
时序大模型 TimechoAI:从预测到异常检测的全链路分析
时序大模型 TimechoAI:从预测到异常检测的全链路分析

Tokaify解锁AI全维度,把 AI 真正变成生产力
Tokaify是一款聚合式AI能力平台,整合了OpenAI、Claude、Gemini等主流模型,提供一站式AI解决方案。其核心优势在于统一API接口,支持代码、绘图、文案、音乐等多场景创作,大幅提升...
昨天同时用光中外多个免费额度账号
本文探讨了使用Python将带Mermaid图表的Markdown转为HTML时遇到的问题,指出可能应改用Quarto而非纯Python方案。作者分享了因AI模型陷入无效循环导致多平台API额度耗尽的...
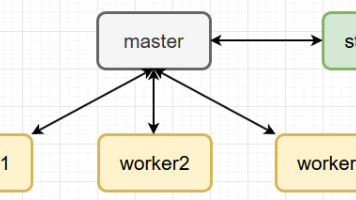
小肥柴的Hadoop之旅 快速实验篇(0-1)虚拟机模拟完全分布式环境搭建
一套在(本地)虚拟机中模拟完全分布式Hadoop环境搭建过程,适配3.0以上版本;对潜在踩坑都做了预判,能够快速上手这门非遗技术。

Python AI基础:Python面向对象编程
本文介绍了Python面向对象编程在AI开发中的核心地位和应用。文章首先阐述了Python在AI领域的优势地位,然后系统讲解了面向对象编程的关键概念、技术原理和实现方法。主要内容包括: 核心概念解析...
10倍写作效率!AI小白必学:Cursor+Word MCP打造智慧文档生成神器
通过Cursor+Word MCP的强大组合,对于个人用户,以前用AI生成文档内容要手动更新到word,手动调整格式,现在直接在一个对话框中完所有的步骤,极大的提高了我们的办公效率,如果和 上一篇讲的...
基于魔珐星云打造的元宇宙社交猫女数字人:赛博朋克风格、实时语音交互、AI智能陪伴
基于魔珐星云打造的元宇宙社交猫女数字人:赛博朋克风格、实时语音交互、AI智能陪伴

Stable-Diffusion-v1-5-archive创意工作者手册:每日10个高质量Prompt灵感库
本文介绍了如何在星图GPU平台上自动化部署stable-diffusion-v1-5-archive镜像,并提供了创意工作者手册与每日Prompt灵感库。该平台简化了经典文生图模型的部署流程,用户可快...

Android16车载音频进阶之新增自定义usage实战(一百六十五)
本篇目的:Android16车载音频进阶之新增自定义usage实战。

大数据领域ClickHouse的权限管理与审计
假设你是一家电商公司的DBA,负责维护ClickHouse集群——里面存着10TB用户行为数据(比如“谁在什么时候点击了什么商品”)。分析师:需要查数据做报表,但不能删表;运维:需要管理用户和集群,但...