【数据分析】基于大数据的脱发影响因素分析与可视化系统 | 大数据可视化大屏 大数据实战项目 选题推荐 hadoop SPark
💖💖作者:计算机毕业设计江挽
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💜💜
网站实战项目
安卓/小程序实战项目
大数据实战项目
深度学习实战项目
目录
- 基于大数据的脱发影响因素分析与可视化系统系统介绍
- 基于大数据的脱发影响因素分析与可视化系统系统演示视频
- 基于大数据的脱发影响因素分析与可视化系统系统演示图片
- 基于大数据的脱发影响因素分析与可视化系统系统代码展示
- 基于大数据的脱发影响因素分析与可视化系统系统文档展示
基于大数据的脱发影响因素分析与可视化系统系统介绍
基于大数据的脱发影响因素分析与可视化系统是一个综合运用Hadoop分布式存储和Spark大数据处理技术的数据分析平台。系统采用Hadoop+Spark作为核心大数据框架,通过HDFS实现海量脱发相关数据的分布式存储,利用Spark SQL和Pandas进行高效的数据清洗、转换与统计分析。后端基于Django框架构建RESTful API接口,前端采用Vue+ElementUI+Echarts技术栈实现交互式数据可视化展示。系统功能涵盖用户管理、人口特征统计分析、日常生活习惯分析、医疗营养状况分析、心理压力风险分析、多维度关联性分析以及脱发风险预测等九大核心模块。通过Spark SQL对大规模脱发数据集进行多维度交叉分析,结合NumPy进行数值计算和统计建模,最终通过Echarts图表库将分析结果以柱状图、饼图、折线图、热力图等多种可视化形式呈现,帮助用户直观理解不同因素对脱发的影响程度及其内在关联关系,为脱发预防和干预提供数据支撑。
基于大数据的脱发影响因素分析与可视化系统系统演示视频
演示视频
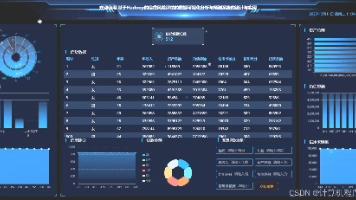
基于大数据的脱发影响因素分析与可视化系统系统演示图片
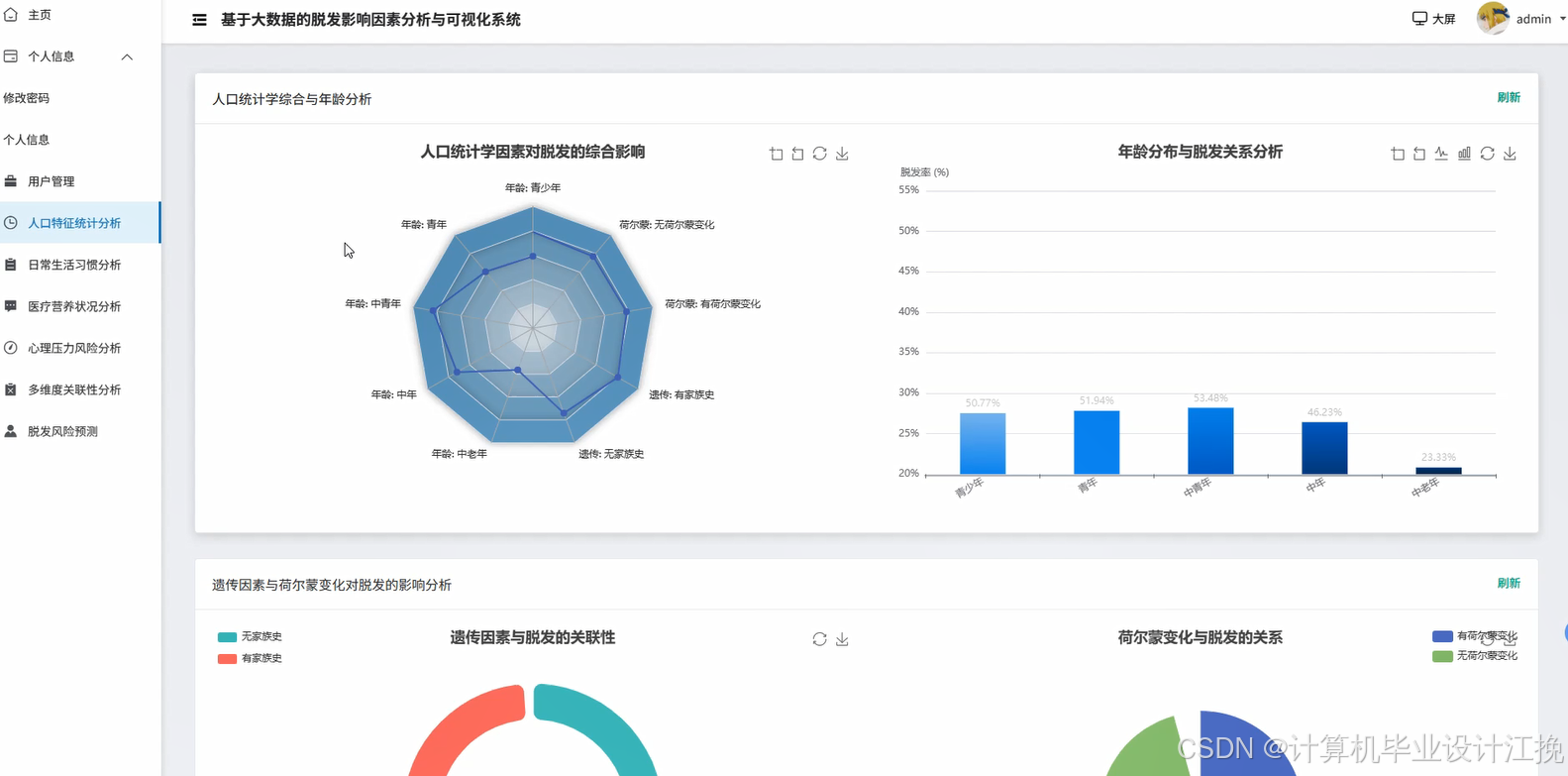
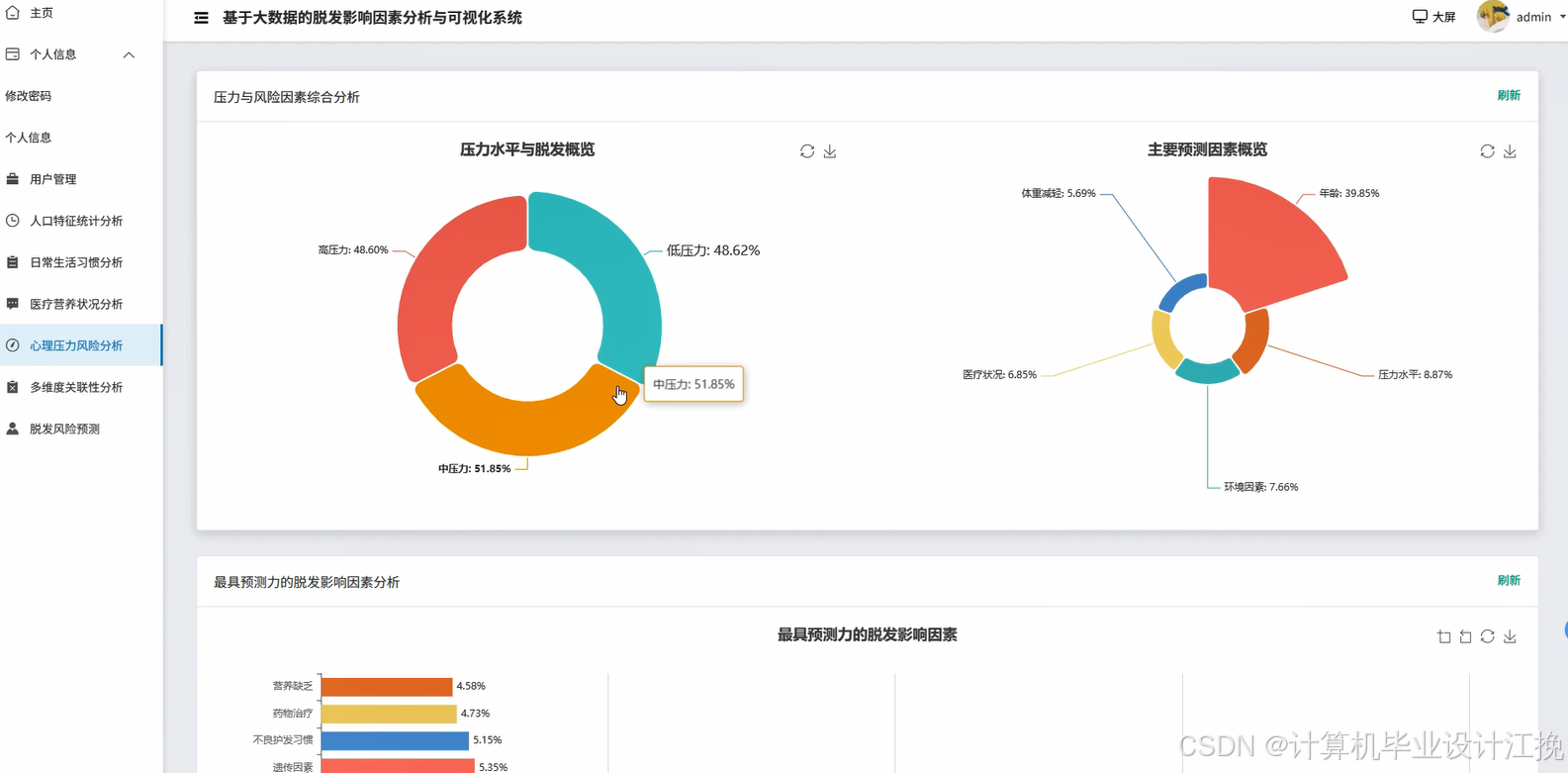
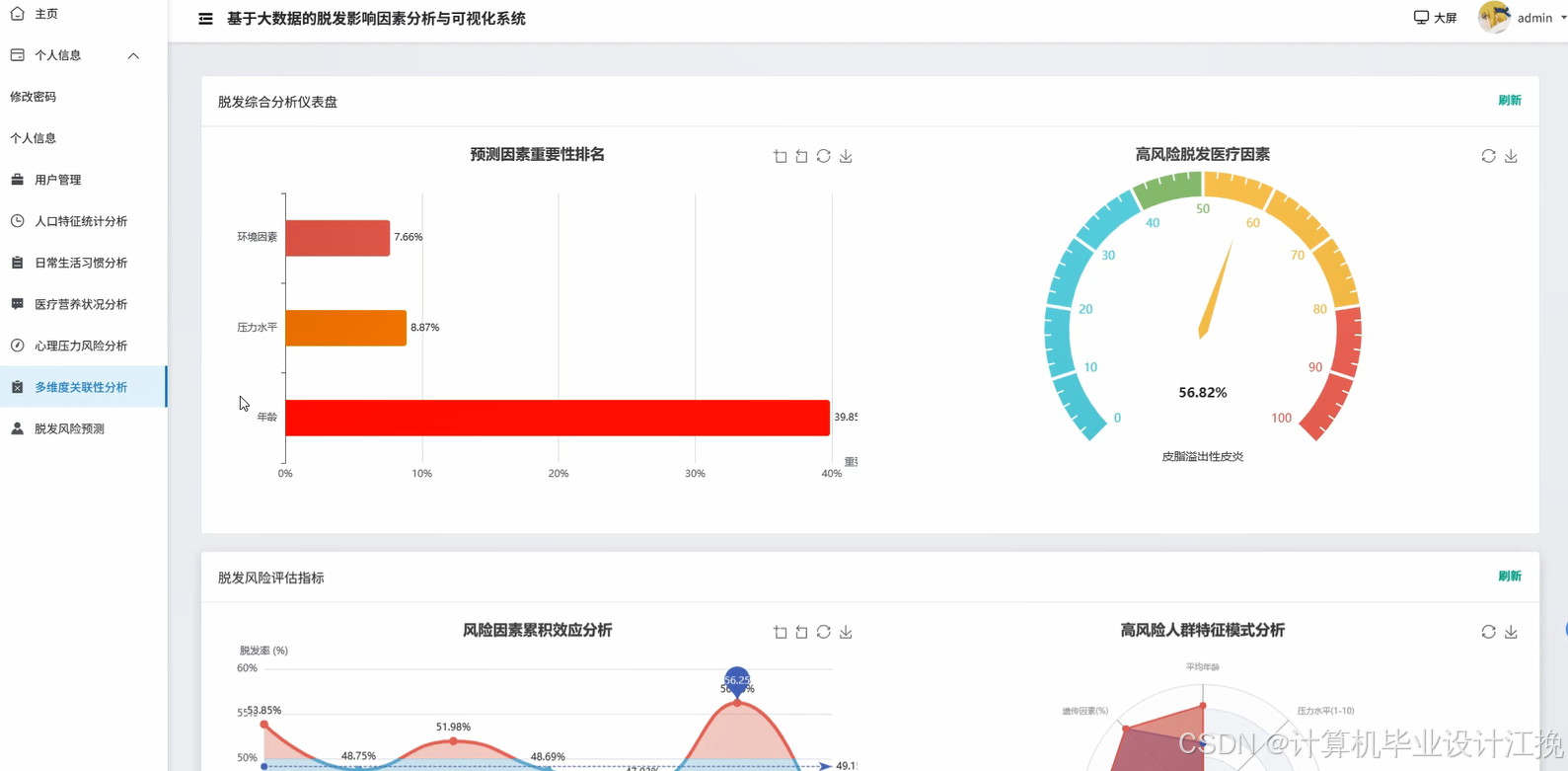
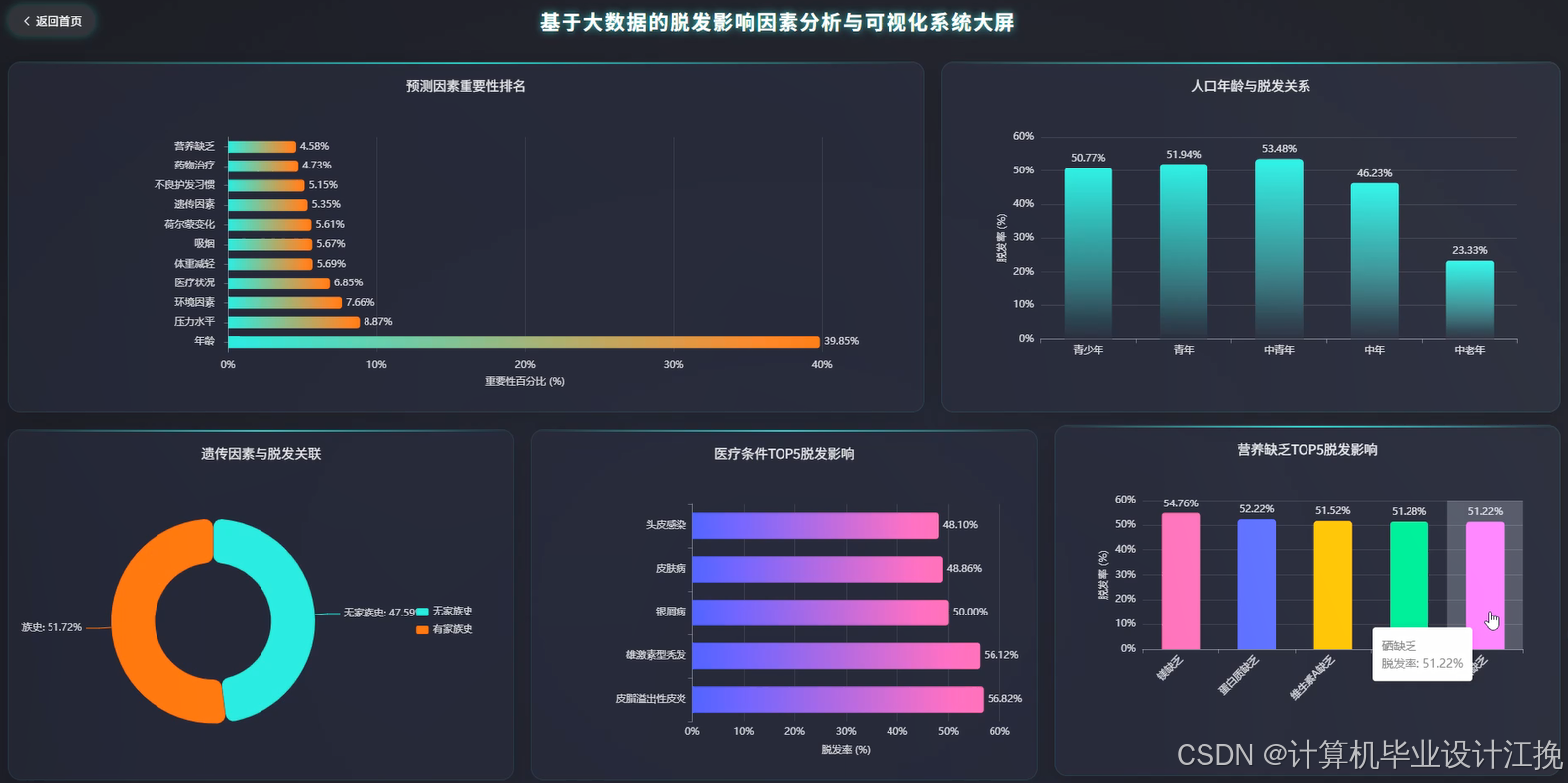
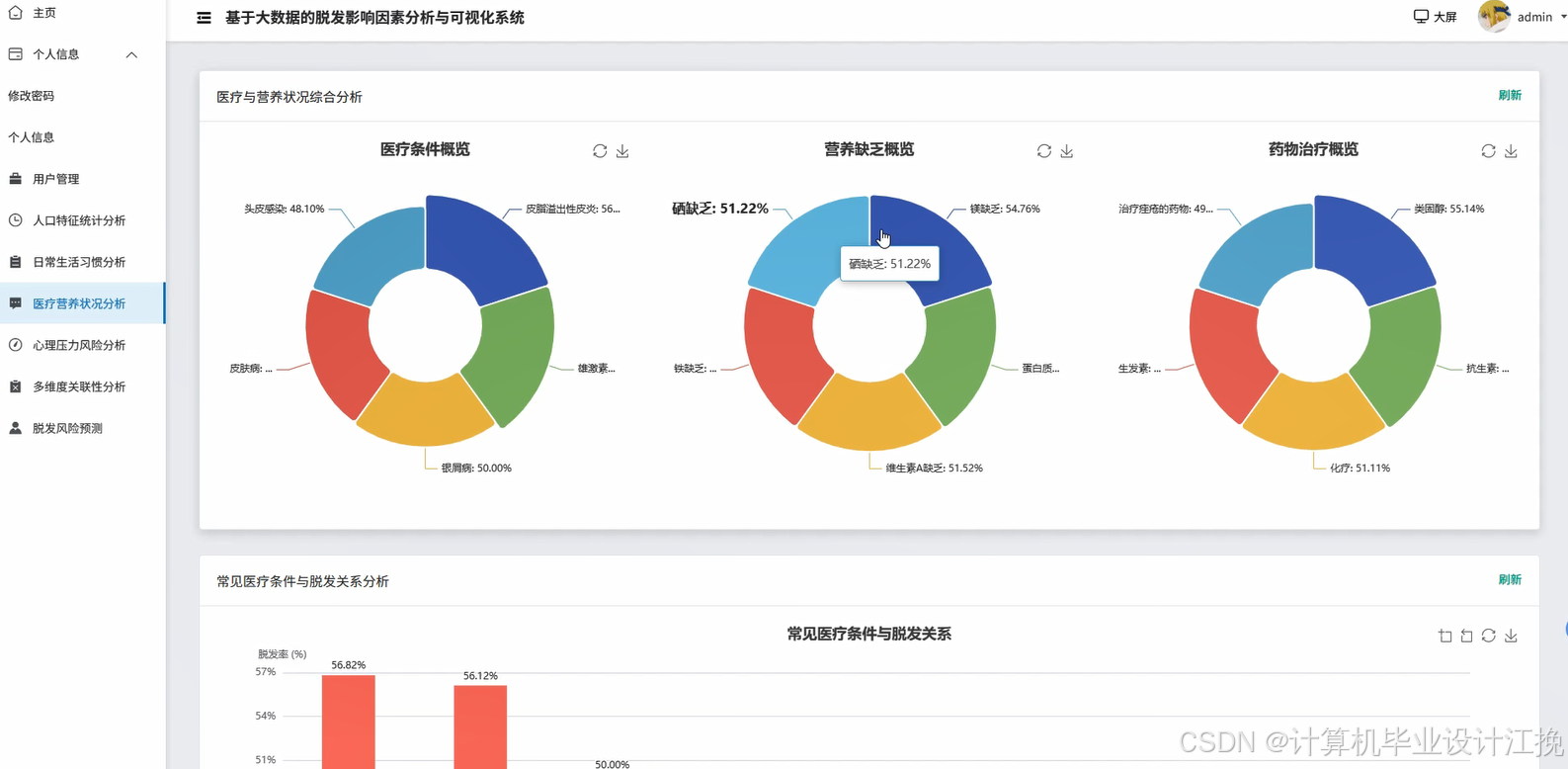
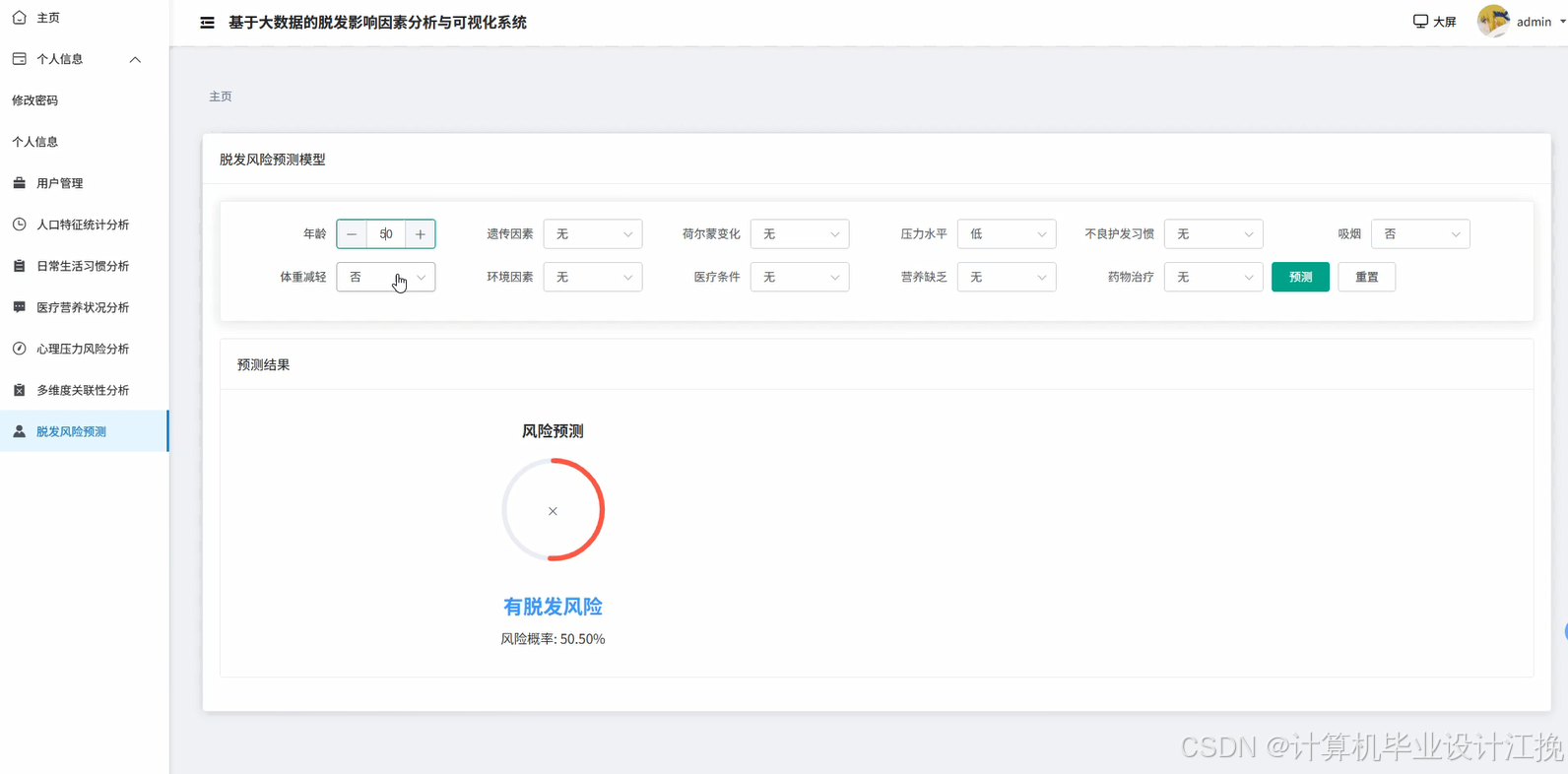
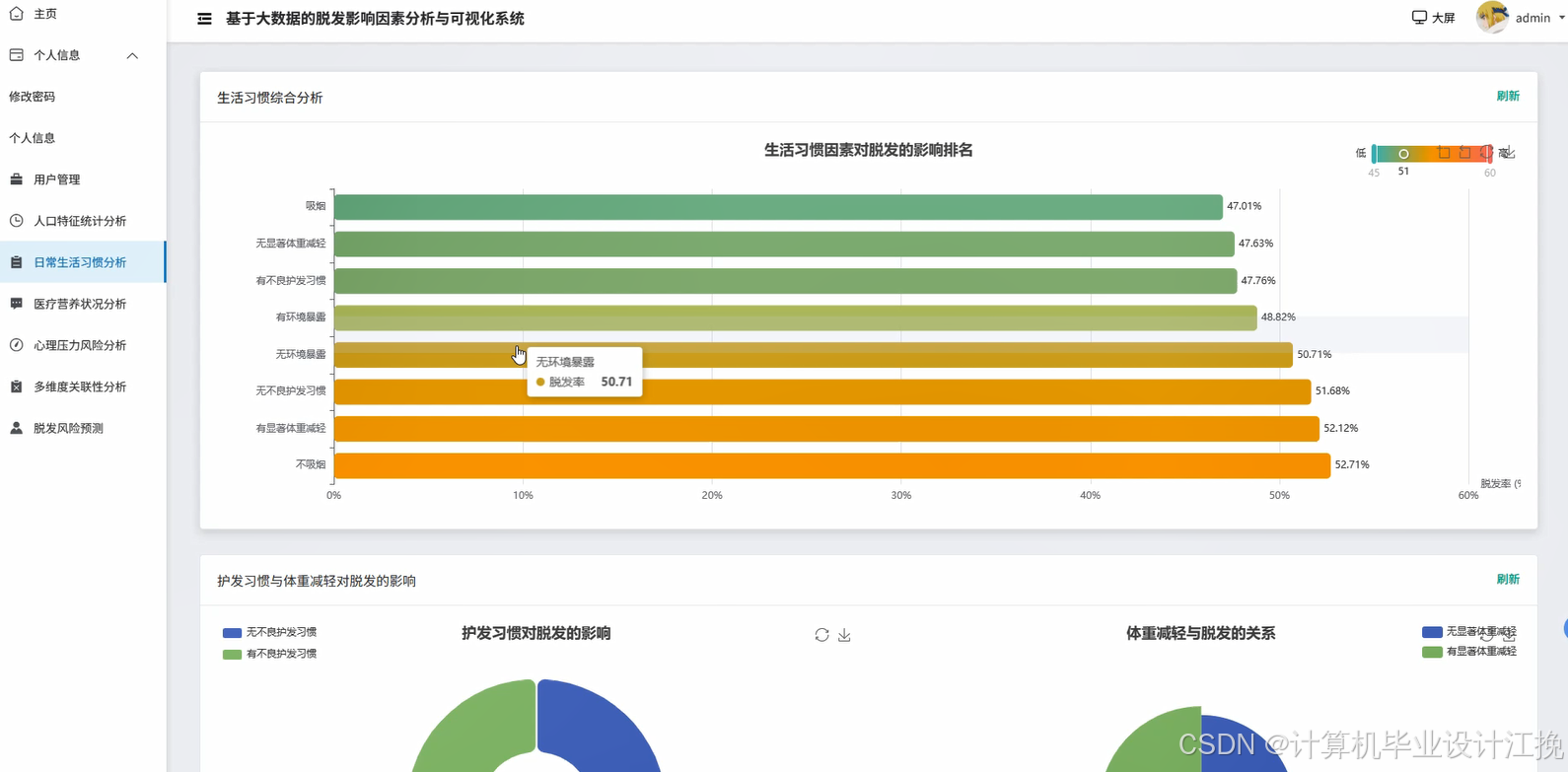
基于大数据的脱发影响因素分析与可视化系统系统代码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, when, sum as spark_sum, round as spark_round
from django.http import JsonResponse
from django.views import View
import pandas as pd
import numpy as np
