
【大数据】车辆二氧化碳排放量可视化分析系统 Hadoop+Spark技术 计算机毕业设计项目 Anaconda+Hadoop+Spark环境配置 附源码+文档+讲解
前言
💖💖作者:计算机程序员小杨
💙💙个人简介:我是一名计算机相关专业的从业者,擅长Java、微信小程序、Python、Golang、安卓Android等多个IT方向。会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。热爱技术,喜欢钻研新工具和框架,也乐于通过代码解决实际问题,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💕💕文末获取源码联系 计算机程序员小杨
💜💜
网站实战项目
安卓/小程序实战项目
大数据实战项目
深度学习实战项目
计算机毕业设计选题
💜💜
一.开发工具简介
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python
后端框架:Django
前端:Vue
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
二.系统内容简介
基于大数据的车辆二氧化碳排放量可视化分析系统是一个面向车辆碳排放数据管理与分析的综合性平台,该系统采用Hadoop与Spark作为大数据处理框架,通过HDFS实现海量数据的分布式存储,利用Spark SQL配合Pandas、NumPy等数据处理工具完成对车辆排放数据的清洗、转换与计算工作。系统后端基于Django框架搭建,前端使用Vue技术实现交互界面,数据持久化则依托MySQL数据库来完成。在功能设计方面,平台提供了用户管理、车辆二氧化碳排放量记录、汽车品牌碳排放分析、车辆综合排放分析等多个模块,能够从不同维度对车辆排放数据进行统计与展示,包括发动机技术减排效果评估、燃油消耗与排放关系分析、不同燃料类型的排放对比以及不同车辆类型的排放特征分析等内容。通过这样的方式,系统希望能够为车辆排放数据的管理者提供一个比较直观的数据查看工具,帮助相关人员更好地去了解车辆排放的实际情况,从而为后续的节能减排工作提供一定的数据支撑。
三.系统功能演示
基于大数据的车辆二氧化碳排放量可视化分析系统-演示视频
四.系统界面展示
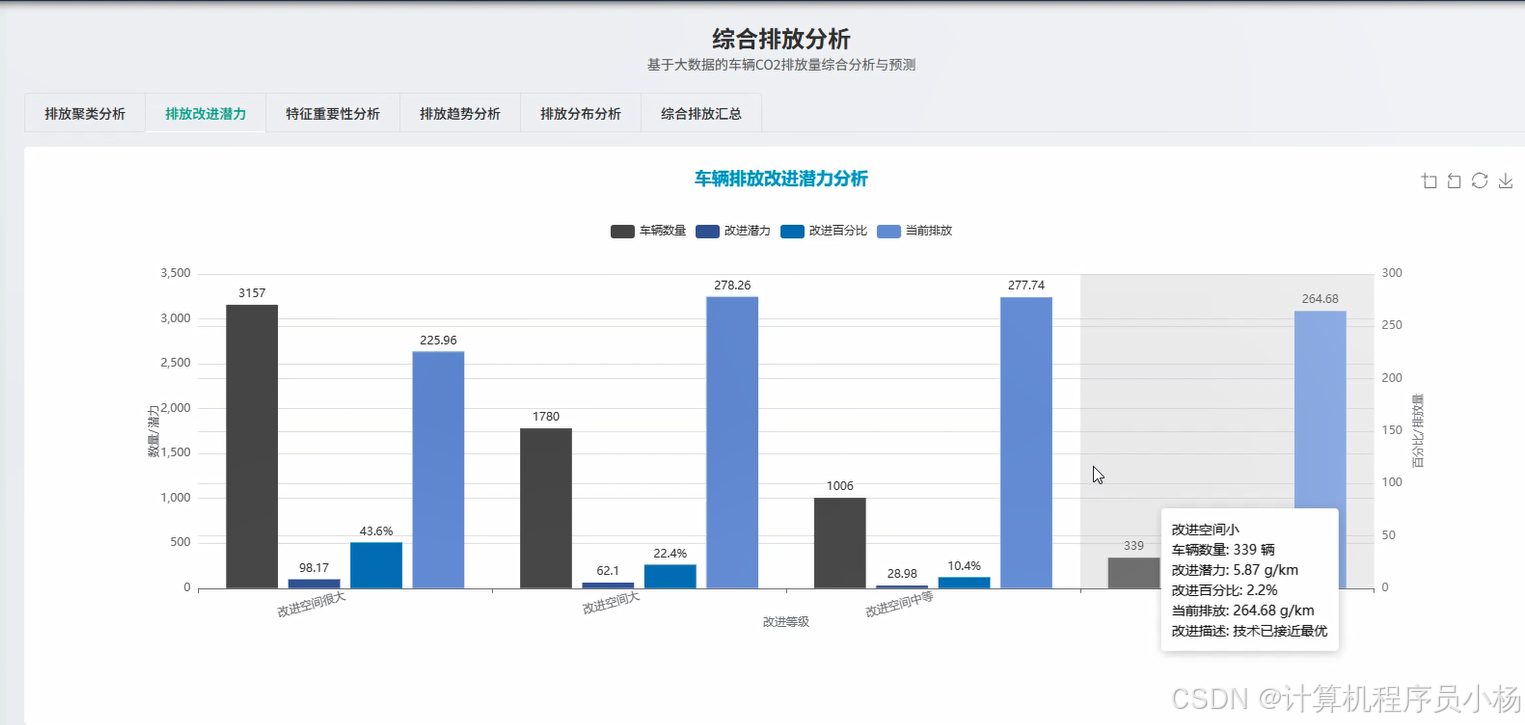
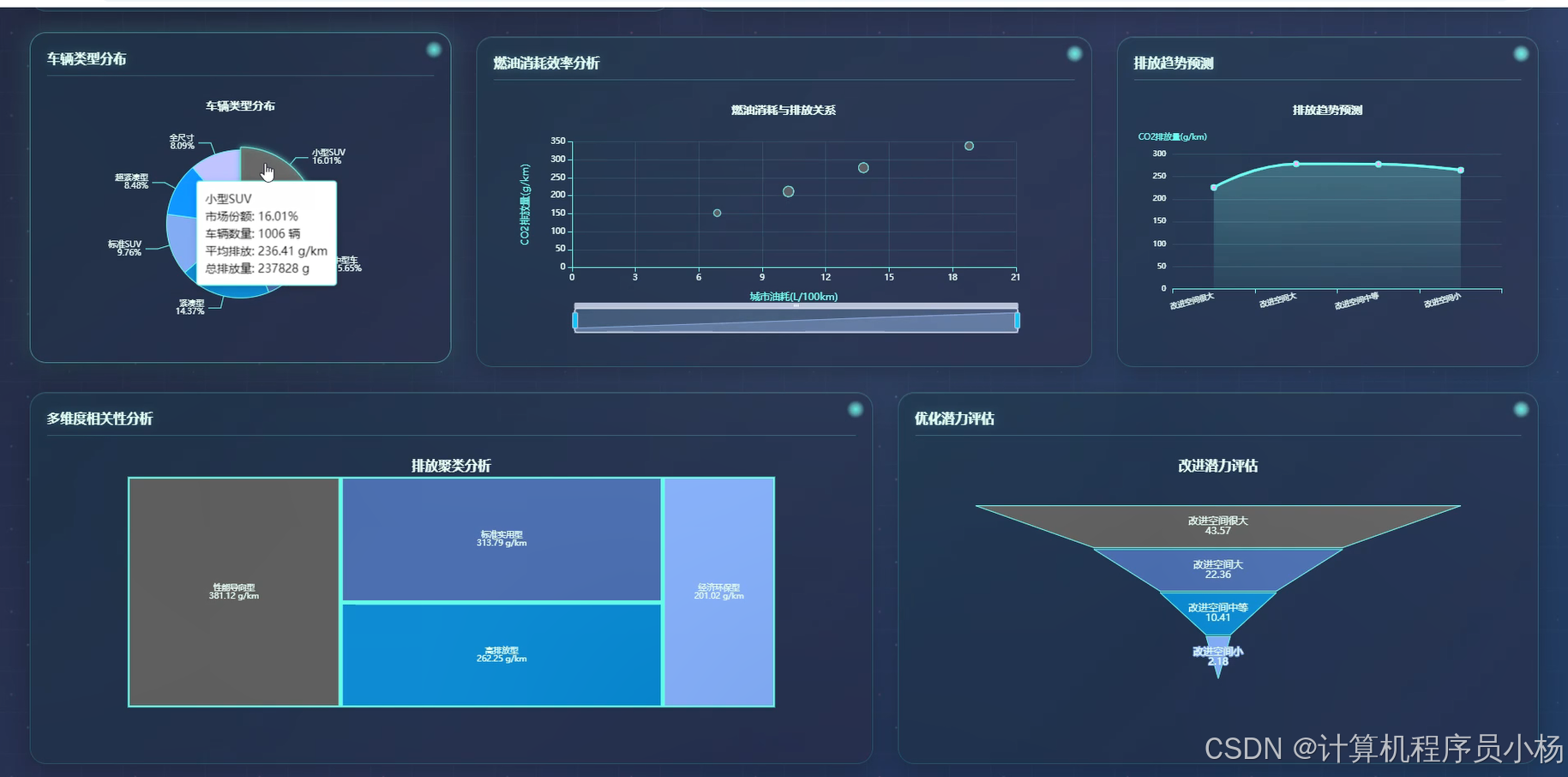
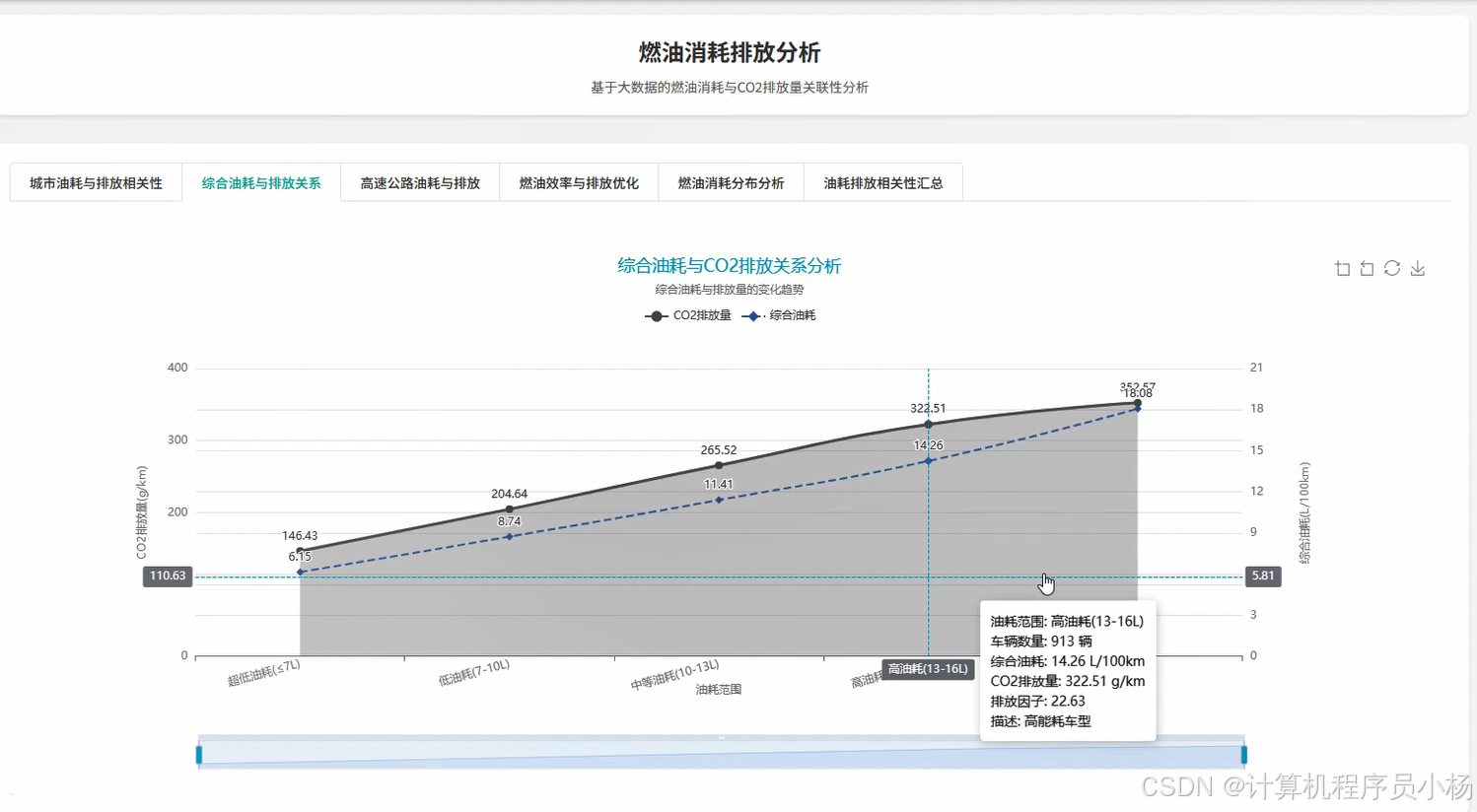
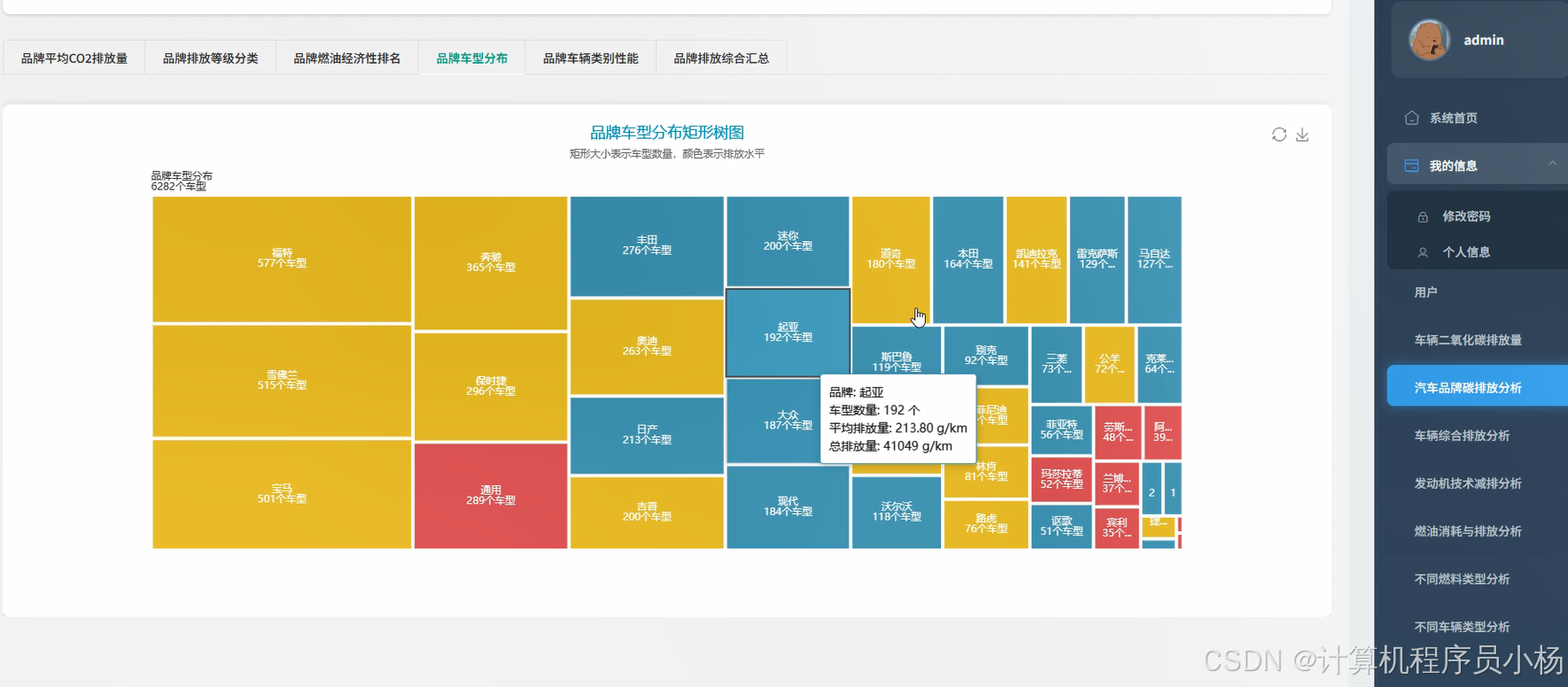
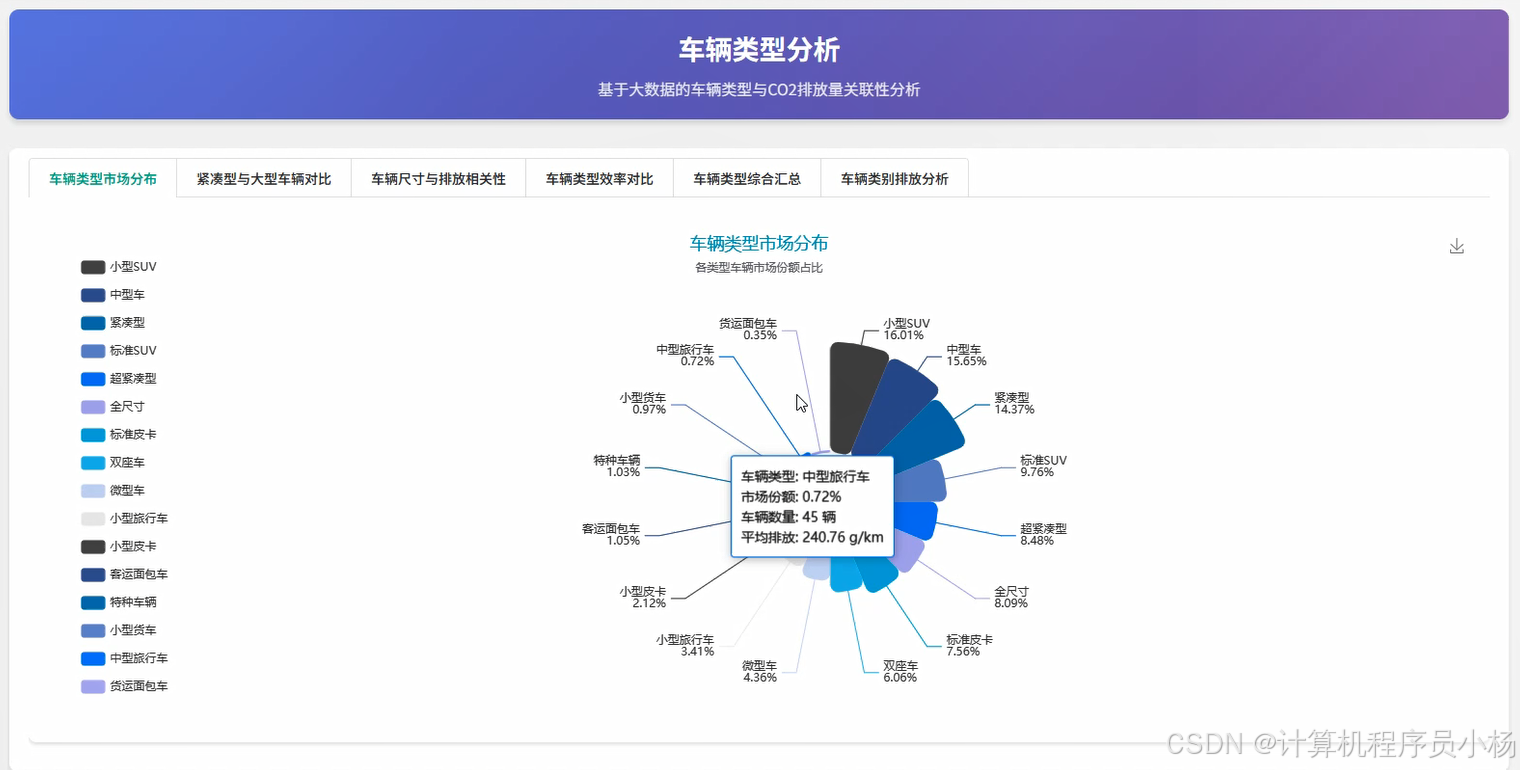
