电影票房数据采集分析可视化系统 | Python Flask Echarts requests爬虫 大数据 人工智能 deepseek 毕业设计源码
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
以Python为开发语言,基于Flask框架搭建后端服务架构,采用MySQL数据库存储各类票房数据,借助Echarts实现数据可视化展示,通过requests库编写爬虫程序,从艺恩电影票房网抓取所需数据。
功能模块
- 地区票房占有率分析
- 月份票房分析
- 电影类型票房占有率分析
- 首页展示
- 实时票房排名
- 采集日志
- 数据采集
项目介绍
本电影票房数据采集分析可视化系统专注于电影票房数据的全流程处理,依托Python、Flask等技术构建核心架构,通过定制化爬虫程序从艺恩电影票房网自动抓取票房数据,经解析处理后存入MySQL数据库。系统提供多维度可视化分析功能,涵盖地区票房占比、月份票房、电影类型票房占比等模块,支持按年份查看实时票房排名,同时记录数据采集日志。用户可灵活筛选条件,查看可视化图表与数据表格,直观掌握票房分布、趋势等信息,为电影行业从业者及爱好者提供便捷的数据查询与分析工具。
2、项目界面
(1)地区票房占有率分析
通过环形图直观展示各地区票房占比情况,鼠标悬停可显示对应地区的票房数据及占比信息,同时页面顶部还设有首页、数据中心、总票房排行、类型占比分析、场均人次排名分析、月份票房分析、地区票房及登录等功能入口。
