巾帼力量助力 Flink 引擎 CDC 源模式演进支持 | Apache SeaTunnel 开源之夏成果
实现思路
我的实现灵感主要来自于 Flink CDC 项目的设计思路。在研究 Flink CDC 的 schema evolution 实现后结合 Apache SeaTunnel 的架构特点,设计了一套适配 Flink 引擎的 schema 演化方案。
具体实现时序图如下:
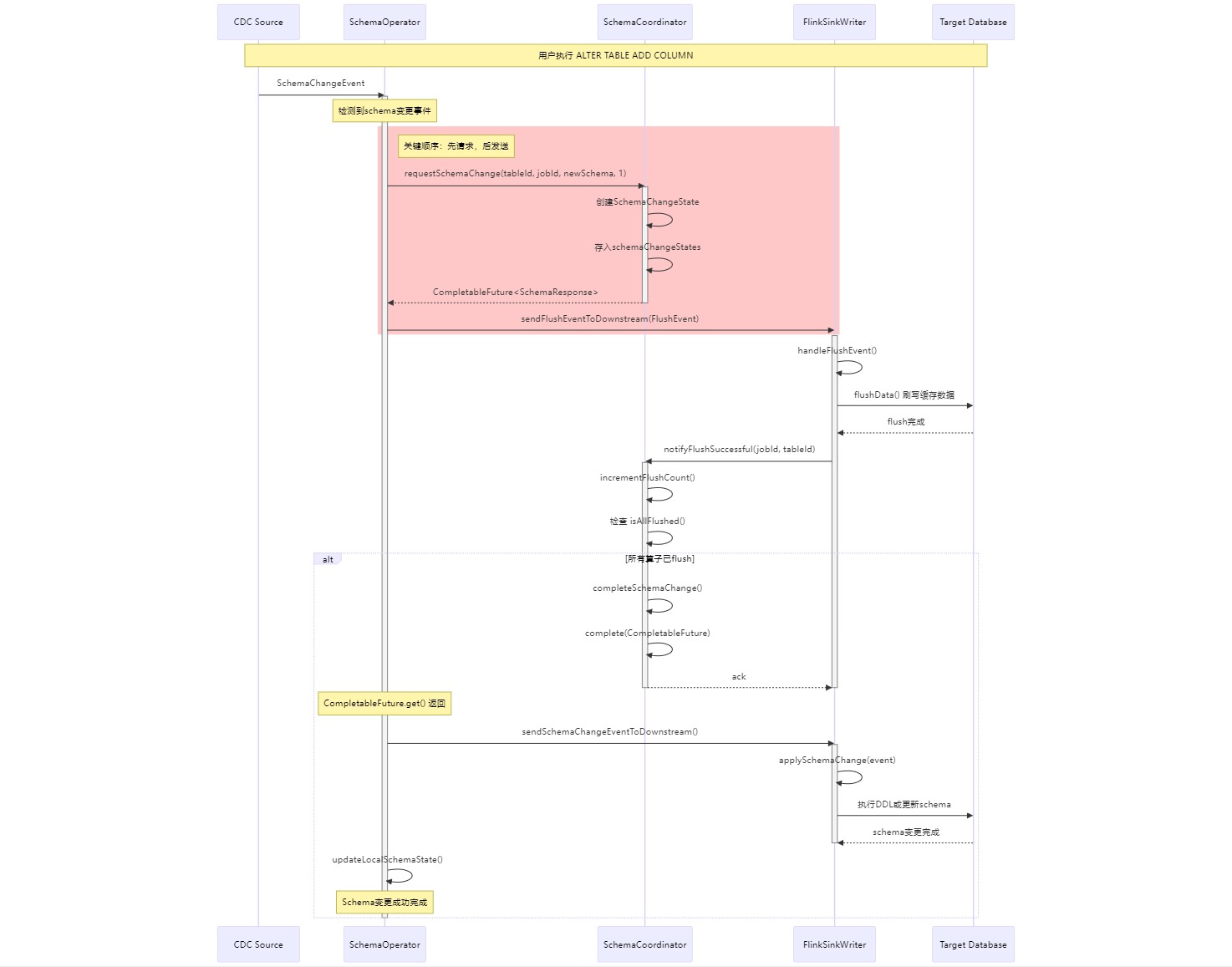
核心架构设计包含以下几个关键组件:
-
SchemaCoordinator
-
职责:这是整个方案的核心协调中心,负责全局 schema 变更的状态管理和同步协调
-
实现细节:
-
维护了 schemaChangeStates 映射表,记录每个表的 schema 变更状态
-
通过 schemaVersions 跟踪每个表的 schema 版本号
-
使用 ReentrantLock 锁机制保证多个并发 schema 变更请求的线程安全
-
维护 pendingRequests 队列,管理等待 schema 变更完成的 CompletableFuture
-
-
-
SchemaOperator
-
职责:插入在 CDC Source 和 Sink 之间的专用算子,负责拦截和处理 schema 变更事件
-
实现细节:
-
在 processElement () 方法中检测 SchemaChangeEvent
-
调用 processSchemaChangeEvent () 处理 schema 变更流程
-
维护 currentSchemaChangeFuture 用于支持 schema 变更的取消和回滚
-
通过 lastProcessedEventTime 防止重复处理旧的 schema 变更事件
-
-
遇到的关键问题及解决过程:
在开发过程中,我遇到了一个比较棘手的问题:在 processElement 方法中处理 schema 变更事件时,整个流程会卡住,不再继续处理后续数据,只会不断地执行 checkpoint 流程。
通过仔细分析日志,我发现了问题的根源:
2025-08-17 12:33:36,597 INFO FlinkSinkWriter - FlinkSinkWriter handled FlushEvent for table: .schema_test.products
2025-08-17 12:33:36,597 INFO SchemaOperator - FlushEvent sent to downstream for table: .schema_test.products
2025-08-17 12:33:36,597 INFO SchemaCoordinator - Processing schema change for table: .schema_test.products
2025-08-17 12:33:36,598 WARN SchemaCoordinator - No schema change state found for table: .schema_test.products
从这些日志可以看出,先发送了 FlushEvent 到下游,FlinkSinkWriter 处理完 FlushEvent 后尝试通知 SchemaCoordinator,但此时 SchemaCoordinator 还没有初始化 schema change state(因为请求协调器的代码还没执行),导致通知失败。SchemaOperator 中的 schemaChangeFuture.get() 方法会一直等待,直到 60 秒超时。
