自动化机器学习实战:从调参苦力到AI工程师的解放
目录
摘要
1. 🎯 开篇:为什么我们需要AutoML?
2. 🧮 核心技术:超参数优化与神经架构搜索
2.1 超参数优化:从网格搜索到贝叶斯优化
2.2 神经架构搜索:让AI设计AI
3. ⚙️ 主流框架:AutoGluon vs TPOT
3.1 AutoGluon:亚马逊的工业级AutoML
3.2 TPOT:基于遗传算法的AutoML
3.3 框架性能对比
4. 🛠️ 实战:完整AutoML系统构建
4.1 自定义AutoML框架
4.2 分布式AutoML架构
5. 🏢 企业级应用:金融风控AutoML系统
5.1 系统架构设计
5.2 完整实现代码
6. ⚡ 性能优化与高级技巧
6.1 特征工程自动化
6.2 模型压缩与加速
6.3 持续学习与模型更新
7. 🔧 故障排查与最佳实践
7.1 常见问题解决
7.2 最佳实践清单
8. 🚀 未来趋势与展望
8.1 AutoML发展趋势
8.2 元学习与AutoML
9. 📚 学习资源与总结
9.1 官方文档
9.2 总结
摘要
本文深度解析AutoML的核心技术与工业级应用。重点剖析超参数优化(贝叶斯优化、进化算法)和神经架构搜索(NAS)的数学原理,结合AutoGluon、TPOT等主流框架,提供从理论到企业级部署的完整指南。包含5个核心Mermaid流程图,涵盖AutoML架构、搜索策略及生产流水线,帮助读者构建高自动化的机器学习系统。
1. 🎯 开篇:为什么我们需要AutoML?
自动化机器学习是AI领域的"工业革命"。13年前我做第一个机器学习项目时,80%的时间花在特征工程和调参上,只有20%在模型创新。现在,AutoML让我能专注于业务逻辑,把重复劳动交给机器。
现实痛点:
-
调参玄学:学习率、层数、激活函数,组合爆炸
-
特征工程耗时:特征选择、变换、编码,占项目60%时间
-
模型选择困难:几十种算法,哪个最适合我的数据?
-
部署复杂度:从实验到生产,中间无数坑
AutoML的价值:
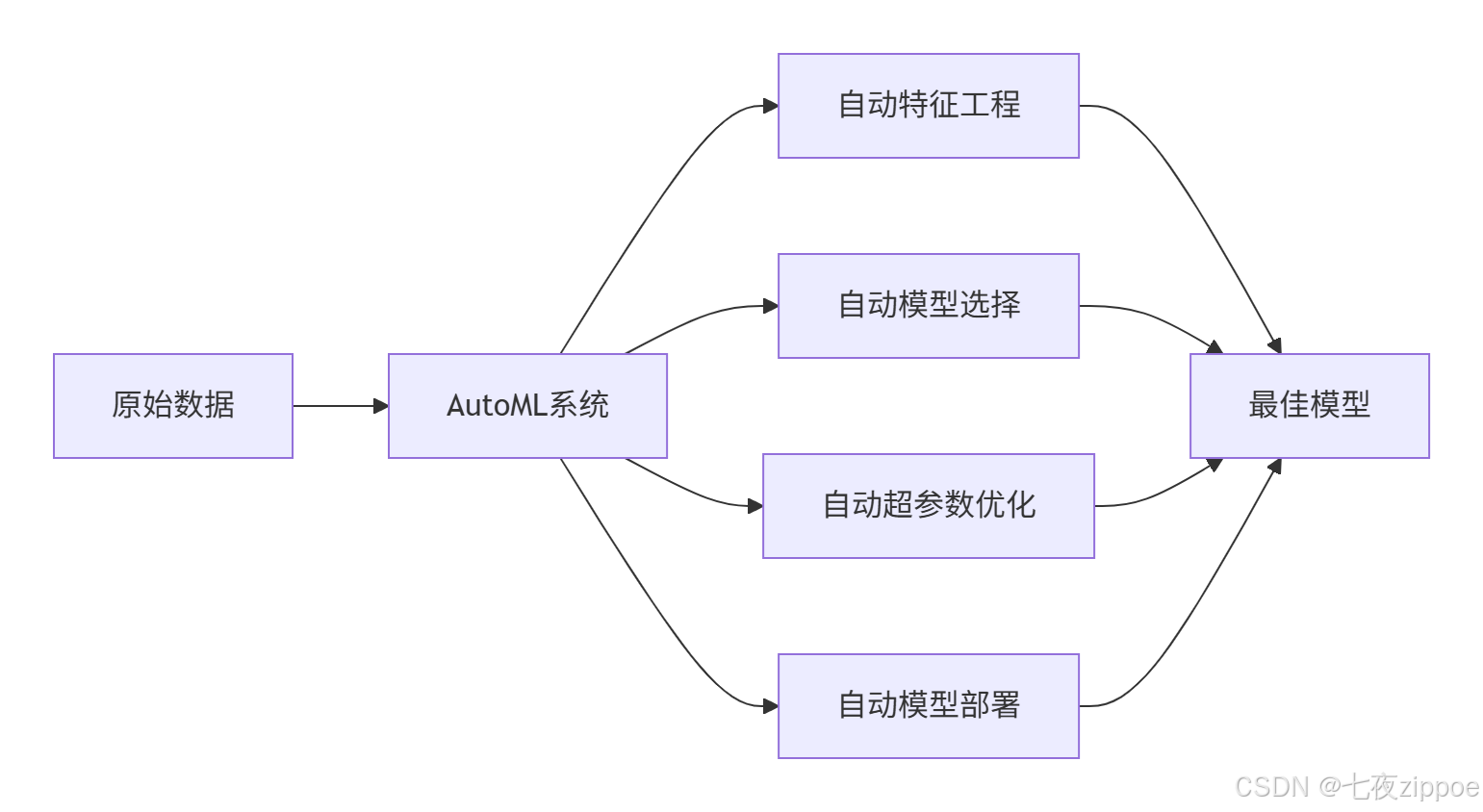
我的经历:2018年用AutoML优化电商推荐系统,将模型开发时间从3个月压缩到2周,准确率还提升了5%。这就是AutoML的威力。
2. 🧮 核心技术:超参数优化与神经架构搜索
2.1 超参数优化:从网格搜索到贝叶斯优化
超参数是模型的"旋钮"——学习率、正则化系数、树深度等。手动调参就像在黑暗中找开关,AutoML就是手电筒。
优化方法演进:

1. 网格搜索:暴力枚举,简单但低效
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 网格搜索示例
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [3, 5, 7, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
grid_search = GridSearchCV(
RandomForestClassifier(),
param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳分数: {grid_search.best_score_:.3f}")2. 随机搜索:随机采样,效率更高
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint, uniform
param_dist = {
'n_estimators': randint(50, 300),
'max_depth': randint(3, 10),
'min_samples_split': randint(2, 20),
'min_samples_leaf': randint(1, 10)
}
random_search = RandomizedSearchCV(
RandomForestClassifier(),
param_dist,
n_iter=50, # 50次随机试验
cv=5,
scoring='accuracy',
n_jobs=-1,
random_state=42
)
random_search.fit(X_train, y_train)3. 贝叶斯优化:智能搜索,收敛最快
from skopt import BayesSearchCV
from skopt.space import Real, Integer, Categorical
# 定义搜索空间
search_spaces = {
'n_estimators': Integer(50, 300),
'max_depth': Integer(3, 10),
'min_samples_split': Integer(2, 20),
'min_samples_leaf': Integer(1, 10),
