
【AI大模型前沿】通义万相Wan2.2:阿里270亿参数巨兽开源,消费级显卡就能跑,免费平替Sora上线
系列篇章💥
| No. | 文章 |
|---|---|
| 1 | 【AI大模型前沿】深度剖析瑞智病理大模型 RuiPath:如何革新癌症病理诊断技术 |
| 2 | 【AI大模型前沿】清华大学 CLAMP-3:多模态技术引领音乐检索新潮流 |
| 3 | 【AI大模型前沿】浙大携手阿里推出HealthGPT:医学视觉语言大模型助力智能医疗新突破 |
| 4 | 【AI大模型前沿】阿里 QwQ-32B:320 亿参数推理大模型,性能比肩 DeepSeek-R1,免费开源 |
| 5 | 【AI大模型前沿】TRELLIS:微软、清华、中科大联合推出的高质量3D生成模型 |
| 6 | 【AI大模型前沿】Migician:清华、北大、华科联手打造的多图像定位大模型,一键解决安防监控与自动驾驶难题 |
| 7 | 【AI大模型前沿】DeepSeek-V3-0324:AI 模型的全面升级与技术突破 |
| 8 | 【AI大模型前沿】BioMedGPT-R1:清华联合水木分子打造的多模态生物医药大模型,开启智能研发新纪元 |
| 9 | 【AI大模型前沿】DiffRhythm:西北工业大学打造的10秒铸就完整歌曲的AI歌曲生成模型 |
| 10 | 【AI大模型前沿】R1-Omni:阿里开源全模态情感识别与强化学习的创新结合 |
| 11 | 【AI大模型前沿】Qwen2.5-Omni:阿里巴巴的多模态大模型,实现看、听、说、写一体化 |
| 12 | 【AI大模型前沿】SmolDocling:256M参数的轻量级多模态文档处理利器,10分钟搞定百页PDF |
| 13 | 【AI大模型前沿】Stable Virtual Camera:Stability AI 推出的2D图像转3D视频模型,一键生成沉浸式视频 |
| 14 | 【AI大模型前沿】阿里 Qwen3 震撼开源,模型新王诞生,开启全球大模型新纪元 |
| 15 | 【AI大模型前沿】InternVL:OpenGVLab开源多模态大模型,解锁视觉问答与多语言翻译的全能应用图鉴 |
| 16 | 【AI大模型前沿】Fin-R1:上海财经大学联合财跃星辰推出的金融推理大模型,凭7B参数拿下评测第二,离行业第一仅差3分 |
| 17 | 【AI大模型前沿】Med-R1:基于强化学习的医疗视觉语言模型,突破跨模态医学推理的普适性 |
| 18 | 【AI大模型前沿】Baichuan-M1-14B:百川智能推出专为医疗优化的开源大语言模型 |
| 19 | 【AI大模型前沿】一键生成宫崎骏动画风,EasyControl Ghibli 让照片秒变吉卜力艺术品 |
| 20 | 【AI大模型前沿】TxGemma:谷歌推出的高效药物研发大模型,临床试验预测准确率超90% |
| 21 | 【AI大模型前沿】F5R-TTS:腾讯推出TTS领域的新王者,又快又准又自然,零样本语音克隆新高度 |
| 22 | 【AI大模型前沿】MiniMind-V:低成本打造超小多模态视觉语言模型(仅需1.3元人民币和1小时) |
| 23 | 【AI大模型前沿】MoCha:端到端对话角色视频生成模型、电影级对话角色合成黑科技、重新定义动画创作 |
| 24 | 【AI大模型前沿】HuatuoGPT-o1-7B:中英文双语医学推理,打破语言障碍的AI大模型 |
| 25 | 【AI大模型前沿】MedReason:大规模医学推理数据集、借用知识图谱将大模型打造成“医术”专家 |
| 26 | 【AI大模型前沿】SkyReels-V2:昆仑万维开源的无限时长电影生成模型,开启视频生成新纪元 |
