
flink架构和关键组件
++总体架构概览
客户端、JobManage和TaskManage
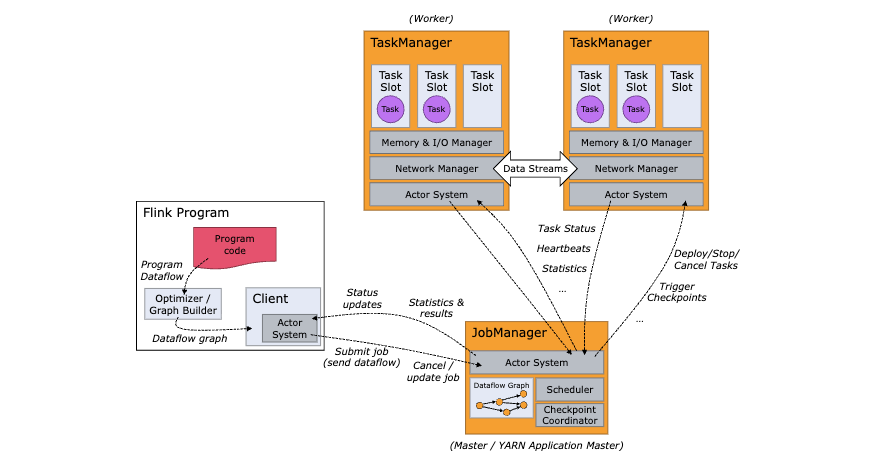
++JobManage机制解析
一、JobManager 的核心定位与整体职责
JobManager 是 Flink 集群的控制节点,运行在主节点上,其核心作用是协调分布式作业的全生命周期管理,具体包括:
- 作业调度:将作业的 JobGraph 转换为 ExecutionGraph,分配任务到 TaskManager 的 TaskSlot 中执行;
- 故障处理:监控任务执行状态,处理任务失败、节点宕机等异常,触发重启或恢复;
- 检查点协调:统一协调所有 TaskManager 完成快照(Checkpoint),保障故障后的数据一致性;
- 资源管理:通过 ResourceManager 管理集群的 TaskSlot 资源,按需分配 / 释放资源;
- 作业提交:通过 Dispatcher 提供 REST 接口接收作业提交,为每个作业启动独立的 JobMaster。
二、JobManager 三大核心组件的分工与协作
JobManager 由 ResourceManager、Dispatcher、JobMaster 三个独立组件构成,三者各司其职又相互协作,共同完成作业管理。
1. ResourceManager:集群资源的 “总管家”
核心职责
- 资源分配与回收:管理集群中所有 TaskManager 的 TaskSlot(Flink 中最小的资源调度单位,每个 TaskSlot 对应 TaskManager 的一组 CPU / 内存资源);
- 多环境适配:为不同部署环境(Standalone、YARN、Kubernetes)实现专属的 ResourceManager,适配不同的资源调度体系;
- Slot 管理:跟踪 TaskSlot 的使用状态(空闲 / 已分配),当 JobMaster 申请资源时,将空闲 Slot 分配给作业,作业结束后回收 Slot。
2. Dispatcher:作业提交的 “接待员”
核心职责
- 提供作业提交入口:暴露 REST 接口(默认端口 8081),支持通过 CLI、WebUI、第三方工具提交 Flink 作业;
- 启动 JobMaster:为每个提交的作业创建独立的 JobMaster 实例,负责该作业的具体执行管理;
- WebUI 运行:提供 Flink 集群的可视化监控界面,展示作业状态、任务执行情况、资源使用等信息;
- 作业暂存与恢复:在高可用(HA)模式下,可暂存提交的作业信息,当 JobMaster 故障时重新启动 JobMaster。
关键特性
- 无状态设计:Dispatcher 本身不存储作业的执行状态,仅负责作业提交的转发和 JobMaster 的启动;
- 多作业支持:可同时接收多个作业提交,为每个作业启动独立的 JobMaster,实现多作业并行运行。
3. JobMaster:单个作业的 “项目经理”
核心职责
- 作业执行管理:为单个作业创建 ExecutionGraph(JobGraph 的执行层表示),负责任务的调度、启动和监控;
- 资源申请:向 ResourceManager 申请作业所需的 TaskSlot,当 Slot 分配完成后,将任务部署到 TaskManager 上;
- 检查点协调:触发并协调所有 TaskManager 完成 Checkpoint,记录检查点元数据,用于故障恢复;
- 故障处理:监控任务执行状态,当任务失败时,根据重启策略触发任务重启,若失败超过阈值则终止作业。
关键特性
- 作业隔离:每个作业拥有独立的 JobMaster,不同作业的执行状态相互隔离,一个作业的故障不会影响其他作业;
- 动态扩展:当作业需要更多资源时,可通过 JobMaster 向 ResourceManager 申请额外的 TaskSlot。
三、JobManager 组件间的核心交互流程(以作业提交为例)
以 “用户提交作业到 Standalone 集群” 为例,梳理三大组件的协作流程:
- 作业提交:用户通过 CLI 或 WebUI 向 Dispatcher 的 REST 接口提交 Flink 作业(包含 JobGraph);
- JobMaster 启动:Dispatcher 为该作业创建并启动一个 JobMaster 实例;
- 资源申请:JobMaster 向 ResourceManager 发送资源申请,指定所需的 TaskSlot 数量;
- Slot 分配:ResourceManager 从集群的 TaskManager 中筛选出空闲的 TaskSlot,分配给 JobMaster;
- 任务部署:JobMaster 将任务部署到分配的 TaskSlot 中,TaskManager 启动任务执行;
- 运行监控:JobMaster 监控任务执行状态,Dispatcher 通过 WebUI 展示作业运行信息,ResourceManager 跟踪 Slot 使用状态;
- 作业结束:作业执行完成后,JobMaster 向 ResourceManager 释放 Slot,Dispatcher 记录作业执行结果。
四、JobManager 的高可用(HA)设计
为避免 JobManager 成为单点故障,Flink 支持高可用部署模式,核心设计如下:
- 多 JobManager 节点:集群中启动多个 JobManager 节点,其中一个为Leader(承担实际的调度和管理职责),其余为Standby(备用节点);
- Leader 选举:通过分布式协调服务(ZooKeeper / Kubernetes ConfigMap)实现 Leader 选举,当 Leader 宕机时,Standby 节点自动竞选为新的 Leader;
