
两级液氧甲烷不锈钢火箭健康管理系统深度解读与总体方案设计
火箭健康管理系统通过"四层三环"架构实现全生命周期预测性维护,将传统定期检修转变为基于状态的精准维护。系统整合传感器网络、数字孪生和AI分析,建立"...
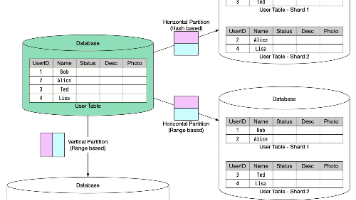
分库分表方法论:什么时候该拆?怎么拆?
数据库分库分表是应对数据量增长的核心解决方案。文章系统阐述了分库分表的决策时机和具体实施策略:当单表数据超过500万行、并发请求达1000QPS时,应考虑拆分。拆分应遵循"先垂直后水...

【人工智能】OpenClaw(一):MacOS极简安装OpenClaw之Docker版
OpenClaw最近实在是太火了,作为CSDN认证的“优质人工智能博主”,不跟进有点说不过去了,还是一贯的风格,尽量极简让你养上自己的小龙虾。

ToClaw他来了!融合OpenClaw、网页AI、远程功能,更适合真正的办公落地
AI办公助手ToClaw深度对比分析 摘要:随着AI技术发展,ToClaw融合OpenClaw开源Agent技术与远程控制能力,为办公场景提供全新解决方案。相比网页AI的内容生成、传统远程工具的设备连...

AI实践(5)检索增强(RAG)
本文介绍了检索增强生成(RAG)技术及其核心组件。RAG通过结合信息检索与文本生成模型,解决了大语言模型知识过时、幻觉和缺乏领域知识的问题。文章详细阐述了RAG的工作原理和发展历程,从早期的Naive...

两级液氧甲烷不锈钢火箭飞行控制系统深度解读与总体方案设计
本文提出了一种新一代智能飞行控制系统,采用"云-边-端"三级协同架构,实现了从传统程序制导向自适应智能制导的跨越。系统通过在线轨迹优化、自适应控制和智能故障处置三位...

AI安全高阶:AI模型可解释性与安全防护的结合
本文深入探讨了AI模型可解释性与安全防护结合这一关键议题。文章首先阐述了AI安全、合规与治理作为AI健康发展的三大基石,指出当前AI应用中面临的安全风险、合规要求和治理挑战。通过概念解析明确了AI安全...

医疗AI场景下算法编程的深度解析(2026新生培训讲稿)(一)
人工智能在医疗健康领域的应用正在经历从技术验证到临床落地的关键转型。自2022年以来,以大模型为代表的新一代AI技术更是加速了这一进程。然而,技术的进步与临床的采纳之间仍存在显著鸿沟。本综述将从医疗A...

Java + AI 混合编程落地实施方案(保姆级)
Java + AI 混合编程落地实施方案(保姆级)
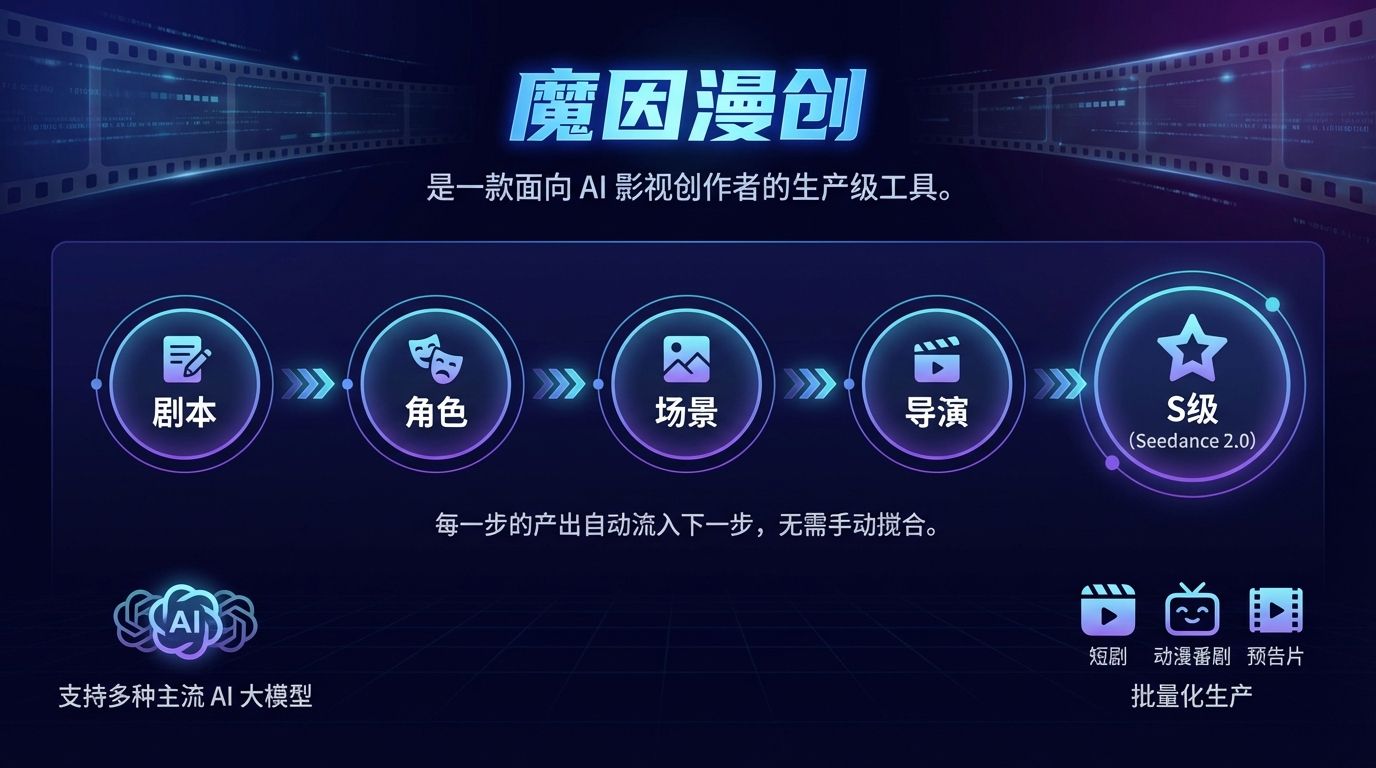
【GitHub项目推荐–Moyin Creator(魔因漫创):AI影视生产级全流程创作工具】⭐⭐⭐
Moyin Creator(魔因漫创) 是一款面向AI影视创作者的生产级工具,致力于实现从剧本到成片的完整创作链路自动化。作为支持Seedance 2.0技术的先进创作平台,它通过五大核心板块的环环...