
GROUPING SETS — 高效实现多维聚合分析(Hive / Spark)
GROUPING SETS — 高效实现多维聚合分析(Hive / Spark)
- Hive 官方文档 – Grouping Sets
- Spark SQL 支持的 GROUPING SETS
一、问题发现:看板背后的 SQL 引发的好奇
最近在与数据分析师(DA)同学对接,搭建业务看板、Review 他提交的 SQL 脚本时,注意到一段让我眼前一亮的写法(Demo不涉及具体业务逻辑,仅做演示):
SELECT
region,
product_category,
channel,
SUM(sales_amount) AS total_sales
FROM dws_sales_detail
GROUP BY region, product_category, channel
GROUPING SETS (
(region, product_category, channel),
(region, product_category),
(region),
()
);
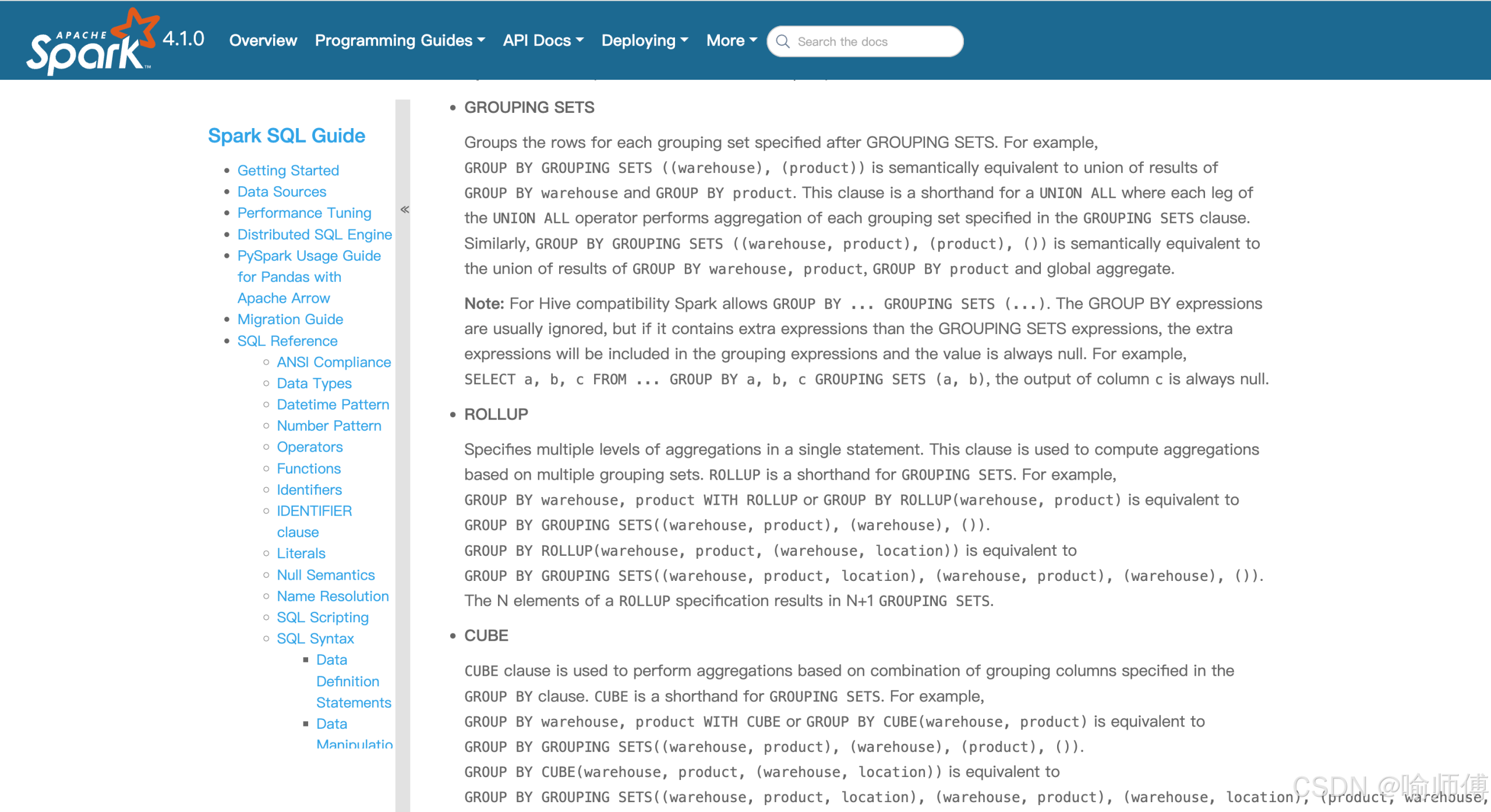
并不是我熟悉的 GROUP BY 或 UNION ALL 写法。虽然能大致猜到它的作用——同时输出多个粒度的聚合结果(比如“地区+品类+渠道”、“地区+品类”、“仅地区”以及“全局总计”),但从未在日常开发中使用过 GROUPING SETS。
出于职业敏感,意识到这可能是一个被我长期忽略的 SQL 高级特性。于是决定深入研究一下:它到底是什么?为什么 DA 会用它?相比传统写法有什么优势?是否值得在我们团队推广?