- 状态持久化:作业的元数据、Checkpoint 信息等持久化到共享存储(如 HDFS、S3),新 Leader 可从共享存储中恢复作业状态;
-
组件容灾:
- Dispatcher HA:多个 Dispatcher 节点共享作业提交信息,确保作业提交入口不中断;
- JobMaster HA:当 JobMaster 故障时,Dispatcher 或新 Leader 会重新启动 JobMaster,从最近的 Checkpoint 恢复作业执行。
HA 模式的核心价值
- RTO(恢复时间目标):Leader 切换通常在秒级完成,几乎不影响作业执行;
- RPO(恢复点目标):通过 Checkpoint 实现数据零丢失(RPO=0),保障业务数据一致性。
++Flink TaskManager 与 Task Slots 机制
一、核心概念:TaskManager、Task Slot 与 Subtask 的关系
首先明确三者的层级关系,这是理解资源调度的前提:
| 概念 | 定义 | 角色定位 |
|---|---|---|
| TaskManager | 执行任务的工作节点,是一个独立的 JVM 进程 | 集群的 “工作者”,负责实际执行计算任务,可运行在物理机、容器或虚拟机上 |
| Task Slot | TaskManager 中资源的逻辑划分单位,是 Flink 调度的最小资源单位 | 资源的 “分配单元”,每个 Slot 对应 TaskManager 一部分预留资源(主要是管理内存) |
| Subtask | 算子的并行执行实例(由算子并行度决定数量) | 计算的 “执行单元”,运行在 Task Slot 中,由独立线程执行 |
核心关系:
- 一个 TaskManager 包含 N 个 Task Slot(N ≥ 1,由配置决定);
- 一个 Task Slot 可运行一个或多个 Subtask(由 Slot 共享机制决定);
- 一个 Subtask 对应一个线程,运行在某个 Task Slot 中。
二、Task Slots 的资源模型:隔离与共享的平衡
Flink 的 Task Slots 并非全资源隔离,而是针对 “管理内存” 的逻辑隔离,这种设计兼顾了资源利用率和执行效率,是其核心特点之一。
1. Slot 的资源隔离特性
-
管理内存(Managed Memory)的硬隔离:TaskManager 的管理内存(用于中间结果、状态存储、排序等)会按 Slot 数量平均分配。例如,一个 TaskManager 有 4GB 管理内存和 4 个 Slot,则每个 Slot 独占 1GB 管理内存,不同 Slot 的 Subtask 不会竞争这部分内存,避免了内存溢出或资源抢占。
管理内存是 Flink 中专门为计算任务预留的内存区域,与 JVM 堆内存、直接内存共同构成 TaskManager 的内存模型。
- CPU 无隔离:当前 Flink 的 Slot 不提供 CPU 隔离,所有 Slot 的 Subtask 共享 TaskManager 的 CPU 核心。这意味着如果一个 Slot 中的 Subtask 占用大量 CPU,可能会影响其他 Slot 的任务执行。
- 其他资源的共享:TaskManager 的网络连接、心跳消息、JVM 堆外内存等资源由所有 Slot 共享,减少了每个任务的额外开销。
2. Slot 隔离的价值与局限
| 特性 | 价值 | 局限 |
|---|---|---|
| 管理内存隔离 | 避免不同任务的内存竞争,提升作业稳定性 | 仅隔离管理内存,堆内存仍可能存在竞争(需通过任务配置限制) |
| CPU 不隔离 | 简化资源调度,提升 CPU 利用率 | 高负载任务可能导致 CPU 争用,需通过并行度和 Slot 数量合理分配 |
3. 调整 Slot 数量的意义:控制任务隔离级别
通过配置 TaskManager 的 Slot 数量,用户可灵活定义 Subtask 的隔离程度:
- 1 个 Slot 每 TaskManager:每个 TaskManager 只运行一个 Slot,意味着每个任务组(Subtask 集合)运行在独立的 JVM 进程中,隔离性最强。适合对隔离性要求高的场景(如不同作业的任务、高优先级任务),但资源利用率较低。
-
多个 Slot 每 TaskManager:多个 Subtask 共享同一个 JVM 进程,可带来以下优势:
- 共享 TCP 连接(通过多路复用)和心跳消息,减少网络开销;
- 共享数据集和数据结构(如静态配置、缓存数据),降低内存占用;
- 减少 JVM 进程的启动和维护开销,提升集群整体效率。
三、Slot 共享机制(Slot Sharing):Flink 资源利用率的核心优化
Flink 默认启用 Slot 共享机制:同一作业的不同任务的 Subtask 可以共享同一个 Slot,甚至一个 Slot 可以容纳整个作业的执行流水线。这是 Flink 区别于其他分布式计算框架的重要特性,也是提升资源利用率的关键。
1. Slot 共享的核心规则
- 仅同一作业的 Subtask 可共享 Slot:不同作业的 Subtask 不会共享 Slot,保证作业间的资源隔离;
- 按 “任务流水线” 共享:一个 Slot 通常容纳的是作业中同一并行度的完整流水线(如 Source Subtask + Map Subtask + Window Subtask + Sink Subtask);
- 资源密集型任务的公平分配:Slot 共享机制会将资源密集型的 Subtask(如 Window 聚合)均匀分布在不同的 TaskManager 上,避免资源倾斜。
2. Slot 共享的两大核心优势
优势 1:简化并行度配置,降低调度复杂度
Flink 集群所需的 Slot 数量等于作业中使用的最高并行度,无需计算作业中所有任务的总数量。