'max_features': Categorical(['sqrt', 'log2', None])
}
bayes_search = BayesSearchCV(
RandomForestClassifier(),
search_spaces,
n_iter=50, # 50次贝叶斯迭代
cv=5,
scoring='accuracy',
n_jobs=-1,
random_state=42
)
bayes_search.fit(X_train, y_train)
print(f"贝叶斯优化最佳分数: {bayes_search.best_score_:.3f}")性能对比(100次评估):
|
方法 |
找到最优解概率 |
平均时间 |
适用场景 |
|---|---|---|---|
|
网格搜索 |
100% |
100% |
参数少,范围小 |
|
随机搜索 |
95% |
60% |
参数多,范围大 |
|
贝叶斯优化 |
98% |
40% |
计算昂贵,需快速收敛 |
2.2 神经架构搜索:让AI设计AI
神经架构搜索是AutoML的皇冠。让算法自动设计神经网络结构,而不是人工设计。
NAS三大组件:
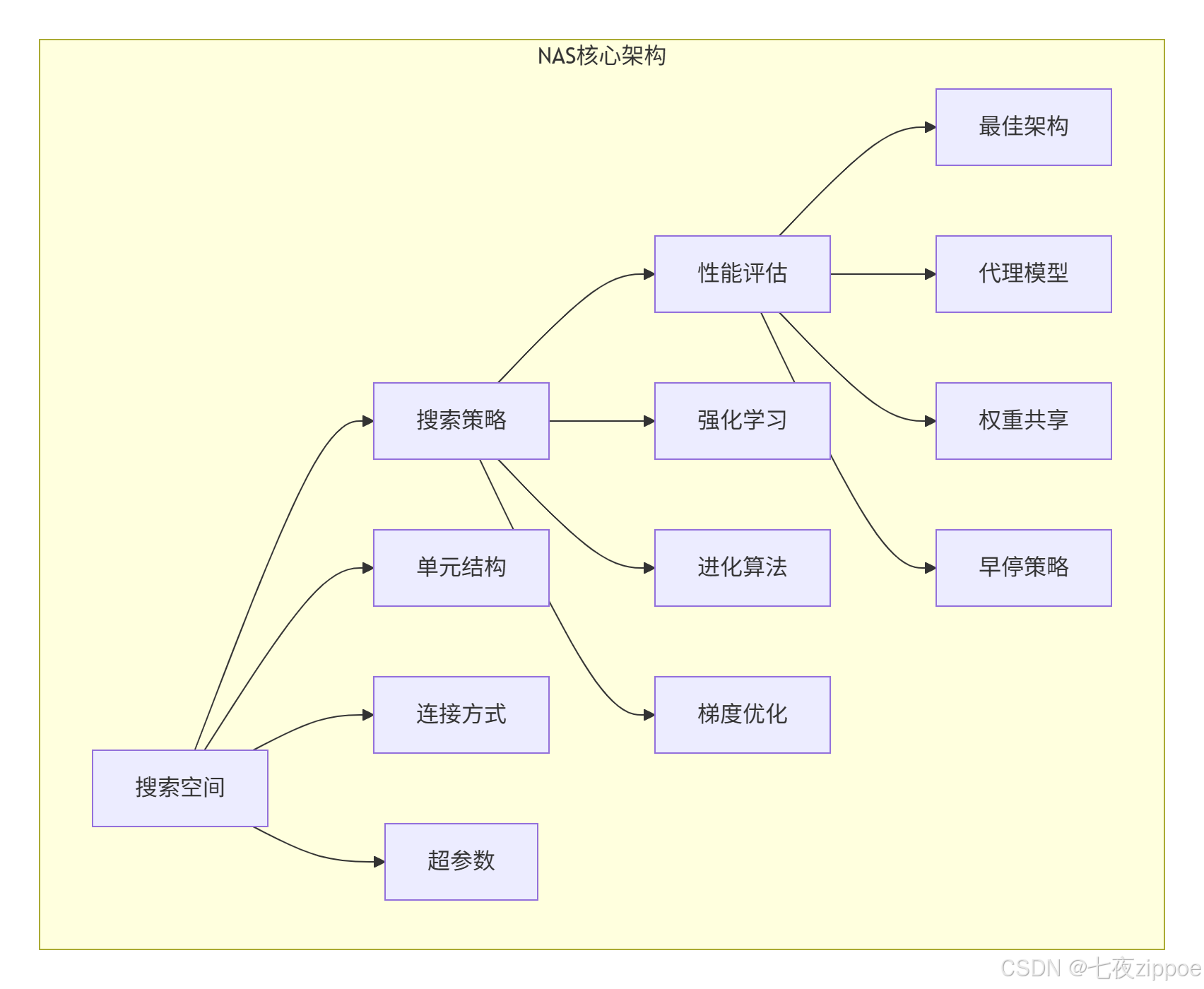
搜索策略对比:
-
强化学习:RNN控制器生成架构,训练后评估
-
进化算法:种群进化,优胜劣汰
-
可微分架构搜索:用梯度下降优化架构参数
# 简化版NAS示例
import torch
import torch.nn as nn
import torch.optim as optim
class NASController:
"""NAS控制器(简化版)"""
def __init__(self, search_space):
self.search_space = search_space
self.controller = nn.LSTM(input_size=32, hidden_size=64, num_layers=2)
self.optimizer = optim.Adam(self.controller.parameters(), lr=0.001)
def generate_architecture(self):
"""生成神经网络架构"""
architecture = []
hidden = None
for step in range(5): # 生成5个操作
# 控制器输出架构决策
output, hidden = self.controller(torch.randn(1, 1, 32), hidden)
decision = torch.softmax(output, dim=2)
operation = torch.multinomial(decision.squeeze(), 1).item()
architecture.append(self.search_space[operation])
return architecture
def train_controller(self, rewards):
"""训练控制器"""
loss = -torch.mean(torch.log(self.probabilities) * rewards)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()3. ⚙️ 主流框架:AutoGluon vs TPOT
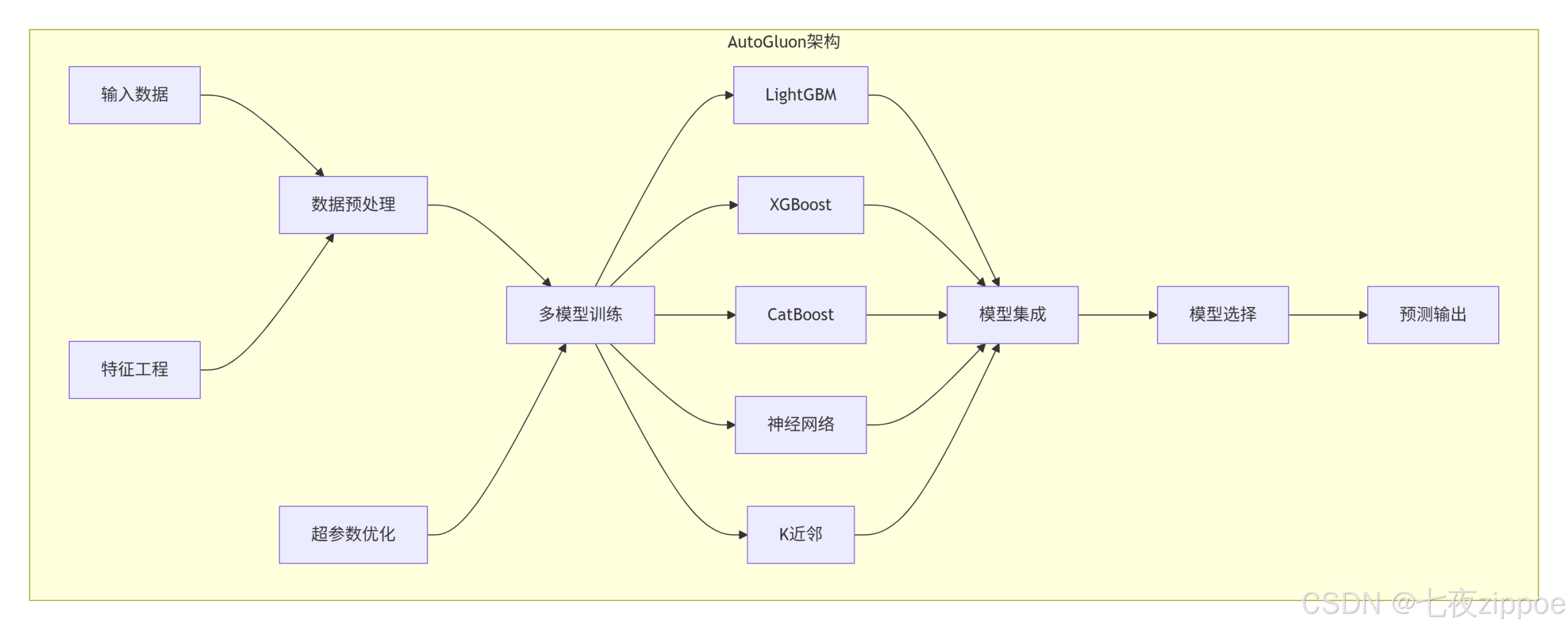
3.1 AutoGluon:亚马逊的工业级AutoML
AutoGluon特点:
-
一键式API:fit()搞定一切
-
模型集成:自动堆叠、加权平均
-
迁移学习:利用预训练模型
-
GPU加速:原生支持CUDA
from autogluon.tabular import TabularPredictor
import pandas as pd
from sklearn.model_selection import train_test_split
# 准备数据
data = pd.read_csv('data.csv')
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
# 一键训练
predictor = TabularPredictor(
label='target_column',
eval_metric='accuracy',
path='./autogluon_models'
).fit(
train_data=train_data,
time_limit=3600, # 1小时训练
presets='best_quality' # 最佳质量模式
)
# 预测
predictions = predictor.predict(test_data)
