通过实践聊聊NVIDIA DGX Spark真的适合部署企业级大模型吗?
____simple_html_dom__voku__html_wrapper____>
今年上半年,NVIDIA 高调宣布可以将 200B 大模型装在一个手掌大小的桌面级产品,核心就是 GB10 Grace Blackwell 超级芯片,这颗 SoC 将 CPU 和 GPU 封装在一起。
CPU 部分有 20 个核心(联发科,ARM架构,包含10大核、10小核)
GPU 部分基于 Blackwell 架构,有 6144 个 CUDA 核,NVFP4 格式算力为 11PetaFLOPS,FP32 格式算力为 31TFLOPS,从官方的宣传海报可以看出来可以回避掉了 除 FP4 格式外的算力指标。
内存部分,128G(系统内存+显存,开机占用 30G 左右),内存带宽 273GB/s(刀法精准)
系统部分,搭载了 NVIDIA 定制版的 Ubuntu 24.04,默认集成了 NVIDIA CUDA 生态,不用在花时间去安装。
正好手上有一台 NVIDIA DGX Spark,马上开搞。
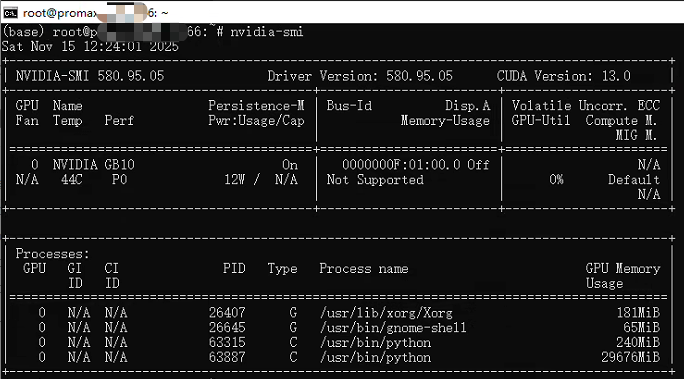
一、部署推理框架
这台机器是 ARM 架构,且是定制版的 Ubuntu,并且比较新,生态比较糟糕,尝试以前部署的方案,在国内比较 麻烦。所以使用 Docker 部署推理引擎 TensorRT LLM(NVIDIA 自家开发的,听说有优化,比vLLM 能快上 10%),获取镜像地址链接,使用Tag 为 1.2.0rc2 的镜像即可,镜像约 30G 左右,下载比较久,请耐心等待。
如果不会下载,后面我可以写一篇如何利用云厂商的服务快速下载的教程。
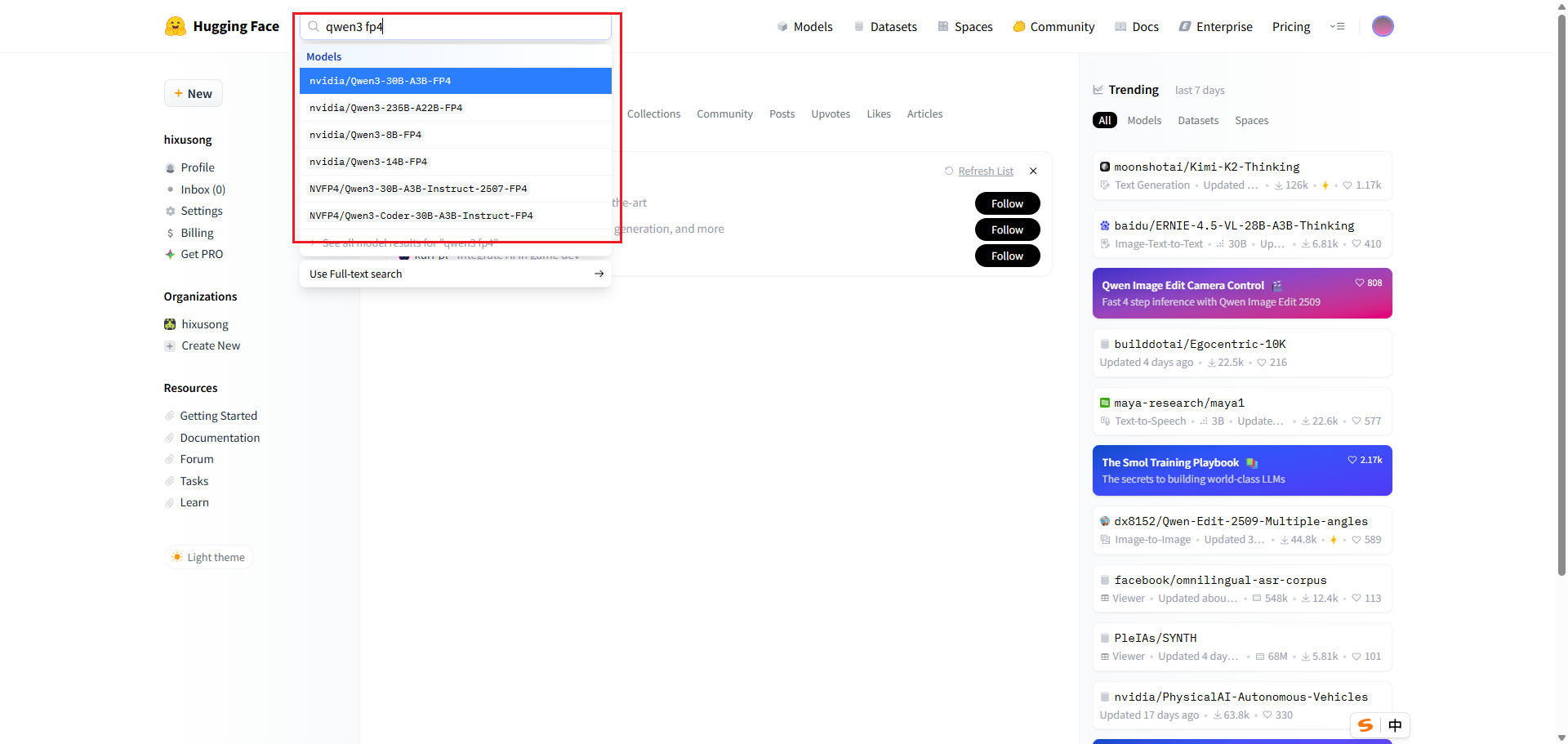
二、下载模型文件
镜像文件,可以先去 huggingface 选模型,这里推荐 NVIDIA官方量化的 FP4 模型 Qwen3-30B-A3B-FP4 。换成别的模型有可能跑不起来,NVIDIA 非常贴心的帮我们量化了主流的模型。
