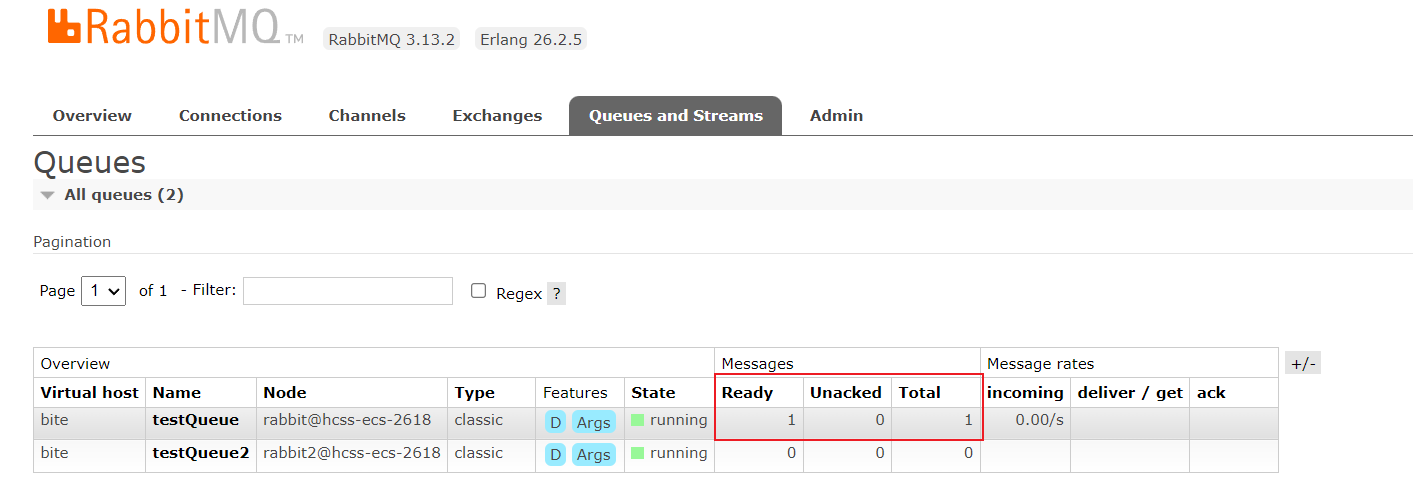
4、关闭主节点
rabbitmqctl -n rabbit stop_app关闭之后可以看到rabbit2和rabbit3没有该队列的数据了,但是另一个队列不受影响
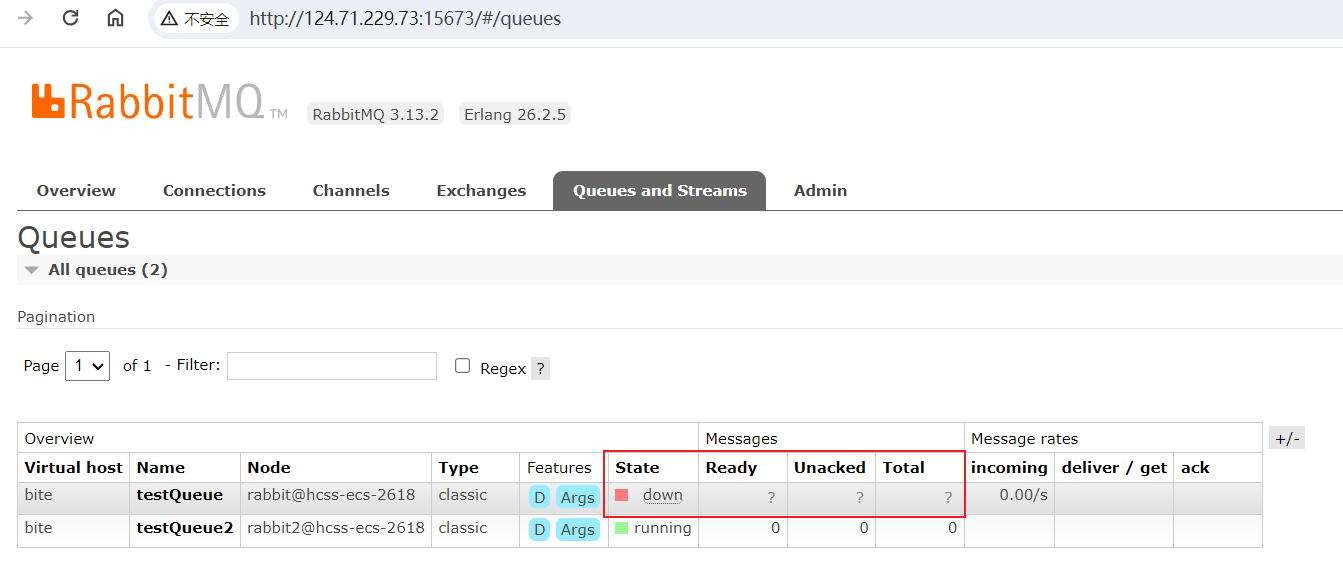
ps:RabbitMQ版本不同,界面显示会有些差异。
也就是说,这个数据只在主节点存在,从节点没有。
如果关闭的是rabbit2,那么testQueue2的数据会消失。
如何解决这个问题呢?这就需要引入我们的“仲裁队列”。
仲裁队列
RabbitMQ的仲裁队列是一种基于Raft一致性算法实现的持久化、复制的FIFO队列,仲裁队列提供队列复制的能力,保障数据的高可用和安全性。使用仲裁队列可以在RabbitMQ节点间进行队列数据的复制,从而达到在一个节点宕机时,队列仍然可以提供服务的效果。
官方文档:https://www.rabbitmq.com/docs/quorum-queues
仲裁队列是RabbitMQ 3.8版本最重要的改动。他是镜像队列的替代方案。在RabbitMQ3.8版本问世之前,镜像队列是实现数据高可用的唯一手段,但是它有一些设计上的缺陷,这也是RabbitMQ提供仲裁队列的原因。镜像队列已被弃用,并计划在将来的版本中移除,如果当前使用镜像队列的RabbitMQ安装需要迁移,可以参考官方提供的迁移指南:https://www.rabbitmq.com/docs/migrate-mcq-to-qq
Raft协议介绍
什么是Raft?