示例:一个作业的算子并行度分布为:Source(2)→ Map(2)→ KeyBy/Window(6)→ Sink(6)。
- 无 Slot 共享:需要的 Slot 数量 = 2 + 2 + 6 + 6 = 16;
- 有 Slot 共享:需要的 Slot 数量 = 最高并行度 = 6(仅需 6 个 Slot 即可运行整个作业)。
这一特性大幅简化了集群资源的规划和配置,尤其是对于包含多个不同并行度算子的复杂作业。
优势 2:提升资源利用率,避免资源浪费
无 Slot 共享时,非资源密集型任务(如 Source、Map)会占用与资源密集型任务(如 Window、Aggregation)相同数量的 Slot,导致资源闲置;而 Slot 共享机制可让不同任务的 Subtask 共享 Slot,充分利用资源。
示例对比:假设作业包含:
- 轻量任务:Source(并行度 2)、Map(并行度 2)(资源占用低);
- 重量级任务:Window(并行度 2)、Sink(并行度 2)(资源占用高)。
| 模式 | Slot 数量 | 资源利用率 | 问题 |
|---|---|---|---|
| 无 Slot 共享 | 8(2+2+2+2) | 低(轻量任务占用大量 Slot,资源闲置) | 资源浪费严重,集群开销大 |
| 有 Slot 共享 | 2(最高并行度 2) | 高(一个 Slot 容纳完整流水线,轻量与重量级任务共享资源) | 资源充分利用,无闲置 |
若将并行度从 2 提升到 6,Slot 共享机制会让 6 个 Slot 被充分利用,且重量级任务均匀分布在不同 TaskManager 上,保证负载均衡。
3. Slot 共享的底层实现:Slot Sharing Group(Slot 共享组)
Flink 通过Slot Sharing Group 控制 Subtask 的共享规则:
-
默认共享组:所有 Subtask 都属于同一个默认共享组(
default),因此可共享 Slot; - 自定义共享组:用户可通过 API 为算子指定不同的共享组,不同共享组的 Subtask 不会共享 Slot。
示例:自定义 Slot 共享组
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements("a", "b", "c")
.map(s -> s.toUpperCase())
.slotSharingGroup("group1") // 指定共享组 group1
.filter(s -> s.length() > 0)
.slotSharingGroup("group2") // 指定共享组 group2
.print();
上述代码中,map 的 Subtask 属于 group1,filter 的 Subtask 属于 group2,两者不会共享 Slot,从而实现更精细的资源隔离。
四、生产环境中 Task Slots 的配置与优化实践
Task Slots 的数量配置直接影响集群的资源利用率和作业执行效率,需结合集群规模、作业特性、资源类型综合调整。
1. Task Slot 数量的核心配置参数
| 参数 | 作用 | 配置位置 | 生产建议 |
|---|---|---|---|
taskmanager.numberOfTaskSlots |
每个 TaskManager 的 Slot 数量(默认 1) |
flink-conf.yaml 或 TaskManager 启动参数 |
建议设置为 CPU 核心数的 1~2 倍(如 8 核 CPU 配置 8~16 个 Slot) |
parallelism.default |
作业的默认并行度 | flink-conf.yaml |
建议等于集群总 Slot 数 / TaskManager 数量 |
taskmanager.memory.managed.size |
TaskManager 的管理内存大小 | flink-conf.yaml |
建议占 TaskManager 总内存的 40%~60%(为 Slot 隔离提供足够内存) |
2. Slot 数量的配置原则
原则 1:与 CPU 核心数匹配
Slot 数量应与 TaskManager 的 CPU 核心数相匹配(如 4 核 CPU 配置 4 个 Slot),避免因 CPU 核心不足导致任务争用,或因 Slot 过多导致 CPU 闲置。
原则 2:兼顾内存隔离与利用率
- 若作业的内存需求高(如大状态、大窗口),可适当减少 Slot 数量(如 8 核 CPU 配置 4 个 Slot),让每个 Slot 获得更多管理内存;
- 若作业的内存需求低(如简单 ETL),可适当增加 Slot 数量(如 8 核 CPU 配置 8 个 Slot),提升资源利用率。
原则 3:结合作业并行度
集群总 Slot 数应不小于作业的最高并行度,否则作业会因资源不足而等待 Slot 分配。例如,作业最高并行度为 128,若每个 TaskManager 配置 16 个 Slot,则至少需要 8 个 TaskManager。
3. Slot 共享机制的生产调优
场景 1:核心作业的资源隔离
对于金融交易、实时风控等核心作业,可通过自定义 Slot 共享组将其与普通作业隔离开,避免资源争用:
// 核心作业的算子指定独立的共享组
dataStream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.slotSharingGroup("critical-job-group");
场景 2:资源密集型任务的隔离
对于 Window 聚合、大状态计算等资源密集型任务,可将其分配到独立的共享组,保证其获得足够的资源:
// 重量级任务指定独立共享组
dataStream.window(...)