from datetime import datetime
spark = SparkSession.builder.appName("HairLossAnalysis").config("spark.sql.warehouse.dir", "/user/hive/warehouse").config("spark.executor.memory", "2g").config("spark.driver.memory", "1g").getOrCreate()
class PopulationAnalysisView(View):
def get(self, request):
try:
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/hairloss_db").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "user_hairloss_data").option("user", "root").option("password", "123456").load()
df.createOrReplaceTempView("hairloss_data")
age_distribution = spark.sql("SELECT CASE WHEN age < 20 THEN '20岁以下' WHEN age BETWEEN 20 AND 30 THEN '20-30岁' WHEN age BETWEEN 31 AND 40 THEN '31-40岁' WHEN age BETWEEN 41 AND 50 THEN '41-50岁' ELSE '50岁以上' END as age_group, COUNT(*) as count, ROUND(AVG(CASE WHEN hairloss_level >= 3 THEN 1 ELSE 0 END) * 100, 2) as hairloss_rate FROM hairloss_data GROUP BY age_group ORDER BY age_group")
age_data = age_distribution.toPandas().to_dict('records')
gender_analysis = spark.sql("SELECT gender, COUNT(*) as total_count, SUM(CASE WHEN hairloss_level >= 3 THEN 1 ELSE 0 END) as hairloss_count, ROUND(AVG(hairloss_level), 2) as avg_level FROM hairloss_data GROUP BY gender")
gender_data = gender_analysis.toPandas().to_dict('records')
region_stats = spark.sql("SELECT region, COUNT(*) as count, ROUND(AVG(hairloss_level), 2) as avg_hairloss, MAX(hairloss_level) as max_level FROM hairloss_data GROUP BY region ORDER BY avg_hairloss DESC LIMIT 10")