参考自:https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14
Raft是一种用于管理和维护分布式系统一致性的协议,它是一种共识算法,旨在实现高可用和数据的持久性。Raft通过在节点间复制数据来保证分布式系统中的一致性,即使在节点故障的情况下也能保证数据不会丢失去。
在分布式系统中,为了消除单点提高系统可用性,通常会使用副本来进行容错,但这会带来另一个问题,即如何保证多个副本之间的一致性?
共识算法就是做这个事情的,它允许多个分布式节点就某个值或一系列值达成一致性协议,即使在一些节点发生故障,网络分区或其他问题的情况下,共识算法也能保证系统的一致性和数据的可靠性。
常见的共识算法有:Paxos,Raft,Zab等
- Paxos:一种经典的共识算法,用于解决分布式系统中的一致性问题。
- Raft:一种较新的共识算法,Paxos不易实现,Raft是对Paxos算法的简化和改进,旨在易于理解和实现。
- Zab:ZooKeeper使用的共识算法,基于Paxos算法,大部分和Raft相同,主要区别是对于Leader任期,Raft叫做term,Zab叫做epoch,状态复制的过程中,Raft的心跳从Leader向Follower发送,而Zab则相反。
- Gossip:Gossip算法每个节点都是对等的,没有角色之分。Gossip算法中的每个节点都会将数据改动告诉其他节点(有点类似于传八卦)
Raft基本概念
Raft使用Quorum机制来实现共识和容错,我们对Raft集群的操作必须得到大多数(大于二分之N)节点同意才能提交。
当我们向Raft集群发起一系列读写操作时,集群内部究竟发生了什么呢?
Raft集群必须存在一个主节点(Leader),客户端向集群发起的所有操作都必须经由主节点处理。所以Raft核心算法的第一部分就是选主(Leader election)。没有主节点集群就无法工作,先选出一个主节点,在考虑其他事情。
主节点会负责接收客户端发过来的操作请求,将操作打包为日志同步给其他节点,在保证大部分节点同步本次操作后,就可以安全地给客户端回应响应了。这一部分工作在Raft核心算法中叫日志复制(Log replication)。