.slotSharingGroup("heavy-task-group");
场景 3:禁用 Slot 共享(特殊场景)
仅在作业间隔离要求极高的场景下(如多租户集群),可禁用 Slot 共享,通过配置 slotSharingGroup("exclusive") 实现:
// 禁用 Slot 共享,每个 Subtask 独占一个 Slot
dataStream.map(...)
.slotSharingGroup(SlotSharingGroup.EXCLUSIVE);
4. 监控与调优:Slot 资源的可视化管理
通过 Flink WebUI 可实时监控 Slot 的使用状态:
- 在 Cluster Overview 页面,查看集群总 Slot 数、已使用 Slot 数、空闲 Slot 数;
- 在 Job Details 页面,查看作业的 Slot 分配情况和任务执行状态;
- 当出现 Slot 不足时,可通过扩容 TaskManager 或调整 Slot 数量解决。
五、常见问题与解决方案
1. 作业提交后提示 “Insufficient number of slots available”
原因:集群空闲 Slot 数小于作业的最高并行度。解决:
- 临时解决方案:增加 TaskManager 的 Slot 数量(修改
taskmanager.numberOfTaskSlots); - 长期解决方案:扩容 TaskManager 节点,提升集群总 Slot 数。
2. TaskManager 的 CPU 利用率过高,但内存利用率低
原因:Slot 数量过多,导致 CPU 核心被争用,而内存未被充分利用。解决:减少 Slot 数量,让每个 Slot 获得更多 CPU 时间片,同时提升内存利用率。
3. 不同作业的任务相互影响(如一个作业的任务占用大量内存导致另一个作业 OOM)
原因:虽然 Slot 隔离了管理内存,但堆内存仍可能存在竞争,或作业间共享了 TaskManager 的其他资源。解决:
- 将不同作业分配到不同的 TaskManager 节点(通过资源组实现);
- 为每个作业设置内存上限(
taskmanager.memory.process.size)
++Flink Streams 核心特性与处理机制
一、流的核心分类:维度与特征
Flink 从数据边界和处理时机两个维度对流进行了分类,不同类型的流对应不同的处理策略和技术选型。
1. 按数据边界划分:无界流(Unbounded Streams)vs 有界流(Bounded Streams)
这是流处理最核心的分类维度,决定了数据的处理模式、时间语义和容错策略。
| 特征 | 无界流(Unbounded Streams) | 有界流(Bounded Streams) |
|---|---|---|
| 数据特征 | 无固定开始和结束,数据持续生成、无限增长(如用户行为日志、交易流水、传感器数据) | 有固定的开始和结束,数据量有限(如每日批处理的日志文件、数据库快照、历史数据批量导入) |
| 别名 | 流数据(Stream Data) | 批数据(Batch Data)/ 有限数据集 |
| 处理核心挑战 | 需处理无限数据、乱序数据、迟到数据,依赖时间语义(事件时间 / 处理时间)和检查点(Checkpoint)保证容错 | 需高效处理大规模有限数据,依赖分区、并行计算提升吞吐量,可利用数据的完整性做优化 |
| 典型应用场景 | 实时监控、实时风控、实时数仓、事件驱动型应用 | 离线数仓 ETL、历史数据分析、报表统计、数据归档 |
| Flink 定位 | Flink 的原生核心场景,提供全套成熟的处理特性 | Flink 通过流批一体模型将其作为特殊的流处理,提供专用算子优化性能 |
关键认知:Flink 中的 “批是流的特例”
Flink 并没有像传统框架(如 Spark)那样区分 “流处理引擎” 和 “批处理引擎”,而是将有界流视为无界流的一种特殊情况(数据最终会停止生成的流)。这种设计让 Flink 可以用同一套 API 处理两种流,实现了流批一体的核心目标。
2. 按处理时机划分:实时流(Real-time Streams)vs 记录流(Recorded Streams)
该维度关注的是数据生成与处理的时间差,与数据本身的边界无关,体现了 Flink 处理场景的灵活性。
| 特征 | 实时流(Real-time Streams) | 记录流(Recorded Streams) |
|---|---|---|
| 处理时机 | 数据生成后立即处理(延迟通常在毫秒到秒级) | 数据先持久化到存储系统(如 HDFS、S3、Kafka),之后再批量处理(延迟从分钟到天级) |
| 数据存储 | 通常存储在实时消息队列(Kafka、Pulsar、RocketMQ),仅临时缓存 | 存储在持久化存储(HDFS、S3、Hive、数据库),可长期保存 |
| 处理目标 | 追求低延迟,满足实时业务需求 | 追求高吞吐量和高准确性,满足离线分析需求 |
| 与边界的关系 | 可处理无界流(如 Kafka 实时数据),也可处理有界流(如实时导入的有限文件) | 可处理有界流(如 HDFS 上的历史文件),也可处理无界流的历史快照(如 Kafka 某一时间段的消息) |
关键认知:处理时机与数据边界解耦
- 无界流可以是实时处理(如 Kafka 实时消费),也可以是记录流处理(如消费 Kafka 中过去 7 天的历史数据);
- 有界流可以是实时处理(如实时读取刚生成的日志文件),也可以是记录流处理(如读取上个月的历史数据文件)。
Flink 对这种解耦的支持,使其能覆盖从实时低延迟到离线高吞吐的全场景处理需求。
二、Flink 对不同流的核心处理机制