region_data = region_stats.toPandas().to_dict('records')
occupation_risk = spark.sql("SELECT occupation, COUNT(*) as count, ROUND(SUM(CASE WHEN hairloss_level >= 4 THEN 1 ELSE 0 END) * 100.0 / COUNT(*), 2) as high_risk_rate FROM hairloss_data GROUP BY occupation HAVING COUNT(*) >= 10 ORDER BY high_risk_rate DESC")
occupation_data = occupation_risk.toPandas().to_dict('records')
correlation_matrix = df.select('age', 'bmi', 'hairloss_level').toPandas()
corr_result = np.corrcoef(correlation_matrix.values.T)
correlation_data = {'age_hairloss': float(corr_result[0, 2]), 'bmi_hairloss': float(corr_result[1, 2])}
result = {'age_distribution': age_data, 'gender_analysis': gender_data, 'region_stats': region_data, 'occupation_risk': occupation_data, 'correlation': correlation_data, 'timestamp': datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
return JsonResponse({'code': 200, 'message': '人口特征分析成功', 'data': result})
except Exception as e:
return JsonResponse({'code': 500, 'message': f'分析失败: {str(e)}'})
class LifestyleAnalysisView(View):
def get(self, request):
try:
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/hairloss_db").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "lifestyle_data").option("user", "root").option("password", "123456").load()
df.createOrReplaceTempView("lifestyle")
