
Oracle Redo日志与Undo回滚段损坏恢复实战
没有RMAN备份的情况下,分别针对Redo日志损坏和Undo回滚段损坏的恢复方法。

RabbitMQ 进阶
MQ 是异步调用,那么要如何确保 MQ 消息的可靠性,如果真的发送失败,有没有其它的兜底方案?相信本文章可以给你想要的答案。

聚合多个顶尖AI模型,打造极速编程流|Chatbox AI 实战精讲
ChatboxAI是一款支持多AI模型调用的全平台工具,覆盖Windows、macOS、Linux、Android、iOS等操作系统,并提供网页版访问方式。其核心功能包括集成DeepSeek、Chat...

NotebookLM 深度实战:30分钟用AI吃透一本书,自动生成PPT大纲与思维导图
NotebookLM 是 Google 出品的免费 AI 学习工具,能将 YouTube 视频、PDF、网页等任意资料变成可对话的知识库。本文手把手带你走完完整闭环:用「YouTube to Note...

电脑部署龙虾AI(OpenClaw)完整教程 + 日常使用详解
本文详细介绍了如何从零部署和使用龙虾AI(OpenClaw)智能助手。内容涵盖Windows/macOS/Linux三大系统的部署教程,包括环境准备、一键安装命令、权限设置等关键步骤。特别提供了5个高...
大数据数据标准化与数据治理的关系?一次性讲清楚(附框架图)
标准化是治理的“基础”:没有标准化,治理就没有“统一的语言”,无法落地;治理是标准化的“保障”:没有治理,标准化就没有“执行的动力”,无法持续;两者的目标一致:都是为了“让数据成为可信、可用、可控的资...
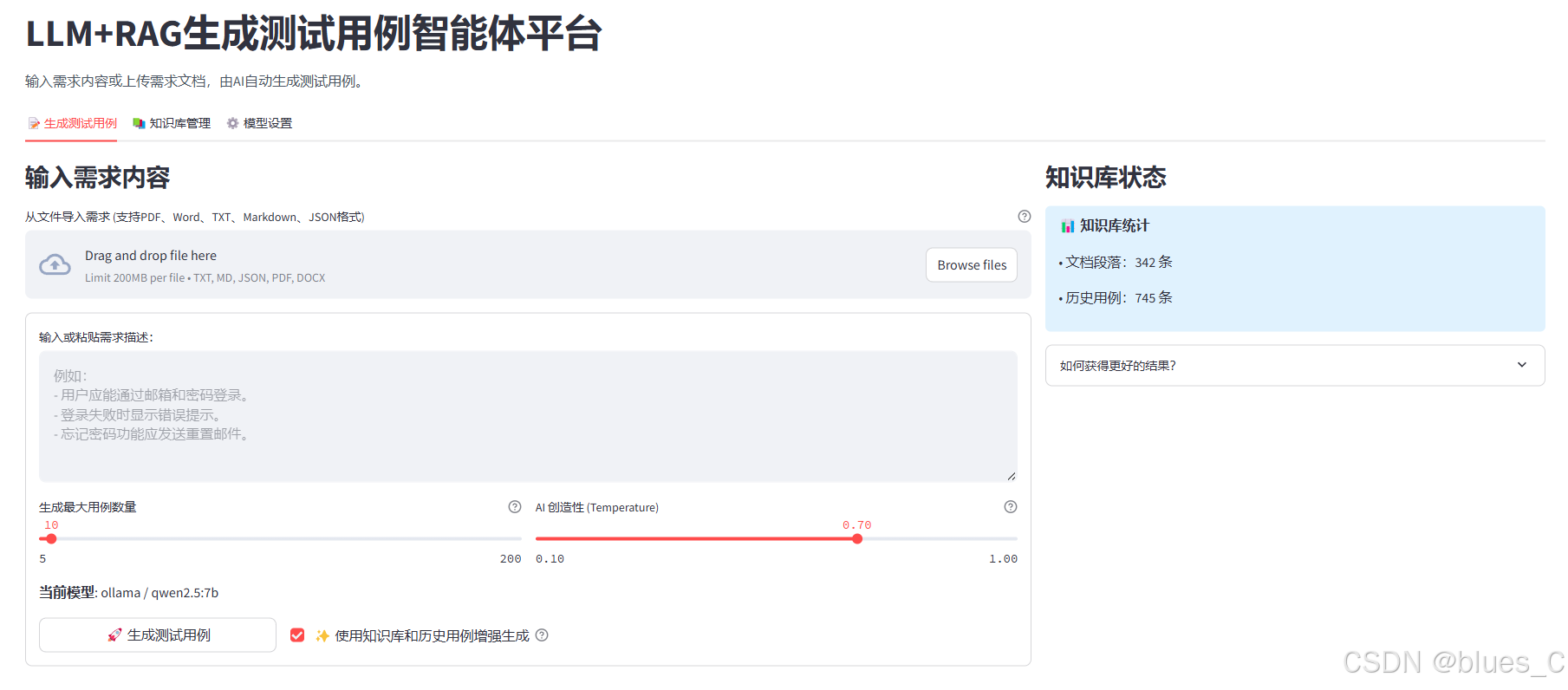
LLM+RAG:AI生成测试用例智能体平台「详细介绍」
AI生成测试用例智能体平台是一款基于人工智能技术的测试用例自动生成工具,利用RAG(检索增强生成)技术,能够结合项目相关知识文档和历史用例,智能生成高质量的测试用例。本平台适用于测试团队快速创建测试用...

Hadoop与视频流分析:内容推荐系统
你是否注意到:当你在视频平台搜索过“猫咪”,半小时后首页就会出现大量猫主子的萌视频;当你看完一部科幻电影,接下来三天推荐列表里全是“太空探险”主题内容?这些“比你更懂你”的推荐,本质是“内容推荐系统...

【AI大模型入门】05:即梦——字节的AI创作神器,图像+视频一站搞定
即梦是字节跳动为创意人打造的AI创作平台,在中文环境下的图像生成🎨中文提示词效果最好的AI绘图工具之一🖼️图像编辑功能强大,局部修改精准📹图生视频/文生视频功能持续增强🆓有免费额度,普通使用基本够用...
计算机毕业设计hadoop+spark+hive 高考志愿填报推荐推荐系统 高考数据分析可视化大屏 高考爬虫 高考分数线预测 数据仓库 大数据毕业设计
摘要:本项目基于Hadoop+Spark+Hive技术栈开发高考志愿填报推荐系统,整合历年录取数据、院校信息等多源数据,利用Spark进行实时数据处理和机器学习算法实现个性化推荐。系统包含数据存储(H...