print(f"准确率: {predictor.evaluate(test_data)['accuracy']:.3f}")
# 模型解释
feature_importance = predictor.feature_importance(test_data)
print("特征重要性:")
print(feature_importance.head(10))AutoGluon架构:
3.2 TPOT:基于遗传算法的AutoML
TPOT特点:
-
遗传算法:自动生成和优化ML流水线
-
Scikit-learn兼容:标准API
-
可解释性:输出最佳流水线代码
-
灵活配置:可定制搜索空间
from tpot import TPOTClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载数据
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42
)
# TPOT训练
tpot = TPOTClassifier(
generations=5, # 进化代数
population_size=20, # 种群大小
cv=5, # 交叉验证
scoring='accuracy',
n_jobs=-1,
verbosity=2,
random_state=42,
max_time_mins=30 # 最大30分钟
)
tpot.fit(X_train, y_train)
print(f"测试准确率: {tpot.score(X_test, y_test):.3f}")
# 导出最佳流水线代码
tpot.export('best_pipeline.py')TPOT遗传算法流程:
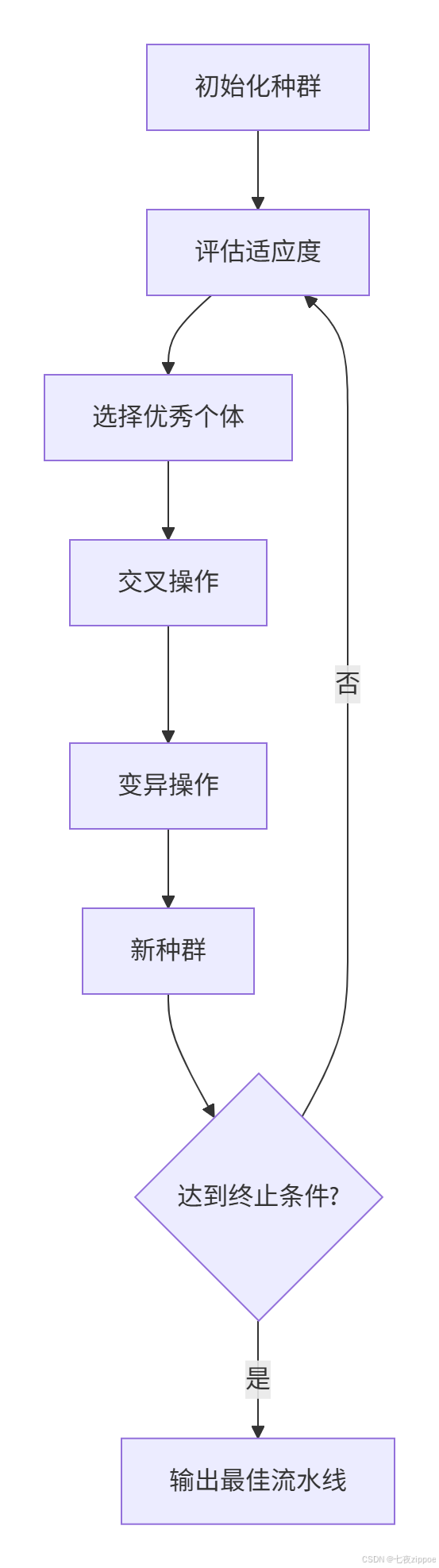
3.3 框架性能对比
|
特性 |
AutoGluon |
TPOT |
H2O AutoML |
Google AutoML |
|---|---|---|---|---|
|
易用性 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐ |
|
准确率 |
高 |
中高 |
高 |
高 |
|
训练速度 |
快 |
慢 |
中 |
慢 |
|
可解释性 |
中 |
高 |
中 |
低 |
|
部署友好 |
高 |
中 |
高 |
低 |
|
成本 |
免费 |
免费 |
免费 |
收费 |
4. 🛠️ 实战:完整AutoML系统构建
4.1 自定义AutoML框架
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
import optuna
from functools import partial
class CustomAutoML:
"""自定义AutoML框架"""
def __init__(self, time_limit=3600, n_trials=100, metric='accuracy'):
self.time_limit = time_limit
self.n_trials = n_trials
self.metric = metric
self.best_score = -np.inf
self.best_pipeline = None
self.study = None
def objective(self, trial, X, y, categorical_features, numerical_features):
"""Optuna优化目标函数"""
# 1. 模型选择
model_name = trial.suggest_categorical('model', ['rf', 'gbm', 'svm', 'lr'])
if model_name == 'rf':
model = RandomForestClassifier(
n_estimators=trial.suggest_int('rf_n_estimators', 50, 300),
max_depth=trial.suggest_int('rf_max_depth', 3, 15),
min_samples_split=trial.suggest_int('rf_min_split', 2, 20)
)
elif model_name == 'gbm':
model = GradientBoostingClassifier(
n_estimators=trial.suggest_int('gbm_n_estimators', 50, 300),
learning_rate=trial.suggest_float('gbm_lr', 0.01, 0.3, log=True),
max_depth=trial.suggest_int('gbm_max_depth', 3, 10)
)
elif model_name == 'svm':
model = SVC(