二、什么是 GROUPING SETS?
GROUPING SETS 是 一种多维分组聚合语法,允许在单条查询中指定多个分组组合,从而一次性生成不同维度的汇总结果。
link:https://cwiki.apache.org/confluence/display/Hive/Enhanced+Aggregation%2C+Cube%2C+Grouping+and+Rollup
举个简单例子
假设我们有销售数据,想同时看到:
- 每个地区每类产品的销售额
- 每个地区的总销售额(忽略产品)
- 所有产品的总销售额(忽略地区)
- 全局总销售额
传统做法可能是写 4 个 SELECT ... GROUP BY ... 然后 UNION ALL 起来,代码冗长且效率低。
而用 GROUPING SETS,只需:
SELECT
region,
product_category,
SUM(sales) AS total
FROM sales_table
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
执行后,结果集中会自动包含所有四种粒度的数据,未参与当前分组的字段显示为 NULL。
三、如何正确识别“汇总行”?—— 处理 NULL 的两种最佳实践
使用 GROUPING SETS 时,一个关键挑战是:当某列未参与当前分组时,其值会被设为 NULL。但原始业务数据中也可能存在真实的 NULL 值(例如用户未填写城市、产品分类未知等)。如果不加区分,会导致报表语义错误或分析偏差。
为此,业界通常采用以下两种方法:
方法一:用 COALESCE 替换 NULL(适合最终报表展示)
SELECT
COALESCE(city, 'ALL') AS city,
COALESCE(product, 'ALL') AS product,
SUM(sales) AS total_sales
FROM sales
GROUP BY GROUPING SETS (
(city, product),
(city),
()
);
优点:
- 输出结果直观易读,
'ALL'明确表示“该维度已汇总”;适合直接对接 BI 工具或生成业务日报。
缺点:
-
无法区分原始 NULL 和汇总 NULL。
例如:如果原始数据中真有一条city = NULL的记录,它会被错误地显示为'ALL',与汇总行混在一起。
📌 适用场景:你确定业务字段非空(如通过 ETL 清洗过),或可接受轻微语义模糊的报表场景。
方法二:用 GROUPING() 函数精准判断(推荐用于严谨分析)
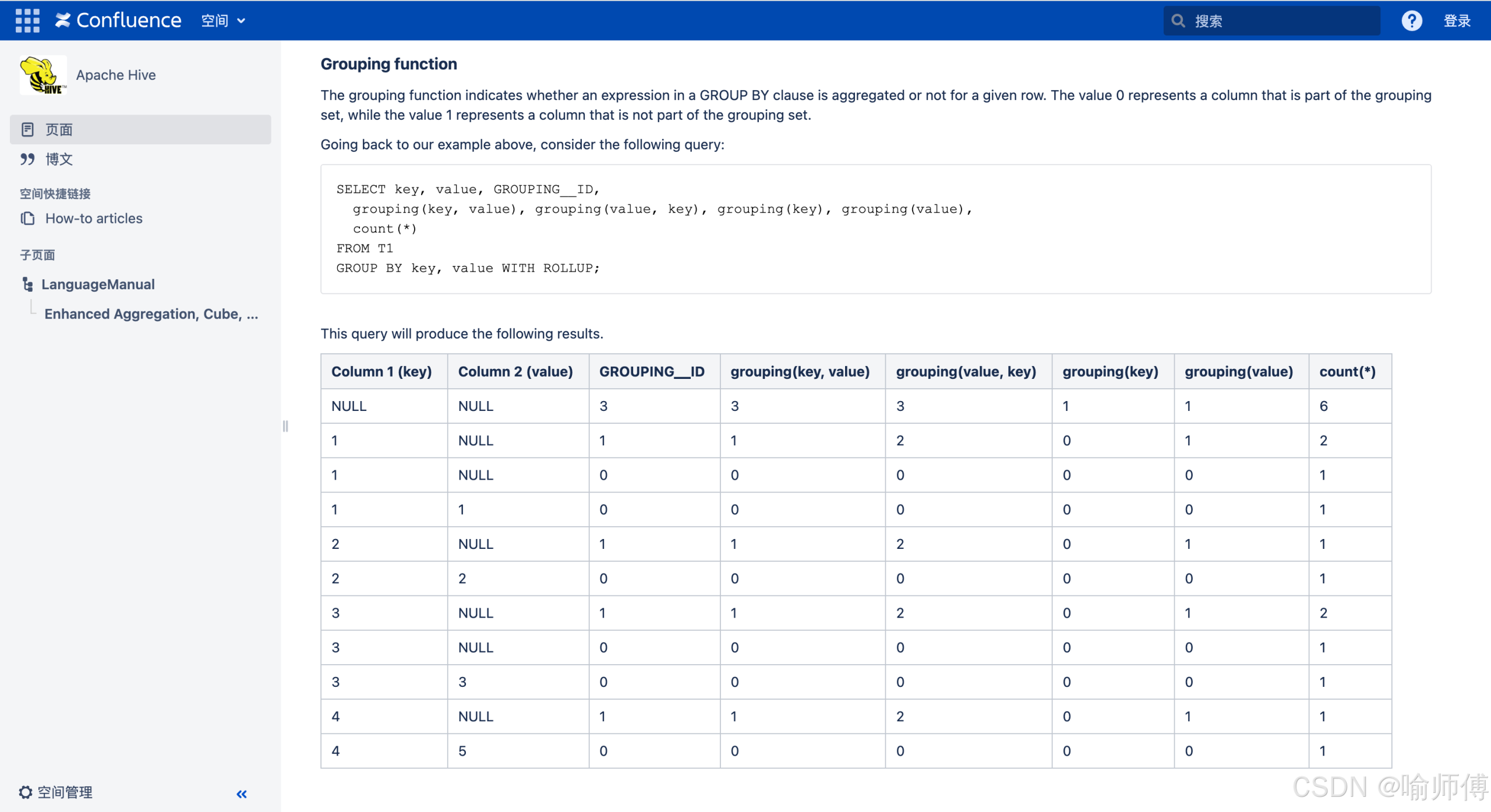
Hive、Spark SQL等现代数仓引擎均支持 GROUPING(col) 函数:
- 返回
0:该列参与了当前分组,值是真实数据(即使是 NULL,也是原始 NULL); - 返回
1:该列未参与分组,当前 NULL 是汇总占位符。
SELECT