| 27 | 【AI大模型前沿】Dia:Nari Labs开源16亿参数TTS模型,只需文本输入,生成媲美真人对话的语音 |
| 28 | 【AI大模型前沿】阿里巴巴开源LHM:单图生成可动画3D人体模型,开启3D建模新纪元 |
| 29 | 【AI大模型前沿】TinyLLaVA-Video-R1:北航开源视频推理模型、小尺寸大智慧、参数少一半,性能翻一番 |
| 30 | 【AI大模型前沿】TTRL:测试时强化学习,开启无标签数据推理新篇章 |
| 31 | 【AI大模型前沿】Aero-1-Audio:Qwen2.5架构加持,轻量级音频模型天花板、吊打Whisper |
| 32 | 【AI大模型前沿】DianJin-R1:阿里云通义点金联合苏大推出的金融推理增强大模型 |
| 33 | 【AI大模型前沿】VITA-Audio:腾讯开源的高效语音交互多模态大语言模型 |
| 34 | 【AI大模型前沿】Multiverse:全球首个AI多人游戏世界模型,低成本高效率新突破 |
| 35 | 【AI大模型前沿】Seed1.5-VL:多模态理解的效率革新者,以小博大,性能惊艳 |
| 36 | 【AI大模型前沿】ViLAMP:蚂蚁集团和人民大学联手打造的长视频理解利器,单卡处理3小时视频 |
| 37 | 【AI大模型前沿】Muyan-TTS:开源零样本语音合成模型、0.33秒极速生成播客级语音、小白也能玩转AI配音 |
| 38 | 【AI大模型前沿】Dolphin:字节跳动开源文档解析大模型,轻量级、高效、多格式,开启文档处理新时代 |
| 39 | 【AI大模型前沿】ChatTS:字节跳动联合清华大学开源、多模态时序大模型助力时序数据对话与推理 |
| 40 | 【AI大模型前沿】Index-AniSora:B站开源的动漫视频生成模型,助力高效创作 |
| 41 | 【AI大模型前沿】RelightVid:上海 AI Lab联合复旦等高校推出的视频重照明模型 |
| 42 | 【AI大模型前沿】BAGEL:字节跳动开源、多模态大模型的创新突破与实践指南 |
| 43 | 【AI大模型前沿】Matrix-Game:昆仑万维开源大模型,一键生成你的专属虚拟世界 |
| 44 | 【AI大模型前沿】Pixel Reasoner:滑铁卢联合港科大等高校推出的视觉语言模型,助力视觉推理新突破 |
| 45 | 【AI大模型前沿】CoGenAV:多模态语音表征新范式、通义联合深技大打造、噪声环境WER降低70%+ |
| 46 | 【AI大模型前沿】Ming-Lite-Omni:蚂蚁集团开源的统一多模态大模型的创新实践 |
| 47 | 【AI大模型前沿】DeepEyes:小红书与西安交大联合打造的多模态深度思考模型 |
| 48 | 【AI大模型前沿】OmniAudio:阿里通义实验室的空间音频生成模型,开启沉浸式体验新时代 |
| 49 | 【AI大模型前沿】MiniCPM 4.0:面壁智能开源的极致高效端侧大模型(小版本、低消耗、220倍极致提速) |
| 50 | 【AI大模型前沿】SmolVLA:Hugging Face开源的轻量级视觉-语言-行动机器人模型 |
| 51 | 【AI大模型前沿】Time-R1:伊利诺伊大学香槟分校开源的时间推理语言模型、实现过去→未来全链路推演 |
| 52 | 【AI大模型前沿】MonkeyOCR:基于结构-识别-关系三元组范式的文档解析模型 |
| 53 | 【AI大模型前沿】GLM-4.5:智谱打造的开源SOTA模型,推理、代码与智能体能力融合先锋 |
| 54 | 【AI大模型前沿】百度飞桨PaddleOCR 3.0开源发布,支持多语言、手写体识别,赋能智能文档处理 |