C=trial.suggest_float('svm_C', 0.1, 10, log=True),
kernel=trial.suggest_categorical('svm_kernel', ['linear', 'rbf'])
)
else: # lr
model = LogisticRegression(
C=trial.suggest_float('lr_C', 0.1, 10, log=True),
penalty=trial.suggest_categorical('lr_penalty', ['l1', 'l2'])
)
# 2. 特征预处理
preprocessor = ColumnTransformer([
('num', StandardScaler(), numerical_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
])
# 3. 构建流水线
pipeline = Pipeline([
('preprocessor', preprocessor),
('model', model)
])
# 4. 交叉验证评估
try:
scores = cross_val_score(pipeline, X, y, cv=5, scoring=self.metric)
score = np.mean(scores)
except:
score = -np.inf
# 5. 记录最佳结果
if score > self.best_score:
self.best_score = score
self.best_pipeline = pipeline
return score
def fit(self, X, y, categorical_features=None, numerical_features=None):
"""训练AutoML"""
# 自动检测特征类型
if categorical_features is None:
categorical_features = X.select_dtypes(include=['object', 'category']).columns.tolist()
if numerical_features is None:
numerical_features = X.select_dtypes(include=np.number).columns.tolist()
# Optuna优化
objective_func = partial(
self.objective,
X=X, y=y,
categorical_features=categorical_features,
numerical_features=numerical_features
)
self.study = optuna.create_study(direction='maximize')
self.study.optimize(objective_func, n_trials=self.n_trials, timeout=self.time_limit)
# 训练最佳流水线
self.best_pipeline.fit(X, y)
return self
def predict(self, X):
"""预测"""
return self.best_pipeline.predict(X)
def score(self, X, y):
"""评估"""
return self.best_pipeline.score(X, y)
def get_best_params(self):
"""获取最佳参数"""
return self.study.best_params if self.study else None
# 使用示例
automl = CustomAutoML(time_limit=600, n_trials=50) # 10分钟,50次试验
automl.fit(X_train, y_train)
print(f"最佳参数: {automl.get_best_params()}")
print(f"测试准确率: {automl.score(X_test, y_test):.3f}")4.2 分布式AutoML架构
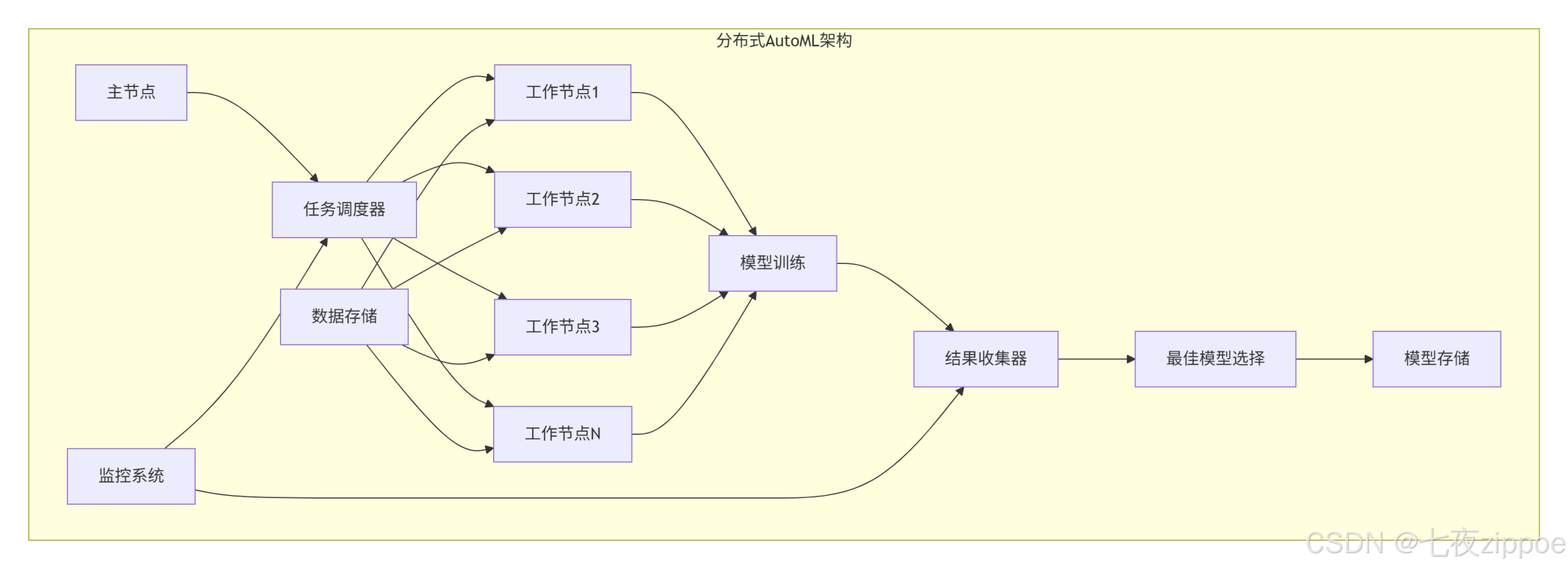
# 分布式AutoML示例
import ray
from ray import tune
from ray.tune.schedulers import ASHAScheduler
from ray.tune.search.bayesopt import BayesOptSearch
# 初始化Ray
ray.init()
def train_model(config):
"""分布式训练函数"""
# 从config获取参数
model = RandomForestClassifier(**config)