五.系统源码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, sum, count, round as spark_round, when
from django.http import JsonResponse
from django.views.decorators.http import require_http_methods
import json
from .models import VehicleEmission, VehicleBrand, FuelType
spark = SparkSession.builder.appName("VehicleEmissionAnalysis").config("spark.sql.warehouse.dir", "/user/hive/warehouse").config("spark.executor.memory", "2g").config("spark.driver.memory", "1g").getOrCreate()
@require_http_methods(["GET"])
def analyze_brand_emission(request):
try:
brand_id = request.GET.get('brand_id', None)
year_start = request.GET.get('year_start', None)
year_end = request.GET.get('year_end', None)
emission_data = VehicleEmission.objects.all()
if brand_id:
emission_data = emission_data.filter(brand_id=brand_id)
if year_start and year_end:
emission_data = emission_data.filter(production_year__gte=year_start, production_year__lte=year_end)
data_list = list(emission_data.values('brand__name', 'vehicle_model', 'co2_emission', 'fuel_consumption', 'production_year', 'engine_size'))
if not data_list:
return JsonResponse({'code': 404, 'msg': '暂无相关数据'})
spark_df = spark.createDataFrame(data_list)
brand_stats = spark_df.groupBy('brand__name').agg(spark_round(avg('co2_emission'), 2).alias('avg_emission'),spark_round(avg('fuel_consumption'), 2).alias('avg_fuel'),count('vehicle_model').alias('vehicle_count'),spark_round(sum('co2_emission'), 2).alias('total_emission'))
brand_stats = brand_stats.withColumn('emission_level',when(col('avg_emission') < 120, '低排放').when((col('avg_emission') >= 120) & (col('avg_emission') < 160), '中等排放').otherwise('高排放'))
result_data = brand_stats.collect()
response_list = []
for row in result_data:
response_list.append({'brand_name': row['brand__name'],'avg_emission': float(row['avg_emission']),'avg_fuel_consumption': float(row['avg_fuel']),'vehicle_count': int(row['vehicle_count']),'total_emission': float(row['total_emission']),'emission_level': row['emission_level']})
response_list.sort(key=lambda x: x['avg_emission'], reverse=True)
return JsonResponse({'code': 200, 'msg': '分析成功', 'data': response_list})
except Exception as e:
return JsonResponse({'code': 500, 'msg': f'分析失败: {str(e)}'})
@require_http_methods(["POST"])
def analyze_fuel_type_comparison(request):
try:
request_data = json.loads(request.body)
fuel_types = request_data.get('fuel_types', [])
vehicle_class = request_data.get('vehicle_class', None)