| 55 | 【AI大模型前沿】Stream-Omni:多模态交互的“黄金三角”——视觉、语音、文本的完美融合 |
| 56 | 【AI大模型前沿】Vui:Fluxions-AI开源的轻量级语音对话模型,开启自然语音交互新时代 |
| 57 | 【AI大模型前沿】腾讯AI Lab开源的SongGeneration:音乐生成大模型的技术探索与实践 |
| 58 | 【AI大模型前沿】Osmosis-Structure-0.6B:小型语言模型在结构化信息提取中的突破 |
| 59 | 【AI大模型前沿】Kwai Keye-VL:颠覆认知!国产多模态大模型突然发布,视频理解能力堪比人类 |
| 60 | 【AI大模型前沿】Nanonets-OCR-s:从学术论文到法律合同,智能识别公式、签名、表格与图像 |
| 61 | 【AI大模型前沿】OmniAvatar:浙大联合阿里打造的音频驱动全身视频生成模型 |
| 62 | 【AI大模型前沿】DAMO GRAPE:阿里达摩院与浙江肿瘤医院联合打造的早期胃癌识别AI模型 |
| 63 | 【AI大模型前沿】阿里开源Lingshu:一个模型搞定12种医学影像诊断 |
| 64 | 【AI大模型前沿】原石科技MetaStone-S1:突破性反思型生成式大模型的技术解析与实践指南 |
| 65 | 【AI大模型前沿】清华实验室开源MOSS-TTSD:口语对话语音生成的突破 |
| 66 | 【AI大模型前沿】昆仑万维开源Skywork-R1V3:38B多模态推理模型,高考数学142分刷新开源SOTA |
| 67 | 【AI大模型前沿】Voxtral:Mistral AI开源的高性价比语音转录与理解模型 |
| 68 | 【AI大模型前沿】Goedel-Prover-V2:普林斯顿联合清华开源的定理证明模型,AI数学研究新里程碑 |
| 69 | 【AI大模型前沿】Seed-X:字节跳动开源的7B参数多语言翻译模型,挑战超大型模型性能 |
| 70 | 【AI大模型前沿】OpenReasoning-Nemotron:英伟达开源的推理利器,助力数学、科学与代码任务 |
| 71 | 【AI大模型前沿】阿里通义千问 Qwen3-Coder:开启智能代码生成与代理式编程新时代 |
| 72 | 【AI大模型前沿】Qwen3-SmVL:基于阿里通义千问3和SmolVLM拼接打造1 GB显存可跑的中文超小多模态大模型 |
| 73 | 【AI大模型前沿】通义万相Wan2.2:阿里270亿参数巨兽开源,消费级显卡就能跑,免费平替Sora上线 |
目录
- 系列篇章💥
- 前言
- 一、项目概述
- 二、技术原理
-
- (一)混合专家(MoE)架构
- (二)扩散模型(Diffusion Model)
- (三)高压缩率3D VAE
- (四)大规模数据训练
- (五)美学数据标注
- 三、主要功能
-
- (一)文生视频(Text-to-Video)
- (二)图生视频(Image-to-Video)
- (三)统一视频生成(Text-Image-to-Video)
- (四)电影级美学控制
- (五)复杂运动生成
- 四、应用场景
-
- (一)短视频创作
- (二)广告与营销
- (三)教育与培训
- (四)影视制作
- (五)新闻与媒体
- 五、性能表现
-
- (一)生成质量
- (二)计算效率
- (三)泛化能力
- (四)与同类模型比较
- 六、快速使用
-
- (一)环境准备
- (二)模型下载
- (三)文生视频(Text-to-Video)生成实践
- (四)图生视频(Image-to-Video)生成实践
- (五)统一视频生成(Text-Image-to-Video)实践
- (六)多GPU推理
- 七、结语
前言