因为主节点地责任非常大,所以只有符合条件的节点才可以当选主节点。为了保证集群对外展现地一致性,主节点在处理操作日志时,也一定要谨慎,这部分在Raft核心算法中叫安全性(Safety)。
Raft算法将一致性问题分解为三个子问题:Leader选举,日志复制和安全性
选主(Leader election)
选主(Leader election)就是在集群中抉择出一个主节点来负责一些特定的工作。在执行了选主过程后,集群中每个节点都会识别出一个特定的,唯一的节点作为leader。
节点角色
在Raft算法中,每个节点都处于以下三种角色之一
- Leader(领导者):负责处理所有客户请求,并将这些请求作为日志项复制到所有Follower。Leader定期向所有Follower发送心跳信息,以维持其领导者地位,防止Follower进入选举过程。
- Follower(跟随者):接收来自Leader的日志条目,并在本地应用这些条目。跟随者不直接处理客户请求。
- Candidate(候选者):当跟随着在一段时间内没有收到来自Leader的心跳消息,它会变得不确定Leader是否仍然可用。在这种情况下,跟随者会转变角色成为Candidate,并开始尝试通过投票成为新的Leader
在正常情况下,集群只有一个Leader,剩下的节点都是Follower,下图展示了这些状态和它们之间的转换关系:
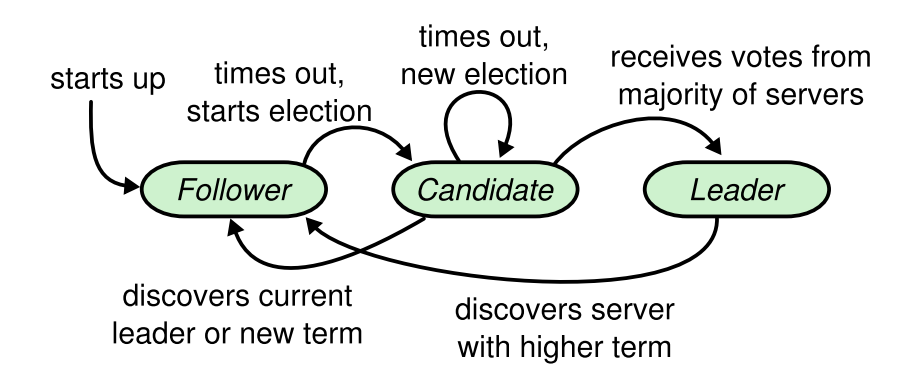
可以看出所有节点在启动时,都是Follower状态,在一段时间内如果没有收到来自Leader的心跳,从Follower切换到Candidate,发起选举。如果收到多数节点的投票(含自己的一票)则切换到leader状态。Leader一般会一直工作直到它发生异常为止。
任期
Raft将时间划分成任意长度的任期(term)。每一段任期从一次选举开始,在这个时候会有一个或者多个candidate尝试去成为leader。在成功完成一次leaderelection之后,一个leader就会一直管理集群直到任期结束。在某些情况下,一次选举无法选出leader,这个时候这个任期会以没有leader而结束(如下图3).同时一个新的任期(包含一次新的选举)会很快重新开始。