CASE WHEN GROUPING(city) = 1 THEN 'ALL' ELSE city END AS city,
CASE WHEN GROUPING(product) = 1 THEN 'ALL' ELSE product END AS product,
-- 可选:保留原始值用于调试
-- city AS raw_city,
-- product AS raw_product,
SUM(sales) AS total_sales
FROM sales
GROUP BY GROUPING SETS (
(city, product),
(city),
()
);
优点:
- 100% 区分原始 NULL 与汇总 NULL;
- 逻辑严谨,适合对数据准确性要求高的场景(如财务、风控);
- 可配合
GROUPING_ID实现自动粒度标签。
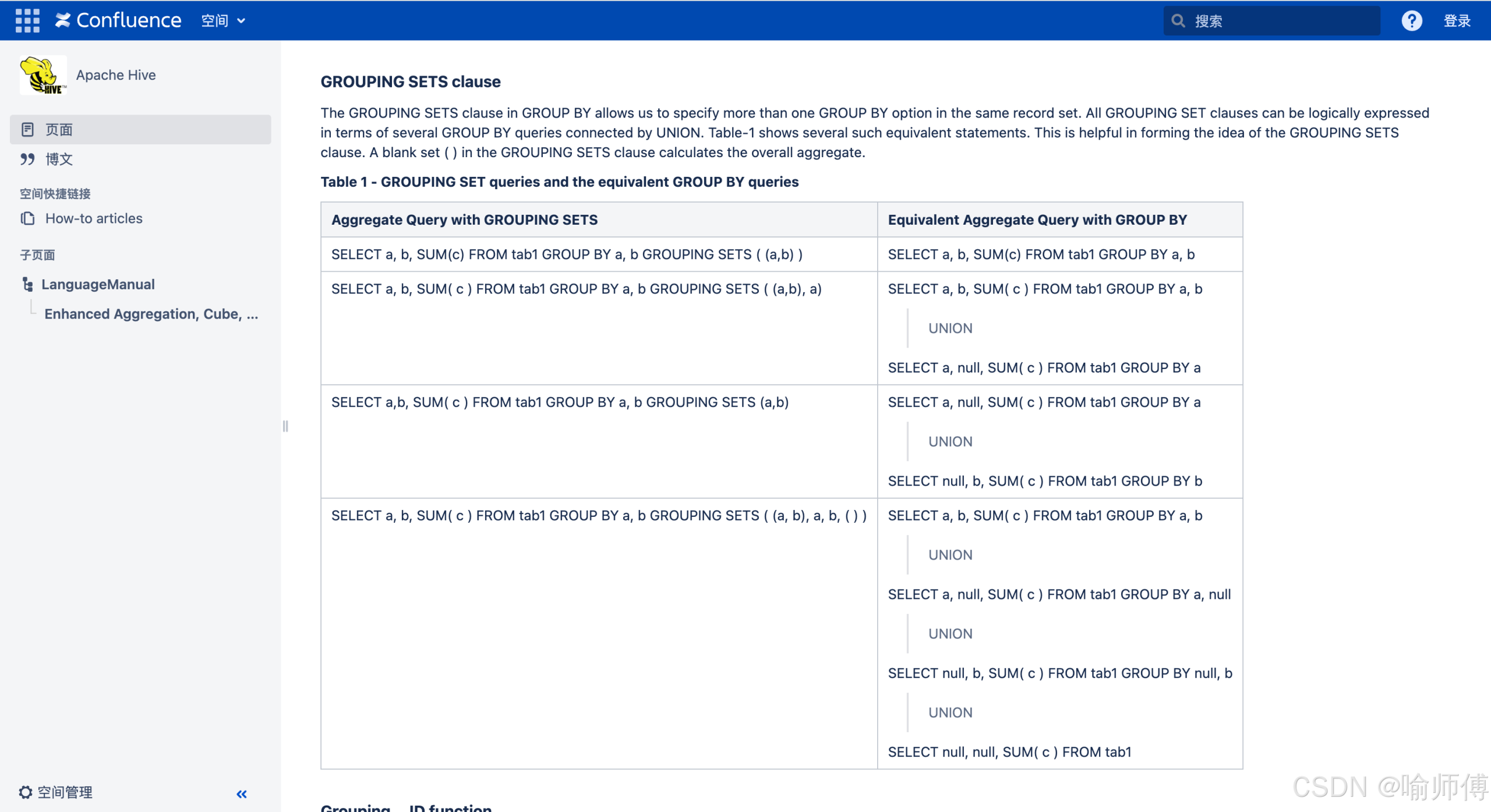
示例对比(假设原始数据含 city = NULL):
| city(原始) | product | sales |
|---|---|---|
| 北京 | 手机 | 100 |
| NULL | 电脑 | 50 |
使用 COALESCE:
北京 手机 100
ALL 电脑 50 ← 把真实 NULL 当成汇总了
ALL ALL 150
使用 GROUPING():
北京 手机 100
NULL 电脑 50 ← 正确保留原始 NULL
ALL ALL 150 ← 明确标识汇总行