sleep_analysis = spark.sql("SELECT CASE WHEN sleep_hours < 6 THEN '严重不足' WHEN sleep_hours BETWEEN 6 AND 7 THEN '不足' WHEN sleep_hours BETWEEN 7 AND 8 THEN '正常' ELSE '充足' END as sleep_category, COUNT(*) as count, ROUND(AVG(hairloss_score), 2) as avg_score, ROUND(STDDEV(hairloss_score), 2) as std_score FROM lifestyle GROUP BY sleep_category ORDER BY avg_score DESC")
sleep_data = sleep_analysis.toPandas().to_dict('records')
exercise_impact = spark.sql("SELECT exercise_frequency, COUNT(*) as user_count, ROUND(AVG(hairloss_score), 2) as avg_hairloss, MIN(hairloss_score) as min_score, MAX(hairloss_score) as max_score FROM lifestyle GROUP BY exercise_frequency ORDER BY CASE exercise_frequency WHEN '从不' THEN 1 WHEN '偶尔' THEN 2 WHEN '每周1-2次' THEN 3 WHEN '每周3-5次' THEN 4 ELSE 5 END")
exercise_data = exercise_impact.toPandas().to_dict('records')
diet_pattern = spark.sql("SELECT diet_type, smoking, drinking, COUNT(*) as count, ROUND(AVG(hairloss_score), 2) as avg_score FROM lifestyle GROUP BY diet_type, smoking, drinking HAVING COUNT(*) >= 5 ORDER BY avg_score DESC")
diet_data = diet_pattern.toPandas().to_dict('records')
screen_time_analysis = spark.sql("SELECT CASE WHEN screen_hours < 4 THEN '低' WHEN screen_hours BETWEEN 4 AND 8 THEN '中' ELSE '高' END as screen_level, ROUND(AVG(hairloss_score), 2) as avg_score, COUNT(*) as count FROM lifestyle GROUP BY screen_level")