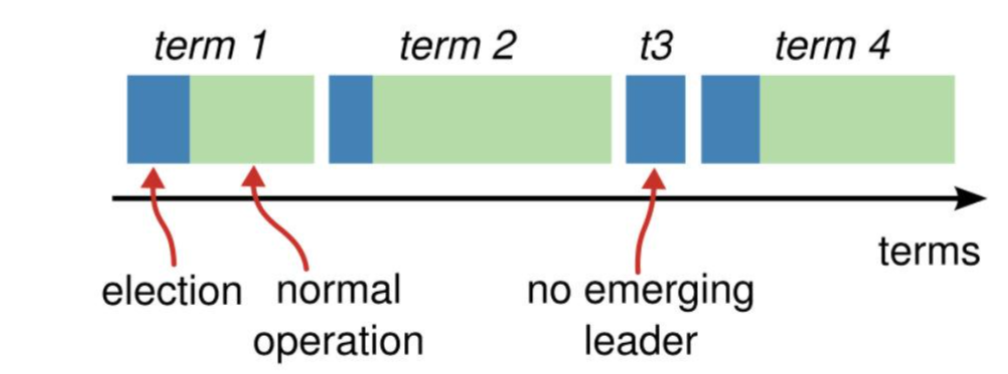
Term更像是一个逻辑时钟(logic clock)的作用,有了它,就可以发现哪些节点的状态已经过期。每一个节点都保存一个current term,在通信时带上这个term的值。
每一个节点都存储这一个当前任期号(current term number)。该任期号会随着时间单调递增。节点之间通信的时候会交换当前任期号,如果一个节点的当前任期号比其他节点小,那么他就将自己的任期号更新为较大的那个值。如果一个candidate或者leader发现自己的任期号过期了,他就会立刻回到follower状态。如果一个节点接收了一个带到过期的任期号的请求,那么他会拒绝这次请求。
Raft算法中服务器节点采用RPC进行通信,主要有两类RPC请求:
- RequestVote RPCs:请求投票,由candidate在选举过程中发出
- AppendEntries:追加条目,由leader发出,用来做日志复制和提供心跳机制
选举过程
Raft采用一种心跳机制来触发Leader选举,当服务器启动的时候,都是follow状态。如果follower在election timeout内没有收到来自leader的心跳(可能没有选出leader,也可能leader挂了,或者leader与follower之间网络故障),则会主动发起选举。
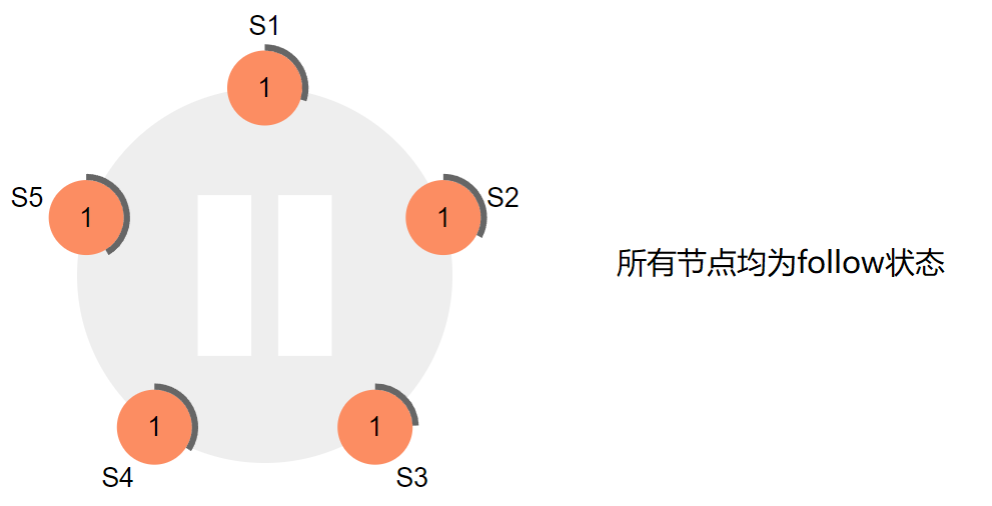
步骤如下:
- 率先超时的节点,自增当前任期号然后切换为candidate状态,并投自己一票。
- 以并行的方式发送一个RequestVote RPCs给集群中的其他服务器节点(企图得到它们的投票)
- 等待其他节点的回复

在这个过程中,可能出现三种结果
- 赢得选举,成为Leader(包括自己的一票)
- 其他节点赢得了选举,它自行切换到follower
- 一段时间内没有收到majority投票,保持candidate状态,重新发出选举
投票要求:
- 每个服务器节点会按照先来先服务原则只投给一个candidate
- 候选人知道的信息不能比自己的少
接下来对这三种情况进行说明:
第一种情况:赢得了选举之后,新的leader会立刻给所有节点发信息,广而告知,避免其余节点触发新的选举。
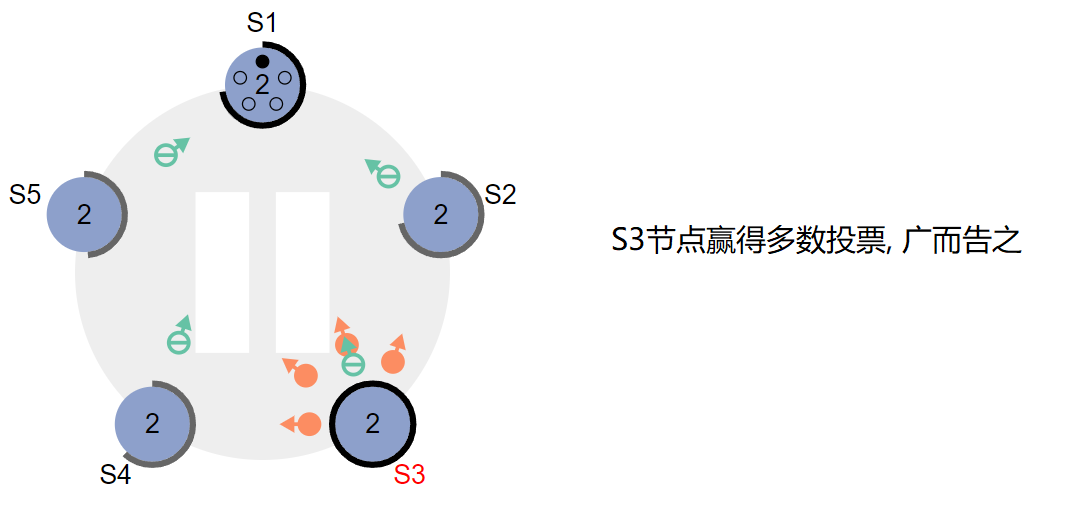
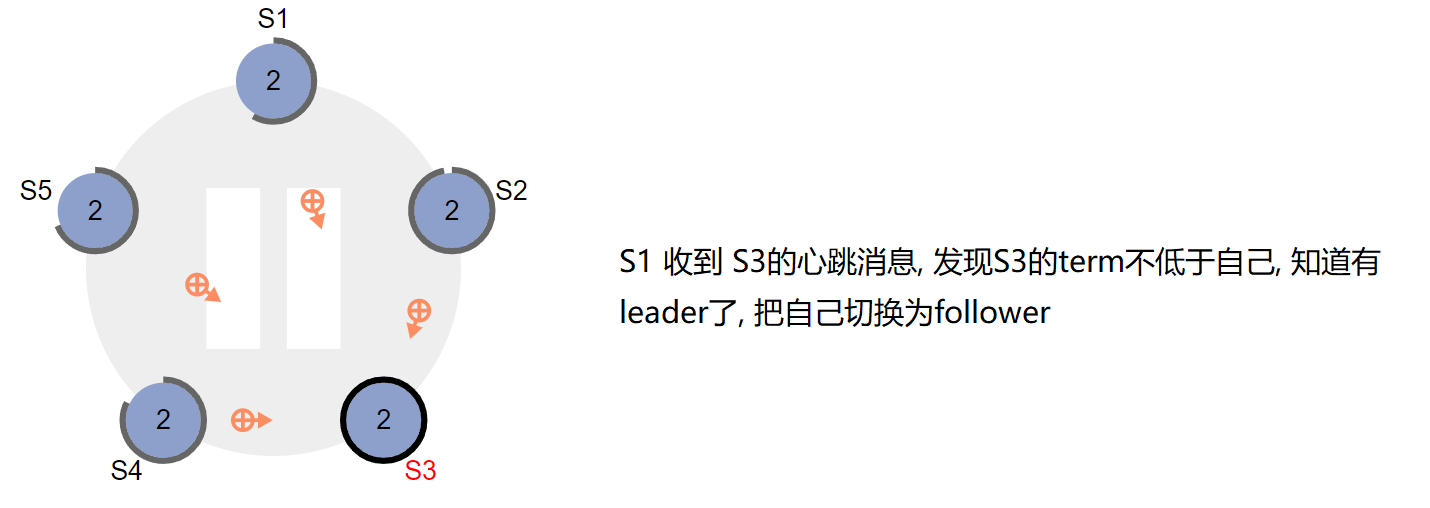
第二种情况:比如有三个节点A B C,A B同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的第一个约束,即C不会给B投票,这时候A就胜出了。A胜出之后,会给B、C发心跳消息,节点B发现节点A的term不低于自己的term,知道已经有Leader了,于是把自己转换成follower
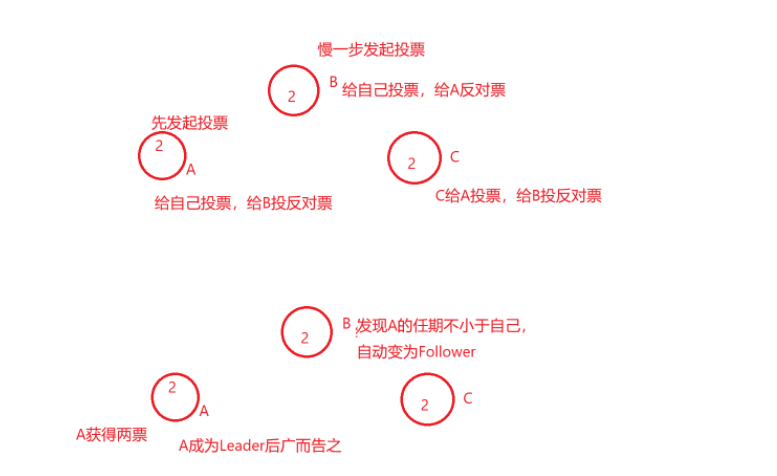
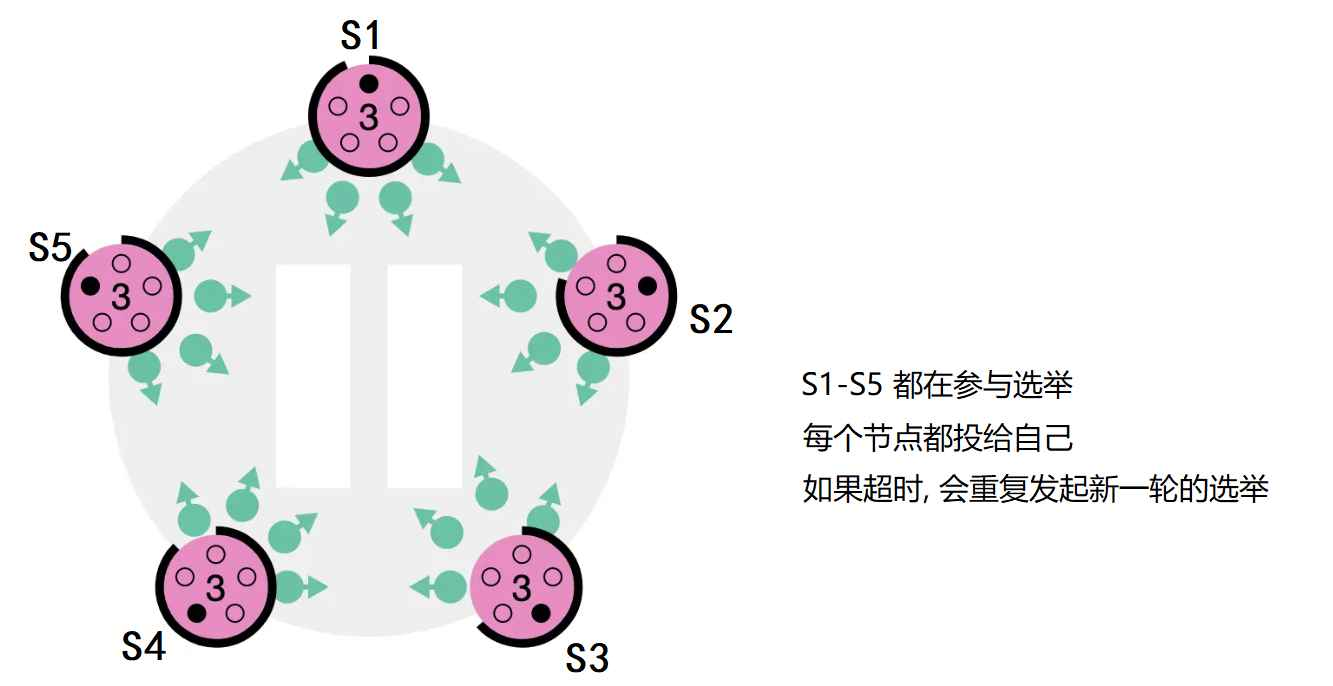
第三种情况:没有任何节点获得majority投票。比如所有的follower同时变为candidate,然后它们都把票投给自己,那这样就没有candidate能得到超过半数的投票了,当这种情况发生时,每个candidate都会进行一次超时响应,然后通过自增任期号来开启新一轮的选举,并启动另一轮的RequestVote RPCs。如果没有额外的措施,这种无结果的投票可能会无限重复下去。
为了解决上述问题,Raft采用了随机选举超时时间来确保很少产生无结果的投票,并且就算发生了也能很快地解决。为了防止选票一开始就被瓜分,选举超时时间时从一个固定的区间(比如,150~300ms)种随机选择。这样可以把服务器分散开来以确保大多数情况下会只有一个服务器率先结束超时,那么这个时候,他就可以赢得选举并在其他服务器结束超时之前发送心跳。
Raft动画演示:https://raft.github.io/
详细视频演示(包括下面的Raft协议下的消息复制):https://thesecretlivesofdata.com/raft/
Raft协议下的消息复制