Flink 针对不同类型的流设计了差异化的处理机制,但底层共享同一套执行引擎,这是其流批一体的技术核心。
1. 无界流的处理机制:面向无限数据的实时计算
Flink 对无界流的处理是其核心竞争力,主要依赖时间语义、状态管理、检查点、水位线等关键技术。
核心技术组件:
- 时间语义:支持处理时间(Processing Time)、事件时间(Event Time) 和摄入时间(Ingestion Time),其中事件时间是处理无界乱序流的核心(通过数据中的时间戳判断事件发生时间,而非处理时间)。
- 水位线(Watermark):用于衡量事件时间的进度,解决乱序数据和迟到数据的处理问题(如水位线到达后触发窗口计算)。
- 状态管理:提供 Keyed State、Operator State 等状态类型,用于存储计算过程中的中间结果(如窗口聚合的计数、用户的会话状态),状态可通过检查点持久化,保证故障恢复。
- 检查点(Checkpoint):基于 Chandy-Lamport 算法实现的分布式快照,定期保存作业的状态和偏移量,故障时可从最近的检查点恢复,保证精确一次(Exactly Once) 的语义。
- 背压(Backpressure):当消费速度跟不上生产速度时,Flink 会自动触发背压机制,限制数据源的读取速度,避免数据积压导致的 OOM。
典型处理流程:
Kafka 无界流 → Flink 数据源(Source)→ 水位线生成 → 算子处理(Map/Filter/KeyBy/Window)→ 状态存储 → Sink(ClickHouse/Doris)
2. 有界流的处理机制:面向有限数据的高效批处理
Flink 对有界流的处理并非简单复用无界流的机制,而是提供了专用的优化算子和执行策略,使其批处理性能可与传统批处理框架(如 Spark、Hive)媲美。
核心优化策略:
-
批处理模式(Batch Mode):Flink 1.12 后引入了批处理模式,当检测到输入是有界流时,自动启用批处理优化:
- 取消水位线:有界流数据完整,无需水位线处理乱序数据;
- 优化检查点:批处理的检查点更轻量(仅在作业开始和结束时保存状态),甚至可禁用检查点(依赖数据重放实现容错);
- 本地排序与聚合:利用有界流的特性,在本地进行排序和聚合,减少网络 Shuffle 开销。
-
专用算子:提供
BatchTableSource、BatchSink等专用算子,以及针对有界流的优化连接策略(如 Hash Join、Sort Merge Join)。 - 数据倾斜优化:针对有界流的特点,提供更高效的数据倾斜解决方案(如动态负载均衡、局部聚合)。
典型处理流程:
HDFS 有界文件 → Flink 批处理 Source → 并行分区处理 → Shuffle(如需)→ 聚合计算 → Sink(Hive/MySQL)
3. 实时流与记录流的统一处理
Flink 对实时流和记录流的处理差异主要体现在数据源的读取方式,而非处理逻辑:
- 实时流:从 Kafka、Pulsar 等实时消息队列读取数据,使用流数据源(StreamSource),支持实时消费和动态分区发现;
- 记录流:从 HDFS、S3、Hive 等持久化存储读取数据,使用批数据源(BatchSource),支持批量读取和数据分片。
核心优势:同一套业务逻辑可无缝切换处理实时流和记录流,例如:
// 处理实时流(Kafka)
DataStream<Order> realTimeStream = env.fromSource(
KafkaSource.<Order>builder().setTopic("orders").build(),
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5)),
"kafka-real-time-source"
);
// 处理记录流(HDFS 文件)
DataStream<Order> recordedStream = env.readTextFile("hdfs:///orders/20250101")
.map(new OrderMapFunction());
// 同一套处理逻辑
DataStream<OrderStats> statsStream = realTimeStream // 或 recordedStream
.keyBy(Order::getRegion)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.aggregate(new OrderAggregateFunction());
三、流批一体的技术实现:Flink 的统一执行引擎
Flink 能处理所有类型的流,核心在于其统一的执行引擎和Table API & SQL 的抽象层。
1. 底层执行引擎:统一的 Task 执行模型
Flink 的执行引擎不区分流和批任务,所有任务都被转换为数据流图(StreamGraph),并通过 TaskManager 的 Task Slot 执行。差异仅在于:
- 无界流任务:持续运行,依赖检查点实现容错,需处理动态数据;
- 有界流任务:运行完成后终止,利用数据完整性做优化,无需持续运行。
2. Table API & SQL:流批一体的抽象层
Flink 的 Table API & SQL 是实现流批一体的核心抽象,用户只需编写一次 SQL,即可处理无界流和有界流:
-- 处理无界流(Kafka 表)
CREATE TABLE kafka_orders (
order_id STRING,
region STRING,
create_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'format' = 'json'