screen_data = screen_time_analysis.toPandas().to_dict('records')
lifestyle_df = df.select('sleep_hours', 'exercise_frequency', 'screen_hours', 'hairloss_score').toPandas()
lifestyle_df['exercise_numeric'] = lifestyle_df['exercise_frequency'].map({'从不': 0, '偶尔': 1, '每周1-2次': 2, '每周3-5次': 3, '每天': 4})
correlation_matrix = lifestyle_df[['sleep_hours', 'exercise_numeric', 'screen_hours', 'hairloss_score']].corr()
lifestyle_correlation = {'sleep_hairloss': float(correlation_matrix.loc['sleep_hours', 'hairloss_score']), 'exercise_hairloss': float(correlation_matrix.loc['exercise_numeric', 'hairloss_score']), 'screen_hairloss': float(correlation_matrix.loc['screen_hours', 'hairloss_score'])}
combined_risk = spark.sql("SELECT CASE WHEN sleep_hours < 6 AND screen_hours > 8 THEN '高危组合' WHEN sleep_hours < 7 AND exercise_frequency = '从不' THEN '中危组合' ELSE '低危组合' END as risk_group, COUNT(*) as count, ROUND(AVG(hairloss_score), 2) as avg_score FROM lifestyle GROUP BY risk_group ORDER BY avg_score DESC")
risk_data = combined_risk.toPandas().to_dict('records')
result = {'sleep_analysis': sleep_data, 'exercise_impact': exercise_data, 'diet_pattern': diet_data, 'screen_time': screen_data, 'correlation': lifestyle_correlation, 'combined_risk': risk_data, 'analysis_time': datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
return JsonResponse({'code': 200, 'message': '生活习惯分析完成', 'data': result})