Tips:进阶用法可结合 GROUPING_ID 自动打标签:
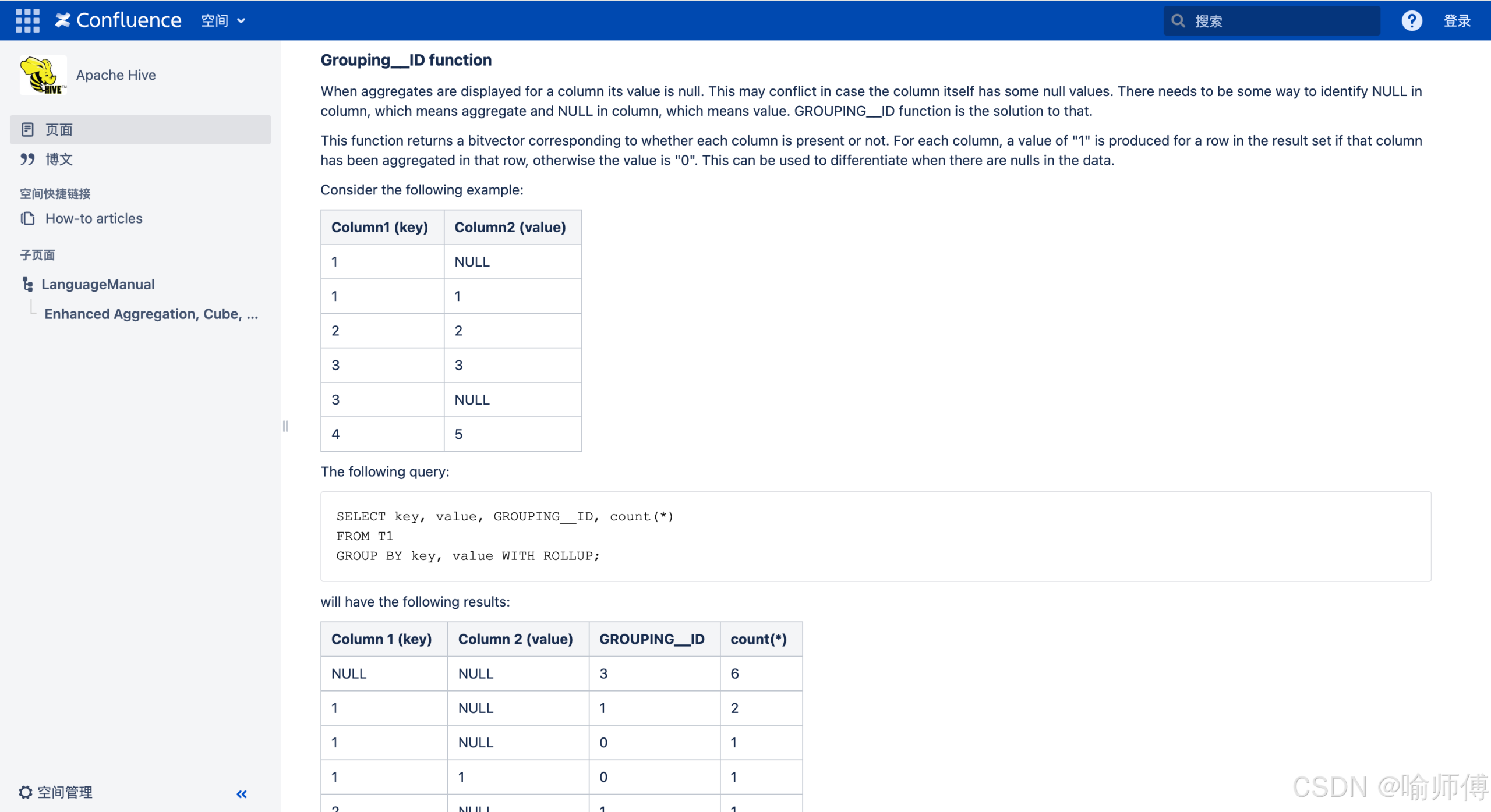
GROUPING_ID(col1, col2, ..., colN):把多个字段是否“被汇总”(即未参与分组)的状态,编码成一个整数 ID,用来唯一标识当前行的分组粒度。
假设你有两列:city 和 product,并写了如下查询:
SELECT
city,
product,
SUM(sales) AS total
FROM sales
GROUP BY GROUPING SETS (
(city, product), -- 组合 A
(city), -- 组合 B
(product), -- 组合 C
() -- 组合 D(全局汇总)
);
那么结果中会有 4 种不同“类型”的行。我们想知道:每一行到底来自哪个组合? 这时候就用 GROUPING_ID(city, product)。
对每个字段:
- 如果该字段 参与了当前分组 →
GROUPING(字段) = 0 - 如果该字段 未参与分组(是汇总占位符) →
GROUPING(字段) = 1
然后,把这些 GROUPING 值按顺序拼成一个二进制数,再转成十进制 —— 就是 GROUPING_ID。
注意:左边的字段是高位,右边是低位(大多数引擎如此,如 Hive/Spark)
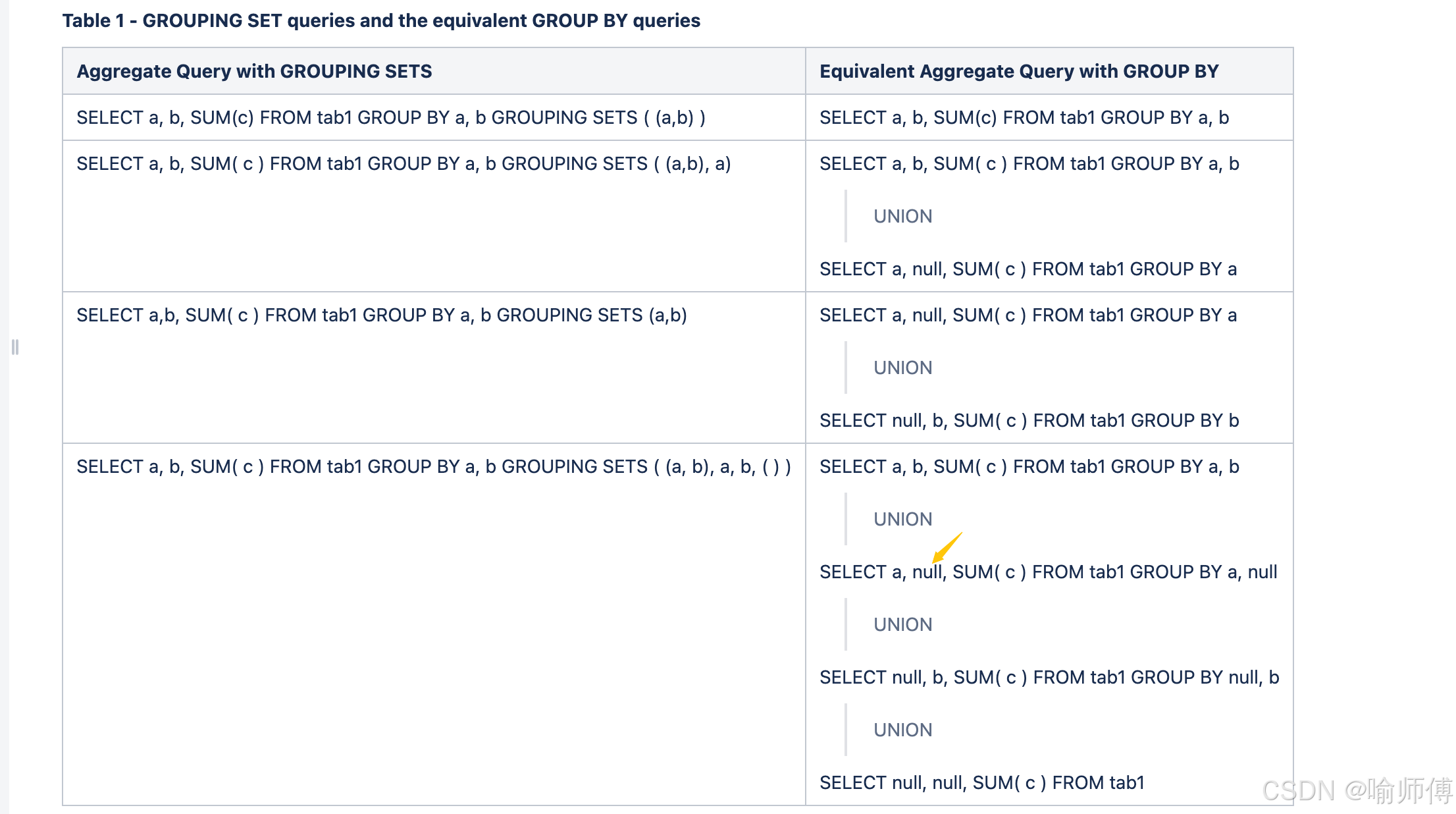