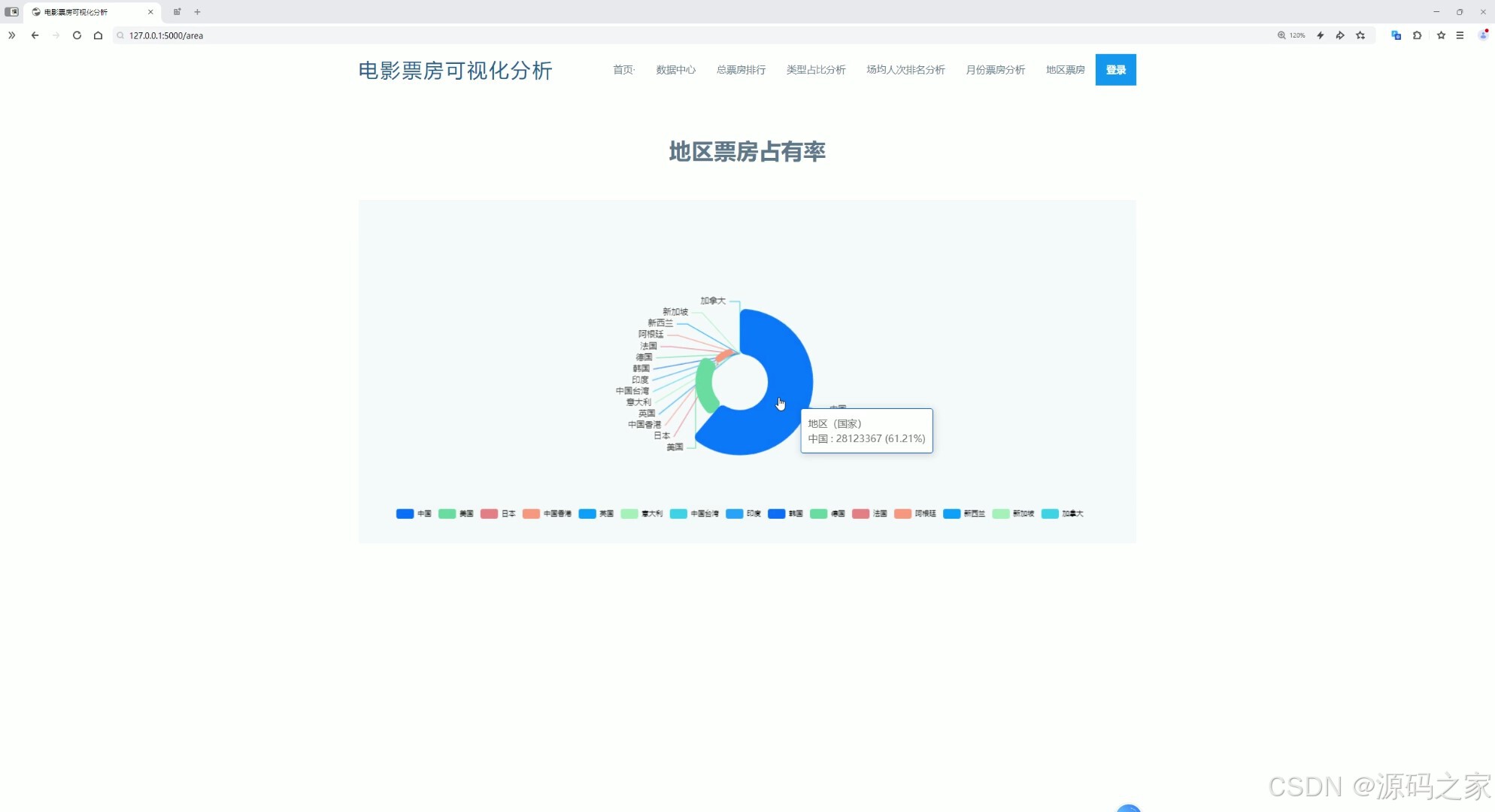
(2)月份票房分析
通过横向条形图直观展示各月份的票房数据,鼠标悬停在对应月份的条形上时,可显示该月份的具体票房数值,同时页面顶部还设有首页、数据中心、总票房排行、类型占比分析、场均人次排名分析、月份票房分析、地区票房及登录等功能入口。
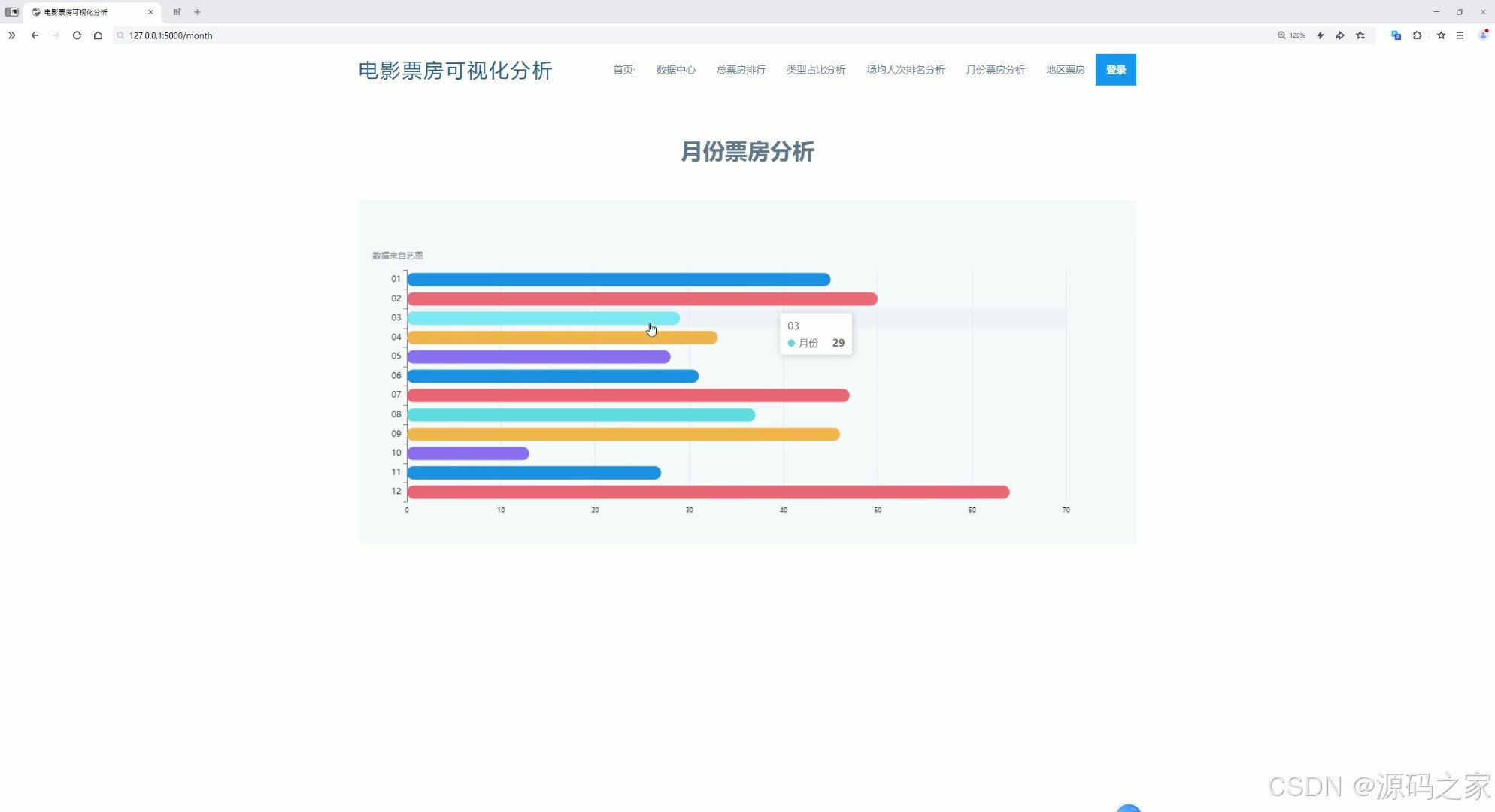
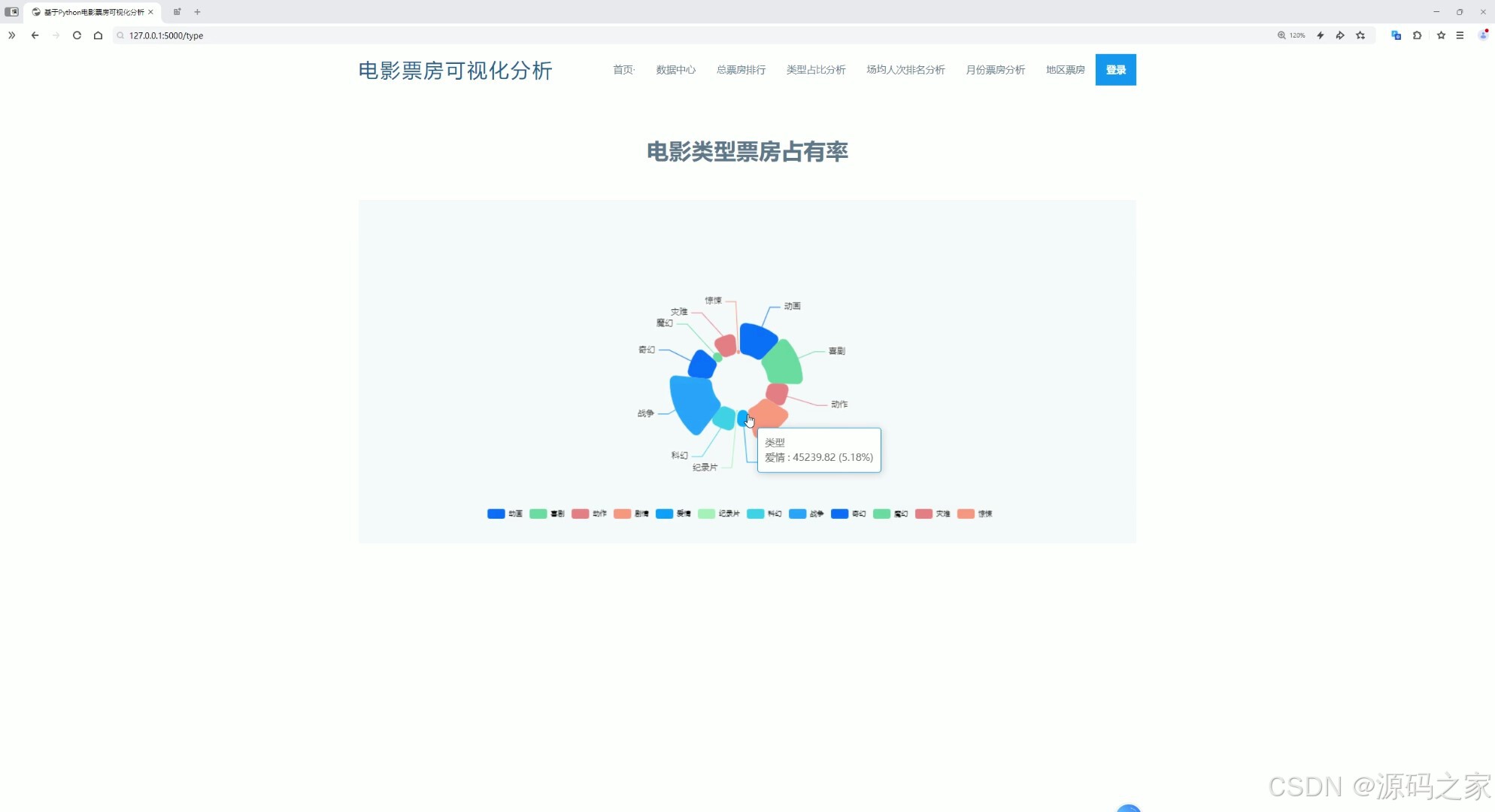
(3)电影类型票房占有率
通过环形玫瑰图直观展示不同电影类型的票房占比情况,鼠标悬停在对应类型的扇区上时,可显示该类型的具体票房数值及占比信息,同时页面顶部还设有首页、数据中心、总票房排行、类型占比分析、场均人次排名分析、月份票房分析、地区票房及登录等功能入口。
(4)首页展示
提供了票房排名、总票房排行 top20、电影类型票房占有率、场均人次排名分析 top20 等快捷入口,同时页面顶部还设有首页、数据中心、总票房排行、类型占比分析、场均人次排名分析、月份票房分析、地区票房及登录等功能入口。
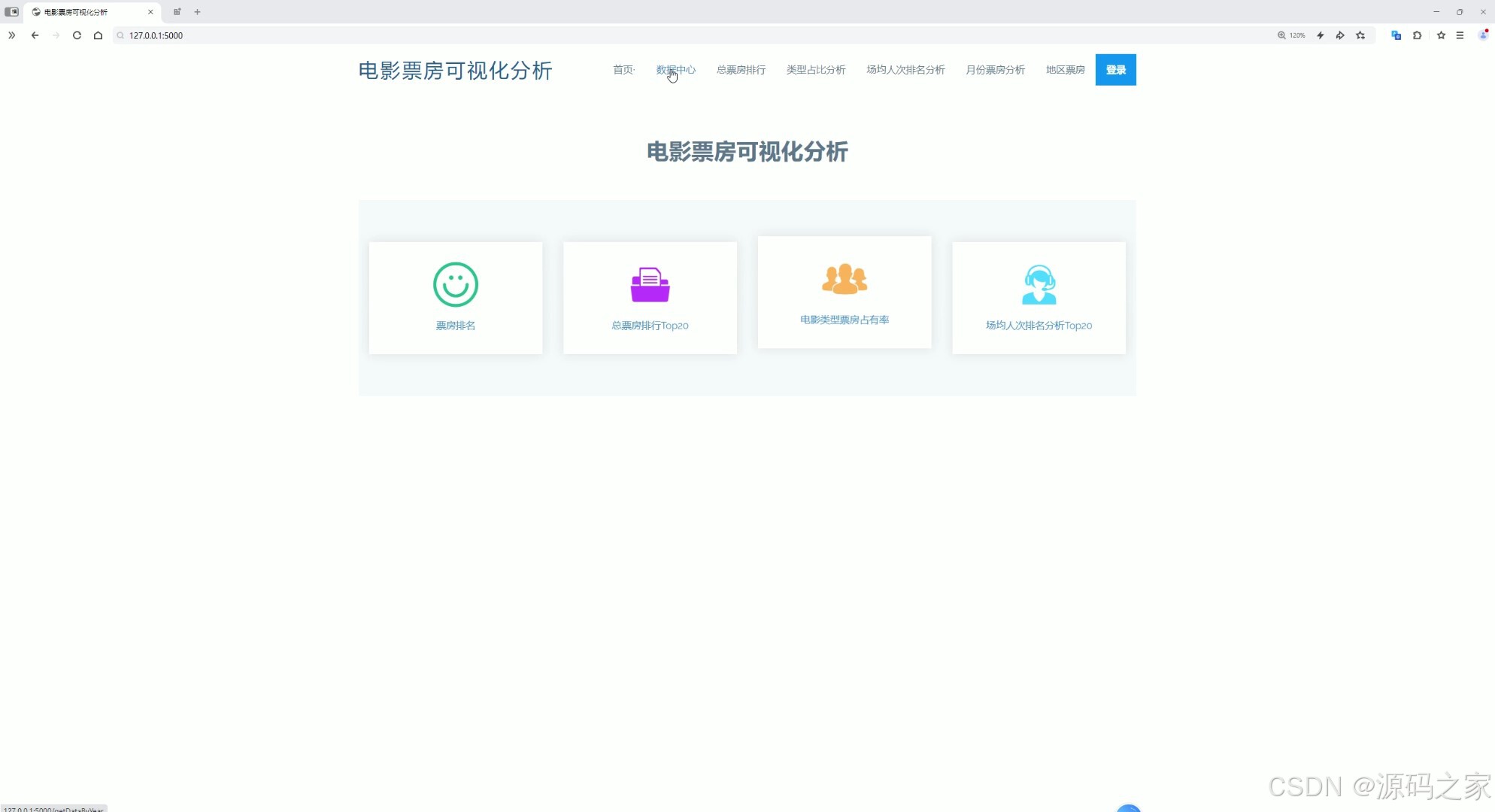
(5)实时票房排名
通过年份选择下拉框可切换不同年份,以表格形式清晰展示对应年度影片的排名、影片名称、类型、总票房、平均票价、场均人次、国家及地区、上映日期等详细信息,同时页面顶部还设有首页、数据中心、总票房排行、类型占比分析、场均人次排名分析、月份票房分析、地区票房及登录等功能入口。