except Exception as e:
return JsonResponse({'code': 500, 'message': f'分析异常: {str(e)}'})
class MultiDimensionalCorrelationView(View):
def post(self, request):
try:
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/hairloss_db").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "comprehensive_data").option("user", "root").option("password", "123456").load()
df.createOrReplaceTempView("comprehensive")
stress_nutrition_analysis = spark.sql("SELECT stress_level, nutrition_score, COUNT(*) as count, ROUND(AVG(hairloss_level), 2) as avg_hairloss, ROUND(MAX(hairloss_level), 2) as max_hairloss FROM comprehensive GROUP BY stress_level, nutrition_score HAVING COUNT(*) >= 3 ORDER BY avg_hairloss DESC")
stress_nutrition_data = stress_nutrition_analysis.toPandas().to_dict('records')
age_lifestyle_correlation = spark.sql("SELECT age_group, sleep_quality, exercise_level, ROUND(AVG(hairloss_level), 2) as avg_hairloss, COUNT(*) as sample_size FROM comprehensive GROUP BY age_group, sleep_quality, exercise_level HAVING COUNT(*) >= 5 ORDER BY avg_hairloss DESC LIMIT 20")
age_lifestyle_data = age_lifestyle_correlation.toPandas().to_dict('records')
medical_psychological_impact = spark.sql("SELECT medical_history, psychological_score, ROUND(AVG(hairloss_level), 2) as avg_hairloss, ROUND(STDDEV(hairloss_level), 2) as std_hairloss, COUNT(*) as count FROM comprehensive GROUP BY medical_history, psychological_score HAVING COUNT(*) >= 5 ORDER BY avg_hairloss DESC")