);
-- 处理有界流(Hive 表)
CREATE TABLE hive_orders (
order_id STRING,
region STRING,
create_time TIMESTAMP(3)
) WITH (
'connector' = 'hive',
'table-name' = 'orders',
'format' = 'parquet'
);
-- 同一套 SQL 处理两种流
SELECT region, COUNT(order_id) FROM kafka_orders -- 或 hive_orders
GROUP BY region, TUMBLE(create_time, INTERVAL '1' HOUR);
Table API & SQL 会根据数据源的类型(有界 / 无界)自动选择合适的执行策略,无需用户手动调整。
3. 连接器(Connector):统一的数据源接入
Flink 提供了丰富的连接器,支持接入各种类型的数据源,且大部分连接器同时支持有界和无界模式:
- Kafka 连接器:支持实时消费(无界)和消费指定时间段的消息(有界);
- Hive 连接器:支持读取历史数据(有界)和实时读取新增分区(无界);
- File 连接器:支持读取单个文件(有界)和监控文件目录的新增文件(无界)。
四、生产实践中的流类型选择与优化
在生产环境中,选择何种流处理方式需结合业务需求、数据特征、性能指标综合判断。
1. 流类型选择的核心原则
| 业务需求 | 推荐流类型 | 技术选型 |
|---|---|---|
| 实时监控、低延迟响应 | 无界流 + 实时流 | Kafka + Flink Stream API/ SQL |
| 离线报表、历史数据分析 | 有界流 + 记录流 | HDFS/Hive + Flink Batch Mode/SQL |
| 流批一体数仓 | 无界流 + 有界流 | Flink SQL + Iceberg/Hudi(湖仓) |
| 数据同步(实时 + 离线) | 无界流 / 有界流 | Flink CDC + Kafka/Hive |
2. 无界流的优化策略
- 优化水位线:根据业务场景合理设置水位线的延迟时间,平衡延迟和准确性;
- 状态管理:选择合适的状态后端(如 RocksDB),设置状态过期时间,避免状态无限增长;
- 并行度调整:根据数据量调整并行度,充分利用集群资源,减少数据倾斜。
3. 有界流的优化策略
-
启用批处理模式:通过
env.setRuntimeMode(RuntimeExecutionMode.BATCH)显式启用批处理模式,获得更好的性能; - 数据分片:将大文件拆分为多个小文件,提升并行读取效率;
- 本地聚合:尽量在数据源端进行本地聚合,减少网络 Shuffle 开销。
4. 实时流与记录流的混合处理
在生产中,常需混合处理实时流和记录流,例如:
- 实时补全历史数据:用记录流加载历史数据到缓存,实时流查询缓存补全数据;
- 实时数据校验:将实时流的数据与记录流的历史数据对比,校验数据准确性。
++Flink 状态 (State)、检查点 (Checkpoint) 与水位线 (Watermark) 解析
一、State(状态)与 Checkpoint(检查点):记忆与备份的关系
1. 核心定义与本质
(1)State(状态)
- 本质:Flink 算子在处理流数据时,需要保存的中间计算结果或历史信息,是算子的 “内存”。例如:窗口聚合中累计的订单数、用户会话的状态、CDC 同步中的数据版本号等。
- 作用:支撑有状态的计算,让流处理从 “一次性处理单个事件” 升级为 “基于历史数据的连续计算”。
- 存储位置:默认存储在 TaskManager 的内存中,生产中通常使用 RocksDB State Backend 将状态持久化到本地磁盘(内存 + 磁盘混合存储)。
(2)Checkpoint(检查点)
- 本质:Flink 分布式快照机制,是整个作业所有算子状态的一致性快照,以及数据源的消费偏移量(如 Kafka 的 offset)。
- 作用:实现故障恢复 —— 当作业失败时,可从最近的 Checkpoint 恢复所有算子的状态和数据源偏移量,保证计算的Exactly Once(精确一次) 语义。
- 存储位置:通常存储在分布式文件系统(HDFS、S3)或数据库中,是全局的、持久化的状态备份。
2. 核心联系:相互依赖,缺一不可
| 关联点 | 具体说明 |
|---|---|
| Checkpoint 是 State 的 “备份” | Checkpoint 的核心内容就是作业中所有算子的 State 快照,没有 State,Checkpoint 就失去了备份的对象;没有 Checkpoint,State 仅存于内存,故障后会全部丢失。 |
| State 的恢复依赖 Checkpoint | 作业重启时,Flink 会从 Checkpoint 中读取所有算子的 State 数据,恢复到故障前的计算状态,保证计算的连续性。 |
| State 的大小影响 Checkpoint 性能 | State 越大,Checkpoint 序列化、持久化的时间越长,对集群资源的消耗也越大;反之则 Checkpoint 更高效。 |
| Checkpoint 触发依赖 State 的快照 | Checkpoint 采用Chandy-Lamport 算法,通过向所有算子发送快照请求,收集每个算子的 State 快照,最终形成全局一致的 Checkpoint。 |
3. 核心区别:维度、作用、生命周期完全不同
| 维度 | State(状态) | Checkpoint(检查点) |