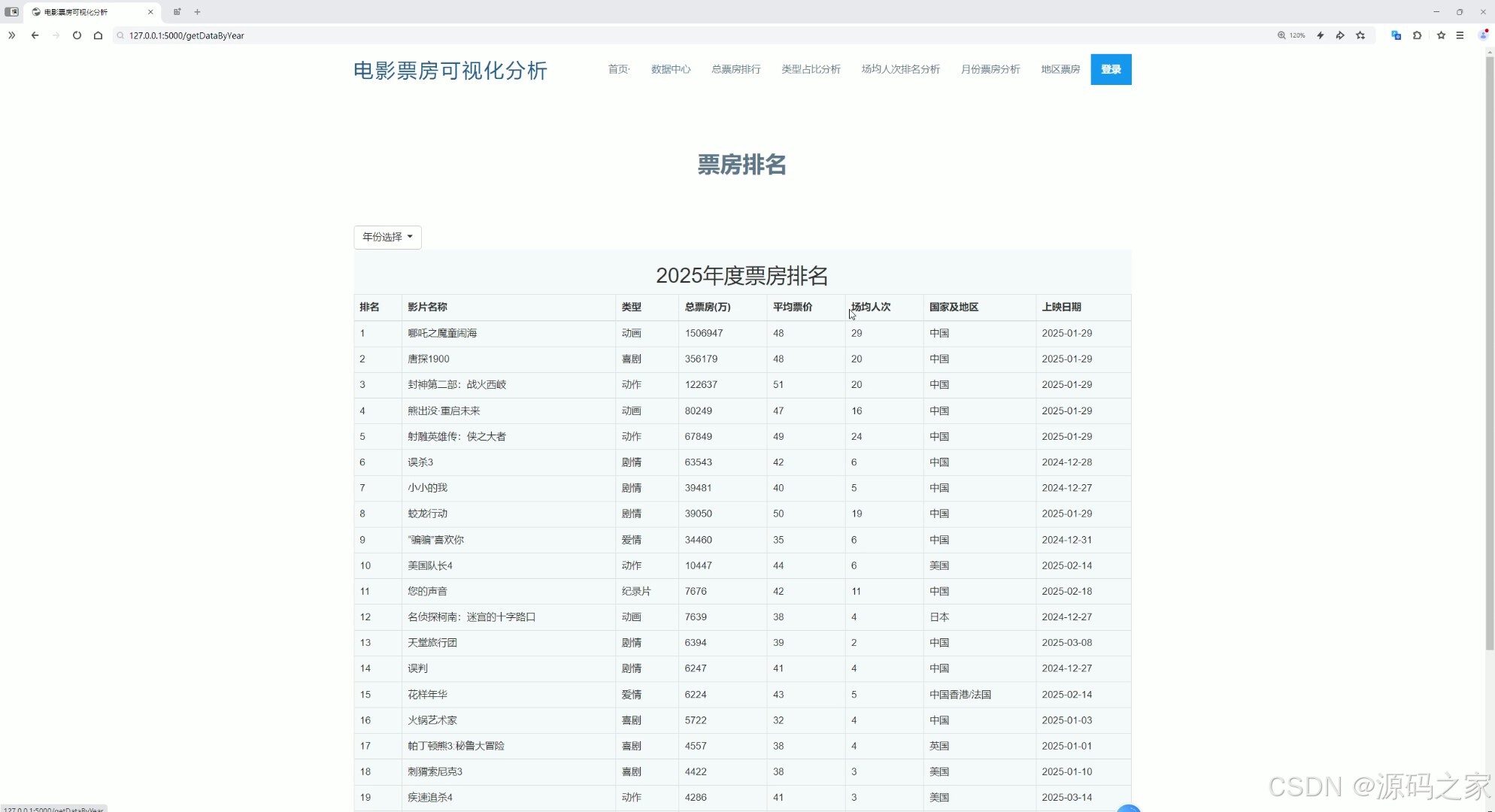
(6)采集日志
以表格形式清晰展示每次数据爬取的操作人、开始爬取时间、爬取结束时间、爬取数据条数以及爬取目标地址等信息,同时页面顶部还设有首页、数据中心、总票房排行、类型占比分析、场均人次排名分析、月份票房分析、地区票房及用户登录等功能入口。
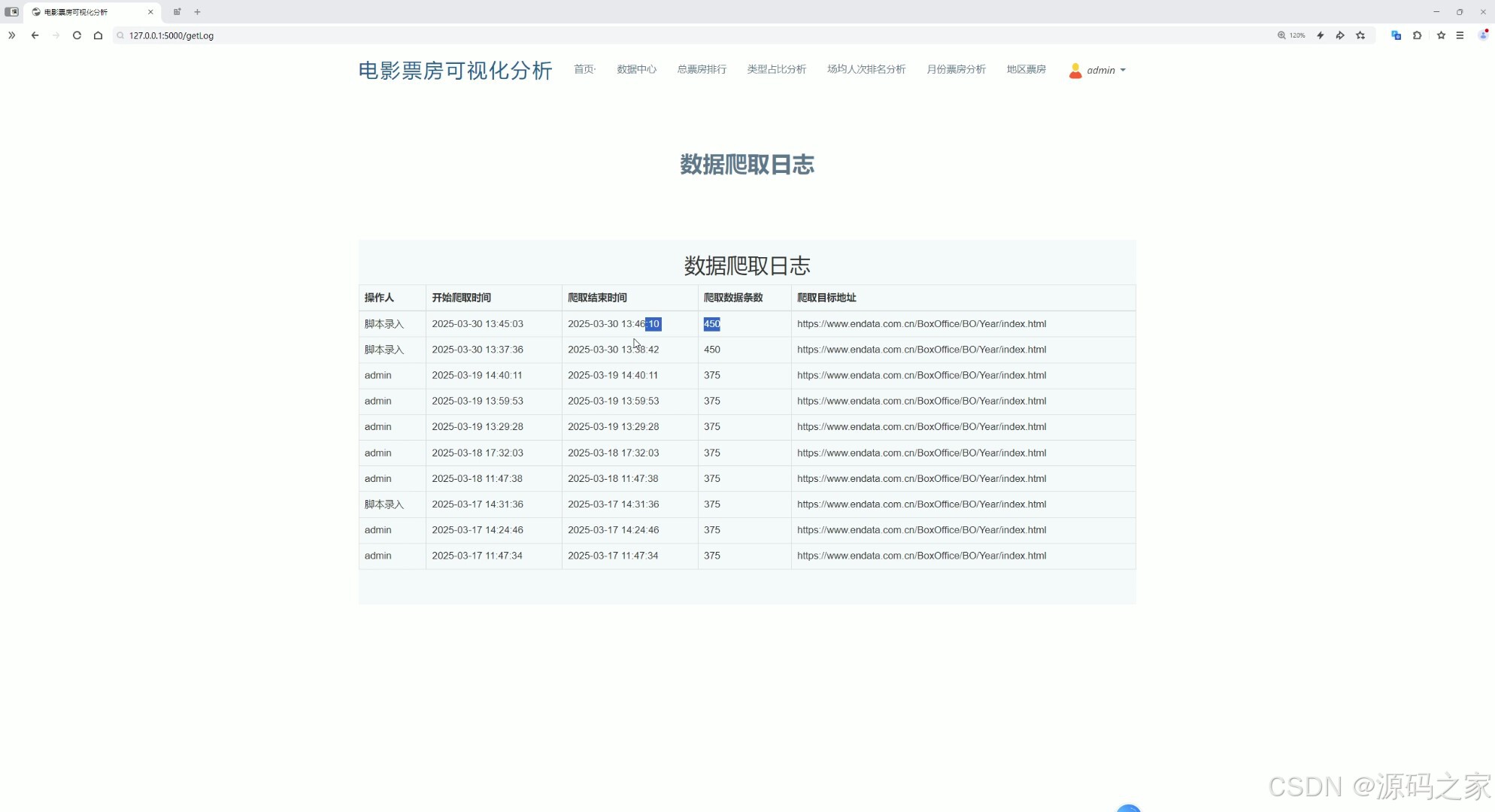
(7)数据采集页面
左侧是 Python 代码编辑与运行环境,用于编写和执行数据爬取脚本,实现从指定网页自动获取电影票房数据并存储到数据库,同时记录操作日志,右侧是目标数据来源网页,用于展示原始的电影票房信息,整个流程实现了数据的自动采集、存储与日志记录功能。
3、项目说明
一、技术栈
本项目以Python为核心开发语言,基于Flask框架搭建后端服务架构,采用MySQL数据库存储各类电影票房数据,借助Echarts可视化库实现多形式的数据图表展示,通过requests库编写爬虫程序,定向从艺恩电影票房网抓取所需的票房相关数据。
二、功能模块详细介绍
- 地区票房占有率分析:以环形图展示各地区票房占比,鼠标悬停可查看对应地区票房数据及占比,页面顶部配备全功能导航入口,直观呈现票房的地域分布特征。
- 月份票房分析:通过横向条形图展示各月份票房数据,鼠标悬停可显示具体票房数值,搭配全功能导航入口,清晰呈现票房的时间分布趋势。
- 电影类型票房占有率分析:以环形玫瑰图展示不同电影类型票房占比,鼠标悬停可查看对应类型票房数值及占比,辅助分析不同类型电影的票房表现。