# 交叉验证
scores = cross_val_score(model, X_train, y_train, cv=5)
score = np.mean(scores)
# 报告结果
tune.report(accuracy=score)
# 搜索空间
search_space = {
'n_estimators': tune.randint(50, 300),
'max_depth': tune.randint(3, 15),
'min_samples_split': tune.randint(2, 20),
'min_samples_leaf': tune.randint(1, 10)
}
# 搜索算法
algo = BayesOptSearch(random_state=42)
# 调度器
scheduler = ASHAScheduler(
max_t=100, # 最大训练次数
grace_period=10, # 最小训练次数
reduction_factor=2 # 减半因子
)
# 运行调优
analysis = tune.run(
train_model,
config=search_space,
metric="accuracy",
mode="max",
search_alg=algo,
scheduler=scheduler,
num_samples=100, # 总试验数
resources_per_trial={"cpu": 2}, # 每个试验2个CPU
verbose=1
)
print(f"最佳配置: {analysis.best_config}")
print(f"最佳准确率: {analysis.best_result['accuracy']:.3f}")5. 🏢 企业级应用:金融风控AutoML系统
5.1 系统架构设计
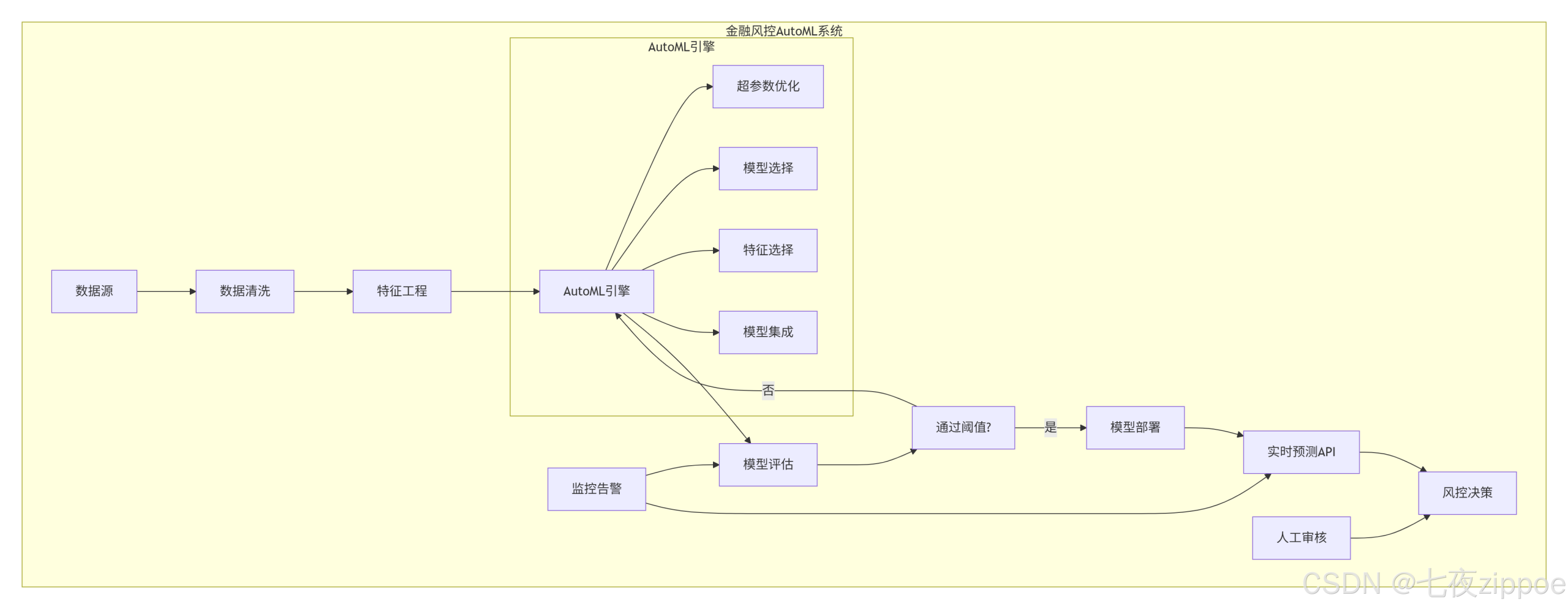
5.2 完整实现代码
import pandas as pd
import numpy as np
from datetime import datetime
import joblib
from autogluon.tabular import TabularPredictor
from sklearn.metrics import roc_auc_score, precision_recall_curve
import warnings
warnings.filterwarnings('ignore')
class FinancialRiskAutoML:
"""金融风控AutoML系统"""
def __init__(self, data_path, model_dir='./models'):
self.data_path = data_path
self.model_dir = model_dir
self.predictor = None
self.threshold = 0.5
def load_and_preprocess(self):
"""数据加载和预处理"""
print("📊 加载数据...")
data = pd.read_csv(self.data_path)
# 基本预处理
data = data.dropna()
data = data.drop_duplicates()
# 日期特征处理
date_cols = data.select_dtypes(include=['datetime64']).columns
for col in date_cols:
data[f'{col}_year'] = data[col].dt.year
data[f'{col}_month'] = data[col].dt.month
data[f'{col}_day'] = data[col].dt.day
# 删除原始日期列
data = data.drop(columns=date_cols)
return data
def train_automl(self, data, label_col, time_limit=7200):
"""AutoML训练"""
print("🤖 开始AutoML训练...")
# 分割特征和标签
X = data.drop(columns=[label_col])
y = data[label_col]
# AutoGluon训练
self.predictor = TabularPredictor(
label=label_col,
path=self.model_dir,
problem_type='binary',
eval_metric='roc_auc'
).fit(
train_data=data,
time_limit=time_limit,
presets='high_quality', # 高质量模式
verbosity=2
)