emission_queryset = VehicleEmission.objects.all()
if fuel_types:
emission_queryset = emission_queryset.filter(fuel_type__name__in=fuel_types)
if vehicle_class:
emission_queryset = emission_queryset.filter(vehicle_class=vehicle_class)
emission_list = list(emission_queryset.values('fuel_type__name', 'co2_emission', 'fuel_consumption', 'engine_size', 'cylinders', 'vehicle_class'))
if len(emission_list) == 0:
return JsonResponse({'code': 404, 'msg': '未找到符合条件的数据'})
spark_df = spark.createDataFrame(emission_list)
fuel_analysis = spark_df.groupBy('fuel_type__name').agg(spark_round(avg('co2_emission'), 2).alias('avg_co2'),spark_round(avg('fuel_consumption'), 2).alias('avg_fuel'),spark_round(avg('engine_size'), 2).alias('avg_engine'),count('fuel_type__name').alias('sample_count'),spark_round(sum('co2_emission') / count('fuel_type__name'), 2).alias('per_vehicle_emission'))
fuel_analysis = fuel_analysis.withColumn('efficiency_score',spark_round((100 - col('avg_co2') / 3), 2))
fuel_analysis = fuel_analysis.withColumn('fuel_efficiency_ratio',spark_round(col('avg_co2') / col('avg_fuel'), 2))
result_rows = fuel_analysis.collect()
comparison_results = []
for row in result_rows:
fuel_data = {'fuel_type': row['fuel_type__name'],'average_co2_emission': float(row['avg_co2']),'average_fuel_consumption': float(row['avg_fuel']),'average_engine_size': float(row['avg_engine']),'sample_count': int(row['sample_count']),'per_vehicle_emission': float(row['per_vehicle_emission']),'efficiency_score': float(row['efficiency_score']),'fuel_efficiency_ratio': float(row['fuel_efficiency_ratio'])}
comparison_results.append(fuel_data)
comparison_results.sort(key=lambda x: x['average_co2_emission'])
return JsonResponse({'code': 200, 'msg': '燃料类型对比分析完成', 'data': comparison_results, 'total_types': len(comparison_results)})
except Exception as e:
return JsonResponse({'code': 500, 'msg': f'分析过程出现异常: {str(e)}'})
@require_http_methods(["POST"])
def comprehensive_emission_analysis(request):
try:
params = json.loads(request.body)
min_year = params.get('min_year', 2010)
max_year = params.get('max_year', 2024)
selected_brands = params.get('brands', [])
emission_threshold = params.get('emission_threshold', None)
all_emissions = VehicleEmission.objects.filter(production_year__gte=min_year, production_year__lte=max_year)
if selected_brands:
all_emissions = all_emissions.filter(brand__name__in=selected_brands)