| 分组组合 | city 分组? | product 分组? | GROUPING(city) | GROUPING(product) | 二进制(city, product) | GROUPING_ID |
|---|---|---|---|---|---|---|
| (city, product) | 是 | 是 | 0 | 0 | 00 |
0 |
| (city) | 是 | 否 | 0 | 1 | 01 |
1 |
| (product) | 否 | 是 | 1 | 0 | 10 |
2 |
| () | 否 | 否 | 1 | 1 | 11 |
3 |
-
GROUPING_ID = 0→ 明细行(两个维度都有) -
GROUPING_ID = 1→ 只按 city 汇总(product 是 ALL) -
GROUPING_ID = 2→ 只按 product 汇总(city 是 ALL) -
GROUPING_ID = 3→ 全局总计(city 和 product 都是 ALL)
- 给聚合行打标签:下游看板可以直接用
agg_type做筛选、着色或说明。
SELECT
CASE WHEN GROUPING(city) = 1 THEN 'ALL' ELSE city END AS city,
CASE WHEN GROUPING(product) = 1 THEN 'ALL' ELSE product END AS product,
CASE GROUPING_ID(city, product)
WHEN 0 THEN '明细:城市+品类'
WHEN 1 THEN '汇总:仅城市'
WHEN 2 THEN '汇总:仅品类'
WHEN 3 THEN '总计:全局'
END AS agg_type,
SUM(sales) AS total
FROM sales
GROUP BY GROUPING SETS (
(city, product),
(city),
(product),
()
);
- 过滤特定粒度的数据 :比如只看“城市维度汇总”,不要明细和全局:
WHERE GROUPING_ID(city, product) = 1
- 调试复杂 GROUPING SETS
当你写了 5 个维度的GROUPING SETS,有几十种组合时,GROUPING_ID能让你一眼看出每行的来源。
-
字段顺序很重要
GROUPING_ID(a, b)和GROUPING_ID(b, a)的结果不同(因为二进制位顺序变了)。
| 函数 | 作用 | 返回值 |
|---|---|---|
GROUPING(col) |
判断单个列是否被汇总 | 0 或 1 |
GROUPING_ID(...) |
把多个列的汇总状态编码成一个 ID | 0, 1, 2, 3… |
四、与 ROLLUP / CUBE 的关系
GROUPING SETS 是最通用的形式,而 ROLLUP 和 CUBE 是它的特例:
-
