Java 大视界 — Java 大数据在智能物流仓储货位优化与库存周转率提升中的应用实战

Java 大视界 — Java 大数据在智能物流仓储货位优化与库存周转率提升中的应用实战
- 引言:
- 正文:
-
-
- 一、传统智能物流仓储的困境与挑战
-
- 1.1 货位管理:无序中的效率瓶颈
- 1.2 库存管理:积压与缺货并存的矛盾
- 二、Java 大数据:智能物流仓储的破局之道
-
- 2.1 全链路数据采集与处理:构建仓储数字孪生体
- 2.2 智能货位优化:算法驱动的空间革命
- 2.3 库存周转率提升:精准预测与智能协同
- 三、实战案例:京东亚洲一号智能仓的数字化转型
-
- 3.1 货位优化实践
- 3.2 库存管理创新
- 四、技术挑战与未来展望
-
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!每一次对技术边界的突破,都印证着 Java 大数据在不同领域的无限可能。而今天,我们将目光投向智能物流仓储领域 —— 这片承载着全球贸易流通的关键枢纽,正经历着从传统人力驱动向数据智能驱动的深刻变革。
想象一个日均处理数十万件商品的现代化智能仓库:机械臂精准地抓取货物,AGV 小车沿着最优路径穿梭,库存数据如同鲜活的生命体实时更新。这并非科幻场景,而是 Java 大数据赋能下的真实写照。当传统仓储在货位混乱、库存失衡的困境中举步维艰时,Java 大数据以其强大的数据处理与分析能力,成为重塑智能物流仓储的核心力量,开启了仓储管理的 “数字革命”。

正文:
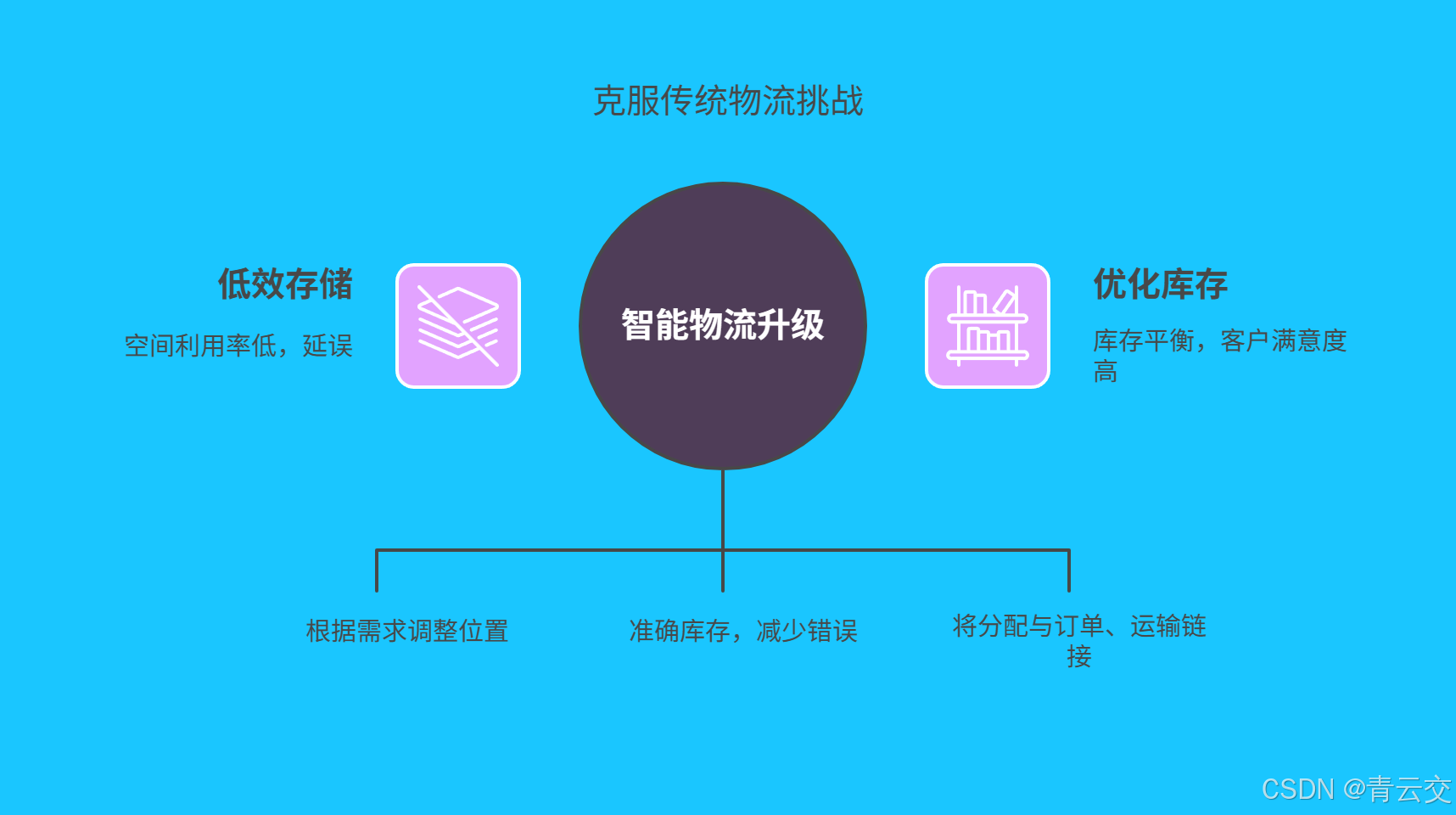
一、传统智能物流仓储的困境与挑战
1.1 货位管理:无序中的效率瓶颈
在传统物流仓储中,货位分配往往依赖人工经验和简单规则,这种 “拍脑袋” 式的管理方式导致仓储空间利用效率低下。根据行业调研数据显示,传统仓储的平均空间利用率仅为 55%-60%,部分仓库甚至低于 50%。由于缺乏科学的货位规划,高频出货商品可能被放置在远离分拣区的角落,而低频商品却占据着黄金位置,使得拣货员每日行走里程可达 10-15 公里,拣货效率严重受限。