在人工智能飞速发展的当下,AI视频生成技术正逐渐成为内容创作领域的热门研究方向。阿里巴巴开源的通义万相Wan2.2项目,凭借其强大的多模态生成能力和创新的技术架构,为AI视频生成领域带来了新的突破,有望为创作者和企业带来更高效、更优质的视频创作体验。
一、项目概述
通义万相Wan2.2是阿里巴巴开源的先进AI视频生成模型,包含文生视频(Wan2.2-T2V-A14B)、图生视频(Wan2.2-I2V-A14B)和统一视频生成(Wan2.2-IT2V-5B)三款模型,总参数量达270亿 。该项目首次引入混合专家(MoE)架构,有效提升生成质量和计算效率,同时首创电影级美学控制系统,能精准控制光影、色彩、构图等美学效果,支持文本和图像生成视频,可在消费级显卡上运行,为视频创作带来了前所未有的灵活性和高效性。

二、技术原理
(一)混合专家(MoE)架构
通义万相Wan2.2引入了Mixture-of-Experts(MoE)架构,将模型分为高噪声专家和低噪声专家。高噪声专家负责视频的整体布局,低噪声专家负责细节完善。在保持计算成本不变的情况下,大幅提升模型的参数量和生成质量。这种架构设计使得模型在处理复杂的视频生成任务时,能够更好地平衡整体结构与细节表现,从而生成更高质量的视频内容。
(二)扩散模型(Diffusion Model)
基于扩散模型作为基础架构,通过逐步去除噪声来生成高质量的视频内容。MoE架构与扩散模型结合,能进一步优化生成效果。扩散模型在视频生成过程中,通过逐步降低噪声,逐步构建出清晰、连贯的视频帧序列,使得生成的视频在视觉上更加自然、流畅。
(三)高压缩率3D VAE
为提高模型的效率,通义万相2.2基于高压缩率的3D变分自编码器(VAE)。架构实现了时间、空间的高压缩比,让模型能在消费级显卡上快速生成高清视频。这种高压缩率的设计使得模型在不牺牲生成质量的前提下,大幅降低了对硬件资源的需求,使得更多的用户能够在普通的消费级设备上使用该模型进行视频创作。
(四)大规模数据训练
模型在大规模数据集上进行训练,包括更多的图像和视频数据,提升模型在多种场景下的泛化能力和生成质量。通过在海量数据上进行训练,模型能够学习到不同场景、不同风格的视频特征,从而在生成视频时能够更好地适应各种输入条件,生成更具多样性和真实感的视频内容。
(五)美学数据标注
基于精心标注的美学数据(如光影、色彩、构图等),模型能生成具有专业电影质感的视频内容,满足用户对视频美学的定制需求。这种美学数据的引入,使得模型在生成视频时能够更好地理解和应用电影级的美学原则,从而生成更具艺术感和观赏性的视频作品。
三、主要功能
(一)文生视频(Text-to-Video)
用户只需输入一段文本描述,如“一只猫在草地上奔跑”,模型便能根据文本内容生成相应的视频。这一功能极大地简化了视频创作的流程,使得创作者无需复杂的视频拍摄和剪辑技术,仅通过文字描述即可快速生成所需的视频内容,大大提高了创作效率。
(二)图生视频(Image-to-Video)
用户上传一张图片,模型会根据图片内容生成动态视频,让静态图片“活”起来。这一功能为图片创作者提供了一种全新的创作方式,能够将静态的图片转化为具有动态效果的视频,为观众带来更加生动、丰富的视觉体验。
(三)统一视频生成(Text-Image-to-Video)
结合文本描述和图片信息生成视频,能够生成更精准、更符合用户需求的视频内容。通过同时利用文本和图片两种模态的信息,模型能够更准确地理解用户的创作意图,从而生成更具针对性和表现力的视频作品。
(四)电影级美学控制
用户可以通过输入相关关键词(如“暖色调”“中心构图”)来定制视频的美学风格,生成具有专业电影质感的视频。这一功能使得用户能够根据自己的创作需求和审美偏好,对生成的视频进行个性化的美学调整,提升视频的艺术价值和观赏性。