medical_psych_data = medical_psychological_impact.toPandas().to_dict('records')
comprehensive_df = df.select('age', 'stress_level', 'nutrition_score', 'sleep_hours', 'exercise_frequency', 'psychological_score', 'hairloss_level').toPandas()
comprehensive_df['stress_numeric'] = comprehensive_df['stress_level'].map({'低': 1, '中': 2, '高': 3, '极高': 4})
comprehensive_df['exercise_numeric'] = comprehensive_df['exercise_frequency'].map({'从不': 0, '偶尔': 1, '每周1-2次': 2, '每周3-5次': 3, '每天': 4})
numeric_df = comprehensive_df[['age', 'stress_numeric', 'nutrition_score', 'sleep_hours', 'exercise_numeric', 'psychological_score', 'hairloss_level']].dropna()
correlation_matrix = numeric_df.corr()
correlation_dict = {}
for col_name in correlation_matrix.columns:
if col_name != 'hairloss_level':
correlation_dict[f'{col_name}_hairloss'] = float(correlation_matrix.loc[col_name, 'hairloss_level'])
factor_weights = np.abs(list(correlation_dict.values()))
normalized_weights = factor_weights / np.sum(factor_weights)
weight_dict = dict(zip(correlation_dict.keys(), normalized_weights.tolist()))
high_risk_combination = spark.sql("SELECT * FROM (SELECT stress_level, sleep_hours, nutrition_score, psychological_score, ROUND(AVG(hairloss_level), 2) as avg_hairloss, COUNT(*) as count FROM comprehensive WHERE stress_level IN ('高', '极高') AND sleep_hours < 6 GROUP BY stress_level, sleep_hours, nutrition_score, psychological_score HAVING COUNT(*) >= 3) ORDER BY avg_hairloss DESC LIMIT 10")