- 首页展示:整合票房排名、总票房排行top20等多维度分析快捷入口,页面顶部设有完整功能导航,是系统功能的集中展示与快速访问入口。
- 实时票房排名:支持通过年份下拉框切换查询维度,以表格形式展示影片排名、名称、类型、总票房等详细信息,可查看不同年度的票房排行数据。
- 采集日志:以表格形式记录每次数据爬取的操作人、爬取时间、数据条数、目标地址等信息,清晰追溯数据采集的全流程记录。
- 数据采集:左侧为Python代码编辑运行环境,可编写执行爬取脚本,右侧展示目标数据源网页,实现票房数据自动采集、存储与日志记录。
三、项目总结
本电影票房数据采集分析可视化系统围绕电影票房数据构建全流程处理体系,基于Python+Flask搭建后端架构,通过requests爬虫从艺恩电影票房网抓取数据并存储至MySQL数据库,借助Echarts实现多维度可视化分析。系统涵盖地区票房占比、月份票房、类型票房占比等分析模块,支持按年份查看实时票房排名,同步记录采集日志,用户可灵活筛选条件查看可视化图表与数据表格。该系统为电影行业从业者及爱好者提供了便捷的票房数据查询与分析工具,能直观呈现票房分布、趋势等核心信息。
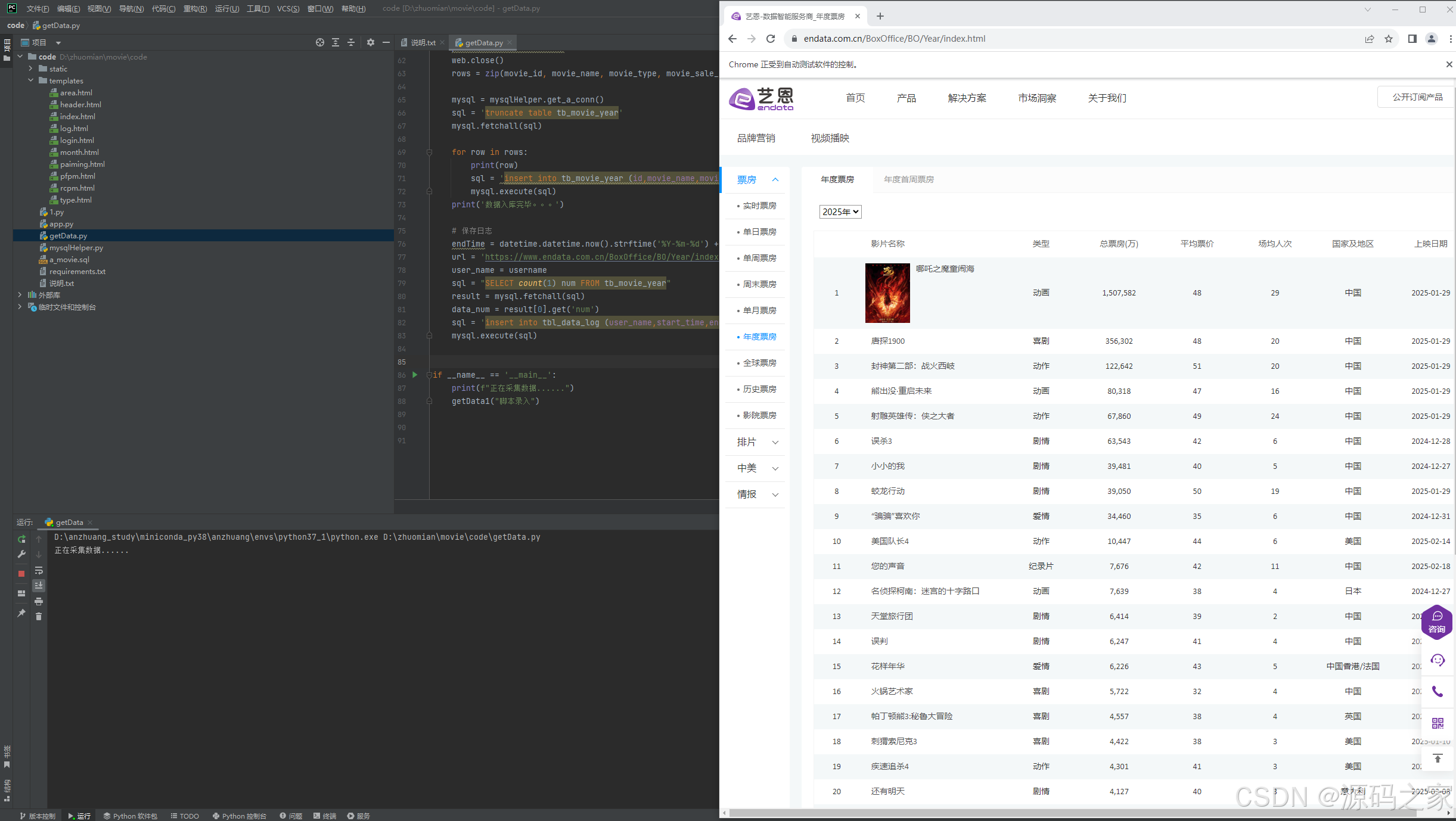
4、核心代码
from selenium.webdriver import Chrome
from selenium.webdriver.support.select import Select
import sys
