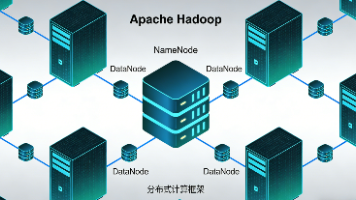
centos7安装hadoop3(下)
windows虚拟机centos7,安装hadoop3,完全分布式安装
![[硬核] 别再用网页版聊 Gemini 了:Google AI Studio 最佳实践与 3.0 Pro 参数调教](https://os.v.madlive.cn/idcmadlive/2026/04/43c14aa745fc48418167367e80f19fc8.png)
[硬核] 别再用网页版聊 Gemini 了:Google AI Studio 最佳实践与 3.0 Pro 参数调教
Google AI Studio 为开发者提供了比网页版更强大的Gemini 3.0 Pro定制能力。关键配置包括:选择Gemini 3.0 Pro Preview模型、保持默认1.0温度值、开启Hi...
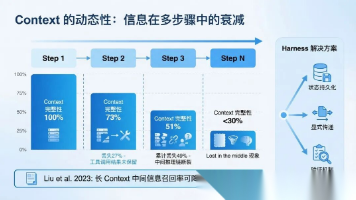
Harness Engineering工程化教程(非常详细),AI Agent复杂长任务从入门到精通,收藏这一篇就够了!
OpenAI 的一个团队在五个月内用 Codex 写了一百万行代码,三个工程师平均每天合并 3.5 个 PR,没有一行代码是工程师手写的。Anthropic 的 Claude Code 能连续工作数天...

【AI Coding 系列】——什么是AI Coding,怎么合理使用AI Coding,大模型上下文限制解决方案,任务拆解策略
AICoding是一种以大型语言模型(LLM)为核心的新型编程范式,要求开发者掌握模型边界感知、上下文工程等新技能。随着GPT-4等模型的发展,编程模式正从AI辅助转向AI主导架构、人工决策的代理编程...

数据结构——单链表常见面试习题
本文介绍了单链表的常见操作及算法实现。主要包括:1)单链表逆置的两种方法(辅助节点法和三指针法);2)查找链表倒数第k个节点的快慢指针法;3)判断链表相交及求交点的长度差法;4)删除节点的数据覆盖法...
再见OpenClaw!ZeroClaw重磅开源,轻量极速的Rust版AI Agent神器来了
OpenClaw爆火后暴露两大痛点:超高内存占用和缓慢启动速度。为解决这些问题,Rust重构版ZeroClaw应运而生,具备四大核心优势:1)Rust驱动实现秒级启动;2)沙盒隔离保障安全;3)模块化...

最新 阶跃AI桌面伙伴 完整实操教程:MCP协议配置 + 16款工具集成(Excel/邮箱/飞书/高德自动化)
本文为阶跃 AI 桌面伙伴完整实操教程,聚焦 MCP 协议快速配置,详解 16 款常用工具集成(含 Excel、邮箱、飞书、高德自动化),全程纯操作无冗余,指令可直接复制,适配 CSDN 技术学习需求...

MongoDB(81)事务的应用场景有哪些?
摘要 本文介绍了MongoDB事务在实际应用中的两个典型场景:资金转账和订单处理。在资金转账示例中,通过Java代码展示了如何确保银行账户间的转账操作具有原子性,要么同时成功,要么回滚。订单处理示例则...
CodeBuddy Code + 腾讯混元打造“AI识菜通“
摘要:本文介绍了使用CodeBuddyCode和腾讯混元大模型开发"AI识菜通"应用的全过程。该应用能够识别多语言菜单图片,通过AI模型自动翻译成中文并生成菜品介绍...

Python与大数据:非科班转码者的指南
Python在大数据处理领域有着广泛的应用,它的简洁语法和丰富生态使其成为大数据处理的理想选择。作为一个非科班转码者,我认为学习Python与大数据的结合不仅可以提高数据处理能力,还可以打开更多的职业...