之后通过观察日志状态,我调整了执行顺序,将原本 “先发送 FlushEvent,后请求 SchemaCoordinator” 的逻辑,改为 “先请求 SchemaCoordinator 创建状态,后发送 FlushEvent“ **,就比如这里:
CompletableFuture<SchemaResponse> schemaChangeFuture =
schemaCoordinator.requestSchemaChange(
tableId, jobId, schemaChangeEvent.getChangeAfter(), 1);
currentSchemaChangeFuture.set(schemaChangeFuture);
sendFlushEventToDownstream(schemaChangeEvent); // 在请求协调器之后才发送
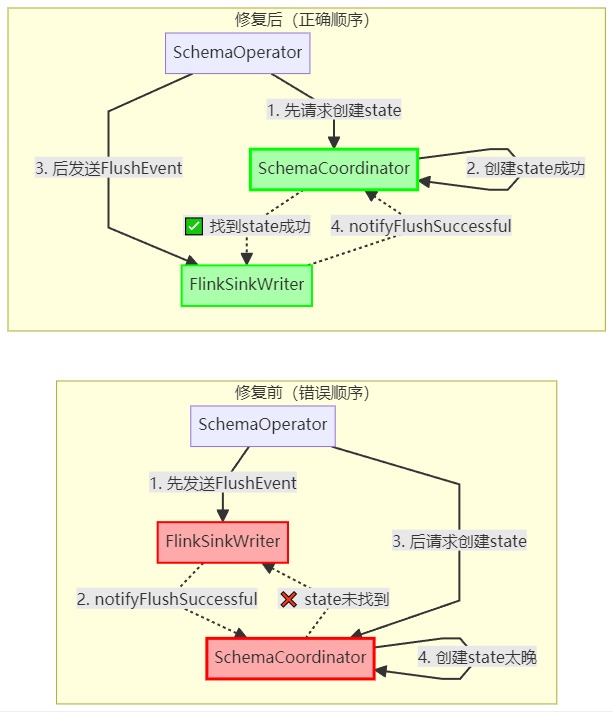
这样确保 SchemaCoordinator 先创建好 schema change state,之后请求的时候就不会返回空,然后算子将 FlushEvent 被发送到下游,下游处理完 FlushEvent 后,因为此时 state 已经存在,就可以成功通知 SchemaCoordinator,SchemaCoordinator 收到通知后,完成 schema change 的 CompletableFuture,之后 processSchemaChangeEvent 方法的等待结束,继续执行后续流程。
项目成果
-
解决的问题:
- 实现了 Flink 引擎上的实时 schema 演化能力,用户在使用 Flink 引擎进行 CDC 同步时,源表发生 schema 变更后无需重启任务
- 提供了完整的 schema 变更协调机制,确保多算子之间的 schema 变更同步
-
为用户带来的好处:
- 业务连续性提升:schema 变更不再需要停机,大大提高了数据同步的可用性
- 运维成本降低:减少了人工干预,避免了频繁的任务重启
- 数据一致性保障:通过 FlushEvent 机制确保 schema 变更前后的数据一致性
- 引擎选择灵活性:用户可以根据自己的需要选择 Flink 引擎或 SeaTunnel 引擎,都能获得 schema evolution 能力
-
技术贡献:
- 新增了 SchemaCoordinator 全局协调器
- 新增了 FlushEvent 事件类型和处理机制
- 在 Flink translation 层实现了完整的 schema evolution 适配
-
改进方向:
- 多并行度支持:设计并实现多并行度场景下的 flush 协调机制,可能需要引入并行度感知的计数器和更细粒度的状态管理
- 状态持久化:考虑将 SchemaCoordinator 改造为 Flink 的 Operator 或利用 Flink 的 BroadcastState,使其状态能够参与 checkpoint
同时,为了更好地了解同学们在参与开源之夏项目中的开发心得和感受,Apache SeaTunnel 对同学们进行了简短的采访,以下为采访实录:
Q:在众多项目中,为什么选择参与 Apache SeaTunnel 的项目?