ROLLUP(a, b, c)=GROUPING SETS( (a,b,c), (a,b), (a), () )→ 层级式汇总
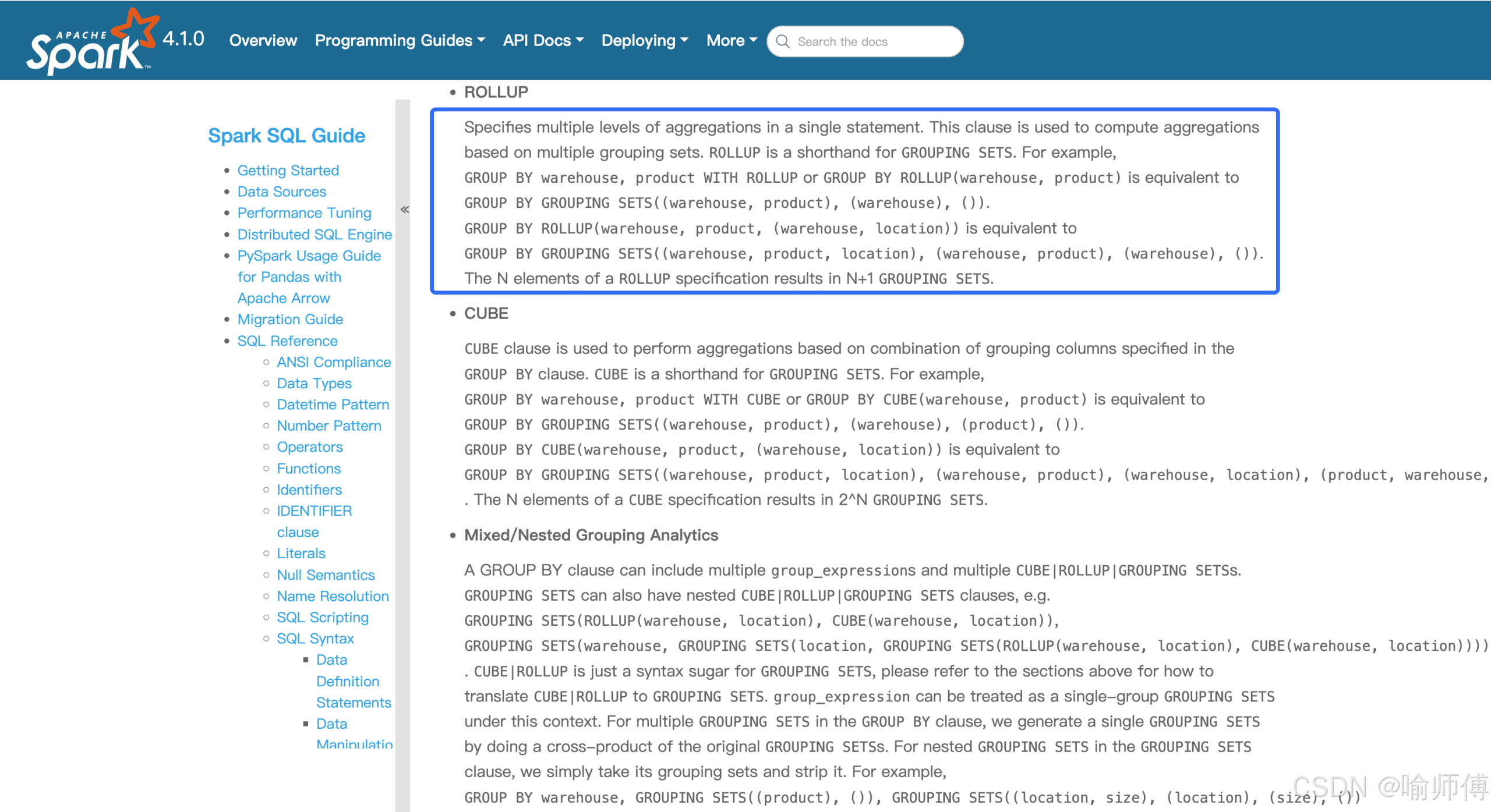
-
CUBE(a, b)=GROUPING SETS( (a,b), (a), (b), () )→ 所有组合
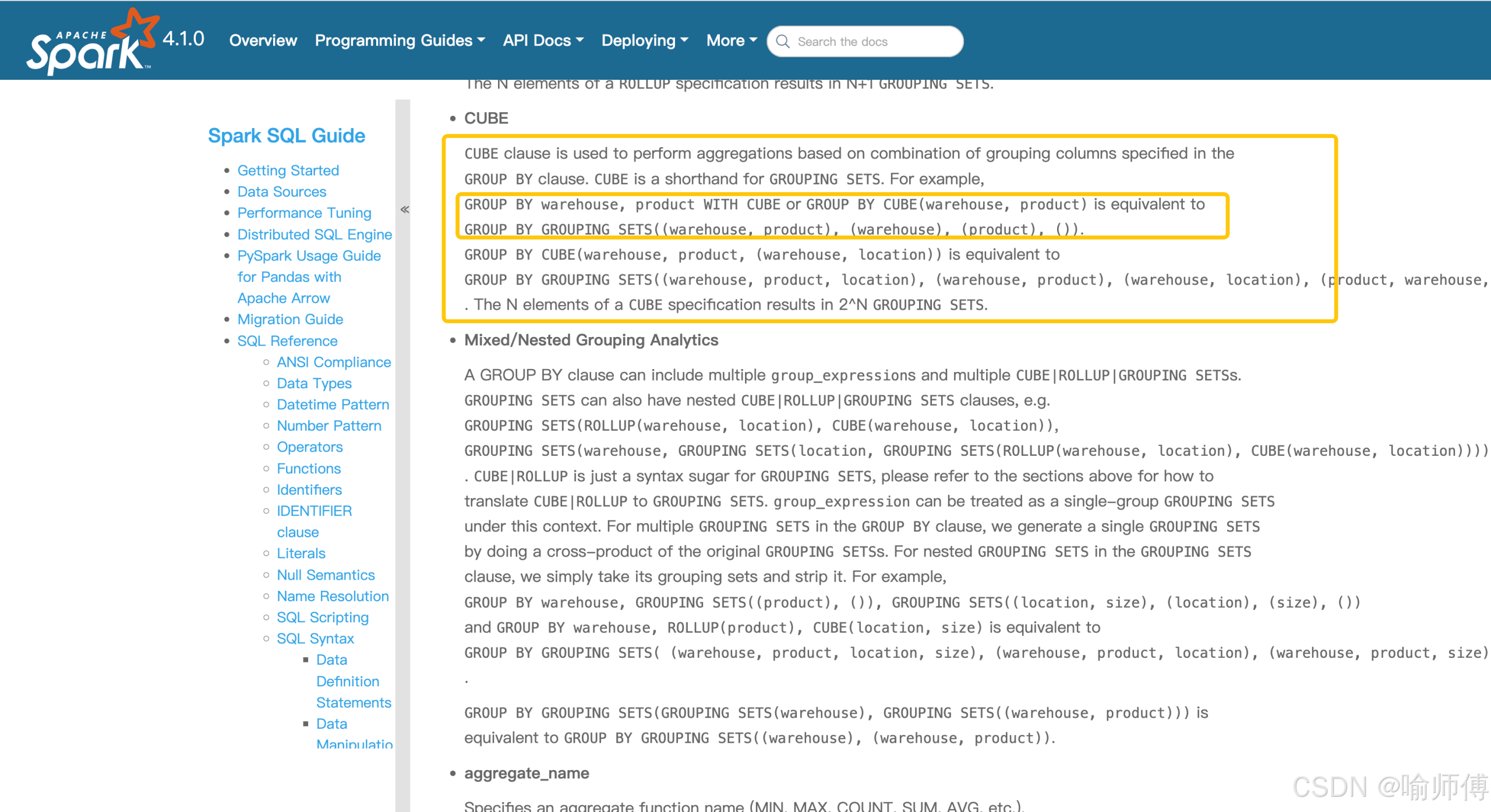
当需要非对称或自定义的分组组合时(比如只要 (a,b) 和 (),不要 (a)),就必须用 GROUPING SETS。
回过头再来看一下DA同学为什么要在数据看板场景使用GROUPING SETS?
- 代码简洁,逻辑统一 :避免重复编写相似的聚合逻辑,减少出错概率。
- 性能更优 :引擎只需扫描一次底表,就能完成多种分组计算(在 Spark/Hive 中有专门优化),而
UNION ALL方案需要多次扫描或 shuffle。
- 天然支持 OLAP 多维分析: DA 做看板时经常需要“下钻(drill-down)”和“上卷(roll-up)”,
GROUPING SETS正好满足这种需求。
- 与 BI 工具兼容性好 : 很多现代 BI 工具在生成底层 SQL 时,也会使用类似语法来支持动态维度切换。
后记:技术成长往往始于一个“没见过”的新事物。希望大家保持好奇,主动探究,长期主义。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