sys.path.append('utils')
import mysqlHelper
import datetime
import time
# 获取列表信息
def getData1(username):
web = Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
# 找到下拉菜单
sel_list = web.find_element_by_xpath('//*[@id="OptionDate"]')
sel = Select(sel_list)
# 初始化信息列表
movie_id = []
movie_name = []
movie_type = []
movie_sale_number = []
movie_average_sale = []
movie_average_people = []
movie_country = []
movie_online_time = []
movie_year = []
startTime = datetime.datetime.now().strftime('%Y-%m-%d') + ' ' + time.strftime("%H:%M:%S")
for s in range(len(sel.options)):
# 使用index索引逐个选择下拉菜单
sel.select_by_index(s)
time.sleep(2)
# 获取到每一个tr
tr_list = web.find_elements_by_xpath('//*[@id="TableList"]/table/tbody/tr')
for tr in range(len(tr_list)):
# 获取select选中的值
ele_sel = web.find_element_by_xpath('//*[@id="OptionDate"]') # 获取Select元素对像
year = ele_sel.get_attribute('value') # 获取Select选中的值
# 获取每一个tr里的信息
money = tr_list[tr].find_element_by_xpath('./td[4]').text
money = money.replace(',', '')
movie_id.append(tr_list[tr].find_element_by_xpath('./td[1]').text)
movie_name.append(tr_list[tr].find_element_by_xpath('./td[2]').text)
movie_type.append(tr_list[tr].find_element_by_xpath('./td[3]').text)
movie_sale_number.append(money)
movie_average_sale.append(tr_list[tr].find_element_by_xpath('./td[5]').text)