A:我选择参与 Apache SeaTunnel 项目,主要有这样几点考虑:第一是它的技术方向和我已有的经验非常契合。之前在一家初创公司实习时,我们就是用 SeaTunnel 做数据集成,支持数据仓库的搭建。我自己也常用 Flink 开发数据处理管道、搭建实时血缘系统,对数据集成和实时同步这个领域很感兴趣。SeaTunnel 作为新一代数据集成平台,技术栈新、架构清晰,我觉得很适合深入学习并做出贡献。
而且,Apache SeaTunnel 社区氛围特别好,社区非常活跃,大家响应也很及时,对像我这样初次参与开源的同学来说非常友好,CDC schema evolution 这个功能解决的是真实场景中的痛点,能看到自己写的代码真正帮助到用户,会很有成就感。
Q:Apache SeaTunnel 的项目与你的学业有什么交集吗?
A: 有挺多交集的。比如我们大数据处理课程中讲到的 Flink、StarRocks 等框架,在 SeaTunnel 里都有深入的应用。大二时为了处理 Spark 相关的微批次任务,我还用过 StreamPark,所以对数据集成这一块也比较熟悉。参与 SeaTunnel 项目,正好能把课堂上学到的理论知识在实际项目中落地,加深理解。
Q:参与这个项目给你的学业和未来个人规划带来了哪些影响?
这个项目让我收获很大。比如,为了理解 CDC 的实现,我深入阅读了 Flink CDC 的源码,对 Flink 的运行机制、分布式协调、异步编程等有了更扎实的理解。
同时,在导师的指导下,我也学会了如何在大型开源项目中协作:包括代码规范、PR 流程、测试覆盖等工程实践,为我未来的开源参与打下了很好的基础。更重要的是,通过这个项目,我明确了自己对数据基础架构方向的兴趣,未来也希望在这个领域继续深耕。
Q: 参与这个项目的过程中您遇到的最大的挑战是什么?是如何克服的?
A: 最大的挑战是遇到一个比较棘手的技术问题:在实现过程中,processElement 方法会卡住,只做 checkpoint 却不继续处理数据。此外,在架构设计上,如何将新功能优雅地集成到现有系统中,也比我预想的要复杂。
为解决这些问题,除了自己反复调试、查阅资料,也积极向导师和社区伙伴请教。大家的建议给了我很多启发,也帮助我逐步理清了思路。
Q: 您参与开源有多长时间了?喜欢开源吗?开源给你带来了哪些改变?
A: 这是我第一次正式参与开源。虽然之前在公司实习时也写过一些内部功能的代码,但向社区提交 PR 还是第一次。我非常喜欢开源。最吸引我的是那种开源的氛围 —— 大家为了一个共同的目标,公开讨论、协作贡献,每个人都能在过程中学习和成长。这种开放、共享的精神,让我觉得特别有意义。
Q: 您之前是否了解过或使用过 Apache SeaTunnel 或其他数据集成产品?
之前实习时就用过 SeaTunnel,主要是做不同数据源之间的同步,比如从 Kafka 到 Hive,或者从 Kafka 到 StarRocks。Flink CDC 我也接触过,主要用在 CDC Source 的流式集成场景。相比之下,SeaTunnel 支持三种执行引擎,既能做流处理也能做批处理,覆盖的场景更全面。如果未来再选择数据集成工具,我会优先考虑 SeaTunnel—— 一是功能全面,二是配置起来也比较方便。
Q: Apache SeaTunnel 社区贡献给您的第一印象是怎样的?您希望在这里有何收获?
A: 第一印象特别好:社区氛围友好,Mentor 响应及时,代码 Review 也非常认真细致。我希望在这里能继续认识更多志同道合的朋友,为社区做出有价值的贡献,同时也精进自己的技术水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。