| 问题类型 | 具体表现 | 典型影响 |
|---|---|---|
| 静态货位规划 | 货位布局长期固定,不随业务变化调整 | 仓储效率随业务增长持续下降 |
| 信息滞后性 | 货位变动依赖人工记录,存在延迟和误差 | 库存数据准确率不足 85% |
| 缺乏协同性 | 货位分配未与订单、运输环节联动 | 订单履约时效平均延长 2-3 小时 |
1.2 库存管理:积压与缺货并存的矛盾
传统库存预测主要基于历史数据的简单统计分析,难以应对市场需求的快速变化。某知名服装品牌曾因对流行趋势误判,导致当季库存积压超 10 万件,直接经济损失达 5000 万元;而在生鲜电商领域,因库存不足导致的订单流失率高达 15%-20%。这种库存失衡不仅造成资金占用和资源浪费,更直接影响客户满意度和企业竞争力。
二、Java 大数据:智能物流仓储的破局之道
2.1 全链路数据采集与处理:构建仓储数字孪生体
Java 凭借其跨平台性、高稳定性以及庞大的开源生态,搭建起覆盖仓储全生命周期的数据采集网络。从货物入库时的基础信息(如商品条码、品类、重量、保质期),到存储过程中的环境数据(温湿度、光照、货架承重),再到出库时的订单信息(客户地址、配送时效要求),所有数据均通过传感器、RFID 标签、扫码设备等终端实时采集,并传输至分布式存储系统(如 HDFS)。
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.functions;
public class WarehouseDataPipeline {
public static void main(String[] args) {
// 初始化SparkSession,配置应用名称和运行模式
SparkSession spark = SparkSession.builder()
.appName("WarehouseDataProcessing")
.master("local[*]")
.getOrCreate();© 版权声明
文章版权归作者所有,未经允许请勿转载。