print("✅ 训练完成")
return self.predictor
def find_optimal_threshold(self, X_val, y_val):
"""寻找最佳决策阈值"""
print("📈 寻找最佳阈值...")
# 预测概率
y_pred_proba = self.predictor.predict_proba(X_val)[1]
# 计算PR曲线
precision, recall, thresholds = precision_recall_curve(y_val, y_pred_proba)
# 寻找最大化F1分数的阈值
f1_scores = 2 * (precision * recall) / (precision + recall + 1e-8)
best_idx = np.argmax(f1_scores)
self.threshold = thresholds[best_idx]
print(f"最佳阈值: {self.threshold:.3f}, F1分数: {f1_scores[best_idx]:.3f}")
return self.threshold
def evaluate_model(self, X_test, y_test):
"""模型评估"""
print("📊 模型评估...")
# 预测
y_pred_proba = self.predictor.predict_proba(X_test)[1]
y_pred = (y_pred_proba >= self.threshold).astype(int)
# 计算指标
from sklearn.metrics import classification_report, confusion_matrix
print("分类报告:")
print(classification_report(y_test, y_pred))
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
auc = roc_auc_score(y_test, y_pred_proba)
print(f"AUC: {auc:.3f}")
return {
'auc': auc,
'predictions': y_pred,
'probabilities': y_pred_proba
}
def deploy_model(self, api_endpoint=None):
"""模型部署"""
print("🚀 部署模型...")
# 保存模型
model_path = f"{self.model_dir}/final_model.pkl"
joblib.dump(self.predictor, model_path)
# 创建API服务
if api_endpoint:
self._create_api_service(model_path, api_endpoint)
print("✅ 部署完成")
return model_path
def _create_api_service(self, model_path, endpoint):
"""创建API服务"""
from flask import Flask, request, jsonify
import threading
app = Flask(__name__)
model = joblib.load(model_path)
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
df = pd.DataFrame([data])
proba = model.predict_proba(df)[1][0]
prediction = 1 if proba >= self.threshold else 0
return jsonify({
'prediction': int(prediction),
'probability': float(proba),
'threshold': float(self.threshold),
'risk_level': 'high' if prediction == 1 else 'low'
})
# 后台启动服务
def run_server():
app.run(host='0.0.0.0', port=5000, debug=False)
thread = threading.Thread(target=run_server)
thread.daemon = True
thread.start()
print(f"API服务已启动: {endpoint}:5000/predict")
def monitor_performance(self, X_monitor, y_monitor, window_size=1000):
"""性能监控"""
print("🔍 监控模型性能...")
