
JetBrains AI Assistant 超全使用教程|从安装到实战,解锁 AI 编程高效体验
在「Third-party AI providers」中选择服务商(OpenAI/Anthropic/OpenAI 兼容接口);输入你的 API Key,点击「Test Connection」测试连接...

大数据领域数据仓库对企业的重要性
本文旨在帮助企业管理者、数据从业者理解数据仓库的核心价值,重点覆盖:数据仓库的定义与核心功能、技术原理(如ETL流程)、企业实际应用场景,以及其对数字化转型的战略意义。内容不涉及过于底层的技术细节(如...

Python AI基础:NumPy数组操作入门
本文系统介绍了Python在AI领域的核心应用,重点讲解了NumPy数组操作的基础知识。内容包括: 重要性:Python凭借简洁语法和丰富生态成为AI开发首选,掌握NumPy数组操作是AI从业者必备技...
计算机毕业设计:Python基于Spark与协同过滤的小说数据分析推荐系统 Spark Hadoop Hive Django 可视化 图书 大数据(建议收藏)✅
技术栈Python 语言、Spark 分布式计算框架、Hadoop 分布式存储、Hive 数据仓库、Django Web 框架、Echarts 可视化库、基于用户的协同过滤推荐算法、scikit-le...

小龙虾终于不用配环境了!OpenClaw v7.0.0 桌面版首发,一键启动你的本地 AI 特工!附下载链接!
OpenClaw 团队发布 v7.0.0 Beta Windows 桌面版,提供一键安装体验。这个本地 AI 助理支持文件管理、代码辅助、网络自动化等功能,所有数据本地处理确保隐私安全。新版本内置运行...

Flink与HBase集成:实时数据存储与查询方案
在当今数字化时代,实时数据处理和存储变得越来越重要。很多业务场景都需要对海量的实时数据进行快速处理和存储,以便能够及时做出决策。Flink是一个强大的实时流处理框架,而HBase是一个分布式、可伸缩的...

大数据领域分布式计算的政府项目实践
随着“数字政府”战略推进,政府部门日均产生PB级政务数据,涉及人口、交通、医疗、应急等多领域。传统集中式架构在数据吞吐量、扩展性、容错性上的瓶颈日益凸显,分布式计算成为破解政务数据“存不下、算不动、用...

深入剖析Spark UI界面:参数与界面详解|得物技术
围绕 Spark UI 监控模块,解析 Executors、SQL、Stages 等核心入口与关键指标,结合表扫描慢、Shuffle 并行度不足等典型场景,给出基于内存、并行度及 AQE 参数的调优方...

RabbitMQ与Kafka的区别?
从实现思路上看,RabbitMQ 更像把消息投递给消费者处理,Kafka 更像把消息顺序写入分区日志,消费者通过 offset 自己控制消费进度。也能保证可靠性,但它更偏“分区日志”的思路,路由灵活性...
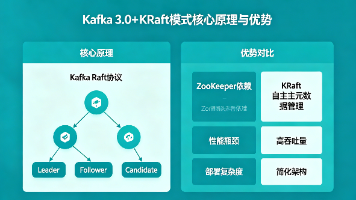
【Kafka核心】Kafka 3.0+ KRaft模式(替代ZooKeeper)核心原理与优势
本文系统解析Kafka 3.0+ KRaft模式全知识体系,涵盖背景演进、核心架构、Raft原理、元数据管理、部署运维、最佳实践等九大维度,深度对比ZK模式,详解Controller/Broker角色...