|---|---|---|
| 粒度 | 算子级:每个算子有自己的 State(如 Keyed State 按 Key 分区,Operator State 按算子实例划分) | 作业级:包含整个作业所有算子的 State 及数据源偏移量,是全局快照 |
| 存储形态 | 可分为内存态(运行时的活跃数据)和持久化态(Checkpoint 中的备份数据) | 只有持久化态,存储在分布式存储中,不参与实时计算 |
| 生命周期 | 随算子的生命周期存在:算子启动时初始化,算子运行时更新,算子销毁时释放(若未备份则丢失) | 由 Checkpoint 策略控制:定期生成,可配置保留策略(如保留最近 3 个),超过保留数则被清理 |
| 核心作用 | 支撑实时计算,保存中间结果,是计算的 “实时记忆” | 保障故障恢复,是计算的 “灾难备份” |
| 更新方式 | 实时更新:每个事件处理时可能修改 State(如窗口聚合的计数 + 1) | 批量快照:按固定间隔(如 10 秒)触发一次,生成后不再修改 |
| 性能影响 | 影响算子的实时处理性能(如 State 读写的耗时) | 影响作业的整体吞吐量(触发时会有短暂的性能开销) |
4. 生产中的协同实践
- State 选型:根据业务选择合适的 State 类型(Keyed State 用于按 Key 分组的计算,Operator State 用于算子级的全局状态),并通过状态过期(TTL)限制 State 大小。
-
Checkpoint 配置:
- 生产中通常设置 Checkpoint 间隔为 10~60 秒(平衡恢复速度和性能开销);
- 选择增量 Checkpoint(仅备份变化的 State 数据,减少 IO 开销);
- 配置 Checkpoint 超时时间和最大并行数(避免 Checkpoint 堆积)。
- 故障恢复:作业失败后,Flink 自动从最近的 Checkpoint 恢复 State,无需人工干预,实现 RTO(恢复时间目标)秒级、RPO(恢复点目标)等于 Checkpoint 间隔。
二、Watermark(水位线):事件时间的 “进度时钟”
在无界流处理中,事件时间(Event Time) 是数据本身携带的时间戳(如订单的创建时间),而 Watermark 是 Flink 用来衡量事件时间进度、处理乱序和迟到数据的核心机制。
1. Watermark 的核心原理
(1)为什么需要 Watermark?
无界流的两个核心问题:
- 乱序数据:网络延迟、分布式系统调度等原因,导致数据到达 Flink 算子的顺序与事件发生的顺序不一致(如事件时间 10:00 的数据可能比 10:01 的数据晚到)。
- 如何确定窗口关闭时间:对于事件时间窗口(如 10:00~10:01 的窗口),无法确定何时所有数据都已到达,因此需要一个 “时钟” 来判断窗口是否可以触发计算。
Watermark 的出现就是为了解决这两个问题:它是一个特殊的时间戳,代表 “事件时间到这里为止,之前的所有数据应该都已经到达了”。
(2)Watermark 的生成规则
-
核心公式:
Watermark = 当前观察到的最大事件时间 - 允许的乱序延迟例如:观察到的最大事件时间是 10:00:05,允许的乱序延迟是 3 秒,则 Watermark = 10:00:02。 - 语义:当 Watermark 到达 T 时,Flink 认为所有事件时间 ≤ T 的数据都已经到达,可触发对应窗口的计算。
-
生成方式:
- 数据源生成:在 Source 算子中直接生成 Watermark(推荐,因为数据源最接近原始数据);
-
算子生成:通过
assignTimestampsAndWatermarks()方法在算子中生成,适用于需要对数据清洗后再提取时间戳的场景。
(3)Watermark 的传播机制
- Watermark 会沿着算子链从上游向下游传播,下游算子的 Watermark 取所有上游输入 Watermark 的最小值(保证全局事件时间的一致性)。
- 例如:算子 A 收到两个上游的 Watermark 分别为 10:00:02 和 10:00:05,则算子 A 的 Watermark 为 10:00:02。
2. Watermark 的核心应用场景
(1)触发事件时间窗口计算
这是 Watermark 最核心的应用。对于事件时间窗口(Tumbling Window、Sliding Window、Session Window),只有当 Watermark 超过窗口的结束时间时,窗口才会触发计算。
示例:
- 窗口为 10:00:00 ~ 10:00:10(滚动窗口,10 秒);
- 允许的乱序延迟为 2 秒;
- 当 Watermark 到达 10:00:12 时,Flink 认为该窗口的所有数据都已到达,触发窗口聚合。
(2)处理迟到数据
即使有 Watermark,仍可能有少量数据在 Watermark 之后到达(即迟到数据)。Flink 提供了两种处理方式:
-
窗口迟到数据:通过
allowedLateness()为窗口设置额外的迟到时间,在该时间内到达的数据仍可加入窗口重新计算; - 侧输出流(Side Output):将超过迟到时间的迟到数据发送到侧输出流,供后续处理(如写入异常表)。
示例代码:
// 定义水位线生成策略(允许 3 秒乱序)
WatermarkStrategy<Order> watermarkStrategy = WatermarkStrategy
.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((event, timestamp) -> event.getCreateTime());