# 环境变量,使用镜像
export HF_ENDPOINT=https://hf-mirror.com
from huggingface_hub import snapshot_download
# 模型名称
model_name = "openai/Qwen3-30B-A3B-FP4"
# 本地保存路径
local_dir = "/home/Qwen3-30B-A3B-FP4/"
# 下载模型(包括所有文件)
snapshot_download(
repo_id=model_name,
local_dir=local_dir,
local_dir_use_symlinks=False, # 不使用符号链接,直接保存文件
ignore_patterns=None # 下载所有文件(可根据需要过滤)
)
三、启动模型服务
docker run -it --gpus all -p 8000:8000 -v /home/Qwen3-30B-A3B-FP4:/models nvcr.io/nvidia/tensorrt-llm/release:1.2.0rc2 bash -c "trtllm-serve /models --host 0.0.0.0 --port 8000"
四、压测结果
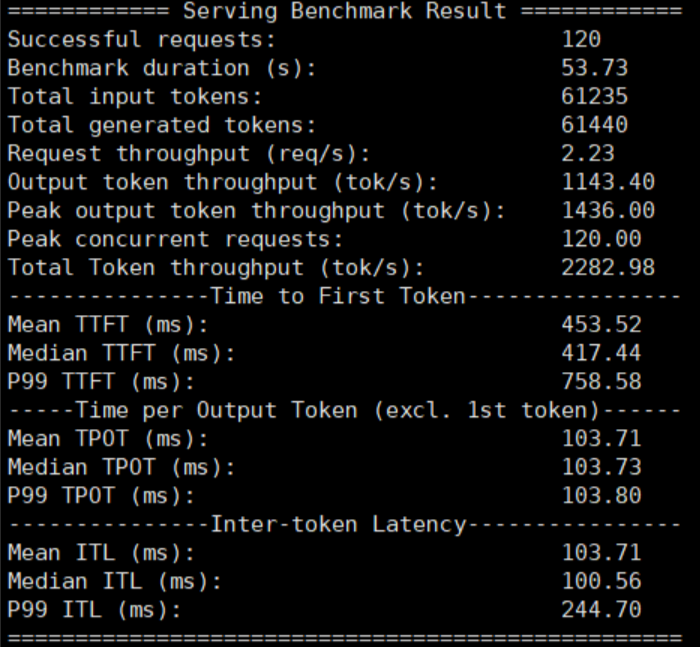
在输入输出都是 512 的情况下,性能表现最好,大约能支撑 120 并发。
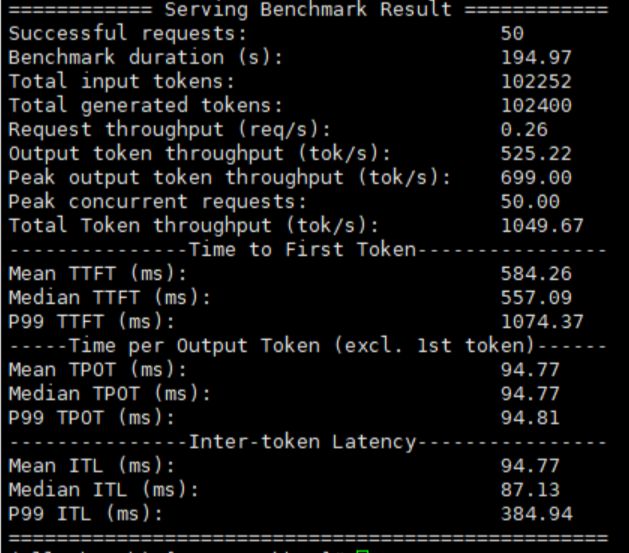
在输入输出都是 2048 的情况下,最适合企业知识库场景,约能支撑 50 并发。
输入输出 512,120 并发
输入输出 2048,50 并发
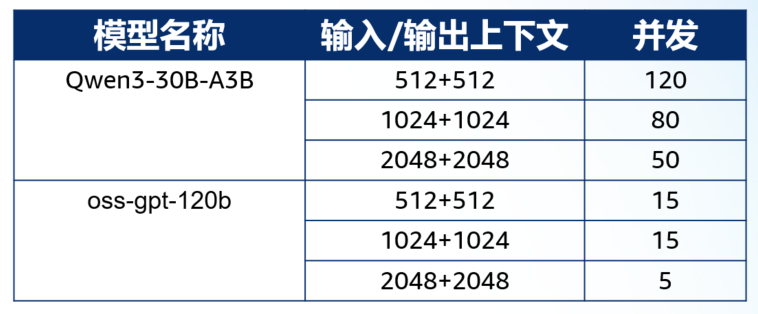
最后,在引入oss-gpt-120b 的模型加入对比
五、讨论:你觉得 NVIDIA DGX Spark 或同类 GB10 主机适合部署企业级模型吗
© 版权声明
文章版权归作者所有,未经允许请勿转载。