emission_values = list(all_emissions.values('brand__name', 'vehicle_model', 'co2_emission', 'fuel_consumption', 'production_year', 'engine_size', 'cylinders', 'transmission', 'fuel_type__name', 'vehicle_class'))
if not emission_values:
return JsonResponse({'code': 404, 'msg': '没有找到符合筛选条件的排放数据'})
df = spark.createDataFrame(emission_values)
if emission_threshold:
df = df.filter(col('co2_emission') <= emission_threshold)
year_trend = df.groupBy('production_year').agg(spark_round(avg('co2_emission'), 2).alias('yearly_avg_emission'),count('vehicle_model').alias('vehicle_count')).orderBy('production_year')
transmission_analysis = df.groupBy('transmission').agg(spark_round(avg('co2_emission'), 2).alias('trans_avg_emission'),spark_round(avg('fuel_consumption'), 2).alias('trans_avg_fuel'),count('transmission').alias('trans_count'))
class_analysis = df.groupBy('vehicle_class').agg(spark_round(avg('co2_emission'), 2).alias('class_avg_emission'),spark_round(avg('engine_size'), 2).alias('class_avg_engine'),count('vehicle_class').alias('class_count'))
overall_stats = df.agg(spark_round(avg('co2_emission'), 2).alias('overall_avg'),spark_round(avg('fuel_consumption'), 2).alias('overall_fuel'),count('vehicle_model').alias('total_vehicles'))