每个仲裁队列都有多个副本,它包含一个主和多个从副本。如:replicationfactor为5的仲裁队列将会有1个主副本和4个从副本.每个副本都在不同的RabbitMQ节点上。
客户端(生产者和消费者)只会与主副本进行交互,主副本再将这些命令复制到从副本,当主副本所在的节点下线,其中一个从副本会被选举成为主副本,继续提供服务。
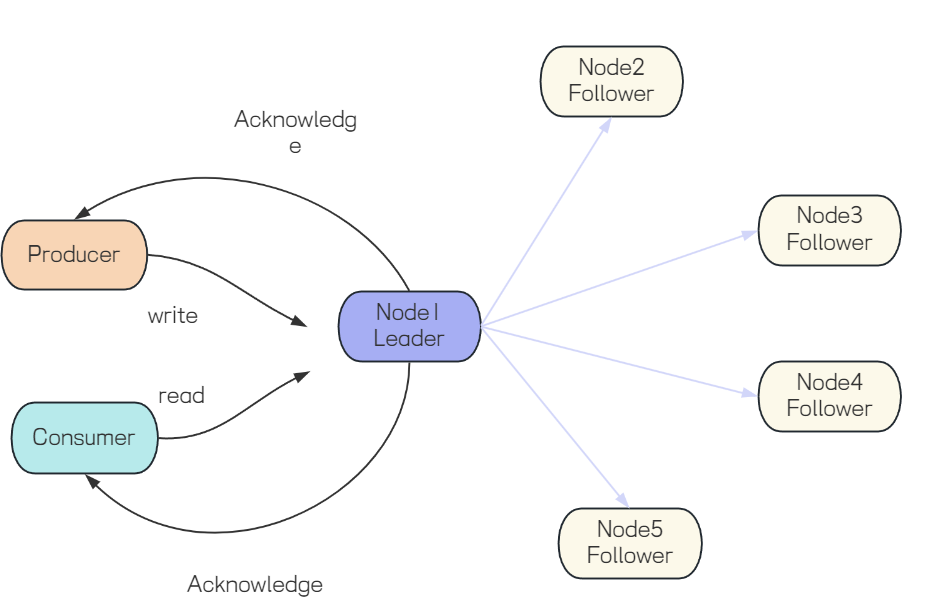
消息复制和主副本选举的操作,需要超过半数副本同意,当生产者发送一条消息,需要超过半数的队列副本都将消息写入磁盘以后才会向生产者进行确认,这意味着少部分比较慢的副本不会影响整个队列的性能。
仲裁队列的使用
创建仲裁队列
1、使用Spring创建
@Configuration
public class RabbitMQConfig {
@Bean("quorumQueue")
public Queue quorumQueue(){
return QueueBuilder.durable("quorum.queue").quorum().build();
}
}
2、使用管理平台创建
创建后观察管理平台
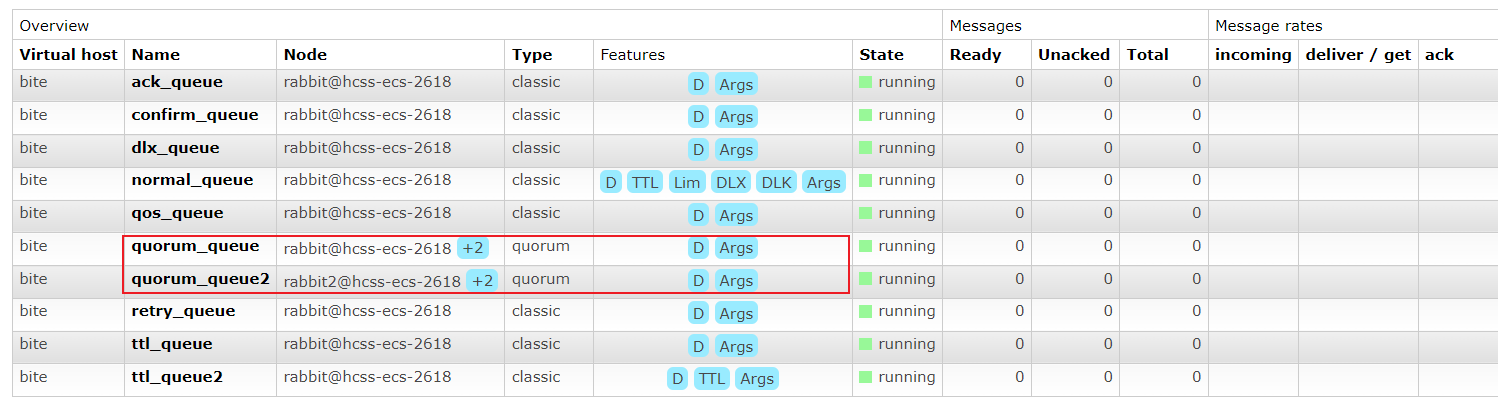
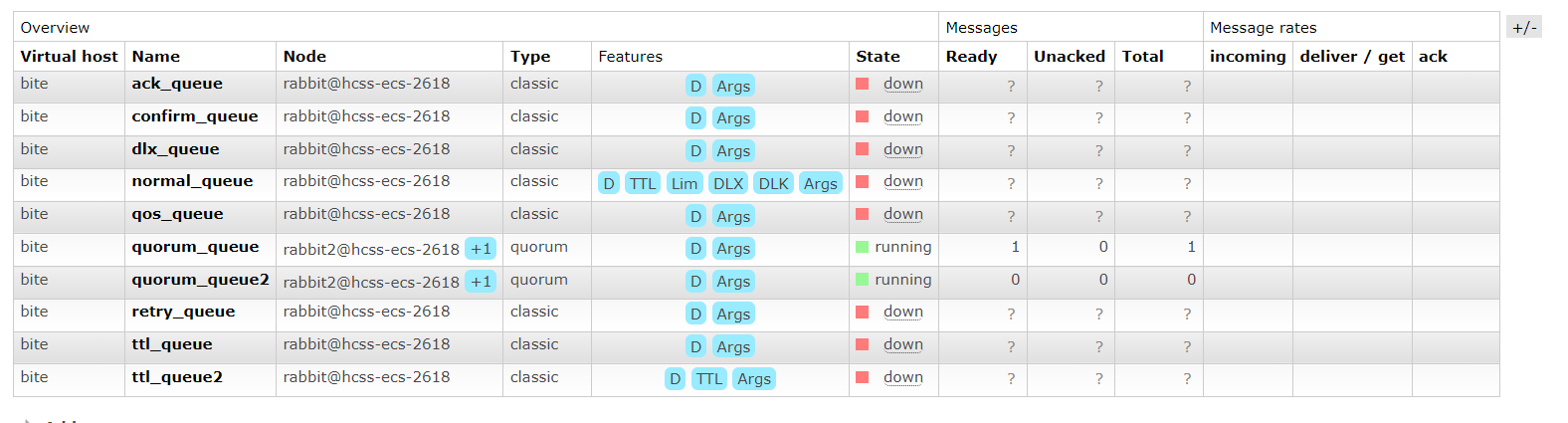
可以看到,仲裁队列后面有一个+2字样,代表这个队列有两个镜像节点。
仲裁队列默认的镜像数为5,即一个主节点,4个从副本节点。
如果集群种节点的数量少于5,比如我们搭建了3个节点的集群,那么创建的仲裁队列就是1主2从,如果集群中的节点大于5,那么就只会在5个节点中创建出1主4从。
点进去,可以看到队列详情:
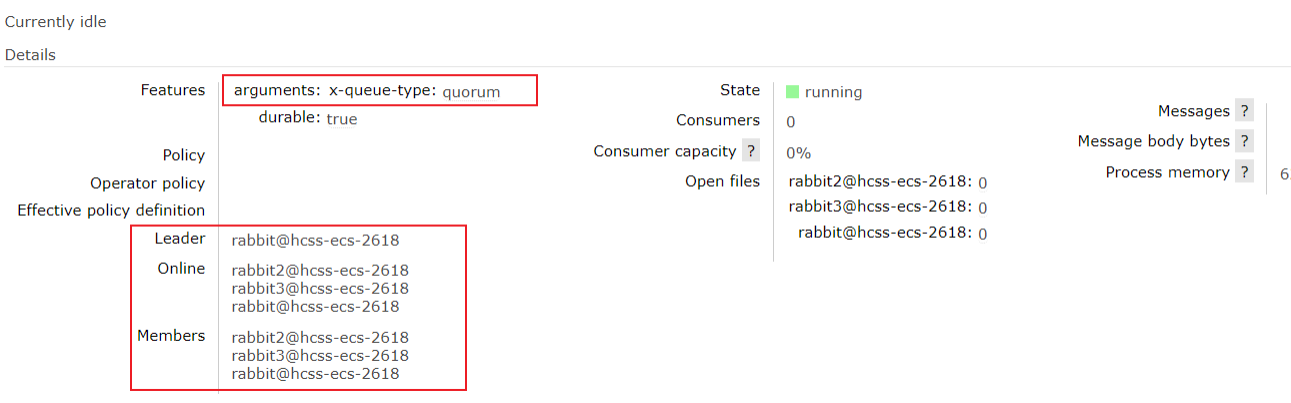
可以看到:当有多个仲裁队列时,主副本和从副本会分布在集群的不同节点上,每个节点可以承载多个主副本和从副本。
接收/发送消息
@RequestMapping("/producer")
@RestController
public class ProducerController {
@Autowired
