
深入剖析Spark UI界面:参数与界面详解|得物技术
围绕 Spark UI 监控模块,解析 Executors、SQL、Stages 等核心入口与关键指标,结合表扫描慢、Shuffle 并行度不足等典型场景,给出基于内存、并行度及 AQE 参数的调优方...

RabbitMQ与Kafka的区别?
从实现思路上看,RabbitMQ 更像把消息投递给消费者处理,Kafka 更像把消息顺序写入分区日志,消费者通过 offset 自己控制消费进度。也能保证可靠性,但它更偏“分区日志”的思路,路由灵活性...
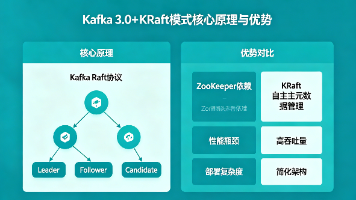
【Kafka核心】Kafka 3.0+ KRaft模式(替代ZooKeeper)核心原理与优势
本文系统解析Kafka 3.0+ KRaft模式全知识体系,涵盖背景演进、核心架构、Raft原理、元数据管理、部署运维、最佳实践等九大维度,深度对比ZK模式,详解Controller/Broker角色...

Google I/O 2026 技术全解析:Gemini 3.5/Omni/Spark 架构升级与开发者影响
Google I/O 2026发布13项重大更新,包括Gemini 3.5系列模型、多模态Gemini Omni、24/7运行的Gemini Spark AI助手等。AI Studio新增Vibe C...

从归档项目openclawbrain-archive解析数据采集与智能处理系统架构
数据采集与智能处理系统是现代信息技术中处理海量信息的基础设施,其核心原理是通过自动化程序从互联网或特定数据源获取原始数据,并经过清洗、解析、结构化等智能处理流程,转化为有价值的结构化信息。这类系统的技...

Stable-Diffusion-v1-5-archive镜像交付标准:Dockerfile透明/构建层可追溯/SHA256校验
本文介绍了在星图GPU平台上自动化部署stable-diffusion-v1-5-archive镜像的标准与实践。该平台支持一键拉起服务,通过遵循Dockerfile透明、构建层可追溯及SHA256校...

大数据转AI Agent开发
连接成功后,在 Cursor 里点击 "Open Folder",打开你在虚拟机里的工作目录(比如 /home/username/ai_projects)。打开 Cursor,ct...
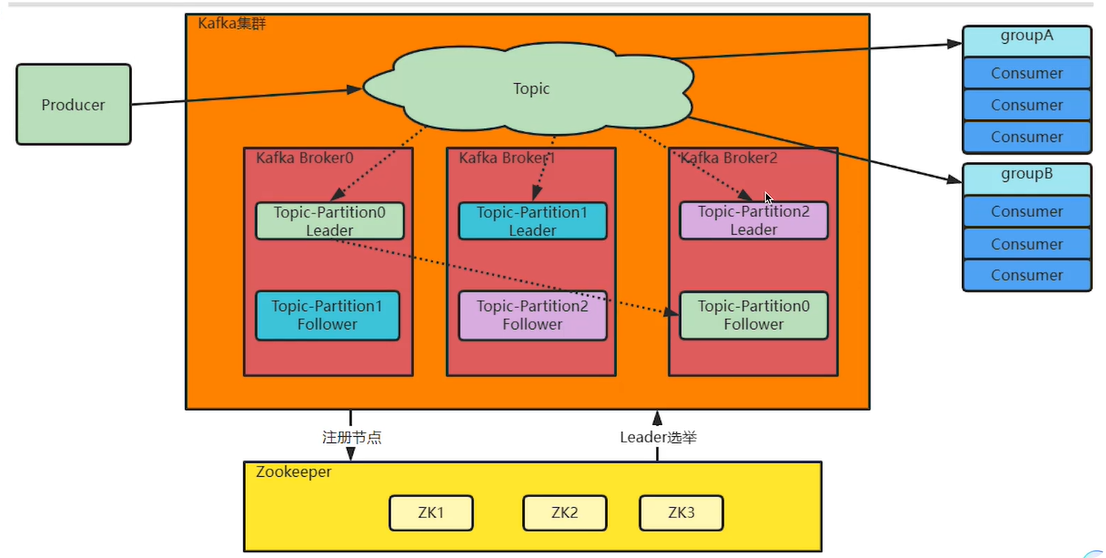
消息队列之Kafka(一)搭建服务
最后:Kafka集群中的这些Broker信息,包括Partiton的选举信息,都会保存在额外部署的Zookeper集群当中,这样,kaka集群就不会因为某一些Broker服务崩溃而中断。Kaka是面向...
windows下RabbitMQ的使用(1)——下载与安装
RabbitMQ是一款基于AMQP协议的开源消息队列中间件,采用Erlang语言开发。本文首先介绍了RabbitMQ的核心组件(生产者、交换机、队列、消费者等)及其工作流程,并详细阐述了其高可靠性、灵...
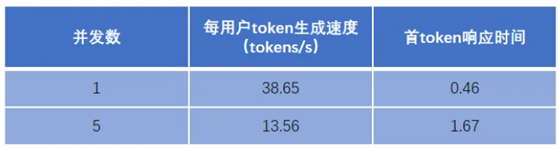
当SPARK遇到671B:揭秘桌面级设备如何运行超大模型
通过这次测试数据的梳理,小编有几点思考想和大家分享:1)算力民主化的可能性超大模型推理不再是大型企业的专属能力。通过合理的架构设计,中小规模的硬件集群也能支撑起千亿参数模型,这为更多企业和研究机构提供...