year_data = [{'year': row['production_year'], 'avg_emission': float(row['yearly_avg_emission']), 'count': int(row['vehicle_count'])} for row in year_trend.collect()]
trans_data = [{'transmission': row['transmission'], 'avg_emission': float(row['trans_avg_emission']), 'avg_fuel': float(row['trans_avg_fuel']), 'count': int(row['trans_count'])} for row in transmission_analysis.collect()]
class_data = [{'vehicle_class': row['vehicle_class'], 'avg_emission': float(row['class_avg_emission']), 'avg_engine': float(row['class_avg_engine']), 'count': int(row['class_count'])} for row in class_analysis.collect()]
overall_row = overall_stats.collect()[0]
overall_info = {'overall_avg_emission': float(overall_row['overall_avg']),'overall_avg_fuel': float(overall_row['overall_fuel']),'total_analyzed_vehicles': int(overall_row['total_vehicles'])}
return JsonResponse({'code': 200, 'msg': '综合排放分析已完成', 'year_trend': year_data, 'transmission_analysis': trans_data, 'class_analysis': class_data, 'overall_statistics': overall_info})
except Exception as e:
return JsonResponse({'code': 500, 'msg': f'综合分析时发生错误: {str(e)}'})
六.系统文档展示

结束
💕💕文末获取源码联系 计算机程序员小杨
© 版权声明
文章版权归作者所有,未经允许请勿转载。


