AI生成图片R18提示词:新手入门指南与最佳实践
____simple_html_dom__voku__html_wrapper____>
快速体验
在开始今天关于 AI生成图片R18提示词:新手入门指南与最佳实践 的探讨之前,我想先分享一个最近让我觉得很有意思的全栈技术挑战。
我们常说 AI 是未来,但作为开发者,如何将大模型(LLM)真正落地为一个低延迟、可交互的实时系统,而不仅仅是调个 API?
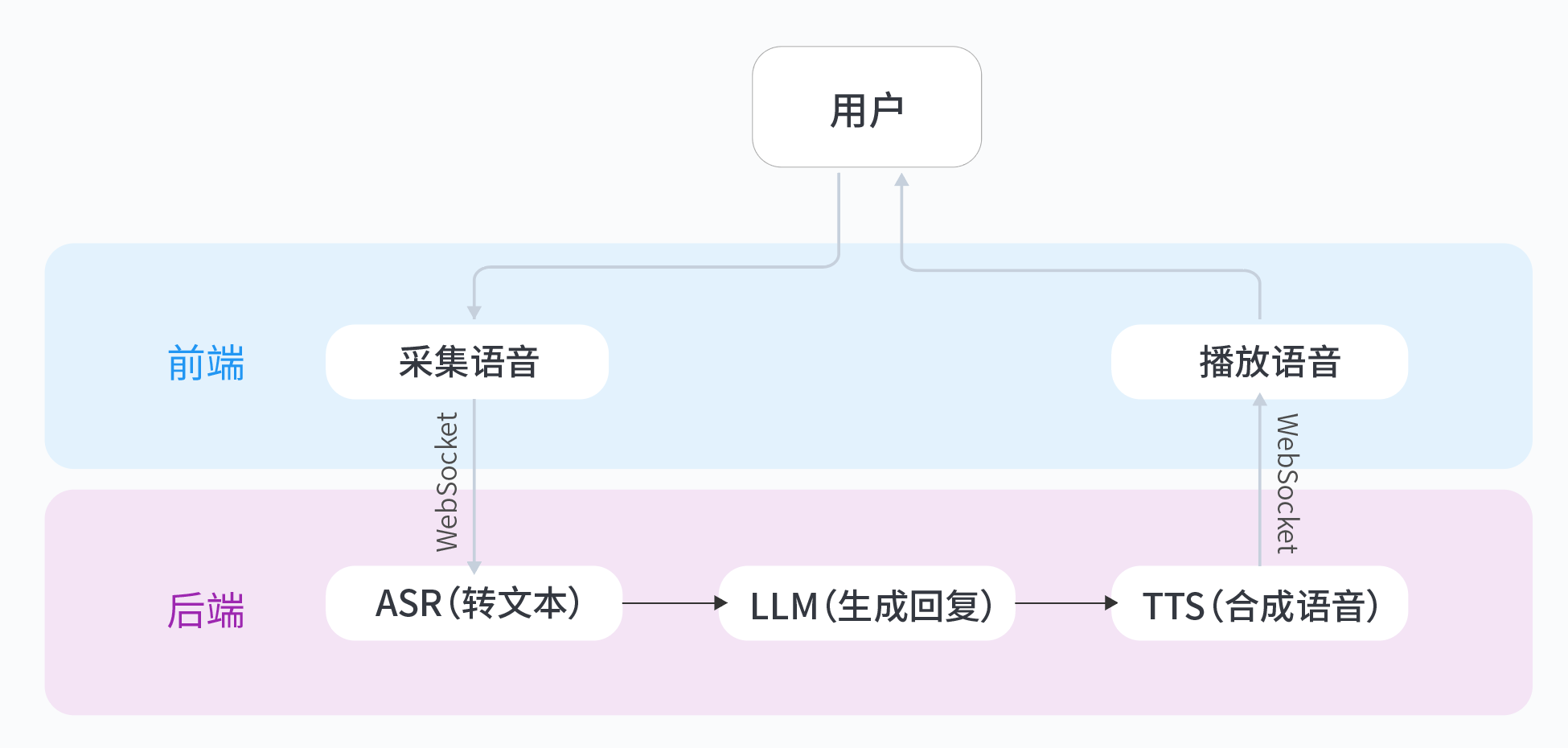
这里有一个非常硬核的动手实验:基于火山引擎豆包大模型,从零搭建一个实时语音通话应用。它不是简单的问答,而是需要你亲手打通 ASR(语音识别)→ LLM(大脑思考)→ TTS(语音合成)的完整 WebSocket 链路。对于想要掌握 AI 原生应用架构的同学来说,这是个绝佳的练手项目。

从0到1构建生产级别应用,脱离Demo,点击打开 从0打造个人豆包实时通话AI动手实验
AI生成图片R18提示词:新手入门指南与最佳实践
背景与痛点
对于刚接触AI生成图片的新手来说,使用R18提示词往往会遇到几个典型问题:
- 内容合规性把控困难:多数平台对生成内容有严格限制,容易触发审核机制导致生成失败
- 提示词效果不稳定:相同的提示词在不同模型或参数下可能产生差异巨大的结果
- 细节控制能力不足:难以精确控制生成图片的构图、风格和具体元素
- 伦理边界模糊:缺乏对生成内容合理使用范围的专业判断
技术选型对比
主流AI图片生成模型对R18提示词的响应存在显著差异:
-
Stable Diffusion系列:
- 优点:开源可本地部署,支持LoRA微调
- 限制:需要较强硬件支持,默认模型过滤严格
-
DALL·E 3:
- 优点:与ChatGPT集成,理解复杂描述
- 限制:内容审查最严格,创意受限
-
MidJourney:
- 优点:艺术表现力强,社区资源丰富
- 限制:仅限Discord使用,审查机制不透明
核心实现细节
关键词选择三要素
- 主体描述:使用明确的名词组合(如"fantasy elf"而非简单"person")
- 风格限定:叠加至少2种风格标签(如"digital painting, anime style")
- 细节修饰:通过形容词分级控制(如"lightly detailed"→"hyper detailed")
语法结构示例
[主体][动作][场景][风格][光照][细节][负面提示]
↓
"mysterious sorceress casting spell in moonlit forest,
digital painting style, volumetric lighting,
intricate details, nsfw,
negative prompt: deformed, blurry"
代码示例
import requests
import base64
def generate_r18_image(api_key, prompt):
# 配置API参数
headers = {"Authorization": f"Bearer {api_key}"}
payload = {
"prompt": prompt,
"steps": 30, # 渲染迭代次数
"cfg_scale": 7, # 提示词遵循度
"width": 512,
"height": 768,
"safety_checker": False # 本地部署时可关闭安全检查
}
try:
response = requests.post(
"https://api.stable-diffusion.com/v1/generate",