private RabbitTemplate rabbitTemplate;
@RequestMapping("/quorum")
public String quorum(){
rabbitTemplate.convertAndSend("","quorum.queue","quorum test...");
return "消息发送成功";
}
}仲裁队列发送接收消息和普通队列操作一样。
宕机演示
1、给仲裁队列quorum_queue发送发送消息
发送消息后:
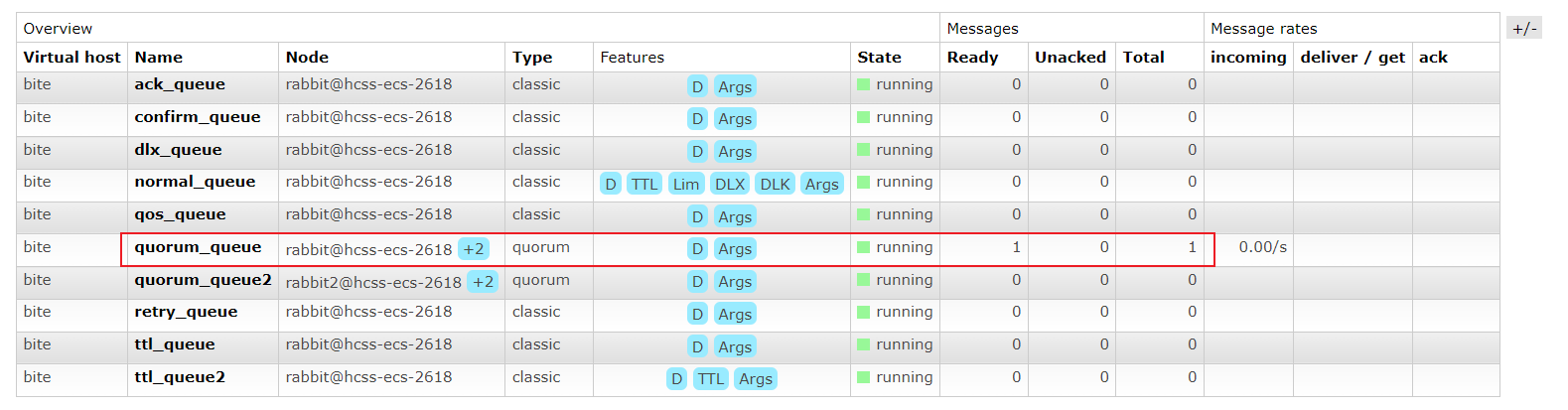
2、停掉队列主副本所在的节点
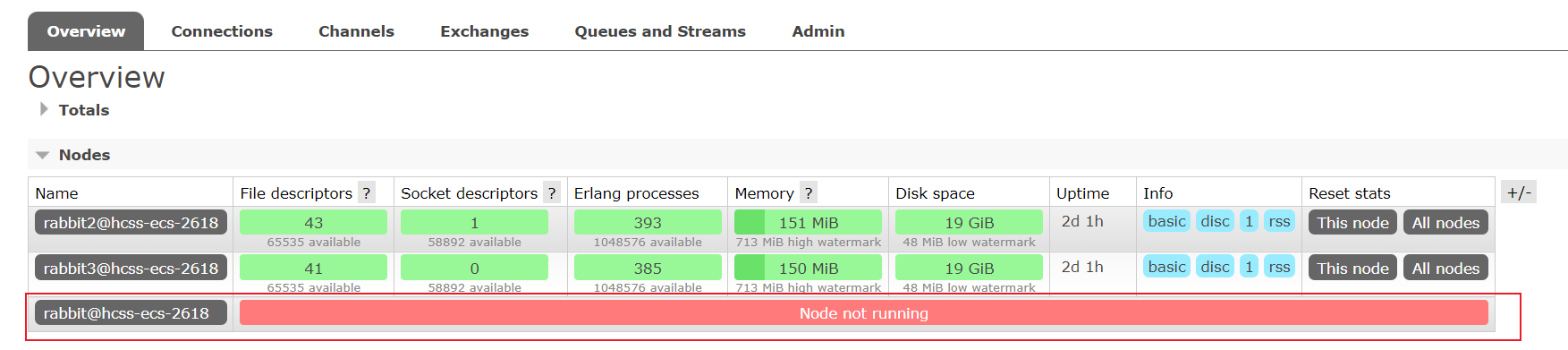
通过上图,我们知道:quorum_queue队列主副本所在的节点在rabbit@hcss-ecs-2618,停掉这台机器。
rabbitmqctl -n rabbit stop_app #rabbit为节点名称ps:这里如果不再当前主机上操作,需要将rabbit改为节点名称,如我们这里就需要改为rabbit@hcss-ecs-2618。
观察其他节点,可以看到quorum_queue队列的内容依然存在。
并且,因为主副本所在节点宕机了,quorum_queue主副本从rabbit@hcss-ecs-2618转移到了rabbit2@hcss-ecs-2618
仲裁队列,是RabbitMQ从3.80版本引入的新的队列类型,Quorum相比Classic分布式环境下对消息的可靠性保障。普通队列只会存放在集群中的一个节点上,虽然通过其他节点可以访问普通队列,但是其他节点只是把请求转发到队列所在的节点进行操作。一旦队列所在节点宕机,队列中的消息依然会丢失,因此普通集群只是提高了并发能力,并未实现高可用。仲裁队列可以极大地保障RabbitMQ集群对接的高可用。
HAProxy负载均衡
面对大量的业务访问、高并发请求,可以使用高性能的服务器来提升RabbitMQ服务的负载能力。当单机容量到达极限时,可以采取集群的策略来对策略对负载能力做进一步的提升,但这里还存在一些问题。
如果一个集群有三个节点,我们在写代码时,访问哪个节点呢?
