
Kafka:为什么分区是高并发的关键?
Kafka:为什么分区是高并发的关键?

人工智能:预训练语言模型与BERT实战应用
摘要:本章介绍预训练语言模型的核心思想及BERT实战应用。预训练语言模型通过"预训练+微调"范式解决传统NLP模型对标注数据依赖大、上下文理解有限的问题。重点解析B...
Ling Studio深度体验:一站式AI生产力平台完全指南
一句话总结:Ling Studio是蚂蚁百灵大模型团队推出的官方Web交互平台,集成Ling、Ring、Ming三大模型系列,支持代码模式、文档对话、图像生成、API调用等丰富功能,每日50万免费to...

AI 时代,鸿蒙 App 还需要传统导航结构吗?
AI时代鸿蒙App导航结构的转型与重构 摘要:随着AI成为系统级能力,传统移动App导航结构正面临根本性变革。本文分析了传统导航结构解决的信息分区、路径预期和功能发现三大问题,指出AI通过任务直达、语...

AI 应用层革命(一)——软件的终结与智能体的崛起
AI应用层革命正在颠覆传统软件范式。随着AI智能体(如ChatGPT、AutoGPT等)的崛起,人类交互方式从"命令"转向"意图"...
OpenClaw(养龙虾) +关于Hadoop hive的Skills(CLoudera CDH、CDP)
摘要:OpenClaw生态未内置Hadoop/Hive专用技能,因其企业级特性难以通用化。建议通过组合基础技能实现操作:1)使用tmux/session-logs管理长时任务;2)通过shell/ex...
被搜狗输入法背刺了!偷偷装的 “AI 汪仔” 狂占 CPU!手把手教你如何彻底关闭删除搜狗AI功能AI汪仔
手把手教你如何彻底关闭删除搜狗输入法的AI汪仔🚀
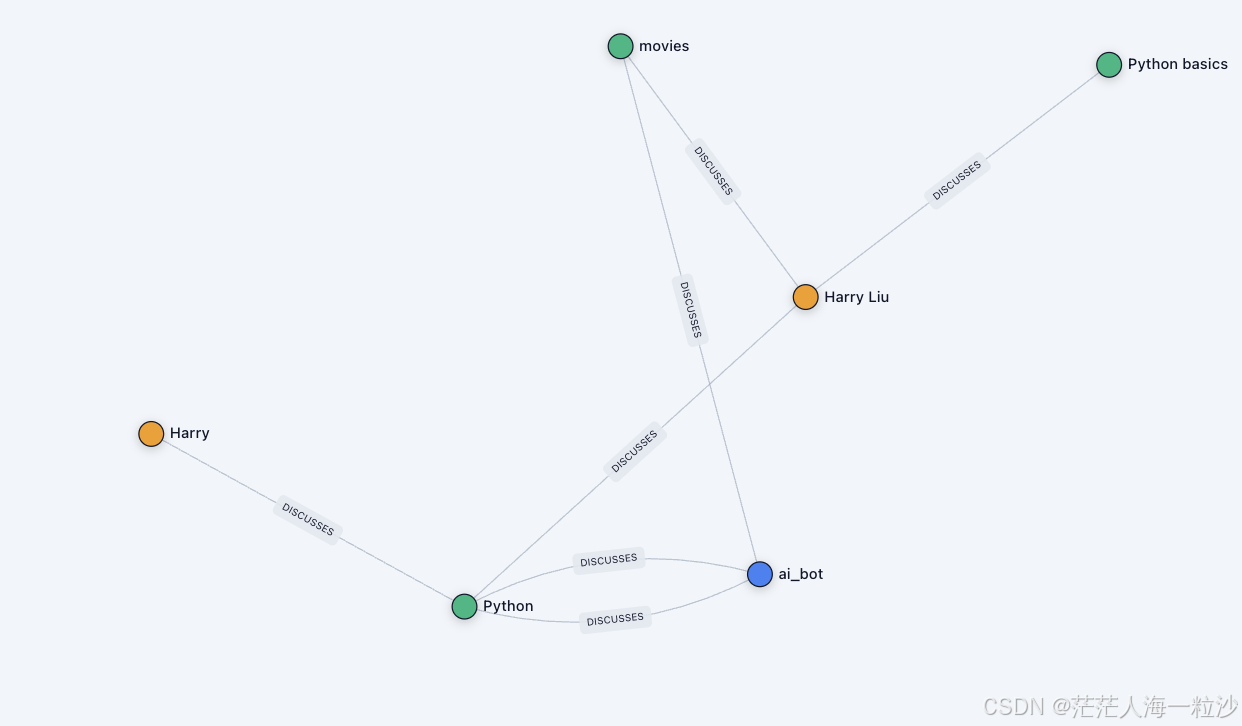
给 AI 装上长期记忆:Zep Cloud 初探与上手教程
传统的聊天机器人往往是「短期记忆」:只记住本轮对话内容。而 Zep 则进一步赋予 AI 「长期记忆」:它能管理用户信息、保存对话线程、抽取知识图谱,并支持高效的检索和推理。对于想要打造真正个性化 AI...

