
【大数据毕设选题】基于Spark+Django的胆结石消化系统疾病数据分析系统源码 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘
为探究胆结石风险因素,本系统构建了基于Spark+Django的数据分析平台。利用Hadoop存储海量医疗数据,通过Spark SQL及Pandas进行多维度分析,涵盖人口统计学、体成分、血脂等指标...

计算机毕业设计Hadoop+Spark+Hive酒店推荐系统 酒店可视化 酒店爬虫 大数据毕业设计(源码+文档+PPT+讲解)
本文提出基于Hadoop+Spark+Hive的酒店推荐系统,通过分布式架构整合用户行为、酒店属性和情境数据,构建混合推荐模型。系统采用五层架构实现数据采集、存储、处理和推荐闭环,创新性地提出动态权重...
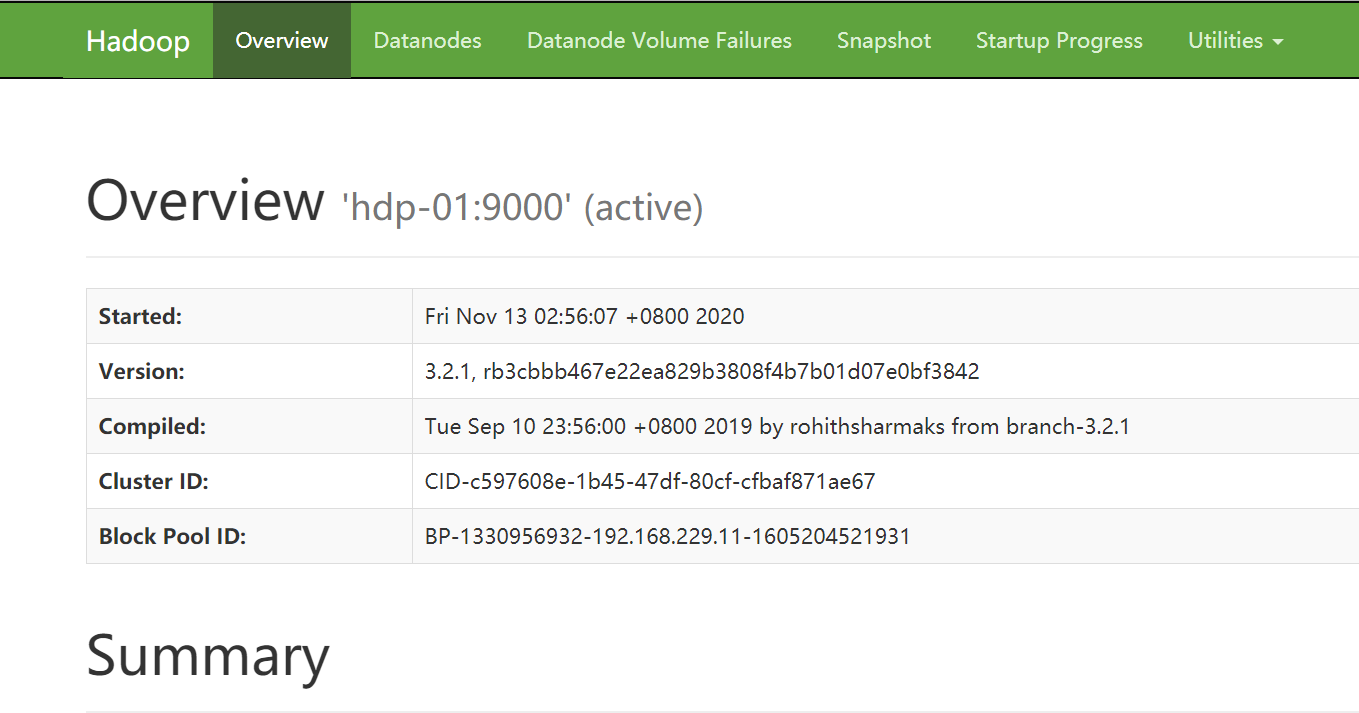
Hadoop:HDFS 集群环境搭建
HDFS 集群由一个主/从架构组成,单个运行 NameNode 进程的服务器为主节点服务器,多个运行 DataNode 进程的服务器为从节点服务器。

DGX Spark (Blackwell) 部署 Qwen3.6 35B FP8 踩坑实录:从无限崩溃到成功跑通
本文记录了在全新 NVIDIA DGX Spark G10(Blackwell ARM64架构)服务器上,使用 vLLM 部署 Qwen3.6-35B-A3B-FP8 模型的硬核踩坑实录。针对新硬件架...
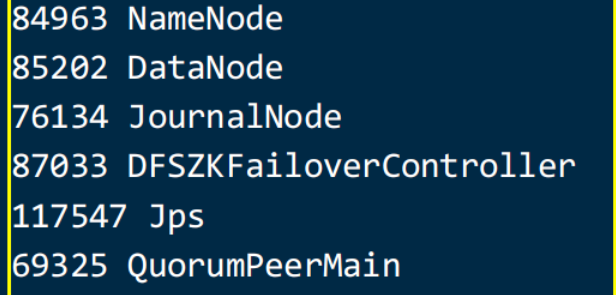
Hadoop高可用集群搭建全攻略
首先准备3台服务器 hadoop11 hadoop12 hadoop13完成分布式的搭建 hadoop11为namenode datanode hadoop12 hadoop13 为datanodej...

大数据存算分离:提升数据存储性能的秘诀
当大数据像洪水一样涌来,传统“存算一体”架构就像“家庭厨房”——做饭(计算)和储物(存储)挤在同一个空间,人多了就会拥挤不堪。而存算分离则像“餐厅+中央厨房”:存储(中央厨房)和计算(餐厅后厨)分开...

Flink技术实践-Flink指标监控全景指南
Flink作业的实时运行状态,本质上是黑盒的——如果你只盯着业务延迟这一个指标,就像开车只看后视镜。本文将从 Flink 监控底层逻辑出发,系统梳理生产必盯核心指标,构建一套完整的 Flink 作业监...

Ai智能体专栏—从零搭建完全本地、无依赖、可离线的个人知识库—Ollama+RAGFlow 保姆级教程
从零搭建完全本地、无依赖、可离线的个人知识库---Ollama+RAGFlow 保姆级教程
agency-agents:211 个即插即用的 AI 专家角色 — 覆盖工程、设计、营销、产品、游戏、安全、金融等 18 个部门。不是通用提示词模板,每个智能体都有独立的人设、专业流程和可交付成果
摘要:成功将211个AI专家角色从agency-agents-zh仓库转换为Skill格式并安装。这些角色涵盖18个专业领域,包括46个中国市场专属智能体(小红书/抖音/微信等)。转换后每个Skill...

护眼钢化膜真的有用吗?选购指南+3个核心指标
下次选购护眼贴膜时,依次确认:✅ 是否有AR降反射?反射率多少?(≤1%合格,≤0.5%优秀)✅ 是否有圆偏振光转换?(明确标注,不能含糊)✅ 透光率是否≥95%?是否不偏色?✅ 硬度是否标注莫氏硬度...