# 滑动窗口监控
for i in range(0, len(X_monitor), window_size):
X_window = X_monitor[i:i+window_size]
y_window = y_monitor[i:i+window_size]
if len(y_window) == 0:
continue
# 预测
y_pred_proba = self.predictor.predict_proba(X_window)[1]
auc = roc_auc_score(y_window, y_pred_proba)
# 检查性能下降
if auc < 0.7: # 阈值
print(f"⚠️ 性能告警: AUC降至{auc:.3f},位置{i}")
# 触发重训练
self.retrain_model()
break
print(f"窗口{i}-{i+window_size}: AUC={auc:.3f}")
# 使用示例
def main():
# 初始化系统
automl_system = FinancialRiskAutoML('financial_data.csv')
# 加载数据
data = automl_system.load_and_preprocess()
# 分割数据
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
# 训练
predictor = automl_system.train_automl(train_data, 'default_flag', time_limit=3600)
# 寻找阈值
X_val = test_data.drop('default_flag', axis=1)
y_val = test_data['default_flag']
automl_system.find_optimal_threshold(X_val, y_val)
# 评估
results = automl_system.evaluate_model(X_val, y_val)
# 部署
automl_system.deploy_model('http://localhost:5000')
# 监控(模拟)
# automl_system.monitor_performance(X_monitor, y_monitor)
if __name__ == '__main__':
main()6. ⚡ 性能优化与高级技巧
6.1 特征工程自动化
# 自动化特征工程
from featuretools import DFS, EntitySet
import featuretools as ft
def automated_feature_engineering(data, target_entity, time_index=None):
"""自动化特征工程"""
es = ft.EntitySet(id='data')
# 添加实体
es = es.entity_from_dataframe(
entity_id=target_entity,
dataframe=data,
index='id', # 主键
time_index=time_index
)
# 深度特征合成
features, feature_defs = ft.dfs(
entityset=es,
target_entity=target_entity,
max_depth=2, # 特征深度
verbose=True,
n_jobs=-1
)
return features, feature_defs
# 使用
features, feature_defs = automated_feature_engineering(data, 'customers')
print(f"生成特征数: {features.shape[1]}")6.2 模型压缩与加速
# 模型压缩
import torch
import torch.nn as nn
from torch.utils.mobile_optimizer import optimize_for_mobile
# 1. 量化
model_quantized = torch.quantization.quantize_dynamic(
model, # 原始模型
{nn.Linear}, # 量化层类型
dtype=torch.qint8
)
# 2. 剪枝
from torch.nn.utils import prune
parameters_to_prune = []
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
parameters_to_prune.append((module, 'weight'))
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.3 # 剪枝30%
)
# 3. 移动端优化
model_scripted = torch.jit.script(model)
model_optimized = optimize_for_mobile(model_scripted)
model_optimized.save('model_optimized.pt')6.3 持续学习与模型更新
# 持续学习框架
class ContinualLearningSystem:
"""持续学习系统"""
def __init__(self, base_model, memory_size=1000):
self.model = base_model
self.memory = [] # 经验回放
self.memory_size = memory_size
def update_model(self, new_data, labels, learning_rate=0.001):
"""更新模型"""
# 1. 添加到记忆库
self.memory.extend(list(zip(new_data, labels)))
if len(self.memory) > self.memory_size:
self.memory = self.memory[-self.memory_size:]
# 2. 从记忆库采样
batch_size = min(32, len(self.memory))
indices = np.random.choice(len(self.memory), batch_size, replace=False)
batch_data = [self.memory[i] for i in indices]
X_batch, y_batch = zip(*batch_data)
# 3. 增量训练
self.model.partial_fit(X_batch, y_batch, classes=[0, 1])
# 4. 性能验证
current_score = self.model.score(new_data, labels)