// 应用水位线并处理窗口
DataStream<Order> stream = env.fromSource(kafkaSource, watermarkStrategy, "kafka-source");
stream.keyBy(Order::getRegion)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.seconds(2)) // 额外允许 2 秒迟到
.sideOutputLateData(new OutputTag<Order>("late-data"){}) // 侧输出迟到数据
.aggregate(new OrderAggregateFunction());
(3)实现事件时间的状态过期
Flink 的 Keyed State 支持基于事件时间的 TTL(生存时间),而 TTL 的计算依赖 Watermark 的进度。例如:设置状态 TTL 为 10 秒,当 Watermark 超过状态的事件时间 10 秒时,状态会被自动清理。
3. Watermark 的生产优化实践
(1)合理设置乱序延迟
- 乱序延迟过小:会导致大量迟到数据,窗口计算结果不准确;
- 乱序延迟过大:会增加窗口的触发延迟,影响实时性。
- 生产建议:通过监控数据的乱序分布(如 99% 的数据在 5 秒内到达),设置略高于该值的乱序延迟(如 6 秒)。
(2)选择合适的 Watermark 生成器
| 生成器类型 | 适用场景 | 生产建议 |
|---|---|---|
| BoundedOutOfOrdernessWatermarks(固定乱序延迟) | 数据乱序程度可预测(如大部分乱序在固定时间内) | 绝大多数场景首选 |
| Custom Watermark Generators(自定义生成器) | 数据乱序程度动态变化(如高峰时段乱序大,低峰时段乱序小) | 复杂场景使用,需自定义实现 WatermarkGenerator 接口 |
| MonotonousTimestampsWatermarks(单调递增时间戳) | 数据时间戳严格递增(如数据库 CDC 数据) | 无需处理乱序时使用,性能最优 |
(3)处理 Watermark 停滞
生产中可能出现 Watermark 停滞(如数据源长时间无数据),导致窗口无法触发。解决方案:
-
设置空闲超时:通过
withIdleness(Duration.ofSeconds(10))标记空闲的数据源分区,避免其拖慢全局 Watermark; - 人工注入 Watermark:当数据源无数据时,定期注入人工 Watermark,保证事件时间进度。
4. State、Checkpoint 与 Watermark 的协同关系
在实际作业中,三者是协同工作的:
- Watermark 驱动 State 更新:Watermark 触发窗口计算时,会更新算子的 State(如将窗口结果写入 State);
- Checkpoint 备份 State 和 Watermark 进度:Checkpoint 不仅备份算子的 State,还会备份当前的 Watermark 进度,故障恢复时可恢复到正确的事件时间进度;
- State 存储 Watermark 相关信息:算子会在 State 中存储已处理的 Watermark 时间戳,避免重复触发窗口计算。
++WaterMark的进一步解释和作用原理
一、示例
事件时间线:
A@12:00:00
B@12:00:30
C@12:01:10 // 这个是后面到的
D@12:01:20
窗口: [12:00:00, 12:01:00) // 结束时间是12:01:00
允许乱序延迟: 10秒
二、分析
事件A: timestamp = 12:00:00
当前最大事件时间 = 12:00:00
Watermark = 12:00:00 - 10s = 11:59:50
窗口是否触发? Watermark(11:59:50) >= 12:01:00? ❌ 否
事件B: timestamp = 12:00:30
当前最大事件时间 = 12:00:30
Watermark = 12:00:30 - 10s = 12:00:20
窗口是否触发? Watermark(12:00:20) >= 12:01:00? ❌ 否
事件D: timestamp = 12:01:20
当前最大事件时间 = 12:01:20
Watermark = 12:01:20 - 10s = 12:01:10
窗口是否触发? Watermark(12:01:10) >= 12:01:00? ✅ 是!触发窗口计算
事件C: timestamp = 12:01:10
但窗口[12:00,12:01)已经在12:01:10时触发了!
所以事件C被丢弃了❌
-
允许延迟时间是额外的等待时间,所以从逻辑上来说窗口的应该是 实际关闭时间 = 窗口结束时间 + 允许延迟,但是一般认为观测到的事件时间超过窗口结束时间+允许延迟时窗口才会触发。
三、数据晚到时间在允许乱序延迟之外
Flink提供了额外的机制:allowedLateness
.window(TumblingEventTimeWindows.of(Time.seconds(60)))
.allowedLateness(Time.seconds(5)) // 额外允许5秒延迟
这实际上创建了两个触发点:
-
第一次触发(准时触发):
-
当Watermark >= windowEndTime时
-
输出一次结果
-
-
迟到的数据更新:
-
窗口状态保留额外5秒
-
如果有迟到数据到达,会再次触发窗口计算
-
输出更新后的结果
-
© 版权声明
文章版权归作者所有,未经允许请勿转载。