答案是访问任何一个节点都可以。
此时就存在两个问题:
- 如果我们访问的是node1,但是node1挂了,咱们的程序也会出现问题,所以最好是有一个统一的入口,一个节点故障时,流量可以及时转移到其他节点。
- 如果所有的客户端都与node1建立连接,那么node1的网络负载必然会大大增加,而其他节点又由于没有那么多的负载而造成硬件的浪费。
此时负载均衡显得尤其重要。
引入负载均衡后,各个客户端的连接可以通过负载均衡分摊到集群的各个节点之中,从而避免前面的问题。
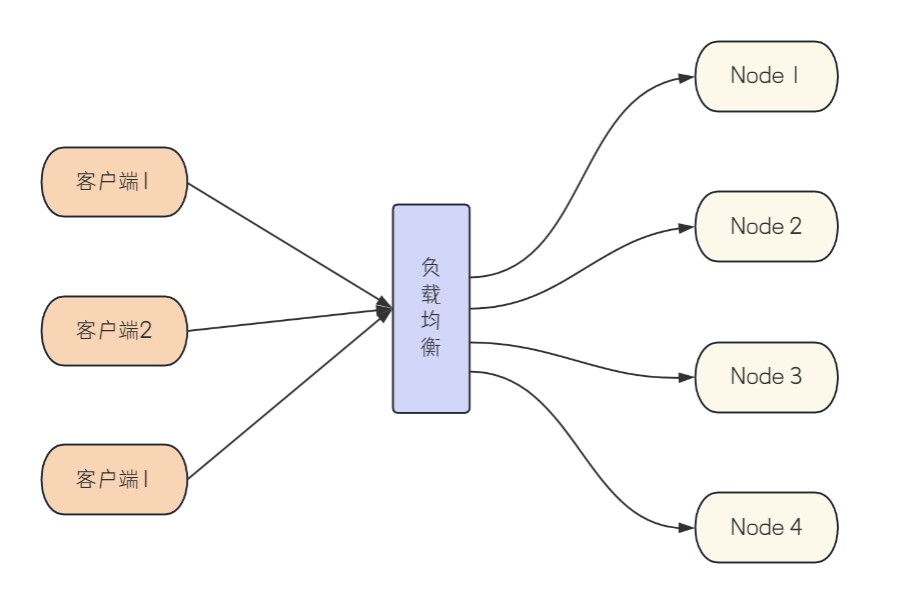
这里主要讨论的是如何有效地对RabbitMQ集群使用软件负载均衡技术,目前主流的方式有在客户端内部实现负载均衡,或者使用HAProxy、LVS等负载有软件来实现。咱们这里讲一下使用HAProxy来实现负载均衡。
安装
安装参考:HAProxy配置与实践-CSDN博客
使用
引入HAProxy之后,RabbitMQ集群使用和单机使用方式一样,只不过需要把RabbitMQ的IP和port改为HAProxy的IP和port
修改配置文件
spring:
application:
name: rabbitmq-op
rabbitmq:
addresses: amqp://admin:admin@106.52.188.165:5670/ops
声明队列
@Bean("clusterQueue")
public Queue clusterQueue(){
return QueueBuilder.durable("cluster.queue").quorum().build();
}发送消息
@RequestMapping("/haproxy")
public String haproxy(){
rabbitTemplate.convertAndSend("","cluster.queue","\"cluster test...");
return "消息发送成功";
}测试
可以看到发送成功:

宕机演示
我们停止其中一个节点,继续测试
1rabbitmqctl -n rabbit stop_app下图界面是访问HAProxy管理端界面:http://主机IP:配置的端口号
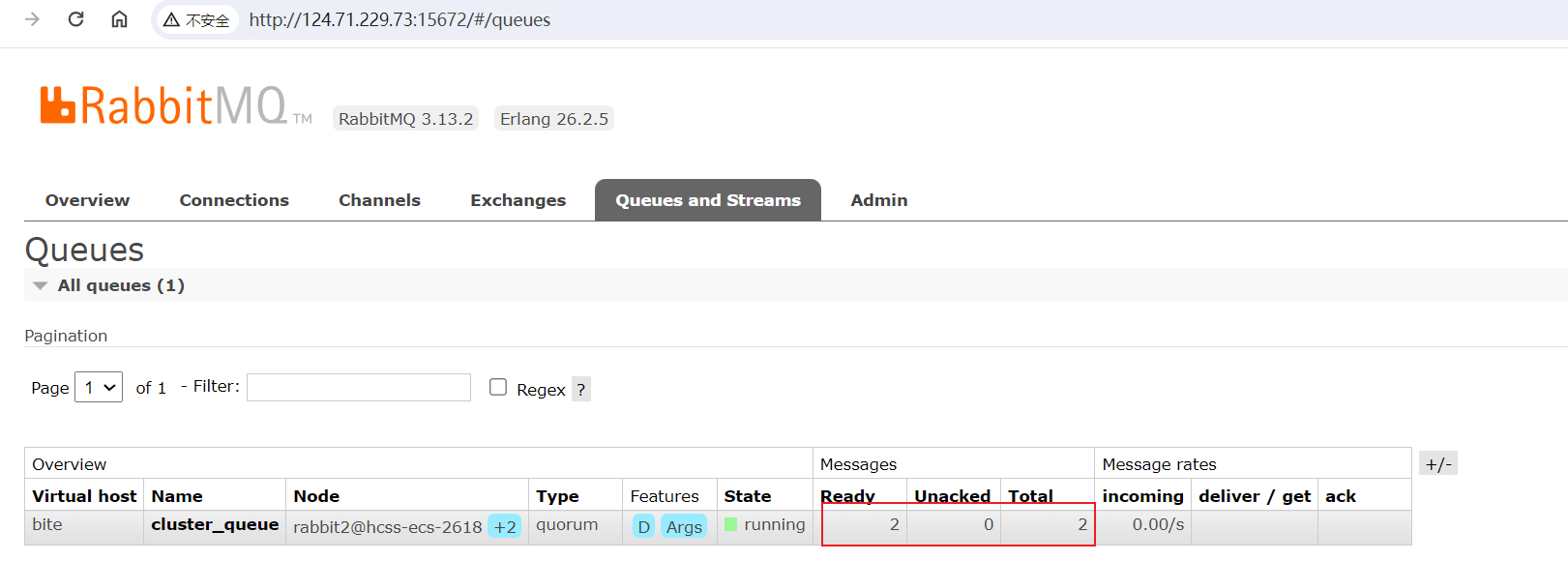
在节点宕机的情况下,继续发送消息:

可以看到消息发送成功了,观察界面,可以看到队列有两条消息:

集群恢复
恢复上述节点
rabbitmqctl -n rabbit start_app观察消息也同步到当前节点了
© 版权声明
文章版权归作者所有,未经允许请勿转载。