high_risk_data = high_risk_combination.toPandas().to_dict('records')
protective_factors = spark.sql("SELECT exercise_level, nutrition_score, sleep_quality, ROUND(AVG(hairloss_level), 2) as avg_hairloss, COUNT(*) as count FROM comprehensive WHERE exercise_level IN ('高', '中') AND nutrition_score >= 70 AND sleep_quality = '良好' GROUP BY exercise_level, nutrition_score, sleep_quality HAVING COUNT(*) >= 3 ORDER BY avg_hairloss ASC LIMIT 10")
protective_data = protective_factors.toPandas().to_dict('records')
result = {'stress_nutrition_correlation': stress_nutrition_data, 'age_lifestyle_correlation': age_lifestyle_data, 'medical_psychological_impact': medical_psych_data, 'correlation_matrix': correlation_dict, 'factor_weights': weight_dict, 'high_risk_combinations': high_risk_data, 'protective_factors': protective_data, 'analysis_timestamp': datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
return JsonResponse({'code': 200, 'message': '多维度关联分析完成', 'data': result})
except Exception as e:
return JsonResponse({'code': 500, 'message': f'关联分析失败: {str(e)}'})
基于大数据的脱发影响因素分析与可视化系统系统文档展示

💖💖作者:计算机毕业设计江挽
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💜💜
网站实战项目
安卓/小程序实战项目
大数据实战项目
深度学习实战项目
© 版权声明
文章版权归作者所有,未经允许请勿转载。