(五)复杂运动生成
能够生成复杂的运动场景和人物交互,提升视频的动态表现力和真实感。这一功能使得模型在生成视频时能够更好地处理复杂的运动场景,生成更加自然、流畅的动态效果,为观众带来更加逼真的视觉体验。

四、应用场景
(一)短视频创作
创作者可以快速生成吸引人的短视频内容,用于社交媒体平台,节省创作时间和成本。在短视频竞争日益激烈的当下,通义万相Wan2.2能够帮助创作者快速产出高质量的视频作品,提升内容的吸引力和传播力。
(二)广告与营销
广告公司和品牌可以利用该模型生成高质量的广告视频,提升广告效果和品牌影响力。通过生成更具创意和吸引力的广告视频,能够更好地吸引消费者的注意力,提高品牌的知名度和美誉度。
(三)教育与培训
教育机构和企业可以生成生动的教育视频和培训材料,提升学习效果和培训质量。将复杂的知识点通过生动的视频形式呈现出来,能够更好地激发学习者的兴趣,提高学习效果。
(四)影视制作
影视制作团队可以快速生成场景设计和动画片段,提升创作效率,降低制作成本。在影视制作过程中,通义万相Wan2.2可以作为一种高效的创意工具,帮助制作团队快速实现创意构思,缩短制作周期,降低制作成本。
(五)新闻与媒体
新闻机构和媒体可以生成动画和视觉效果,增强新闻报道的视觉效果和观众参与度。通过生成更具视觉冲击力的新闻视频,能够更好地吸引观众的注意力,提升新闻报道的传播效果。
五、性能表现
(一)生成质量
通义万相Wan2.2在生成质量上表现出色,能够生成高质量、高分辨率的视频内容。无论是文生视频、图生视频还是统一视频生成,模型都能够生成符合用户输入条件的视频,并且在细节表现、动态效果等方面都具有较高的水平。与前一代模型相比,Wan2.2在生成质量上有显著提升,尤其是在复杂运动场景和人物交互的生成上,表现更加自然、流畅。
(二)计算效率
借助混合专家(MoE)架构和高压缩率3D VAE,通义万相Wan2.2在计算效率上也取得了显著的提升。模型能够在消费级显卡上快速运行,生成高清视频的速度明显加快。例如,5B参数的紧凑视频生成模型可以在单个RTX 4090 GPU上生成5秒720P视频,耗时不到9分钟,这使得模型在实际应用中具有更高的可用性和实用性。
(三)泛化能力
通过在大规模数据集上进行训练,通义万相Wan2.2在多种场景下的泛化能力得到了显著提升。模型能够适应不同的输入条件和创作需求,生成具有多样性和真实感的视频内容。无论是在不同的主题、风格还是场景下,模型都能够生成高质量的视频作品,展现出良好的泛化性能。
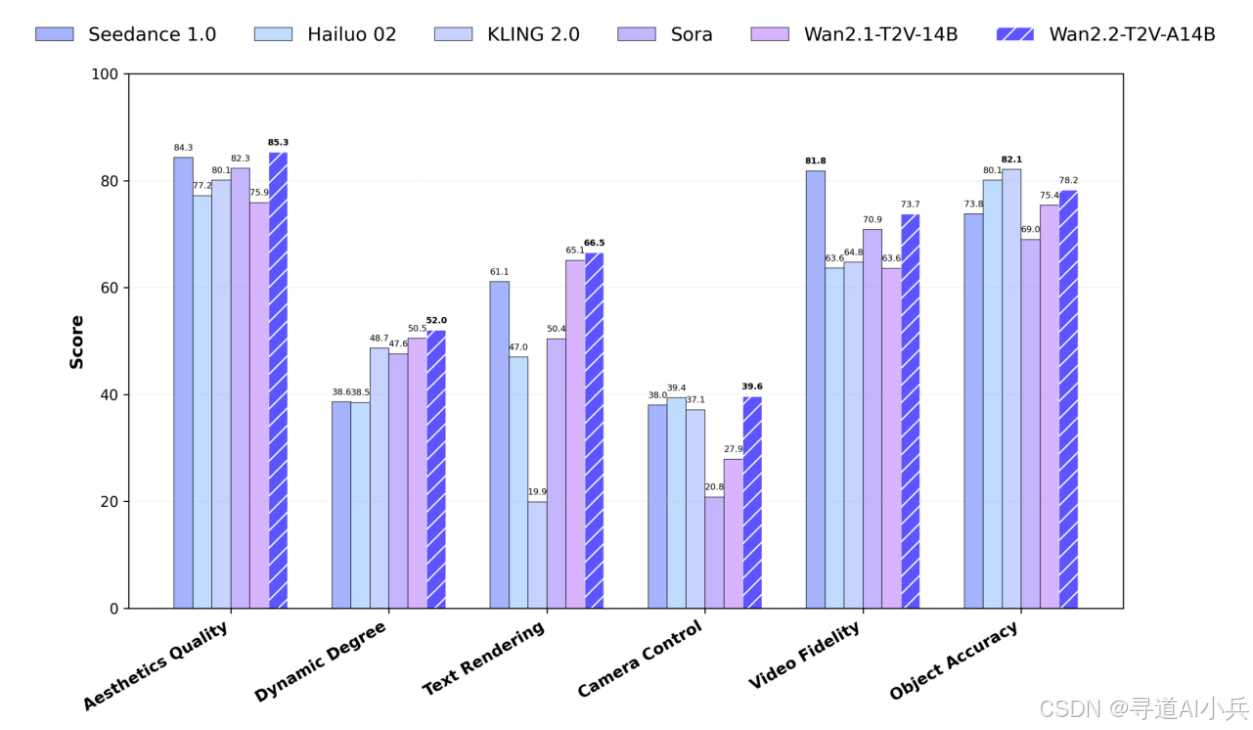
(四)与同类模型比较
在与同类AI视频生成模型的比较中,通义万相Wan2.2在多个方面都表现出色。在生成质量上,Wan2.2能够生成更加细腻、逼真的视频内容;在计算效率上,Wan2.2能够在更低的硬件资源消耗下实现更快的生成速度;在功能多样性上,Wan2.2提供了多种生成模式和美学控制功能,能够满足用户在不同场景下的创作需求。总体而言,通义万相Wan2.2在当前的AI视频生成领域中具有较强的竞争力。
六、快速使用
(一)环境准备
在开始使用通义万相Wan2.2之前,需要先准备好相应的开发环境。建议使用Python 3.8及以上版本,并确保安装了PyTorch 2.4.0及以上版本。此外,还需要安装一些依赖库,可以通过以下命令进行安装:
pip install -r requirements.txt
(二)模型下载
通义万相Wan2.2提供了多种模型可供选择,用户可以根据自己的需求下载相应的模型。例如,下载5B参数的统一视频生成模型(Wan2.2-TI2V-5B),可以通过以下命令进行下载:
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-TI2V-5B --local-dir ./Wan2.2-TI2V-5B
或者使用ModelScope进行下载:
pip install modelscope
modelscope download Wan-AI/Wan2.2-TI2V-5B --local_dir ./Wan2.2-TI2V-5B
(三)文生视频(Text-to-Video)生成实践
以生成一段描述为“一只猫在草地上奔跑”的视频为例,用户可以使用以下命令进行生成:
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "一只猫在草地上奔跑"
在执行该命令后,模型会根据输入的文本描述生成相应的视频内容,并将其保存在指定的路径下。用户可以通过调整--size参数来设置生成视频的分辨率,通过调整--prompt参数来输入不同的文本描述,从而生成不同内容的视频。
(四)图生视频(Image-to-Video)生成实践
如果用户想要根据一张图片生成视频,可以使用以下命令:
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "描述图片内容的文本"
在该命令中,--image参数用于指定输入的图片路径,--prompt参数用于输入对图片内容的描述。模型会根据图片内容和文本描述生成一段动态视频,使得图片中的场景“活”起来。
(五)统一视频生成(Text-Image-to-Video)实践
结合文本和图片生成视频时,用户可以使用以下命令:
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "结合文本和图片描述的详细内容"
通过同时输入文本描述和图片,模型能够生成更加精准、更具表现力的视频内容。用户可以根据自己的创作需求,灵活地调整文本和图片的输入内容,以生成满足特定需求的视频作品。
(六)多GPU推理
对于需要更高生成速度的场景,通义万相Wan2.2支持多GPU推理。用户可以通过以下命令进行多GPU推理:
torchrun --nproc_per_node=8 generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --dit_fsdp --t5_fsdp --ulysses_size 8 --image examples/i2v_input.JPG --prompt "描述内容"
在该命令中,--nproc_per_node参数用于指定每个节点上的GPU数量,--ulysses_size参数用于指定分布式训练的规模。通过多GPU推理,可以显著加快视频生成的速度,提高模型的运行效率。
七、结语
通义万相Wan2.2作为阿里巴巴开源的先进AI视频生成模型,凭借其强大的技术实力和丰富的功能特性,为AI视频生成领域带来了新的突破。无论是创作者、广告公司、教育机构还是影视制作团队,都可以通过使用通义万相Wan2.2,快速生成高质量的视频内容,提升创作效率和作品质量。随着技术的不断发展和优化,相信通义万相Wan2.2将在更多的领域发挥重要作用,为视频创作带来更多的可能性和创新。感兴趣的读者可以通过以下
项目地址
- GitHub仓库:https://github.com/Wan-Video/Wan2.2
- HuggingFace模型库:https://huggingface.co/Wan-AI/models

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!
© 版权声明
文章版权归作者所有,未经允许请勿转载。