Spark-Submit参数介绍及任务资源使用测试
yarn-client模式中,通过指定“--num-executors”参数则默认为Spark任务启动2个Executor;提交任务后,可以通过WebUI查看当前Application使用资源情况:A...
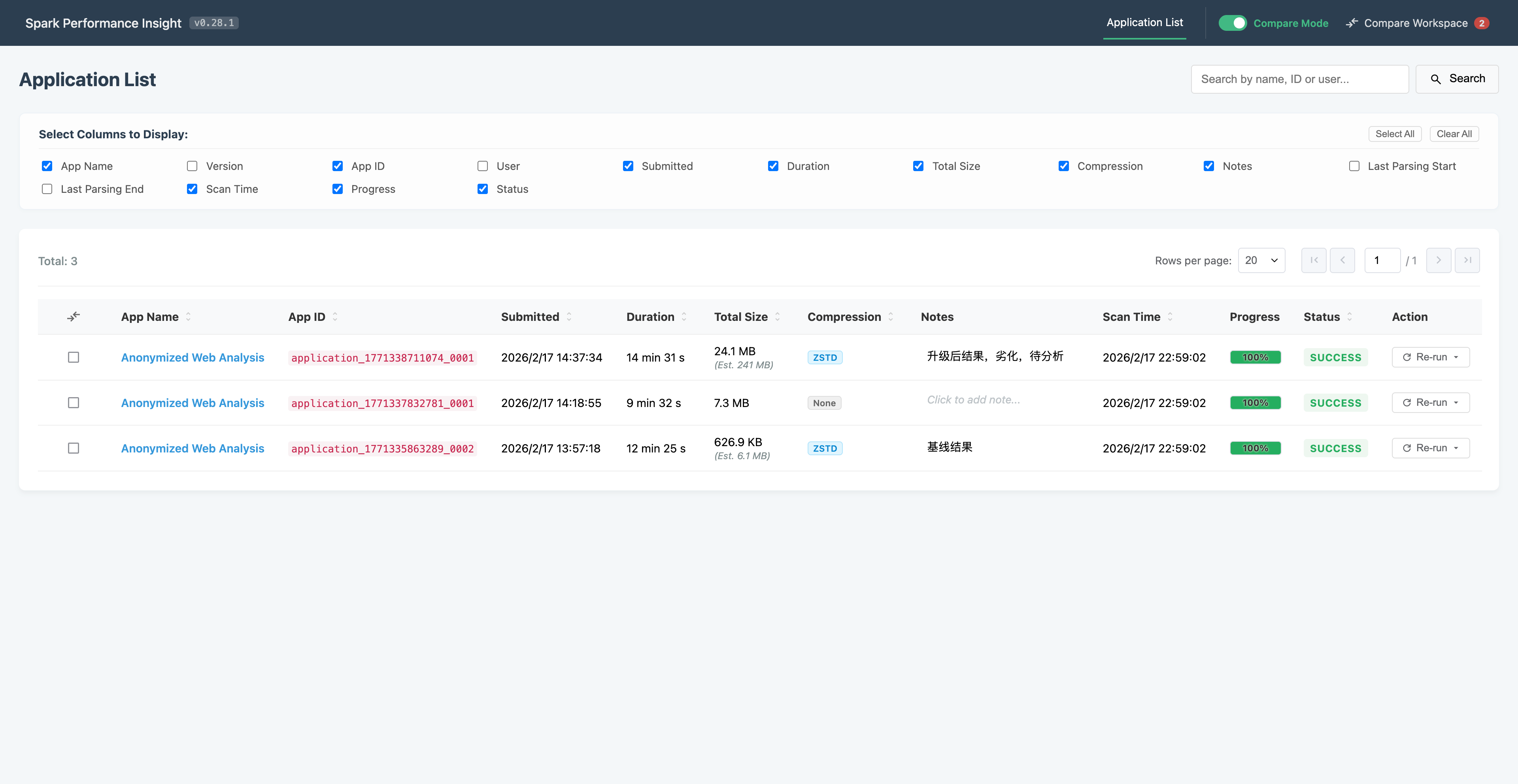
从“吐槽”到“交付”——我是如何协同 AI 撸出一个 Spark 性能分析工具的(上)
本文记录了一位后端开发者利用AI协作在3周内完成Spark性能分析工具开发的真实经历。通过"吐槽驱动开发"模式,作者实现了三大突破:跨越10年前端技术断层、24倍性...