headers=headers,
json=payload
)
response.raise_for_status()
# 解码Base64图片数据
image_data = base64.b64decode(response.json()["image"])
with open("output.png", "wb") as f:
f.write(image_data)
except Exception as e:
print(f"生成失败: {str(e)}")
# 示例调用
prompt = "fantasy warrior, dynamic pose, detailed armor,
cinematic lighting, trending on artstation,
negative: low quality, extra limbs"
generate_r18_image("your_api_key_here", prompt)
性能与安全性
资源优化方案
-
显存控制:
- 使用–medvram参数启动Stable Diffusion
- 分辨率不超过512×768像素
-
批量生成技巧:
# 使用种子值生成变体 params = { "seed": 12345, "variation_strength": 0.3 }
合规检查策略
-
预处理过滤:
banned_words = ["loli", "violent"] if any(word in prompt.lower() for word in banned_words): raise ValueError("包含违禁关键词") -
后处理审核:
- 使用CLIP模型计算图片与敏感概念的相似度
- 设置置信度阈值自动过滤
避坑指南
常见错误及解决方案
-
生成内容破碎:
- 问题:肢体畸形/物体融合
- 解决:增加"perfect anatomy"等负面提示词
-
风格偏离预期:
- 问题:写实与卡通风格混淆
- 解决:明确风格权重"style:cartoon:1.3"
-
审核误判:
- 问题:正常内容被过滤
- 解决:添加"artistic nudity"等说明性标签
进阶技巧
-
提示词矩阵测试:
for style in ["anime", "realistic", "painting"]: test_prompt = f"portrait, {style} style, 8k" generate_image(test_prompt) -
动态参数调整:
def auto_adjust_cfg(original_prompt): # 根据提示词长度自动调整引导系数 return min(7 + len(original_prompt)/100, 12)
通过系统学习这些方法,开发者可以更安全高效地实现创意表达。建议从从0打造个人豆包实时通话AI等基础实验开始积累经验,逐步掌握AI内容生成的完整技术栈。
实验介绍
这里有一个非常硬核的动手实验:基于火山引擎豆包大模型,从零搭建一个实时语音通话应用。它不是简单的问答,而是需要你亲手打通 ASR(语音识别)→ LLM(大脑思考)→ TTS(语音合成)的完整 WebSocket 链路。对于想要掌握 AI 原生应用架构的同学来说,这是个绝佳的练手项目。
你将收获:
- 架构理解:掌握实时语音应用的完整技术链路(ASR→LLM→TTS)
- 技能提升:学会申请、配置与调用火山引擎AI服务
- 定制能力:通过代码修改自定义角色性格与音色,实现“从使用到创造”
从0到1构建生产级别应用,脱离Demo,点击打开 从0打造个人豆包实时通话AI动手实验
© 版权声明
文章版权归作者所有,未经允许请勿转载。