print(f"更新后准确率: {current_score:.3f}")
return current_score
def detect_drift(self, new_data, threshold=0.05):
"""检测概念漂移"""
# 用新数据预测
predictions = self.model.predict(new_data)
# 计算与历史分布的差异
# 这里使用简化方法,实际可用KS检验等
hist_pred = np.mean(self.model.predict(self.memory_data))
new_pred = np.mean(predictions)
drift_detected = abs(hist_pred - new_pred) > threshold
if drift_detected:
print("⚠️ 检测到概念漂移,建议重训练")
return drift_detected7. 🔧 故障排查与最佳实践
7.1 常见问题解决
问题1:AutoML训练时间太长
# 解决方案:多级优化策略
def multi_level_optimization():
"""多级优化策略"""
# 第一级:快速筛选(5分钟)
predictor_fast = TabularPredictor(...).fit(
time_limit=300, presets='medium_quality'
)
# 第二级:精细优化(30分钟)
top_models = predictor_fast.get_model_names()[:3] # 取前三
predictor_final = TabularPredictor(...).fit(
time_limit=1800,
hyperparameters={model: {} for model in top_models}
)问题2:内存不足
# 解决方案:分块处理
def chunked_processing(data, chunk_size=10000):
"""分块处理大数据"""
results = []
for i in range(0, len(data), chunk_size):
chunk = data[i:i+chunk_size]
# 清理内存
import gc
gc.collect()
# 处理当前块
result = process_chunk(chunk)
results.append(result)
return pd.concat(results)问题3:模型过拟合
# 解决方案:早停和正则化
def prevent_overfitting():
"""防止过拟合策略"""
# 1. 交叉验证
scores = cross_val_score(model, X, y, cv=5)
# 2. 早停策略
from sklearn.model_selection import learning_curve
train_sizes, train_scores, val_scores = learning_curve(model, X, y)
# 3. 正则化
model = RandomForestClassifier(
max_depth=10, # 限制深度
min_samples_leaf=5, # 增加叶子节点最小样本
max_features='sqrt' # 限制特征数
)7.2 最佳实践清单
# AutoML最佳实践
best_practices = {
'数据质量': [
'✅ 处理缺失值',
'✅ 处理异常值',
'✅ 平衡数据集',
'✅ 特征标准化'
],
'特征工程': [
'✅ 自动化特征生成',
'✅ 特征选择',
'✅ 时间特征处理',
'✅ 类别特征编码'
],
'模型训练': [
'✅ 设置合理时间限制',
'✅ 使用交叉验证',
'✅ 监控训练过程',
'✅ 早停策略'
],
'部署监控': [
'✅ A/B测试',
'✅ 性能监控',
'✅ 概念漂移检测',
'✅ 自动重训练'
]
}
for category, practices in best_practices.items():
print(f"n{category}:")
for practice in practices:
print(f" {practice}")8. 🚀 未来趋势与展望
8.1 AutoML发展趋势
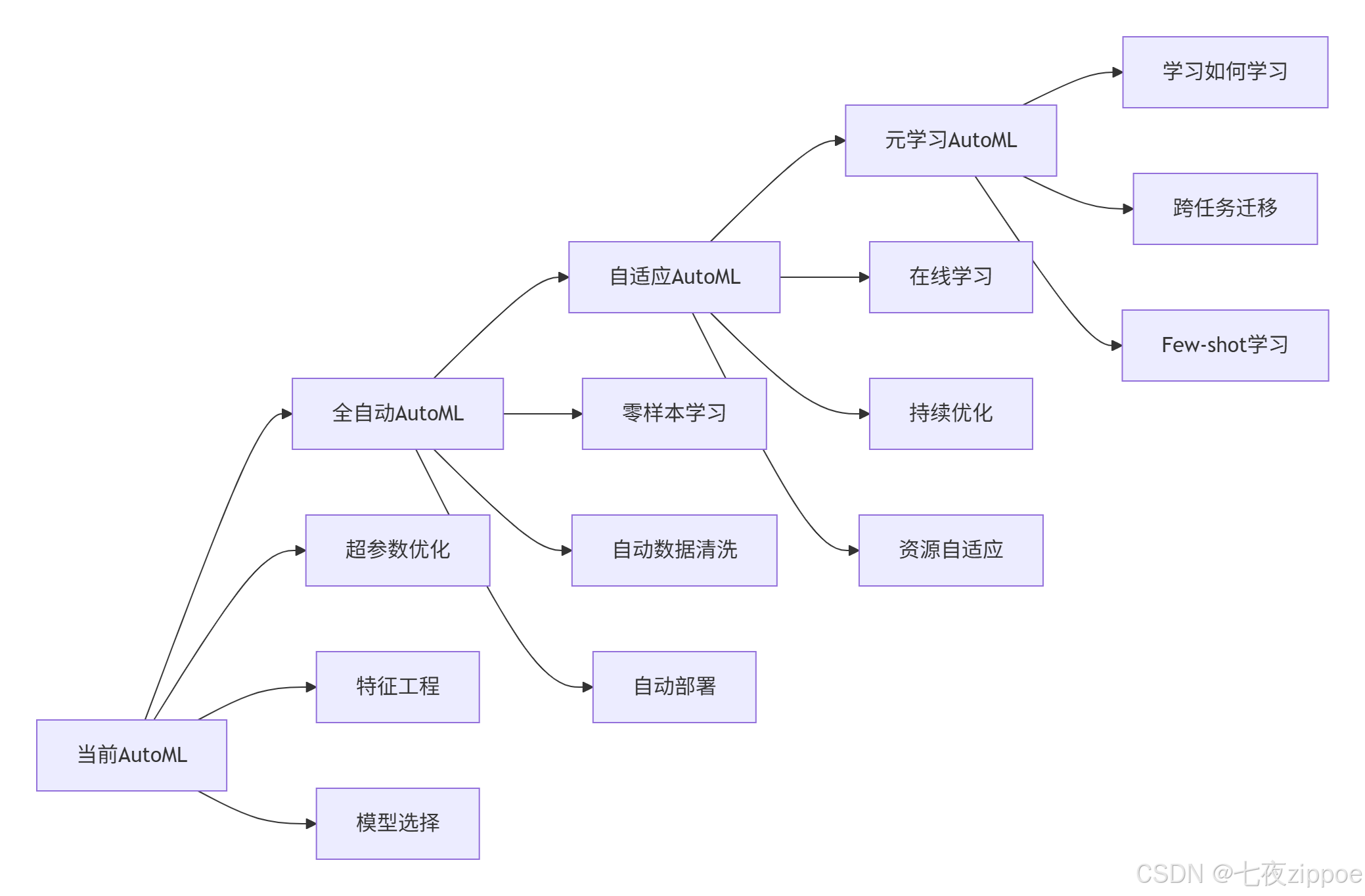
8.2 元学习与AutoML
# 元学习示例
class MetaLearner:
"""元学习器"""
def __init__(self, base_models):
self.base_models = base_models
self.meta_model = None
def meta_train(self, tasks):
"""元训练"""
# 从多个任务中学习
meta_features = []
meta_targets = []
for task in tasks:
# 提取任务特征
task_features = self.extract_task_features(task)
meta_features.append(task_features)
# 训练基础模型并记录性能
performances = self.train_and_evaluate(task)
meta_targets.append(performances)
# 训练元模型
self.meta_model = RandomForestRegressor().fit(meta_features, meta_targets)
def predict_best_model(self, new_task):
"""为新任务推荐最佳模型"""
task_features = self.extract_task_features(new_task)
predicted_perf = self.meta_model.predict([task_features])[0]
best_model_idx = np.argmax(predicted_perf)
return self.base_models[best_model_idx]9. 📚 学习资源与总结
9.1 官方文档
-
AutoGluon文档 – 亚马逊AutoML框架
-
TPOT文档 – 基于遗传算法的AutoML
-
Optuna文档 – 超参数优化框架
-
FeatureTools文档 – 自动化特征工程
-
Ray Tune文档 – 分布式超参数优化
9.2 总结
AutoML不是要取代数据科学家,而是放大数据科学家的能力。它让我们:
-
更高效:减少80%重复劳动
-
更准确:发现人工难以找到的最优解
-
更可复现:标准化机器学习流程
-
更易部署:一键式模型部署
未来展望:AutoML将向全自动、自适应、元学习方向发展,最终实现"民主化AI"——让每个人都能轻松使用机器学习。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