movie_average_people.append(tr_list[tr].find_element_by_xpath('./td[6]').text)
movie_country.append(tr_list[tr].find_element_by_xpath('./td[7]').text)
movie_online_time.append(tr_list[tr].find_element_by_xpath('./td[8]').text)
movie_year.append(year)
print('数据获取完毕。。。')
web.close()
rows = zip(movie_id,movie_name, movie_type, movie_sale_number, movie_average_sale, movie_average_people, movie_country,movie_online_time,movie_year)
mysql = mysqlHelper.get_a_conn()
sql = 'truncate table tb_movie_year'
mysql.fetchall(sql)
for row in rows:
print(row)
sql = 'insert into tb_movie_year (id,movie_name,movie_type,movie_money,movie_price,movie_peo,movie_country,movie_date,movie_year) values("%s","%s","%s","%s","%s","%s","%s","%s","%s")' % row
mysql.execute(sql)
print('数据入库完毕。。。')
# 保存日志
endTime = datetime.datetime.now().strftime('%Y-%m-%d') + ' ' + time.strftime("%H:%M:%S")
url = 'https://www.endata.com.cn/BoxOffice/BO/Year/index.html'
user_name = username
sql = "SELECT count(1) num FROM tb_movie_year"
result = mysql.fetchall(sql)
data_num = result[0].get('num')
sql = 'insert into tbl_data_log (user_name,start_time,end_time,data_num,data_url) values ("%s","%s","%s","%s","%s")' % (user_name,startTime,endTime,data_num,url)
mysql.execute(sql)
if __name__ == '__main__':
getData1("脚本录入")
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
© 版权声明
文章版权归作者所有,未经允许请勿转载。


